传送门:蓝桥云课实验
目录
- 1. 实验环境
- 2. 实验目的
- 3. 相关原理
- 4. 实验步骤
- 4.1 数据预处理
- 4.1.1 对于类型变量的处理
- 4.1.2 对于数值类型变量进行标准化
- 4.1.3 数据集分割
- 4.2 创建模型
- 手写用Tensor运算的人工神经网络
- 4.3 训练模型
- 4.3.1 数据的分批次处理
- 4.4 测试模型
1. 实验环境
Jupyter Notebook
Python 3.7
PyTorch 1.4.0
2. 实验目的
构建人工神经网络,并用它来预测未来某地区租赁单车的使用情况。
3. 相关原理
数据归一化、类型变量的转换。
搭建基本神经网络的方法。
数据分批次训练原则。
测试及简单分析神经网络的方法
4. 实验步骤
#数据的下载与解压:
!wget http://labfile.oss.aliyuncs.com/courses/1073/bike-sharing-dataset.zip
!unzip bike-sharing-dataset.zip
数据都在文件“hour.csv”中,该文件大小为 1.2M,完全可以直接读取到内存中

数据文件记录了每小时(hr)共享单车的使用数量(cnt),除了这两个数据项外,还包括当天的日期(dteday),季节(season),星期几(weekday),是否是假期(holiday),当天的温度、湿度、风速、用户是否注册等等,我们就是要使用这些数据训练神经网络模型。
4.1 数据预处理
import numpy as np
import pandas as pd #读取csv文件的库
import matplotlib.pyplot as plt
import torch
from torch.autograd import Variable
import torch.optim as optim
# 让输出的图形直接在Notebook中显示
%matplotlib inline
#首先,让我们再来看看数据长什么样子
#读取数据到内存中,rides为一个dataframe对象
data_path = 'bike-sharing-dataset/hour.csv'
rides = pd.read_csv(data_path)
rides.head() #运用 pandas 模块的 head 方法,将数据的数据表头和部分数据项打印出来。
4.1.1 对于类型变量的处理
类型变量是指这个变量的不同值仅仅表达不同的类型,值的大小不同但没有高低之分。
有很多变量都属于类型变量,例如 season=1,2,3,4 代表四季。
我们不能将 season 变量直接输入到神经网络,这是因为 season 数值越高并不表示相应的信号强度越大。
解决方案是将类型变量用一个“一位热码“(one-hot)来编码,也就是:
𝑠𝑒𝑎𝑠𝑜𝑛=1→(1,0,0,0)
𝑠𝑒𝑎𝑠𝑜𝑛=2→(0,1,0,0)
𝑠𝑒𝑎𝑠𝑜𝑛=3→(0,0,1,0)
𝑠𝑒𝑎𝑠𝑜𝑛=4→(0,0,0,1)
因此,如果一个类型变量有 n 个不同取值,那么我 one-hot 所对应的向量长度就为 n。
例如:
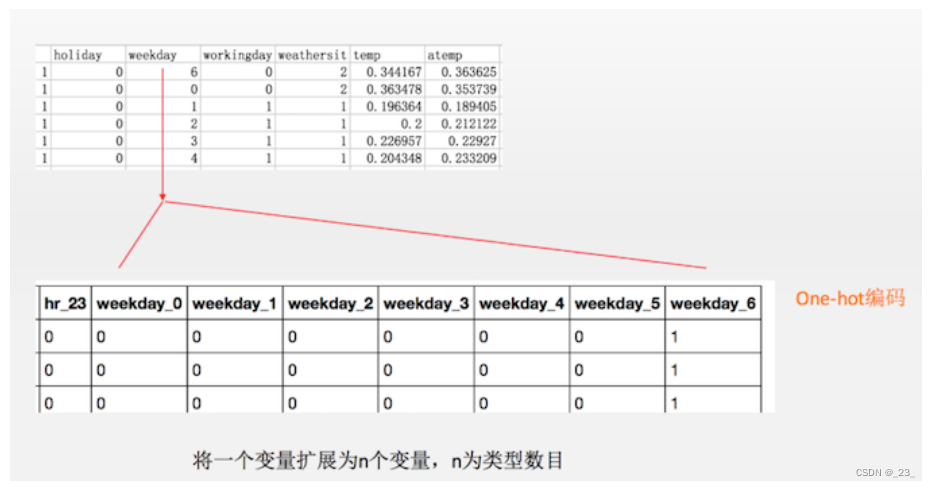
#对于类型变量的特殊处理
# season=1,2,3,4, weathersi=1,2,3, mnth= 1,2,...,12, hr=0,1, ...,23, weekday=0,1,...,6
# 经过下面的处理后,将会多出若干特征,例如,对于season变量就会有 season_1, season_2, season_3, season_4
# 这四种不同的特征。
dummy_fields = ['season', 'weathersit', 'mnth', 'hr', 'weekday']
for each in dummy_fields:
#利用pandas对象,我们可以很方便地将一个类型变量属性进行one-hot编码,变成多个属性
dummies = pd.get_dummies(rides[each], prefix=each, drop_first=False)
rides = pd.concat([rides, dummies], axis=1)
# 把原有的类型变量对应的特征去掉,将一些不相关的特征去掉
fields_to_drop = ['instant', 'dteday', 'season', 'weathersit',
'weekday', 'atemp', 'mnth', 'workingday', 'hr']
data = rides.drop(fields_to_drop, axis=1)
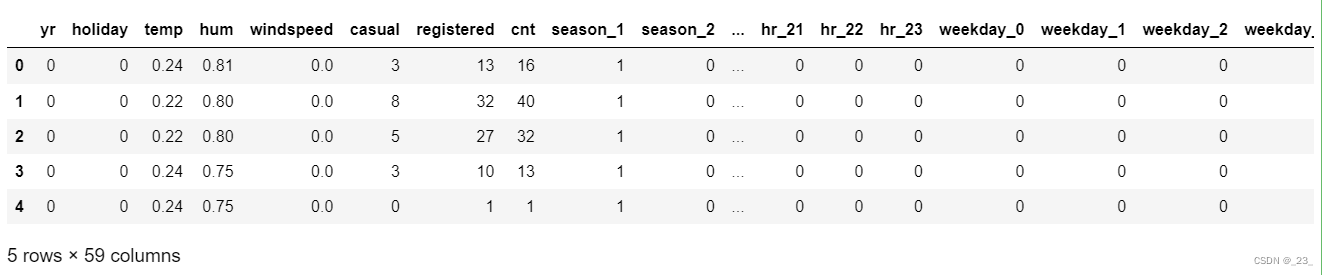
data.head()
从显示出的数据中可以看到一年四季、12 个月份、24 个小时数、一周 7 天、天气情况都已经被转化成了 one-hot 变量。
4.1.2 对于数值类型变量进行标准化
由于每个数值型变量都是相互独立的,所以它们的数值绝对大小与问题本身没有关系。(更看重变化趋势而非数值大小)
为了消除数值大小的差异,我们对每一个数值型变量进行标准化处理,也就是让其数值都围绕着0左右波动。
比如,对于温度 temp 这个变量来说,它在整个数据库取值的平均值为 mean(temp),方差为 std(temp),所以,归一化的温度计算为:
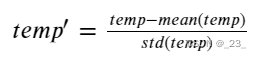
这样做的好处就是可以将不同的取值范围的变量设置为让它们处于一个平等的地位。
# 调整所有的特征,标准化处理
quant_features = ['cnt', 'temp', 'hum', 'windspeed']
#quant_features = ['temp', 'hum', 'windspeed']
# 我们将每一个变量的均值和方差都存储到scaled_features变量中。
scaled_features = {}
for each in quant_features:
mean, std = data[each].mean(), data[each].std()
scaled_features[each] = [mean, std]
data.loc[:, each] = (data[each] - mean)/std
4.1.3 数据集分割
首先,在变量集合上,我们分为了特征和目标两个集合。
其中,特征变量集合包括:年份(yr),是否节假日( holiday),温度(temp),湿度(hum),风速(windspeed),季节1~4(season),天气1~4(weathersit,不同天气种类),月份1~12(mnth),小时0~23(hr),星期0~6(weekday),它们是输入给神经网络的变量;
目标变量包括:用户数(cnt),临时用户数(casual),以及注册用户数(registered),其中我们仅仅将 cnt 作为我们的目标变量,另外两个暂时不做任何处理。
这样我们就将利用 56 个特征变量作为神经网络的输入,来预测 1 个变量作为神经网络的输出。
接下来,我们再将 17379 条纪录划分为两个集合,分别为前 16875 条记录作为训练集训练我们的神经网络;后 21 天的数据,也就是 21x24=504 条记录作为测试集来检验我们的模型的预测效果。这一部分数据是不参与神经网络训练的。
# 将所有的数据集分为测试集和训练集,我们以后21天数据一共21*24个数据点作为测试集,其它是训练集
test_data = data[-21*24:]
train_data = data[:-21*24]
print('训练数据:',len(train_data),'测试数据:',len(test_data))
# 将我们的数据列分为特征列和目标列
#目标列
target_fields = ['cnt', 'casual', 'registered']
features, targets = train_data.drop(target_fields, axis=1), train_data[target_fields]
test_features, test_targets = test_data.drop(target_fields, axis=1), test_data[target_fields]
# 将数据从pandas dataframe转换为numpy
X = features.values
Y = targets['cnt'].values
Y = Y.astype(float)
Y = np.reshape(Y, [len(Y),1])
losses = []
features.head()
4.2 创建模型
# 定义神经网络架构,features.shape[1]个输入层单元,10个隐含层,1个输出层
input_size = features.shape[1]
hidden_size = 10
output_size = 1
batch_size = 128
neu = torch.nn.Sequential( #调用 torch.nn.Sequential 来构造的神经网络
torch.nn.Linear(input_size, hidden_size), #从输入到隐含层的线性映射
torch.nn.Sigmoid(),
torch.nn.Linear(hidden_size, output_size), #从隐含到输出的线性映射
)
cost = torch.nn.MSELoss() # PyTorch 自带的损失函数
#neu.parameters():neu包含的所有权重和偏置 lr=0.01:执行梯度下降算法的学习率
optimizer = torch.optim.SGD(neu.parameters(), lr = 0.01) #PyTorch自带了优化器来自动实现优化算法
注:torch.nn.Sequential :作用是将一系列的运算模块按顺序搭建成一个多层的神经网络。
torch.nn.Sigmoid():隐含层的非线性 Sigmoid 函数
torch.nn.MSELoss :是 PyTorch 自带的一个封装好的计算均方误差的损失函数,它是一个函数指针,赋予了变量 cost
cost(x,y) :计算时调用这个函数,就可以计算预测向量 x 和目标向量 y 之间的均方误差。
torch.optim.SGD :调用了 PyTorch 自带的随机梯度下降算法(Stochastic Gradient Descent,SGD)作为优化器。
手写用Tensor运算的人工神经网络
# 定义神经网络架构,features.shape[1]个输入层单元,10个隐含层,1个输出层
input_size = features.shape[1] #输入层单元个数
hidden_size = 10 #隐含层单元个数
output_size = 1 #输出层单元个数
batch_size = 128 #每隔batch的记录数
weights1 = Variable(torch.randn([input_size, hidden_size]), requires_grad = True) #第一到二层权重
biases1 = Variable(torch.randn([hidden_size]), requires_grad = True) #隐含层偏置
weights2 = Variable(torch.randn([hidden_size, output_size]), requires_grad = True) #隐含层到输出层权重
def neu(x):
#计算隐含层输出
#x为batch_size * input_size的矩阵,weights1为input_size*hidden_size矩阵,
#biases为hidden_size向量,输出为batch_size * hidden_size矩阵
hidden = x.mm(weights1) + biases1.expand(x.size()[0], hidden_size)
hidden = torch.sigmoid(hidden)
#输入batch_size * hidden_size矩阵,mm上weights2, hidden_size*output_size矩阵,
#输出batch_size*output_size矩阵
output = hidden.mm(weights2)
return output
def cost(x, y):
# 计算损失函数
error = torch.mean((x - y)**2)
return error
def zero_grad():
# 清空每个参数的梯度信息
if weights1.grad is not None and biases1.grad is not None and weights2.grad is not None:
weights1.grad.data.zero_()
weights2.grad.data.zero_()
biases1.grad.data.zero_()
def optimizer_step(learning_rate):
# 梯度下降算法
weights1.data.add_(- learning_rate * weights1.grad.data)
weights2.data.add_(- learning_rate * weights2.grad.data)
biases1.data.add_(- learning_rate * biases1.grad.data)
4.3 训练模型
4.3.1 数据的分批次处理
设置每批处理的数据大小 batch_size = 128
# 神经网络训练循环
losses = []
for i in range(1000):
# 每128个样本点被划分为一个撮,在循环的时候一批一批地读取
batch_loss = []
# start和end分别是提取一个batch数据的起始和终止下标
for start in range(0, len(X), batch_size):
end = start + batch_size if start + batch_size < len(X) else len(X)
xx = Variable(torch.FloatTensor(X[start:end]))
yy = Variable(torch.FloatTensor(Y[start:end]))
predict = neu(xx)
loss = cost(predict, yy)
optimizer.zero_grad()
loss.backward()
optimizer.step()
batch_loss.append(loss.data.numpy())
# 每隔100步输出一下损失值(loss)
if i % 100==0:
losses.append(np.mean(batch_loss))
print(i, np.mean(batch_loss))
# 打印输出损失值
fig = plt.figure(figsize=(10, 7))
plt.plot(np.arange(len(losses))*100,losses, 'o-')
plt.xlabel('epoch')
plt.ylabel('MSE')
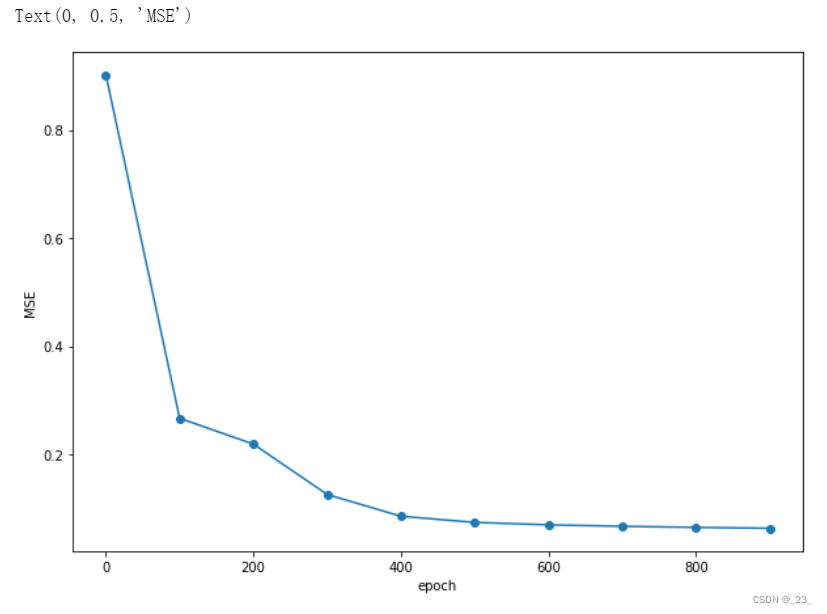
输出:
0 0.90184915
100 0.26658106
200 0.21872732
300 0.12553026
400 0.085256845
500 0.07389378
......
横坐标表示训练周期,纵坐标表示平均误差。可以看到,平均误差快速地随训练周期而下降
4.4 测试模型
# 用训练好的神经网络在测试集上进行预测
targets = test_targets['cnt'] #读取测试集的cnt数值
targets = targets.values.reshape([len(targets),1]) #将数据转换成合适的tensor形式
targets = targets.astype(float) #保证数据为实数
# 将属性和预测变量包裹在Variable型变量中
x = Variable(torch.FloatTensor(test_features.values))
y = Variable(torch.FloatTensor(targets))
# 用神经网络进行预测
predict = neu(x)
predict = predict.data.numpy()
# 将后21天的预测数据与真实数据画在一起并比较
# 横坐标轴是不同的日期,纵坐标轴是预测或者真实数据的值
fig, ax = plt.subplots(figsize = (10, 7))
mean, std = scaled_features['cnt']
ax.plot(predict * std + mean, label='Prediction', linestyle = '--')
ax.plot(targets * std + mean, label='Data', linestyle = '-')
ax.legend()
ax.set_xlabel('Date-time')
ax.set_ylabel('Counts')
# 对横坐标轴进行标注
dates = pd.to_datetime(rides.loc[test_data.index]['dteday'])
dates = dates.apply(lambda d: d.strftime('%b %d'))
ax.set_xticks(np.arange(len(dates))[12::24])
_ = ax.set_xticklabels(dates[12::24], rotation=45)
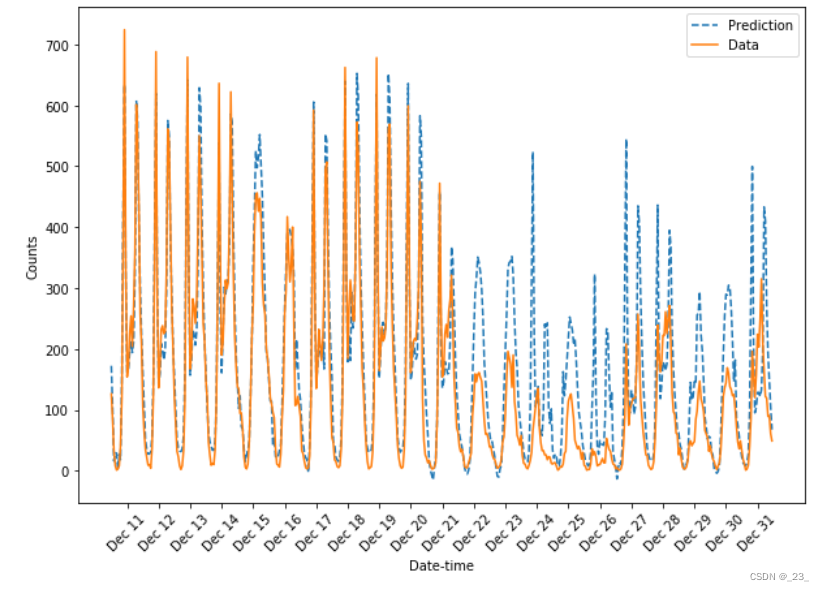
最后就是预测结果分析实验就结束了
通过数据的可视化,两条曲线基本吻合,但在12.25前后实际与预测偏差较大。
考虑现实12.25是圣诞节,并且之后1.1是元旦节,人们的出行习惯会有很大不同,又因为训练样本只有两年长度,圣诞节前后的样本只有1次,所以没有办法对这个特殊假期的模式进行更准确的预测。