https://rocketmq.apache.org/zh/docs/deploymentOperations/16autoswitchdeploy/
https://github.com/apache/rocketmq/blob/develop/docs/cn/controller/design.md
controller 端
leader选举
主备自动切换模式就是controller模式,controller可以嵌入name server,也可以独立部署,嵌入name server需要在name server开启如下配置:
enableControllerInNamesrv = true #在name server开启controller模式
controllerDLegerGroup = group1 #对应dLedgerConfig.group
controllerDLegerPeers = n0-127.0.0.1:9877;n1-127.0.0.1:9878;n2-127.0.0.1:9879 #对应dLedgerConfig.peers
controllerDLegerSelfId = n0 #对应dLedgerConfig.selfId
controllerStorePath = /home/admin/DledgerController #对应dLedgerConfig.storeBaseDir
enableElectUncleanMaster = false #当syncStateSet中的broker都不可用时,是否允许其它数据同步较慢的broker参与master选举,默认false
notifyBrokerRoleChanged = true
enableControllerInNamesrv开启后,NamesrvStartup#controllerManagerMain中会创建、初始化、启动ControllerManager,上面的配置会读取到ControllerConfig,初始化ControllerManager时,会创建DLedgerController,它将ControllerConfig的配置转成DLedgerConfig配置,再根据DLedgerConfig创建DLedgerServer,从而复用DLedger集群的选举和日志同步模块。嵌入了controller的name server需要至少3台,它们是DLedger集群,会选出一个leader

public DLedgerController(final ControllerConfig controllerConfig,
final BiPredicate<String, String> brokerAlivePredicate, final NettyServerConfig nettyServerConfig,
final NettyClientConfig nettyClientConfig, final ChannelEventListener channelEventListener,
final ElectPolicy electPolicy) {
this.controllerConfig = controllerConfig;
this.dLedgerConfig = new DLedgerConfig();
//controllerConfig转成dLedgerConfig
this.dLedgerConfig.setGroup(controllerConfig.getControllerDLegerGroup());
this.dLedgerConfig.setPeers(controllerConfig.getControllerDLegerPeers());
this.dLedgerConfig.setSelfId(controllerConfig.getControllerDLegerSelfId());
this.dLedgerConfig.setStoreBaseDir(controllerConfig.getControllerStorePath());
this.dLedgerConfig.setMappedFileSizeForEntryData(controllerConfig.getMappedFileSize());
// Register statemachine and role handler.
//dLedgerServer包含了选举模块DLedgerLeaderElector,启动时触发选举
this.dLedgerServer = new DLedgerServer(dLedgerConfig, nettyServerConfig, nettyClientConfig, channelEventListener);
...
}
请求处理
ControllerManager#registerProcessor:额外向DLedgerServer注册了请求处理器ControllerRequestProcessor,实现对broker请求的处理
DLedgerController
处理的请求中除了心跳,都由DLedgerController处理,请求分为2类:读和写,都会创建事件处理器ControllerEventHandler并添加到事件队列eventQueue中,由一个单独的线程执行事件队列中事件处理器的run方法,单个线程依此按顺序处理所有的事件,从而确保上一步执行成功才能进行下一步,读写事件都会先获取ControllerResult,不同的是,读事件获取到结果后直接返回给客户端broker,而写事件获取到结果后,需要ControllerResult结果中的事件对象过半写入集群日志,并且提交后,再返回响应给客户端。
提交:只确保leader一定会在响应之前执行提交逻辑,follower同步到最新日志时执行提交逻辑,选举时,新当选的leader一定具有所有已提交的日志,并且会在当选时提交一条空日志来确保提交。这里的提交逻辑是:根据事件对象的类型执行不同逻辑(ReplicasInfoManager#applyEvent)

public class DLedgerController implements Controller {
@Override
public CompletableFuture<RemotingCommand> registerBroker(RegisterBrokerToControllerRequestHeader request) {
//向事件队列追加事件处理器
return this.scheduler.appendEvent("registerBroker", () -> this.replicasInfoManager.registerBroker(request)/*supplier*/, true/*写事件*/);
}
class EventScheduler extends ServiceThread {
public <T> CompletableFuture<RemotingCommand> appendEvent(final String name,
final Supplier<ControllerResult<T>> supplier, boolean isWriteEvent) {
//向事件队列追加事件处理器
final EventHandler<T> event = new ControllerEventHandler<>(name, supplier, isWriteEvent);
this.eventQueue.offer(event, 5, TimeUnit.SECONDS);
}
@Override
public void run() {
while (!isStopped()) {
EventHandler handler;
//轮询事件队列执行事件处理器
handler = this.eventQueue.poll(5, TimeUnit.SECONDS);
handler.run();
}
}
}
class ControllerEventHandler<T> implements EventHandler<T> {
@Override
public void run() throws Throwable {
final ControllerResult<T> result = this.supplier.get();
boolean appendSuccess = true;
if (!this.isWriteEvent || result.getEvents() == null || result.getEvents().isEmpty()) {
//为读事件,或没有事件对象时,直接将ControllerResult返回给客户端
}else{
//写事件
final List<EventMessage> events = result.getEvents();
...
final BatchAppendEntryRequest request = new BatchAppendEntryRequest();
request.setBatchMsgs(eventBytes);
//等待事件对象写入过半集群日志,并提交
appendSuccess = appendToDLedgerAndWait(request);
}
if (appendSuccess) {
//给客户端返回响应,最终返回的是ControllerResult.response
final RemotingCommand response = RemotingCommand.createResponseCommandWithHeader(result.getResponseCode(), (CommandCustomHeader) result.getResponse());...
}
...
}
}
}
//ReplicasInfoManager
//状态机提交时,如果日志为EventMessage类型,则根据事件类型执行不同提交逻辑
public void applyEvent(final EventMessage event) {
final EventType type = event.getEventType();
switch (type) {
case ALTER_SYNC_STATE_SET_EVENT:
handleAlterSyncStateSet((AlterSyncStateSetEvent) event);
break;
case APPLY_BROKER_ID_EVENT:
handleApplyBrokerId((ApplyBrokerIdEvent) event);
break;
case ELECT_MASTER_EVENT:
handleElectMaster((ElectMasterEvent) event);
break;
case CLEAN_BROKER_DATA_EVENT:
handleCleanBrokerDataEvent((CleanBrokerDataEvent) event);
break;
default:
break;
}
}
小结
- 2个关键逻辑:DLedgerController处理请求时,实际上是先执行supplier.get获取ControllerResult,然后根据其中的事件对象类型执行ReplicasInfoManager.applyEvent,只需要关注这2个逻辑,这2个逻辑都在ReplicasInfoManager中,因此可以看出真正处理请求的是ReplicasInfoManager
- 顺序性和原子性:2个关键逻辑的执行是原子的,并且按照请求的先后顺序执行,虽然提交是在另一个QuorumAckChecker线程执行的,但EventScheduler线程会等待它执行完提交逻辑后,再处理下一个请求
- 返回给客户端的是ControllerResult的response,body
注册broker
ReplicasInfoManager#registerBroker
ReplicasInfoManager#handleElectMaster
ReplicasInfoManager#handleApplyBrokerId
- 如果brokerName之前没注册过:注册broker()时,第一个注册的broker选举为master,masterEpoch和syncStateSetEpoch初始值是1,master brokerId是0,提交时,会将brokerName对应的所有broker的id和地址、master地址保存到内存状态机中(syncStateSetInfoTable和replicaInfoTable),后面注册的broker是slave,brokerid从2开始,将master地址、生成的brokerId、masterEpoch、syncStateSetEpoch返回给broker
- broker一旦注册,replicaInfoTable、BrokerInfo、syncStateSetInfoTable不会随着broker的上下线动态变化,broker重启,brokerId不变,如果broker地址变了,需要通过运维命令CleanControllerBrokerData来清理旧地址。SyncStateInfo中的master地址、syncStateSet在master选举和修改syncStateSet时会动态变化。
- 如果broker已经注册了并且master存在,则直接返回broker id和master地址,broker端变为slave;如果broker已经注册了但是master不存在,则判断broker是否在syncStateSet中,存在则当选新master,否则返回注册失败CONTROLLER_REGISTER_BROKER_FAILED(因为默认只有syncStateSet中的节点能够当选master)
- 注册成功后,还会向heartbeatManager中注册心跳信息,以便broker后续更新心跳时间戳、epoch、最大偏移量
public class ReplicasInfoManager {
//broker集群的每个节点信息,每个brokerName表示1主多从
private final Map<String/* brokerName */, BrokerInfo> replicaInfoTable;
private final Map<String/* brokerName */, SyncStateInfo> syncStateSetInfoTable;
}
public class BrokerInfo {
// broker id生成器,从1开始
private final AtomicLong brokerIdCount;
//brokerId这里master是1,但broker端master是0,broker端和controller的slave从2开始
private final HashMap<String/*broker地址*/, Long/*brokerId*/> brokerIdTable;
}
public class SyncStateInfo {
//已经同步上的broker地址,包括master,master刚切换时只有master地址,
private Set<String/*Address*/> syncStateSet;
private int syncStateSetEpoch;
private String masterAddress;
private int masterEpoch;
}
//ReplicasInfoManager
public ControllerResult<RegisterBrokerToControllerResponseHeader> registerBroker(
final RegisterBrokerToControllerRequestHeader request) {
...
boolean canBeElectedAsMaster;
if (isContainsBroker(brokerName)) {
//broker对应的brokerName注册后,只要没有手动执行运维命令CleanControllerBrokerData,brokerName一定存在
final SyncStateInfo syncStateInfo = this.syncStateSetInfoTable.get(brokerName);
final BrokerInfo brokerInfo = this.replicaInfoTable.get(brokerName);
// 获取brokerId
long brokerId;
if (!brokerInfo.isBrokerExist(brokerAddress)) {
//broker第一次注册,分配brokerId,并且通过ApplyBrokerIdEvent事件将broker地址和id保存起来
brokerId = brokerInfo.newBrokerId();
final ApplyBrokerIdEvent applyIdEvent = new ApplyBrokerIdEvent(request.getBrokerName(), brokerAddress, brokerId);
result.addEvent(applyIdEvent);
} else {
//broker已经注册,只要没有手动执行运维命令CleanControllerBrokerData,就算broker重启,那么brokerId仍然不变
brokerId = brokerInfo.getBrokerId(brokerAddress);
}
...
if (syncStateInfo.isMasterExist()) {
//master存在,这里注册broker是slave
final String masterAddress = syncStateInfo.getMasterAddress();
response.setMasterAddress(masterAddress);
return result;
} else {
// master不存在,说明master已经不可用了,如果当前broker在syncStateSet中,则当选(请求的处理是串行的),只有master能保存和修改syncStateSet,所以master不可用时,syncStateSet仍然保存在controller中
//如果开启了EnableElectUncleanMaster,则所有slave都可当选,但是数据一致性将受到影响,因为这时新当选的节点没有同步到足够的数据,这里体现了CAP原则,开启EnableElectUncleanMaster确保了更大的可用性,但数据一致性差;不开启则数据一致性高,但可用性差
canBeElectedAsMaster = syncStateInfo.getSyncStateSet().contains(brokerAddress) || this.controllerConfig.isEnableElectUncleanMaster();
}
}
//broker对应的brokerName第一次注册,controller中还没有broker相关信息,这时按照先到先得的逻辑选举master
else {
canBeElectedAsMaster = true;
}
if (canBeElectedAsMaster) {
...
//将事件对象ElectMasterEvent写入过半集群后,提交时,执行handleElectMaster方法
final ElectMasterEvent event = new ElectMasterEvent(true, brokerName, brokerAddress, request.getClusterName());
result.addEvent(event);
return result;
}
//master不可用,并且注册的broker不在syncStateSet中,不能当选新master,返回空的master地址
response.setMasterAddress("");
result.setCodeAndRemark(ResponseCode.CONTROLLER_REGISTER_BROKER_FAILED, "The broker has not master, and this new registered broker can't not be elected as master");
return result;
}
private void handleElectMaster(final ElectMasterEvent event) {
final String brokerName = event.getBrokerName();
final String newMaster = event.getNewMasterAddress();
if (isContainsBroker(brokerName)) {
final SyncStateInfo syncStateInfo = this.syncStateSetInfoTable.get(brokerName);
if (event.getNewMasterElected()) {
// master不可用,注册的slave符合条件当选
syncStateInfo.updateMasterInfo(newMaster);
final HashSet<String> newSyncStateSet = new HashSet<>();
newSyncStateSet.add(newMaster);
syncStateInfo.updateSyncStateSetInfo(newSyncStateSet);
} else {
// master不可用,并且没有符合条件的slave能够当选新master,这时将master地址留空,该brokerName对应的集群不可用
syncStateInfo.updateMasterInfo("");
}
} else {
//broker对应的brokerName第一次注册时执行,初始化BrokerInfo和SyncStateInfo
...
this.syncStateSetInfoTable.put(brokerName, syncStateInfo);
this.replicaInfoTable.put(brokerName, brokerInfo);
}
}
public class DefaultBrokerHeartbeatManager implements BrokerHeartbeatManager {
private final Map<BrokerAddrInfo/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
//向heartbeatManager中注册心跳信息,以便broker后续更新心跳时间戳、epoch、最大偏移量
@Override
public void registerBroker(String clusterName, String brokerName, String brokerAddr,
long brokerId, Long timeoutMillis, Channel channel, Integer epoch, Long maxOffset) {
final BrokerAddrInfo addrInfo = new BrokerAddrInfo(clusterName, brokerAddr);
final BrokerLiveInfo prevBrokerLiveInfo = this.brokerLiveTable.put(addrInfo,
new BrokerLiveInfo(...
timeoutMillis == null ? DEFAULT_BROKER_CHANNEL_EXPIRED_TIME/*心跳超时时间默认broker不会传,10s*/ : timeoutMillis,
...));
}
}
心跳判活和重新选举
当broker发来心跳时,controller通过DefaultBrokerHeartbeatManager处理心跳,更新心跳时间戳、epoch、最大偏移量。有2种方式检测到broker不可用:1、netty层检测到与broker连接断开,比如触发disconnect、close、连接读写空闲(IdleStateEvent)、异常事件时,执行DefaultBrokerHeartbeatManager#onBrokerChannelClose。2、网络延时很大,定时任务检测到brokerLiveTable中某个broker最近一次心跳时间距离当前大于DEFAULT_BROKER_CHANNEL_EXPIRED_TIME=10s时。
当发现master broker不可用时,会在leader controler上触发选举master
- 选举策略:从syncStateSet的心跳没超时的broker中,选择epoch和日志偏移量最大的成为新master。如果syncStateSet都不可用且enableElectUncleanMaster为true,则从所有的broker中选择
- 修改brokerLiveTable表中新master的brokerId为0,以便下次还能根据brokerId来判断master是否可用。
- 通知master和slave:向master和slave发送角色变更信息,包括masterAddr、masterEpoch、brokerId、syncStateSetEpoch,这时controller是客户端,broker是服务端,用的是注册broker的broker的地址,也就是brokerIP1+listenPort(ReplicasInfoManager#buildBrokerMemberGroup),broker端根据新master地址切换成master或slave
public class DefaultBrokerHeartbeatManager implements BrokerHeartbeatManager {
//心跳表,每个broker对应一个k-v,维护了每个可用的broker
private final Map<BrokerAddrInfo/* brokerAddr */, BrokerLiveInfo> brokerLiveTable;
@Override
public void start() {
//定时任务扫描brokerLiveTable中不可用的broker
this.scheduledService.scheduleAtFixedRate(this::scanNotActiveBroker, 2000, this.controllerConfig.getScanNotActiveBrokerInterval(), TimeUnit.MILLISECONDS);
}
public void scanNotActiveBroker() {
...
//定时任务检测,作为兜底方案
final Iterator<Map.Entry<BrokerAddrInfo, BrokerLiveInfo>> iterator = this.brokerLiveTable.entrySet().iterator();
while (iterator.hasNext()) {
if ((last + timeoutMillis) < System.currentTimeMillis()) {
//移出brokerLiveTable
iterator.remove();
notifyBrokerInActive(next.getKey().getClusterName(), next.getValue().getBrokerName(), next.getKey().getBrokerAddr(), next.getValue().getBrokerId());
}
}
}
@Override
public void onBrokerChannelClose(Channel channel) {
//netty层检测到与broker连接断开
notifyBrokerInActive(next.getKey().getClusterName(), next.getValue().getBrokerName(), next.getKey().getBrokerAddr(), next.getValue().getBrokerId());
if (addrInfo != null) {//移出brokerLiveTable
this.brokerLiveTable.remove(addrInfo);
}
}
@Override
public void onBrokerHeartbeat(String clusterName, String brokerAddr, Integer epoch, Long maxOffset,
Long confirmOffset) {
BrokerAddrInfo addrInfo = new BrokerAddrInfo(clusterName, brokerAddr);
BrokerLiveInfo prev = this.brokerLiveTable.get(addrInfo);
//更新心跳时间戳
prev.setLastUpdateTimestamp(System.currentTimeMillis());
}
}
public class BrokerAddrInfo {
private final String clusterName;
private final String brokerAddr;//broker地址
}
public class BrokerLiveInfo {
//上一次心跳时间戳
private final long heartbeatTimeoutMillis;
private final Channel channel;
}
//ControllerManager
//notifyBrokerInActive调用
private void onBrokerInactive(String clusterName, String brokerName, String brokerAddress, long brokerId) {
//master broker不可用,在leader controler上触发选举master
if (brokerId == MixAll.MASTER_ID) {
if (controller.isLeaderState()) {
//选举
final CompletableFuture<RemotingCommand> future = controller.electMaster(new ElectMasterRequestHeader(brokerName));
try {
final RemotingCommand response = future.get(5, TimeUnit.SECONDS);
final ElectMasterResponseHeader responseHeader = (ElectMasterResponseHeader) response.readCustomHeader();
if (responseHeader != null) {
log.info("Broker {}'s master {} shutdown, elect a new master done, result:{}", brokerName, brokerAddress, responseHeader);
if (StringUtils.isNotEmpty(responseHeader.getNewMasterAddress())) {
//更新brokerLiveTable的brokerid为0
heartbeatManager.changeBrokerMetadata(clusterName, responseHeader.getNewMasterAddress(), MixAll.MASTER_ID);
}
if (controllerConfig.isNotifyBrokerRoleChanged()) {
//向broker发信息,使broker切换角色
notifyBrokerRoleChanged(responseHeader, clusterName);
}
}
} catch (Exception ignored) {
}
} else {
log.info("Broker{}' master shutdown", brokerName);
}
}
}
//DefaultElectPolicy,选举策略,syncStateBrokers都不可用时,该方法会返回空,这样就选不出来broker,服务不可用,直到syncStateSet中的1台broker上线
public String elect(String clusterName, Set<String> syncStateBrokers/*syncStateSet broker*/, Set<String> allReplicaBrokers/*所有broker*/, String oldMaster, String preferBrokerAddr) {
String newMaster = null;
// try to elect in syncStateBrokers
if (syncStateBrokers != null) {
newMaster = tryElect(clusterName, syncStateBrokers, oldMaster, preferBrokerAddr);
}
if (StringUtils.isNotEmpty(newMaster)) {
return newMaster;
}
//只有syncStateSet都不可用,才会考虑其它的broker
// EnableElectUncleanMaster为false时,allReplicaBrokers为null
if (allReplicaBrokers != null) {
newMaster = tryElect(clusterName, allReplicaBrokers, oldMaster, preferBrokerAddr);
}
return newMaster;
}
private String tryElect(String clusterName, Set<String> brokers, String oldMaster, String preferBrokerAddr) {
if (this.validPredicate != null) {
//validPredicate就是DefaultBrokerHeartbeatManager#isBrokerActive, 过滤心跳超时的
brokers = brokers.stream().filter(brokerAddr -> this.validPredicate.test(clusterName, brokerAddr)).collect(Collectors.toSet());
}
if (brokers.size() >= 1) {
//additionalInfoGetter就是BrokerHeartbeatManager#getBrokerLiveInfo,获取心跳信息,根据心跳信息选择master
if (this.additionalInfoGetter != null) {
//comparator就是 x.getEpoch() == y.getEpoch() ? (int) (y.getMaxOffset() - x.getMaxOffset()) : y.getEpoch() - x.getEpoch();
//依此根据epoch和最大偏移量来选择
TreeSet<BrokerLiveInfo> brokerLiveInfos = new TreeSet<>(this.comparator);
brokers.forEach(brokerAddr -> brokerLiveInfos.add(this.additionalInfoGetter.apply(clusterName, brokerAddr)));
if (brokerLiveInfos.size() >= 1) {
return brokerLiveInfos.first().getBrokerAddr();
}
}
}
return null;
}
broker端
注册broker
broker相关类图

broker的配置(https://rocketmq.apache.org/zh/docs/deploymentOperations/16autoswitchdeploy/#broker-%E9%83%A8%E7%BD%B2):
enableControllerMode=true #Broker controller 模式的总开关,只有该值为 true,自动主从切换模式才会打开。默认为 false。
controllerAddr=127.0.0.1:9877;127.0.0.1:9878;127.0.0.1:9879 #controller地址,ip+端口,分号分割
syncControllerMetadataPeriod=10s #查询leader controller地址的时间间隔
syncBrokerMetadataPeriod=5s #同步broker元数据的时间间隔
checkSyncStateSetPeriod=5s #检查并修改syncStateSet的定时任务间隔
sendHeartbeatTimeoutMillis=1s #向controller发心跳的心跳超时时间
asyncLearner=false # 如果开启,该broker只会同步master日志数据,不会加进syncStateSet,参与master选举
syncFromLastFile=false #如果开启,空盘启动的broker只会从最后一个日志文件开始同步;如果关闭,从minOffset开始同步
haTransferBatchSize=32k #主从日志同步单次传输的最大字节数,不能超过缓冲区容量大小HAClient.READ_MAX_BUFFER_SIZE=4M
BrokerController#tart
ReplicasManager#start
当开启enableControllerMode时,会创建ReplicasManager,启动时执行start方法,根据ReplicasManager的状态,依此执行几个步骤:
- 获取controller元数据:依此访问controllerAddr配置的地址,直到获取到leader controller地址并缓存到本地,并且开启一个定时间隔为syncControllerMetadataPeriod=10s的任务,获取leader controller地址并缓存,从而在controller leader切换时动态更新
- 注册broker,确定broker角色:向leader controller注册broker,返回master地址,如果master地址为空则无操作,后续通过定时任务重新注册,直到master不为空;如果master地址不为空,根据是否与自己相同来切换成master或slave,并且将isIsolated设为false。controller模式启动brokerController时,isIsolated会被设为true,这样就不会注册路由信息到name server,只有等注册broker成功,且切换master或slave后,才会注册路由信息到name server、发心跳到controller
- 定时同步broker元数据:每隔syncBrokerMetadataPeriod=5s从controller的syncStateSetInfoTable和replicaInfoTable中获取masterAddress、masterEpoch、brokerId、syncStateSet、syncStateSetEpoch,作用:1、如果返回的masterAddress为空,重新执行一次注册,从而触发master选举。2、如果brokerId<0,重新注册,从而触发分配brokerId的逻辑
- 发心跳到controller:注册broker请求发到controller后,controller实际上会做2件事情:注册和生成心跳信息,注册成功后,开始每隔brokerHeartbeatInterval=1s定时向controller发心跳
public class BrokerController {
public boolean initialize() throws CloneNotSupportedException {
if (this.brokerConfig.isEnableControllerMode()) {
//controller模式,创建ReplicasManager
this.replicasManager = new ReplicasManager(this);
}
}
public void start() throws Exception {
//最终执行replicasManager.startBasicService,进行注册broker,获得当前broker的角色
startBasicService();
scheduledFutures.add(this.scheduledExecutorService.scheduleAtFixedRate(new AbstractBrokerRunnable(this.getBrokerIdentity()) {
@Override
public void run2() {
if (isIsolated) {
//isIsolated开启时,不注册nameserver
BrokerController.LOG.info("Skip register for broker is isolated");
return;
}
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS));
if (this.brokerConfig.isEnableControllerMode()) {
//controller模式,开启向每个controller发送心跳的定时任务,心跳信息包括brokerid,brokerAddr,心跳超时时间sendHeartbeatTimeoutMillis=1s,最大物理偏移量
//isIsolated开启时,不会真的发送心跳到controller
scheduleSendHeartbeat();
}
}
}
public class ReplicasManager {
private boolean startBasicService() {
if (this.state == State.INITIAL) {
//获取controller元数据
if (schedulingSyncControllerMetadata()) {
LOGGER.info("First time sync controller metadata success");
this.state = State.FIRST_TIME_SYNC_CONTROLLER_METADATA_DONE;
} else {
return false;
}
}
if (this.state == State.FIRST_TIME_SYNC_CONTROLLER_METADATA_DONE) {
//注册broker,确定broker角色
if (registerBrokerToController()) {
LOGGER.info("First time register broker success");
this.state = State.RUNNING;
} else {
return false;
}
}
//定时同步broker元数据
schedulingSyncBrokerMetadata();
return true;
}
private boolean registerBrokerToController() {...
if (StringUtils.isNoneEmpty(newMasterAddress)) {
...//注册成功后,将Isolated设为false
brokerController.setIsolated(false);
}
}
}
主从同步
相关类图

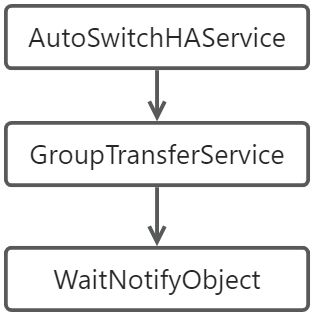
DefaultMessageStore在创建时,如果是controller模式,会创建支持自动切换主从的高可用服务AutoSwitchHAService,AutoSwitchHAService启动时,会通过AutoSwitchAcceptSocketService监听主从同步端口haListenPort,当注册broker成功,切换broker角色时,slave创建并启动AutoSwitchHAClient,尝试连接master,同步消息,连接master的高可用地址haMasterAddress是在切换角色后,向name server的心跳中发送和读取的,所以要支持自动切换,所有broker都需要配置brokerIP2,因为每台都有可能切换到master,haListenPort可以不配置,让系统选择
//BrokerController
protected void startBasicService() throws Exception {
//实际上是先启动messageStore,再启动replicasManager注册broker和确定broker角色,在切换角色时创建AutoSwitchHAClient,发起同步
this.messageStore.start();
this.replicasManager.start();
}
public class DefaultMessageStore implements MessageStore {
public DefaultMessageStore(...) throws IOException {
if (!messageStoreConfig.isEnableDLegerCommitLog() && !this.messageStoreConfig.isDuplicationEnable()) {
if (brokerConfig.isEnableControllerMode()) {
//开启controller模式,但没开启DLeger集群时
this.haService = new AutoSwitchHAService();
}
}
}
public void start() throws Exception {
//先执行init,再start
this.haService.init(this);
this.haService.start();
}
}
public class AutoSwitchHAService extends DefaultHAService {
public boolean changeToSlave(String newMasterAddr, int newMasterEpoch, Long slaveId) {
...
//切换到slave时,在创建AutoSwitchHAClient
this.haClient = new AutoSwitchHAClient(this, defaultMessageStore, this.epochCache);
this.haClient.updateMasterAddress(newMasterAddr);
//高可用地址先留空,等到后面注册broker到name server时,获取master的高可用地址
this.haClient.updateHaMasterAddress(null);
//启动同步线程,连接master,同步
this.haClient.start();
...
}
}
slave创建并启动同步线程AutoSwitchHAClient后,依此进入3种状态:
- READY:初始状态,尝试连接master的高可用地址haMasterAddress,和同步异步复制类似,master对每个slave连接创建连接对象AutoSwitchHAConnection,每个连接对象对应2个线程ReadSocketService和WriteSocketService处理读写,因为是读写数据量较大的连接,所以使用专门的线程,不占用其它IO线程
- HANDSHAKE:握手阶段主要处理2个任务:1、slave将自己的配置信息发给master保存,包括:slaveAddress、isAsyncLearner、isSyncFromLastFile,slaveAddress是brokerIP1+listenPort,发给master是用来更新syncStateSet。2、对比master和slave的epochEntries进行日志截断,master将epoch文件(store/epochFileCheckpoint)中的epochEntries信息发给slave,slave收到后与自己本地的epochEntries进行比对,倒序遍历本地的epochEntries,找到第一个epoch和起始偏移量与master都相等的EpochEntry,选择这个EpochEntry较小的结束偏移量作为截断偏移量。截断后进入TRANSFER状态
- TRANSFER:slave将自己的截断偏移量发给master,master得到该偏移量后,1、尝试更新syncStateSet,如果slave的日志偏移量是否比syncStateSet中最小日志偏移量大,则将slave添加进syncStateSet,更新controller集群的syncStateSet得到新的syncStateSetEpoch,根据新的epoch修改broker本地的syncStateSet。2、将日志数据发送给slave,日志数据的起始偏移量:如果slave是空盘启动且syncFromLastFile=true,则从最后一个日志文件开始同步,否则从minOffset开始同步;日志数据的大小:每次传输不超过haTransferBatchSize=32k,不是以消息为单位,而是面向流的同步;传输的偏移量对应的epochEntry不一定是当前的,slave在同步的过程中可能会追加新的epochEntry,最终和master的epochEntry保持一致
public class EpochFileCache {
//epochEntries是只追加的epochEntry红黑树,epochEntry包括epoch和该epoch对应写入的日志起止偏移量
private final TreeMap<Integer/*epoch*/, EpochEntry> epochMap;
}
public class EpochEntry extends RemotingSerializable {
private int epoch;
private long startOffset;
private long endOffset = Long.MAX_VALUE;
}
//AutoSwitchHAService
public boolean changeToMaster(int masterEpoch) {
//每次新选出master时追加一个新的epoch更大的epochEntry,开始偏移量初始化为最大物理偏移量,结束偏移量是Long.MAX_VALUE
final EpochEntry newEpochEntry = new EpochEntry(masterEpoch, this.defaultMessageStore.getMaxPhyOffset());
//追加新的EpochEntry时,会设置前一个EpochEntry的结束偏移量为新的EpochEntry的开始偏移量
this.epochCache.appendEntry(newEpochEntry);
}
//EpochFileCache,比对master和slave的epochEntries,this是slave的,compareCache是master的
public long findConsistentPoint(final EpochFileCache compareCache) {
this.readLock.lock();
try {
long consistentOffset = -1;
//倒序遍历slave,找到第一个epoch和起始偏移量与master都相等的EpochEntry,选择这个EpochEntry较小的结束偏移量作为截断偏移量
//比对实际上就是找到slave和master最后日志重合的位置,epoch和起始偏移量相等,说明slave和master都具有
final Map<Integer, EpochEntry> descendingMap = new TreeMap<>(this.epochMap).descendingMap();
final Iterator<Map.Entry<Integer, EpochEntry>> iter = descendingMap.entrySet().iterator();
while (iter.hasNext()) {
final Map.Entry<Integer, EpochEntry> curLocalEntry = iter.next();
final EpochEntry compareEntry = compareCache.getEntry(curLocalEntry.getKey());
if (compareEntry != null && compareEntry.getStartOffset() == curLocalEntry.getValue().getStartOffset()) {
consistentOffset = Math.min(curLocalEntry.getValue().getEndOffset(), compareEntry.getEndOffset());
break;
}
}
return consistentOffset;
} finally {
this.readLock.unlock();
}
}
客户端请求
相关配置
inSyncReplicas=1 #客户端发给master消息后,至少要同步inSyncReplicas个节点(可以不是syncStateSet中的节点)才返回成功的响应,包括master本身,也就是说默认情况下相当于异步复制,写入master就可以返回成功的响应,当开启allAckInSyncStateSet时,该配置无效
allAckInSyncStateSet=false #客户端发给master消息后,要同步所有syncStateSet节点才返回成功的响应,注意如果syncStateSet中只有master,那么只要master写入成功,如果要控制syncStateSet的数量,要和minInSyncReplicas同时配置
minInSyncReplicas=1 #客户端发送master消息时,至少需要多少台节点处于syncStateSet中,才可能返回成功的响应,否则拒绝消息写入commitLog,返回IN_SYNC_REPLICAS_NOT_ENOUGH,默认情况下只要master在线,默认的配置偏向于可用性而不是可靠性
生产者发送消息时,broker端的高可用处理:
- 在写入消息之前,判断syncStateSet中的节点数是否小于minInSyncReplicas,如果小于,则拒绝消息写入commitLog,返回IN_SYNC_REPLICAS_NOT_ENOUGH
- 如果配置了allAckInSyncStateSet为true,则等待所有syncStateSet节点同步成功才返回成功响应,根据slave的同步偏移量是否大于等于结束偏移量来判断该slave是否成功同步了该条消息
- 如果allAckInSyncStateSet为false,则等待inSyncReplicas个节点同步成功,可以不是syncStateSet中的节点,包括master本身
//CommitLog,生产者发送消息时,高可用处理
public CompletableFuture<PutMessageResult> asyncPutMessage(final MessageExtBrokerInner msg) {
//至少要同步inSyncReplicas个节点才返回成功的响应,包括master本身
int needAckNums = this.defaultMessageStore.getMessageStoreConfig().getInSyncReplicas();
//controller模式一定是同步复制模式,所有WaitStoreMsgOK为true的消息一定返回true
boolean needHandleHA = needHandleHA(msg);
if (needHandleHA && this.defaultMessageStore.getBrokerConfig().isEnableControllerMode()) {
//syncStateSet的大小如果小于minInSyncReplicas,返回IN_SYNC_REPLICAS_NOT_ENOUGH,拒绝消息写入
if (this.defaultMessageStore.getHaService().inSyncReplicasNums(currOffset) < this.defaultMessageStore.getMessageStoreConfig().getMinInSyncReplicas()) {
return CompletableFuture.completedFuture(new PutMessageResult(PutMessageStatus.IN_SYNC_REPLICAS_NOT_ENOUGH, null));
}
if (this.defaultMessageStore.getMessageStoreConfig().isAllAckInSyncStateSet()) {
// 如果开启了allAckInSyncStateSet,则needAckNums设为-1,表示需要同步所有slave节点才返回成功的响应
needAckNums = MixAll.ALL_ACK_IN_SYNC_STATE_SET;
}
}
//消息写入commitLog...
//等待刷盘和主从同步完成
return handleDiskFlushAndHA(putMessageResult, msg, needAckNums, needHandleHA);
}
private CompletableFuture<PutMessageStatus> handleHA(AppendMessageResult result, PutMessageResult putMessageResult,
int needAckNums) {
if (needAckNums >= 0 && needAckNums <= 1) {
//默认情况下不会等待主从同步,直接返回成功
return CompletableFuture.completedFuture(PutMessageStatus.PUT_OK);
}
HAService haService = this.defaultMessageStore.getHaService();
//新写入消息的结束偏移量,起始偏移量+大小,根据slave的同步偏移量是否大于等于结束偏移量来判断该slave是否成功同步了该条消息
long nextOffset = result.getWroteOffset() + result.getWroteBytes();
GroupCommitRequest request = new GroupCommitRequest(nextOffset, this.defaultMessageStore.getMessageStoreConfig().getSlaveTimeout(), needAckNums);
//将GroupCommitRequest放入groupTransferService.requestsWrite,并唤醒groupTransferService线程,让它检查同步结果
haService.putRequest(request);
haService.getWaitNotifyObject().wakeupAll();
//返回future,当groupTransferService线程检查到该消息同步成功时,执行future.complete
return request.future();
}
private void doWaitTransfer() {
...
if (allAckInSyncStateSet && this.haService instanceof AutoSwitchHAService) {
// 等待syncStateSet中所有节点写入成功
final AutoSwitchHAService autoSwitchHAService = (AutoSwitchHAService) this.haService;
final Set<String> syncStateSet = autoSwitchHAService.getSyncStateSet();
if (syncStateSet.size() <= 1) {
// syncStateSet只有master,直接成功
transferOK = true;
break;
}
// syncStateSet包括master,所以ackNums从1开始计数
int ackNums = 1;
for (HAConnection conn : haService.getConnectionList()) {
final AutoSwitchHAConnection autoSwitchHAConnection = (AutoSwitchHAConnection) conn;
if (syncStateSet.contains(autoSwitchHAConnection.getSlaveAddress()) && autoSwitchHAConnection.getSlaveAckOffset() >= req.getNextOffset()) {
//每次传输开始时,slave会报告自身已经同步的偏移量,根据已同步的偏移量是否大于消息接收偏移量来判断该slave是否成功同步了该条消息
ackNums++;
}
if (ackNums >= syncStateSet.size()) {
//所有syncStateSet的节点同步成功
transferOK = true;
break;
}
}
} else {
// allAckInSyncStateSet为false时
int ackNums = 1;
for (HAConnection conn : haService.getConnectionList()) {
//这里没有判断是否是syncStateSet中的节点,可以不是syncStateSet中的节点
if (conn.getSlaveAckOffset() >= req.getNextOffset()) {
ackNums++;
}
//req.getAckNums()就是inSyncReplicas,同步inSyncReplicas个节点(可以不是syncStateSet中的节点)才返回成功的响应,包括master本身
if (ackNums >= req.getAckNums()) {
transferOK = true;
break;
}
}
}
....
}
syncStateSet
- syncStateSet的初始化:syncStateSet是一个成功同步上master的broker地址的字符串Set集合,一定包含master本身的地址,在master broker和controller集群都保存了,broker切换成master时,初始值只有master的地址
- 添加:在每次传输数据前,slave会向master报告自己的同步偏移量,master根据slave的日志偏移量判断是否将它加入syncStateSet,判断条件是slave的日志偏移量是否比syncStateSet中最小日志偏移量大
- 移除:通过定时间隔为checkSyncStateSetPeriod=5s的任务来遍历connectionCaughtUpTimeTable表,将上一次”同步上“的时间距离当前时间大于haMaxTimeSlaveNotCatchup=15s的slave地址从syncStateSet中移除。“同步上”的含义:slave报告的偏移量等于master最大偏移量,也就是已经同步完master所有数据。
小结:syncStateSet实际上包含了15s内同步进度能够跟上master的节点集合
//ReplicasManager
public void changeToMaster(final int newMasterEpoch, final int syncStateSetEpoch) {
//刚切换master时,初始化为master地址
final HashSet<String> newSyncStateSet = new HashSet<>();
newSyncStateSet.add(this.localAddress);
//这里只是修改broker本地
changeSyncStateSet(newSyncStateSet, syncStateSetEpoch);
schedulingCheckSyncStateSet();
}
private void schedulingCheckSyncStateSet() { ...
this.checkSyncStateSetTaskFuture = this.scheduledService.scheduleAtFixedRate(() -> {
//定时任务移除syncStateSet
final Set<String> newSyncStateSet = this.haService.maybeShrinkInSyncStateSet();
newSyncStateSet.add(this.localAddress);
synchronized (this) {
if (this.syncStateSet != null) {
// Check if syncStateSet changed
if (this.syncStateSet.size() == newSyncStateSet.size() && this.syncStateSet.containsAll(newSyncStateSet)) {
return;
}
}
}
doReportSyncStateSetChanged(newSyncStateSet);
}, 3 * 1000, this.brokerConfig.getCheckSyncStateSetPeriod(), TimeUnit.MILLISECONDS);
}
public class AutoSwitchHAService extends DefaultHAService {
public Set<String> maybeShrinkInSyncStateSet() {
final Set<String> newSyncStateSet = getSyncStateSet();
final long haMaxTimeSlaveNotCatchup = this.defaultMessageStore.getMessageStoreConfig().getHaMaxTimeSlaveNotCatchup();
for (Map.Entry<String, Long> next : this.connectionCaughtUpTimeTable.entrySet()) {
final String slaveAddress = next.getKey();
if (newSyncStateSet.contains(slaveAddress)) {
//根据connectionCaughtUpTimeTable来移除syncStateSet
final Long lastCaughtUpTimeMs = this.connectionCaughtUpTimeTable.get(slaveAddress);
if ((System.currentTimeMillis() - lastCaughtUpTimeMs) > haMaxTimeSlaveNotCatchup) {
newSyncStateSet.remove(slaveAddress);
}
}
}
return newSyncStateSet;
}
}
//connectionCaughtUpTimeTable的更新
//master将日志数据发给slave之前执行该方法,记录传输前master的最大偏移量
private synchronized void updateLastTransferInfo() {
this.lastMasterMaxOffset = this.haService.getDefaultMessageStore().getMaxPhyOffset();
this.lastTransferTimeMs = System.currentTimeMillis();
}
private synchronized void maybeExpandInSyncStateSet(long slaveMaxOffset) {
//slaveMaxOffset >= this.lastMasterMaxOffset,表明上一次传输已经成功同步到了master的最新偏移量,更新connectionCaughtUpTimeTable
if (!this.isAsyncLearner && slaveMaxOffset >= this.lastMasterMaxOffset) {
long caughtUpTimeMs = this.haService.getDefaultMessageStore().getMaxPhyOffset() == slaveMaxOffset ? System.currentTimeMillis() : this.lastTransferTimeMs;
this.haService.updateConnectionLastCaughtUpTime(this.slaveAddress, caughtUpTimeMs);
this.haService.maybeExpandInSyncStateSet(this.slaveAddress, slaveMaxOffset);
}
}
//AutoSwitchHAService,在每次传输数据前,根据slave的日志偏移量判断是否将它加入syncStateSet,判断条件是slave的日志偏移量是否比syncStateSet中最小日志偏移量大
public void maybeExpandInSyncStateSet(final String slaveAddress, final long slaveMaxOffset) {
final Set<String> currentSyncStateSet = getSyncStateSet();
if (currentSyncStateSet.contains(slaveAddress)) {
return;
}
//获取syncStateSet中最小的日志偏移量,包括master
final long confirmOffset = getConfirmOffset();
if (slaveMaxOffset >= confirmOffset) {
final EpochEntry currentLeaderEpoch = this.epochCache.lastEntry();
if (slaveMaxOffset >= currentLeaderEpoch.getStartOffset()) {
currentSyncStateSet.add(slaveAddress);
//执行 ReplicasManager#doReportSyncStateSetChanged修改syncStateSet,syncStateSet在controller集群和broker master都保存了,所以先向leader发送alterSyncStateSet请求,让集群修改syncStateSet并得到新的syncStateSetEpoch,根据新的epoch修改broker本地的syncStateSet
notifySyncStateSetChanged(currentSyncStateSet);
}
}
}




![[ Azure - Subscriptions ] 解决办法:此订阅未在 Microsoft.Insights 资源提供程序中注册](https://img-blog.csdnimg.cn/4e11e58403e84926b37a3277de924f67.png)