为了完成毕设准备开始学习PyTorch,第一步到蓝桥云课搜索实验项目,找到了“PyTorch入门与实战(第二版)”,开始边实验边学习(本身有了一点点点点的相关基础了)
学习传送门:PyTorch基础入门
Tensor 支持的所有操作:传送门——PyTorch官方网站
目录
- 1. 基础知识
- 1.1 特点
- 1.2 张量(Tensor)
- 2. PyTorch的使用
- 2.1
- 2.2 基本 Tensor 运算
- 加法
- Tensor 与 numpy.ndarray 之间的转换
- 区别
- 2.3 自动微分(Autograd)变量的练习
- 2.3.1 基础概念
- 例一
- 例2 “深度”计算图
- 2.4 利用PyTorch实现简单的线性回归算法
- 2.4.1 准备数据
- 2.4.2 构造模型 计算损失函数
- 2.4.3 测试模型
1. 基础知识
Pytorch 是由 Facebook 支持的一套深度学习开源框架。
Tensor(张量)是 PyTorch 的基础数据结构,自动微分运算是深度学习的核心。
1.1 特点
完全开源:意味着你可以轻易获取它的代码,并按照自己的需求对它进行修改。
代码简洁:使用 PyTorch 框架编写出的神经网络模型的代码非常简洁。
1.2 张量(Tensor)
张量(Tensor),它实际上是一种 N 维数组。
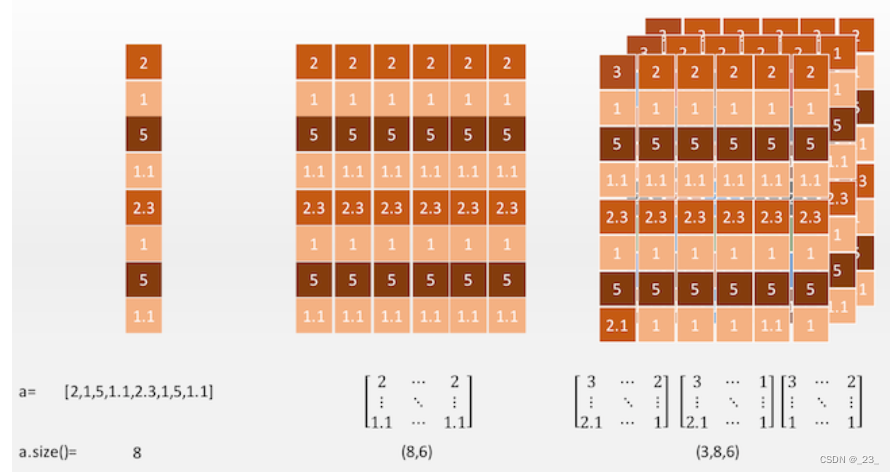
我们可以使用 Tensor.size() 方法获得一个张量的“尺寸”。
在这里注意“尺寸”和维度是两个概念。
就比如对于上图中的 1 阶张量,它的维度为 1,尺寸为 8;
对于上图中的 2 阶张量,它的维度为 2,尺寸为(8,6)。
2. PyTorch的使用
2.1
import torch #导入torch包
print() #输出
torch.__version__ #返回PyTorch的版本号
x = torch.zeros(5, 3) #产生一个5*3的tensor,取值全零
x = torch.ones(5, 3) #产生一个5*3的tensor,取值全1
x = torch.rand(5, 3) #产生一个5*3的tensor,随机取值
x #显示x的值
#输出
#tensor([[0.9817, 0.7694, 0.0797],
# [0.5797, 0.4102, 0.2647],
# [0.4080, 0.8279, 0.4324],
# [0.2985, 0.5336, 0.2487],
# [0.3479, 0.1069, 0.6264]])
2.2 基本 Tensor 运算
Tensor 支持的所有操作:传送门——PyTorch官方网站
加法
相加前,必须保证两个张量的尺寸相同。n* m+n*m
z = x + y #两个tensor可以直接相加
z
y.t() #y矩阵转置
y.transpose(0, 1) #y矩阵转置
q = x.mm(y.t()) #x乘以y的转置
Tensor 与 numpy.ndarray 之间的转换
import numpy as np #导入numpy包
a = np.ones([5, 3]) #建立一个5*3全是1的二维数组(矩阵)
b = torch.from_numpy(a) #利用from_numpy将其转换为tensor
b
c = torch.FloatTensor(a) #转换 Tensor 的方法,类型为 FloatTensor。
d = torch.LongTensor(a) # 还可以是LongTensor,整型数据类型
b.numpy() #tensor 转化为 numpy 的多维数组
输出:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
区别
(我也搞不懂这个GPU啥意思,就写在这里存着,万一用到了就能直接找到)
Tensor 和 Numpy 的最大区别在于 Tensor 可以在 GPU 上进行运算。
默认情况下,Tensor 是在 CPU 上进行运算的,
如果我们需要一个 Tensor 在 GPU 上的实例,需要运行这个 Tensor 的 .cuda() 方法。
在下面的代码中,首先判断在本机上是否有 GPU 环境可用(有 NVIDIA的 GPU,并安装了驱动)。
如果有 GPU 环境可用,那么再去获得张量 x,y 的 GPU 实例。
注意在最后打印 x 和 y 这两个 GPU 张量的和的时候,我们调用了 .cpu() 方法,
意思是将 GPU 张量转化为 CPU 张量,否则系统会报错。
if torch.cuda.is_available(): #检测本机器上有无GPU可用
x = x.cuda() #返回x的GPU上运算的版本
y = y.cuda()
z = x + y
print(z.cpu()) # 打印时注意要把GPU变量转化为CPU变量。
输出:
tensor([[1.9817, 1.7694, 1.0797],
[1.5797, 1.4102, 1.2647],
[1.4080, 1.8279, 1.4324],
[1.2985, 1.5336, 1.2487],
[1.3479, 1.1069, 1.6264]])
2.3 自动微分(Autograd)变量的练习
如果大家觉得去理解这个计算图的叶子结点很困难,这也没有关系。因为我们研究的主题是深度学习,PyTorch 框架会自动搭建好计算图的。
2.3.1 基础概念
动态运算图(Dynamic Computation Graph)是 PyTorch 的最主要特性,
它可以让我们的计算模型更灵活、复杂,并可以让反向传播算法随时进行。
注:只有叶子节点,才有有梯度信息

例一
#导入自动梯度的运算包,主要用Variable这个类
from torch.autograd import Variable
#创建一个Variable,包裹了一个2*2张量,将需要计算梯度属性置为True
x = Variable(torch.ones(2, 2), requires_grad=True)
x #输出:tensor([[1., 1.],
# [1., 1.]], requires_grad=True)
y = x + 2 #可以按照Tensor的方式进行计算
y.grad_fn #每个Variable都有一个creator(创造者节点)
#输出:<AddBackward0 at 0x7f825c429810>
z = torch.mean(y * y) #也可以进行复合运算,比如求均值mean
z.data #.data属性可以返回z所包裹的tensor
#输出:tensor(9.)
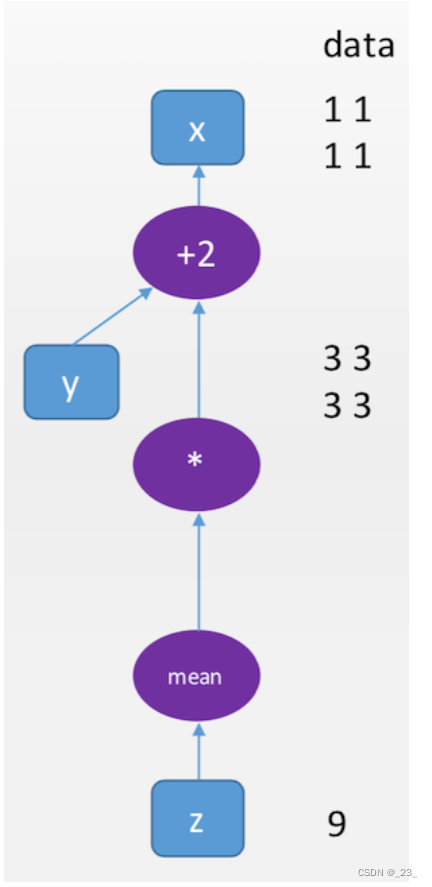
backward 可以实施反向传播算法,并计算所有计算图上叶子节点(没有子节点)的导数(梯度)信息。
z.backward() #梯度反向传播
print(z.grad) # z不是叶子节点,无梯度信息
print(y.grad) # y不是叶子节点,无梯度信息
print(x.grad) # x是叶子节点
输出:
None
None
tensor([[3., 3.],
[3., 3.]])
例2 “深度”计算图
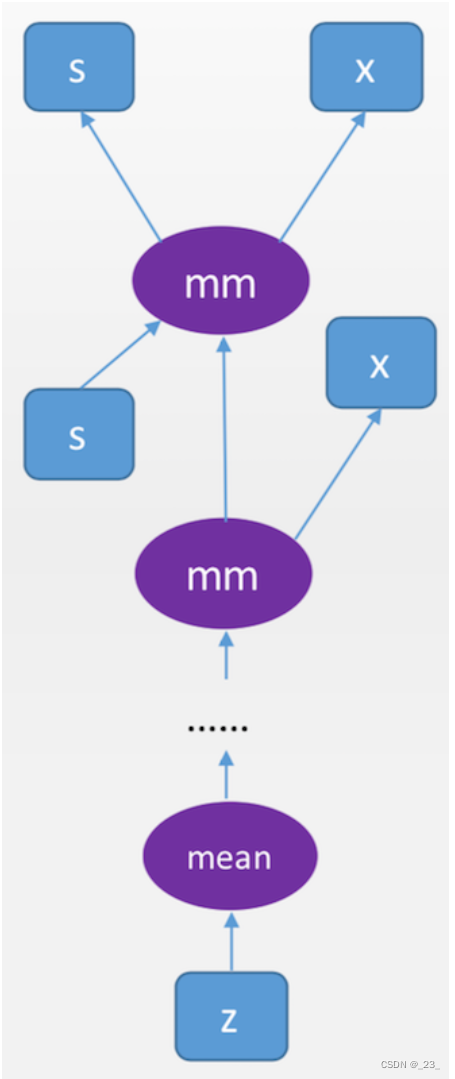
让矩阵 x 反复作用在向量 s 上,系统会自动记录中间的依赖关系和长路径。
s = Variable(torch.FloatTensor([[0.01, 0.02]]), requires_grad = True) #创建一个1*2的Variable(1维向量)
x = Variable(torch.ones(2, 2), requires_grad = True) #创建一个2*2的矩阵型Variable
for i in range(10):
s = s.mm(x) #反复用s乘以x(矩阵乘法),注意s始终是1*2的Variable
z = torch.mean(s) #对s中的各个元素求均值,得到一个1*1的scalar(标量,即1*1张量)
z.backward() #在具有很长的依赖路径的计算图上用反向传播算法计算叶节点的梯度
print(x.grad) #x作为叶节点可以获得这部分梯度信息
print(s.grad) #s不是叶节点,没有梯度信息
输出:
tensor([[37.1200, 37.1200],
[39.6800, 39.6800]])
None
2.4 利用PyTorch实现简单的线性回归算法
2.4.1 准备数据
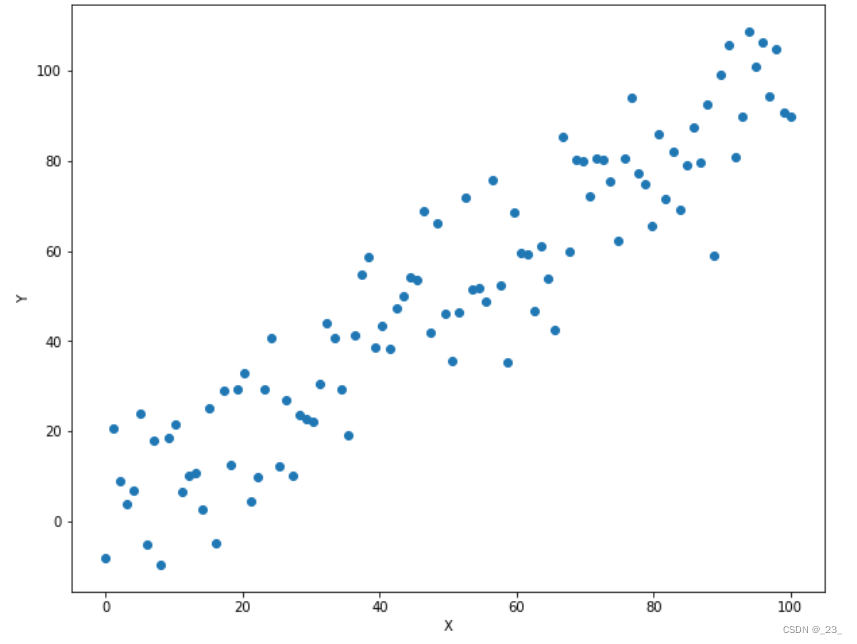
import matplotlib.pyplot as plt #导入画图的程序包
%matplotlib inline
# linspace可以生成0-100之间的均匀的100个数字
x = Variable(torch.linspace(0, 100).type(torch.FloatTensor))
# 随机生成100个满足标准正态分布的随机数,均值为0,方差为1.
# 将这个数字乘以10,标准方差变为10
rand = Variable(torch.randn(100)) * 10
# 将x和rand相加,得到伪造的标签数据y。
# 所以(x,y)应能近似地落在y=x这条直线上
y = x + rand
plt.figure(figsize=(10,8)) #设定绘制窗口大小为10*8 inch
# 绘制数据,考虑到x和y都是Variable,
# 需要用data获取它们包裹的Tensor,并专成numpy
plt.plot(x.data.numpy(), y.data.numpy(), 'o')
plt.xlabel('X') #添加X轴的标注
plt.ylabel('Y') #添加Y轴的标注
plt.show() #将图形画在下面
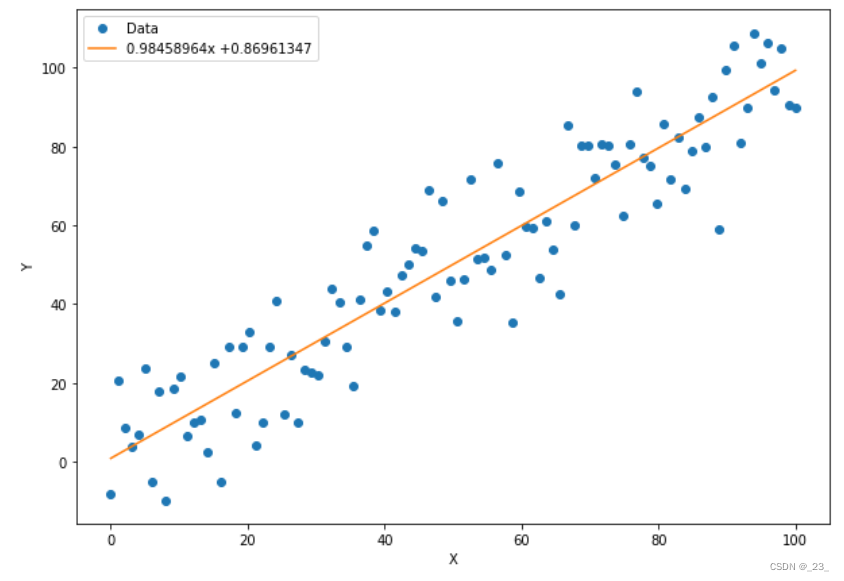
2.4.2 构造模型 计算损失函数
用 ax+b 来表示一条直线。建立变量,随机初始化用于线性拟合的参数 a 和 b。
#创建a变量,并随机赋值初始化
a = Variable(torch.rand(1), requires_grad = True)
#创建b变量,并随机赋值初始化
b = Variable(torch.rand(1), requires_grad = True)
print('Initial parameters:', [a, b])
#输出:Initial parameters: [tensor([0.9102], requires_grad=True), tensor([0.2548], requires_grad=True)]
learning_rate = 0.0001 #设置学习率
for i in range(1000):
### 下面这三行代码非常重要,这部分代码,清空存储在变量a,b中的梯度信息,
### 以免在backward的过程中会反复不停地累加
#如果a和b的梯度都不是空
if (a.grad is not None) and (b.grad is not None):
a.grad.data.zero_() #清空a的数值
b.grad.data.zero_() #清空b的数值
#计算在当前a、b条件下的模型预测数值 首先a的维度为1,x是维度为100*1的Tensor,不能直接相乘,因为维度不同
# .expand_as(x)将张量升维成与 x 同维度的张量。所以如果 a = 1, x 为尺寸为 100
#x*y两个1维张量乘积 =====> (𝑥∗𝑦)𝑖=𝑥𝑖⋅𝑦𝑖
predictions = a.expand_as(x) * x + b.expand_as(x)
#通过与标签数据y比较,计算误差
loss = torch.mean((predictions - y) ** 2)
print('loss:', loss.data.numpy()) #打印出来的数值会发现损失慢慢降低
loss.backward() #对损失函数进行梯度反传
#利用上一步计算中得到的a的梯度信息更新a中的data数值
a.data.add_(- learning_rate * a.grad.data)
#利用上一步计算中得到的b的梯度信息更新b中的data数值
b.data.add_(- learning_rate * b.grad.data)
x_data = x.data.numpy() # 获得x包裹的数据
plt.figure(figsize = (10, 7)) #设定绘图窗口大小
xplot, = plt.plot(x_data, y.data.numpy(), 'o') # 绘制原始数据
yplot, = plt.plot(x_data, a.data.numpy() * x_data + b.data.numpy()) #绘制拟合数据
plt.xlabel('X') #更改坐标轴标注
plt.ylabel('Y') #更改坐标轴标注
str1 = str(a.data.numpy()[0]) + 'x +' + str(b.data.numpy()[0]) #图例信息
plt.legend([xplot, yplot],['Data', str1]) #绘制图例
plt.show()
2.4.3 测试模型
x_test = Variable(torch.FloatTensor([1, 2, 10, 100, 1000])) #随便选择一些点1,2,……,1000
predictions = a.expand_as(x_test) * x_test + b.expand_as(x_test) #计算模型的预测结果
predictions #输出
输出:
tensor([ 1.8542, 2.8388, 10.7155, 99.3286, 985.4593],
grad_fn=<AddBackward0>)