图像预训练
预训练首先是在图像领域广泛应用的。设计网络结构后,处理图像一般是CNN的多层叠加网络结构,先用训练集对网络预先训练,处理新任务时采取相同的网络结构,在比较浅的几层CNN结构,网络参数初始化的时候可以加载训练好的参数,其它CNN高层参数仍然随机初始化。使用新数据训练网络,此时有两种做法,一种是浅层加载的参数在训练C任务过程中不动,这种方法被称为“Frozen”;另外一种是底层网络参数尽管被初始化了,但在训练过程中仍然随着训练的进程不断改变,这种叫“Fine-Tuning”,一般图像或者视频领域要做预训练都这么做。新任务训练集数据量较少的时候,用新任务的数据做Fine-tuning,调整参数以解决新任务。这样原先训练不了的任务就能解决了,即使训练数据足够,增加预训练过程也能极大加快任务训练的收敛速度。
对于层级的CNN结构来说,不同层级的神经元学习到了不同类型的图像特征,由底向上特征形成层级结构,训练好网络后,把每层神经元学习到的特征可视化,最底层的神经元学到的是线段等特征,越是底层的特征越是基础特征,越往上抽取出的特征越与任务相关。因此预训练好的网络参数,尤其是底层的网络参数抽取出特征跟具体任务越无关,越具备任务的通用性,所以这是为何一般用底层预训练好的参数初始化新任务网络参数的原因。而高层特征跟任务关联较大,实际可以不用使用,或者采用Fine-tuning用新数据集合清洗掉高层无关的特征抽取器。
Word_Embedding

语言模型:为了能够量化地衡量哪个句子更符合人话,核心函数P的思想是根据句子里面前面的一系列前导单词预测后面跟哪个单词的概率大小(理论上除了上文之外,也可以引入单词的下文联合起来预测单词出现概率)。句子里面每个单词都有个根据上文预测自己的过程,把所有这些单词的产生概率乘起来,数值越大代表这越像一句人话。
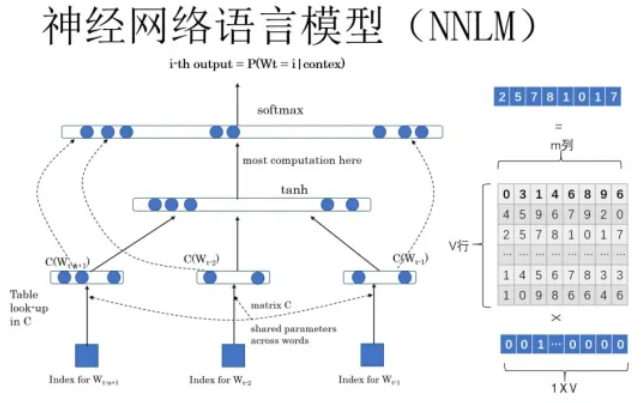
上图为神经网络语言模型(NNLM),输入目标词的前N个词,预测目标词,使用one-hot表征前N个词,输入神经网络,one-hot与矩阵Q相乘,获得向量CWi,CWi通过softmax预测目标词,其中CWi即为word-embedding。
Word2Vec(包括Glove)和NNLM类似,尽管网络结构相近,但是其训练方法不一样。Word2Vec有两种训练方法,一种叫CBOW,核心思想是从一个句子里面把一个词抠掉,用这个词的上文和下文去预测被抠掉的这个词;第二种叫做Skip-gram,和CBOW正好反过来,输入某个单词,要求网络预测它的上下文单词。NNLM是输入一个单词的上文,预测该单词。NNLM的主要任务是要学习一个解决语言模型任务的网络结构,语言模型就是要看到上文预测下文,而word embedding是副产品。而Word2Vec就是要word embedding的,这是主产品。
Word Embedding等价于把Onehot层到embedding层的网络用预训练好的参数矩阵Q初始化。与之前图像领域的低层预训练过程其实是一样的,只是Word Embedding只能初始化第一层网络参数。下游NLP任务在使用Word Embedding的时候类似图像有两种做法,一种是Frozen,就是Word Embedding那层网络参数固定不动;另外一种是Fine-Tuning,就是Word Embedding这层参数使用新的训练集合训练也需要跟着训练过程更新掉。
ELMO
Word Embedding存在处理多义词的问题;Word Embedding本质上是个静态的方式,即训练好之后每个单词的表达就固定住了,不论新句子上下文是什么,该词的Word Embedding不变。
Embedding from Language Models,来自论文Deep contextualized word representation,ELMO的本质思想是:先用语言模型学好一个单词的Word Embedding,此时多义词无法区分。实际使用Word Embedding时,单词已经具备了特定的上下文,此时可根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,解决了多义词的问题。ELMO本身是个根据当前上下文对Word Embedding动态调整的思路。
ELMO采用两阶段过程,第一个阶段是利用语言模型进行预训练;第二个阶段是在做下游任务时,从预训练网络中提取对应单词的网络各层的Word Embedding作为新特征补充到下游任务中。

ELMO预训练过程
采用了双层双向LSTM,目前语言模型训练的任务目标是根据单词 Wi 的上下文去正确预测单词 Wi , Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。图中左端的前向双层LSTM代表正方向编码器,输入的是从左到右顺序的除了预测单词外 Wi 的上文Context-before;右端的逆向双层LSTM代表反方向编码器,输入的是从右到左的逆序的句子下文Context-after;每个编码器的深度都是两层LSTM叠加。使用这个网络结构利用大量语料做语言模型任务就能预先训练好这个网络,如果训练好这个网络后,输入一个新句子 Snew ,句子中每个单词都能得到对应的三个词向量:最底层是单词的Word Embedding,往上走是第一层双向LSTM中对应单词位置的Embedding,这层编码单词的句法信息更多一些;再往上走是第二层LSTM中对应单词位置的Embedding,这层编码单词的语义信息更多一些。ELMO的预训练过程不仅学会单词的Word Embedding,还学会了一个双层双向的LSTM网络结构,而这两者后面都有用。
下游任务的使用过程,比如QA问题,对于问句X,先将句子X作为预训练好的ELMO网络的输入,这样句子X中每个单词在ELMO网络中都能获得对应的三个Embedding,给这三个Embedding中的每一个Embedding一个权重a,这个权重可以学习得来,根据各自权重累加求和,将三个Embedding整合成一个,将整合后的Embedding作为X句在自己任务的那个网络结构中对应单词的输入,以此作为补充的新特征给下游任务使用。
GPT
ELMO的缺点在特征抽取器选择方面,使用了LSTM而不是Transformer,Transformer提取特征的能力是要远强于LSTM的;ELMO采取双向拼接这种融合特征的能力可能比Bert一体化的融合特征方式弱。
GPT(Generative Pre-Training),生成式的预训练。GPTyou 两阶段过程,第一个阶段是利用语言模型进行预训练,第二阶段通过Fine-tuning的模式解决下游任务。预训练过程与ELMO类似,
主要不同在于两点:首先,特征抽取器不是用的RNN,而是用的Transformer;其次,GPT采用的是单向的语言模型,即语言模型训练的任务目标是根据 Wi 单词的上下文去正确预测单词 Wi , Wi 之前的单词序列Context-before称为上文,之后的单词序列Context-after称为下文。ELMO在做语言模型预训练的时候,预测单词 Wi 同时使用了上文和下文,而GPT则只采用Context-before这个单词的上文来进行预测,而抛开了下文。
BERT
Bert采用和GPT完全相同的两阶段模型,首先是语言模型预训练;其次是使用Fine-Tuning模式解决下游任务。和GPT的最主要不同在于在预训练阶段采用了类似ELMO的双向语言模型,语言模型的数据规模要比GPT大。
NLP的四大任务:序列标注、分类任务、句子关系判断、生成式任务。
BERT处理不同下有任务;
对于句子关系类任务,和GPT类似,加上一个起始和终结符号,句子之间加个分隔符即可。对于输出来说,把第一个起始符号对应的Transformer最后一层位置上面串接一个softmax分类层。
对于分类问题,与GPT一样,只需要增加起始和终结符号,输出部分和句子关系判断任务类似改造;
对于序列标注问题,输入部分和单句分类是一样的,只需要输出部分Transformer最后一层每个单词对应位置都进行分类即可。
除了生成类任务外,Bert其它都覆盖到了,而且改造起来很简单直观。对于机器翻译或者文本摘要,聊天机器人这种生成式任务,同样可以稍作改造即可引入Bert的预训练成果。只需要附着在S2S结构上,encoder部分是个深度Transformer结构,decoder部分也是个深度Transformer结构。根据任务选择不同的预训练数据初始化encoder和decoder即可。
Bert本身的效果好和普适性强是最大的亮点。
Masked 语言模型和Next Sentence Prediction。
Masked语言模型本质思想是CBOW,但细节方面有改进。随机选择语料中15%的单词,用[Mask]掩码代替原始单词,用模型去正确预测被抠掉的单词。训练过程大量看到[mask]标记,但用的时候是不会有这个标记的,这会引导模型认为输出是针对[mask]这个标记的,但是实际使用又见不到这个标记,这自然会有问题。为了避免这个问题,Bert改造了一下,15%的被上天选中要执行[mask]替身这项光荣任务的单词中,只有80%真正被替换成[mask]标记,10%被随机替换成另外一个单词,10%情况这个单词还待在原地不做改动。这就是Masked双向语音模型的具体做法。
Next Sentence Prediction(NSP),做语言模型预训练的时候,分两种情况选择两个句子,一种是选择语料中真正顺序相连的两个句子;另外一种是第二个句子从语料库中抛色子,随机选择一个拼到第一个句子后面。我们要求模型除了做上述的Masked语言模型任务外,附带再做个句子关系预测,判断第二个句子是不是真的是第一个句子的后续句子。之所以这么做,是考虑到很多NLP任务是句子关系判断任务,单词预测粒度的训练到不了句子关系这个层级,增加这个任务有助于下游句子关系判断任务。所以可以看到,它的预训练是个多任务过程,这也是Bert的一个创新。
Bert的输入部分,是个线性序列,两个句子通过分隔符分割,最前面和最后增加两个标识符号。每个单词有三个embedding:
位置信息embedding,NLP中单词顺序是很重要的特征,需要在这里对位置信息进行编码;
单词embedding,就是之前一直提到的单词embedding;
第三个是句子embedding,因为前面提到训练数据都是由两个句子构成的,
每个句子有整体的embedding项对应给每个单词。
把单词对应的三个embedding叠加,就形成了Bert的输入。
参考:
https://zhuanlan.zhihu.com/p/49271699