论文:Efficient Emotional Adaptation for Audio-Driven Talking-Head Generation
代码:https://yuangan.github.io/eat/
出处:ICCV2023
特点:能引入表情,但无法眨眼,需要 音频 + pose + 图片 同时作为输入来合成数字人
文章目录
- 一、背景
- 二、方法
- 2.1 第一阶段:与表情无关的预训练
- 2.2 第二阶段:高效的表情调节
- 2.3 目标函数
- 三、效果
- 3.1 实验设置
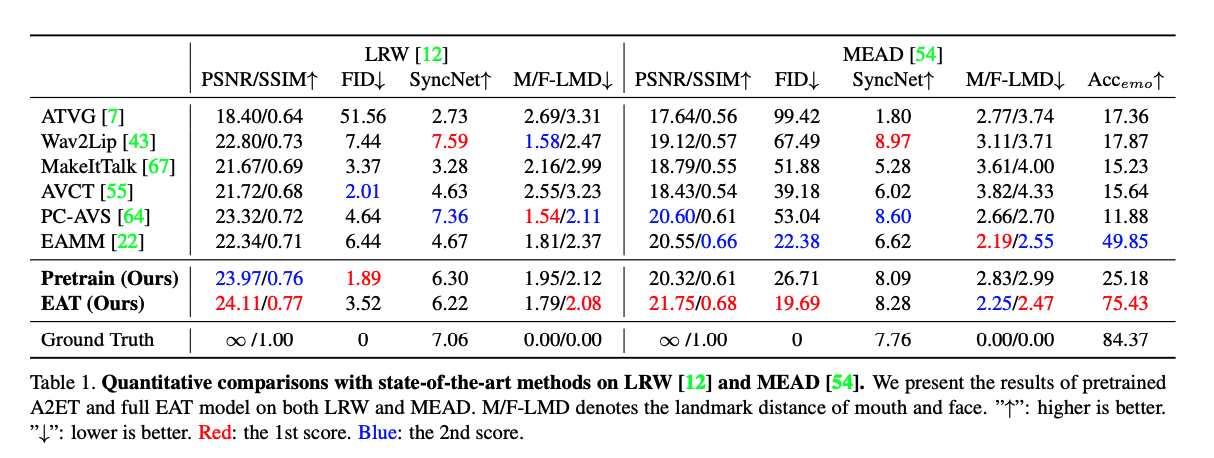
- 3.2 效果对比
一、背景
Audio-driven talking head 生成任务中,如果可以引入表情,则会提升数字人的保真性和多样性,但这样就会需要考虑很多方便,如头部、表情、声音、动作等,加大生成任务的难度
GC-AVT 和 EAMM 算法使用 driven emotional video 和 pose-guiding video 来同时驱动视频的生成
但现有的方普遍有以下两个问题:
- 网络结构的高效问题:当有多个子任务时,训练或者微调一个 talking head 生成网络的代价就比较大。而且与表情无关的训练数据更多,所以如何高效的重利用这些数据就很重要
- 提示的多样性:之前的方法一般都是使用一个表情驱动视频,而不是直接将表情特征学习到网络中,所以在实际使用时,需要考虑驱动视频的分辨率、遮挡率、长度等,但没有考虑嘴唇的形状,所以表情并不是很真实
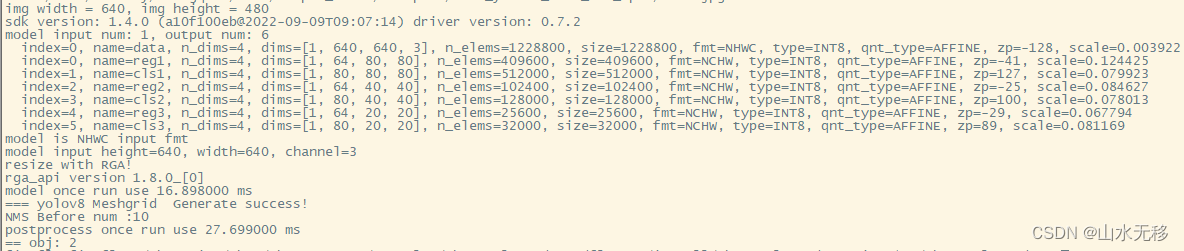
为了解决上面这些问题,就需要能够方便且高效的将预训练好的无表情 talking head 模型迁移到 emotional talking head 模型,且值需要很轻量的 emotional guidance,如图 1 所示。
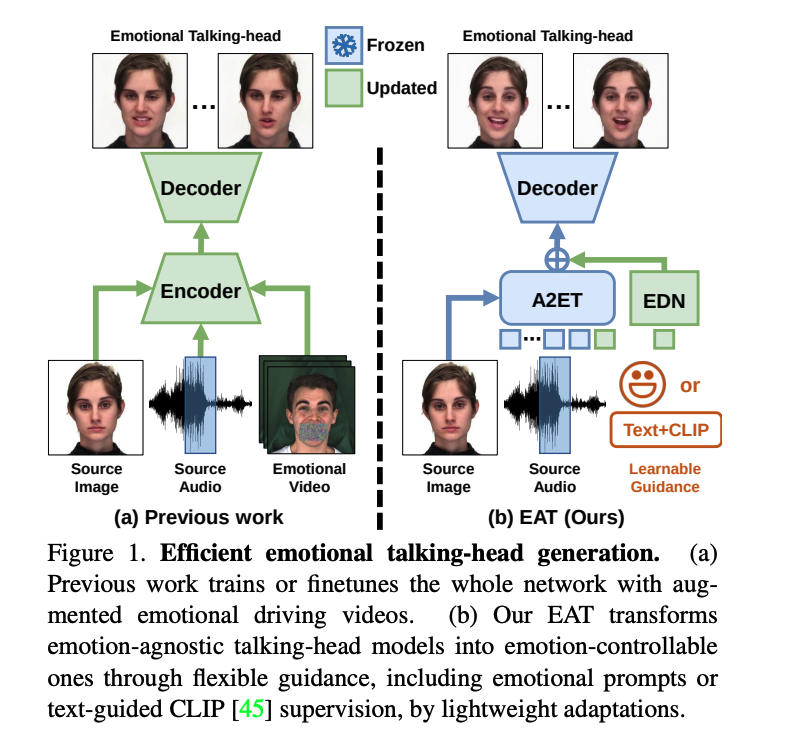
因此,本文提出了一个高效的两阶段网络:
- 第一阶段:使用无监督的 3d 隐空间关键点特征来捕捉表情,然后使用 audio-to-expression transformation(A2ET),也就是学习将 audio 和 3D 隐空间的关键点的关系,这里使用的是大量的无表情标注的数据
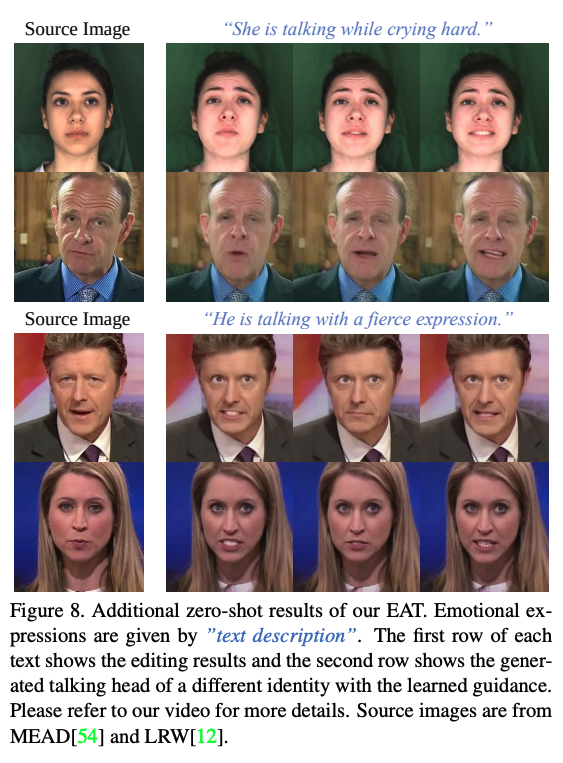
- 第二阶段:使用使用可学习的指导和可适应的模块,来实现表情的生成。这包括用于参数高效情感适应的 Deep Emotional Prompts、一个轻量级的 Emotional Deformation Network (EDN) 用于学习面部潜在表征的情感变形,以及一个即插即用的情感适应模块(y Emotional Adaptation Module,EAM)用于提升视觉质量。此方法使得传统的 talking head 模型能够快速转移到情感生成任务上,并且能产生高质量的结果,同时支持使用 image-text 模型进行零样本表情编辑[45]。
二、方法
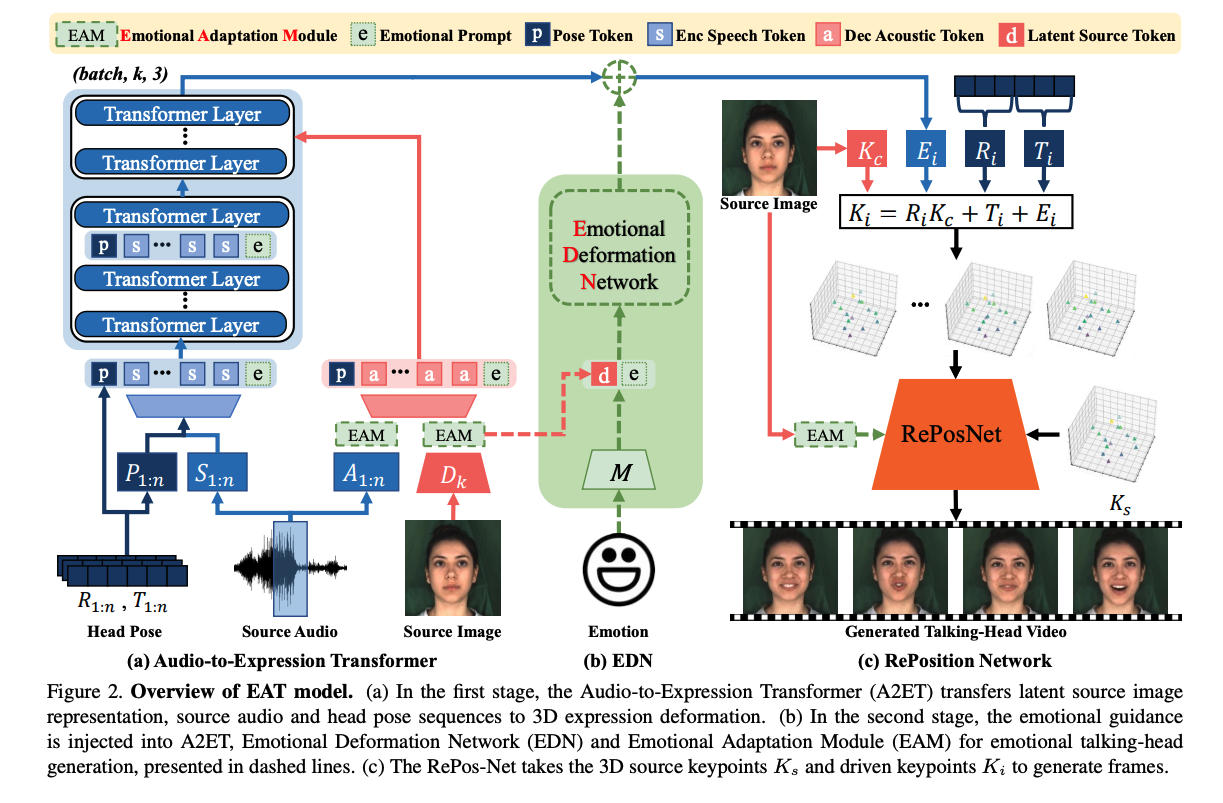
2.1 第一阶段:与表情无关的预训练
1、隐空间关键点
给定一个 talking head 图像帧 i i i,作者会使用无监督的方法学习 3D 隐形关键点 K i K_i Ki,具体包括以下四个部分:
- identity-specific canonical keypoints K c K_c Kc
- rotation matrix R i R_i Ri
- translation T i T_i Ti
- expression deformation E i E_i Ei
这四部分组合方式如下:
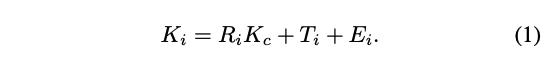
一般来说,基于这些 3D 隐空间关键点,RePosition Network (RePos-Net) [56] 可以将一个人的面部表情迁移到另一个人的面部,如图 3 所示,但是对眉毛、嘴角等没法很好的迁移,所示,作者做了三点改进:
- 移除了 deformation prior loss in OSFV [56]:这个 loss 会限制关键点形变的模值,移除了后会让隐空间的关键点捕捉到很多微小的表情
- 使用 MEAD 数据集:来获得有表情标注、成对儿的人脸数据,能让网络学习更多的表情变化
- 只计算人脸区域的 loss:这样能够避免背景等带来的影响,所以只计算了人脸区域的 loss
2、Audio-to-Expression Transformer
由于 3D 隐空间关键点是和 source identity 关联的,且比 2D 的隐空间关键点更复杂,直接预测 3D 关键点序列很难。作者观察到,面部表情主要是由 expression deformation E i E_i Ei 来表示的,所以,提出了 A2ET 来学习 audio-visual 来合成 expression deformation
Audio-visual Feature Extraction:
作者使用 Vox2 数据集训练这个 Transformer 网络,并且为了避免音频噪声,使用了 deepspeech 提取特征,同时使用了语音特征 S 1 : n S_{1:n} S1:n 和 声学特征 A 1 : n A_{1:n} A1:n。
如图 2a 所示,给点一帧 i,会从 2w+1 个 audio frame 中来抽取语音上下文特征,然后 speech features S i − w : i + w S_{i-w:i+w} Si−w:i+w 和 pose features P i − w : i + w P_{i-w:i+w} Pi−w:i+w 被转换成 speech tokens,当前帧的 6DoF 被编码成 pose token p p p。
A2ET encoder 的输入就是 speech tokens 和 pose token
为了捕捉嘴唇的变化,将声学特征 A i − w : i + w A_{i-w:i+w} Ai−w:i+w 和 image represent 使用 audio encoder 和 keypoint detector D k D_k Dk进行编码
接着,作者将这两种表征(声学特征和图像关键点)结合起来,生成了一系列的声学标记( acoustic tokens 或称为“声学令牌”)。这些标记包含了嘴部动作的信息,输入到 A2ET 的解码器中。这个解码器的作用是根据这些声学标记来重建或输出特定数量的特征,也就是输出长度为2w + 1个标记的特征序列。
Expression Deformation Prediction:
表情形变 E i E_i Ei 是由 k 个 3D 偏移组成的,可以从当前帧 i 的特征中得到,直接优化这个 3D 运动会难以收敛。
作者发现通过 self-supervision 学习到的三维关键点之间存在着内在的相互依赖性,实际上只有少数关键点对面部表情有影响。因此作者采用了主成分分析(PCA)来处理 E i E_i Ei,这有助于减少数据的维度并去除那些不必要的信息。这样一来,就可以根据音频特征来预测面部的三维表情变形了。
2.2 第二阶段:高效的表情调节
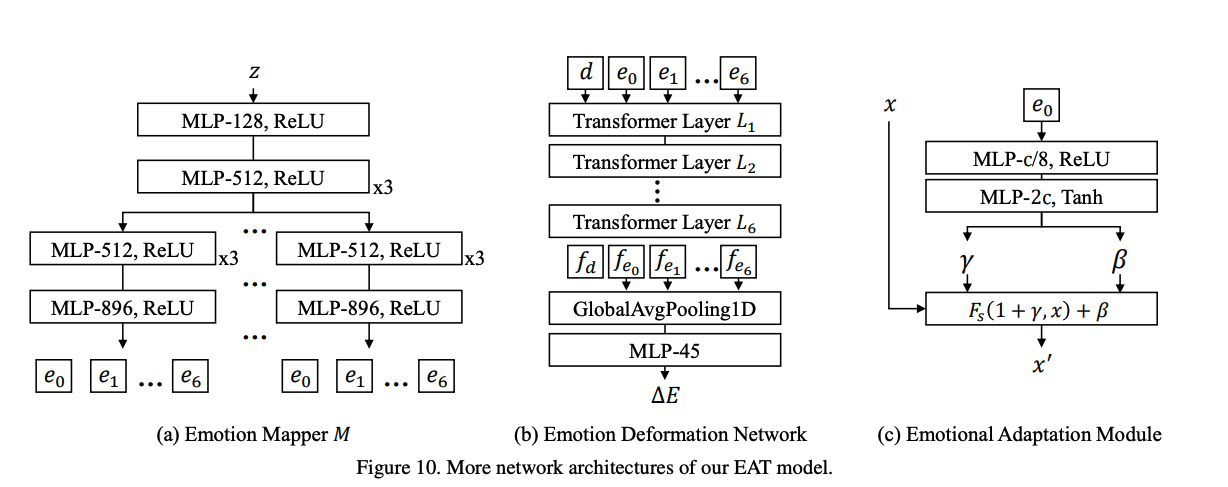
- Deep Emotional Prompts
- Emotional Deformation Network (EDN)
- Emotional Adaptation Module (EAM)
Emotional Guidance:
一个直接的想法是利用可学习的引导条件来生成带有情感的 talking head。作者认为每种情绪类型都属于潜在空间中的一个独特子域。正如图2(b)所示,使用了一个映射网络 M 来提取带有 latent code z ∈ U 16 z ∈ U^{16} z∈U16 的 emotion-conditional guidance。这个 latent code 是从高斯分布中采样的,这是生成模型中常用的方法[29, 9]。这种情绪引导被用来指导情绪表情的生成。
Deep Emotional Prompt:
为了更高效的进行不同表情的调节,作者将这种 guidance 作为 A2ET 的一个输入,如图 2a
作者为 A2ET 分别引入了深层和浅层的 emotional prompts,浅层的 prompt 是加到第一层上,深层的 prompt 是加到后面的其他层上
Emotional Deformation Network:
作者观察到,公式 1 中解耦的三维隐式表示表现出线性可加性。此外,情感话语头部展示了传统话语头部所没有的情感形变。为了补充 Ei,一种直观的方法是包含一个情感表达形变项:
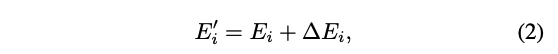
其中, E ′ i E′i E′i 代表情感表达形变, E i E_i Ei代表由 A2ET 预测的与语音相关的表达形变, Δ E i ΔE_i ΔEi 代表与情感相关的表达形变。为了预测 Δ E i ΔE_i ΔEi,我们设计了一个名为情感形变网络(EDN)的子网络,如图2(b)所示。EDN 利用 A2ET 编码器架构,在情感指导和源潜在表示令牌的帮助下预测 Δ E i ΔE_i ΔEi。为了加速适应性,我们用预训练的A2ET编码器初始化了EDN。为了用 E ′ i E′_i E′i更新 KaTeX parse error: Expected group after '_' at position 3: Ei_̲,我们可以使用公式1得到情感3D潜在关键点。
Emotional Adaptation Module:
为了进一步提升视觉效果,作者设计了一个即插即用的调节模块 Emotional Adaptation Module (EAM),能够生成 emotion-conditioned features。如图 3 所示,这个模块的输入是 guidance embedding e e e,然后使用两个 FC 层来获得一系列的 channel weights γ \gamma γ 和 偏置 β \beta β,然后使用激活然后将其限制到 [-1,1]
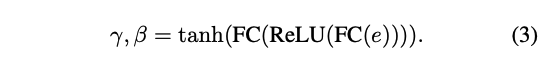
一旦获得了 γ \gamma γ 和 β \beta β,就可以输入特征 x x x 来得到 emotional feature 了:
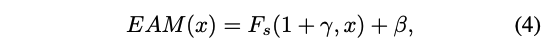
- F s F_s Fs 是通道上的乘
如图 2 所示,EAM 可以被插入 RePosNet、audio 特征提取器、image 特征提取器
Zero-shot Expression Editing:
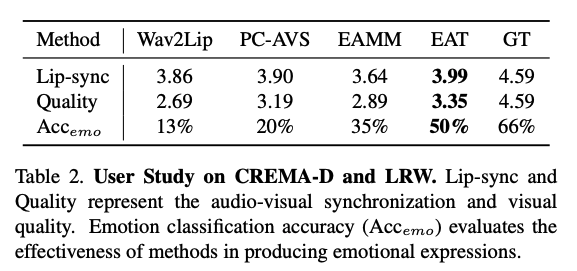
由于 EAT 能够很快的调节,所以可以实现 zero-shot text-guided 表情编辑,方法是从 CLIP 上蒸馏
为了利用 CLIP loss 来学习表情指导,作者使用 head pose、source audio、first frame from target video 作为输入,
为了利用 CLIP 损失(CLIP loss)来学习与文本描述的表情相关的情感引导。作者提取目标视频的头部姿势、原始音频以及第一帧作为输入。
此外,还采用了目标表情描述来进行微调。使用经过改进的EAT模型和我们的训练损失,增加了一个额外的CLIP损失来微调映射网络和EAM模块。
具体就是:使用 CLIP 的图像编码器从预测的说话面部提取图像嵌入,使用其文本编码器从描述中提取文本嵌入。然后,迭代优化图像和文本嵌入之间的距离,以使生成的说话面部与输入文本对齐。
2.3 目标函数



三、效果
3.1 实验设置
作者的 video 帧率都为 25FPS,audio 采样率都为 16kHz,视频大小为 256x256,mel-spectrogram window length 和 hop length 为 640
EAT 中 keypoints 的个数是 15
- enhance 3D latent keypoints:48 小时(4个3090)
- pretrain the A2ET with enhanced latent keypoints:48 小时(4个3090)
- finetune the EAT architecture :6 小时(4个3090)
数据集:
- VoxCeleb2:
- MEAD:有 8 种情感表情,使用人物来划分训练和测试,和 EAMM 的划分一样
3.2 效果对比