这是继上一篇文章 “Elasticsearch:聊天机器人教程(一)”的续篇。本教程的这一部分讨论聊天机器人实现中最有趣的方面,以帮助你理解它并对其进行自定义。
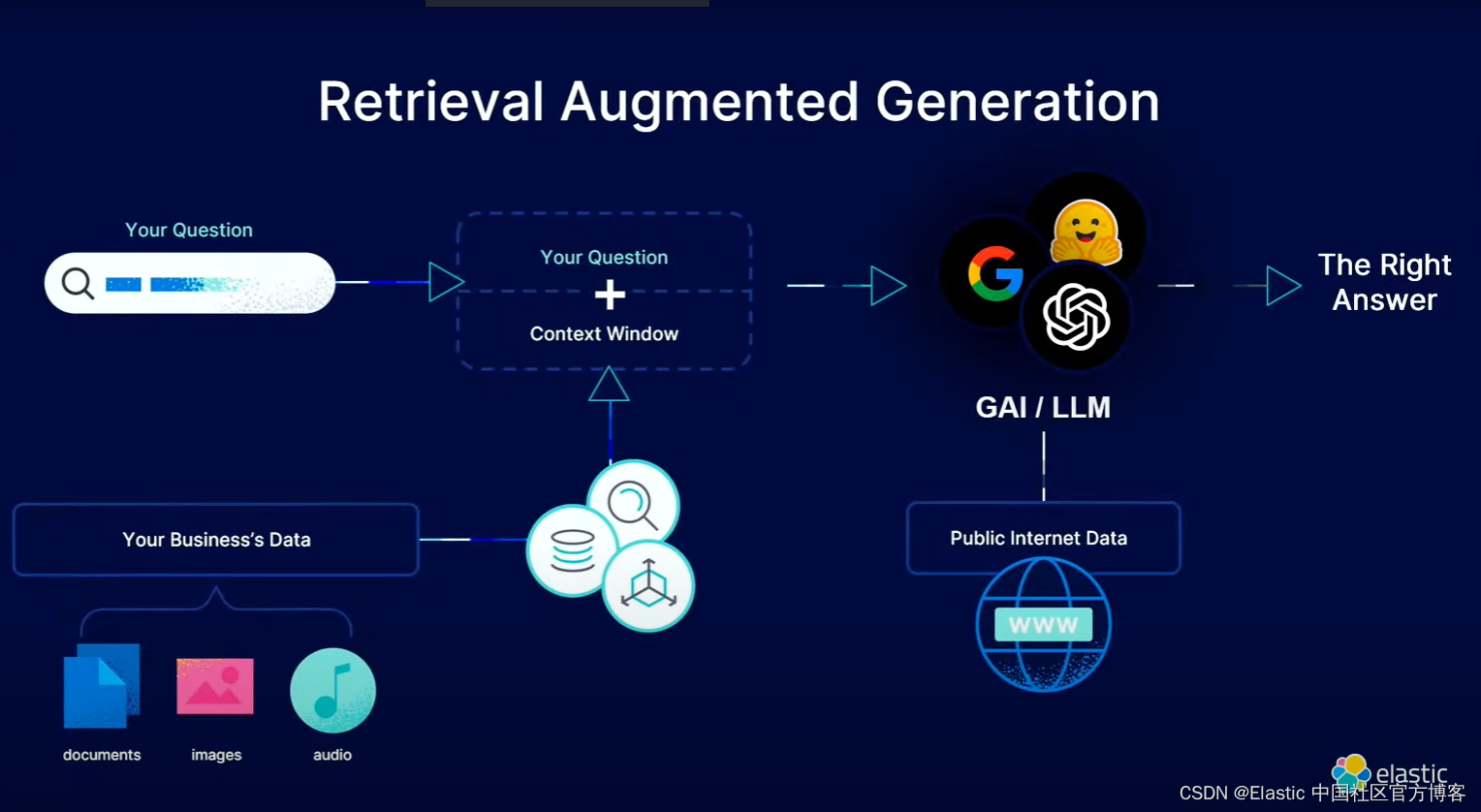
数据摄入
在此应用程序中,所有示例文档的摄取都是通过 flask create-index 命令触发的。 该命令的实现位于 api 目录下的 app.py 文件中,它只是从 data 目录中导入 index_data.py 模块并调用其 main() 函数,该函数对 data 中存储的所有文档执行完整导入 .json 文件。在运行文件之前,我们需要注意到如下的一个配置文件:
.flaskenv
$ pwd
/Users/liuxg/python/elasticsearch-labs/example-apps/chatbot-rag-app
$ ls -al
total 936
drwxr-xr-x 16 liuxg staff 512 Jan 15 10:32 .
drwxr-xr-x 9 liuxg staff 288 Jan 15 09:21 ..
-rw-r--r-- 1 liuxg staff 958 Jan 15 09:39 .env
-rw-r--r-- 1 liuxg staff 55 Jan 15 09:21 .flaskenv
-rw-r--r-- 1 liuxg staff 82 Jan 15 09:21 .gitignore
drwxr-xr-x 6 liuxg staff 192 Jan 15 09:25 .venv
-rw-r--r-- 1 liuxg staff 807 Jan 15 09:21 Dockerfile
-rw-r--r-- 1 liuxg staff 6085 Jan 15 09:21 README.md
drwxr-xr-x 8 liuxg staff 256 Jan 15 10:26 api
-rw-r--r-- 1 liuxg staff 430277 Jan 15 09:21 app-demo.gif
drwxr-xr-x 5 liuxg staff 160 Jan 15 09:44 data
-rw-r--r-- 1 liuxg staff 860 Jan 15 09:21 env.example
drwxr-xr-x 10 liuxg staff 320 Jan 15 12:56 frontend
-rw-r----- 1 liuxg staff 1915 Jan 15 10:32 http_ca.crt
-rw-r--r-- 1 liuxg staff 315 Jan 15 09:21 requirements.in
-rw-r--r-- 1 liuxg staff 5259 Jan 15 09:21 requirements.txt
$ cat .flaskenv
FLASK_APP=api/app.py
FLASK_RUN_PORT=3001
FLASK_DEBUG=1在上面我们可以看到 FLASK_APP 的值对应于 api/app.py。这样我们可以在项目的根目录下进行运行,而不用去 api 目录下去运行 flask 指令。
文件结构
数据文件位于 data/data.json 文件中。每个文档的结构如下:
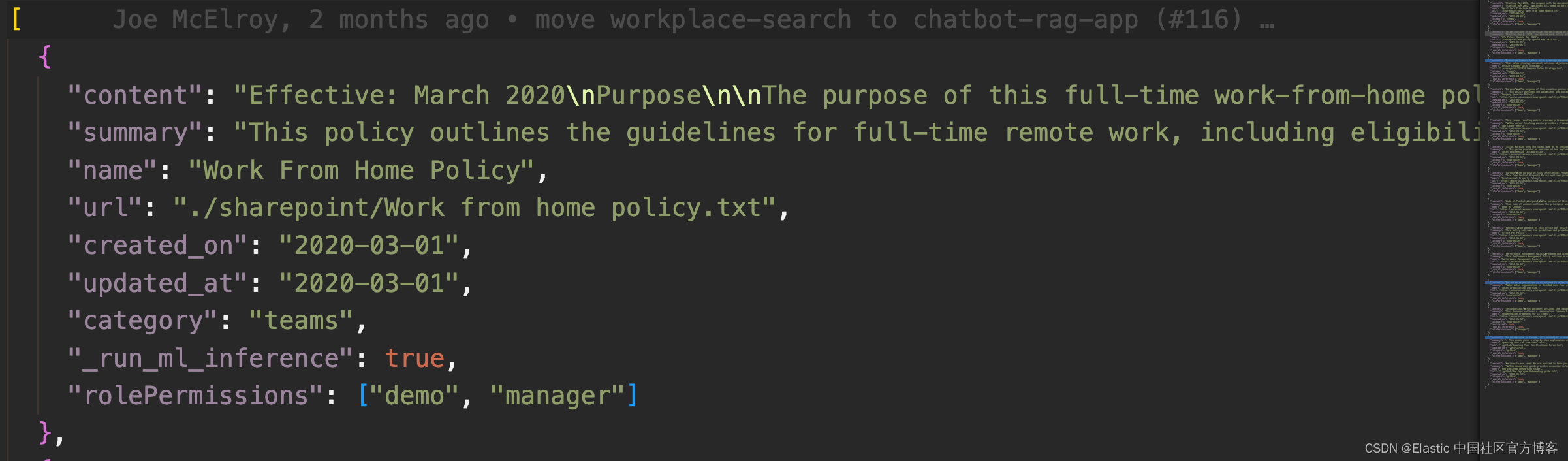
- name:文档标题
- url:外部站点上托管的文档的 URL
- summary:文档内容的简短摘要
- content:文档正文
- create_on:创建日期
- updated_at:更新日期(如果文档从未更新过,则可能会丢失)
- category:文档的类别,可以是 github、sharepoint 或 teams
- rolePermissions:角色权限列表
由此,此示例应用程序使用 content 字段作为要索引的文本,并添加 name、summary、url、category 和 updated_at 作为关联元数据。
以下 Python 代码片段显示了如何导入文档:
data/index_data.py
metadata_keys = ['name', 'summary', 'url', 'category', 'updated_at']
workplace_docs = []
with open(FILE, 'rt') as f:
for doc in json.loads(f.read()):
workplace_docs.append(Document(
page_content=doc['content'],
metadata={k: doc.get(k) for k in metadata_keys}
))这里使用 Python 标准库中的 json 模块来读取数据文件,然后为每个包含的文档创建一个来自 Langchain 的 Document 对象。 文档具有 page_content 属性,该属性定义要转换为向量并搜索的内容,以及许多存储为元数据的附加字段。 metadata_keys 确定源内容中的哪些字段将存储为文档元数据。
根据你的摄取需求,可以改进或更改方法。 Langchain 项目提供了大量可供选择的文档加载器,可以根据源内容的格式使用这些加载器。
Elastic Learned Sparse EncodeR (ELSER) 模型
此应用程序中使用的 Elasticsearch 索引配置为自动为插入的所有文档创建稀疏向量嵌入。 index_data.py 中的 install_elser() 函数确保 ELSER 模型已安装并部署在你正在使用的 Elasticsearch 实例上。
文本分割
这些文档中的内容字段很长,这意味着单个嵌入将无法完全表示它。 处理大量文本时的标准解决方案是将文本分割成较短的段落,然后获取各个段落的嵌入,所有这些都被存储和索引。
在此应用程序中,使用了 Langchain 库中的 RecursiveCharacterTextSplitter 类,与 OpenAI 的 tiktoken 编码器配对,该编码器以 token 的形式计算段落的长度,这与 LLM 使用的单位相同。
考虑以下示例,该示例演示了文本拆分在应用程序中的工作原理:
>>> from langchain.docstore.document import Document
>>> from langchain.text_splitter import RecursiveCharacterTextSplitter
>>> doc = Document(page_content='the quick brown fox jumped over the lazy dog')
>>> text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(chunk_size=5, chunk_overlap=2)
>>> split_docs = text_splitter.transform_documents([doc])
>>> split_docs
[Document(page_content='the quick brown fox jumped'),
Document(page_content='fox jumped over the lazy'),
Document(page_content='the lazy dog')]通过设置文本分割器的 chunk_size 参数,可以控制生成的段落的长度。 chunk_overlap 允许段落之间存在一定程度的重叠,这通常有助于获得更好的嵌入。
在实际应用中,分离器使用以下参数进行初始化:
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=512, chunk_overlap=256
)欢迎你更改这些值并查看更改如何影响聊天机器人的质量。 每次更改拆分器的配置时,你都应该通过运行 flask create-index 命令重新生成索引。
文件存储
文档存储在 Elasticsearch 索引中。 索引的名称由 ES_INDEX 环境变量控制,该变量在 .env 文件中定义。 默认情况下,该索引的名称是 workplace-app-docs。
该应用程序使用 ElasticsearchStore 类,该类是 Langchain 中 Elasticsearch 集成的一部分,并使用官方的 Python Elasticsearch 客户端库。
处理 Elasticsearch 索引的完整逻辑如下所示:
from elasticsearch import Elasticsearch, NotFoundError
from langchain.vectorstores import ElasticsearchStore
INDEX = os.getenv("ES_INDEX", "workplace-app-docs")
ELASTIC_CLOUD_ID = os.getenv("ELASTIC_CLOUD_ID")
ELASTICSEARCH_URL = os.getenv("ELASTICSEARCH_URL")
ELASTIC_API_KEY = os.getenv("ELASTIC_API_KEY")
ELSER_MODEL = os.getenv("ELSER_MODEL", ".elser_model_2")
# create an Elasticsearch client instance
if ELASTICSEARCH_URL:
elasticsearch_client = Elasticsearch(
hosts=[ELASTICSEARCH_URL],
ca_certs = "./http_ca.crt",
verify_certs = True
)
elif ELASTIC_CLOUD_ID:
elasticsearch_client = Elasticsearch(
cloud_id=ELASTIC_CLOUD_ID, api_key=ELASTIC_API_KEY
)
else:
raise ValueError(
"Please provide either ELASTICSEARCH_URL or ELASTIC_CLOUD_ID and ELASTIC_API_KEY"
)
# delete the existing index, if found
elasticsearch_client.indices.delete(index=INDEX, ignore_unavailable=True)
# write documents stored in "docs" to the index
ElasticsearchStore.from_documents(
workplace_docs,
es_connection=elasticsearch_client,
index_name=INDEX,
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy(model_id=ELSER_MODEL),
)
ElasticsearchStore.from_documents() 方法导入 workplace_docs 中存储的所有 Document 实例,将它们写入 index_name 参数中给定的索引。 所有操作都通过 es_connection 参数中给出的客户端执行。
策略参数定义了该索引的使用方式。 对于此应用程序,SparseVectorRetrievalStrategy 类指示要为每个文档维护稀疏向量嵌入。 这将向索引添加一个管道,该管道将通过请求的模型(在本例中为 ELSER 版本 2)生成嵌入。
Elasticsearch 与 Langchain 的集成提供了可以根据用例使用的其他策略。 特别是,当使用密集向量嵌入时可以使用 ApproxRetrievalStrategy。
Chatbot 端点
当你在前端输入问题时,会向 /api/chat 端点发送 POST 请求。 请求正文必须包含用户提出的问题,格式如下:
{
"question": "the question goes here"
}来自应用程序的响应是一个事件流,如服务器发送事件 (server-sent event - SSE) 规范中所定义。 服务器返回给客户端的事件具有以下顺序:
data: [SESSION_ID] session-id-assigned-to-this-chat-sessiondata: [SOURCE] json-formatted-document(repeated for each relevant document source that was identified)data: response chunk(repeated for each response chunk returned by the LLM)data: [DONE]
客户端可以通过向请求 URL 添加 session_id 查询字符串参数来选择提出后续问题。
聊天机器人端点的高级逻辑位于 Flask 应用程序的 api_chat() 函数中,位于文件 api/app.py 中:
@app.route("/api/chat", methods=["POST"])
def api_chat():
request_json = request.get_json()
question = request_json.get("question")
if question is None:
return jsonify({"msg": "Missing question from request JSON"}), 400
session_id = request.args.get("session_id", str(uuid4()))
return Response(ask_question(question, session_id), mimetype="text/event-stream")文件 api/chat.py 中的 ask_question() 函数是一个生成器函数,它使用 Flask 的响应流功能来流式传输上述事件,该功能基于 yield 关键字:
@stream_with_context
def ask_question(question, session_id):
yield f"data: {SESSION_ID_TAG} {session_id}\n\n"
# ...
yield f"data: {DONE_TAG}\n\n"检索阶段
当收到问题时,应用程序首先在 Elasticsearch 索引中搜索相关文档。 这是通过为问题生成稀疏向量嵌入,然后在索引中搜索与其最接近的嵌入(每个嵌入与文档的一段相关联)来实现的。
与摄取阶段一样,Elasticsearch 索引是通过 ElasticsearchStore 与 Langchain 集成来管理的:
store = ElasticsearchStore(
es_connection=elasticsearch_client,
index_name=INDEX,
strategy=ElasticsearchStore.SparseVectorRetrievalStrategy(model_id=ELSER_MODEL),
)Langchain 的 retriver 接口的 invoke() 方法很好地抽象了为问题生成嵌入,然后搜索它,该方法执行所有这些任务并返回找到的最相关文档的列表:
docs = store.as_retriever().invoke(question)
for doc in docs:
doc_source = {**doc.metadata, 'page_content': doc.page_content}
yield f'data: {SOURCE_TAG} {json.dumps(doc_source)}\n\n'你可以在此处查看返回的段落如何作为源发送给客户端。 React 应用程序会将这些显示为答案下方的 “Search Results”。更多关于 Langchain 的 retriever 示例可以在文章 “Elasticsearch:带有自查询检索器的聊天机器人示例” 中进行阅读。
需要注意的是,ElasticsearchStore 类中使用的 strategy 参数必须与摄取期间使用的策略相匹配。 在此示例中,SparseVectorRetrievalStrategy 从 Elastic 的 ELSER 模型创建并搜索稀疏向量。 你可以评估的另一个有趣的选项是使用 ApproxRetrievalStrategy,它使用密集向量嵌入。
LLM Prompt
有了手头的搜索结果,现在可以生成发送给 LLM 的提示。 提示必须包括用户发送的原始问题、在检索阶段获得的相关段落以及对 LLM 的说明,说明答案应来自所包含的段落。
为了渲染提示,应用程序使用 Flask 的 render_template() 函数:
qa_prompt = render_template('rag_prompt.txt', question=question, docs=docs)此调用中引用的模板文件位于 api/templates/rag_prompt.txt 中。
Use the following passages to answer the user's question.
Each passage has a NAME which is the title of the document.
When answering, give the source name of the passages you are answering from at the end.
Put them in a comma separated list, prefixed with SOURCES:.
Example:
Question: What is the meaning of life?
Response:
The meaning of life is 42.
SOURCES: Hitchhiker's Guide to the Galaxy
If you don't know the answer, just say that you don't know, don't try to make up an answer.
----
{% for doc in docs -%}
---
NAME: {{ doc.metadata.name }}
PASSAGE:
{{ doc.page_content }}
---
{% endfor -%}
----
Question: {{ question }}
Response:如果你想查看此模板对聊天机器人响应质量的影响,你可以对此模板进行更改。 但始终确保保留呈现检索到的段落的 for 循环。
生成阶段
LLM 的提示现已准备就绪,剩下的就是发送它并接收响应。 为了连接到 LLM,该应用程序使用 Langchain 的流支持,这非常适合该应用程序中使用的事件流:
answer = ''
for chunk in get_llm().stream(qa_prompt):
yield f'data: {chunk.content}\n\n'
answer += chunk.contentget_llm() 函数在 api/llm_integrations.py 中定义。 其目的是根据配置从 Langchain 返回正确的 LLM 积分。 假设你配置了 OpenAI,返回的 LLM 将是来自 Langchain 的 ChatOpenAI 类的实例。
聊天历史记录和后续问题
当用户只能提出一个问题时,上述过程效果很好。 但该应用程序也允许后续问题,这会带来一些额外的复杂性,主要的一个是需要存储所有先前的问题和答案,以便它们可以包含在后续问题中。
此应用程序中的聊天历史记录通过 ElasticsearchChatMessageHistory 类进行管理,该类是 Elasticsearch 与 Langchain 集成的另一个类。 每组相关问题和答案都会写入 Elasticsearch 索引,并引用所使用的会话 ID。
def get_elasticsearch_chat_message_history(index, session_id):
return ElasticsearchChatMessageHistory(
es_connection=elasticsearch_client, index=index, session_id=session_id
)
INDEX_CHAT_HISTORY = os.getenv(
"ES_INDEX_CHAT_HISTORY", "workplace-app-docs-chat-history"
)
chat_history = get_elasticsearch_chat_message_history(
INDEX_CHAT_HISTORY, session_id
)你可能在上一节中注意到,即使来自 LLM 的响应以块的形式流式传输到客户端,也会使用完整响应生成 answer 变量。 这样,每次交互后,响应及其问题都可以添加到历史记录中:
chat_history.add_user_message(question)
chat_history.add_ai_message(answer)如果客户端在请求 URL 的查询字符串中发送 session_id 参数,则假定该问题是在同一会话下的任何先前问题的上下文中提出的。
该申请针对后续问题采取的方法是向 LLM 发送一个准备问题,其中包含所有问题和答案以及新问题,并要求将所有信息压缩为一个问题。 以下是执行此任务的逻辑:
if len(chat_history.messages) > 0:
# create a condensed question
condense_question_prompt = render_template(
'condense_question_prompt.txt', question=question,
chat_history=chat_history.messages)
question = get_llm().invoke(condense_question_prompt).content这和主要问题的处理方式有很多相似之处,但是在这种情况下不需要使用 LLM 的流接口,所以使用了 invoke() 方法。
压缩问题使用不同的提示,该提示存储在文件 **api/templates/condense_question_prompt.txt` 中:
Given the following conversation and a follow up question, rephrase the follow up question to be a standalone question, in its original language.
Chat history:
{% for dialogue_turn in chat_history -%}
{% if dialogue_turn.type == 'human' %}Question: {{ dialogue_turn.content }}{% elif dialogue_turn.type == 'ai' %}Response: {{ dialogue_turn.content }}{% endif %}
{% endfor -%}
Follow Up Question: {{ question }}
Standalone question:此提示呈现会话中的所有问题和响应,以及最后的新后续问题。 LLM 被要求提供一个包含所有信息的精简问题,然后该问题将替换用户输入的原始后续问题。
你应该注意,使用压缩问题是一个可用的选项,但另一个可行的选项是在主提示中写入整个问题和响应历史记录。 希望现在你已经很好地了解了该应用程序的工作原理,如果你有兴趣,可以尝试不同的提示并找到最适合你的用例的提示。
结论
你已完成聊天机器人教程。 恭喜!
我们希望你现在熟悉聊天机器人项目的基本组件以及检索增强生成(RAG)背后的想法。
我们鼓励你采用我们的示例应用程序,对其进行试验,并使其成为你自己的应用程序。