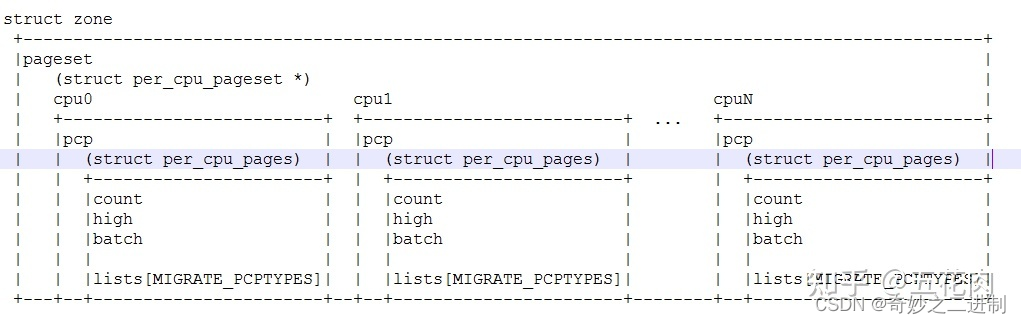
数据库设计范式:
第一范式:
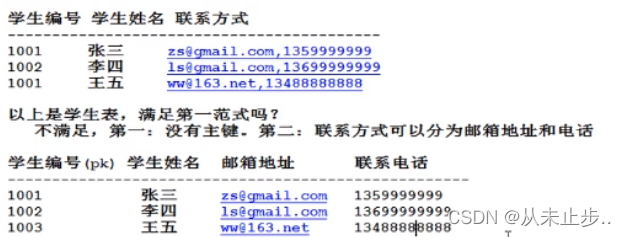
要求任何一张表必须有主键,每一个字段原子性不可再分,第一范式是最核心,最重要的范式,所有的表的设计都需要满足
举例:
第二范式:
建立在第一范式的基础上,要求所有非主键字段完全依赖主键
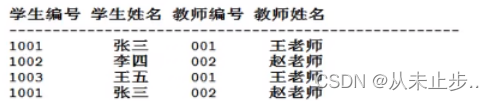
以上的表并不满足第一范式。
修改之后:

学生编号和教师编号两个字段联合做主键,复合主键(PK:学生编号+教师编号),经过修改之后,以上的表满足了第一范式,但是并不满足第二范式,因为"张三依赖1001”,“王老师依赖001”,显然产生了部分依赖,那么产生部分依赖有什么缺点呢?
数据冗余,空间浪费了,“张三”重复了,"王老师"重复了。
为了让上面这张表满足第二范式,我们对其进行修改
使用三张表来表示多对多的关系:

多对多设计技巧:多对多,三张表,关系表两个外键
第三范式:
建立在第二范式的基础上,要求所有非主键字段直接依赖主键,不要产生传递依赖

以上表的设计是描述,班级和学生的关系,很显然是一对多的关系,一个教室中有多个学生。
以上表满足第一范式,因为它包含主键,且也满足第二范式,因为主键不是复合主键,没有产生部分依赖,主键是单一主键,但是并不满足第三范式,因为一年一班依赖01,01依赖1001,产生了传递依赖,不符合第三范式的要求,产生了数据的冗余。
修改如下:

一对多,两张表,多的表加外键
设计数据库表的时候,按照以上的范式进行,可以避免表中数据的冗余,空间的浪费。
数据库设计总结:
一对多,两张表,多的表加外键
多对多,三张表,关系表两个外键
一对一:在实际的开发中,可能存在一张表字段太多,太庞大,这个时候需要拆分
举例:
未拆分的一张表:

拆分成两张之后:

一对一,外键唯一
数据库设计三范式是理论上的,实践和理论有的时候有偏差,最终的目的都是为了满足客户的需求,有的时候会拿冗余换执行速度,因为在sql当中,表和表之间连接次数越多,效率越低(笛卡尔积),有的时候可能会存在冗余,但是为了减少表的连接次数,这样做也是合理的,并且对于开发人员来说,sql语句的编写难度也会降低