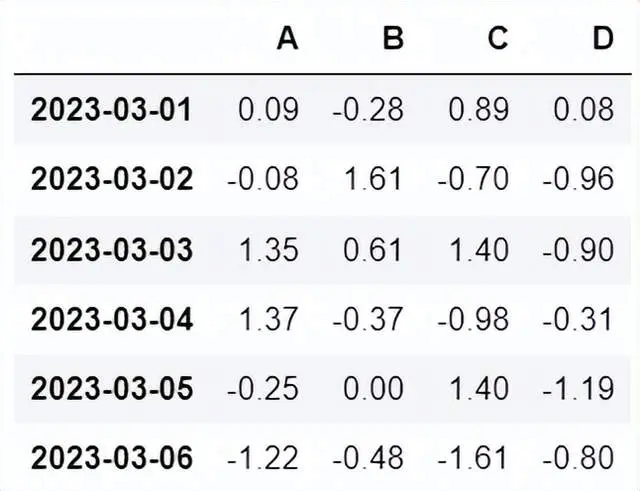
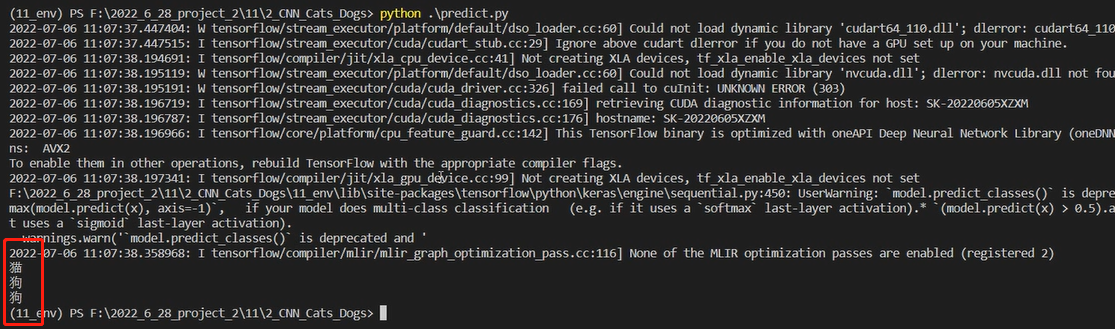
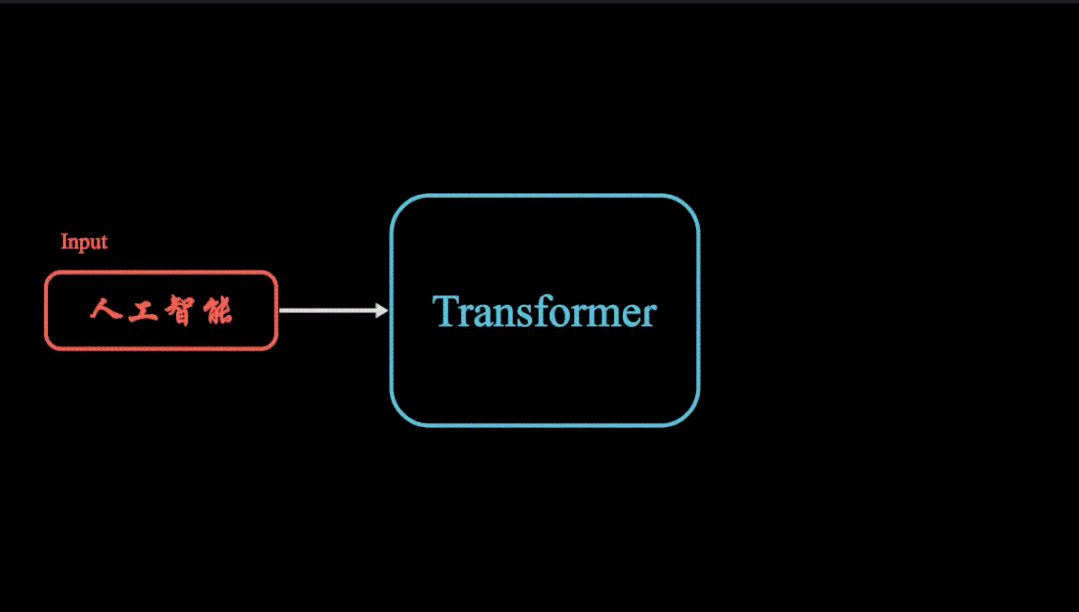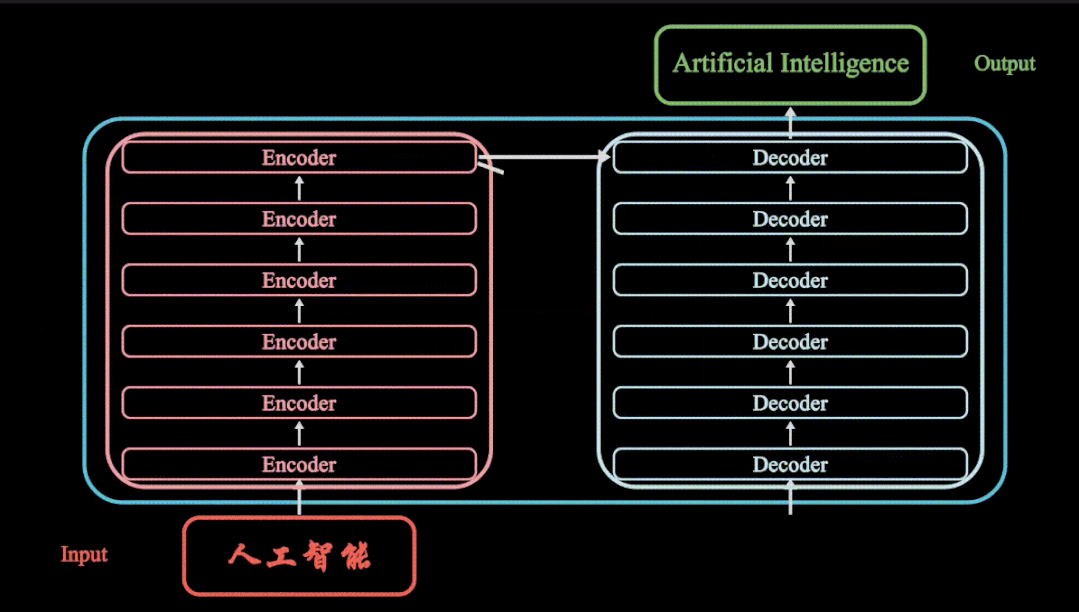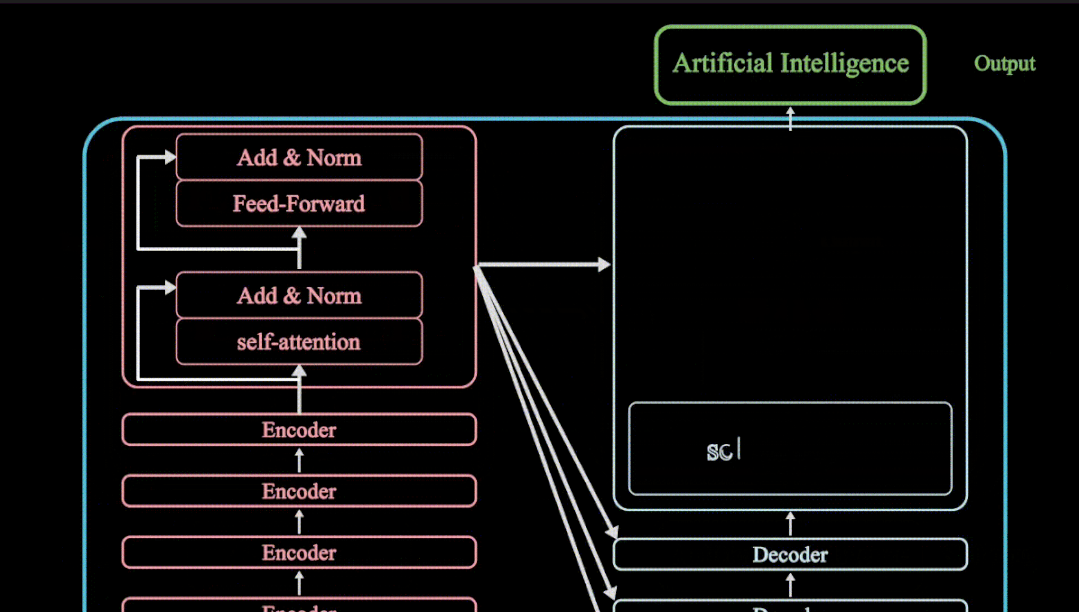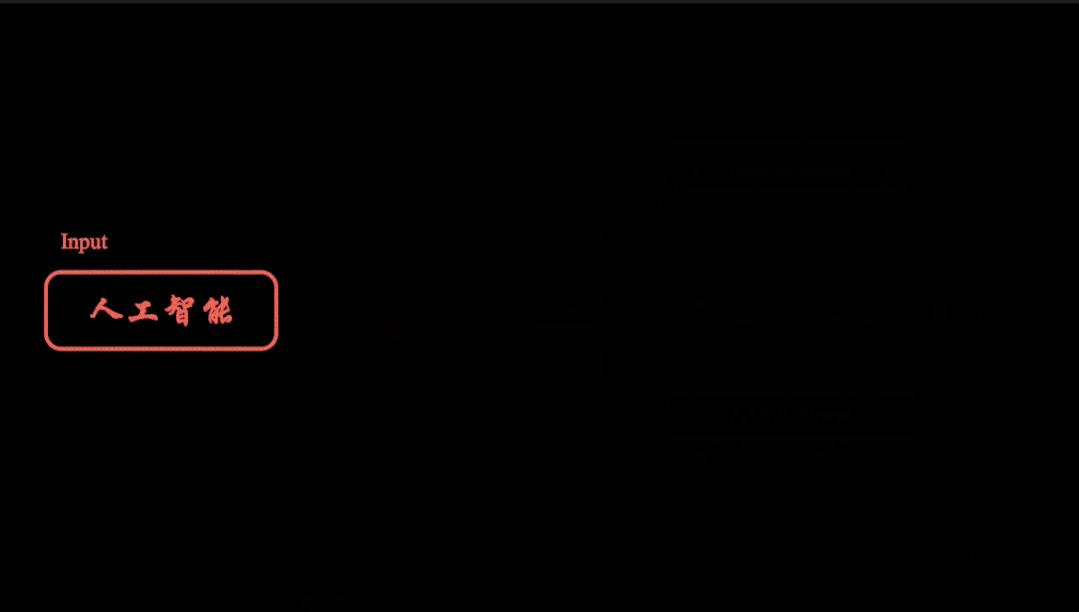
问题一:数据预处理------>剔除处理无效数据
转化完美成分数据----定和为1
中心化对数比变换------消除定和限制对后续分析的影响

类别量化分析相关性
第1小问------对超过20%的比例期望计数小于5的组别---------Pearson卡方检验法

对不满足卡方前提的组别-------->建立Yates校正卡方检验法
stats.chi2_contingency(data,correction=True)
第2小问----分析统计规律------
均值,最大值,最小值,标准差,变异系数,偏度系数,峰度系数
箱线图------多组连续型数据分布的散布范围及中心位置
第3小问----聚类使得数据呈现 时序关系
建立回归方程--------建立化学成分趋势变换模型
问题二
第1小问------监督学习------>决策树法

决策树算法的核心:如何选择最优划分属性。
精准率,召回率,准确率,F1系数

查准率=正确结果数/识别总数量
查全率=正确结果数/正确结果的总数

from sklearn.metrics import precision_score #引入精准率
from sklearn.metrics import confusion_matrix #引入混淆矩阵
from sklearn.metrics import classification_report #分类指标的文本报告
#precision精准度/查准率/准确率 recall召回率 f1-sorce F1系数 support为每个标签的出现次数
#avg / total行为各列的均值(support列为总和)
y_true = [1, 0, 1, 1, 0] #样本实际值
y_pred = [1, 0, 1, 0, 0] #模型预测值
res = precision_score(y_true,y_pred, average=None) #求查准率/准确率=TP / ( TP + FP )
res1 = confusion_matrix(y_true,y_pred) #得出混淆矩阵
res2 = classification_report(y_true,y_pred) #得到文本报告
print(res)
print(res1)
print(res2)
第2小问----亚类分类
R型聚类法得到----->特征变量------进行Q型聚类

Q型聚类(Qualitative Clustering),也称为硬聚类(Hard Clustering),属于一种将样本划分为簇的聚类方法。该方法的特点是每个样本只能划分到一个簇中,且每个簇之间没有交集。Q型聚类通常采用距离作为相似性度量标准,具体而言,根据不同的相似性度量标准可以分为以下几种:
1. K-Means聚类算法
K-Means聚类是一种基于质心的聚类算法,其过程如下:
首先随机选取k个点作为质心;
然后对于每个点,计算其到k个质心的距离,将该点归为距离最近的质心所在的簇;
接着重新计算每个簇的质心;
重复以上两步操作,直到质心不再发生变化或达到最大迭代次数。
K-Means聚类算法的优点是计算简单、速度较快,但其缺点是对初始质心的选择较为敏感,容易陷入局部最优解的问题。
2. 层次聚类算法
层次聚类算法是一种自底向上(Bottom-up)或自顶向下(Top-down)的聚类方法,其过程如下:
对于每个样本,将其视为一个独立的簇;
计算两两样本之间的相似度或距离,根据相似度或距离构建一个树形结构,即聚类树(Dendrogram);
不断合并聚类树中距离最小的两个簇,直至所有样本被合并为一个簇或达到某个预设的簇的数量。
层次聚类算法的优点是不需要事先确定聚类的数目,且可视化效果好,但其缺点是计算复杂度高,适用于样本量较小的情况。
问题三:决策树分类+Q型聚类法-----交叉检验
敏感度分析
问题四:建立灰色关联分析模型-----关联度值
成分数据

原数据/原数据之和
中心化对数比变换

量化处理
空缺数据处理
补0处理
卡方检验
卡方分析是一种利用样本数据的实际值与理论值的符合度来判断接受还是拒绝原假设的方法,常用于分析两个分类变量之间的相关性
1.期望计数
皮尔逊卡方
释然比
线性关联
2.Pearson卡方检验
本文对“ ”组采用Pearson卡方检验。检验步骤如下:
Step1)提出假设
原假设H0:相互独立不相关
备择假设H1:有关联。
Step2)构造卡方检验统计量x2
![]()
针对类型和表面风化的分析,如下:
分析流程
算法配置:
算法: Pearson卡方检验
变量: 分组变量X:{类型};变量Y:{表面风化}
分析结果:
Pearson卡方检验是分析两分类变量是否存在显著性差异:显著性P值为0.009***,水平上呈现显著性,拒绝原假设,因此类型和表面风化数据存在显著性差异。分析步骤
1. 根据列联表的数据情况,分析Pearson卡方检验是否呈现显著性(P<0.05,呈现显著性,拒绝原假设,则说明分类变量X与分类变量Y之间存在显著性差异)。
2. 若Pearson卡方检验呈现显著性,可接着根据效应指标对差异进行深入量化分析。详细结论
输出结果1:Pearson卡方检验结果
题目
名称
类型
合计
X²
P
铅钡
高钾
表面风化
1
12
12
24
6.88
0.009***
2
28
6
34
合计
40
18
58
注:***、**、*分别代表1%、5%、10%的显著性水平
图表说明:上表展示了Pearson卡方检验的结果,包括数据的频数、卡方值、显著性P值。
● 若P<0.05,呈现显著性,拒绝原假设,则说明分类变量X与分类变量Y之间存在显著性差异。
● 若P>0.05,不呈现显著性,不拒绝原假设,不存在显著性差异。
智能分析:Pearson卡方检验分析的结果显示,显著性P值为0.009***,水平上呈现显著性,拒绝原假设,因此类型和表面风化数据存在显著性差异。
输出结果2:交叉列联表热力图
图表说明:上图展示了热力图的形式展示了交叉列联表的值,主要通过颜色深浅去表示值的大小。
输出结果3:效应量化分析
字段名/分析项
Phi
Crammer‘s V
列联系数
lambda
表面风化-类型
0.344
0.344
0.326
0.25
图表说明:上表展示了效应量化分析的结果,包括phi、Crammer's V、列联系数、lambda ,用于分析样本的相关程度。
1. 当呈现出显著性差异(前提),结合分析效应量指标对差异性进行量化分析。
2. 效应量化指标反映的是变量之间的相关程度。
3. 根据交叉类型的不同,可以选用不同的效应量指标(交叉类型表示:交叉表横向格子数×纵向格子数)。
4. phi系数:phi相关系数的大小,表示两样本之间的关联程度。当phi系数小于0.3时,表示相关较弱;当phi系数大于0.6时,表示相关较强(用于2×2交叉类型表)。
5. Cramer's V:与phi系数作用相似,但Cramer's V系数的作用范围较广。当两个变量相互独立时,V=0,当数据中只有2个二分类变量时,Cramer's V系数的结果与phi相同(若m≠n,建议使用Cramer's V )。
6. 列联系数:简称C系数,用于3×3或4×4交叉表,但其受行列数的影响,随着R和C 的增大而增大。因此根据不同的行列和计算的列联系数不便于比较,除非两个列联表中行数和列数一致。
7. lambda:用于反应自变量对因变量的预测效果,一般情况下,其值为1时表示自变量预测因变量效果较好,为0时表明自变量预测因变量较差(X或Y有定序数据时,建议使用lambda)。智能分析:
效应量化分析的结果显示,分析项:表面风化Cramer's V值为0.344,因此类型和表面风化的差异程度为中等程度差异。
参考文献
[1] Scientific Platform Serving for Statistics Professional 2021. SPSSPRO. (Version 1.0.11)[Online Application Software]. Retrieved from https://www.spsspro.com.
[2] 陆运清. 用 Pearson's 卡方统计量进行统计检验时应注意的问题[J]. 统计与决策, 2009 (15): 32-33.

3.Yates校正卡方检验
![]()
针对问题一第二小问
描述统计量
(1)变异系数

(2)偏度系数


(3)峰度系数

Excel快捷处理:

通过计算结果可知:偏度系数小(大)于零,说明落在均值左(右)侧的数据均偏多; 成分指标的峰度系数大(小)于零说明指标分布相比于正态分布顶部更加尖锐(平坦)或者尾部更加粗(细)
箱线图
箱线图可反映多组连续性数据分布的散布范围以及中心位置,其中连续性变量为在一定区间范围内可随意取值的变量,且箱线图中箱子的宽度在一定程度上可以反映样本数据的波动程度,因此本文通过箱线图来统计各个化学成分指标的数据值分布特征。
箱线图绘图步骤如下:
Step1)对N个样本数据X1,X2 ,...,Xn由小到大排序
Step2)根据排序后的样本数据,找出其中位数X 。中位数为箱子中间的一条线,可反映整体数据分布的平均水平。
Step3)分别计算上四分数Q1和下四分数Q2
Step4)计算向箱体的长度Q1-Q2
Step5)分别计算出上限及下限。其中箱子的下限为下四分位数,上限为上四分位数。
Step6)绘制出上下限,须触线,箱体,并标明上下四分数以及中位数,最后绘出箱线图。
超过箱子上下方的数据为异常值数据
针对问题一第三小问
聚类-----时序关系
确定风化点
(1)Q型聚类分析
Q型聚类采用离差平方和法,若分类效果好,则同类文物采样点的离差平方和应当较小,各类别之间的离差平方和应当较大。


(2)2类聚类
风化点+非风化点筛选
建立时序关系
高钾玻璃时序------时段:未风化、轻度风化、中度风化、严重风化
铅钡玻璃时序------时段:未风化、轻度风化、中度风化、严重风化
基于中心化对数比变换的成分数据预测建模
(1)提取中心元素
平均数是统计学中最常用的统计量,可以用以表明数据的相对集中较多的中心位置,即反映了现象总体的集中趋势
(2)回归方程
拟合算法步骤(重点)
①确认拟合曲线的类型:曲线要满足一定的趋势同时尽可能简单。
②使用最小二乘法求出使得曲线误差最小时对应的曲线参数。该步骤可以通过Matlab中的曲线拟合工具箱进行实现,并导出所绘制的曲线图。
拟合优度R2


(3)预测风化点未风化时的化学含量方法
假设回归方程------对拟合曲线平移-----反向预测出未分化前数据
(4)中心化对数比逆变换

使预测值v1,v2,...,vp转化成相应的成分数据x1,x2,....,xp
-
预测结果
-
结果分析与验证
在主观分析层面
在客观分析层面
-
问题二模型的建立与求解
针对问题二第一小问
根据题目分析应对策略,考虑全面周到
决策树
决策树是一种用于数据分类的方法,它有如流程图一样的树状结构,其中每个内部节点表示在一个属性上的测试,每一个分支节点表示一个测试输出,每个叶子节点表示一类或者类分布。决策树本质是一种自顶向下的逐步构造方法,它在构造的过程中一般采用信息增益度量。信息增益最大表明了数据集在分类过程中能够最大化减小其不确定性,因此ID3在构建算法的过程中所挑选的特征具有更好的分类效果。信息熵(H)以及信息增益(G)可定义如下:
![]()
![]()
![]()
其中P表示随机变量的概率,A表示特征,D代表数据集,H(D)定义为经验熵, H(Y|X)定义为条件熵,H(D|A)表示特征A在数据集D的条件下的经验条件熵。
决策树分类结果
(1)针对未风化点数据
针对特定数据集,取70%数据为训练集,30%数据为测试集
-
针对风化点数据
R型聚类分析
相似度量
-
相关系数
两变量xj和xk的样本相关系数作为他们的相似性度量

-
相关系数矩阵求解
皮尔逊相关系数矩阵
相关系数-----度量变量间的相似性
-
最短距离法

(4)R型聚类分析结果
(5)Q型聚类分析结果
针对问题二第三小问
合理性假设
划分亚类------R型聚类----了解个别变量之间的关系的亲疏程度,也可以了解各个变量组合之间的亲疏程度
敏感性分析
敏感性分析需要从定量分析的角度研究有关因素发生某种变化对某一个或一组关键指标影响程度的一种不确定分析技术。
扰动范围
-
问题三模型的建立与求解
针对问题三第一小问
鉴别属性
决策树分类
交叉验证
Q型聚类方法
针对问题三第二小问
敏感性分析
-
问题四模型的建立与求解
针对问题四第一小问
灰色关联分析
对于两个系统之间的因素,其随时间或不同对象而变化的关联性大小的量度,称为关联度。在系统发展过程中,若两个因素变化的趋势具有一致性,即同步变化程度较高,即可谓二者关联程度较高;反之,则较低。因此,灰色关联分析方法,是根据因素之间发展趋势的相似或相异程度,亦即“灰色关联度”,作为衡量因素间关联程度的一种方法。
通常可以运用此方法来分析各个因素对于结果的影响程度,也可以运用此方法解决随时间变化的综合评价类问题。



模型的求解:
由于关联度值介于区间[0,1]上,且关联度值越大表示与母序列的相关性越强,关联度越高,意味着子序列与母序列之间的关联性越高,反之越低