二、Fusion
融合不同的多模态信息,与bridge相比,融合更关注项目之间的多模态内部关系。
它可以灵活地融合不同权重和焦点的多模态信息。
注意机制是应用最为广泛的特征融合。
2.1 粗粒度注意力。
一些模型应用注意力机制在粗粒度级别融合来自多种模式的信息。
注:将多模态信息分为用户侧和项目侧,包括各自的id信息和side信息:UVCAN、MCPTR。
UVCAN: User-Video Co-Attention Network for Personalized Micro-video Recommendation 2019
UVCAN将多模态信息分为用户侧和物品侧,包括各自的id信息和side信息。它利用用户侧的多模态数据,通过自注意力生成项目侧的融合权重。
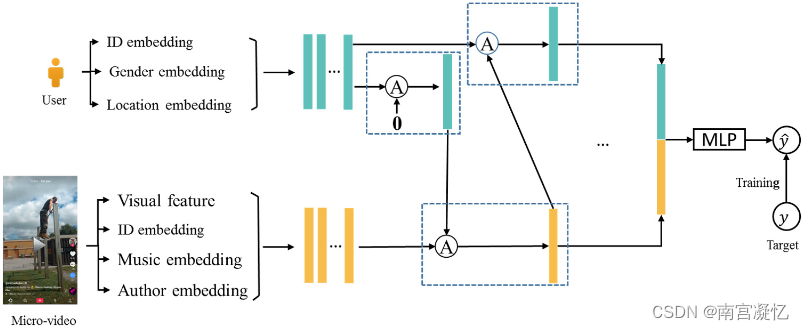
协同过滤的插图通过三步推理堆叠了注意力网络框架来探索用户对微视频特征的关注。
MCPTR: Multi-Modal Contrastive Pre-training for Recommendation 2022
MCPTR建议并行合并项目和用户信息。每个模态占据相同的位置,自注意力机制决定融合权重。
方法包含两个过程:预训练和微调。
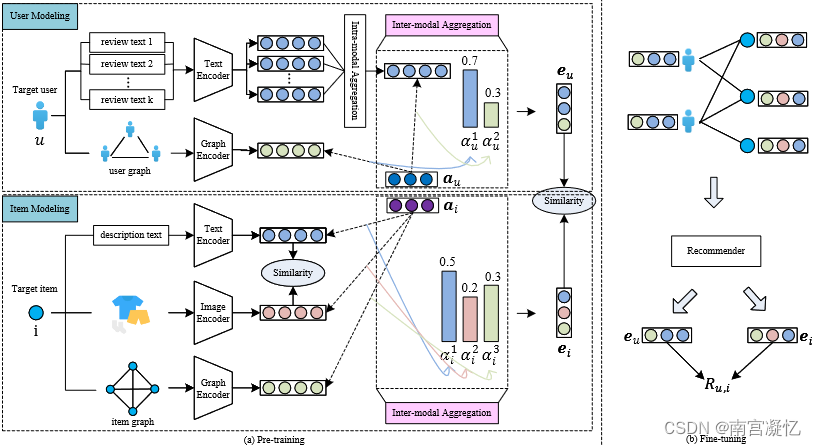
在预训练阶段,我们提出了一种基于辅助信息和隐式反馈矩阵 R 的多模态对比表示模型。具体来说,我们提出的预训练模型包含两个组成部分:用户建模和项目建模。
在用户建模部分,我们首先使用文本编码器来获取每个评论文本的表示,然后使用模内聚合来获取用户的评论嵌入。接下来,应用图编码器来捕获齐次图 Gu 的结构信息。对于这两种不同的模态信息,我们开发了模态间聚合以获得用户的多模态表示。
在项目建模中,我们利用文本编码器、图像编码器和图编码器对每个项目的描述文本、图像和齐次图 Gi 进行编码。然后,我们应用模间聚合来获得项目的多模态表示。此外,由于对于同一项目,描述文本和图像信息是互补的,因此它们具有相似的语义。我们开发了一种自我监督的对比学习方法来调整它们之间的表示。
最后,采用基于反馈矩阵R的二元交叉熵损失函数来捕获目标用户u与其对应的目标项目i的潜在相关性。在微调过程中,现有的推荐模型利用预先训练的用户/项目嵌入作为初始化,并仅基于反馈矩阵 R 微调这些嵌入。
注:CMBF、MML、MCPTR、HCGCN引入交叉注意力机制来分别共同学习图像和文本模态的语义信息。
CMBF: Cross-Modal-Based Fusion Recommendation Algorithm 2021
CMBF引入交叉注意力机制来分别共同学习图像和文本模态的语义信息,然后将它们连接起来。
现有的多模态推荐算法都是提取单一模态的特征并简单拼接不同模态的特征来预测推荐结果。这种融合方法不能完全挖掘多模态特征的相关性,丢失了不同模态之间的关系,影响了预测结果。
在本文中,我们提出了一种基于跨模态的融合推荐算法(CMBF),该算法可以捕获单模态特征和跨模态特征。我们的算法使用一种新颖的跨模态融合方法来完全融合多模态特征并学习不同模态之间的交叉信息。
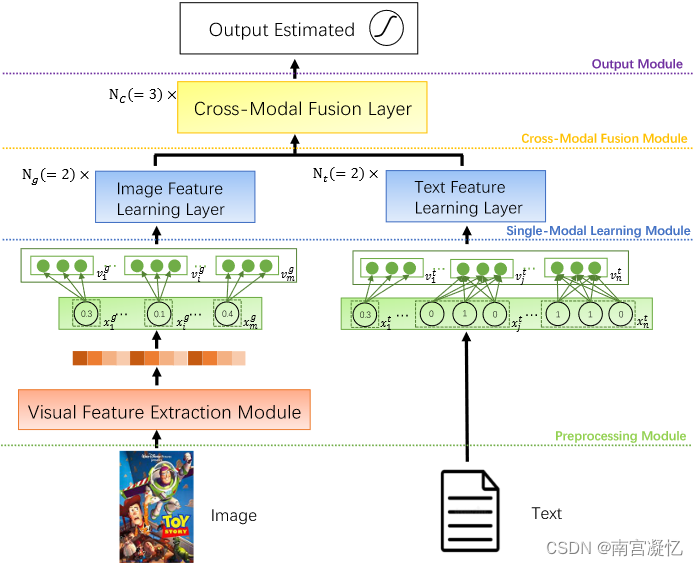
基于CMBF的拟议框架概述。图像/文本特征学习层和跨模态融合层的详细信息分别如图2和图3所示。
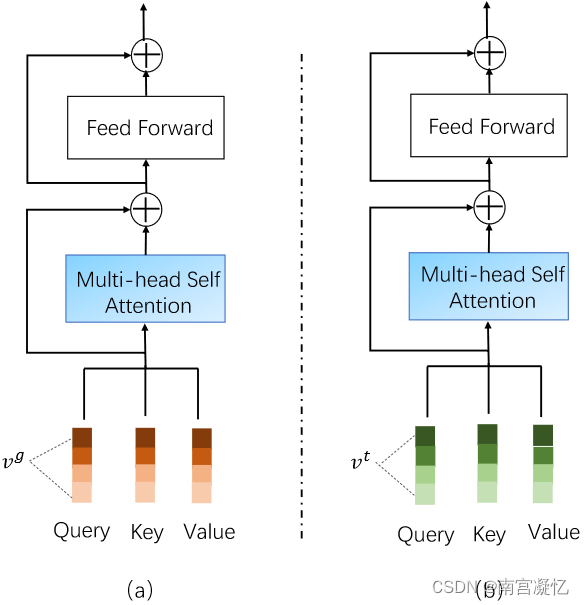
特征学习层的图示。(a)代表图像特征学习层,(b)代表文本特征学习层。
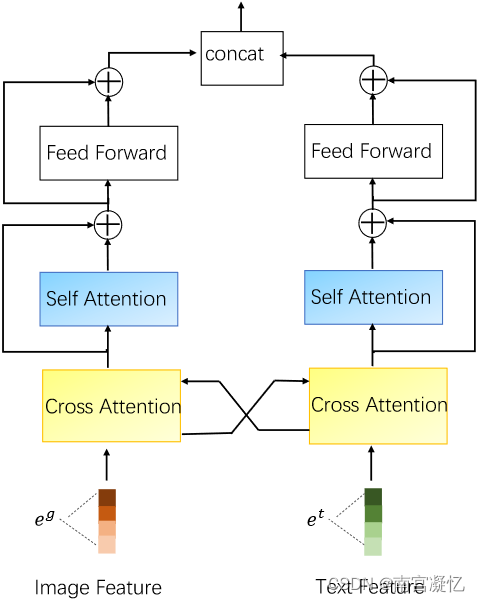
跨模式融合层的图示。
MML: Multimodal Meta-Learning for Cold-Start Sequential Recommendation 2022
MML基于id信息设计了一个注意力层,并辅以视觉和文本信息。
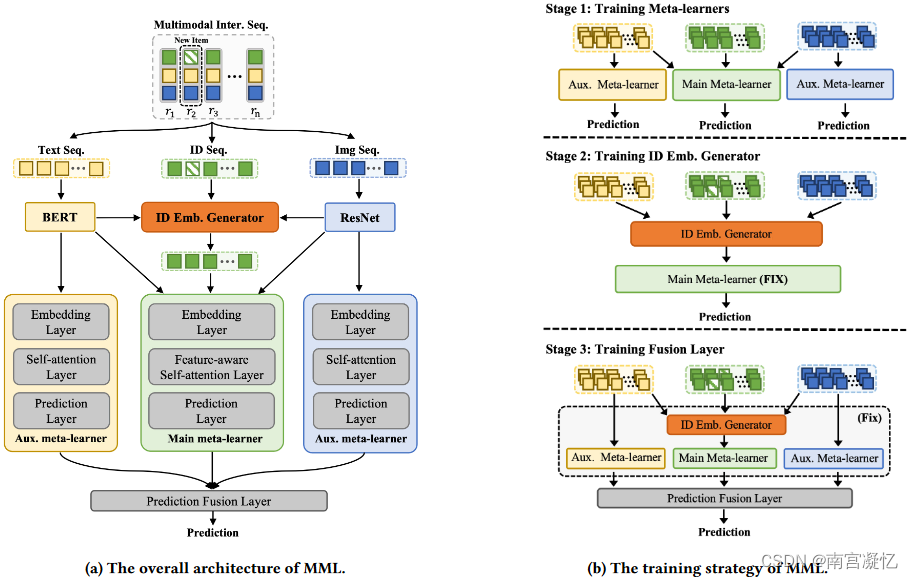
在MAML框架下,我们提出的MML将多模态信息(即相关的文本和图像数据)作为一种辅助信息纳入元学习过程中,以减少任务发散并提高跨任务知识迁移的有效性。具体来说,我们在两个方面利用项目的多模态信息。
首先,为了尽量减少新老用户顺序特征的差异,我们精心设计了一组对应三种不同模态(即ID、文本和图像)的多模态元学习器,这可以通过参考彼此的预测来稳定和改进元训练过程。
其次,考虑到新项目的特征差异,我们设计了一个冷启动项目嵌入生成器,它利用多模态信息来预热新项目的 ID 嵌入。 MML的整体架构如图1(a)所示。
为了快速适应数据不足的冷启动用户,我们将MAML扩展到我们的场景,并设计一个三阶段算法来训练元学习器、嵌入生成器和依次预测融合层如图1(b)所示。文章详细介绍了训练算法。
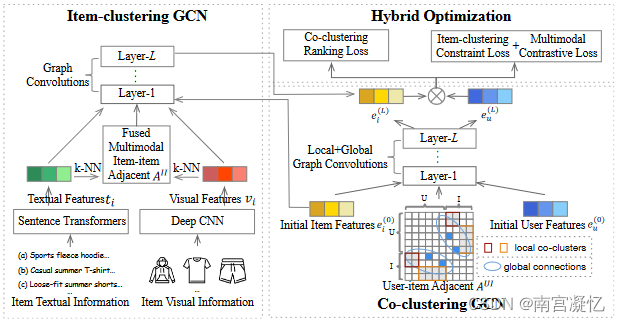
HCGCN: Learning Hybrid Behavior Patterns for Multimedia Recommendation 2022
MCPTR每个模态占据相同的位置,自注意力机制决定融合权重。相比之下,HCGCN更关注项目本身的视觉和文本信息。
2.1 细粒度注意力。
多模态数据包含全局和细粒度特征,例如录音的音调或一件衣服上的图案。
由于粗粒度融合通常是侵入性和不可逆的,它会损坏原始模态的信息并降低推荐性能。
细粒度融合,选择性地融合不同模态之间的细粒度特征信息
注:细粒度融合在时尚推荐场景中意义重大。
POG: Personalized Outfit Generation for Fashion Recommendation at Alibaba iFashion 2019
POG是一个基于Transformer架构的大型在线服装推荐系统。在编码器中,通过多层注意力挖掘时尚图像中属于搭配方案的深层特征,不断实现细粒度的集成。
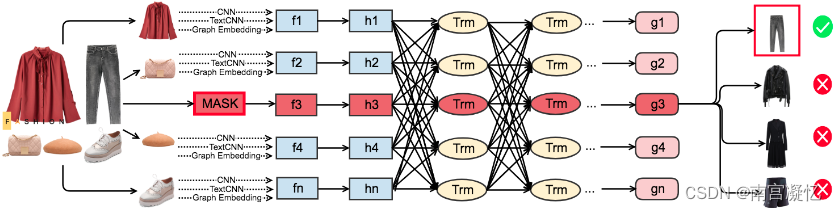
FOM 的架构。我们一次掩盖一件衣物。例如,我们在套装中遮盖一条牛仔裤。模型学会从候选池中选择正确的牛仔裤,以完成对套装中其它衣物的搭配。
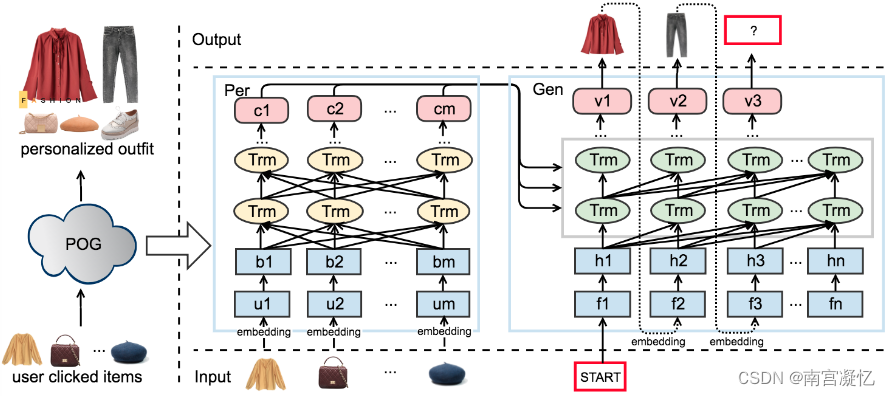
POG的架构,是一个带有Per网络和Gen网络的编码器-解码器架构。套装物品是根据Per网络的用户偏好信号和Gen网络的兼容性信号逐步生成的。
NOR: Explainable Outfit Recommendation with Joint Outfit Matching and Comment Generation 2019
NOR应用了编码器-解码器变压器架构,其中包含细粒度的自注意力结构。它可以根据搭配信息生成相应的方案描述。
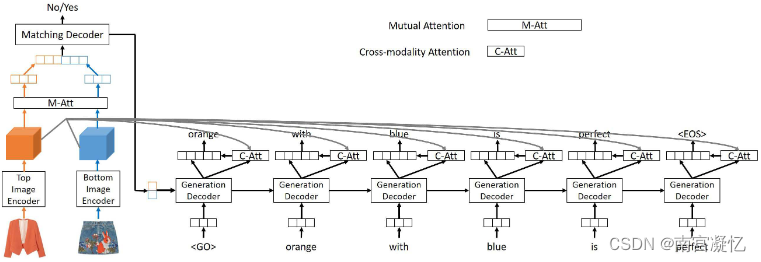
所提出的神经套装推荐 (NOR) 架构的概述。 NOR包含三个部分:(1)顶部和底部图像编码器(对应图(a)),(2)匹配解码器(对应图(b)),以及(3)生成解码器(对应于图©)。
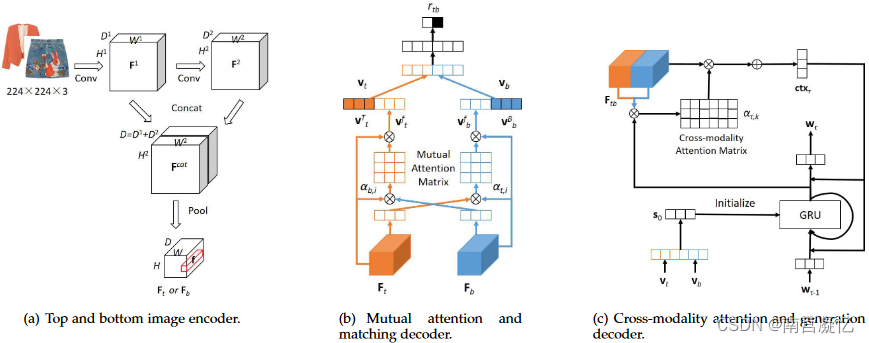
神经时尚推荐架构 (NOR) 的详细信息。 (a) 顶部和底部图像编码器从图像中提取视觉特征 Ft 和 Fb。 (b) 使用相互注意机制,我们将视觉特征转换为潜在表示vt和vb。然后匹配解码器预测匹配指示符rtb。 © 在每个时间戳 τ 处,生成解码器采用跨模态注意机制来生成单词 wτ 。
EFRM: Explainable Fashion Recommendation: A Semantic Attribute Region Guided Approach 2019
EFRM还设计了语义提取网络(SEN)来提取局部特征,最后将两个特征与细粒度的注意力偏好融合。
大多数先前的时尚推荐模型都以全局内容表示来理解服装图像,缺乏对用户语义偏好的详细理解,这通常会导致推荐性能较差。
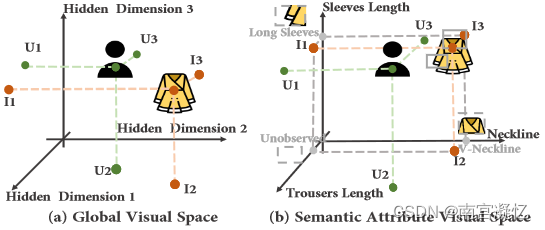
传统的(a)全局视觉空间和我们的(b)语义属性视觉空间之间的区别。
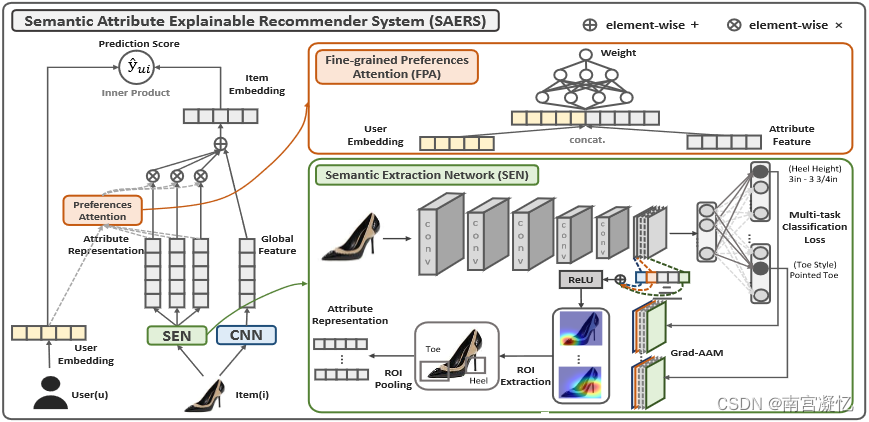
SAERS包含两个主要组件,即语义提取网络(SEN)和细粒度偏好注意(FPA)。
具体来说,利用 SEN,我们首先获得语义特征空间中的时尚商品投影。接下来,我们设计 FPA 将用户投影到相同的语义特征空间中。
然后,我们在成对学习框架下共同学习全局视觉空间和语义属性视觉空间中的项目表示。
最后,通过属性偏好推断,我们可以生成可解释的推荐。
VECF: Personalized Fashion Recommendation with Visual Explanations based on Multimodal Attention Network 2019
VECF执行图像分割,将每个补丁的图像特征与其他模态集成。
对于一个时尚图像来说,并不是所有的区域对于用户来说都同样重要,即人们通常会关心时尚图像的少数部分。为了模拟这种人类感觉,我们在许多预先分割的图像区域上学习了一个注意力模型,基于该模型我们可以了解用户对图像上的哪些地方真正感兴趣,并相应地以更准确的方式表示图像。此外,通过发现这种细粒度的视觉偏好,我们可以通过突出显示图像的某些区域来直观地解释推荐。
为了更好地学习注意力模型,我们还引入了用户评论信息作为弱监督信号,以收集更全面的用户偏好。在我们的最终框架中,视觉和文本特征通过多模态注意力网络无缝耦合。
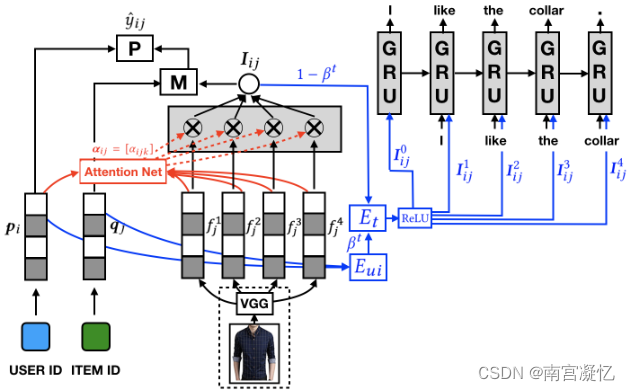
所提出的 VECF 模型。红线表示为时尚形象建模设计的注意力机制。蓝线突出显示了用户评论的建模。
UVCAN: User-Video Co-Attention Network for Personalized Micro-video Recommendation
UVCAN像VECF一样对视频截图进行图像分割,并通过注意力机制分别将图像块与id信息和文本信息融合。
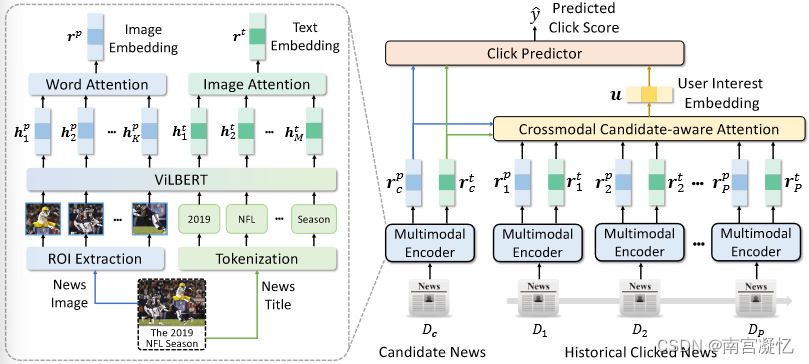
MM-Rec: Multimodal News Recommendation 2022
MM-Rec首先通过目标检测算法Mask-RCNN从新闻图像中提取感兴趣区域,然后利用共同注意力将POI与新闻内容融合。

在论文中,我们提出了一种名为 MM-Rec 的多模态新闻推荐方法,该方法利用文本和视觉新闻信息进行新闻推荐。
在我们的方法中,我们首先通过预训练的 Mask R-CNN 模型提取新闻图像的兴趣区域 (ROI) 以进行对象检测。
然后,我们使用预先训练的视觉语言模型对新闻文本和新闻图像 ROI 进行编码,并通过共同注意 Transformer 对其固有的跨模态相关性进行建模,以学习准确的多模态新闻表示。
此外,我们还提出了一种跨模态候选新闻感知注意力网络,通过评估候选新闻与点击新闻之间的跨模态相关性,选择相关的点击新闻进行用户建模,这有助于模拟用户对候选新闻的特定兴趣。
注:有些模型设计了独特的内部结构,以实现更好的细粒度融合。
MKGformer: Hybrid Transformer with Multi-level Fusion for Multimodal Knowledge Graph Completion 2023
MKGformer通过共享一些QKV参数和相关的感知融合模块来实现细粒度的融合。
大多数多模态知识图谱MKG远未完成,不同的任务和模式需要改变模型架构,并且并非所有图像/对象都与文本输入相关,这阻碍了对不同现实场景的适用性。 我们提出了一种具有多级融合的混合变压器来解决这些问题。具体来说,我们利用具有统一输入输出的混合变压器架构来完成各种多模态知识图任务。此外,我们提出了多级融合,它通过粗粒度前缀引导交互和细粒度相关感知融合模块集成了视觉和文本表示。
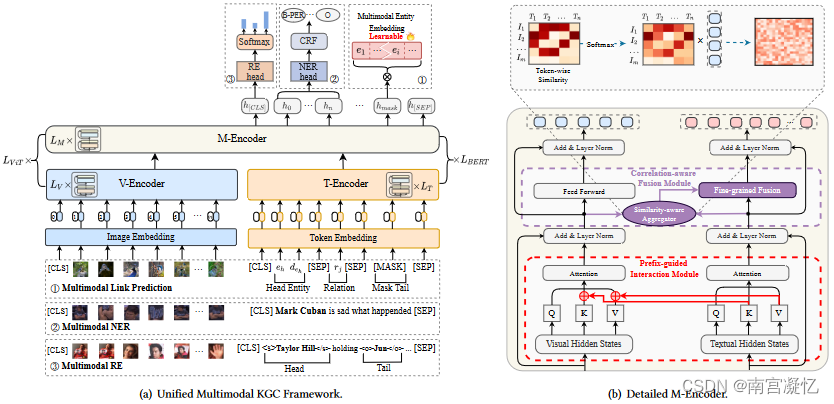
MKGformer,一种用于统一多模态 KGC 的混合 Transformer,它实现了跨视觉 Transformer 和文本 Transformer 的最后几层的实体多模态特征的多级融合建模,即 M-编码器。
之前的工作表明预训练模型(PLM)可以激活与 Transformer Encoder 中的自注意力层和前馈网络(FFN)层的输入相关的知识。受此启发,我们将视觉信息视为补充知识,并在 Transformer 架构中提出多级融合。
具体来说,我们首先在 M-Encoder 的自注意力部分提出一个粗粒度的前缀引导交互模块,以预先减少下一步的模态异质性。其次,M-Encoder 的 FFN 部分提出了相关感知融合模块,以获得细粒度的图像文本表示,从而减轻不相关图像/对象的错误敏感性。特别是,除了多模态链接预测之外,MKGformer 可以通过对特定任务头的简单修改来更广泛地应用于 MRE 和 MNER 任务,如图(a)所示。
MGAT: Multimodal Graph Attention Network for Recommendation 2020
MGAT使用门控注意力机制来关注用户的本地偏好。

MARIO: Modality-Aware Attention and Modality-Preserving Decoders for Multimedia Recommendation 2022
MARIO通过考虑每种方式对每次交互的个体影响来预测用户偏好。因此模型设计了一种模态感知注意力机制来识别各种模态对每次交互的影响,并对不同模态进行点乘。
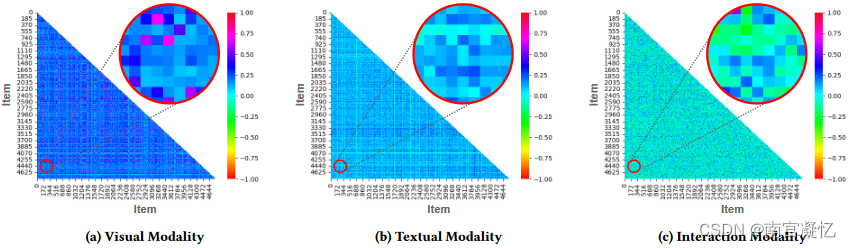
项目对在(a)视觉模态、(b)文本模态和(c)交互模态方面的相似性。每个子图中的放大部分显示了相同项目对之间的相似性。结果表明,即使对于相同的项目对,它们的视觉模态、文本模态和交互模态的相似性也有很大差异。
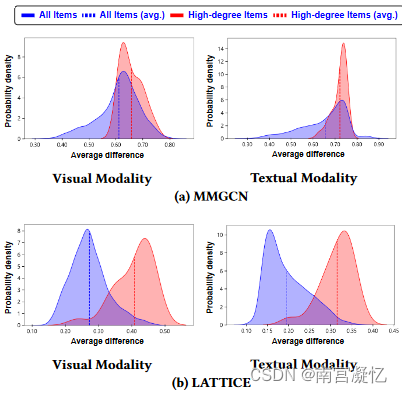
预训练项目嵌入(从每种模态获得)的相似性与最终项目嵌入(通过 MMGCN 和 LATTICE 获得)的相似性之间差异的密度函数。预训练嵌入中的模态特定属性未准确保留在最终嵌入中。
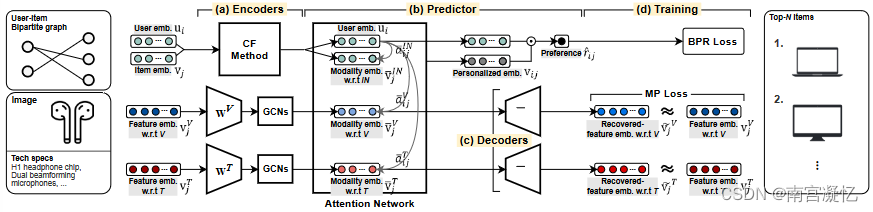
MARIO概述,由三个组件组成:(C1)基于交互和多模态信息的编码器; (C2) 基于注意力网络的预测器; (C3) 用于模态保存的解码器。
首先,MARIO获得每个ui的嵌入ui∈Rd和每个vj的多重模态嵌入 ̄ vVj , ̄ vTj, ̄ vINj ∈ Rd 分别对应视觉、文本和交互模态(图 4- (A))。
给定 ui 、 ̄ vVj 、 ̄ vTj 和 ̄ vINj ,MARIO 使用注意力网络来推断每个模态 m 对 ui 和 vj 之间的每次交互的影响 ̄ amij 。然后,MARIO 根据模态特定的影响获得 vj 相对于 ui 的个性化嵌入,我们用 vij ∈ Rd 表示(图 4-(b))。
基于 ui 和 vij ,MARIO 预测每个用户 ui 对每个项目 vj 的偏好 ˆrij 。同时,MARIO 使用解码器在其个性化嵌入 vij 中保留每个 vj 的模态特定属性(图 4-©)。
最后,MARIO 更新 ui 、 ̄ vVj 、 ̄ v Tj 和 ̄ vINj ,旨在共同最小化两个损失(图 4-(d)):(1)贝叶斯个性化排名(BPR)损失,用于保留ui 和 vj 的交互信息以及(2)模态保留(MP)损失,用于保留 vj 相对于视觉和文本模态的模态特定属性。
2.3 联合注意力。
基于细粒度融合,一些模型设计了组合融合结构,希望细粒度特征的融合也能保留全局信息的聚合。
Non-invasive Self-attention for Side Information Fusion in Sequential Recommendation 2021
NOVA 将辅助信息引入顺序推荐。它指出,直接将不同的模态特征与普通注意力融合通常效果很小,甚至会降低性能。因此,它提出了一种具有两个分支的非侵入式注意力机制,将id嵌入到一个单独的分支中,以在融合过程中保留交互信息。
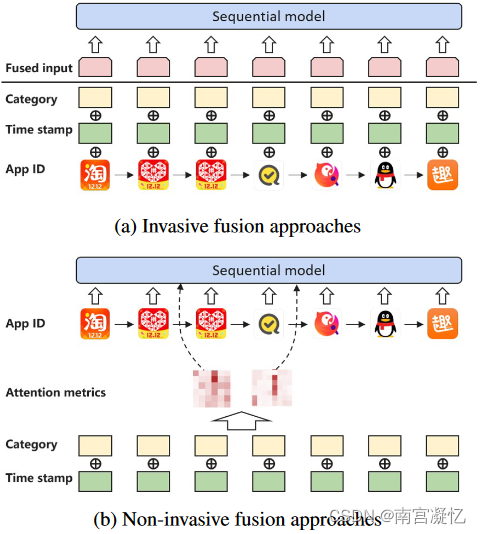
侵入性和非侵入性方法的图示。侵入式方法不可逆地融合各种信息,然后将它们输入顺序模型。对于非侵入式方法,边信息仅参与注意力矩阵计算,而项目信息保存在独立的向量空间中。
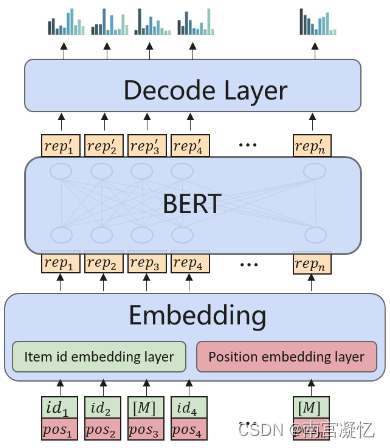
BERT4Rec.项目 ID 和位置分别编码为向量,然后加在一起作为集成的项目表示。在训练期间,项目 ID 被随机屏蔽(显示为 [M])以便模型恢复。
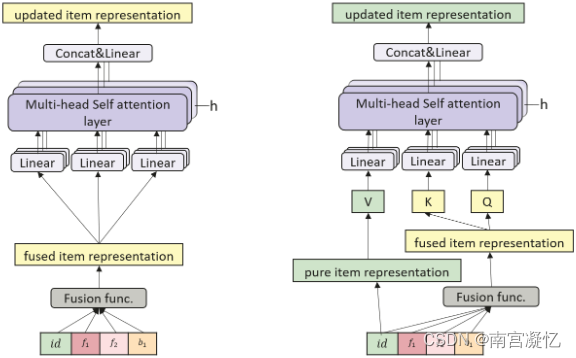
用于特征融合的侵入式和非侵入式自注意力方式的比较。两者都通过融合函数融合项目相关和行为相关的辅助信息,但 NOVA 仅在 Query & Key 中融合它们。
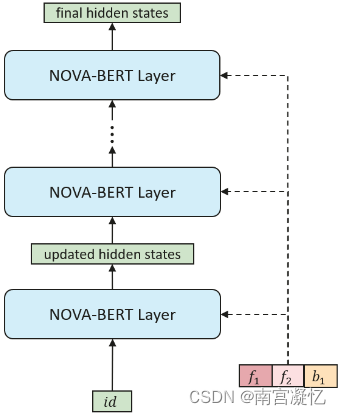
NOVA-BERT。每个 NOVA 层都有两个输入:项目表示和辅助信息。
NRPA: Neural Recommendation with Personalized Attention 2019
NRPA提供了一个个性化的注意力网络,它考虑了用户评论所代表的用户偏好。它利用个性化的词级注意力为每个用户/项目选择评论中更重要的词,并依次通过细粒度和粗粒度的融合传递评论信息注意力层。
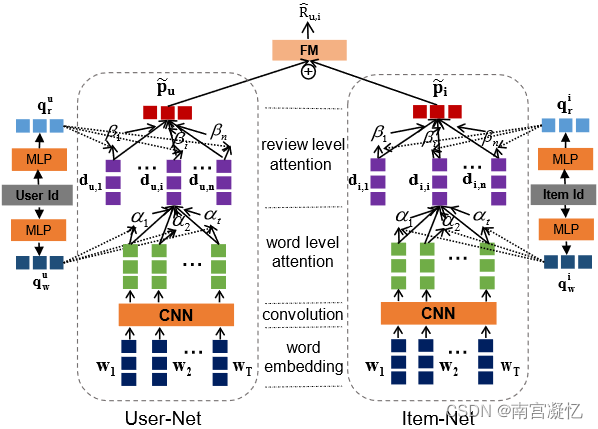
NRPA 包含两个组件,即,用于学习评论表示的评论编码器,用于从评论中学习用户/项目表示的用户/项目编码器。
在评论编码器中,我们利用卷积神经网络(CNN)从单词中提取评论的语义特征,然后使用个性化的单词级注意力来为每个用户/项目选择评论中更重要的单词。
在用户/项目编码器中,我们应用个性化评论级别的注意力,通过根据权重聚合所有评论表示来学习用户/项目表示。此外,用户/项目的单词和评论级注意力向量由两个多层神经网络生成,并以用户/项目 ID 嵌入作为输入。这两个注意力向量可以看作是分层视图(即单词和评论级别)下每个用户和项目的指标。
最后,我们将用户和目标项目的表示结合起来,并将它们输入因子分解机层,以预测用户对该项目投票的评分。
VLSNR:Vision-Linguistics Coordination Time Sequence-aware News Recommendation 2022
VLSNR是顺序推荐的另一个应用——新闻推荐。它可以对用户的临时和长期兴趣进行建模,并通过多头注意力和GRU网络实现细粒度和粗粒度的融合。
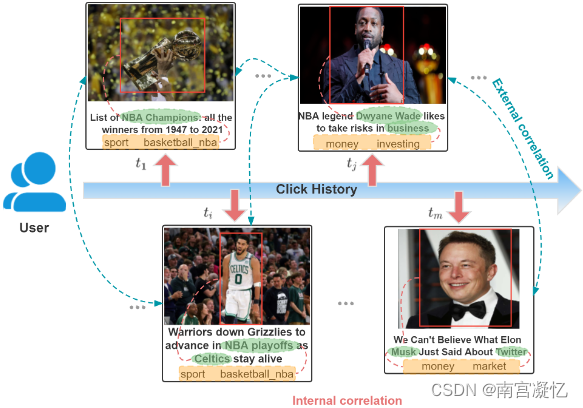
用户对多模态新闻的动态兴趣。蓝色双向箭头代表外部相关性。红色虚线代表内部相关性。
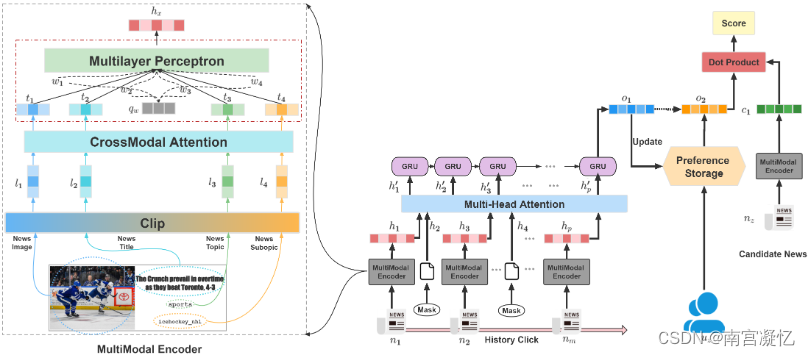
VLSNR:视觉语言协调时间序列感知新闻推荐,它利用融合模块来处理时间序列中的跨模态信息。
我们通过上述时间感知网络建立用户模型,通过历史点击和候选者之间的相关性来评估,这有助于理解用户的可变兴趣。
在我们的方法中,我们将图像和标题传输到 CLIP 编码器以学习新闻的表示。这使得文本和图像的语义能够很好地映射在同一特征空间中。
然后,我们构建了一系列注意力层,这有助于检测图像和文本之间更深层的交互。此外,我们提出了一个注意力 GRU 网络来学习用户的时间兴趣。
Multi-Order Attentive Ranking Model for Sequential Recommendation 2019
MARank设计了一个多阶注意力层,它将注意力和Resnet结合成一个统一的结构来融合信息。
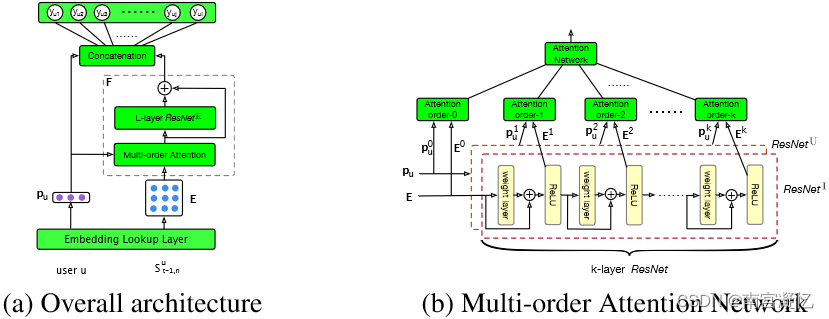
(a) 所提出模型 MARank 的总体架构。 pu 和 E 分别表示检索到的用户嵌入和 Su t−1,n 中先前项目的嵌入。
(b) 多阶注意力网络的图示。由于用于编码用户和项目的残差网络共享相同的架构,我们仅详细阐述 ResN etI 的具体结构。
2.4 其他融合方法。
一些简单的方法,包括平均池化、连接操作和门控机制。它们很少单独出现,并且经常与图和注意力机制结合使用。现有工作表明,简单的交互如果使用得当,不会损害推荐效果,并且可以降低模型的复杂度。
一些早期模型采用RNN和LSTM等结构,试图通过多模态信息对用户时间偏好进行建模。然而,随着注意力机制和CNN等深度学习技术的发展,这些年它们的使用已经越来越少。一些模型通过线性和非线性层融合多模态特征。
Interest-Related Item Similarity Model Based on Multimodal Data for Top-N Recommendation 2019
吕等人在该处设置线性层以融合文本和视觉特征。
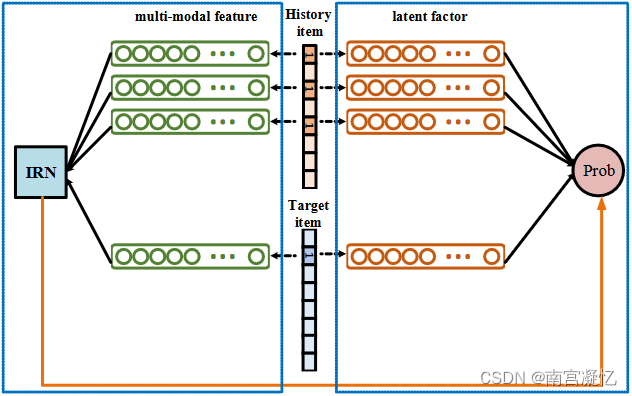
在该框架中,利用项目潜在因子进行相似度计算,并利用多模态特征通过IRN计算兴趣相关性,从而综合用户对目标项目的偏好预测概率。
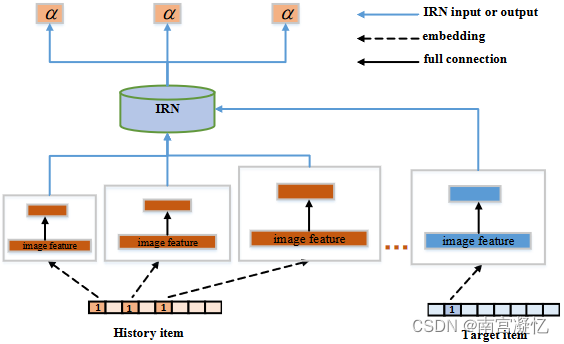
使用图像特征计算项目之间的兴趣相关性。以物品ID作为输入,输出是两者之间的兴趣相关性。
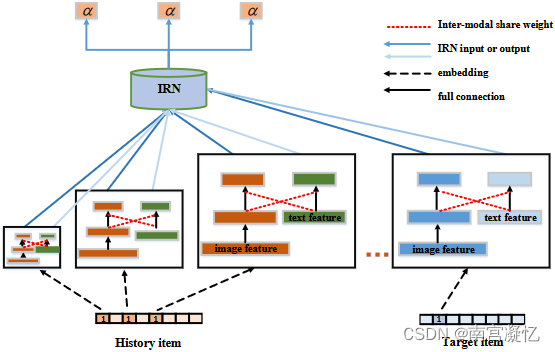
使用多模态特征计算项目之间的兴趣相关性。以物品ID作为输入,输出是两者之间的兴趣相关性。
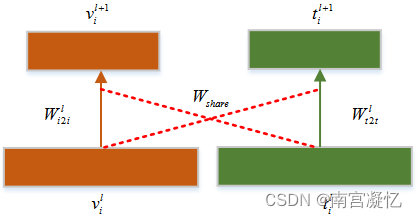
视觉特征和文本特征之间的知识共享单元。
MMT-Net: Transfer learning via contextual invariants for one-to-many cross-domain recommendation. 2020
人工标记餐厅数据的三个上下文不变量,并通过三层MLP网络进行交互。