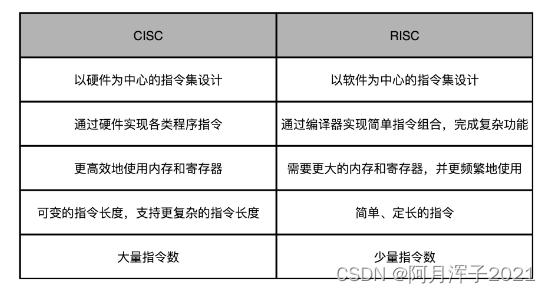
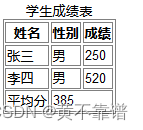
1 基本概念
过度拟合(overfit)
正则化(regularization)
L1正则化(L1 regularization)
L2正则化(L2 regularization)
删除正则化(dropout regularization)
提早停止(early stopping)
离群值
2 过拟合与欠拟合
安装工具
Higgs数据集
演示过度拟合
训练过程
构建细模型(Tiny model)
构建小模型(Small model)
构建中模型(Medium model)
构建大模型(Large model)
分析模型
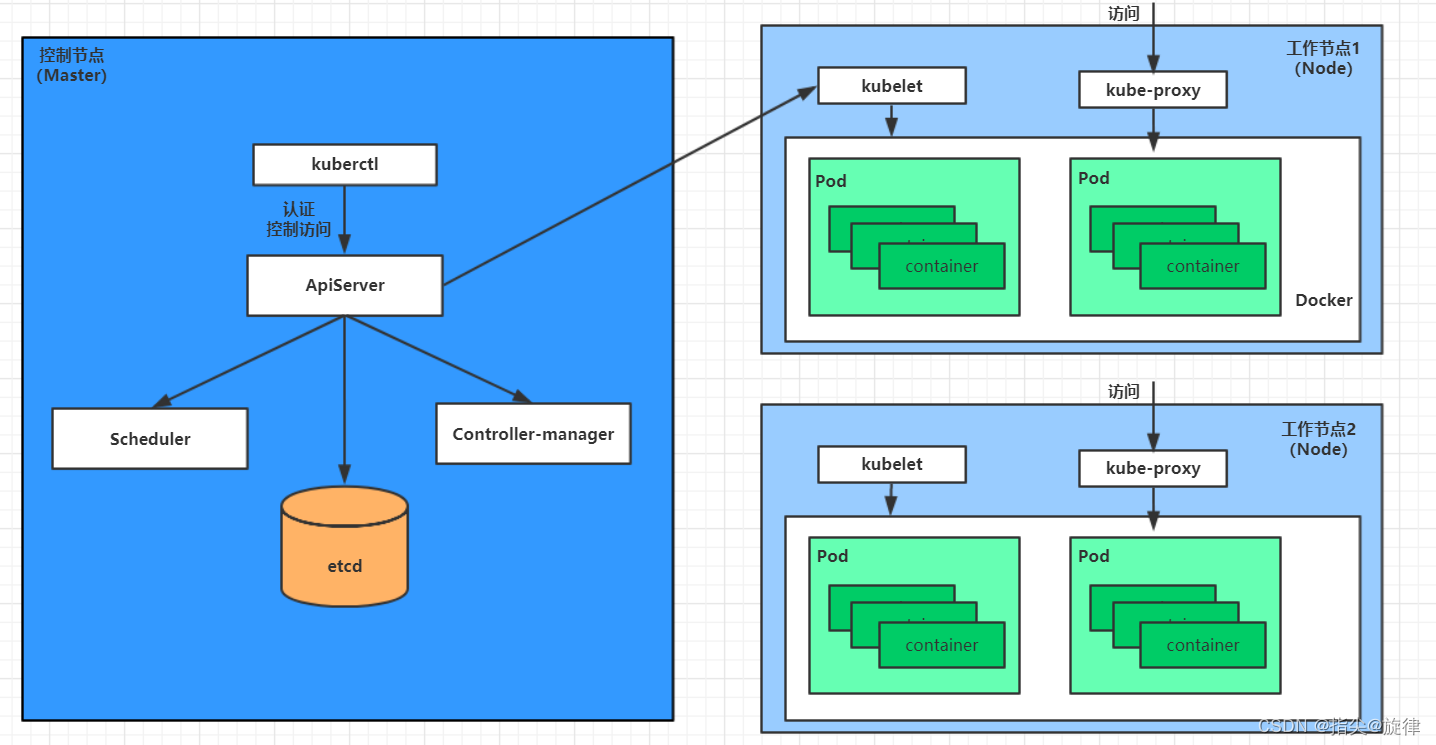
如上所示,使用图形统计分析的方式体现以上构建的细模型、小模型、中模型以及大模型的训练数据集以及验证数据集的损失值随着迭代次数的变化。其中,实线表示训练数据集的损失值,虚线表示验证数据集的损失值。
由前面定义的编译以及训练模型的函数可知,以上所有的模型都是使用callbacks.EarlyStopping的方式进行正则化的处理,在模型训练的损失值不能再优化的时候结束训练数据的迭代。
虽然构建一个大模型用于机器学习能获得更大容积能力,但是如果容积能力没有被权衡与约束,则很容易发生过度拟合训练数据的情况。
细模型的训练损失值以及验证损失值的拟合过程几乎相同,而大模型的训练损失值与验证损失值的拟合过程的速度非常快,很明显大模型的训练效果是过度拟合。
根据图形的显示分析,训练损失值与验证损失值的拟合的过程具有以下的特点:
|
防止过度拟合的策略
如上所示,使用正则化防止过度拟合的操作之前,基线化细模型的训练日志文件。其中,regularizer_histories定义用于正则化细模型。
增加权重正则化
在某些事实中,给定对某件事情的两种解释,则简单的解释似乎是最合理的解释,因为,简单的解释包含简单的逻辑或者假想。这些事实也可以运用到神经网络模型的学习中,假设,给定一些用于训练的数据样本以及一个网络架构,以及各种不同的权重集用于解释这些训练数据,则模型越简单出现过度拟合的可能性越低。
简单模型是指参数较少的模型(参数值的分布属于低熵),减轻过度拟合的通常做法是减少权重值(权重值较小),从而使得权重值的分布更加正则,从而降低网络模型的复杂度,这种方式被称之为权重正则化,其实现方式是给损失函数值增加一个与高权重相关的损耗,其包括如下两种方式:
|
正如前面所述,L1正则化机制将一些权重设置为0,从而使得训练的特征矩阵变得稀疏,而L2正则化机制将一些权重设置为接近于0但是不等于0,并没有使得训练的特征矩阵变稀疏,因此,L2正则化机制更加常用。
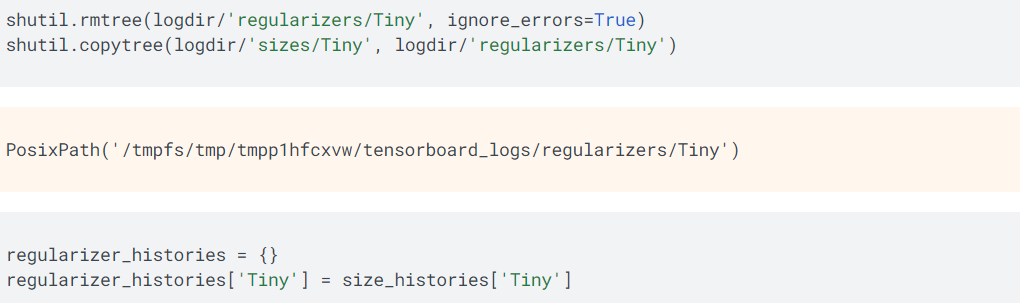
如上所示,l2(0.001)使用L2正则化机制,其计算方式是将0.001 * (weight_coefficient_value的平方)的值增加到网络的总损失值,其中,weight_coefficient_value是权重值。
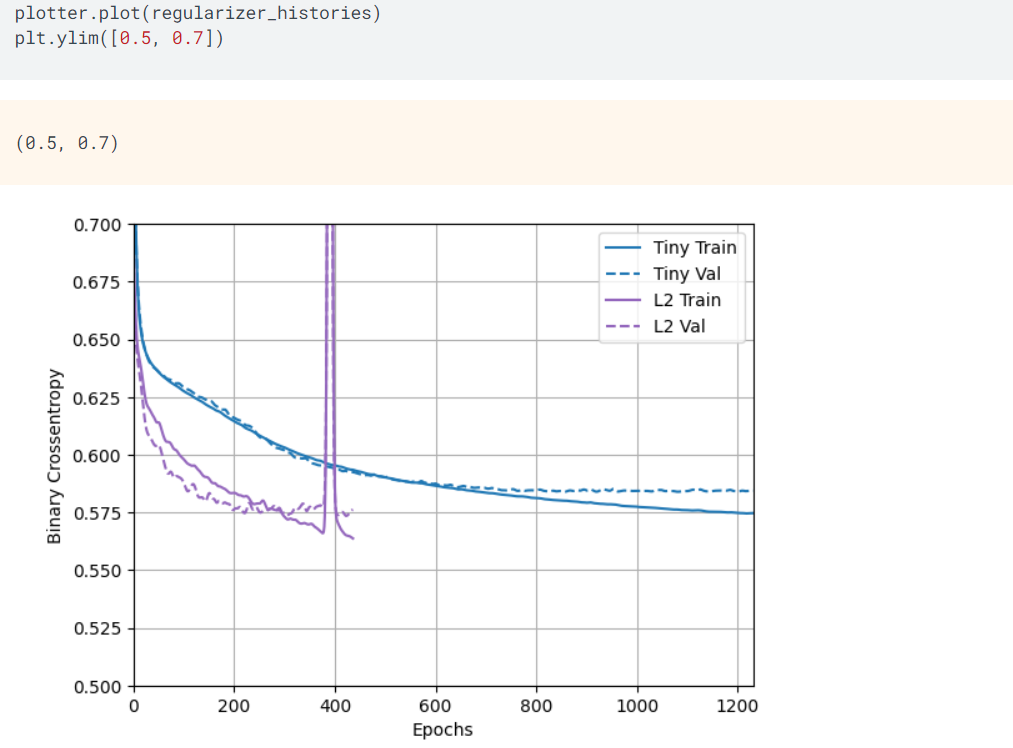
如上所示,使用图形的方式体现细模型与大模型在每次迭代训练中的二元分类交叉嫡的关系,其中,L2 Train是大模型训练数据的L2正则化,L2 Val是大模型验证数据的L2正则化,Tiny Train是细模型训练数据,Tiny Val是细模型验证数据,从图形中可知,L2大模型正则化机制表现得更快更好。
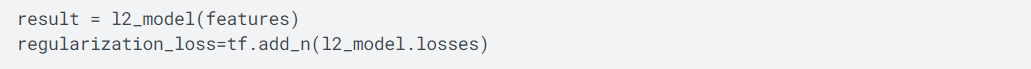
如上所示,从前面构建的L2正则化大模型中获取损失值。
增加删除正则化
删除正则化机制在神经网络中是一种非常高效以及最常用的正则化技术。其随机删除特征集合中的特征值,例如,对于特征集[0.2, 0.5, 1.3, 0.8, 1.1],使用删除正则化机制随机删除一部分特征之后,变成[0, 0.5, 1.3, 0, 1.1],其中,0.2以及0.8的特征值被删除,其选择常用的因子是0.2或者0.5(删除的比例)。
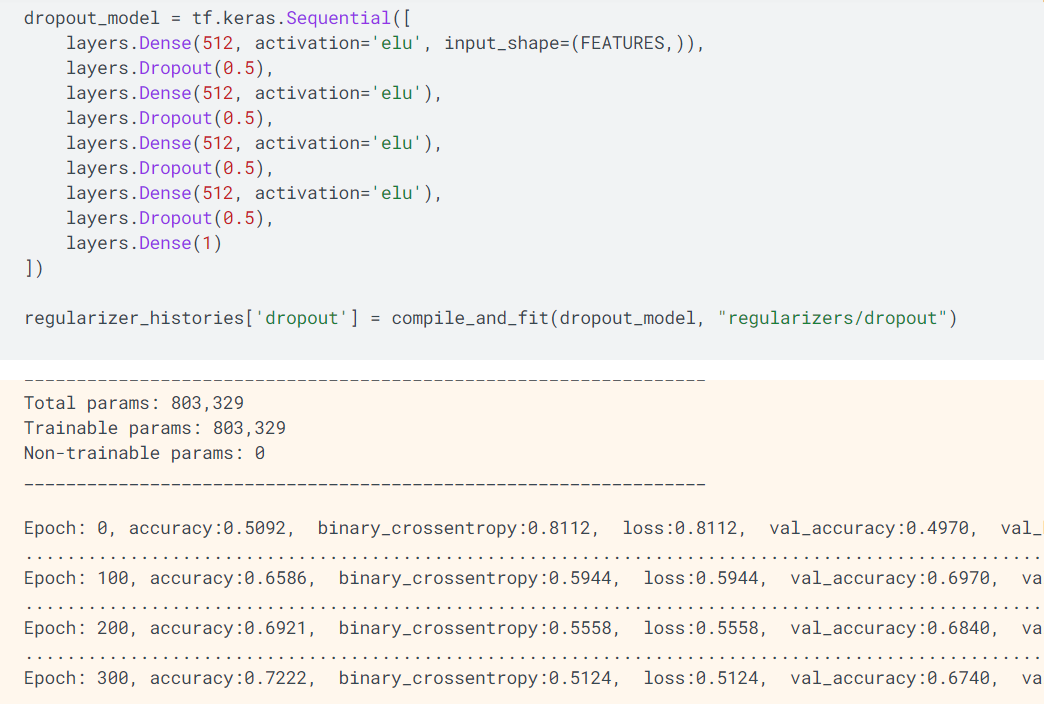
如上所示,对大模型的每层设置删除正则化,其中,Dropout(0.5)表示其随机选择的因子是0.5,该模型设置4个全连接层、每层设置512个处理单元。

如上所示,L2正则化机制以及删除正则化机制都改善了大模型的训练效率以及训练效果,但是,总体上,还是细模型的训练效果最好。
L2与删除正则化机制的组合
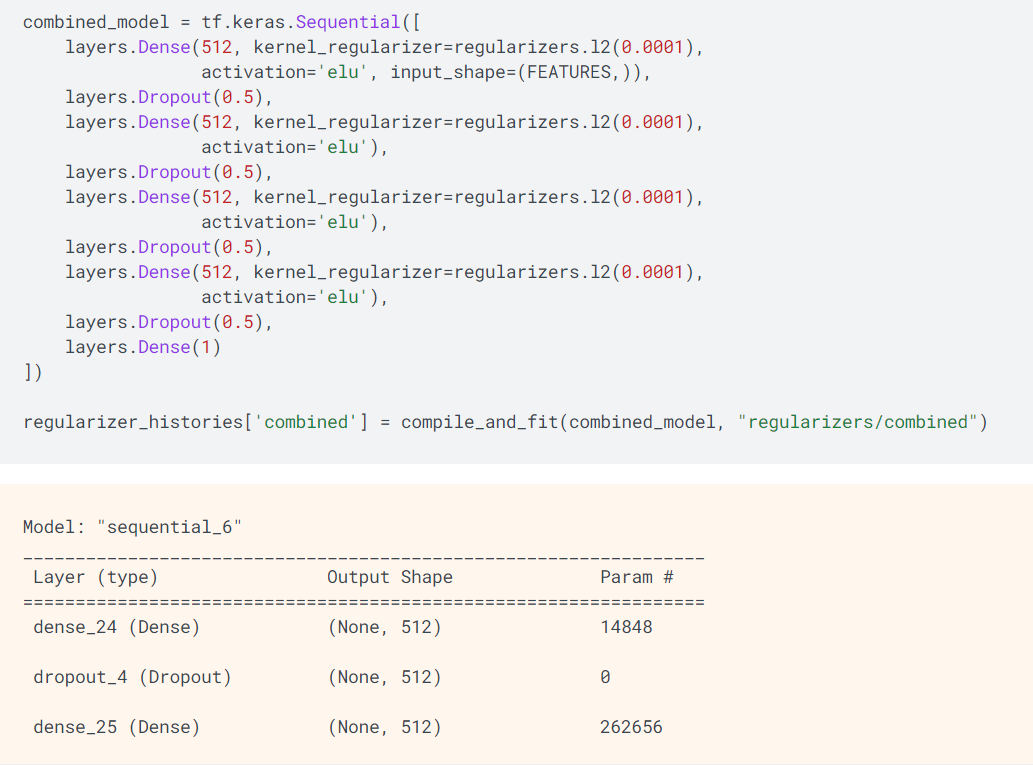
如上所示,综合使用L2正则化机制与删除正则化机制构建大模型。
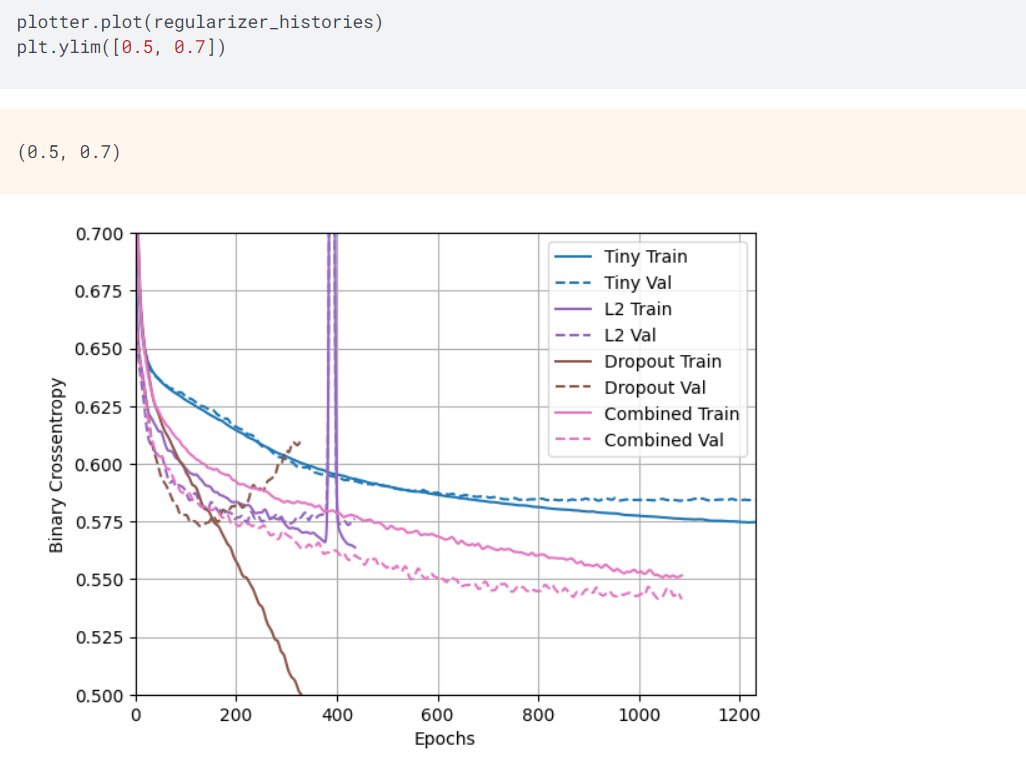
如上所示,综合L2与删除正则化机制的大模型获得最好的训练效果,其中,Tiny Train是细模型训练数据,Tiny Val是细模型验证数据,L2 Train是L2正则化的大模型训练数据,L2 Val是L2正则化的大模型验证数据,Dropout Train是删除正则化的大模型训练数据,Dropout Val是删除正则化的大模型验证数据,Combined Train是综合正则化的大模型训练数据,Combined Val是综合正则化的大模型验证数据。
(未完待续)