Redis 集群有哪些方案?
主从复制:解决了高并发问题
哨兵模式:解决了高并发,高可用问题
分片集群:解决了海量数据存储,高并发写的问题
主从复制
图示:
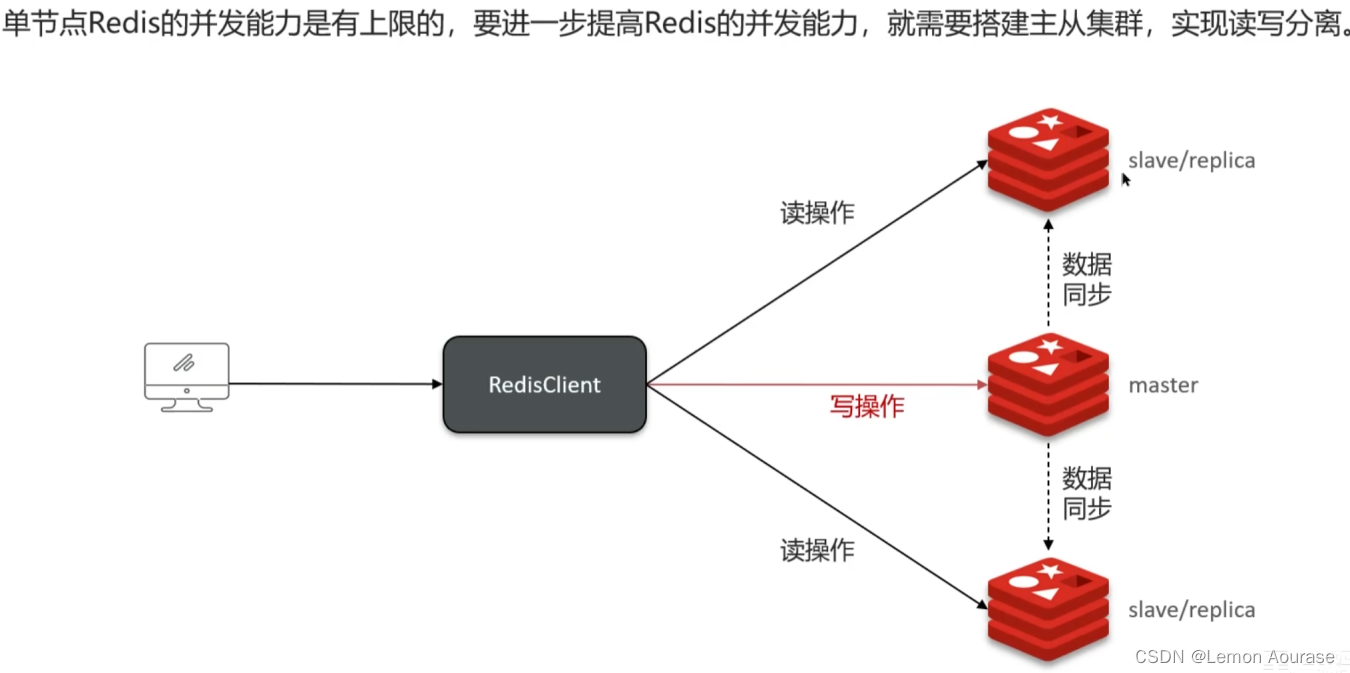
主从复制:单节点 Redis 并发能力有限,为了进一步提高 redis 并发能力,所以搭建主从集群,实现读写分离。主节点是写,从节点是读,这就是主从复制
主从同步流程,分为两种情况,分为全量同步和增量同步
全量同步

根据上图:
- 同步的时候,从节点首先会和 master 节点建立连接,携带replid、offset请求数据同步
- master 节点会判断是否第一次同步(是根据 replid 来进行判断)。
- 如果说是第一次,那么 master 就会返回 master 的数据版本信息(并且还会返回 replid 和 offset),进而从节点进行保存版本信息。
- 接下来 master 节点会执行 bgsave 命令,生成 RDB 文件,并发送给从节点。
- 从节点清空本地数据,加载 RDB 文件。
- 到这里,所有流程其实完毕了,但是在执行 bgsave 命令期间,肯定是会有新的命令执行的。所以说,在 master 节点执行 bgsave 命令期间,还会在 repl_baklog 中记录这期间所有命令,并发送给从节点,从节点收到后执行命令。这样就保证数据不会丢失。
- 假如根据 replid 判断发现不是第一次同步,那么这个时候就需要用到 offset 了。根据 offset 来进行判断偏移量,然后再次进行同步。
增量同步
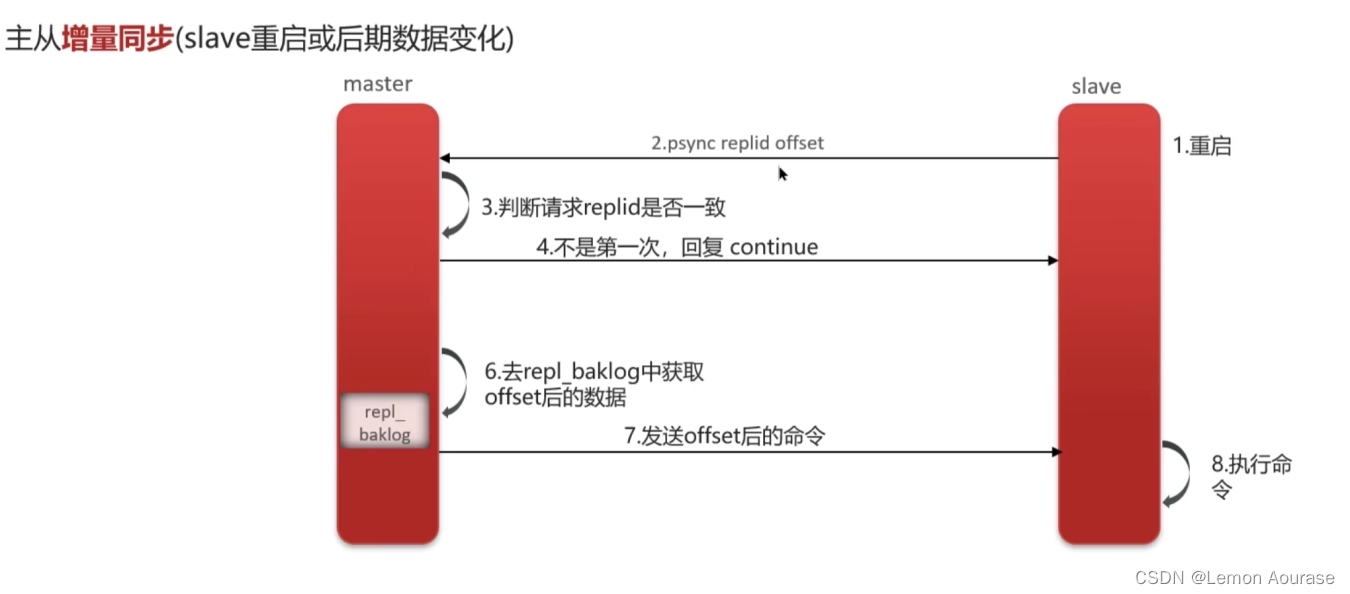
从节点发送同步请求,master 节点判断 replid 是否一致(肯定是一致的),不是第一次同步就会去日志文件中获取 offset 后的数据,然后发送repl_baklog文件中 offset 后的命令,从节点执行命令即可。
哨兵模式
主从复制解决了高并发问题,但是我们能保证Redis不宕机么?那万一宕机了,我们又怎么知道呢?那么就引入哨兵模式,哨兵模式的引入就保证了Redis的高可用问题。
哨兵模式三个作用:监控,自动故障恢复,通知

服务状态监控

哨兵模式中有心跳机制,每隔1s会向集群中每个实例发送ping命令,如果回复pong,那就说明OK。如果某一个哨兵发现某一个实例在一定时间里没有回应,那么认为该实例是主观下线。若是超过一定数量(最好是超过哨兵实例数量的一半。)的哨兵都认为这个实例主观下线,那么这个实例客观下线。
脑裂
脑裂:主节点、从节点、哨兵处于不同网络分区,导致哨兵没有感知到主节点,所以哨兵又选举出了一个从节点为主,这样就存在了两个master,这样导致客户端还在老的主节点那里写数据,新节点无法同步。当网络恢复后,哨兵将老的主节点降为从节点,这是再从新的主节点同步数据,就会导致数据丢失。
解决办法:修改Redis的配置,设置最少的从节点数量以及缩短主从数据同步的延迟时间,达不到要求就拒绝请求。
分片集群
虽然主从复制保证了高并发,哨兵模式保证了高并发和高可用,但是海量数据存储、高并发写的问题并没有解决,那么分片集群就是为了解决上述两个问题。
图示:
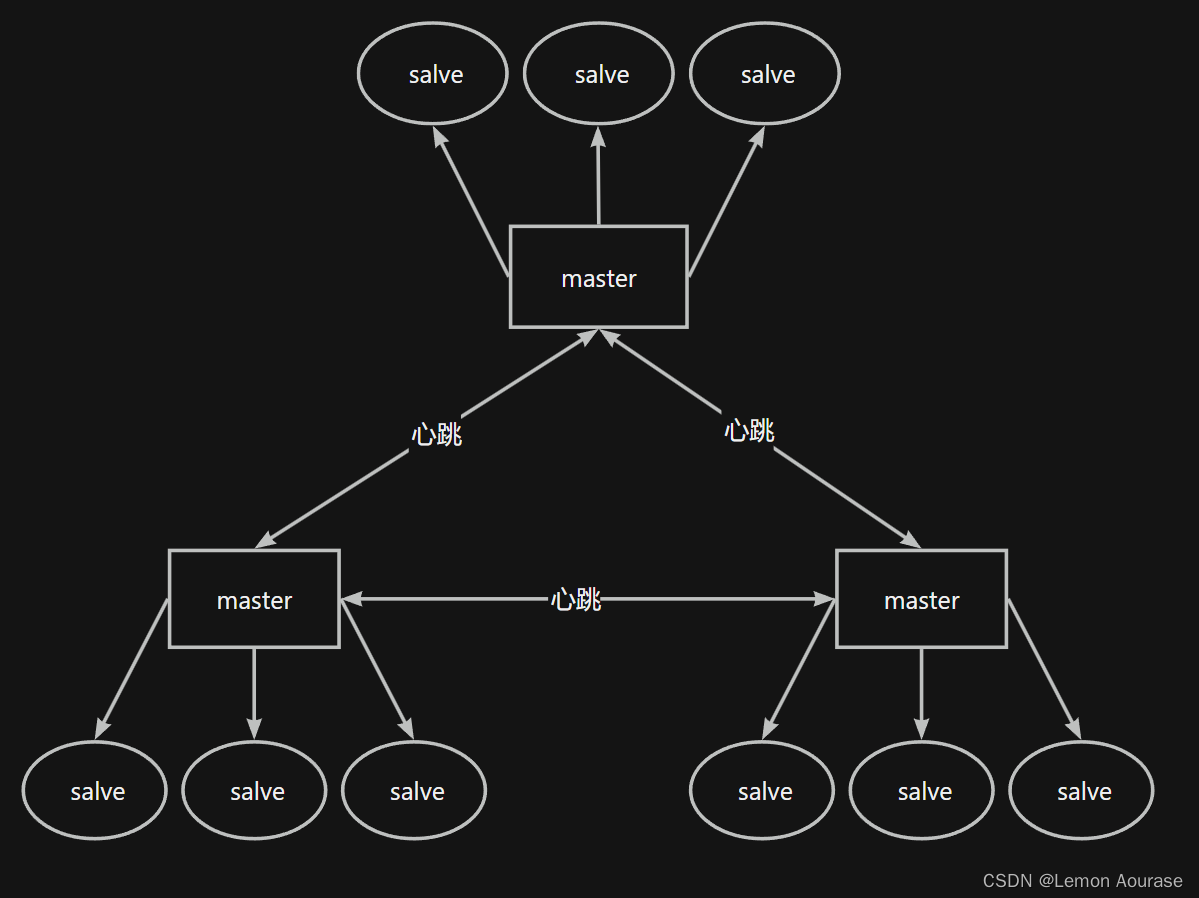
- 集群中有多个master,每个master保存不同数据
- 每个master都可以有多个从节点
- master之间通过ping监测彼此健康状态(就不需要哨兵存在了)
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
分片集群-数据读写
换句话说,分片集群中有很多Master节点,那么 Redis 集群在存储/读取数据时如何确定选择哪个节点呢?
解决方案:
- Redis分片集群引入了哈希槽的概念,Redis集群有16384个哈希槽
- 将16384个槽分配到不同的实例
- 读写数据:根据key的有效部分(有效部分:如果key前面有大括号,大括号的内容就是有效部分;如果没有,就以key本身作为有效部分)计算哈希值,对16384取余,余数作为插槽,寻找插槽所在实例
Redis 是单线程的,为什么那么快?
- Redis纯内存操作,操作速度非常快
- Redis采用单线程,避免不必要的上下文切换可竞争条件,多线程还要考虑线程安全问题。
- Redis采用IO多路复用模型
什么是 I/O 多路复用模型?
Redis 是纯内存操作,执行速度非常快,它的性能瓶颈是网络延迟,而不是执行速度。 I/O 多路复用模型就是为了实现高效的网络请求。
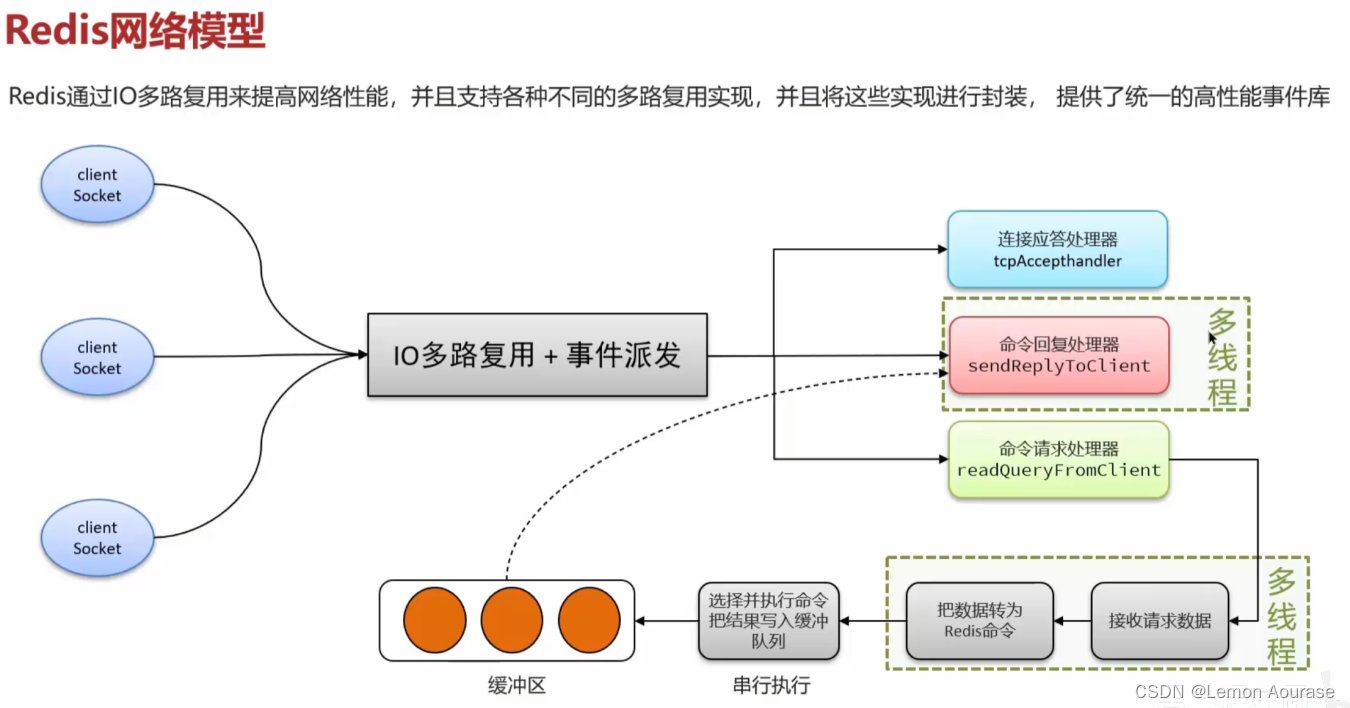
注意:有些时候,我们可能看到说Redis6.0之后引入多线程,在这里引入多线程要明白,是指接收网络请求,指令转换的那一部分采用多线程,是为了进一步解决网络瓶颈,并不是执行命令的时候。
Redis执行命令依旧是单线程。
面试题:

参考链接
https://www.bilibili.com/video/BV1yT411H7YK?p=19