表引擎是ClickHouse设计实现中的一大特色。
表引擎在 ClickHouse 中的作用十分关键,直接决定了数据如何存储和读取、是否支持并发读写、是否支持 index、支持的 query 种类、是否支持主备复制等。
1、表引擎概述
1.1 介绍
ClickHouse 提供了大约 28 种表引擎,各有各的用途,比如有 Log 系列用来做小表数据分析,MergeTree 系列用来做大数据量分析,而 Integration 系列则多用于外表数据集成。再考虑复制表Replicated 系列,分布式表 Distributed 等,纷繁复杂,新用户上手选择时常常感到迷惑。
ClickHouse表引擎一共分为四个系列,分别是Log、MergeTree、Integration、Special。其中包含了两种特殊的表引擎Replicated、Distributed,功能上与其他表引擎正交,根据场景组合使用。
最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。对于大多数正式的任务,推荐使用MergeTree 族中的引擎。因为只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性,同时也只有此系列的表引擎支持ALTER相关操作。
Log、Special、Integration 主要用于特殊用途,场景相对有限。MergeTree 系列才是官方主推的存储引擎,支持几乎所有 ClickHouse 核心功能。
1.2 表引擎概览
一共分为四个系列,分别是Log、MergeTree、Integration、Special。其中包含了两种特殊的表引擎Replicated、Distributed,功能上与其他表引擎正交。

表引擎(即表的类型)决定了:
(1)数据的存储方式和位置,写到哪里以及从哪里读取数据
(2)支持哪些查询以及如何支持。
(3)并发数据访问。
(4)索引的使用(如果存在)。
(5)是否可以执行多线程请求。
(6)数据复制参数。
ClickHouse 的表引擎有很多,下面介绍其中几种,对其他引擎有兴趣的可以去查阅官方文档:https://clickhouse.yandex/docs/zh/operations/table_engines/
2、Ordinary默认数据库引擎
Ordinary就是ClickHouse中默认引擎,如果不指定数据库引擎创建的就是Ordinary数据库引擎,在这种数据库下面可以使用任意表引擎。
3、Log系列表引擎
Log系列表引擎功能相对简单,主要用于快速写入小表(1百万行左右的表),然后全部读出的场景。当你需要快速写入许多小表(最多约100万行)并在以后整体读取它们时,该类型的引擎是最有效的。
几种Log表引擎的共性是:
1、数据被顺序append写到磁盘上;
2、不支持delete、update修改数据;
3、不支持index;
4、不支持原子性写;如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表。
5、insert会阻塞select操作。当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束。
该类型的引擎有:
1、TinyLog
2、StripeLog
3、Log
3.1 TinyLog
TinyLog是Log系列引擎中功能简单、性能较低的引擎。
它的存储结构由数据文件和元数据两部分组成。其中,数据文件是按列独立存储的,也就是说每一个列字段都对应一个文件。
由于TinyLog数据存储不分块,所以不支持并发数据读取,该引擎适合一次写入,多次读取的场景,对于处理小批量中间表的数据可以使用该引擎,这种引擎会有大量小文件,性能会低。
不支持索引
该引擎没有并发控制:
如果同时从表中读取和写入数据,则读取操作将抛出异常;
如果同时写入多个查询中的表,则数据将被破坏。
Log 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
示例:
-- 在ch中创建库 newdb,并使用
create database newdb;
use newdb;
-- 创建表t_tinylog 表,使用TinyLog引擎
create table t_tinylog(
id UInt8
,name String
,age UInt8
) engine=TinyLog;
-- 向表中插入数据
insert into t_tinylog values (1,'张三',18),(2,'李四',19),(3,'王五',20);
-- 查询表中的数据
select * from t_tinylog;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
└────┴──────┴─────┘
不能删除数据
-- 在表中删除一条数据,这里是不支持delete。
delete from t_tinylog where id = 1;//语句不适合CH
alter table t_tinylog delete where id = 1;
:Exception: Mutations are not supported by storage TinyLog.
3.2 StripeLog
相比TinyLog而言,StripeLog数据存储会划分块,每次插入对应一个数据块,拥有更高的查询性能(拥有.mrk标记文件,支持并行查询)。
StripeLog 引擎将所有列存储在一个文件中,使用了更少的文件描述符。对每一次 Insert 请求,ClickHouse 将数据块追加在表文件的末尾,逐列写入。
StripeLog 引擎不支持 ALTER UPDATE 和 ALTER DELETE 操作。
-- 在库 newdb中创建表 t_stripelog,使用StripeLog引擎
create table t_stripelog(
id UInt8
,name String
,age UInt8
) engine = StripeLog;
#向表t_stripelog中插入数据,这里插入分多次插入,会将数据插入不同的数据块中
node1 :) insert into t_stripelog values (1,'张三',18);
node1 :) insert into t_stripelog values (2,'李四',19);
#查询表 t_stripelog数据
node1 :) select * from t_stripelog;
SELECT *
FROM t_stripelog
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
└────┴──────┴─────┘
┌─id─┬─name─┬─age─┐
│ 2 │ 李四 │ 19 │
└────┴──────┴─────┘
2 rows in set. Elapsed: 0.003 sec.
3.3 Log
Log引擎表适用于临时数据,一次性写入、测试场景。Log引擎结合了TinyLog表引擎和StripeLog表引擎的长处,是Log系列引擎中性能最高的表引擎。
Log表引擎会将每一列都存在一个文件中,对于每一次的INSERT操作,会生成数据块,经测试,数据块个数与当前节点的core数一致。
-- 在newdb中创建表t_log 使用Log表引擎
create table t_log(id UInt8 ,name String ,age UInt8 ) engine = Log;
-- 向表 t_log中插入数据,分多次插入,插入后数据存入数据块
insert into t_log values (1,'张三',18);
insert into t_log values (2,'李四',19);
insert into t_log values (3,'王五',20);
insert into t_log values (4,'马六',21);
insert into t_log values (5,'田七',22);
-- 查询表t_log中的数据
select * from t_log;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
└────┴─────┴─────┘
┌─id─┬─name─┬─age─┐
│ 3 │ 王五 │ 20 │
│ 4 │ 马六 │ 21 │
│ 5 │ 田七 │ 22 │
└────┴─────┴─────┘
4、Special系列表引擎
4.1 Memory
Memory表引擎直接将数据保存在内存中,ClickHouse中的Memory表引擎具有以下特点:
Memory 引擎以未压缩的形式将数据存储在 RAM 中,数据完全以读取时获得的形式存储。
并发数据访问是同步的,锁范围小,读写操作不会相互阻塞。
不支持索引。
查询是并行化的,在简单查询上达到最大速率(超过10 GB /秒),在相对较少的行(最多约100,000,000)上有高性能的查询。
没有磁盘读取,不需要解压缩或反序列化数据,速度更快(在许多情况下,与 MergeTree 引擎的性能几乎一样高)。
重新启动服务器时,表存在,但是表中数据全部清空。
Memory引擎多用于测试。
示例:
重启clickhouse服务,Memory表存在,但数据丢失
-- 在 newdb中创建表 t_memory ,表引擎使用Memory
CREATE TABLE t_memory
(
`id` UInt8,
`name` String,
`age` UInt8
)
ENGINE = Memory
-- 向表 t_memory中插入数据
insert into t_memory values (1,'张三',18),(2,'李四',19),(3,'王五',20);
-- 查询表t_memory中的数据
select * from t_memory;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
└────┴──────┴─────┘
-- 重启clickhouse 服务
service clickhouse-server restart
-- 进入 newdb 库,查看表 t_memory数据,数据为空。
select * from t_memory;
4.2 Merge
Merge 引擎 (不要跟 MergeTree 引擎混淆) 本身不存储数据,但可用于同时从任意多个其他的表中读取数据,这里需要多个表的结构相同,并且创建的Merge引擎表的结构也需要和这些表结构相同才能读取。
读是自动并行的,不支持写入。读取时,那些被真正读取到数据的表如果设置了索引,索引也会被使用。
示例:
merge表引擎根据正则查询表名,聚合相同表结构的数据
-- 1、创建3张表,表结构相同,并插入数据
-- 在newdb库中创建表m_t1,并插入数据
create table m_t1 (
id UInt8 ,name String,age UInt8
) engine = TinyLog;
insert into m_t1 values (1,'张三',18),(2,'李四',19)
-- 在newdb库中创建表m_t2,并插入数据
create table m_t2 (
id UInt8 ,name String,age UInt8
) engine = TinyLog;
insert into m_t2 values (3,'王五',20),(4,'马六',21)
-- 在newdb库中创建表m_t3,并插入数据
create table m_t3 (
id UInt8 ,name String,age UInt8
) engine = TinyLog;
insert into m_t3 values (5,'田七',22),(6,'赵八',23)
-- 2、在newdb库中创建表t_merge,使用Merge引擎,匹配m开头的表
create table t_merge (
id UInt8,name String,age UInt8
) engine = Merge(newdb,'^m');
-- 查询 t_merge表中的数据
select * from t_merge;
┌─id─┬─name──┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
└────┴───────┴─────┘
┌─id─┬─name─┬─age─┐
│ 3 │ 王五 │ 20 │
│ 4 │ 马六 │ 21 │
└────┴──────┴─────┘
┌─id─┬─name─┬─age─┐
│ 5 │ 田七 │ 22 │
│ 6 │ 赵八 │ 23 │
└────┴──────┴─────┘
4.3 Distributed
Distributed是ClickHouse中分布式引擎,使用分布式引擎声明的表才可以在其他节点访问与操作。
Distributed引擎和Merge引擎类似,本身不存放数据,功能是在不同的server上把多张相同结构的物理表合并为一张逻辑表。
1> 语法
Distributed(cluster_name, database_name, table_name[, sharding_key])
对以上语法解释:
cluster_name:集群名称,与集群配置中的自定义名称相对应。配置在/etc/clickhouse-server/config.d/metrika.xml文件中,如下图:
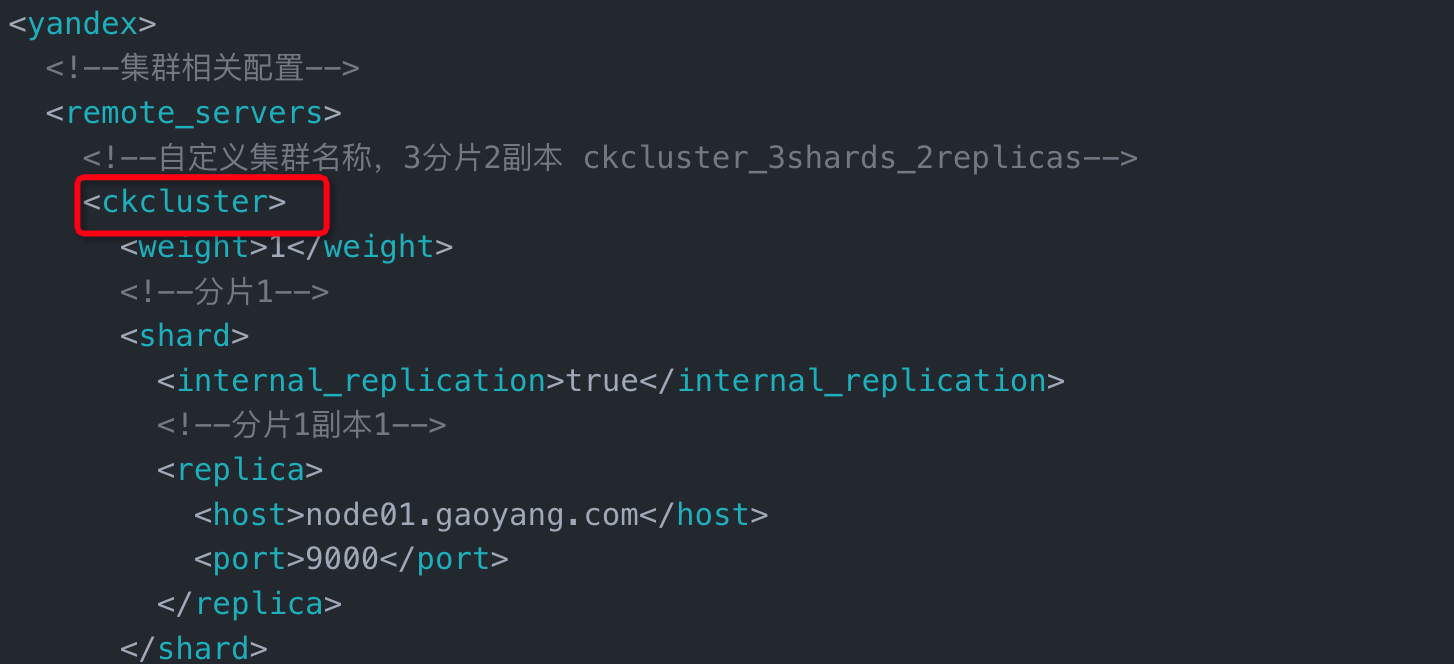
database_name:数据库名称。
table_name:表名称。
sharding_key:可选的,用于分片的key值,在数据写入的过程中,分布式表会依据分片key的规则,将数据分布到各个节点的本地表。
注意:创建分布式表是读时检查的机制,也就是说对创建分布式表和本地表的顺序并没有强制要求。
2> 示例
-- 1、在node1、node2、node3节点上启动ClickHouse 服务
-- 2、使用默认的default库,在每个节点上创建表 test_table
node1 :) create table test_local (id UInt8,name String) engine= TinyLog
node2 :) create table test_local (id UInt8,name String) engine= TinyLog
node3 :) create table test_local (id UInt8,name String) engine= TinyLog
-- 3、在node1上创建分布式表 t_distributed,表引擎使用 Distributed 引擎
node1 :) create table t_distributed(id UInt8,name String) engine = Distributed(ckcluster,default,test_local,id);
-- 注意:以上分布式表 t_distributed 只存在与node1节点的clickhouse中。
-- 4、分别在node1、node2、node3节点上向表test_local中插入2条数据
node1 :) insert into test_local values (1,'张三'),(2,'李四');
node2 :) insert into test_local values (3,'王五'),(4,'马六');
node3 :) insert into test_local values (5,'田七'),(6,'赵八');
-- 5、查询分布式表 t_distributed 中的数据
node1 :) select * from t_distributed;
┌─id─┬─name──┐
│ 1 │ 张三 │
│ 2 │ 李四 │
└────┴───────┘
┌─id─┬─name─┐
│ 5 │ 田七 │
│ 6 │ 赵八 │
└────┴──────┘
┌─id─┬─name─┐
│ 3 │ 王五 │
│ 4 │ 马六 │
└────┴──────┘
-- 6、向分布式表 t_distributed 中插入一些数据,然后查询 node1、node2、node3节点上的test_local数据,发现数据已经分布式存储在不同节点上
node1 :) insert into t_distributed values (7,'zs'),(8,'ls'),(9,'ww'),(10,'ml'),(11,'tq'),(12,'zb');
-- node1查询本地表 test_local
node1 :) select * from test_local;
┌─id─┬─name─┐
│ 1 │ 张三 │
│ 2 │ 李四 │
│ 9 │ ww │
│ 12 │ zb │
└────┴──────┘
-- node2查询本地表 test_local
node2 :) select * from test_local;
┌─id─┬─name─┐
│ 3 │ 王五 │
│ 4 │ 马六 │
│ 7 │ zs │
│ 10 │ ml │
└────┴──────┘
-- node3查询本地表 test_local
node3 :) select * from test_local;
┌─id─┬─name─┐
│ 5 │ 田七 │
│ 6 │ 赵八 │
│ 8 │ ls │
│ 11 │ tq │
└────┴──────┘
以上在node1节点上创建的分布式表t_distributed 虽然数据是分布式存储在每个clickhouse节点上的,但是只能在node1上查询t_distributed 表,其他clickhouse节点查询不到此分布式表。如果想要在每台clickhouse节点上都能访问分布式表我们可以指定集群,创建分布式表:
-- 创建分布式表 t_cluster ,引擎使用Distributed 引擎
node1 :) CREATE TABLE t_cluster ON CLUSTER ckcluster
(
`id` UInt8,
`name` String
)
ENGINE = Distributed(clickhouse_cluster_3shards_1replicas, default, test_local, id)
┌─host──┬─port─┬─status─┬─error─┬─num_hosts_remaining─┬─num_hosts_active─┐
│ node3 │ 9000 │ 0 │ │ 2 │ 0 │
│ node2 │ 9000 │ 0 │ │ 1 │ 0 │
│ node1 │ 9000 │ 0 │ │ 0 │ 0 │
└───────┴──────┴────────┴───────┴─────────────────────┴──────────────────┘
上面的语句中使用了ON CLUSTER分布式DDL(数据库定义语言),这意味着在集群的每个分片节点上,都会创建一张Distributed表,这样便可以从其中任意一端发起对所有分片的读、写请求。
5、MergeTree系列表引擎
在所有的表引擎中,最为核心的当属MergeTree系列表引擎,这些表引擎拥有最为强大的性能和最广泛的使用场合。对于非MergeTree系列的其他引擎而言,主要用于特殊用途,场景相对有限。
最强大的表引擎当属 MergeTree (合并树)引擎及该系列(*MergeTree)中的其他引擎。对于大多数正式的任务,推荐使用MergeTree 族中的引擎。因为只有合并树系列的表引擎才支持主键索引、数据分区、数据副本和数据采样这些特性,同时也只有此系列的表引擎支持ALTER相关操作。
通过理解MergeTree原理,能让我们更好的使用它。 --- 后面介绍原理
合并树家族自身也拥有多种表引擎的变种。其中MergeTree作为家族中最基础的表引擎,提供了主键索引、数据分区、数据副本和数据采样等基本能力,而家族中其他的表引擎则在MergeTree的基础之上各有所长。例如
ReplacingMergeTree表引擎具有删除重复数据的特性,
SummingMergeTree表引擎则会按照排序键自动聚合数据。
合并树系列的表引擎加上Replicated前缀,又会得到一组支持数据副本的表引擎,例如ReplicatedMergeTree、ReplicatedReplacingMergeTree、ReplicatedSummingMergeTree等。
合并树表引擎家族如图所示:
项目 | 类别 | 基础 |
Replicated 支持数据副本 | Replacing Summing Aggregating Collapsing VersionedCollapsing Graghite | MergeTree基础表 |
5.1 MergeTree创建方式
MergeTree作为家族系列最基础的表引擎,主要有以下特点:
存储的数据按照主键排序:创建稀疏索引加快数据查询速度。
支持数据分区,可以通过PARTITION BY语句指定分区字段。
支持数据副本。
支持数据采样。
完整的语法如下所示:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr [DELETE|TO DISK 'xxx'|TO VOLUME 'xxx'], ...]
[SETTINGS name=value, ...]
MergeTree表引擎除了常规参数之外,还拥有一些独有的配置选项。
1、PARTITION BY [选填]:分区键,用于指定表数据以何种标准进行分区。
分区键既可以是单个列字段,也可以通过元组的形式使用多个列字段,同时它也支持使用列表达式。
如果不声明分区键,则ClickHouse会生成一个名为all的分区。合理使用数据分区,可以有效减少查询时数据文件的扫描范围。
2、ORDER BY [必填]:排序键,用于指定在一个数据片段内,数据以何种标准排序。
默认情况下主键(PRIMARY KEY)与排序键相同。
排序键既可以是单个列字段,例如ORDER BY Col1,也可以通过元组的形式使用多个列字段,例如ORDER BY(Col1, Col2)。
当使用多个列字段排序时,以ORDER BY(Col1, Col2)为例,在单个数据片段内,数据首先会以Col1排序,相同Col1的数据再按EventDate排序。
3、PRIMARY KEY [选填]:主键,声明后会依照主键字段生成一级索引,用于加速表查询。
默认情况下,主键与排序键(ORDER BY)相同,所以通常直接使用ORDER BY代为指定主键,无须刻意通过PRIMARY KEY声明。
一般情况下,在单个数据片段内,数据与一级索引以相同的规则升序排列。与其他数据库不同,MergeTree主键允许存在重复数据(ReplacingMergeTree可以去重)
如果指定了PRIMARY KEY与排序字段不一致,要保证PRIMARY KEY 指定的主键是ORDER BY 指定字段的前缀
--允许
... ...
ORDER BY (A,B,C)
PRIMARY KEY A
--报错
... ...
ORDER BY (A,B,C)
PRIMARY KEY B
DB::Exception: Primary key must be a prefix of the sorting key
4、SAMPLE BY [选填]:抽样表达式,用于声明数据以何种标准进行采样。
抽样表达式需要配合SAMPLE子查询使用,这项功能对于选取抽样数据十分有用
如果使用了此配置项,那么在主键的配置中也需要声明同样的表达式,例如:
省略...
) ENGINE = MergeTree()
ORDER BY (CounterID, EventDate, intHash32(UserID)
SAMPLE BY intHash32(UserID)
6、TTL:数据的存活时间 [选填]。在MergeTree中,可以为某个列字段或整张表设置TTL。当时间到达时,如果是列字段级别的TTL,则会删除这一列的数据;如果是表级别的TTL,则会删除整张表的数据。可选。
7、SETTINGS:额外的参数配置。可选。
声明方式如下所示:
省略...
) ENGINE = MergeTree()
省略...
SETTINGS index_granularity = 8192;
index_granularity对于MergeTree而言是一项非常重要的参数,它表示索引的粒度
默认值为8192。也就是说,MergeTree的索引在默认情况下,每间隔8192行数据才生成一条索引。 8192是一个神奇的数字,在ClickHouse中大量数值参数都有它的影子,可以被其整除(例如最小压缩块大小min_compress_block_size:65536)。通常情况下并不需要修改此参数。
index_granularity_bytes [选填]:索引间隔
在19.11版本之前,ClickHouse只支持固定大小的索引间隔,由index_granularity控制,默认为8192。
在新版本中,它增加了自适应间隔大小的特性,即根据每一批次写入数据的体量大小,动态划分间隔大小。而数据的体量大小,正是由index_granularity_bytes参数控制的,默认为10M(10×1024×1024),设置为0表示不启动自适应功能。
enable_mixed_granularity_parts [选填]:设置是否开启自适应索引间隔的功能,默认开启。
merge_with_ttl_timeout [选填]:从19.6版本开始,MergeTree提供了数据TTL的功能
storage_policy [选填]:从19.15版本开始,MergeTree提供了多路径的存储策略
5.2 ReplacingMergeTree
虽然MergeTree拥有主键,但是它的主键却没有唯一键的约束。这意味着即便多行数据的主键相同,它们还是能够被正常写入。ReplacingMergeTree为了数据去重而设计的,它能够在合并分区时删除重复的数据。
5.2.1 基本讲解
ClickHouse提供了ReplacingMergeTree引擎,可以针对同分区内相同主键的数据进行去重,它能够在合并分区时删除重复的数据。
注意:ReplacingMergeTree只是在一定程度上解决了数据重复问题,由于自动分区合并机制在后台定时执行,所以并不能完全保障数据不重复。
ReplacingMergeTree 适用于在后台清除重复的数据以节省空间。
建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
参数解释:
[ver] :可选参数,指定列的版本,可以是UInt*、Date或者DateTime类型的字段作为版本号。该参数决定了数据去重的方式。
当没有指定[ver]时,保留最后插入的数据,也就是最新的数据;
如果指定了具体的[ver]列,则保留最大版本数据。
5.2.2 处理逻辑
1、如何判断数据重复
ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。
2、何时删除重复数据
在执行分区合并时,会触发删除重复数据。optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行。
3、不同分区的重复数据不会被去重
ReplacingMergeTree是以分区为单位删除重复数据的。
相同数据分区内重复的数据会被删除
不同数据分区间的重复数据不会被剔除。
在进行数据去重时,因为分区内的数据已经基于ORBER BY进行了排序,所以能够找到那些相邻的重复数据。
4、数据去重的策略是什么
如果没有设置[ver]版本号,则保留同一组重复数据中的最新插入的数据;
如果设置了[ver]版本号,则保留同一组重复数据中ver字段取值最大的那一行。
5、optimize命令使用
一般在数据量比较大的情况,尽量不要使用该命令。因为在海量数据场景下,执行optimize要消耗大量时间。
5.2.3 测试实例
1> 不指定[ver]列时,插入相同排序字段的数据,保留最新一条数据
-- 删除表 t_replacing_mt 重建,使用ReplacingMergeTree引擎
create table t_replacing_mt(
id UInt8,
name String,
age UInt8,
gender String
) engine = ReplacingMergeTree()
order by id
primary key id
partition by gender;
-- 1、向表 t_replacing_mt 中插入以下数据
insert into t_replacing_mt values (1,'张三',18,'男'),(2,'李四',19,'女'),(3,'王五',20,'男');
-- 2、向表 t_replacing_mt 中插入排序字段相同的一行数据
insert into t_replacing_mt values (1,'张三',10,'男');
-- 查询表 t_replacing_mt 中的数据
select * from t_replacing_mt;
┌─id─┬─name─┬─age─┬─gender─┐
│ 1 │ 张三 │ 10 │ 男 │
└────┴──────┴─────┴────────┘
┌─id─┬─name─┬─age─┬─gender─┐
│ 2 │ 李四 │ 19 │ 女 │
└────┴──────┴─────┴────────┘
┌─id─┬─name─┬─age─┬─gender─┐
│ 1 │ 张三 │ 18 │ 男 │
│ 3 │ 王五 │ 20 │ 男 │
└────┴──────┴─────┴────────┘
-- 执行 optimize命令手动合并分区数据
optimize table t_replacing_mt final;
-- 查询表 t_replacing_mt 中的数据
select * from t_replacing_mt;
┌─id─┬─name─┬─age─┬─gender─┐
│ 2 │ 李四 │ 19 │ 女 │
└────┴──────┴─────┴────────┘
┌─id─┬─name─┬─age─┬─gender─┐
│ 1 │ 张三 │ 10 │ 男 │
│ 3 │ 王五 │ 20 │ 男 │
└────┴──────┴─────┴────────┘
注意:通过以上测试可以发现,ClickHouse ReplacingMergeTree中不指定[ver]列时,当插入排序字段相同的数据时,保留最新一条数据。
2> 指定[ver]列时,插入相同排序字段的数据,保留当前[ver]列最大值
-- 删除表 t_replacing_mt 重新创建,使用ReplacingMergeTree引擎,指定[ver]
create table t_replacing_mt(
id UInt8,
name String,
age UInt8,
gender String
) engine = ReplacingMergeTree(age)
order by id
primary key id
partition by gender;
-- 1、向表 t_replacing_mt 中插入数据:
insert into t_replacing_mt values (1,'张三',18,'男'),(2,'李四',19,'女'),(3,'王五',20,'男');
-- 2、向表 t_replacing_mt 中插入排序字段相同的一行数据
insert into t_replacing_mt values (1,'张三',10,'男');
-- 查看表 t_replacing_mt中的数据
select * from t_replacing_mt;
┌─id─┬─name─┬─age─┬─gender─┐
│ 1 │ 张三 │ 10 │ 男 │
└────┴──────┴─────┴────────┘
┌─id─┬─name─┬─age─┬─gender─┐
│ 1 │ 张三 │ 18 │ 男 │
│ 3 │ 王五 │ 20 │ 男 │
└────┴──────┴─────┴────────┘
┌─id─┬─name─┬─age─┬─gender─┐
│ 2 │ 李四 │ 19 │ 女 │
└────┴──────┴─────┴────────┘
-- 3、对表 t_replacing_mt中的数据执行手动分区合并
optimize table t_replacing_mt final;
-- 查看表 t_replacing_mt中的数据
select * from t_replacing_mt;
┌─id─┬─name─┬─age─┬─gender─┐
│ 2 │ 李四 │ 19 │ 女 │
└────┴──────┴─────┴────────┘
┌─id─┬─name─┬─age─┬─gender─┐
│ 1 │ 张三 │ 18 │ 男 │
│ 3 │ 王五 │ 20 │ 男 │
└────┴──────┴─────┴────────┘
注意:通过以上测试可以发现,在ClickHouse中创建ReplacingMergeTree时,如果指定了[ver]列,当存在Order by字段重复时,会保留ver列最大值对应的行。
5.3 SummingMergeTree
终端用户只需要查询数据的汇总结果,不关心明细数据,并且数据的汇总条件是预先明确的,可以使用SummingMergeTree
5.3.1 基本讲解
该引擎继承了MergeTree引擎,当合并 SummingMergeTree 表的数据片段时,ClickHouse会把所有具有相同主键的行合并为一行,该行包含了被合并的行中具有数值数据类型的列的汇总值,即如果存在重复的数据,会对这些重复的数据进行合并成一条数据,类似于group by的效果,可以显著减少存储空间并加快数据查询速度。
SummingMergeTree建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
[columns]: 将要被汇总的列,或者多个列,多个列需要写在元组中。可选参数。
所选的列必须是数值类型,并且不可位于主键中。
如果没有指定 [columns],ClickHouse 会把所有不在主键中的数值类型的列都进行汇总。
5.3.2 处理逻辑
1、SummingMergeTree是根据什么对两条数据进行合并的
用ORBER BY排序键作为聚合数据的条件Key。即如果排序key是相同的,则会合并成一条数据,并对指定的合并字段进行聚合。
2、仅对分区内的相同排序key的数据行进行合并
以数据分区为单位来聚合数据。当分区合并时,
同一数据分区内Key相同的数据,会被合并汇总
不同分区间Key相同的数据,不会被汇总。
在进行数据汇总时,因为分区内的数据已经基于ORBER BY排序,所以能够找到相邻且拥有相同聚合Key的数据。
3、如果没有指定聚合字段,会怎么聚合
如果没有指定聚合字段,则会按照非主键的数值类型字段进行聚合。
4、对于非汇总字段的数据,该保留哪一条
在汇总数据时,同一分区内,相同聚合Key的多行数据会合并成一行。其中,汇总字段会进行SUM计算;对于那些非汇总字段,则会使用第一行数据的取值,新插入的数据对应的那个字段值会被舍弃
5、什么时候聚合?
只有在合并分区的时候才会触发汇总的逻辑
5.3.3 测试实例
-- 重新创建表 t_summing_mt ,使用SummingMergeTree引擎,并插入数据
create table t_summing_mt(
id UInt8,
name String,
age UInt8,
loc String,
dept String,
workdays UInt8,
salary Decimal32(2)
) engine = SummingMergeTree(salary)
order by (id,age)
primary key id
partition by loc;
-- 向表 t_summing_mt 中插入以下数据
insert into t_summing_mt values (1,'张三',18,'北京','大数据',24,10000),(2,'李四',19,'上海','java',22,8000),(3,'王五',20,'北京','java',26,12000);
select * from t_summing_mt;
┌─id─┬─name─┬─age─┬─loc──┬─dept───┬─workdays─┬───salary─┐
│ 1 │ 张三 │ 18 │ 北京 │ 大数据 │ 24 │ 10000.00 │
│ 3 │ 王五 │ 20 │ 北京 │ java │ 26 │ 12000.00 │
└────┴──────┴─────┴──────┴────────┴──────────┴──────────┘
┌─id─┬─name─┬─age─┬─loc──┬─dept─┬─workdays─┬──salary─┐
│ 2 │ 李四 │ 19 │ 上海 │ java │ 22 │ 8000.00 │
└────┴──────┴─────┴──────┴──────┴──────────┴─────────┘
-- 2、向表 t_summing_mt 中插入一条排序键相同的数据
insert into t_summing_mt values (1,'马六',18,'北京','前端',27,15000);
select * from t_summing_mt;
┌─id─┬─name─┬─age─┬─loc──┬─dept───┬─workdays─┬───salary─┐
│ 1 │ 张三 │ 18 │ 北京 │ 大数据 │ 24 │ 10000.00 │
│ 3 │ 王五 │ 20 │ 北京 │ java │ 26 │ 12000.00 │
└────┴──────┴─────┴──────┴────────┴──────────┴──────────┘
┌─id─┬─name─┬─age─┬─loc──┬─dept─┬─workdays─┬───salary─┐
│ 1 │ 马六 │ 18 │ 北京 │ 前端 │ 27 │ 15000.00 │
└────┴──────┴─────┴──────┴──────┴──────────┴──────────┘
┌─id─┬─name─┬─age─┬─loc──┬─dept─┬─workdays─┬──salary─┐
│ 2 │ 李四 │ 19 │ 上海 │ java │ 22 │ 8000.00 │
└────┴──────┴─────┴──────┴──────┴──────────┴─────────┘
-- 3、手动执行optimize 命令触发合并相同分区数据
optimize table t_summing_mt final;
select * from t_summing_mt;
┌─id─┬─name─┬─age─┬─loc──┬─dept───┬─workdays─┬───salary─┐
│ 1 │ 张三 │ 18 │ 北京 │ 大数据 │ 24 │ 25000.00 │
│ 3 │ 王五 │ 20 │ 北京 │ java │ 26 │ 12000.00 │
└────┴──────┴─────┴──────┴────────┴──────────┴──────────┘
┌─id─┬─name─┬─age─┬─loc──┬─dept─┬─workdays─┬──salary─┐
│ 2 │ 李四 │ 19 │ 上海 │ java │ 22 │ 8000.00 │
└────┴──────┴─────┴──────┴──────┴──────────┴─────────┘
注意:我们可以看到当指定一个聚合字段时,有相同排序字段行进行聚合时,会按照这个数值字段进行合并,其他的保留最开始一条数据的信息。
5.4 AggregatingMergeTree
AggregatingMergeTree是SummingMergeTree的升级版,与 SummingMergeTree的区别在于:SummingMergeTree 对非主键列进行 sum 聚合,而 AggregatingMergeTree 则可以指定各种聚合函数。
5.4.1 基本讲解
该表引擎继承自MergeTree,可以使用 AggregatingMergeTree 表来做增量数据统计聚合。如果要按一组规则来合并减少行数,则使用 AggregatingMergeTree 是合适的。AggregatingMergeTree是通过预先定义的聚合函数计算数据并通过二进制的格式存入表内。
语句如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = AggregatingMergeTree()
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[TTL expr]
[SETTINGS name=value, ...]
5.4.2 处理逻辑
1、根据什么对两条数据进行合并的
用ORBER BY排序键作为聚合数据的条件Key
2、什么时候聚合?
只有在合并分区的时候才会触发聚合计算的逻辑
2、仅对分区内的相同排序key的数据行进行合并
以数据分区为单位来聚合数据。当分区合并时,
同一数据分区内Key相同的数据,会被合并汇总计算
不同分区间Key相同的数据,不会被汇总计算。
在进行数据汇总时,因为分区内的数据已经基于ORBER BY排序,所以能够找到相邻且拥有相同聚合Key的数据。
3、聚合字段有限制吗?
使用AggregateFunction字段类型定义聚合函数的类型以及聚合的字段。
AggregateFunction类型的字段使用二进制存储,在写入数据时,需要调用*State函数;而在查询数据时,则需要调用相应的Merge函数。其中,表示定义时使用的聚合函数。
4、对于非汇总字段的数据,该保留哪一条
在汇总数据时,同一分区内,相同聚合Key的多行数据会合并成一行。对于那些非汇总字段,则会使用第一行数据的取值,新插入的数据对应的那个字段值会被舍弃
5.4.3 测试实例
作为AggregatingMergeTree物化视图的表引擎
-- 1、创建表 t_merge_base 表,使用MergeTree引擎
create table t_merge_base(
id UInt8,
name String,
age UInt8,
loc String,
dept String,
workdays UInt8,
salary Decimal32(2)
) engine = MergeTree()
order by (id,age)
primary key id
partition by loc;
-- 2、创建物化视图 view_aggregating_mt ,使用AggregatingMergeTree引擎
create materialized view view_aggregating_mt
engine = AggregatingMergeTree()
order by id
as select id,name,sumState(salary) as ss from t_merge_base
group by id ,name;
-- 3、向表 t_merge_base 中插入数据
insert into t_merge_base values (1,'张三',18,'北京','大数据',24,10000),(2,'李四',19,'上海','java',22,8000),(3,'王五',20,'北京','java',26,12000);
-- 查看 view_aggregating_mt视图数据
select *,sumMerge(ss) from view_aggregating_mt group by id,name,ss;
┌─id─┬─name─┬─ss─┬─sumMerge(ss)─┐
│ 2 │ 李四 │ 5 │ 8000.00 │
│ 3 │ 王五 │ O │ 12000.00 │
│ 1 │ 张三 │ @B │ 10000.00 │
└────┴──────┴────┴──────────────┘
-- 4、继续向表 t_merge_base中插入排序键相同的数据
insert into t_merge_base values (1,'张三三',18,'北京','前端',22,5000);
-- 手动执行optimize 命令,合并物化视图 view_aggregating_mt 相同分区数据
optimize table view_aggregating_mt final;
-- 查询视图 view_aggregating_mt数据
select *,sumMerge(ss) from view_aggregating_mt group by id,name,ss;
┌─id─┬─name─┬─ss─┬─sumMerge(ss)─┐
│ 2 │ 李四 │ 5 │ 8000.00 │
│ 1 │ 张三 │ `ᔠ│ 15000.00 │
│ 3 │ 王五 │ O │ 12000.00 │
└────┴──────┴────┴──────────────┘
注意:通过普通MergeTree表与AggregatingMergeTree物化视图结合使用,MergeTree中存放原子数据,物化视图中存入聚合结果数据,可以提升数据查询效率。
5.5 CollapsingMergeTree
对于ClickHouse这类高性能分析型数据库而言,对数据源文件修改是一件非常奢侈且代价高昂的操作。相较于直接修改源文件,它们会将修改和删除操作转换成新增操作,即以增代删。
5.5.1 基本讲解
折叠合并树(CollapsingMergeTree)就是一种通过以增代删的思路,支持行级数据修改和删除的表引擎。它通过定义一个sign标记位字段,记录数据行的状态。如果sign标记为1,则表示这是一行有效的数据;如果sign标记为-1,则表示这行数据需要被删除。
当CollapsingMergeTree分区合并时,同一数据分区内,sign标记为1和-1的一组数据会被抵消删除。
语法如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
sign Int8
) ENGINE = CollapsingMergeTree(sign)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
存在的问题:
CollapsingMergeTree对于写入数据的顺序有着严格要求,否则导致无法正常折叠。
5.5.2 处理逻辑
1、CollapsingMergeTree在折叠数据时,遵循以下规则:
如果sign=1比sign=-1的数据多一行,则保留最后一行sign=1的数据。
如果sign=-1比sign=1的数据多一行,则保留第一行sign=-1的数据。
如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=1,则保留第一行sign=-1和最后一行sign=1的数据。
如果sign=1和sign=-1的数据行一样多,并且最后一行是sign=-1,则什么也不保留。
其余情况,ClickHouse会打印警告日志,但不会报错
2、只有相同分区内的数据才有可能被折叠
3、最后这项限制,CollapsingMergeTree对于写入数据的顺序有着严格要求。
如果按照正常顺序写入,先写入sign=1,再写入sign=-1,则能够正常折叠
写入的顺序置换,先写入sign=-1,再写入sign=1,则不能够折叠
解决方案:使用VersionedCollapsingMergeTree
5.5.3 测试实例
按照顺序写入需要更新或删除的数据
-- 1、创建表 t_collapsing_mt ,使用CollapsingMergeTree
create table t_collapsing_mt(
id UInt8,
name String,
loc String,
login_times UInt8,
total_dur UInt8,
sign Int8
)engine = CollapsingMergeTree(sign)
order by (id,total_dur)
primary key id
partition by loc
;
-- 向表t_collapsing_mt 中插入以下数据:
insert into t_collapsing_mt values(1,'张三','北京',1,30,1),(2,'李四','上海',1,40,1)
select * from t_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 1 │ 张三 │ 北京 │ 1 │ 30 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
-- 2、向表 t_collapsing_mt中继续插入一条数据,删除“张三”数据
insert into t_collapsing_mt values(1,'张三','北京',1,30,-1);
select * from t_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 1 │ 张三 │ 北京 │ 1 │ 30 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 1 │ 张三 │ 北京 │ 1 │ 30 │ -1│
└────┴──────┴──────┴─────────────┴───────────┴──────┘
-- 3、手动触发 optimize 合并相同分区数据
optimize table t_collapsing_mt final;
select * from t_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
------------------------------------------------------
-- 4、插入以下两条数据,来更新 “李四”数据
insert into t_collapsing_mt values(2,'李四','上海',1,40,-1),(2,'李四','上海',2,100,1);
select * from t_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 2 │ 李四│ 上海 │ 1 │ 40 │ -1 │
│ 2 │ 李四│ 上海 │ 2 │ 100 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
-- 5、手动执行 optimize 触发相同分区合并
node1 :) optimize table t_collapsing_mt;
select * from t_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┐
│ 2 │ 李四 │ 上海 │ 2 │ 100 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┘
5.6 VersionedCollapsingMergeTree
5.6.1 基本讲解
VersionedCollapsingMergeTree使用version列来实现乱序情况下的数据折叠,该引擎除了需要指定一个sign标识之外,还需要指定一个UInt*类型的version版本号。
建表语句:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
sign Int8,
version UInt8
) ENGINE = VersionedCollapsingMergeTree(sign, version)
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
5.6.2 处理逻辑
在定义ver字段之后,VersionedCollapsingMergeTree会自动将ver作为排序条件并增加到ORDER BY的末端。所以无论写入时数据的顺序如何,在折叠处理时,都能回到正确的顺序。
5.6.3 测试实例
-- 1、创建表 t_version_collapsing_mt ,使用VersionedCollapsingMergeTree引擎
create table t_version_collapsing_mt(
id UInt8,
name String,
loc String,
login_times UInt8,
total_dur UInt8,
sign Int8,
version UInt8
)engine = VersionedCollapsingMergeTree(sign,version)
order by (id,total_dur)
primary key id
partition by loc
;
-- 向表 t_version_collapsing_mt 中插入以下数据
insert into table t_version_collapsing_mt values(1,'张三','北京',1,30,-1,1),(2,'李四','上海',1,40,1,2);
select * from t_version_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 1 │ 张三 │ 北京 │ 1 │ 30 │ -1│ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ 1 │ 2 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
-- 2、向表 t_version_collapsing_mt中插入以下数据,删除“张三”信息,更新“李四”信息
insert into table t_version_collapsing_mt values(1,'张三','北京',1,30,1,1),(2,'李四','上海',1,40,-1,2),(2,'李四','上海',2,100,1,2);
select * from t_version_collapsing_mt ;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 1 │ 张三 │ 北京 │ 1 │ 30 │ -1 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ 1 │ 2 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 1 │ 张三 │ 北京 │ 1 │ 30 │ 1 │ 1 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 2 │ 李四 │ 上海 │ 1 │ 40 │ -1 │ 2 │
│ 2 │ 李四 │ 上海 │ 2 │ 100 │ 1 │ 2 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
-- 3、手动执行 optimize 命令,合并相同分区的数据
optimize table t_version_collapsing_mt final;
select * from t_version_collapsing_mt;
┌─id─┬─name─┬─loc──┬─login_times─┬─total_dur─┬─sign─┬─version─┐
│ 2 │ 李四 │ 上海 │ 2 │ 100 │ 1 │ 2 │
└────┴──────┴──────┴─────────────┴───────────┴──────┴─────────┘
6、Integration系列表引擎
ClickHouse提供了许多与外部系统集成的方法,包括一些表引擎。这些表引擎与其他类型的表引擎类似,可以用于将外部数据导入到ClickHouse中,或者在ClickHouse中直接操作外部数据源。
6.1 HDFS
HDFS引擎支持ClickHouse 直接读取HDFS中特定格式的数据文件,目前文件格式支持Json,Csv文件等,ClickHouse通过HDFS引擎建立的表,不会在ClickHouse中产生数据,读取的是HDFS中的数据,将HDFS中的数据映射成ClickHouse中的一张表,这样就可以使用SQL操作HDFS中的数据。
ClickHouse并不能够删除HDFS上的数据,当我们在ClickHouse客户端中删除了对应的表,只是删除了表结构,HDFS上的文件并没有被删除,这一点跟Hive的外部表十分相似。
6.1.1 基本讲解
语法:
ENGINE = HDFS(URI, format)
注意:URI是HDFS文件路径,format指定文件格式。HDFS文件路径中文件为多个时,可以指定成some_file_?,或者当数据映射的是HDFS多个文件夹下数据时,可以指定somepath/* 来指定URI
其他配置:
由于HDFS配置了HA 模式,有集群名称,所以URI使用mycluster HDFS集群名称时,ClickHouse不识别,这时需要做以下配置:
将hadoop路径下$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件复制到/etc/clickhouse-server目录下。
修改/etc/init.d/clickhouse-server 文件,加入一行 “export LIBHDFS3_CONF=/etc/clickhouse-server/hdfs-site.xml”
重启ClickHouse-server 服务
当然,这里也可以不做以上配置,在写HDFS URI时,直接写成对应的节点+端口即可。
6.1.2 测试实例
先在HDFS上准备一个数据文件:student.csv CSV格式的数据,数据如下:
95002,刘晨,女,19,IS
95017,王风娟,女,18,IS
95018,王一,女,19,IS
95013,冯伟,男,21,CS
95014,王小丽,女,19,CS
95019,邢小丽,女,19,IS
95020,赵钱,男,21,IS
95003,王敏,女,22,MA
95004,张立,男,19,IS
95012,孙花,女,20,CS
95010,孔小涛,男,19,CS
95005,刘刚,男,18,MA
95006,孙庆,男,23,CS
95007,易思玲,女,19,MA
95008,李娜,女,18,CS
95021,周二,男,17,MA
95022,郑明,男,20,MA
95001,李勇,男,20,CS
95011,包小柏,男,18,MA
95009,梦圆圆,女,18,MA
95015,王君,男,18,MA
95016,钱国,男,21,MA
上传文件到HDFS
# 上传到HDFS:
hadoop fs -ls /clickhouse_data/student/
# 如果该目录存在,就删除!
hadoop fs -rm -r /clickhouse_data/student/
hadoop fs -mkdir -p /clickhouse_data/student/
hadoop fs -put student.csv /clickhouse_data/student/
1> 从HDFS读取数据
从HDFS上读取数据类似于将HDFS作为外部存储,然后去拉取HDFS上的数据。所以这种模式,肯定要比直接从 ClickHouse 中读取数据要慢的多。
-- ClickHouse 建表语句
create database if not exists nxdb3;
use nxdb3;
drop table if exists nxdb3.nx_table_student_csv;
create table if not exists nxdb3.nx_table_student_csv(
id Int8,
name String,
sex String,
age Int8,
department String
) Engine = HDFS('hdfs://bigdata02:9000/clickhouse_data/student/stu*.csv','CSV');
-- 查询
select * from nxdb3.nx_table_student_csv;
注意:这里表nx_table_student_csv不会在clickhouse对应的节点路径下创建数据目录,同时这种表映射的是HDFS路径中的csv文件,不能插入数据,nx_table_student_csv是只读表。
注意:
1、支持CSV, TSV, Parquet 等格式,注意CSV是大写的!
2、执行并行读写操作(Reads and writes can be parallel)
3、字符串中的是否有引号,都能被自动解析,有引号也行,没有引号也行。
4、如果需要关联多个文件,ClickHouse虽然不支持直接关联文件夹,但是对于文件路径还是提供给了多个支持,具体可以参照官网:https://clickhouse.tech/docs/en/engines/table-engines/integrations/hdfs/
5、支持虚拟列 path 和 file,分别代表文件路径,和文件名。
6、不支持的操作:alter 和 select ... sample 语法, Indexes 语法,和 Replication 操作
说明:从HDFS读取 Parquet 格式文件的数据。可能有所不同
2> 从HDFS导入数据**
我们想要将读取到的数据保存到本地,只需要将读取数据的表导入其他的本地表。在实际企业工作环境中,数据往往存在 HDFS,或者Hive 等环境中。我们需要把 HDFS 上的数据导入到 ClickHouse 依次来提高查询分析的效率。
-- 先在 ClickHouse 中创建一张表 nx_table_hdfs_csv1:
create database if not exists nxdb3;
use nxdb3;
drop table if exists nx_table_student_csv1;
create table if not exists nx_table_student_csv1(
id Int8,
name String,
sex String,
age Int8,
department String
) engine = TinyLog;
-- 从 HDFS 上导入数据到 ClickHouse:
insert into nxdb3.nx_table_student_csv1
select *
from hdfs(
'hdfs://bigdata02:9000/clickhouse_data/student/student.csv'
,'CSV'
, 'id Int8
, name String
, sex String
, age Int8
, department String'
);
详细语法可以参考官网:https://clickhouse.tech/docs/zh/sql-reference/table-functions/hdfs/
3> 插入数据
-- 创建表 t_hdfs2 文件 ,使用HDFS引擎
create table t_hdfs2(
id UInt8,
name String,
age UInt8
) engine = HDFS('hdfs://mycluster/chdata','CSV');
-- 向表 t_hdfs2中写入数据
insert into t_hdfs2 values(5,'田七',23),(6,'赵八',24);
-- 查询表t_hdfs2中的数据
select * from t_hdfs2;
┌─id─┬─name─┬─age─┐
│ 5 │ 田七 │ 23 │
│ 6 │ 赵八 │ 24 │
└────┴──────┴─────┘
注意:t_hdfs2表没有直接映射已经存在的HDFS文件,这种表允许查询和插入数据。
6.2 MySQL
MySQL引擎用于将远程的 MySQL 服务器中的表映射到 ClickHouse 中,并允许您对表进行INSERT 和SELECT 查询,以方便您在 ClickHouse 与 MySQL 之间进行数据交换。这个模式类似于 Hive 的外部表。
这里映射的表只能做查询和插入操作,不支持删除和更新操作。
官网链接:MySQL 引擎
6.2.1 基本讲解
语法:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
) ENGINE = MySQL('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause']);
参数解释:
参数 | 说明 |
host:port | MySQL服务器名称和端口 |
database | 数据库的名称 |
table | 映射的MySQL中的表 |
user | 登录mysql的用户名 |
password | 登录mysql的密码 |
replace_query | 将INSERT INTO 查询是否替换为 REPLACE INTO 的标志,默认为0,不替换。当设置为1时,所有的insert into 语句更改为 replace into 语句。当插入的数据有重复主键数据时,此值为0默认报错,此值为1时,主键相同这条数据,默认替换成新插入的数据。 |
on_duplicate_clause | 默认不使用。当插入数据主键相同时,可以指定只更新某列的数据为新插入的数据,对应于on duplicate key 后面的语句,其他的值保持不变,需要replace_query 设置为0。 |
mysql表与ClickHouse表字段映射类型:
Mysql | ClickHouse | 类型解释 |
UNSIGNED TINYINT | UInt8 | 无符号的范围是从0到255的整型数据,占位大小为1字节 |
TINYINT | Int8 | 有符号的范围是-128-127,占位大小为1字节 |
UNSIGNED SMALLINT | UInt16 | 小整数。无符号的范围是0到65535,占位大小为2个字节 |
SMALLINT | Int16 | 一个小整数。有符号的范围是-2^15(-32,768) 到 2^15-1(32,767),占位大小为2个字节 |
UNSIGNED MEDIUMINT | UInt32 | 一个中等大小整数。有符号的范围是-8388608到8388607,占位大小为3个字节 |
MEDIUMINT | Int32 | 一个中等大小整数,无符号的范围是0到16777215,占位大小为3个字节。 |
UNSIGNED INT | Int32 | 一个正常大小整数。有符号的范围是-2^31(-2,147,483,648)到2^31-1(2,147,483,647) |
INT | Int32 | 一个正常大小整数。有符号的范围是-2^31(-2,147,483,648)到2^31-1(2,147,483,647),占位大小为 4 个字节。 |
UNSIGNED BIGINT | UInt64 | |
BIGINT | Int64 | |
FLOAT | Float32 | |
DOUBLE | Float64 | |
DATE | Date | |
DATETIME, TIMESTAMP | DateTime | |
BINARY | FixedString |
6.2.2 处理逻辑
1、MySQL映射Clickhouse的映射方式有几种?
创建一个库映射 mysql 的库
创建一张表映射 mysql 的表
2、ClickHouse是如何操作MySQL数据的?
MySQL数据库引擎会将对其的查询转换为MySQL语法并发送到MySQL服务器中,如 WHERE 子句(例如 =, !=, >, >=, <, <=)是在 MySQL 服务器上执行,也可以执行如SHOW TABLES或SHOW CREATE TABLE之类的操作
其余条件以及 LIMIT 采样约束语句仅在对MySQL的查询完成后才在 ClickHouse中执行
ClickHouse引擎不支持Nullable数据类型,因此,当从MySQL表中读取数据时,NULL将转换为指定列类型的默认值(通常为0或空字符串)。
ClickHouse不允许创建表、修改表、删除数据、重命名操作。
3、在目标库MySQL中操作数据,Clickhouse的映射表如何变化
在MySQL对应的表中插入删除数据,对应的在ClickHouse中也能插入和删除的数据
在MySQL库创建表,ClickHouse中可以看到
4、在映射表Clickhouse中操作数据,目标库MySQL如何变化?
在ClickHouse中向映射表中插入数据,可以在msyql中查询到。
ClickHouse中不支持创建表和删除数据操作
5、注意:在clickhouse 中映射表不会在ClickHouse服务器节点上创建数据目录。
6.2.3 测试实例
1> 映射数据库
如果这个库里面需要有大量的表需要映射到clickhouse做分析,可以不用移动数据,直接映射就可以执行分析(不推荐使用)
映射数据库:
-- 1、登录mysql 在mysql中创建数据库与表,并插入两条数据
mysql> create database test;
mysql> use test;
mysql> create table mysql_table(id int ,name varchar(255));
mysql> insert into mysql_table values (1,"zs"),(2,"ls");
-- 2、ClickHouse中创建mysql引擎的数据库,映射test数据库
node1 :) CREATE DATABASE mysql_db
ENGINE = MySQL('node2:3306', 'test', 'root', '123456')
-- 测试1:查看映射结果
-- 在ClickHouse中使用mysql_db库,并展示表,看是否映射MySQL中的表
node1 :) use mysql_db;
node1 :) show tables;
┌─name────────┐
│ mysql_table │
└─────────────┘
-- 在ClickHouse中查询表mysql_table
node1 :) select * from mysql_table;
┌─id─┬─name─┐
│ 1 │ zs │
│ 2 │ ls │
└────┴──────┘
-- 测试2:查看映射后ClickHouse中的字段类型。
-- 在ClickHouse中查看表 mysql_table的描述
node1 :) desc mysql_table;
┌─name─┬─type────────────┬
│ id │ Nullable(Int32) │
│ name │ Nullable(String)│
└──────┴─────────────────┴
-- 测试3:在MySQL表中插入删除数据,可以在ClickHouse中查到
mysql> insert into mysql_table values (3,"ww");
mysql> delete from mysql_table where id = 1;
-- 在ClickHouse中 mysql_db库下查询表mysql_table
node1 :) select * from mysql_table;
┌─id─┬─name─┐
│ 2 │ ls │
│ 3 │ ww │
└────┴──────┘
-- 测试4:在MySQL中创建新表,ClickHouse中也可以展示
mysql> create table a (id int,name varchar(255),age int);
mysql> insert into a values (1,"zhangsan",18),(2,"lisi",19);
-- 在ClickHouse中 mysql_db库下查询表a是否存在,同时查看数据
node1 :) show tables;
┌─name────────┐
│ a │
│ mysql_table │
└─────────────┘
node1 :) select * from a;
┌─id─┬─name─────┬─age─┐
│ 1 │ zhangsan │ 18 │
│ 2 │ lisi │ 19 │
└────┴──────────┴─────┘
-- 测试5:在ClickHouse中插入数据,可以在MySQL中查到
-- 在ClickHouse中向表a中插入数据
node1 :) insert into a values(3,'wangwu',20);
-- 在MySQL中查询表a数据
mysql> select * from a;
+------+----------+------+
| id | name | age |
+------+----------+------+
| 1 | zhangsan | 18 |
| 2 | lisi | 19 |
| 3 | wangwu | 20 |
+------+----------+------+
在数仓开发中,你写了一个离线任务计算得到结果之后,一般都会通过比如sqoop datax canal 工具迁移数据到 mysql,供业务项目使用。
2> 映射数据表
-- 1、登录mysql 在mysql中创建数据库与表,并插入两条数据
mysql> create database test;
mysql> use test;
mysql> create table mysql_table(id int ,name varchar(255));
mysql> insert into mysql_table values (1,"zs"),(2,"ls");
-- 2、ClickHouse中创建mysql引擎的数据库,映射mysql_table数据表
node1 :) use ck_db;
node1 :) CREATE TABLE ck_db.ck_table
ENGINE = MySQL('node2:3306','test','mysql_table','root','123456');
-- 查询
node1 :) select * from ck_db.ck_table;
┌─id─┬─name─┐
│ 2 │ ls │
│ 3 │ ww │
└────┴──────┘
-- 3、也可以不做映射,直接查询
select * from mysql('node2:3306','test','mysql_table','root','123456') limit 3;
3> 数据迁移(IS语法 和 CTAS语法)
-- 1、insert into ... select ... 语法
node1 :) create table ck_db.ck_table2(
id Int8,
name String
) engine = Log;
-- 从mysql中,把数据弄到了 clickhouse中
node1 :) insert into ck_db.ck_table2
select * from mysql('node2:3306','test','mysql_table','root','123456');
-- 2、create table ... as select ... 语法
node1 :) create table if not exists ck_db.ck_table3 engine = Log
as select * from mysql('node2:3306','test','mysql_table','root','123456');
4> replace_query、on_duplicate_clause测试
测试 replace_query
-- 1、在mysql 中删除表 t_ch,重新创建,指定id为主键,并插入数据
mysql> CREATE TABLE t_ch (
id INT,
NAME VARCHAR (255),
age INT,
PRIMARY KEY (id)
)
mysql> insert into t_ch values (1,"张三",18),(2,"李四",19),(3,"王五",20);
-- 2、在ClickHouse中删除MySQL引擎表 t_mysql_engine,重建
node1 :) create table t_mysql_engine (
id UInt8,
name String,
age UInt8
)engine = MySQL('node2:3306','test','t_ch','root','123456',1);
-- 查询ClickHouse表 t_mysql_engine 中的数据:
node1 :) select * from t_mysql_engine;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
└────┴──────┴─────┘
-- 3、在ClickHouse中向表 t_mysql_engine中插入一条数据,主键重复。这里由于指定了replace_query = 1 ,所以当前主键数据会被替换成新插入的数据。
node1 :) insert into t_mysql_engine values (3,'马六','21');
-- 4、查询ClichHouse t_mysql_engine表数据
node1 :) select * from t_mysql_engine;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 马六 │ 21 │
└────┴──────┴─────┘
测试 on_duplicate_clause:
-- 1、在mysql 中删除表 t_ch,重新创建,指定id为主键,并插入数据
mysql> CREATE TABLE t_ch (
id INT,
NAME VARCHAR (255),
age INT,
PRIMARY KEY (id)
)
mysql> insert into t_ch values (1,"张三",18),(2,"李四",19),(3,"王五",20)
-- 2、在ClickHouse中删除MySQL引擎表 t_mysql_engine,重建
node1 :) create table t_mysql_engine (
id UInt8,
name String,
age UInt8
)engine = MySQL('node2:3306','test','t_ch','root','123456',0,'update age = values(age)');
-- 查询ClickHouse表 t_mysql_engine 中的数据:
node1 :) select * from t_mysql_engine;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
└────┴──────┴─────┘
-- 3、在ClickHouse 中向表 t_mysql_engine中插入一条数据
node1 :) insert into t_mysql_engine values (4,'马六','21');
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
│ 4 │ 马六 │ 21 │
└────┴──────┴─────┘
-- 4、在ClickHouse中向表 t_mysql_engine中插入一条数据,主键重复。
node1 :) insert into t_mysql_engine values (4,'田七','100');
-- 查询ClichHouse t_mysql_engine表数据
node1 :) select * from t_mysql_engine;
┌─id─┬─name─┬─age─┐
│ 1 │ 张三 │ 18 │
│ 2 │ 李四 │ 19 │
│ 3 │ 王五 │ 20 │
│ 4 │ 马六 │ 100 │
└────┴──────┴─────┘