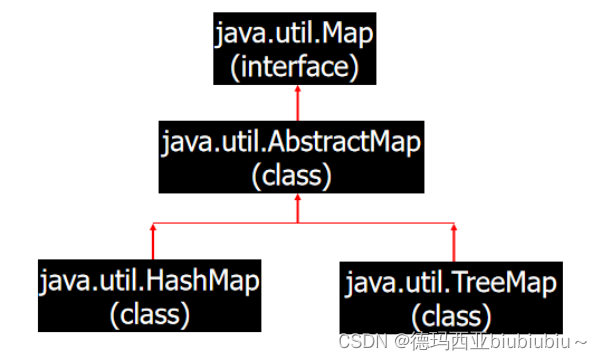
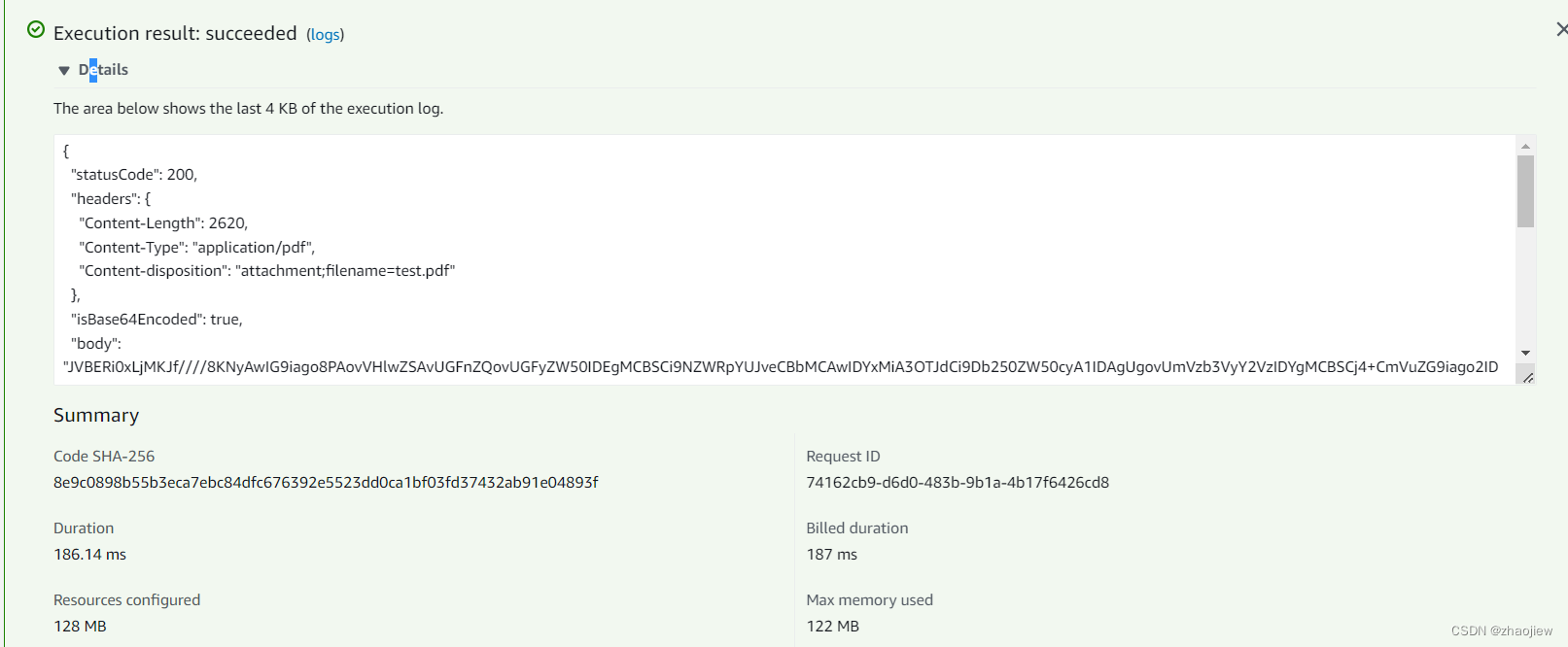
前面的一些章节介绍了如何在只有6万张图像的Fashion-MNIST训练数据集上训练模型。 我们还描述了学术界当下使用最广泛的大规模图像数据集ImageNet,它有超过1000万的图像和1000类的物体。 然而,我们平常接触到的数据集的规模通常在这两者之间。
假如我们想识别图片中不同类型的椅子,然后向用户推荐购买链接。 一种可能的方法是首先识别100把普通椅子,为每把椅子拍摄1000张不同角度的图像,然后在收集的图像数据集上训练一个分类模型。 尽管这个椅子数据集可能大于Fashion-MNIST数据集,但实例数量仍然不到ImageNet中的十分之一。 适合ImageNet的复杂模型可能会在这个椅子数据集上过拟合。 此外,由于训练样本数量有限,训练模型的准确性可能无法满足实际要求。
为了解决上述问题,一个显而易见的解决方案是收集更多的数据。 但是,收集和标记数据可能需要大量的时间和金钱。 例如,为了收集ImageNet数据集,研究人员花费了数百万美元的研究资金。 尽管目前的数据收集成本已大幅降低,但这一成本仍不能忽视。
另一种解决方案是应用迁移学习(transfer learning)将从源数据集学到的知识迁移到目标数据集。 例如,尽管ImageNet数据集中的大多数图像与椅子无关,但在此数据集上训练的模型可能会提取更通用的图像特征,这有助于识别边缘、纹理、形状和对象组合。 这些类似的特征也可能有效地识别椅子。
1. 网络架构
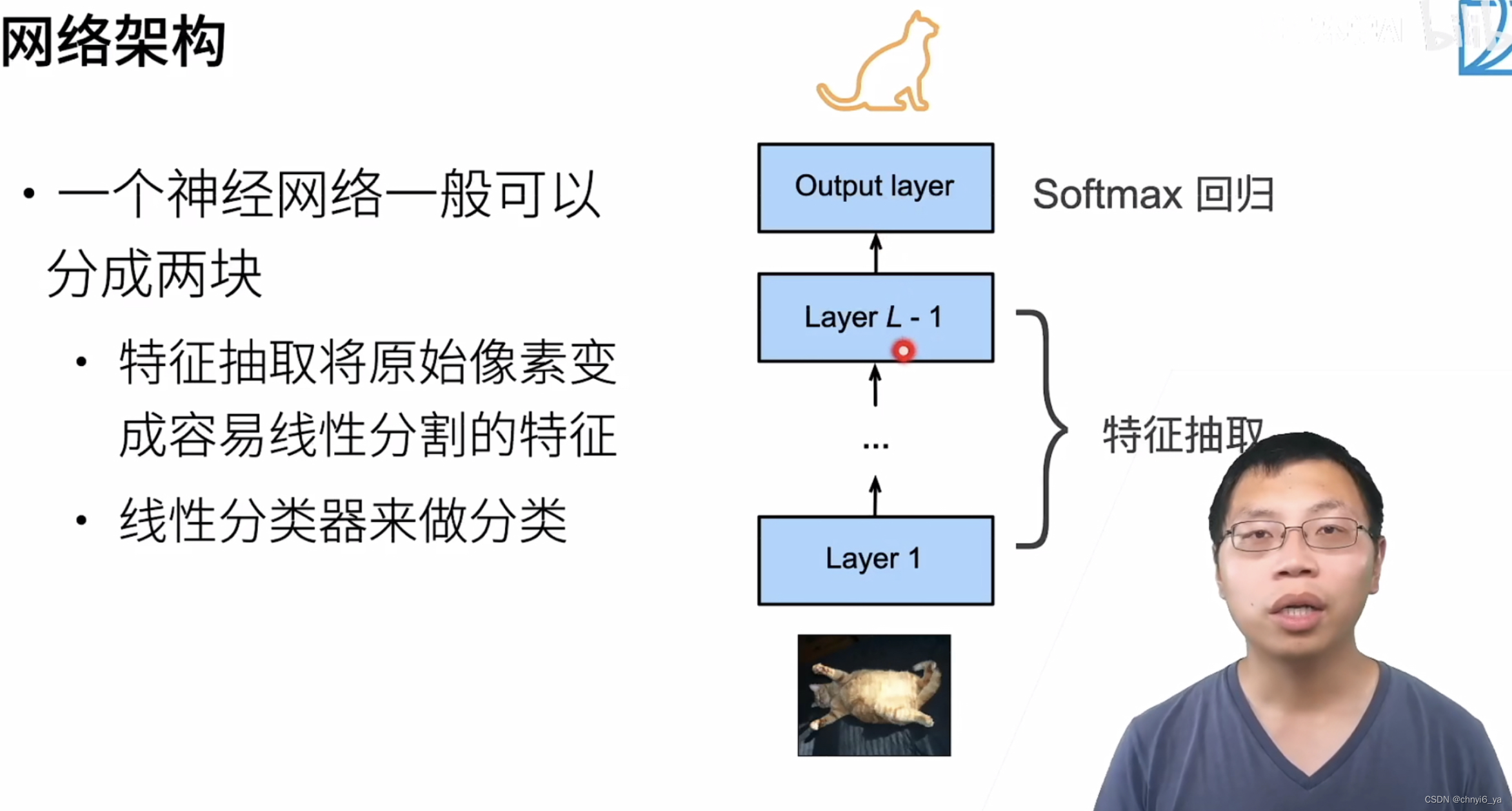
2. 微调
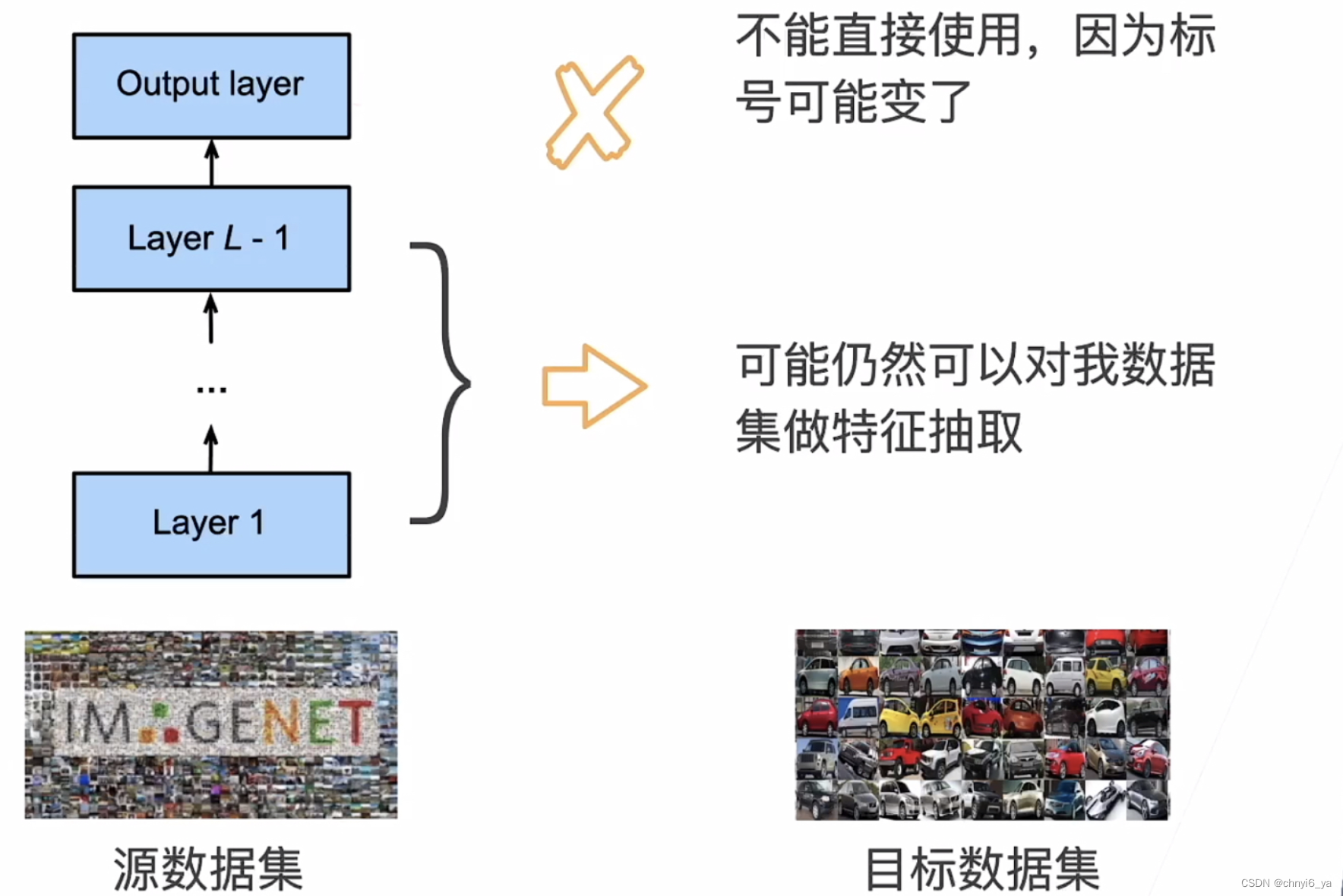
2. 微调中的权重初始化
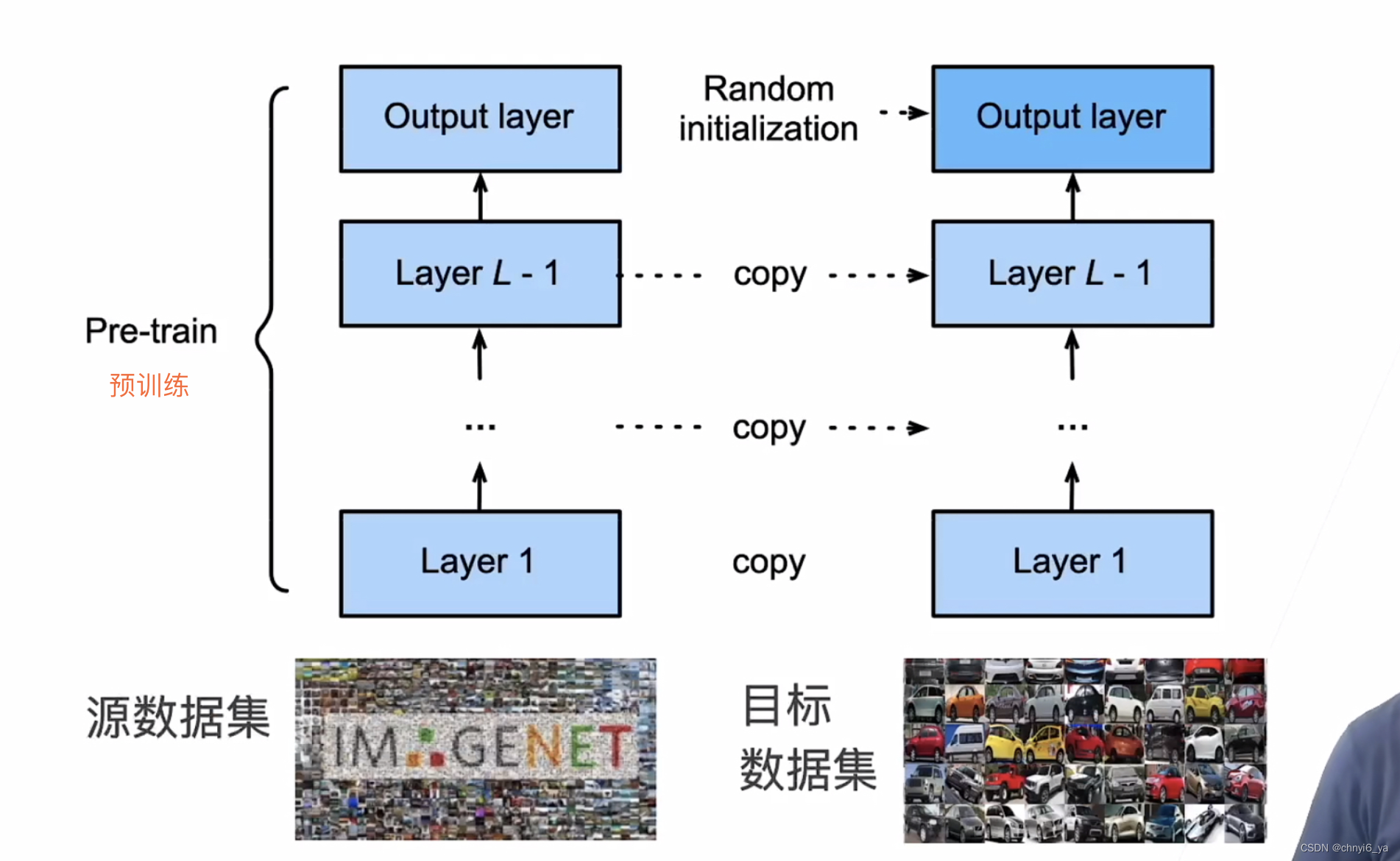
3. 训练
-
是一个目标数据集上的正常训练任务,但使用更强的正则化
- 使用更小的学习率
- 使用更少的数据迭代
-
源数据集远复杂于目标数据,通常微调效果更好
4. 重用分类器权重
- 源数据可能也有目标数据中的部分标号
- 可以使用预训练好的模型分类器中对应标号对应的向量来做初始化
5. 固定一些层

ps:可以理解为,越到后面和标号越相关,在前面就是一些低层次的特征。
6. 总结
- 微调通过使用在大数据上得到的预训练好的模型来初始化模型权重来完成提升精度
- 预训练模型质量很重要
- 微调通常速度更快、精度更高
7. 一些Q&A
Q1:重用标号的话,对于无关的标号是直接删除吗,原始模型中的没有的标号怎么加进去呢?
A1: 重用标号的话,就把对应标号的权重拎出来,其他都不要,如果原始模型中没有的标号就随机初始化。
Q2: 标号那块,是不是都是label的名称字符串,对应到数字上?微调中有相同标号,怎么做原始标号和目标标号的对应?
A2:是的,标号都是对应label的名称字符串,有时标号还要去做语义匹配(可能同一个东西在不同数据集上的名称不同),做标号的映射。
Q3:微调就是transfer learning吗?
A3:微调是transfer learning里面的一类算法。
Q4:如果源数据集和目标数据集差异较大的话,微调的效果会下降吗?例如imageNet上的模型用到医疗影像分类。
A4:会的,源数据集和目标数据集最好是相似的,最好是源数据集大于目标数据集。
Q5:微调的话,源数据集中的样本是否必须包含目标数据集里的类别。
A5:不一定,类似就可以了,不用完全一样。
Q6:为什么微调中的归一化保持一致很重要?是为了保留数据分布信息吗?
A6:是的,可以认为微调代码实现时最后一个normalize可以认为是网络中的一块,并且normalize也可以换成batch_normalize layer,可以认为ToTensor后面的都是网络架构中一块,只是resnet 去copy的时候没有把那一块copy过来,所以手动弄过去,但是如果resnet18中有batch normalization layer的话,是不需要的。
Q7: normalize里的那些参数(2行3列)从哪里来的?
A7:是从ImageNet上算出来的。
Q8:比较常用的CV预训练模型有哪些?
A8: Resnet比较常用
Q9: 关于“重用分类器权重”,对于一个80类的数据集,只想选用其中的5类,加上另外的4类,怎么重用着这5类呢?有什么快速的方式?
A9:只能手动提取,没有更快的方式。
Q10:微调中怎么获取某个类别其输出层中的相应权重参数。
A10: 附上练习题中的提示:
weight = pretrained_net.fc.weight
hotdog_w = torch.split(weight.data, 1, dim=0)[934]
hotdog_w.shape
Q11:是不是已经有过是随机选择层的实验了呢?如何选择迁移那些层效果更好呢?就是靠测试?
A11: 是的,有过是随机选择层的实验了。假设有10层卷积层,写一个for循环,第i次就固定最下面的i层,然后调上面的就行了,会有效果,但是训练起来很贵。