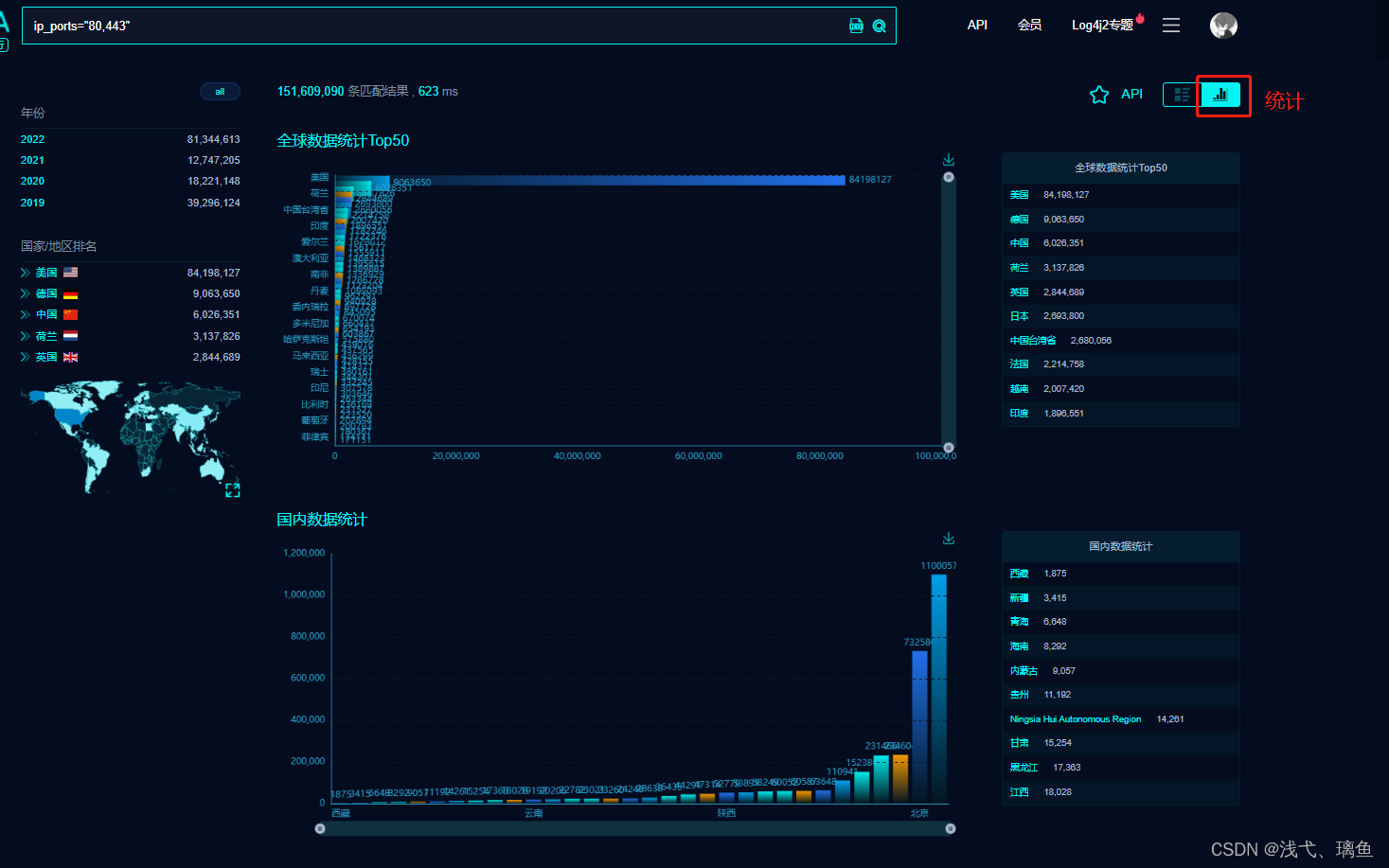
浮点类型能表示包括小数在内更大范围的数。浮点数的表示类似于科学计数法(即用小数乘以10的幂来表示数字)。该记数系统常用于表示非常大或非常小的数。
float
C语言规定,float类型必须至少能表示6位有效数字,且取值范围至少是~
。前一项规定指float类型必须能够表示33.333333的前6位数字,而不是精确到小数点后6位数字。后一项规定用于方便地表示诸如太阳质量(2.0e30千克)、一个质子的电荷量(1.6e-19库仑)或国家债务之类的数字。通常,系统存储一个浮点数要占用32位。其中8位用于表示指数的值和符号,剩下24位用于表示非指数部分(也叫作尾数或有效数)及其符号。
double
C语言提供的另一种浮点类型是double(意为双精度)。double类型和float类型的最小取值范围相同,但至少必须能表示10位有效数字。一般情况下,double占用64位而不是32位。一些系统将多出的32位全都用来非指数部分,这不仅增加了有效数字的位数(即提高了精度),而且还减少了舍入误差。另一些系统把其中的一些位分配给指数部分,以容纳更大的指数,从而增加了可表示的范围。无论哪种方法,double类型的值至少有13位有效数字,超过了标准的最低位规定。
long double
C语言的第3种浮点类型是long double,以满足比double类型更高的精度要求。不过,C只保证long double类型至少与double类型的精度相同。
浮点型常量
浮点型常量的基本形式是:有符号的数字(包括小数点),后面紧跟e或E,最后是一个有符号数表示10的指数。例如:
-1.56E+12
2.76e-3
正号可以省略。可以没有小数点(如,2E5)或指数部分(如,19.28),但是不能同时省略两者。可以省略小数部分(如,3.E16)或整数部分(如,.45E-6),但是不能同时省略两者。
例如:
3.14159
-2
4e16
.8E-5
100.
不要在浮点型常量中间加空格:1.56 E+12(错误!)
默认情况下,编译器假定浮点型常量是doble类型的精度。例如,假设some是float类型的变量,编写下面的语句:
some = 4.0 * 2.0;通常,4.0和2.0被存储为64位的double类型,使用双精度进行乘法运算,然后将乘积截断成float类型的宽度。这样做虽然计算精度更高,但是会减慢程序的运行速度。
在浮点数后面加上f或F后缀可覆盖默认设置,编译器会将浮点型常量看作float类型,如2.3f和9.1E9F。使用l后L后缀使得数字成为long double类型,如54.32和4.32L.注意,最好使用L后缀,因为字母l与数字1容易混淆。没有后缀的浮点型常量是double类型。
浮点值的上溢和下溢
假设系统的最大float类型值是3.4E38,编写如下代码:
float toobig = 3.4E38 * 100.0f;
printf("%e\n", toobig);
会发生什么呢?这是一个上溢的示例。当计算导致数字过大,超过当前类型能表达的范围时,就会发生上溢。这种行为在过去是未定义的,不过现在C语言规定,在这种情况下会给toobig赋一个表示无穷大的特定值,而且printf()显示该值为inf 或 infinity(或者具有无穷含义的其他内容)。
当对一个很小的数做除法时,情况更为复杂。回忆一下,float类型的数是以指数和尾数部分来存储。存在这样一个数,它的指数部分是最小值,即由全部可用位表示的最小尾数值。该数字是float类型能用全部精度表示的最小数字。现在把它除以2.通常,这个操作会减小指数部分,但是假设的情况中,指数已经是最小值了。所以计算机只好把尾数部分的位向右移,空出第1个二进制位,并丢弃最后一个二进制数。以十进制为例,把一个有4位有效数字的数(如,0.1234E-10)除以10,得到的结果是0.0123E-10.虽然得到了结果,但是在计算过程中却损失了原末尾有效位上的数字。这种情况叫作下溢。C语言把损失了类型全精度的浮点值称为低于正常的浮点值。因此,把最小的正浮点数除以2将得到一个低于正常的值。如果除以一个非常大的值,会导致所有的位都为0.现在c库已经提供了用于检查计算是否会产生低于正常值的函数。
还有另一个特殊的浮点值NaN。例如,给asin()函数传递一个值,该函数将返回一个角度,该角度的正弦就是传入函数的值。但是正弦值不能大于1,因此,如果传入的参数大于1,该函数的行为是未定义的。在这种情况下,该函数将返回NaN值,printf()函数可将其显示为nan、NaN或其他类似的内容。