机器翻译
- 机器翻译概述
- 典型神经机器翻译模型
- 神经机器翻译 ( Neural Machine Translation, NMT
- 神经机器翻译系统相关技术
- 罕见词处理技术(词表受限问题)
- 解决办法
- subword 方法
- beam search
- coverage penalty (翻译覆盖率问题)
- 推敲网络(Deliberation Network)
- 非自回归模型
- 系统鲁棒性
- 低资源神经机器翻译
- 语料资源受限问题
- 多语预训练语言模型
机器翻译概述
任务描述:利用计算机把一种语言(源语言, source language) 翻译成另
一种语言(目标语言, target language)的技术
发展历程:
基于规则的机器翻译系统:需要经过词法分析,句法分析等诸多步骤各步需要的规则均需要人工编写。
基于统计的机器翻译系统:用概率统计方法分不同翻译粒度和不的同翻译方法
- 基于词的翻译方法
- 基于短语的翻译方法
- 基于层次化短语方法
- 基于树的方法
端到端的翻译架构
- GNMT
- ConvS2S
- Transformer
典型神经机器翻译模型
神经机器翻译 ( Neural Machine Translation, NMT
机器翻译问题是序列生成问题,可采用“编码-解码” 框架建模
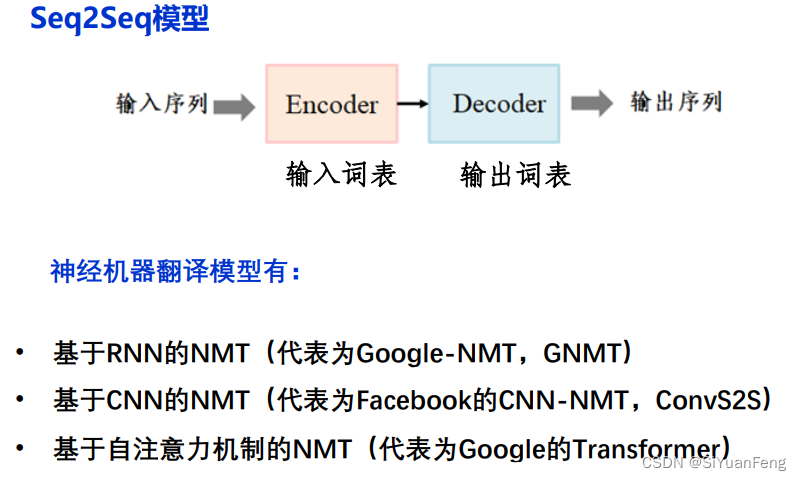
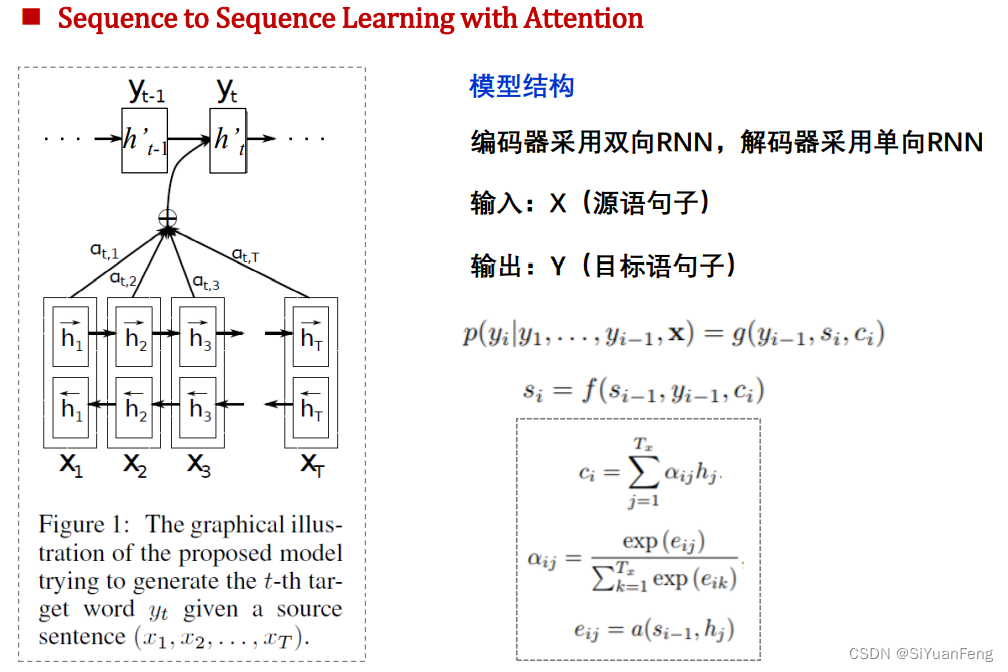
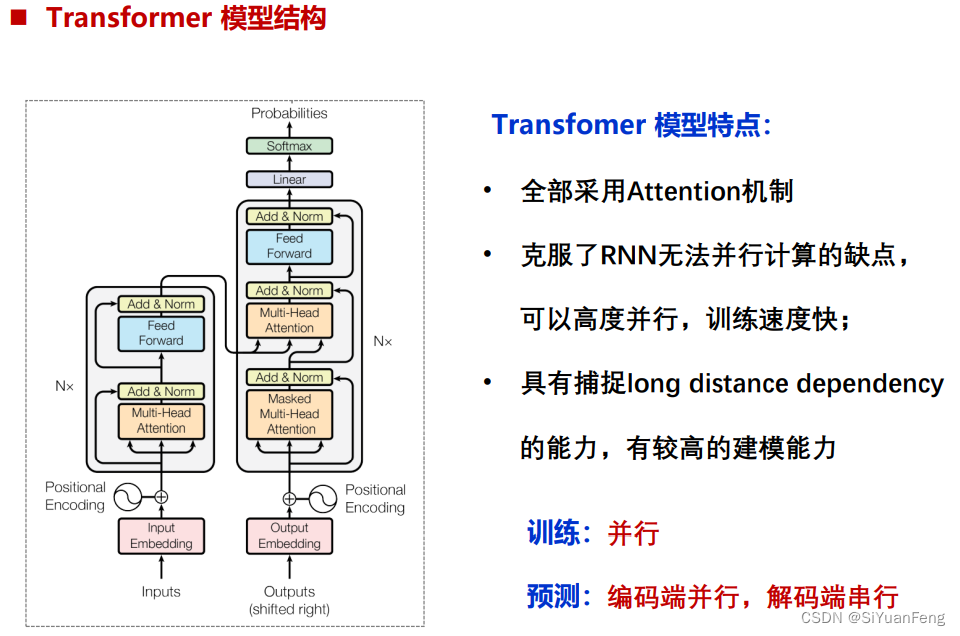
神经机器翻译系统相关技术
- 罕见词处理技术
sub-word unit - 解码策略及改进
机器翻译系统相关技术:
• beam search
• coverage penalty
• 推敲网
• 非自回归解码 - 系统鲁棒性
罕见词处理技术(词表受限问题)
在神经网络机器翻译模型中,由于考虑到计算的复杂度问题,都使用一个受限词表,这样会导致很多单词成了词表外的OOV词,而这种OOV词在翻译时很难处理并且打破了句子结构,增加了语句的歧义性,因此,如何处理罕见词成为NMT领域非常必要的研究问题
解决办法
• subword 方法
• 词语/字混合方法(Mixed Word/Character Model)
• UNK处理
• 扩大词表
• 固定词表 + 动态的词表
subword 方法
基本思想:将单词划分为更小的单元,如“older”划分为“old” 和 “er”,这些单元能组成其他词汇。由子词构成的词汇表可以有效的缓解机器翻译中的词表受限问题
获取subword词表的流程(learn-bpe)
- 准备语料,分解成最小单元,比如英文中26个字母加上各种符号,作为原始词表
- 根据语料统计相邻字符对出现的频次
- 挑出频次最高的相邻字符对,比如“t”和“h”,合并组成“th”,加入词表,训练语料中所有该相邻字符对都进行融合
- 重复2和3操作,直至词表中单词的数量达到期望,或下一个最高频的字节对出现频率为1
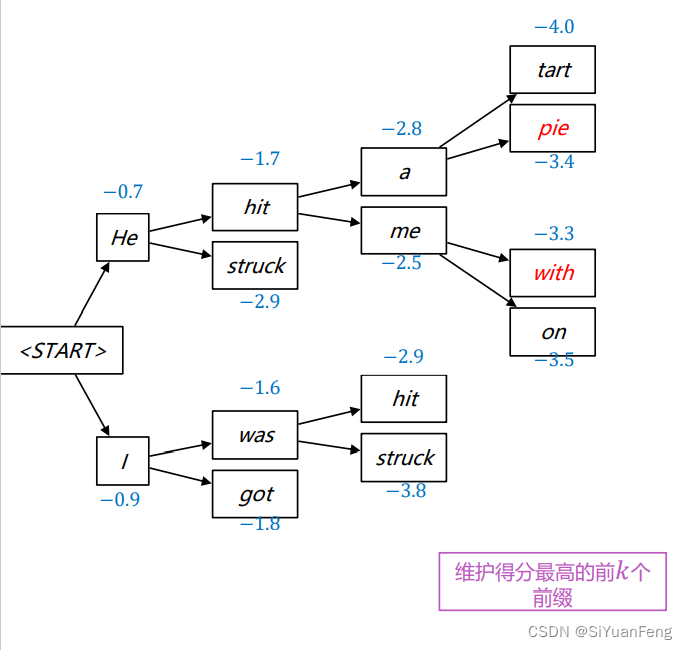
beam search
Greedy Search 解码:方法:每个step选择概率最大的词作为输出
Beam Search 解码:每个step选择概率最大的K个 词作为输出
比如下图,每次选两个词
coverage penalty (翻译覆盖率问题)
基本思想:建立coverage 向量,在解码的过程中,保持对attention信号持续关注和利用,以此来解决attention信号之间的独立问题
推敲网络(Deliberation Network)
目前的序列生成方法往往通过一轮前向计算解码出整个目标序列,缺乏推敲过程。本文引入一个推敲网络进行双轮解码以模拟人类书写文章的过程,即先解码出一个基础序列,然后对其进行斟酌推敲形成最终的目标序列
非自回归模型
非自回归 (Non-Autoregressive Translation, NAT)模型打破了生成时的串行顺
序希望一次能够解码出整个目标句子,从而解决AT模型的问题。
NAT模型将解码问题建模为:

系统鲁棒性
鲁棒性问题:神经网络能够对全局上下文进行建模,但对于局部变化过于敏感,提升系统的容错性,一致性(鲁棒性)对用户体验十分重要
解决方法:可采用对抗学习等训练方法提升系统的鲁棒性
核心思想:对于噪声输入生成与原始输入相同的输出译文以提升模型的鲁棒性
解决方法:在输入端加入微小的扰动,用对抗学习方法使得模型不受扰动影响
低资源神经机器翻译
语料资源受限问题
神经机器翻译(NMT)性能高度依赖于平行语料的规模、质量和领域覆盖面。在中英等平行语料资源丰富的语对上,NMT表现出极好的翻译性能。然而,在平行语料匮乏的语对上,NMT的性能急剧下降;对于“小语种”语言,平行语料资源匮乏是常态。因此,如何充分利用现有数据缓解资源匮乏问题,成为神经机器翻译的一个重要研究方向。

多语预训练语言模型