一、前言
这些年,我们的cpu、内存和i/o设备都在不断迭代,不断朝着更快的方向努力。但是,在这个快速发展的过程中,有一个核心矛盾一直存在,就是这三者的速度。
- cpu是天上1天,内存是地上1年
- cpu是天上1天,io是地上10年
为了合理利用cpu的高性能,平衡这三者的速度差异,计算机系结构、操作系统、编译程序都做出了贡献,主要体现为:
- cpu加了缓存,以均衡与内存的速度差异
- 操作系统增加了进程、线程,以时分复用cpu,进而均衡cpu与i/o设备的速度差异
- 编译程序优化指令执行次序,使得缓存能够更加合理的利用
二、造成的问题
1.缓存导致的可见性问题
在多核cpu时代,每个cpu都有自己的缓存,cpu1对于缓存的操作对于cpu2是不可见的,所以当cpu2对某一个值处理时,是不知道别的cpu对它的更改的,所以会有可见性问题
2.线程切换带来的原子性问题
java并发程序是基于多线程的,多线程自然就涉及任务切换,比如一条 count+1=1, 至少需要三条cpu指令
- 指令1: 首先,需要把变量count从内存加载到CPU的寄存器
- 指令2: 之后,在寄存器中执行+1的操作
- 指令3: 最后,把结果写入到内存中(缓存机制导致可能写入的是cpu缓存而不是内存)
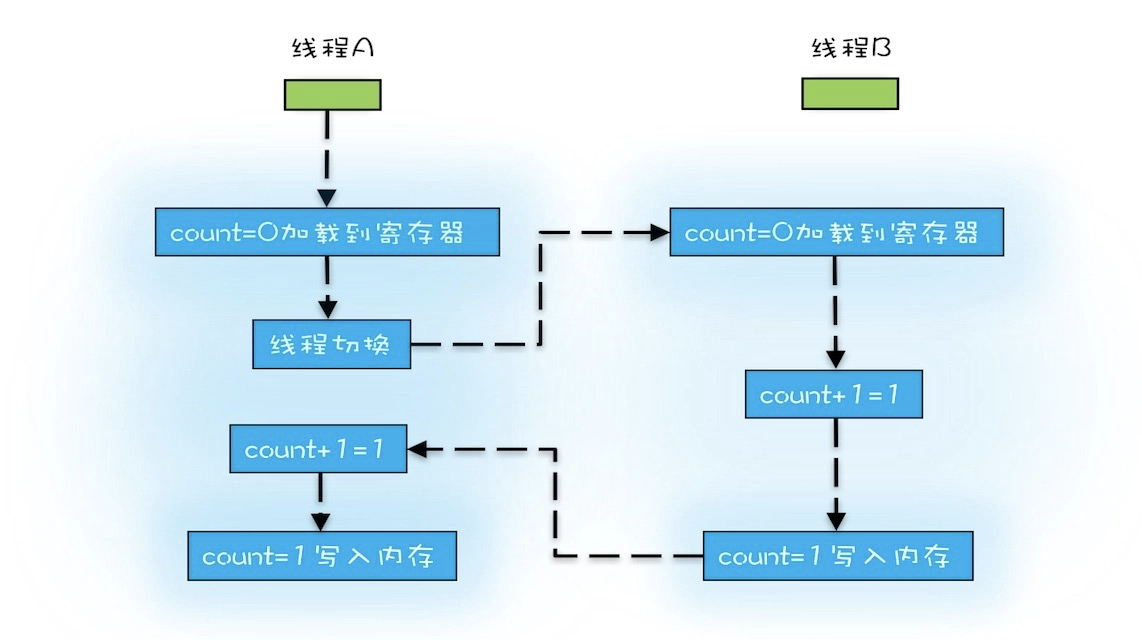
cpu保证的是cpu指令是原子的,但是高级语言的指令不会是原子操作。一条高级语言的操作往往对于多条cpu指令,如果想解决这种原子性的问题,大多要使用🔒。
3.编译优化带来的有序性问题
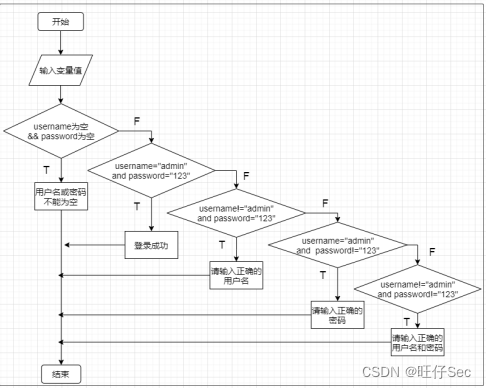
通过一个双重检查创建单例对象来说明这个编译优化带来的问题:
public class Singletion{
static Singleton instance;
static Singletion getInstance(){
if (instance == null ){
synchronized(Singleton.class){
if(instance == null)
instance = new Singletion();
}
}
}
}
我们理想的情况是:
- 线程A和线程B同时执行getInstance方法,线程A先进入获取到锁之后,然后开始创建Singleton对象,线程B后来进入,没有拿到锁,然后阻塞起来。
- 等线程A创建完对象,释放锁之后线程B 判断 instance== null时发现,已经创建过来,就不会再创建了
but:这里问题出现在了 newSingleton上,new Singleton会出现先释放引用,然后再分配内存的指令重排序,如果刚好在这个时候,内存还没来的分配好,就发生了线程切换,线程B 判断instance == null 为false,就返回了,但是真正去获取成员变量的时候,就会发生空指针,因为成员变量内存还没有分配好。
三、如何解决这些问题
java提供了很多关键字(sync、final、volatile)来按需禁用缓存、按需禁用编译优化。
1.解决可见性
volatile、sync这些解决可见性本质上就是通过内存屏障保证对于工作内存的修改或者读取都直接作用于主内存
2.解决原子性
volatile并不具备原子性,只是在32位机器上对于Long类型的读写保证原子性
要具备原子性,还是要有锁,要有临界区的概念,要让一组操作一起。sync里面的操作都是具有原子性的。
3.解决有序性
volatile、sync都是通过内存屏障来解决有序性的问题