利用一些有用的属性来总结树的工作原理,其中最常用的事特征重要性,它为每个特征树的决策的重要性进行排序。对于每个特征来说,它都是介于0到1之间的数字,其中0代表“根本没有用到”,1代表“完美预测目标值”。特征重要性的求和为1。
将特征重要性进行可视化:
import mglearn.datasets
import numpy as np
from sklearn.tree import DecisionTreeClassifier,export_graphviz
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
from sklearn.datasets import load_breast_cancer
def plot_importances(model):
n_feature=cancer.data.shape[1]
plt.barh(range(n_feature),model.feature_importances_,align='center')
plt.yticks(np.arange(n_feature),cancer.feature_names)
plt.xlabel('特征重要性')
plt.ylabel('特征')
plt.rcParams['font.sans-serif'] = ['SimHei']
cancer=load_breast_cancer()
X_train,X_test,y_train,y_test=train_test_split(
cancer.data,cancer.target,stratify=cancer.target,random_state=42
)
tree=DecisionTreeClassifier(max_depth=4,random_state=0)
tree.fit(X_train,y_train)
plot_importances(tree)
plt.show()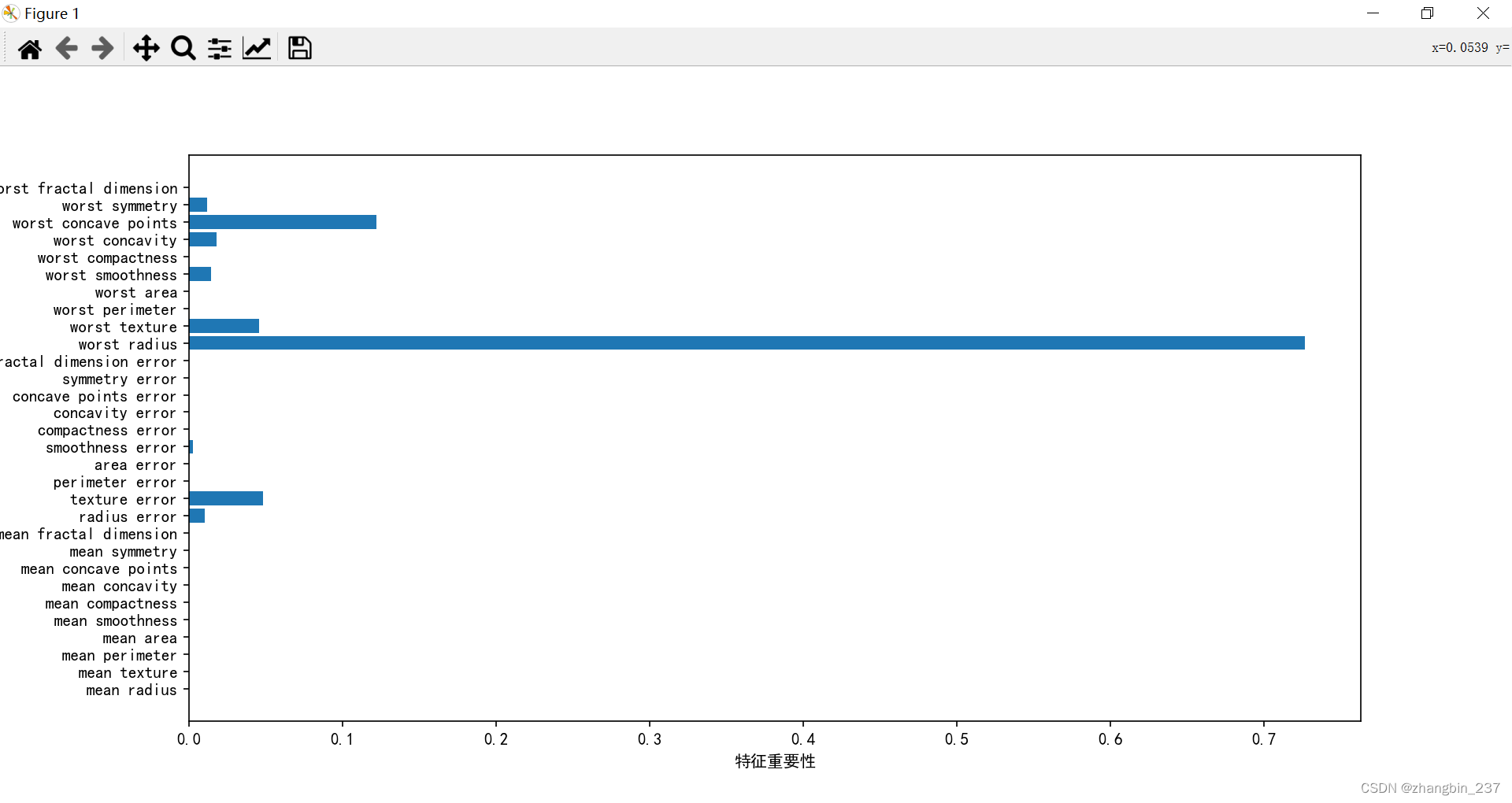
可以看到,“worst radius” 是最重要的特征。
如果某个特征的feature_importance_很小,不代表这个特征没有提供任何信息,只能说明这个特征没有被树选中,可能是因为另一个特征也包含的同样的信息。
与线性模型的系数不同,决策树的特征重要性一定为正数。