论文信息
Subjects: Computation and Language (cs.CL)
(1)题目:Deep contextualized word representations (深度语境化的单词表示)
(2)文章下载地址:
https://doi.org/10.48550/arXiv.1802.05365
Cite as: arXiv:1802.05365 [cs.CL]
(or arXiv:1802.05365v2 [cs.CL] for this version)
(3)相关代码:
(4)作者信息:Matthew Peters
————————————————
目录
- Abstract
- Introduction
- Related work
- ELMo: Embeddings from Language Models
- Bidirectional language models 双向语言模型
- Evaluation
- Question answering
- Textual entailment 文本蕴涵
- Semantic role labeling 语义角色标注
- Coreference resolution 算法
- Named entity extraction 命名实体提取
- Sentiment analysis 情绪分析
- Analysis
- Alternate layer weighting schemes 交替层加权方案
- Where to include ELMo? 在哪里包含ELMo?
- What information is captured by the biLM’s representations? biLM的表示捕获了什么信息?
- Sample efficiency 样品的效率
- Visualization of learned weights 学习权重的可视化
- Conclusion
Abstract
We introduce a new type of deep contextualized word representation that models both (1) complex characteristics of word use (e.g., syntax and semantics), and (2) how these uses vary across linguistic contexts (i.e., to model polysemy). Our word vectors are learned functions of the internal states of a deep bidirectional language model (biLM), which is pretrained on a large text corpus. We show that these representations can be easily added to existing models and significantly improve the state of the art across six challenging NLP problems, including question answering, textual entailment and sentiment analysis. We also present an analysis showing that exposing the deep internals of the pre-trained network is crucial, allowing downstream models to mix different types of semi-supervision signals.
我们引入了一种新型的深度语境化单词表示,它既可以模拟(1)单词使用的复杂特征(例如,语法和语义),也可以模拟(2)这些使用在语言上下文中的变化(即建模多义性)。我们的词向量是深度双向语言模型(biLM)内部状态的学习函数,该模型在大型文本语料库上进行了预训练。我们表明,这些表示可以很容易地添加到现有的模型中,并在六个具有挑战性的NLP问题(包括问题回答、文本蕴含和情感分析)上显著提高了目前的水平。我们还提出了一项分析,表明暴露预训练网络的深层内部是至关重要的,允许下游模型混合不同类型的半监督信号。
Introduction
预训练词表示(Mikolov等人,2013;Pennington et al, 2014)是许多神经语言理解模型的关键组成部分。然而,学习高质量的表示可能具有挑战性。理想情况下,它们应该同时模拟(1)单词使用的复杂特征(例如,语法和语义),以及(2)这些用法在不同的语言语境中是如何变化的(即,模拟多义性)。在本文中,我们介绍了一种新型的深度上下文化单词表示,它直接解决了这两个挑战,可以很容易地集成到现有模型中,并在一系列具有挑战性的语言理解问题的每个考虑案例中显著提高了当前的技术水平。
我们的表示与传统的词类型嵌入不同,因为每个标记都被分配了一个表示,该表示是整个输入句子的函数。我们使用来自双向LSTM的向量,该向量是用耦合语言模型(LM)目标在大型文本语料库上训练的。因此,我们称它们为ELMo(来自语言模型的嵌入)表示。
与之前学习上下文化词向量的方法不同(Peters等人,2017;McCann等人,2017),ELMo表示是深刻的,从某种意义上说,它们是biLM所有内层的函数。更具体地说,我们学习了为每个最终任务堆叠在每个输入单词之上的向量的线性组合, 这比仅使用顶部LSTM层显著提高了性能。
以这种方式组合内部状态可以实现非常丰富的单词表示。使用内在评估,我们展示了更高级别的LSTM状态 捕获单词意义的上下文依赖方面(例如,它们可以在没有修改的情况下用于监督单词意义消除歧义任务 ),而较低级别的状态建模语法方面(例如,它们可以用于词性标记)。同时暴露所有这些信号是非常有益的,允许学习的模型选择对每个终端任务最有用的半监督类型。
大量的实验证明,ELMo表示法在实践中工作得非常好。
我们首先表明,它们可以很容易地添加到现有的模型中,用于解决六个不同且具有挑战性的语言理解问题,包括文本蕴含、问题回答和情绪分析。单独添加ELMo表示就可以显著提高每种情况下的技术水平,包括最多减少20%的相对误差。对于可能进行直接比较的任务,ELMo优于CoVe (McCann等人,2017),后者使用神经机器翻译编码器计算上下文化表示。最后,对ELMo和CoV e的分析表明,深度表示的表现更好,这些都来自于LSTM的顶层。
我们训练过的模型和代码是公开可用的,我们希望ELMo将为许多其他NLP问题提供类似的收益。
Related work
由于它们能够从大规模未标记文本中捕获单词的语法和语义信息,预训练词向量(Turian等人,2010;Mikolov等人,2013;Pennington等人,2014)是大多数最先进的NLP架构的标准组件,包括问题回答(Liu等人,2017),文本蕴涵(Chen等人,2017)和语义角色标记(He等人,2017)。然而,这些学习词向量的方法只允许每个词有一个独立于上下文的表示。
先前提出的方法通过用子词信息丰富传统词向量来克服传统词向量的一些缺点(例如,Wieting等人,2016;Bojanowski等人,2017),或者为每个词的意义学习单独的向量(例如,Neelakantan等人,2014)。通过使用字符卷积,我们的方法还受益于子词单元,并且我们无缝地将多感信息集成到下游任务中,而无需显式训练来预测预定义的感类。
最近的其他工作也集中在学习上下文相关的表示。
context2vec (Melamud等人,2016)使用双向长短期记忆(LSTM;Hochreiter和Schmidhuber, 1997)对围绕枢轴词的上下文进行编码。学习上下文嵌入的其他方法包括表示中的中心词本身,并使用监督神经机器翻译(MT)系统(CoV e;McCann等人,2017)或无监督语言模型(Peters等人,2017)。这两种方法都受益于大型数据集,尽管MT方法受到并行语料库大小的限制。在本文中,我们充分利用了对丰富的单语数据的访问,并在大约3000万句的语料库上训练我们的biLM (Chelba et al, 2014)。我们还将这些方法推广到深度上下文表示,我们表明这些方法在广泛的不同NLP任务中都能很好地工作。
之前的研究也表明,不同层的深度birnn编码不同类型的信息。例如,在深度LSTM的较低级别引入多任务语法监督(例如,词性标签)可以提高较高级别任务的整体性能,如依赖项解析(Hashimoto et al, 2017)或CCG超级标签(Søgaard and Goldberg, 2016)。
在一个基于rnn的编码器-解码器机器翻译系统中,Belinkov等人(2017)表明,在2层LSTM编码器的第一层学习的表示在预测POS标签方面比第二层更好。最后,用于编码单词上下文的LSTM的顶层(Melamud等人,2016年)已被证明可以学习词义的表示。我们表明,我们的ELMo表示的修改语言模型目标也诱导了类似的信号,并且对于混合了这些不同类型的半监督的下游任务学习模型非常有益。
Dai和Le(2015)和Ramachandran等
(2017)使用语言模型和序列自编码器预训练编码器-解码器对,然后使用特定于任务的监督进行微调。相比之下,在用未标记的数据预训练biLM之后,我们固定权重并添加额外的特定于任务的模型容量,允许我们利用大型、丰富和通用的biLM表示,用于下游训练数据大小决定较小的监督模型的情况。
ELMo: Embeddings from Language Models
与大多数广泛使用的词嵌入(Pennington et al, 2014)不同,ELMo词表示是整个输入句子的函数,如本节所述。它们是在带有字符卷积(第3.1节)的两层bilm之上计算的,作为内部网络状态的线性函数(第3.2节)。这种设置允许我们进行半监督学习,其中biLM被大规模预训练(第3.4节),并且很容易集成到广泛的现有神经NLP架构中(第3.3节)。
Bidirectional language models 双向语言模型
Evaluation
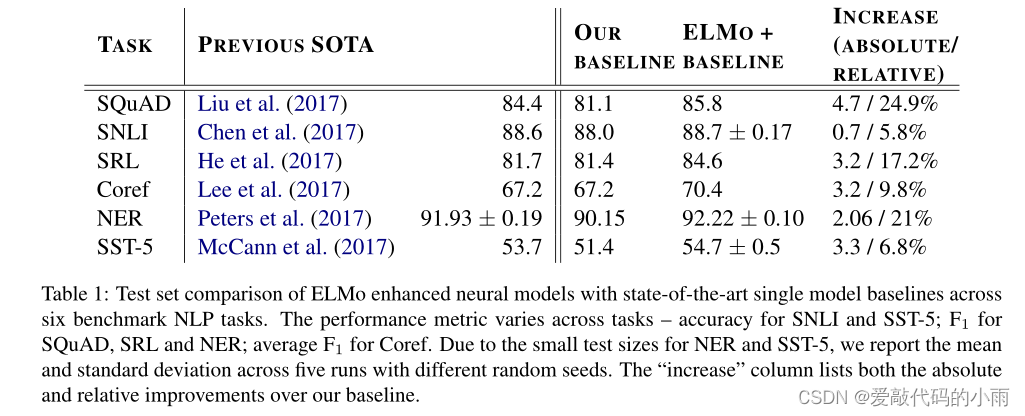
表1显示了ELMo在一组不同的六个基准NLP任务中的性能。在考虑的每个任务中,只需添加ELMo就可以建立一个新的最先进的结果,相对于强基础模型,误差减少了6 - 20%。对于不同的模型架构和语言理解任务,这是一个非常普遍的结果。在本节的剩余部分,我们将提供单个任务结果的高级草图;有关完整的实验细节,请参阅补充材料。
Question answering
斯坦福问答数据集(SQuAD) (Rajpurkar et al, 2016)包含100,000多个人群来源的问答对,其中答案是给定维基百科段落中的跨度。我们的基线模型(Clark and Gardner, 2017)是Seo等人的双向注意力流模型的改进版本
(BiDAF;2017)。它在双向注意组件之后增加了一个自注意层,简化了一些池化操作,并将lstm替换为门控循环单元(gru;Cho等人,2014)。在基线模型中加入ELMo后,测试集F1从81.1%提高到85.8%,提高了4.7%,相对基线误差降低了24.9%,整体单模型的先进度提高了1.4%。11名成员的组合将F1推到了87.4,这是提交到排行榜时的整体最先进水平。2加上ELMo后4.7%的增幅也明显大于将CoVe加入基线模型后1.8%的增幅(McCann et al, 2017)。
Textual entailment 文本蕴涵
文本蕴涵是在给定一个“前提”的情况下,确定一个“假设”是否正确的任务。斯坦福自然语言推断(SNLI)语料库(Bowman et al, 2015)提供了大约550K个假设/前提对。我们的基线,Chen等人(2017)的ESIM序列模型,使用一个biLSTM来编码前提和假设,然后是一个矩阵注意层,一个局部推理层,另一个biLSTM推理组合层,最后在输出层之前进行池化操作。总体而言,将ELMo添加到ESIM模型中,在五个随机种子上平均提高了0.7%的准确性。五名成员的集合将整体精度提高到89.3%,超过了之前的集合最佳88.9% (Gong et al, 2018)。
Semantic role labeling 语义角色标注
语义角色标记(SRL)系统对句子的谓词-参数结构进行建模,通常被描述为回答“谁对谁做了什么”。他等人
(2017)继Zhou和Xu(2015)之后,将SRL建模为BIO标记问题,并使用向前和向后方向交错的8层深biLSTM。如表1所示,当将ELMo添加到He等人的重新实现时
(2017)单模型测试集F1从81.4%跃升至84.6%,这是OntoNotes基准的最新水平(Pradhan等人,2013年),甚至比之前的最佳集合结果提高了1.2%。
Coreference resolution 算法
共指解析是对文本中提及的同一底层现实实体进行聚类的任务。我们的基线模型是Lee等人(2017)的端到端基于跨度的神经模型。它首先利用biLSTM和注意力机制计算跨度表示,然后应用softmax提及排序模型寻找共参考链。在我们使用来自CoNLL 2012共享任务的OntoNotes共参考注释的实验中(Pradhan et al, 2012),添加ELMo将平均F1从67.2提高了3.2%到70.4,建立了一个新的艺术状态,再次比之前的最佳集成结果提高了1.6% F1。
Named entity extraction 命名实体提取
CoNLL 2003 NER任务(Sang和Meulder, 2003)由来自路透社RCV1语料库的新闻专线组成,标记有四种不同的实体类型(PER, LOC, ORG, MISC)。遵循最近最先进的系统(Lample等人,2016;Peters等人,2017),基线模型使用预训练的词嵌入、基于字符的CNN表示、两个biLSTM层和一个条件随机场(CRF)损失(Lafferty等人,2001),类似于Collobert等人
(2011)。如表1所示,我们的ELMo增强biLSTM-CRF在5次运行中平均F1达到92.22%。我们的系统与彼得斯等人之前的艺术状态之间的关键区别
(2017)是我们允许任务模型学习所有biLM层的加权平均值,而Peters等人(2017)只使用顶部biLM层。如第5.1节所示,使用所有层而不是最后一层可以提高多个任务的性能。
Sentiment analysis 情绪分析
斯坦福情感树库(SST-5;Socher et al, 2013)涉及从五个标签(从非常消极到非常积极)中选择一个来描述电影评论中的一句话。句子中包含多种多样的语言现象,如成语和复杂的句法Tic结构,例如否定,模型很难学习。我们的基线模型是McCann等人(2017)的双关注分类网络(BCN),当使用CoV e嵌入增强时,它也保持了先前最先进的结果。将BCN模型中的CoV e替换为ELMo,其绝对精度比目前的技术水平提高了1.0%。
Analysis
本节提供烧蚀分析,以验证我们的主要主张,并阐明ELMo表示的一些有趣方面。第5.1节表明,在下游任务中使用深度上下文表示法比以前只使用顶层的工作提高了性能,无论它们是由biLM还是MT编码器产生的,并且ELMo表示法提供了最佳的整体性能。第5.3节探讨了在bilm中捕获的不同类型的上下文信息,并使用两种内在的评估来表明,语法信息在较低的层中更好地表示,而语义信息在较高的层中捕获,与MT编码器一致。它还表明,我们的biLM始终提供比CoV更丰富的表示。
此外,我们分析了对任务模型中包含ELMo的位置(第5.2节)、训练集大小(第5.4节)的敏感性,并在任务中可视化ELMo学习的权重(第5.5节)。
Alternate layer weighting schemes 交替层加权方案
对于组合biLM层,有许多替代公式1的方法。之前关于上下文表示的工作只使用了最后一层,无论是来自biLM (Peters等人,2017)还是MT编码器(CoV e;McCann等人,2017)。正则化参数λ的选择也很重要,因为较大的值(如λ = 1)有效地将加权函数降低为层上的简单平均,而较小的值(如λ = 0.001)允许层权重变化。

表2比较了SQuAD、SNLI和SRL的这些备选方案。与只使用最后一层相比,包含来自所有层的表示可以提高整体性能,并且包含来自最后一层的上下文表示可以提高基准性能。例如,在SQuAD的情况下,仅使用最后一个biLM层就可以使开发F1比基线提高3.9%。
平均所有biLM层,而不是只使用最后一层,使F1再提高0.3%(将“last Only”列与λ=1列进行比较),并允许任务模型学习单个层的权重,使F1再提高0.2% (λ=1 vs. λ=0.001)。在大多数情况下,ELMo首选小λ,尽管对于具有较小训练集的NER任务,结果对λ不敏感(未显示)。
总体趋势与冠状病毒相似,但与基线相比增长较小。对于SNLI,与仅使用最后一层相比,平均λ=1的所有层可以将显像精度从88.2提高到88.7%。与仅使用最后一层相比,SRL F1在λ=1的情况下边际增加0.1%至82.2。
Where to include ELMo? 在哪里包含ELMo?
本文中的所有任务体系结构都只将词嵌入作为最低层biRNN的输入。然而,我们发现在特定于任务的架构中,在biRNN的输出中包含ELMo可以改善某些任务的整体结果。
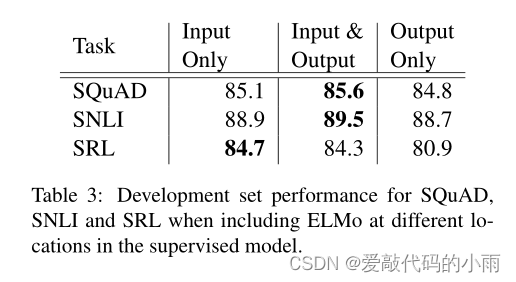
如表3所示,在SNLI和SQuAD的输入和输出层同时包含ELMo比仅在输入层提高,但对于SRL(和协参分辨率,未显示),当它仅包含在输入层时性能最高。
对这个结果的一个可能的解释是SNLI和SQuAD架构都在biRNN之后使用注意层,因此在这一层引入ELMo允许模型直接关注biLM的内部表示。在SRL案例中,特定于任务的上下文表示可能比来自biLM的上下文表示更重要。
What information is captured by the biLM’s representations? biLM的表示捕获了什么信息?
由于添加ELMo比单独的词向量提高了任务性能,因此biLM的上下文表示必须编码通常对NLP任务有用的信息,而这些信息不是在词向量中捕获的。直观地说,biLM必须使用上下文消除单词含义的歧义。以“play”为例,这是一个高度多义词。

表4的顶部列出了使用GloV e向量“玩”的最近邻居。
它们分布在几个词性中(例如,“玩的”,“玩的”作为动词,“球员”,“游戏”作为名词),但集中在“玩”的体育相关意义上。相比之下,下面两行显示了来自SemCor数据集的最近邻居句子(见下文),使用了biLM在源句中“play”的上下文表示。在这些情况下,biLM能够消除源句中的词性和词义的歧义。
这些观察结果可以用与Belinkov等人(2017)相似的上下文表征的内在评价。为了分离由biLM编码的信息,使用该表示直接对细粒度词义消歧(WSD)任务和POS标记任务进行预测。使用这种方法,还可以与CoVe进行比较,并跨每个单独的层进行比较。
Word sense disambiguation (词义消歧) 给定一个句子,我们可以使用biLM表示来预测目标词的意义,使用简单的1最近邻方法,类似于Melamud等人(2016)。为此,我们首先使用biLM来计算SemCor 3.0(我们的训练语料库,Miller et al, 1994)中所有单词的表示,然后对每个意义取平均表示。在测试时,我们再次使用biLM来计算给定目标单词的表示,并从训练集中提取最近邻感,对于训练期间未观察到的引理,返回到WordNet中的第一感。
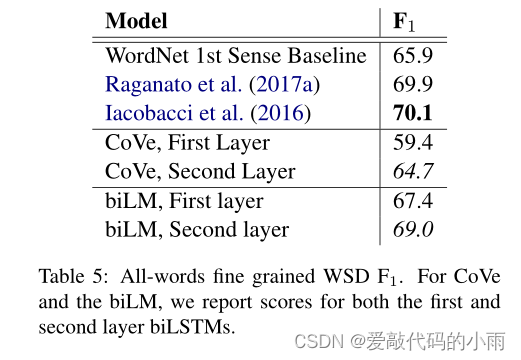
表5比较了使用Raganato等人(2017b)的评估框架在Raganato等人(2017a)的同一套四个测试集之间的水务结果。总的来说,biLM顶层代表resays的F1为69,在WSD比第一层更好。这与使用手工制作特征的最先进的特定于wsd的监督模型(Iacobacci等人,2016年)和特定于任务的biLSTM(也使用辅助粗粒度语义标签和POS标签进行训练)(Raganato等人,2017a)竞争。CoV e biLSTM层遵循与biLM相似的模式(与第一层相比,第二层的总体性能更高);然而,我们的biLM优于CoVe biLSTM,后者落后于WordNet第一感觉基线。
POS tagging (POS标签) 为了检查biLM是否捕获了基本语法,我们使用上下文表示作为线性分类器的输入,该分类器使用Penn树库(PTB)的华尔街日报部分预测POS标记(Marcus et al, 1993)。
由于线性分类器只增加了少量的模型容量,这是对biLM表示的直接测试。与WSD类似,biLM表示与经过精心调整的、特定于任务的bilstm具有竞争力(Ling等人,2015;Ma和Hovy, 2016)。然而,与WSD不同的是,使用第一层biLM的准确性高于顶层,这与多任务训练中深度biLSTMs的结果一致(s æ gaard和Goldberg, 2016;Hashimoto等人,2017)和MT (Belinkov等人,2017)。CoV POS标记的准确度与来自biLM的相同模式,与水务署一样,biLM的准确度比CoV编码器更高。
Implications for supervised tasks (对监督任务的影响) 综上所述,这些实验证实了biLM中的不同层代表不同类型的信息,并解释了为什么包括所有biLM层对于下游任务的最高性能很重要。此外,biLM的表示法比CoVe中的表示法更易于转换为WSD和POS标记,有助于说明为什么ELMo在下游任务中表现优于CoVe。
Sample efficiency 样品的效率
将ELMo添加到模型中可以显著提高样本效率,无论是在参数更新数量以达到最先进的性能方面,还是在整体训练集大小方面。例如,SRL模型在没有ELMo的情况下经过486 epoch的训练后达到最大发展F1。在添加ELMo之后,模型在第10个纪元超过了基线最大值,需要达到的更新数量相对减少了98%同样的表现水平。
此外,ELMo增强模型使用更小的训练集,比没有ELMo的模型更有效。
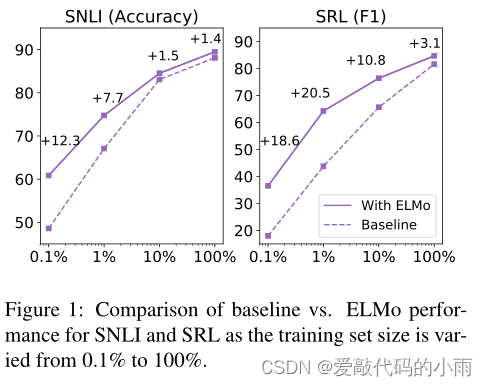
图1比较了有和没有ELMo的基线模型的性能,因为完整训练集的百分比从0.1%到100%不等。对于较小的训练集,ELMo的改进最大,并显著减少了达到给定性能水平所需的训练数据量。在SRL情况下,具有1%训练集的ELMo模型与具有10%训练集的基线模型具有大致相同的F1。
Visualization of learned weights 学习权重的可视化
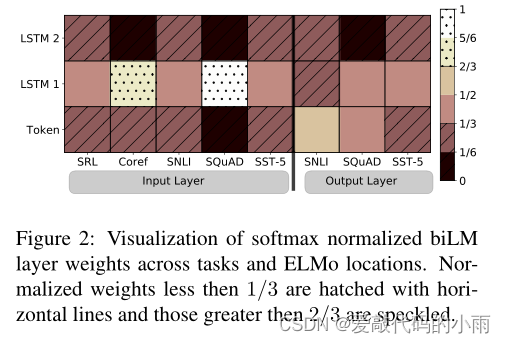
图2显示了softmax规范化的学习层权重。在输入层,任务模型倾向于第一个biLSTM层。对于coreference和SQuAD,这是非常受欢迎的,但其他任务的分布峰值较小。输出层权重相对平衡,对较低的层略有偏好。
Conclusion
我们已经介绍了一种从bilm中学习高质量的深度上下文依赖表示的通用方法,并在将ELMo应用于广泛的NLP任务时显示出了很大的改进。通过烧蚀和其他对照实验,我们也证实了biLM层有效地编码了上下文中关于单词的不同类型的语法和语义信息,并且使用所有层可以提高整体任务性能。