分享语义分割领域的一篇经典论文DeepLabv3,由谷歌发表于CVPR2017。开源代码地址:
- Tensorflow版本:https://github.com/tensorflow/models/tree/master/research/deeplab
- Pytorch版本:https://github.com/open-mmlab/mmsegmentation/tree/master/configs/deeplabv3

1.动机
在使用CNN处理图像分割任务时,有2个难点:
(1)若使用连续的池化操作或步长大于1的卷积操作来提取全局上下文特征,会丢失细节信息,从而影响图像分割效果。
(2)如何对不同尺寸的目标提取特征。
作者指出,使用空洞卷积能有效地解决上述2个问题。在使用空洞卷积时,作者增加了一些工程上的优化,并且对空洞卷积的串行、并行结构进行了实验,提出了DeepLabv3网络用于语义分割任务。
2.使用空洞卷积提取特征
空洞卷积的计算示意图如下:

空洞卷积相当于对卷积核进行上采样操作,用rate控制上采样率,rate=1时的空洞卷积是普通卷积。通过控制rated的值,可以控制卷积操作的感受野。
空洞卷积并不增加可学习参数的情况,因此,使用空洞卷积时,仍然可以使用原始模型在ImageNet数据集上的预训练权重。
**定义output_stride为网络输入图像尺寸与输出feature map尺寸的比值。**在用于分类任务的CNN中,全连接层或全局池化层之前的feature map尺寸一般为输入图像尺寸的1/32,因此output_stirde=32。
若想让网络输出的feature map的output_stride=16,可以将原网络中最后一个下采样操作(比如池化或者步长为2的卷积)的步长设置为1,然后将后续的卷积替换为rate=2的空洞卷积。这样既可以让网络有比较大的输出feature map,还能保证足够大的感受野,同时仍可复用原模型中的权重。
3.空洞卷积的串联

复制多次ResNet中的block4,将它们串联的网络后面,如图2(a)所示。在该结构中,每个block有3个 3 × 3 3 \times 3 3×3卷积,除末尾的block以外,每个block中最后1个卷积的步长为2,这样的网络结构能够增加感受野,将整张图像的信息总结为尺寸很小的feature map。这种结构的缺点是丢失了细节信息。
在图2(b)中,作者使用了空洞卷积,用空洞卷积来补偿不使用下采样导致的无法提取全局特征的问题。从Block3以后,每当需要进行一次下采样操作时,均通过让rate变为原来2倍的空洞卷积代替下采样操作。
Multi-Grid空洞卷积Block 为了进一步增加感受野,作者引入了Multi-Grid的概念。定义 Multi_Grid = ( r 1 , r 2 , r 3 ) \text { Multi\_Grid }=\left(r_1, r_2, r_3\right) Multi_Grid =(r1,r2,r3)为unit rate,每个Block中3个空洞卷积的rate为图2(b)中的rate值与Multi_Grid相乘。比如:若 Multi_Grid = ( 1 , 2 , 4 ) \text { Multi\_Grid }=\left(1, 2, 4\right) Multi_Grid =(1,2,4),对于上图Block4中的3个卷积操作,rate分别为 2 ⋅ ( 1 , 2 , 4 ) = ( 2 , 4 , 8 ) 2 \cdot(1,2,4)=(2,4,8) 2⋅(1,2,4)=(2,4,8)。
4.空洞卷积的并联
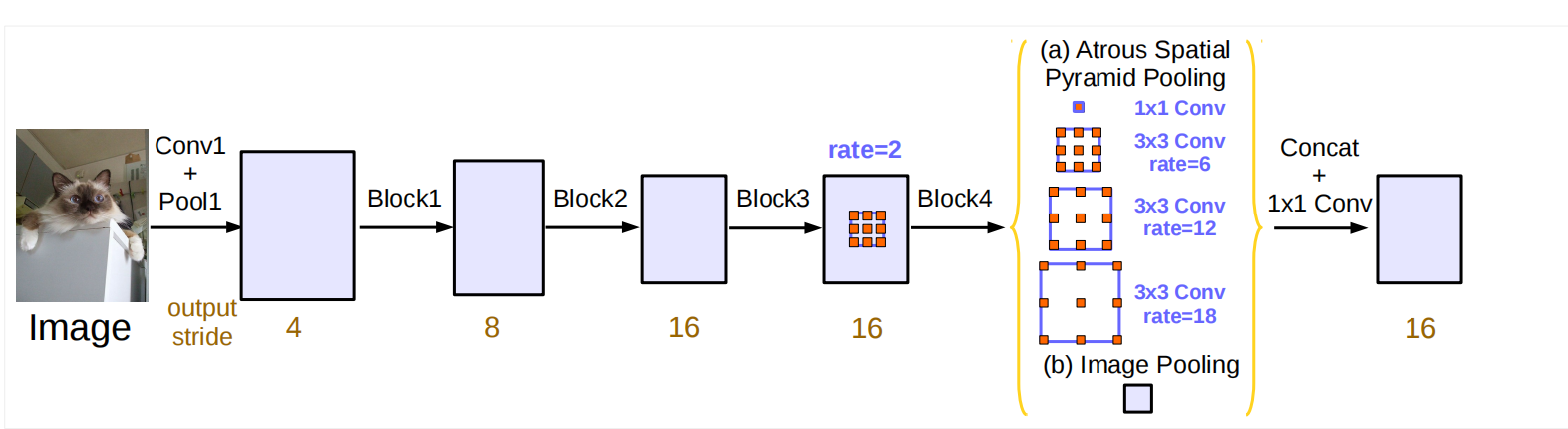
空洞卷积的并联结构(Atrous Spatial Pyramid Pooling,简称ASPP)是由论文《Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs》提出的。ASPP可以提取多个尺度的特征,以提高图像分割性能。
若想要进一步提取图像的全局上下文特征,不断增加空洞卷积的rate是不可取的,当rate很大时,会导致相当一部分权重作用于feature map的padding区域,这样降低了特征提取的效率。因此作者在原始ASPP的基础上,增加了1个额外的global average pooling(全局平均池化)操作,global average pooling的输出经过256通道的 1 × 1 1 \times 1 1×1卷积和BN操作,将输出的feature map上采样至合适的尺寸,便于与ASPP中其他空洞卷积输出的feature map进行concat操作。
如图3所示,ASPP包含如下结构:
(1)1个 1 × 1 1 \times 1 1×1卷积和3个 3 × 3 3 \times 3 3×3的空洞卷积,rate的值分别是 ( 6 , 12 , 18 ) (6,12,18) (6,12,18);
(2)global average pooling提取全局特征
ASPP的所有分支的输出feature map先进行concat,然后经过 1 × 1 1 \times 1 1×1卷积和BN操作,最后再经过1个 1 × 1 1 \times 1 1×1卷积输出分割结果。
此外,相比于原始的ASPP,作者在ASPP的卷积中加入了BN结构,以提高网络的分割性能。
5.实验结果
5.1 训练
以下为作者在PASCAL VOC2012分割数据集上的训练设置。
网络结构 以在ImageNet数据集上预训练过的ResNet为基础,增加额外的Block并使用空洞卷积。
学习率设置 使用poly学习率衰减策略,每次迭代的学习率是初始学习率乘以 ( 1 − iter max_iter ) power \left(1-\frac{\text { iter }}{\text { max\_iter }}\right)^{\text {power }} (1− max_iter iter )power ,power的值为0.9。
BN的学习 为了提高BN中参数的学习效果,需要令batch size大一些,因此刚开始训练时,令output_stride=16,减少网络的显存占用,以提高训练的batch size,这里batch size为16。当训练完30K次迭代后,固定BN的参数,令output_stride=8,此时网络中某些feature map的尺寸会大一些,因此会占用更多的显存。之所以要使用output_stride=8继续训练,是因为若使用output_stride=16一直训练,会导致网络的输出比较粗糙,会降低分割性能。需要特别指出的是,output_stride值为16到8的切换,是通过用空洞卷积代替下采样操作实现的,而空洞卷积只是在普通卷积的卷积核中增加0,因此仍然可以复用普通卷积的可学习参数,不会引入额外的可学习参数。
上采样网络输出 当output_stride=8时,上采样网络的输出结果,使其与ground truth的尺寸一致,然后再计算损失,这样可以最大限度地保留ground turth的细节;而不是对ground truth下采样使其与网络输出结果尺寸一致。
数据增强 在训练时使用了随机缩放、水平随机翻转进行数据增强。
5.2 结果
串联结构在PASCAL VOC2012验证集上的结果如下图所示(在训练时令output_stride=16)

并联结构在PASCAL VOC2012验证集上的结果如下图所示(在训练时令output_stride=16)

在OS=8且使用MS和Flip时,并联结构的性能(79.77%)高于串联结构(79.35%),因此作者使用并联结构与其他语义分割算法对比。
在训练时先令output_stride=16,然后改变output_stride的值为8,针对困难样本使用了bootstrapping方法,在PASCAL VOC2012测试集上的结果如下图所示。图中的DeepLabv3-JFT表示使用了ImageNet和JFT-300M这2个数据集的预训练权重。

关于实验设置细节、消融实验以及在其他数据集测试的详细内容,请参考原文。
如果你对计算机视觉领域的目标检测、跟踪、分割、轻量化神经网络、Transformer、3D视觉感知、人体姿态估计兴趣,欢迎关注公众号一起学习交流~

欢迎关注我的个人主页,这里沉淀了计算机视觉多个领域的知识:https://www.yuque.com/cv_51