1写在前面
上次介绍了两组发生率的样本量计算方法,通过pwr包进行计算非常简单,可以有效地减少我们的工作量。😘
有时候我们想比较两组之间的均值,如何计算样本量又一次成了老大难问题。🤒
本期我们还是基于pwr包,试一下通过两组的均值进行样本量的估算。😏
2用到的包
rm(list = ls())
library(pwr)
library(tidyverse)
3研究假设
还是假设我们正在进行一项RCT研究,旨在评估Treatment A和Treatment B之间血红蛋白A1c (HbA1c)相对于基线的平均变化的差异。🤪
我们先提出研究假设, 和 :👇
: Treatment A和Treatment B间HbA1c相对于基线的平均变化没有差异。: Treatment A和Treatment B间HbA1c相对于基线的平均变化存在差异。
接着我们还有几个参数需要设置:👇
alpha level(通常为two-sided);effect size(Cohen’s d);power(通常为80%);
4计算样本量
Treatment A和Treatment B的HbA1c平均变化我们还是需要检索既往文献,然后做出假设。😉
这里我们假设Treatment A的预期平均变化为1.5%,标准差为0.25%,Treatment B的预期平均变化为1.0%,标准差为0.20。🥳
4.1 计算并合标准偏差
首先我们计算一下并合标准偏差(pooled standard deviation, σpooled)。😂
sd1 <- 0.25
sd2 <- 0.30
sd_pooled <- sqrt((sd1^2 +sd2^2) / 2)
sd_pooled

4.2 计算Cohen’s d
得到了σpooled,我们就可以计算Cohen’s d了。🥰
mu1 <- 1.5
mu2 <- 1.0
d <- (mu1 - mu2) / sd_pooled
d

4.3 pwr计算样本量
现在,我们可以利用pwr包计Treatment A和Treatment B之间平均HbA1c变化差0.5%(1.5% - 1.0%)所需的样本量,具有 80%的power和0.05的显著性。
n_i <- pwr.t.test(d = d, power = 0.80, sig.level = 0.05)
n_i

Note! 这里我们得到每组需要6个受试者。🤔
5Power Analysis
接着是效力分析(Power Analysis),还是和之前的一样,如果结果不好的话,我们应该修改或者直接终止实验。🫠
我们绘制一下Power随着样本量的变化吧。🥳
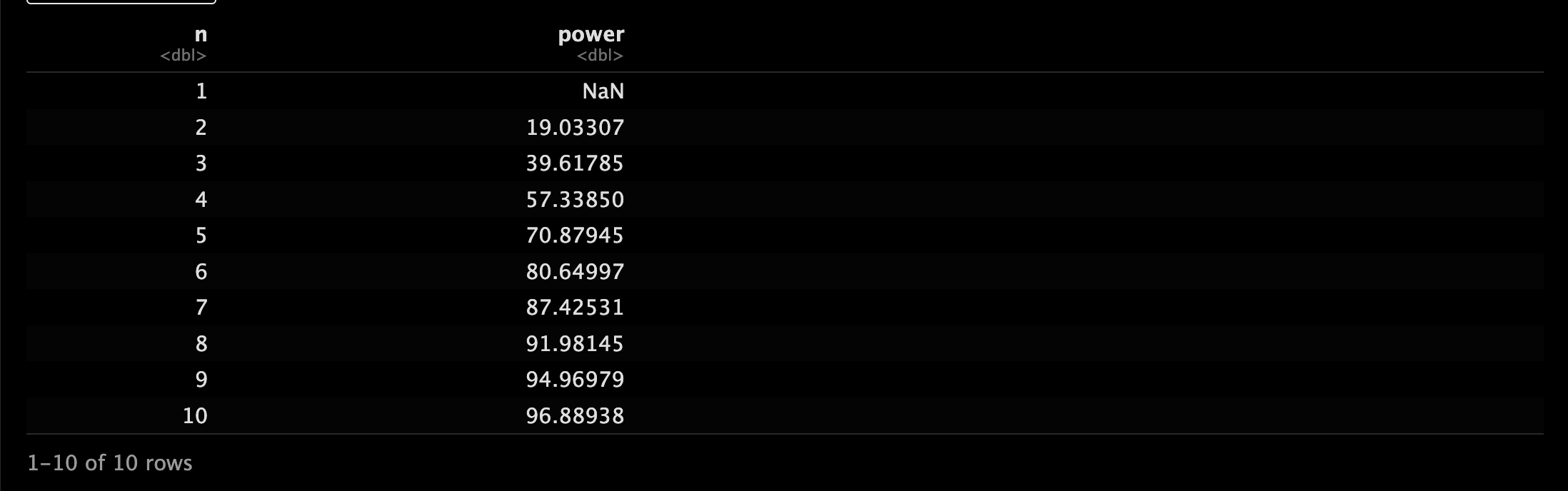
n <- seq(1, 10, 1)
nchange <- pwr.t.test(d = d, n = n, sig.level = 0.05)
nchange.df <- data.frame(n, power = nchange$power * 100)
nchange.df
plot(nchange.df$n,
nchange.df$power,
type = "b",
xlab = "Sample size, n",
ylab = "Power (%)")
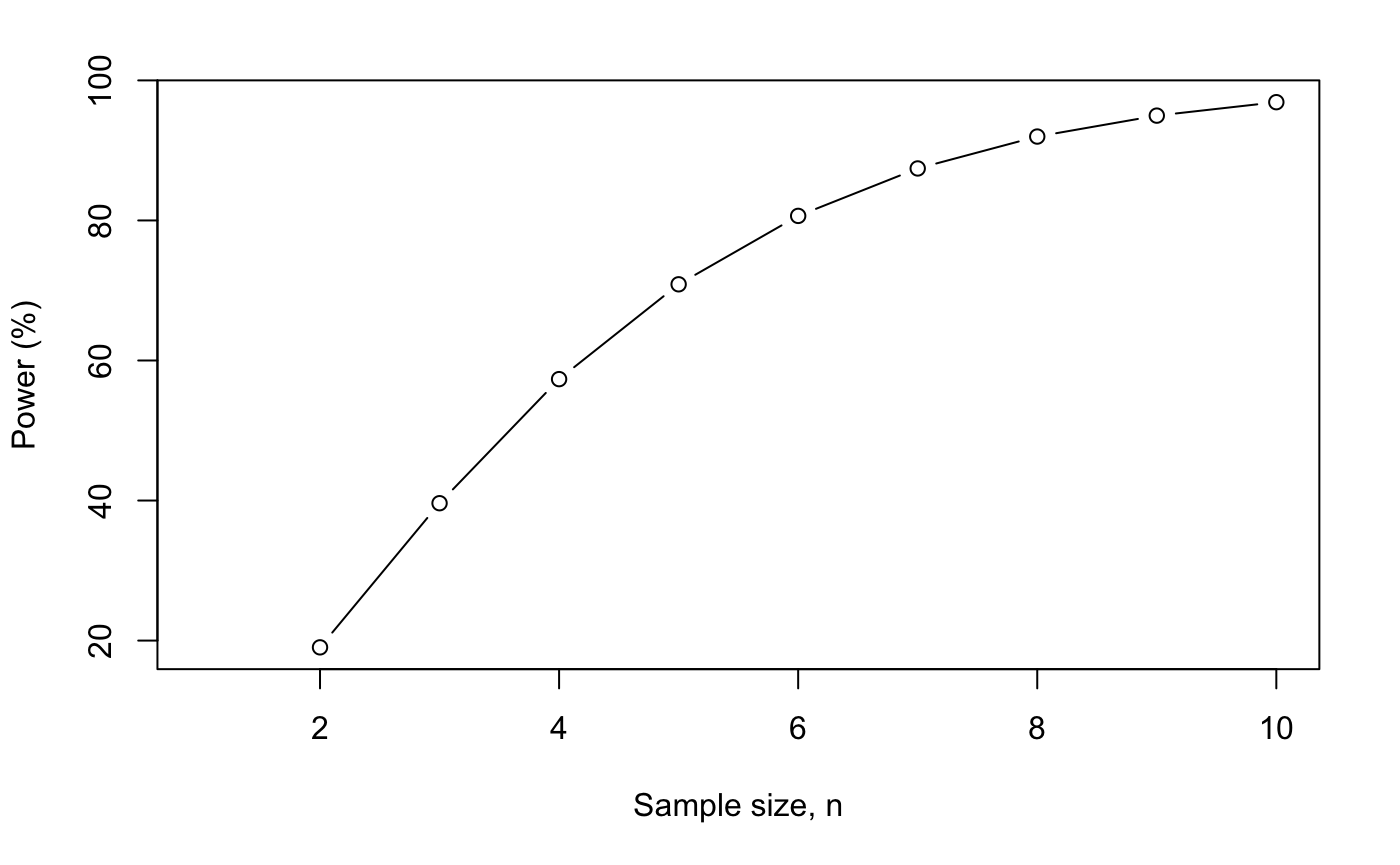
随着样本量的增加,power也是不断增加的。😗
与我们之前的例子一样,随着我们增加样本量,我们减少了估算的不确定性。🤤 通过减少这种不确定性,有效减少了犯II类错误的可能性。🥸
6改变一下
接着我们固定一下两组各位6例受试者,alpha为0.05。😬
我们再改变一下Treatment A的HbA1c相对于基线的平均变化设为0-2%,间隔为0.1%。🤒
mu1 <- seq(0.0, 2.0, 0.1)
d <- (mu1 - mu2) / sd_pooled
power1 <- pwr.t.test(d = d, n = 6, sig.level = 0.05)
powerchange <- data.frame(d, power = power1$power * 100)
powerchange
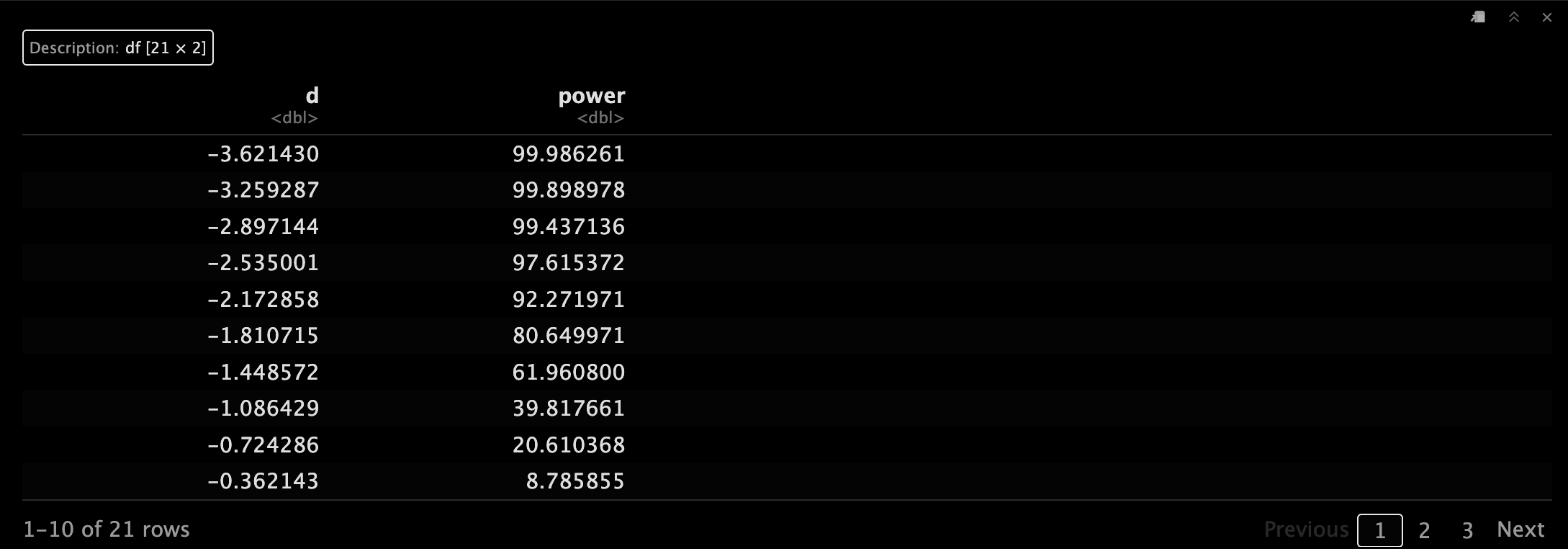
随着Cohen's d的绝对值增大,power也随之增大。⤴️ 也就是说在固定样本大小的情况小,两组间差异越大我们越有可能得到阳性结果。🤠
相反,如果差异很小,那么我们在当前样本量6的情况下没有足够的把握得到阳性结果。🤒
plot(powerchange$d,
powerchange$power,
type = "b",
xlab = "Cohen's d",
ylab = "Power (%)")

点个在看吧各位~ ✐.ɴɪᴄᴇ ᴅᴀʏ 〰
📍 🤩 ComplexHeatmap | 颜狗写的高颜值热图代码!
📍 🤥 ComplexHeatmap | 你的热图注释还挤在一起看不清吗!?
📍 🤨 Google | 谷歌翻译崩了我们怎么办!?(附完美解决方案)
📍 🤩 scRNA-seq | 吐血整理的单细胞入门教程
📍 🤣 NetworkD3 | 让我们一起画个动态的桑基图吧~
📍 🤩 RColorBrewer | 再多的配色也能轻松搞定!~
📍 🧐 rms | 批量完成你的线性回归
📍 🤩 CMplot | 完美复刻Nature上的曼哈顿图
📍 🤠 Network | 高颜值动态网络可视化工具
📍 🤗 boxjitter | 完美复刻Nature上的高颜值统计图
📍 🤫 linkET | 完美解决ggcor安装失败方案(附教程)
📍 ......
本文由 mdnice 多平台发布