前言
- 📚 笔记专栏:斯坦福CS231N:面向视觉识别的卷积神经网络(23)
- 🔗 课程链接:https://www.bilibili.com/video/BV1xV411R7i5
- 💻 CS231n: 深度学习计算机视觉(2017)中文笔记:https://zhuxiaoxia.blog.csdn.net/article/details/80155166
- 🔥 2023最新课程PPT:https://download.csdn.net/download/Julialove102123/88734395
本节重点内容:
- 存在一些挑战:图像分类挑战;
- 怎么解决?数据驱动方式:最近邻、k近邻;
- 怎么让电脑看懂?线性分类-评分函数;
- 怎么损通过电脑找出最合适的?损失函数
图像分类是计算机视觉的核心任务,计算机视觉领域中很多问题,如目标检测、语义分割等都可以关联到图像分类问题。图像分类问题,就是已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像。在本篇内容汇总,ShowMeAI将给大家讲解数据驱动的模型算法,包括简单的 KNN 模型和 线性分类模型。
1. 图像分类的挑战
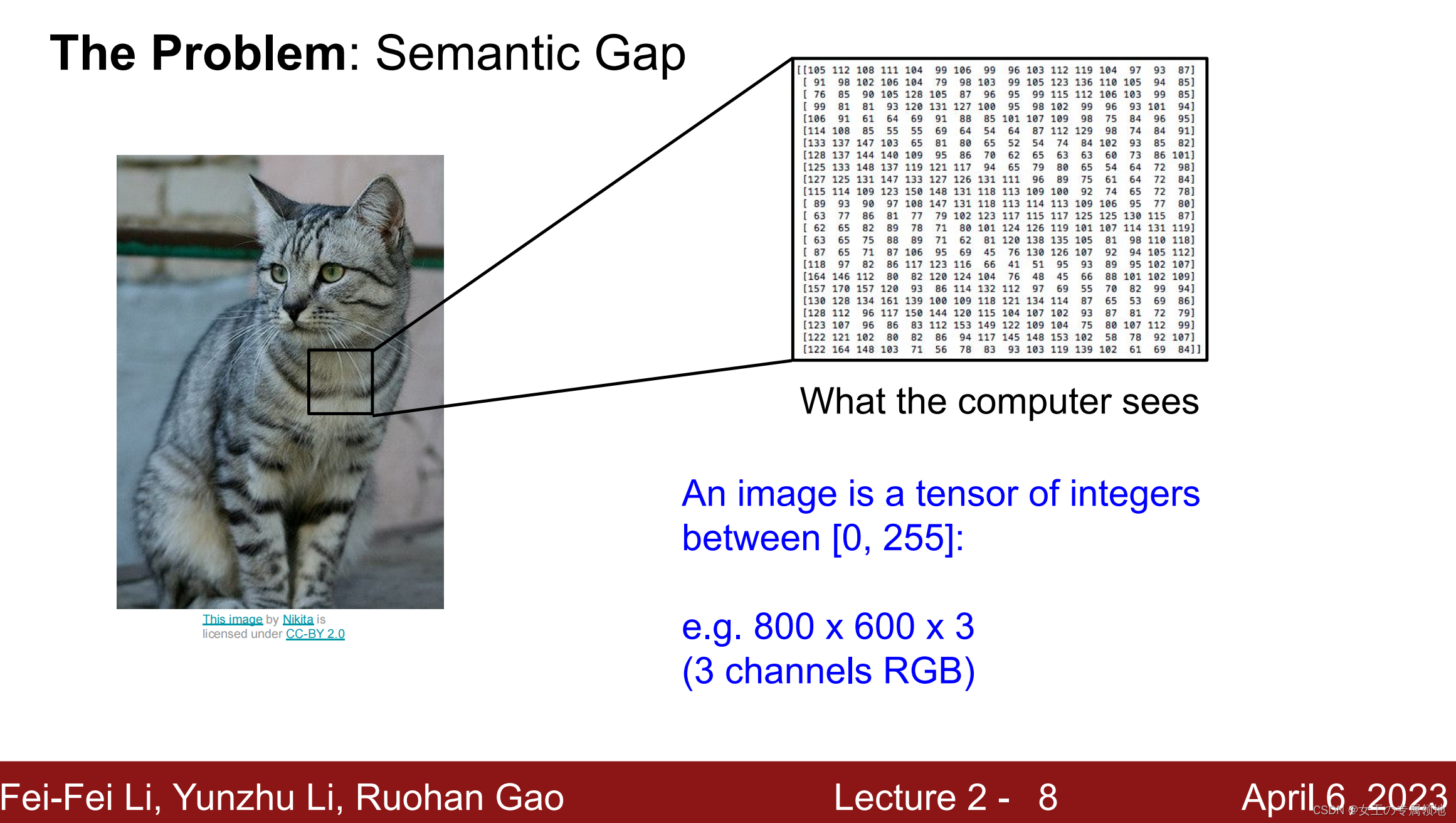
对于计算机而言,图像等同于一个像素矩阵;而对人类,图像是包含丰富语义信息的多媒体呈现,对应不同的物体类别,所以对计算机而言存在巨大的语义鸿沟。
比如,给计算机输入如下小猫的图片,计算机图像分类模型会读取该图片,并计算该图片属于集合{dog, cat, truck, plane, …}中各个标签的概率。但读取的输入图像数据是一个由数字组成的巨大的3维数组。
在下图中,猫的图像大小高800像素,宽600像素,有3个颜色通道(红、绿和蓝,简称RGB),因此它包含了800x600x3个数字,每个数字都是在0~255之间的整型,其中0表示全黑,255表示全白。
我们的任务就是把这些数字变成一个简单的标签,比如 「猫」 。
图像分类算法要足够健壮(鲁棒,robust),这样它能够适应下述变化及组合:
-
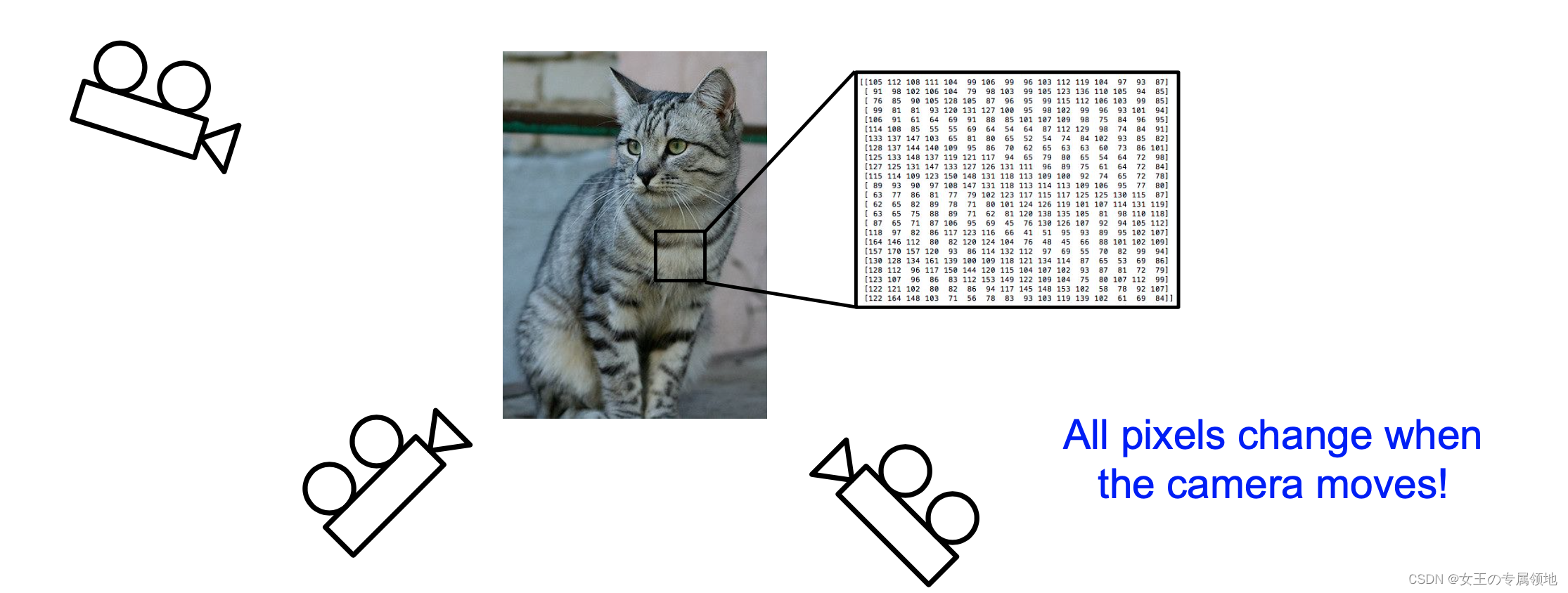
视角变化(Viewpoint variation):同一个物体,摄像机可以从多个角度来展现。
-
光照条件(Illumination conditions):在像素层面上,光照的影响非常大。
-
背景干扰(Background clutter):物体可能混入背景之中,使之难以被辨认。


-
遮挡(Occlusion):目标物体可能被挡住,有时候只有物体的一小部分(可以小到几个像素)是可见的。

-
形变(Deformation):很多东西的形状并非一成不变,会有很大变化。

-
类内差异(Intra-class variation):一类物体的个体之间的外形差异很大,比如椅子。

-
上下文变化(Context):环境中的一些复杂影响。

2. 数据驱动的方式
一种尝试:「硬编码」:先获取猫图像的边缘得到一些线条,然后定义规则比如三条线交叉是耳朵之类。然而这种方式的识别效果不好,并且不能识别新的物体。

新的尝试:采用数据驱动算法,不具体写出识别每个物体对应的规则,而是针对每一类物体,① 收集大量样例图片和标签;② 输入给计算机进行机器学习,归纳模式规律,生成一个分类器模型,总结出区分不同类物体的核心知识要素;③ 用训练好的模型,识别新的图像。

数据驱动算法过程如下:
- 「输入」:输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集。
- 「学习」:这一步的任务是使用训练集来学习每个类的模式规律。一般该步骤叫做分类器训练或者模型学习。
- 「评价」:让分类器对它未曾见过的图像进行分类,把分类器预测的标签和图像真正的分类标签 (基本事实) 对比,并以此来评价分类器的质量。
2.1 最近邻算法(1 Nearest Neighbor)
最近邻算法。训练过程只是简单的记住图像数据和标签,预测的时候和训练数据中图片比较找出最接近的输出标签。这个分类器和卷积神经网络没有任何关系,实际中也极少使用,但通过实现它,可以对解决图像分类问题的方法有个基本认识。
算法原理
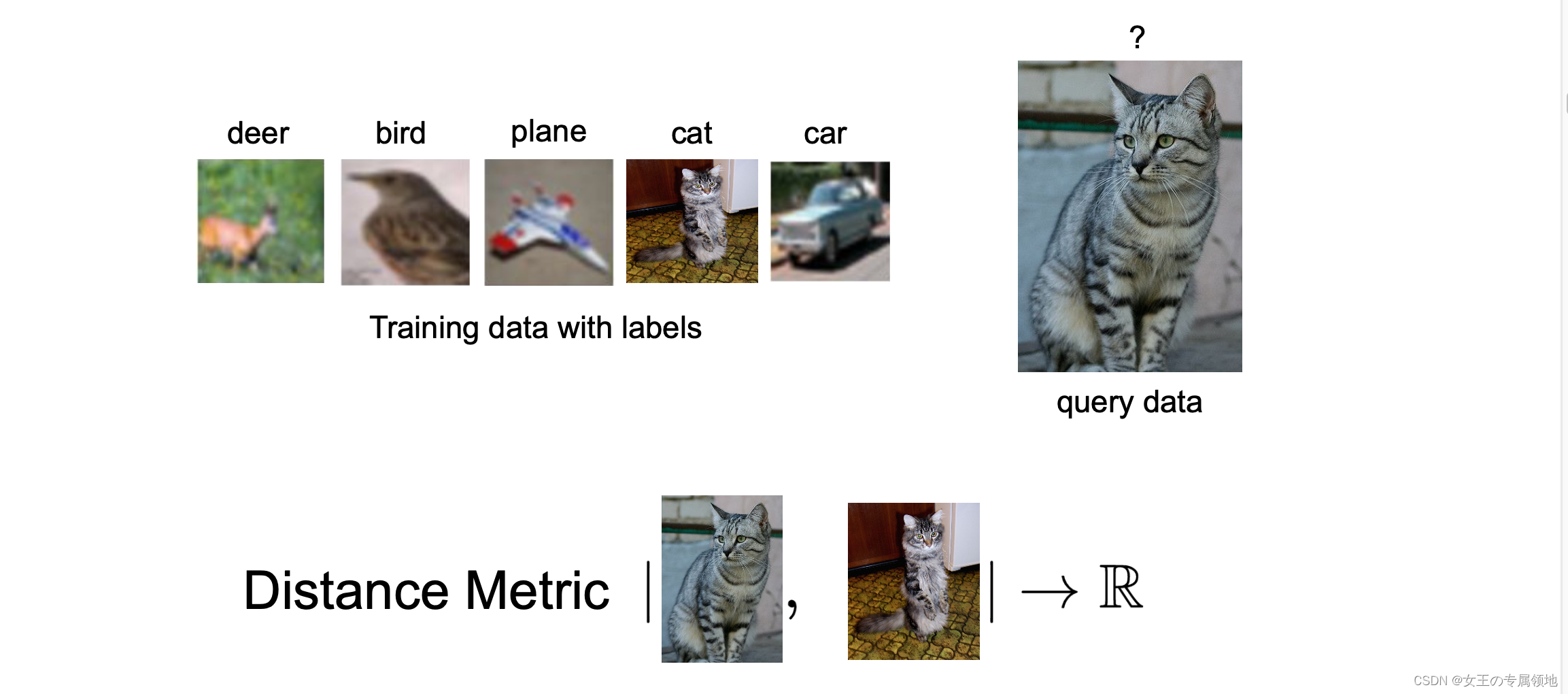
CIFAR-10 是一个非常流行的图像分类数据集。这个数据集包含 10 种分类标签,60000 张 32x32
的小图像,每张图片含有一个标签。这 60000 张图像被分为包含 50000 张(10类 x 5000 张)图像的训练集和包含 10000
张(10类 x 1000张)图像的测试集。
-
划分数据集:
假设现在我们用这 50000 张图片作为训练集,将余下的 10000 作为测试集并打上标签,Nearest Neighbor 算法将会拿着测试图片和训练集中每一张图片去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
-
距离计算:
-
L1距离(曼哈顿距离):

-
L2距离(欧氏距离):
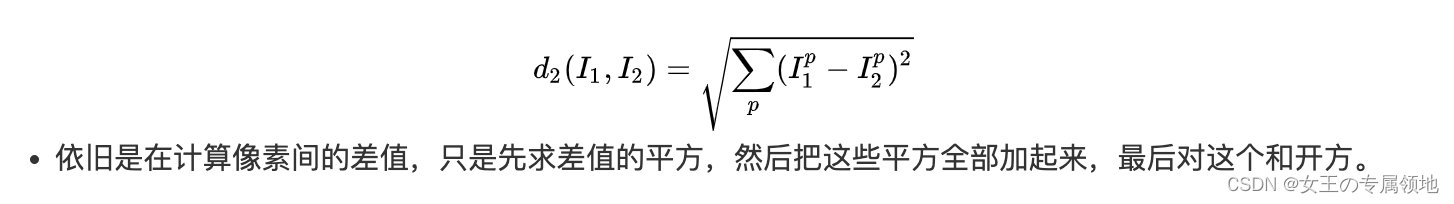
-
L1 距离更依赖于坐标轴的选定,坐标轴选择不同 L1 距离也会跟着变化,判定的数据归类的边界会更趋向于贴近坐标系的轴来分割所属区域,而 L2 的话相对来说与坐标系的关联度没那么大,会形成一个圆,不跟随坐标轴变化。
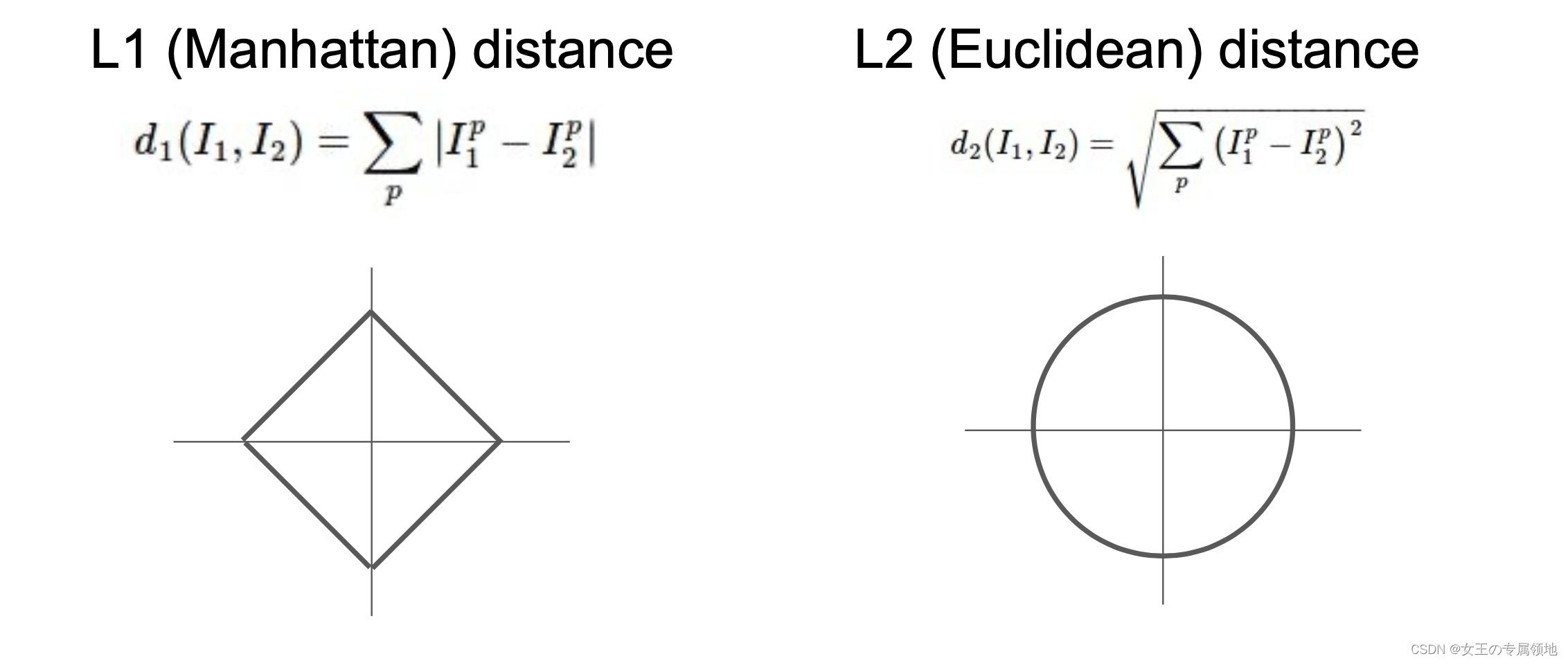
在面对两个向量之间的差异时,L2 比 L1 更加不能容忍这些差异。也就是说,相对于1个巨大的差异,L2 距离更倾向于接受多个中等程度的差异(因为会把差值平方)。
当图像中有特别在意的特征时可以选择 L1 距离;当对图像中所有元素未知时,L2 距离会更自然一些。最好的方式是两种距离都尝试,然后找出最好的那一个。
2.2 K近邻算法(K Nearest Neighbor)
只用最相似的 1 张图片的标签来作为测试图像的标签,有时候会因为参照不够多而效果不好,我们可以使用 k-Nearest Neighbor 分类器。KNN的思想是:找最相似的 k 个图片的标签,k中数量最多的标签作为对测试图片的预测。
当k=1的时候,k-Nearest Neighbor 分类器就是上面所说的最邻近分类器。
🔥 可视化近邻算法:http://vision.stanford.edu/teaching/cs231n-demos/knn/
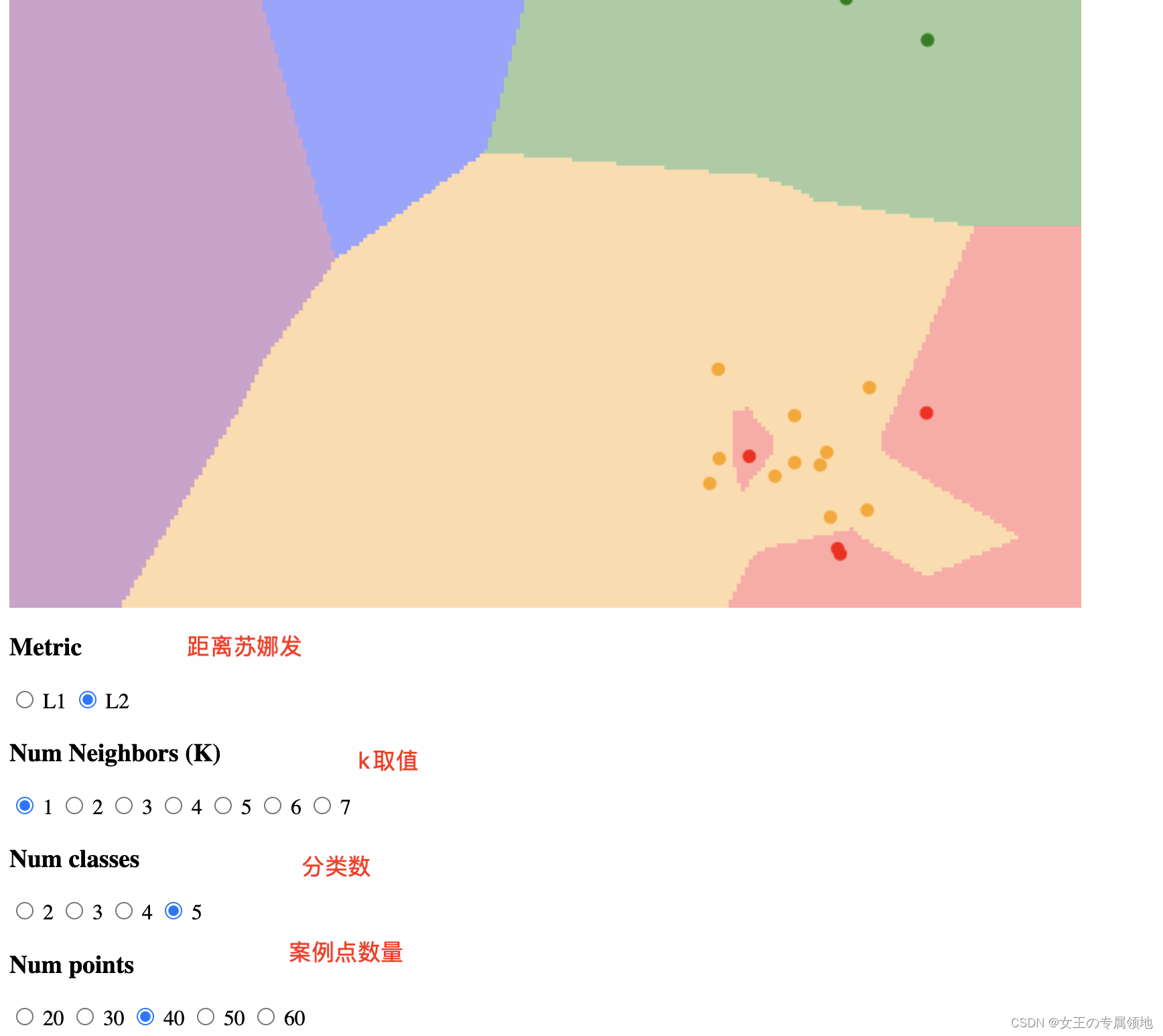

❓那么问题来了?
1. k怎么选?KNN 分类器需要设定k值,如何选择k值最合适?
2. 距离计算方式怎么选?L1 距离和 L2 距离选哪个比较好(还是使用其他的距离度量准则例如点积)?
就有了超参数的概念!!!
1)超参数调优
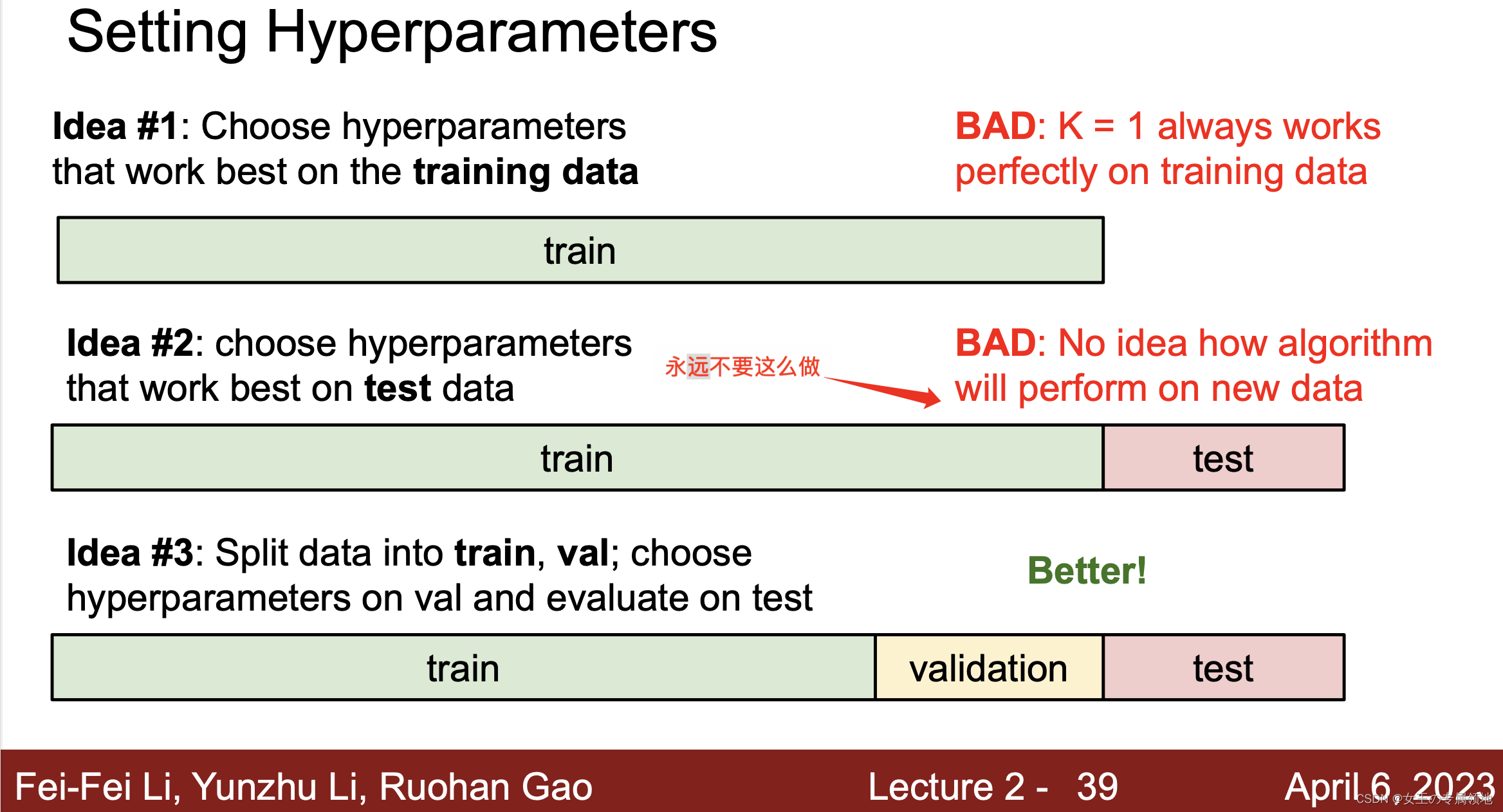
上述这些选择,被称为超参数(hyperparameter)。在基于数据进行学习的机器学习算法设计中,超参数是很常见的。超参数是需要提前设置的,设置完成后模型才可以训练学习,具体的设置方法通常要借助于实验,尝试不同的值,根据效果表现进行选择。那如何调优来选择呢?答案是借助验证集。
方法 1:设置验证集
从训练集中取出一部分数据用来调优,称之为 验证集(validation set)。以 CIFAR-10 为例,可以用 49000 个图像作为训练集,用 1000 个图像作为验证集。验证集其实就是作为假的测试集来调优。
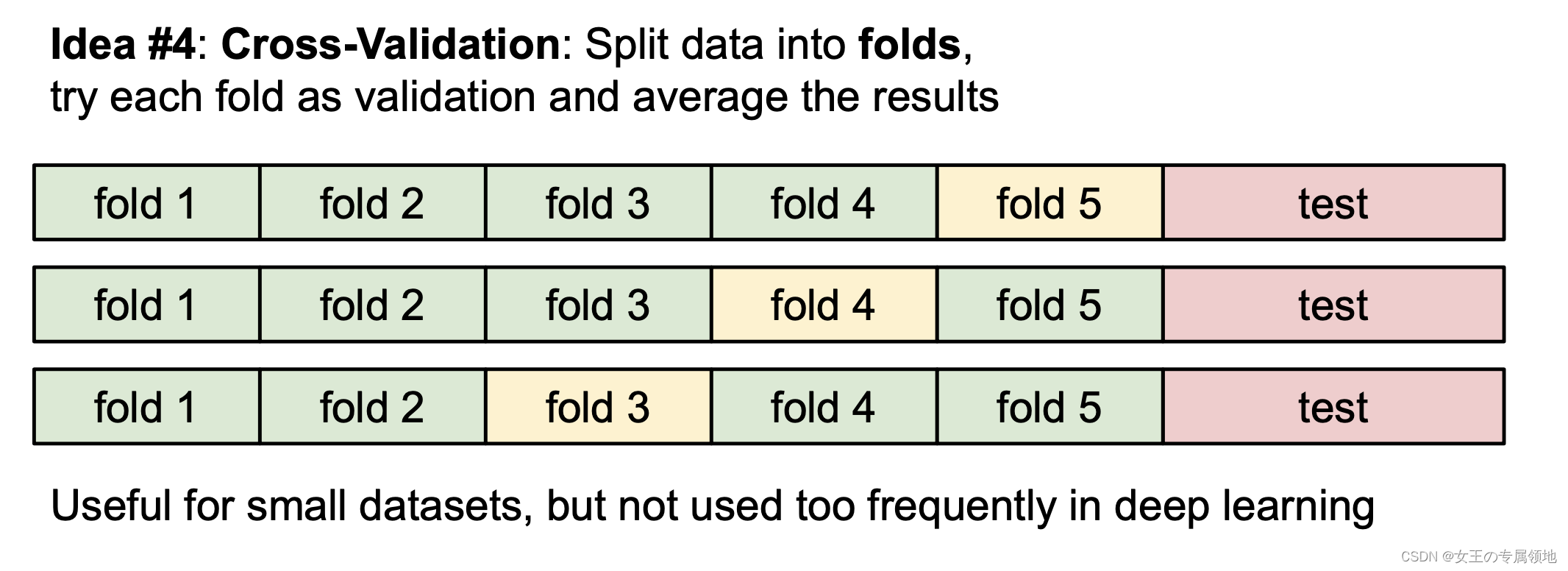
方法 2:交叉验证
训练集数量较小(因此验证集的数量更小)时,可以使用交叉验证的方法。还是用刚才的例子,如果是交叉验证集,我们就不是取 1000 个图像,而是将训练集平均分成 5 份,每份 10000 张图片,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。
2)KNN分类器优点
① 易于理解,实现简单。
② 算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。
3) KNN分类器缺点
① 测试要花费大量时间:因为每个测试图像需要和所有存储的训练图像进行比较在实际应用中,关注测试效率远远高于训练效率;
② 使用像素差异来比较图像是不够的,图片间 L2 距离小,更多的是被背景主导而不是图片语义内容本身主导,往往背景相似图片的 L2 距离就会小。也就是说,在高维度数据上,基于像素的相似和基于感官上的相似非常不同。感官上不同的两张图片,可能有相同的 L2 距离。
③ 维度灾难:KNN 有点像训练数据把样本空间分成几块,我们需要训练数据密集的分布在样本空间里,否则测试图片的最邻近点可能实际距离会非常远,导致和最接近的训练集样本实际上完全不同。但是如果使训练数据密集分布,需要的训练集数量指数倍增加,是数据维度的平方。
4) 应用KNN建议
对于实际应用 KNN 算法的建议
① 预处理数据:对数据中的特征进行归一化(normalize),让其具有零均值(zero mean)和单位方差(unit variance)。
② 降维:如果数据是高维数据,考虑使用降维方法,比如 PCA 或者随机投影。
③ 将数据随机分为训练集和验证集:
- 一般规律,70%-90%数据作为训练集。这个比例根据算法中有多少超参数,以及这些超参数对于算法的预期影响来决定。
- 如果需要预测的超参数很多,就应该使用更大的验证集来有效地估计它们;
- 如果担心验证集数量不够,尝试交叉验证方法;
- 如果计算资源足够,使用交叉验证更好(份数越多,效果越好,也更耗费计算资源)。
④ 在验证集上调优:尝试足够多的K值,尝试 L1 和 L2 两种范数计算方式。
⑤ 加速分类器:如果分类器跑得太慢,尝试使用ANN库(比如 FLANN 来加速这个过程,其代价是降低一些准确率。)
⑥ 对最优的超参数做记录:
- 记录最优参数后,不要使用最优参数的算法在完整的训练集上运行并再次训练,这样做会破坏对于最优参数的估计。
- 直接使用测试集来测试用最优参数设置好的最优模型,得到测试集数据的分类准确率,并以此作为你的 KNN 分类器在该数据上的性能表现。
3.线性分类:评分函数
3.1 线性分类概述
KNN 模型中训练过程中没有使用任何参数,只是单纯的把训练数据存储起来(参数 k 是在预测中使用的,找出k个接近的图片,然后找出标签最多的,并且k是超参数,是人为设定的)。
与之相对的是参数模型,参数模型往往会在训练完成后得到一组参数,之后就可以完全扔掉训练数据,预测的时候只需和这组参数做某种运算,即可根据运算结果做出判断。线性分类器是参数模型里最简单的一种,但却是神经网络里很重要的基础模块。
线性分类的方法由两部分组成:
① 评分函数(score function):原始图像数据到类别分值的映射。
② 损失函数(loss function):用来量化评分函数计算的分数与真实标签之间的一致性。该方法可转化为一个最优化问题,在最优化过程中,通过更新评分函数的参数来最小化损失函数值。
3.2 评分函数
评分函数将图像的像素值映射为各个分类类别的得分,得分高低代表图像属于该类别的可能性高低。
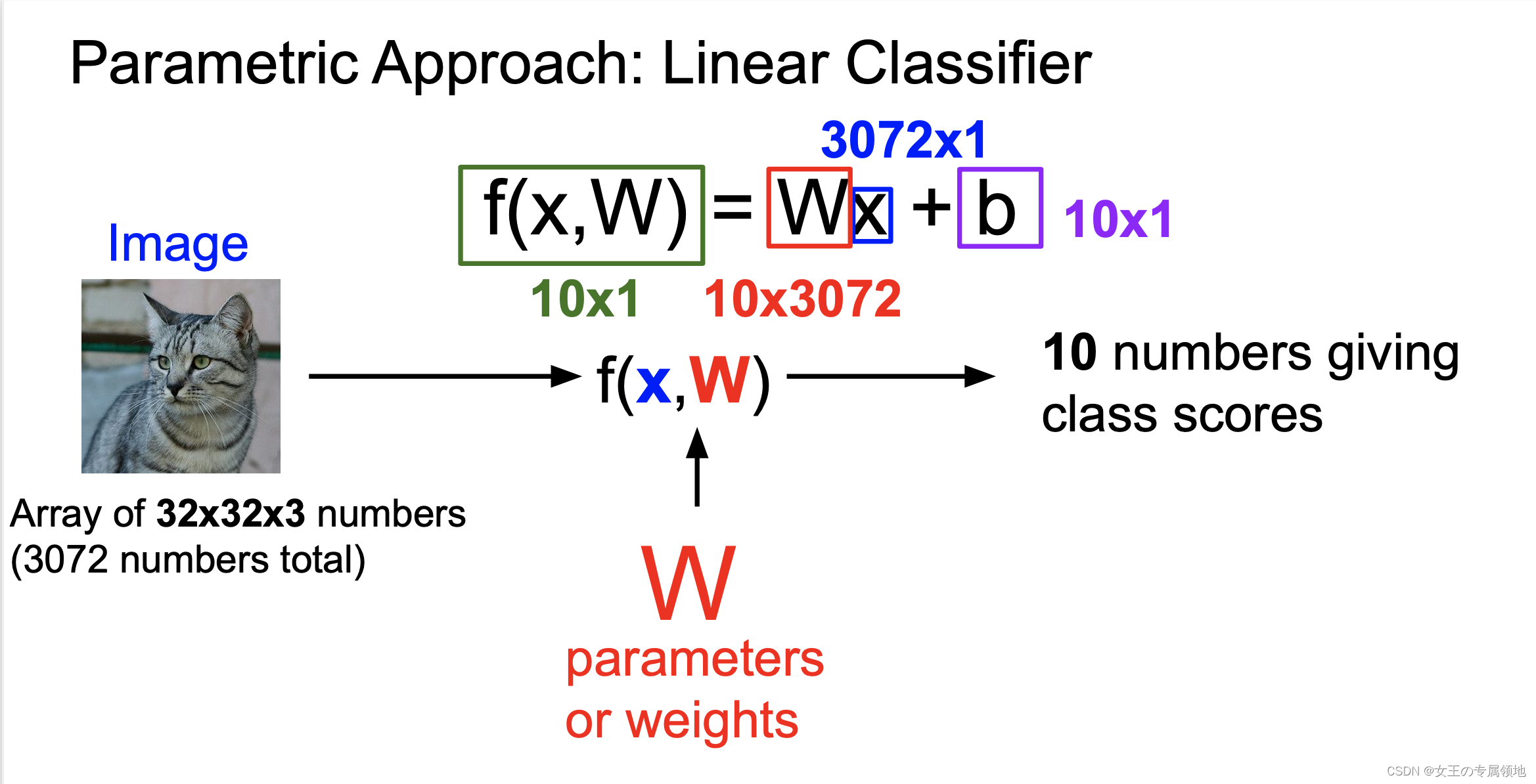
重新回到 KNN 使用的 CIFAR-10 图像分类数据集。

3.3 理解线性分类器
1) 理解一:W是所有分类器的组合
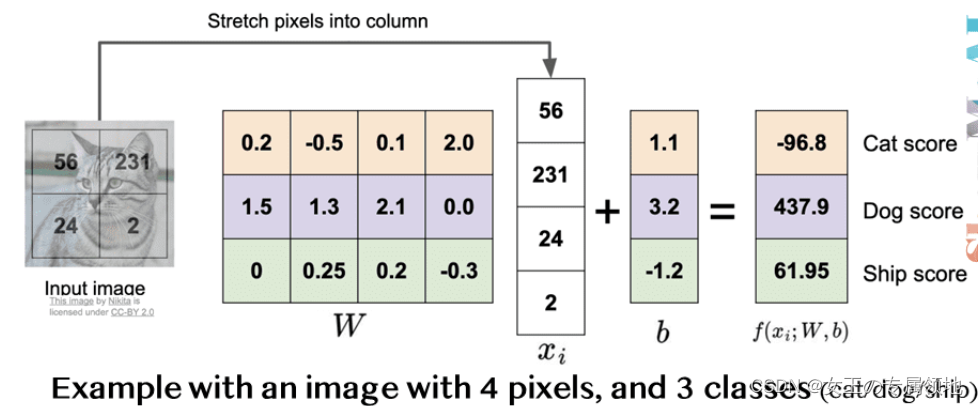
如图所示,将小猫的图像像素数据拉伸成一个列向量,这里为方便说明,假设图像只有4个像素(都是黑白像素,不考虑RGB通道),即D=4;有 3个分类(红色代表猫,绿色代表狗,蓝色代表船,颜色仅代表不同类别,和 RGB 通道没有关系),即 K=3。W矩阵乘列向量x得到各个分类的分值。
实际上,我们可以看到,参数矩阵W相当于是三个分类器的组合,W的每一行都是一个分类器,分别对应猫、狗、船。 在线性模型中每个分类器的参数个数与输入图像的维度相当,每个像素和对应的参数相乘,就表示该像素在该分类器中应占的比重。
我们可以这样理解,线性分类器会计算图像中 3 个颜色通道中所有像素的值与权重矩阵的乘积,进而得到每个类别分值。根据我们对权重设置的值,对于图像中的某些位置的某些颜色,函数表现出喜好或者厌恶(根据每个权重的符号而定)。
Eg:可以想象 「船」 分类就是被大量的蓝色所包围(对应的就是水)。那么 「船」 分类器在蓝色通道上的权重就有很多的正权重(它们的出现提高了 「船」 分类的分值),而在绿色和红色通道上的权重为负的就比较多(它们的出现降低了 「船」 分类的分值)。
结合上面的小猫示例,猫分类器对第二个位置的像素比较 「厌恶」 ,而恰好输入的小猫图像第二个位置像素值很大,最终计算得到一个很低的分数(当然,这个分类器是错误的)。
2) 理解二:将线性分类器看做模板匹配
把权重W的每一行看作一个分类的模板,一张图像对应不同分类的得分,是通过使用内积(也叫点积)来比较图像和模板,然后找到和哪个模板最相似。
这种理解角度下,线性分类器在利用学习到的模板,和输入图像做模板匹配。我们设置可以把其视作一种高效的KNN,不同的是不再使用所有的训练集的图像来比较,而是每个类别只用了一张图片来表征(这张图片是我们学习到的模板,而不存在训练集中),而且我们会更换度量标准,使用(负)内积来计算向量间的距离,而不是使用 L1 或者 L2 距离。

上图是以 CIFAR-10 为训练集,学习结束后的权重的例子。可以看到:
- 马的模板看起来似乎是两个头的马,这是因为训练集中的马的图像中马头朝向各有左右造成的。线性分类器将这两种情况融合到一起了;
- 汽车的模板看起来也是将几个不同的模型融合到了一个模板中,这个模板上的车是红色的,是因为 CIFAR-10 中训练集的车大多是红色的。- - 线性分类器对于不同颜色的车的分类能力是很弱的,但是后面可以看到神经网络是可以完成这一任务的;
- 船的模板如期望的那样有很多蓝色像素。如果图像是一艘船行驶在大海上,那么这个模板利用内积计算图像将给出很高的分数。
3) 理解三:将图像看做高维空间的点
既然定义每个分类类别的分值是权重和图像的矩阵乘积,那么每个分类类别的分数就是这个空间中的一个线性函数的函数值。我们没办法可视化3072维空间中的线性函数,但假设把这些维度挤压到二维,那么就可以看看这些分类器在做什么了:
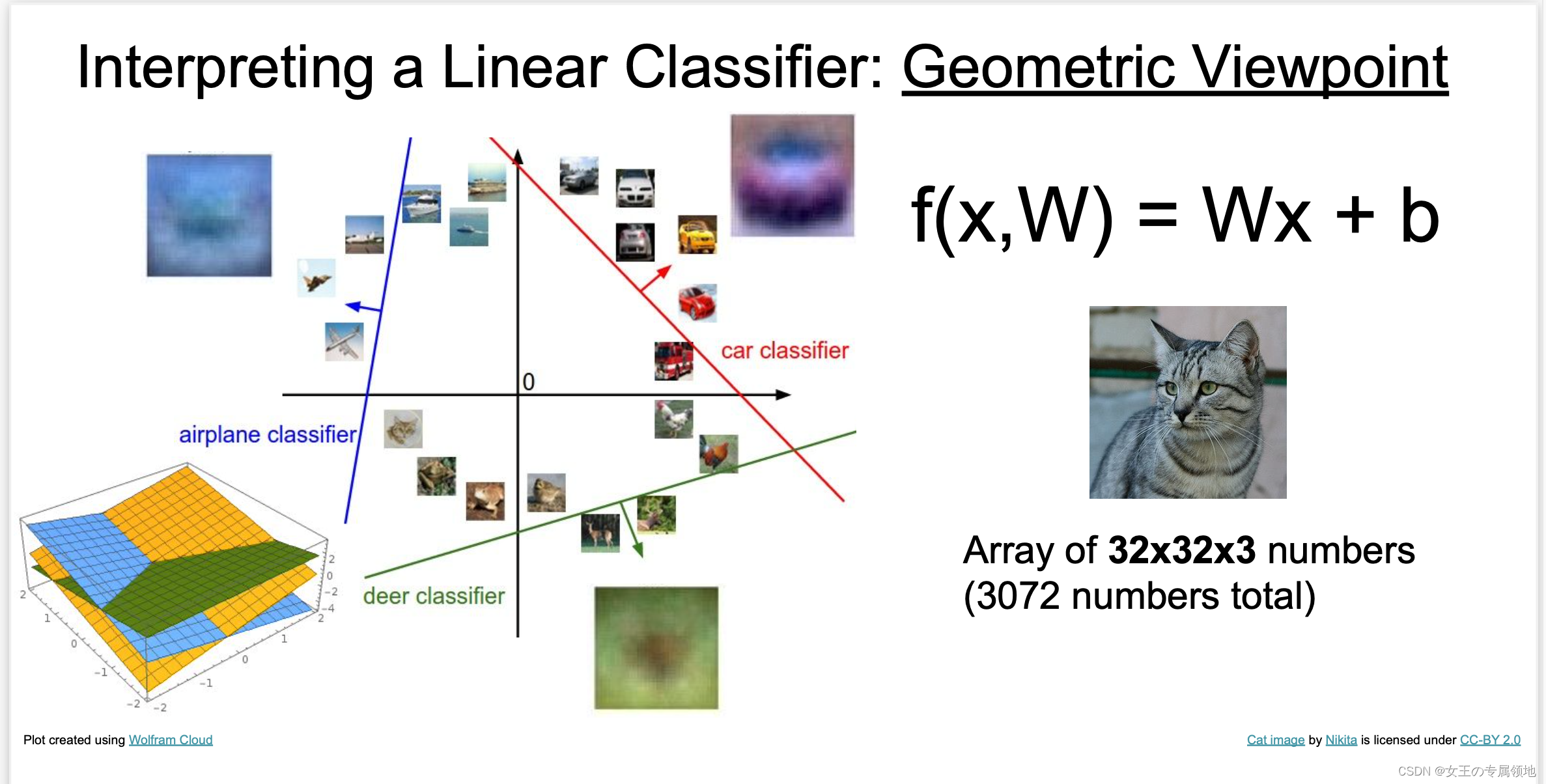
在上图中,每张输入图片是一个点,不同颜色的线代表 3 个不同的分类器。以红色的汽车分类器为例,红线表示空间中汽车分类分数为0的点的集合,红色的箭头表示分值上升的方向。所有红线右边的点的分数值均为正,且线性升高。红线左边的点分值为负,且线性降低。
从上面可以看到,W 的每一行都是一个分类类别的分类器,对于这些数字的几何解释是:
- 如果改变 W一行的数字取值,会看见分类器在空间中对应的直线开始向着不同方向旋转。而偏置项b,则允许分类器对应的直线平移。
- 需要注意的是,如果没有偏置项,无论权重如何,在 x i = 0 x_i = 0 xi=0时分类分值始终为0。这样所有分类器的线都不得不穿过原点。
3.4 偏置项和权重合并
上面的推导过程大家可以看到:实际我们有权重参数W和偏置项参数b 两个参数,分开处理比较冗余,常用的优化方法是把两个参数放到同一个矩阵中,同时列向量 x i x_i xi就要增加一个维度,这个维度的数值是常量1,这就是默认的偏置项维度。
如下图所示,新的公式就简化成如下形式:
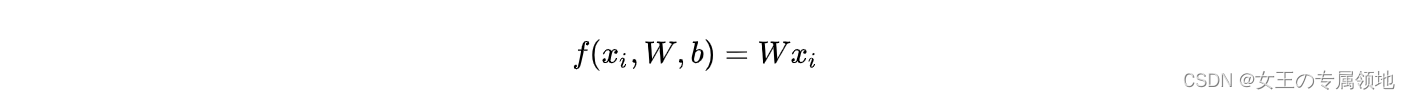
还是以 CIFAR-10 为例,那么
x
i
x_i
xi的大小就变成[3073x1]了,多出了包含常量1的1个维度; W大小就是[10 x 3073] 了,W中多出来的这一列对应的就是偏差值b:
经过这样的处理,最终只需学习一个权重矩阵,无需学习两个分别装着权重和偏差的矩阵。
3.5 图像数据预处理
在上面的例子中,所有图像都是使用的原始像素值(0~255)。在机器学习中,我们经常会对输入的特征做归一化(normalization)处理,对应到图像分类的例子中,图像上的每个像素可以看做一个特征。
在实践中,我们会有对每个特征减去平均值来中心化数据这样一个步骤。
在这些图片的例子中,该步骤是根据训练集中所有的图像计算出一个平均图像值,然后每个图像都减去这个平均值,这样图像的像素值就大约分布在 -127 ~ 127 之间了。
后续可以操作的步骤包括归一化,即让所有数值分布的区间变为 -1 ~ 1。
3.6 线性分类器失效的情形
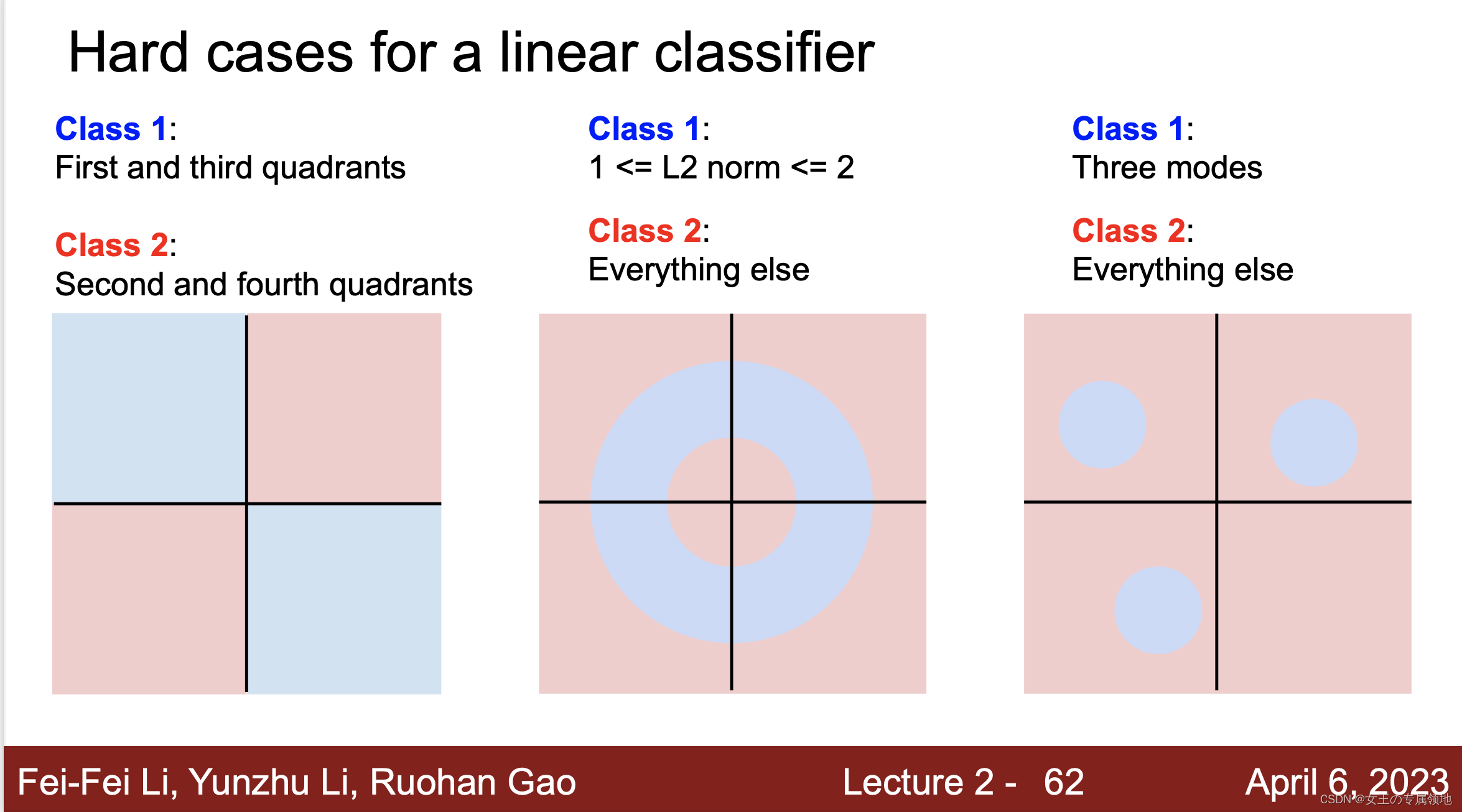
线性分类器的分类能力实际是有限的,例如上图中的这三种情形都无法找到合适的直线区分开。其中第 1 个 case 是奇偶分类,第 3 个 case 是有多个模型。
❓那么问题来了?1. 如何找到这个最合适的参数W?答案是定义损失函数并找到可以最小化该损失函数的参数(即优化)。
4. 线性分类:损失函数
4.1 损失函数的概念

4.2 多类支持向量机损失函数 (Multiclass Support Vector Machine Loss)




备注:这里的
Δ
Δ
Δ默认为1,关于这个参数会在下节专门提到!!!
4.3 Softmax损失函数(Multinomial Logistic Regression)
Softmax 分类器可以理解为逻辑回归分类器面对多个分类的一般化归纳,又称为多项式逻辑回归(Multinomial Logistic Regression)。

最大似然估计


KL散度

交叉熵

4.4 MSVM vs Softmax
Softmax 和 SVM 这两类损失的对比如下图所示: