微服务架构下的可观测性
一、服务可观测性
-
传统架构下排查问题
传统项目在出现异常或性能问题时,通常都是基于系统日志文件来排查。而在微服务分布式部署架构下,日志文件随微服务分散存储,对于排查问题工作量很大。 传统监控告警平台也仅针对平台资源的监控(cpu、内存、网络等),对业务应用的指标(平均响应时间、接口耗时、调用链路等)无法监控。

-
可观测性的三大支柱

Logging: 用于记录离散的事件。如 程序的调试信息或错误信息,是我们诊断问题的依据
可集成日志组件,打印 traceId等Metrics: 用于记录可聚合的指标性数据,如Counter(计数器)|Gauge(仪表)|Histogram(直方图)等。
统计全局|服务|实例|接口级的吞吐量、访问指标、成功率及JVM GC等指标。 系统层面:CPU、内存、IO等信息,一般运维关注 应用层面:调用量、出错率、请求延迟等,一般开发关注 业务层面:转化率、下单率等,一般运营关注 同时提供告警机制,可根据配置不同的规则指标进行告警 Tracing: 用于记录请求范围内的信息。如 一次请求的执行过程和耗时
可以看到一次请求完整的过程,包括Http、Rest、Feign调用、db等和相应的响应时间,跨度
-
从功效看总结
Metrics: 用于提供统一的仪表板和报警,通常能检测并解决一大类问题。Tracing: 用于定位分布式长链路中什么服务的什么逻辑有问题Logging: 用于事件分类和复杂问题的细节定位、调试。
二、FELK+SW整体架构
-
解决问题
1. 如何串联整个调用链路快速定位问题?
2. 如何理清各个微服务之间的依赖关系?
3. 如何进行各个微服务接口的性能分折?
4. 如何跟踪整个业务流程的调用处理顺序?
5. 如何通过日志文件快速定位问题根本原因?

三、skywalking简介
skywalking是分布式系统的应用程序性能监视工具,提供分布式追踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。专为微服务、云原生架构和基于容器(Docker、K8s、Mesos)架构而设计的观察性分析平台和应用性能管理系统。
-
链路追踪相关
通过traceId,segment,spanId记录完成
Trace: 一整个操作链路内为一个trace (全局唯一)
Segment: 一个jvm进程内的一个线程中的所有操作的集合
span: 每个具体的操作
-
新版本架构

-
老版本架构

-
skywalking部署方案
四、部署Skywalking
① 使用版本
# 原始版本
docker pull apache/skywalking-oap-server:9.2.0
docker pull apache/skywalking-ui:9.2.0
docker pull bitnami/elasticsearch:8.5.2
docker pull bitnami/kafka:3.3.1
docker pull bitnami/zookeeper:3.6.3
docker pull apache/skywalking-java-agent:8.13.0-alpine
# 私服版本
docker pull 192.168.100.86/library/skywalking-oap-server:9.2.0
docker pull 192.168.100.86/library/skywalking-ui:9.2.0
docker pull 192.168.100.86/library/elasticsearch:8.5.2
docker pull 192.168.100.86/library/kafka:3.3.1
docker pull 192.168.100.86/library/zookeeper:3.6.3
docker pull 192.168.100.86/library/skywalking-java-agent:8.13.0-alpine
② Docker部署
-
部署说明
这里基于
zookeeper来做skywalking集群管理,使用kafka-fetcher来做trace和metrics收集上报。
-
脚本配置说明
SW_STORAGE: 选择存储类型默认为h2,这里使用elasticsearch来做为存储
SW_STORAGE_ES_CLUSTER_NODES: 配置es的集群地址,多个用逗号分隔
SW_CLUSTER: 选择注册中心类型默认为standalone,这里使用zookeeper来做做为注册中心
SW_CLUSTER_ZK_HOST_PORT: 配置zk的集群地址,多个用逗号分隔
SW_KAFKA_FETCHER: default 使用kafka来做链路轨迹缓冲,此配置为default
SW_KAFKA_FETCHER_SERVERS: 配置kafka的集群地址,多个用逗号分隔
SW_KAFKA_FETCHER_PARTITIONS_FACTOR: 配置kafka的副本数
-
build.sh
#!/bin/bash
sduo docker run -d \
--restart always \
--name skywalking-oap \
-p 11800:11800 \
-p 12800:12800 \
-e TZ=Asia/Shanghai \
-e SW_STORAGE=elasticsearch \
-e SW_STORAGE_ES_CLUSTER_NODES=192.168.100.200:9200,192.168.100.201:9200,192.168.100.202:9200 \
-e SW_CLUSTER=zookeeper \
-e SW_CLUSTER_ZK_HOST_PORT=192.168.100.200:2181,192.168.100.201:2181,192.168.100.202:2181 \
-e SW_KAFKA_FETCHER=default \
-e SW_KAFKA_FETCHER_SERVERS=192.168.100.200:9092,192.168.100.201:9092,192.168.100.202:9092 \
-e SW_KAFKA_FETCHER_PARTITIONS_FACTOR=1 \
apache/skywalking-oap-server:9.2.0
-
查看日志
docker logs -f skywalking-oap
③ docker-compose部署
-
说明
部署需要修改
es|zk|kafka为真实的生产地址
version: "3.1"
services:
oap:
image: apache/skywalking-oap-server:9.2.0
container_name: oap
restart: always
ports:
- "11800:11800"
- "12800:12800"
environment:
- TZ=Asia/Shanghai
- SW_STORAGE=elasticsearch
- SW_STORAGE_ES_CLUSTER_NODES=192.168.100.200:9200,192.168.100.201:9200,192.168.100.202:9200
- SW_CLUSTER=zookeeper
- SW_CLUSTER_ZK_HOST_PORT=192.168.100.200:2181,192.168.100.201:2181,192.168.100.202:2181
- SW_KAFKA_FETCHER=default
- SW_KAFKA_FETCHER_SERVERS=192.168.100.200:9092,192.168.100.201:9092,192.168.100.202:9092
- SW_KAFKA_FETCHER_PARTITIONS_FACTOR=1
networks:
- monitor
oap-ui:
image: apache/skywalking-ui:9.2.0
container_name: oap-ui
restart: always
privileged: true
ports:
- "8090:8080"
environment:
- TZ=Asia/Shanghai
- SW_OAP_ADDRESS=http://oap:12800
networks:
- monitor
depends_on:
- oap
links:
- oap
networks:
monitor:
driver: bridge
④ UI访问
http://192.168.xxx.xxx:8090

五、配置说明
① oap-server配置
config/application.yml
# 集群配置
cluster:
selector: ${SW_CLUSTER:standalone}
standalone: #单机版
# 确保zooKeeper版本3.5+
zookeeper:
namespace: ${SW_NAMESPACE:""}
hostPort: ${SW_CLUSTER_ZK_HOST_PORT:localhost:2181} # zk地址
# 重试策略
baseSleepTimeMs: ${SW_CLUSTER_ZK_SLEEP_TIME:1000} # 初始化等待时间
maxRetries: ${SW_CLUSTER_ZK_MAX_RETRIES:3} # # 最大重试次数 默认3次
# 开启访问控制
enableACL: ${SW_ZK_ENABLE_ACL:false} # 默认关闭
schema: ${SW_ZK_SCHEMA:digest} # only support digest schema
expression: ${SW_ZK_EXPRESSION:skywalking:skywalking}
internalComHost: ${SW_CLUSTER_INTERNAL_COM_HOST:""}
internalComPort: ${SW_CLUSTER_INTERNAL_COM_PORT:-1}
nacos:
serviceName: ${SW_SERVICE_NAME:"SkyWalking_OAP_Cluster"} # skywalking注册到nacos名称
hostPort: ${SW_CLUSTER_NACOS_HOST_PORT:localhost:8848} # nacos地址
namespace: ${SW_CLUSTER_NACOS_NAMESPACE:"public"} # nacos名称空间
username: ${SW_CLUSTER_NACOS_USERNAME:""} # nacos用户名
password: ${SW_CLUSTER_NACOS_PASSWORD:""} # nacos密码
# Nacos auth accessKey
accessKey: ${SW_CLUSTER_NACOS_ACCESSKEY:""}
secretKey: ${SW_CLUSTER_NACOS_SECRETKEY:""}
internalComHost: ${SW_CLUSTER_INTERNAL_COM_HOST:""}
internalComPort: ${SW_CLUSTER_INTERNAL_COM_PORT:-1}
core:
selector: ${SW_CORE:default}
default:
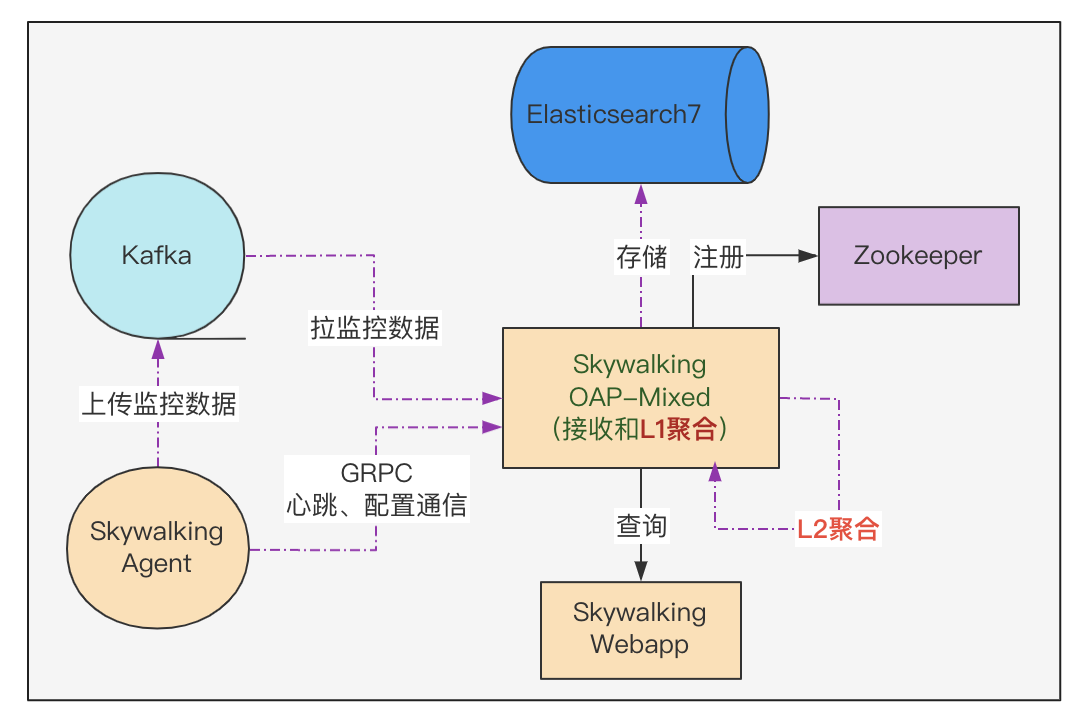
# Mixed: Receive agent data, Level 1 aggregate, Level 2 aggregate 混合角色:接收代理数据,1级聚合、2级聚合
# Receiver: Receive agent data, Level 1 aggregate 接收者:接收代理数据,1级聚合点
# Aggregator: Level 2 aggregate 聚合器:2级聚合点
# 后端集群角色配置,默认 Mixed 代表 Receiver 和 Aggregator 角色共存。
# 当我们的微服务规模较大的时候,可以通过调整 Receiver 和 Aggregator 集群来指责分离,提高 OAP 集群接收数据的效率。
role: ${SW_CORE_ROLE:Mixed} # Mixed/Receiver/Aggregator
restHost: ${SW_CORE_REST_HOST:0.0.0.0} # 接收IP
restPort: ${SW_CORE_REST_PORT:12800} # 接收端口
restContextPath: ${SW_CORE_REST_CONTEXT_PATH:/} # 服务路径
restMaxThreads: ${SW_CORE_REST_MAX_THREADS:200} # 最小线程
restIdleTimeOut: ${SW_CORE_REST_IDLE_TIMEOUT:30000} # 线程空闲时间,超时关闭
restAcceptQueueSize: ${SW_CORE_REST_QUEUE_SIZE:0} # 接收队列大小
httpMaxRequestHeaderSize: ${SW_CORE_HTTP_MAX_REQUEST_HEADER_SIZE:8192} # httP最大请求头大小
gRPCHost: ${SW_CORE_GRPC_HOST:0.0.0.0} # grpc服务接收IP
gRPCPort: ${SW_CORE_GRPC_PORT:11800} # grpc服务接收端口
maxConcurrentCallsPerConnection: ${SW_CORE_GRPC_MAX_CONCURRENT_CALL:0} # 最大并发连接数
maxMessageSize: ${SW_CORE_GRPC_MAX_MESSAGE_SIZE:0} # 最大消息体
gRPCThreadPoolQueueSize: ${SW_CORE_GRPC_POOL_QUEUE_SIZE:-1} # grpc线程队列大小
gRPCThreadPoolSize: ${SW_CORE_GRPC_THREAD_POOL_SIZE:-1} # grpc线程队列
gRPCSslEnabled: ${SW_CORE_GRPC_SSL_ENABLED:false} # grpc安全协议是否开启
gRPCSslKeyPath: ${SW_CORE_GRPC_SSL_KEY_PATH:""}
gRPCSslCertChainPath: ${SW_CORE_GRPC_SSL_CERT_CHAIN_PATH:""}
gRPCSslTrustedCAPath: ${SW_CORE_GRPC_SSL_TRUSTED_CA_PATH:""}
downsampling:
- Hour
- Day
# 此处是关于数据清理策略的相关配置
# 设置度量指标数据的超时时间,超时后数据自动删除
enableDataKeeperExecutor: ${SW_CORE_ENABLE_DATA_KEEPER_EXECUTOR:true} # 自动数据清理机制的开关,默认开启
dataKeeperExecutePeriod: ${SW_CORE_DATA_KEEPER_EXECUTE_PERIOD:5} # 数据清理执行频率 单位分钟,默认每5分钟执行一次删除超期数据
recordDataTTL: ${SW_CORE_RECORD_DATA_TTL:3} # Trace、Database数据有效时长 单位天
metricsDataTTL: ${SW_CORE_METRICS_DATA_TTL:7} # 聚合指标数据数据有效时长 单位天
l1FlushPeriod: ${SW_CORE_L1_AGGREGATION_FLUSH_PERIOD:500} # L1聚合刷新到L2聚合的周期 单位毫秒
storageSessionTimeout: ${SW_CORE_STORAGE_SESSION_TIMEOUT:70000} # 会话时间阈值 单位毫秒
persistentPeriod: ${SW_CORE_PERSISTENT_PERIOD:25} # 数据持久化的周期 单位毫秒
# 如果OAP集群在一分钟内发生变化,缓存metrics数据以减少数据库查询
# 如果OAP集群在那一分钟内发生变化,那么在那一分钟内,这些度量可能不准确
enableDatabaseSession: ${SW_CORE_ENABLE_DATABASE_SESSION:true}
topNReportPeriod: ${SW_CORE_TOPN_REPORT_PERIOD:10} # 每个报告周期的前N条记录
# 额外的模型字段,用于在可视化工具中查看es数据,开启会增加一定的性能损耗
activeExtraModelColumns: ${SW_CORE_ACTIVE_EXTRA_MODEL_COLUMNS:false}
# 服务名最大长度,服务名+实例名的最大长度必须小于70
serviceNameMaxLength: ${SW_SERVICE_NAME_MAX_LENGTH:70}
instanceNameMaxLength: ${SW_INSTANCE_NAME_MAX_LENGTH:70}
# 端点名最大长度,服务名+端点名(api)的最大长度必须小于240
endpointNameMaxLength: ${SW_ENDPOINT_NAME_MAX_LENGTH:150}
# 定义一组span标记键,这些键可以通过GraphQL进行搜索
searchableTracesTags: ${SW_SEARCHABLE_TAG_KEYS:http.method,http.status_code,rpc.status_code,db.type,db.instance,mq.queue,mq.topic,mq.broker}
# Define the set of log tag keys, which should be searchable through the GraphQL.
searchableLogsTags: ${SW_SEARCHABLE_LOGS_TAG_KEYS:level}
# Define the set of alarm tag keys, which should be searchable through the GraphQL.
searchableAlarmTags: ${SW_SEARCHABLE_ALARM_TAG_KEYS:level}
# The max size of tags keys for autocomplete select.
autocompleteTagKeysQueryMaxSize: ${SW_AUTOCOMPLETE_TAG_KEYS_QUERY_MAX_SIZE:100}
# The max size of tags values for autocomplete select.
autocompleteTagValuesQueryMaxSize: ${SW_AUTOCOMPLETE_TAG_VALUES_QUERY_MAX_SIZE:100}
# The number of threads used to prepare metrics data to the storage.
prepareThreads: ${SW_CORE_PREPARE_THREADS:2}
# Turn it on then automatically grouping endpoint by the given OpenAPI definitions.
enableEndpointNameGroupingByOpenapi: ${SW_CORE_ENABLE_ENDPOINT_NAME_GROUPING_BY_OPAENAPI:true}
storage:
selector: ${SW_STORAGE:h2}
elasticsearch:
# Skywalking 默认不支持多租户/多环境/多项目概念的。多套 Skywalking 的时候为了实现数据隔离,可以通过该参数生成带前缀的索引名。
namespace: ${SW_NAMESPACE:""} # 命名空间
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:localhost:9200} # 集群节点
protocol: ${SW_STORAGE_ES_HTTP_PROTOCOL:"http"} # 协议 http https
connectTimeout: ${SW_STORAGE_ES_CONNECT_TIMEOUT:3000} # 连接超时
socketTimeout: ${SW_STORAGE_ES_SOCKET_TIMEOUT:30000} # socket超时
responseTimeout: ${SW_STORAGE_ES_RESPONSE_TIMEOUT:15000} # 响应超时
numHttpClientThread: ${SW_STORAGE_ES_NUM_HTTP_CLIENT_THREAD:0} # 线程数
user: ${SW_ES_USER:""} # elasticsearch 用户名 7.0.0后可以在secretsManagementFile里管理
password: ${SW_ES_PASSWORD:""} # elasticsearch 密码 7.0.0后可以在secretsManagementFile里管理
trustStorePath: ${SW_STORAGE_ES_SSL_JKS_PATH:""} # SSL文件路径: ../es_keysotre.jks
trustStorePass: ${SW_STORAGE_ES_SSL_JKS_PASS:""} # SSL password 7.0.0后可以在secretsManagementFile里管理
secretsManagementFile: ${SW_ES_SECRETS_MANAGEMENT_FILE:""} # 安全管理文件
dayStep: ${SW_STORAGE_DAY_STEP:1} # 表示 1 分钟/小时/天的步长。按1配置es每天创建一个新索引
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:1} # elasticsearch索引分片数
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:1} # elasticsearch索引副本数
# Super data set has been defined in the codes, such as trace segments.The following 3 config would be improve es performance when storage super size data in es.
superDatasetDayStep: ${SW_SUPERDATASET_STORAGE_DAY_STEP:-1} # Represent the number of days in the super size dataset record index, the default value is the same as dayStep when the value is less than 0
superDatasetIndexShardsFactor: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_SHARDS_FACTOR:5} # This factor provides more shards for the super data set, shards number = indexShardsNumber * superDatasetIndexShardsFactor. Also, this factor effects Zipkin and Jaeger traces.
superDatasetIndexReplicasNumber: ${SW_STORAGE_ES_SUPER_DATASET_INDEX_REPLICAS_NUMBER:0} # Represent the replicas number in the super size dataset record index, the default value is 0.
indexTemplateOrder: ${SW_STORAGE_ES_INDEX_TEMPLATE_ORDER:0} # the order of index template
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:5000} # 每5000个请求执行异步批量任务保存数据到es
# 无论请求的数量是否达到上面批量写入的数量阈值,每10秒刷盘一次
# flush the bulk every 10 seconds whatever the number of requests
# INT(flushInterval * 2/3) would be used for index refresh period
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:15} # 刷盘间隔时间
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2} # 并发请求数
resultWindowMaxSize: ${SW_STORAGE_ES_QUERY_MAX_WINDOW_SIZE:10000} # 结果窗口最大值
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:10000} # 元数据查询最值
scrollingBatchSize: ${SW_STORAGE_ES_SCROLLING_BATCH_SIZE:5000} # 滚动数据量大小
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200} # 分段查询最大数据量
profileTaskQueryMaxSize: ${SW_STORAGE_ES_QUERY_PROFILE_TASK_SIZE:200} # 性能剖析最大查询数
profileDataQueryBatchSize: ${SW_STORAGE_ES_QUERY_PROFILE_DATA_BATCH_SIZE:100} # 性能剖析批量数
oapAnalyzer: ${SW_STORAGE_ES_OAP_ANALYZER:"{\"analyzer\":{\"oap_analyzer\":{\"type\":\"stop\"}}}"} # the oap analyzer.
oapLogAnalyzer: ${SW_STORAGE_ES_OAP_LOG_ANALYZER:"{\"analyzer\":{\"oap_log_analyzer\":{\"type\":\"standard\"}}}"} # the oap log analyzer. It could be customized by the ES analyzer configuration to support more language log formats, such as Chinese log, Japanese log and etc.
advanced: ${SW_STORAGE_ES_ADVANCED:""}
# Enable shard metrics and records indices into multi-physical indices, one index template per metric/meter aggregation function or record.
logicSharding: ${SW_STORAGE_ES_LOGIC_SHARDING:false}
# 接收探针代理
agent-analyzer:
selector: ${SW_AGENT_ANALYZER:default}
default:
# 采样率配置文件 traceSamplingPolicySettingsFile
traceSamplingPolicySettingsFile: ${SW_TRACE_SAMPLING_POLICY_SETTINGS_FILE:trace-sampling-policy-settings.yml}
slowDBAccessThreshold: ${SW_SLOW_DB_THRESHOLD:default:200,mongodb:100} # 慢数据访问阀值,单位ms
forceSampleErrorSegment: ${SW_FORCE_SAMPLE_ERROR_SEGMENT:true}
# 分段状态分析策略
# FROM_SPAN_STATUS:任何一个span状态决定分段状态,只要一个span为Error则为Error。默认此策略
# FROM_ENTRY_SPAN:入口span状态决定分段状态
# FROM_FIRST_SPAN:第一个span状态决定分段状态
segmentStatusAnalysisStrategy: ${SW_SEGMENT_STATUS_ANALYSIS_STRATEGY:FROM_SPAN_STATUS}
# Nginx和外部代理无法获取到原始地址的
# 且端口不在范围内的,不会产生客户端实例关系
noUpstreamRealAddressAgents: ${SW_NO_UPSTREAM_REAL_ADDRESS:6000,9000}
meterAnalyzerActiveFiles: ${SW_METER_ANALYZER_ACTIVE_FILES:datasource,threadpool,satellite} # 可以被分析的文件,用“,”逗号分隔
kafka-fetcher:
selector: ${SW_KAFKA_FETCHER:-}
default:
bootstrapServers: ${SW_KAFKA_FETCHER_SERVERS:localhost:9092} # kafka地址
namespace: ${SW_NAMESPACE:""}
partitions: ${SW_KAFKA_FETCHER_PARTITIONS:3} # 默认分区
replicationFactor: ${SW_KAFKA_FETCHER_PARTITIONS_FACTOR:2} # 默认副本
enableNativeProtoLog: ${SW_KAFKA_FETCHER_ENABLE_NATIVE_PROTO_LOG:true}
enableNativeJsonLog: ${SW_KAFKA_FETCHER_ENABLE_NATIVE_JSON_LOG:true}
consumers: ${SW_KAFKA_FETCHER_CONSUMERS:1}
kafkaHandlerThreadPoolSize: ${SW_KAFKA_HANDLER_THREAD_POOL_SIZE:-1}
kafkaHandlerThreadPoolQueueSize: ${SW_KAFKA_HANDLER_THREAD_POOL_QUEUE_SIZE:-1}
# 动态配置
configuration:
selector: ${SW_CONFIGURATION:none}
none:
zookeeper:
period: ${SW_CONFIG_ZK_PERIOD:60} # 同步刷新配置周期,默认60s
namespace: ${SW_CONFIG_ZK_NAMESPACE:/default} # 保存配置的节点路径
hostPort: ${SW_CONFIG_ZK_HOST_PORT:localhost:2181} # zk地址
# 重试策略
baseSleepTimeMs: ${SW_CONFIG_ZK_BASE_SLEEP_TIME_MS:1000} # 每次重试间隔等待时间 1000ms
maxRetries: ${SW_CONFIG_ZK_MAX_RETRIES:3} # 最大重试次数 3次
nacos:
serverAddr: ${SW_CONFIG_NACOS_SERVER_ADDR:127.0.0.1} # nacos地址
port: ${SW_CONFIG_NACOS_SERVER_PORT:8848} # nacos端口
group: ${SW_CONFIG_NACOS_SERVER_GROUP:skywalking} # nacos配置分组
namespace: ${SW_CONFIG_NACOS_SERVER_NAMESPACE:} # nacos配置名称空间
period: ${SW_CONFIG_NACOS_PERIOD:60} # 同步刷新配置间隔 默认60s
username: ${SW_CONFIG_NACOS_USERNAME:""} # nacos用户名
password: ${SW_CONFIG_NACOS_PASSWORD:""} # nacos密码
# Nacos auth accessKey
accessKey: ${SW_CONFIG_NACOS_ACCESSKEY:""}
secretKey: ${SW_CONFIG_NACOS_SECRETKEY:""}
-
采样率
trace-sampling-policy-settings.yml
default:
# 替代"agent-analyzer.default.sampleRate"的默认采样率
# 采样率精度为1/10000。 10000 表示默认为 100% 样本
rate: 10000
# 替换"agent-analyzer.default.slowTraceSegmentThreshold"的默认跟踪延迟时间
# 设置这个延迟阈值将使慢跟踪段在花费更多时间时被采样,即使采样机制被激活。 默认值为"-1",这意味着不会对慢速跟踪进行采样。 单位,毫秒。
duration: -1
#services:
# - name: serverName
# rate: 1000 # Sampling rate of this specific service
# duration: 10000 # Trace latency threshold for trace sampling for this specific service
② agent配置
config/agent.config
# The service name in UI
# ${service name} = [${group name}::]${logic name}
# The group name is optional only.
# 设置服务名称,会在 Skywalking UI 上显示的名称
agent.service_name=${SW_AGENT_NAME:Your_ApplicationName}
# The agent namespace
# 设置Agent命名空间,它用来隔离追踪和监控数据,当两个应用使用不同的名称空间时,跨进程传播链会中断
agent.namespace=${SW_AGENT_NAMESPACE:}
# The agent cluster
agent.cluster=${SW_AGENT_CLUSTER:}
# The number of sampled traces per 3 seconds
# Negative or zero means off, by default
# 每 3秒采集的样本跟踪比例,如果是负数则表示 100%采集
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}
# 配置链路的最大Span数量。一般情况下不需要配置,默认为 300。
# 主要考虑,有些新上 SkyWalking Agent 的项目,代码可能比较糟糕。
# The max amount of spans in a single segment.
# Through this config item, SkyWalking keep your application memory cost estimated.
agent.span_limit_per_segment=${SW_AGENT_SPAN_LIMIT:300}
# grpc channel status check interval.
# grpc状态检查间隔 默认30秒
collector.grpc_channel_check_interval=${SW_AGENT_COLLECTOR_GRPC_CHANNEL_CHECK_INTERVAL:30}
# Agent heartbeat report period. Unit, second.
# agent心跳报告周期 默认30秒 单位秒
collector.heartbeat_period=${SW_AGENT_COLLECTOR_HEARTBEAT_PERIOD:30}
# The agent sends the instance properties to the backend every
# collector.heartbeat_period * collector.properties_report_period_factor seconds
# agent发送实例属性到server周期 heartbeat_period*properties_report_period_factor 秒 默认300秒=5分钟
collector.properties_report_period_factor=${SW_AGENT_COLLECTOR_PROPERTIES_REPORT_PERIOD_FACTOR:10}
六、skywalking使用kafka-fetcher
skywalking使用kafka-fetcher从agent向服务端传输链路
① oap server端配置
-
官方文档
-
修改
oap中application.yml配置
修改说明
selector: default 选择使用kafak-fetcher
bootstrapServers: kafka的bootstrap server地址,集群用逗号分隔
partitions:topic分区数
replicationFactor:topic副本数
原始配置
kafka-fetcher:
selector: ${SW_KAFKA_FETCHER:-}
default:
bootstrapServers: ${SW_KAFKA_FETCHER_SERVERS:localhost:9092}
namespace: ${SW_NAMESPACE:""}
partitions: ${SW_KAFKA_FETCHER_PARTITIONS:3}
replicationFactor: ${SW_KAFKA_FETCHER_PARTITIONS_FACTOR:2}
enableNativeProtoLog: ${SW_KAFKA_FETCHER_ENABLE_NATIVE_PROTO_LOG:true}
enableNativeJsonLog: ${SW_KAFKA_FETCHER_ENABLE_NATIVE_JSON_LOG:true}
consumers: ${SW_KAFKA_FETCHER_CONSUMERS:1}
kafkaHandlerThreadPoolSize: ${SW_KAFKA_HANDLER_THREAD_POOL_SIZE:-1}
kafkaHandlerThreadPoolQueueSize: ${SW_KAFKA_HANDLER_THREAD_POOL_QUEUE_SIZE:-1}
重启
oap server后会在kafka创建如下主题(允许自动创建主题,否则需要手动创建)
skywalking-segments
skywalking-metrics
skywalking-profilings
skywalking-managements
skywalking-meters
skywalking-logs
skywalking-logs-json
进入容器查看
$ cd /opt/bitnami/kafka/bin
$
$ ./kafka-topics.sh --bootstrap-server kafka.one-piece:9092 --list
__consumer_offsets
skywalking-logs
skywalking-logs-json
skywalking-managements
skywalking-meters
skywalking-metrics
skywalking-profilings
skywalking-segments
$
$

② agent端配置
-
官方文档
拷贝
optional-reporter-plugins目录下kafka-reporter-plugin-8.13.0.jar到plugins目录下,以激活kafka上报链路

-
修改 config中agent.config配置
配置说明
plugin.kafka.bootstrap_servers:kafka集群地址
plugin.kafka.namespace:名称空间
原始配置
plugin.kafka.bootstrap_servers=${SW_KAFKA_BOOTSTRAP_SERVERS:localhost:9092}
plugin.kafka.get_topic_timeout=${SW_GET_TOPIC_TIMEOUT:10}
plugin.kafka.producer_config=${sw_plugin_kafka_producer_config:}
plugin.kafka.producer_config_json=${SW_PLUGIN_KAFKA_PRODUCER_CONFIG_JSON:}
plugin.kafka.topic_meter=${SW_PLUGIN_KAFKA_TOPIC_METER:skywalking-meters}
plugin.kafka.topic_metrics=${SW_PLUGIN_KAFKA_TOPIC_METRICS:skywalking-metrics}
plugin.kafka.topic_segment=${SW_PLUGIN_KAFKA_TOPIC_SEGMENT:skywalking-segments}
plugin.kafka.topic_profiling=${SW_PLUGIN_KAFKA_TOPIC_PROFILINGS:skywalking-profilings}
plugin.kafka.topic_management=${SW_PLUGIN_KAFKA_TOPIC_MANAGEMENT:skywalking-managements}
plugin.kafka.topic_logging=${SW_PLUGIN_KAFKA_TOPIC_LOGGING:skywalking-logs}
plugin.kafka.namespace=${SW_KAFKA_NAMESPACE:}
以上配置可以不用修改,在项目启动时通过环境变量来指定
-
项目使用
agent可选参数
-javaagent:D:/Company/apache-skywalking-java-agent-8.13.0/skywalking-agent/skywalking-agent.jar
-Dskywalking.collector.backend_service=192.168.100.71:32119
-Dskywalking.plugin.kafka.bootstrap_servers=192.168.100.71:30094
-Dskywalking.agent.instance_name=192.168.56.1@gateway-server
-Dskywalking.agent.service_name=gateway-server
七、采样率配置
配置文件
config/agent.config
# 采样率,每3秒trace几条
# 小于等于0使用默认值,每条都采样
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}
# 配置链路的最大Span数量。一般情况下不需要配置,默认为 300。
# 主要考虑,有些新上 SkyWalking Agent 的项目,代码可能比较糟糕。
agent.span_limit_per_segment=${SW_AGENT_SPAN_LIMIT:300}
-
配置动态调整
服务端配置 agent端配置

八、项目接入
① 下载agent
apache-skywalking-java-agent-8.13.0.tgz
-
准备工作
1. 解压到apache-skywalking-java-agent-8.13.0
2. 拷贝skywalking-agent/ooptional-reporter-plugins目录中的
kafka-reporter-plugin-8.13.0.jar
到plugins目录,以支持kafka
3. 解压后,拷贝skywalking-agent/optional-plugins目录中的
apm-trace-ignore-plugin-8.13.0.jar
到pulgins或activations目录下,以支持忽略插件
-
IDEA配置
-javaagent:D:/Company/apache-skywalking-java-agent-8.13.0/skywalking-agent/skywalking-agent.jar
-Dskywalking.agent.service_name=jingyou::license-server
-Dskywalking.agent.instance_name=192.xxx.56.1@license-server
-Dskywalking.plugin.kafka.bootstrap_servers=192.xxx.xxx.71:31775
-Dskywalking.trace.ignore_path=/eureka/**,actuator/**,durid/**
参数说明
-javaagent: 指定agent所在的绝对路径
-Dskywalking.agent.service_name: 指定服务在skywalking显示的名称(可通过service.group::service.names进行分组)
-Dskywalking.agent.instance_name: 指定配置实例名称
-Dskywalking.plugin.kafka.bootstrap_servers: 指定kafka集群地址
-Dskywalking.trace.ignore_path: 忽略链路端点

-
示例说明
服务实例

链路示例

② 日志接入traceId
官方示例
-
logback日志
说明
1. encoder的class是LayoutWrappingEncoder,不是PatternLayoutEncoder
2. 使用 %tid来标识traceId的位置,默认为:TID: N/A。当有请求时会显示traceId。
3. skywalking是基于字节码增强的,traceId的传递依赖于skywalking服务端。
当服务端异常等客户端连接不上的情况时,会显示:TID: [Ignored Trace],此时会丢失traceId
pom.xml添加依赖
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-logback-1.x</artifactId>
<version>8.13.0</version>
</dependency>
logback.xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration scan="true" scanPeriod=" 5 seconds">
<appender name="stdout" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
<appender name="fileAppender" class="ch.qos.logback.core.FileAppender">
<file>/tmp/skywalking-logs/logback/e2e-service-provider.log</file>
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.TraceIdPatternLogbackLayout">
<Pattern>[%sw_ctx] [%level] %d{yyyy-MM-dd HH:mm:ss.SSS} [%thread] %logger:%line - %msg%n</Pattern>
</layout>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="grpc-log"/>
<appender-ref ref="stdout"/>
</root>
<logger name="fileLogger" level="INFO">
<appender-ref ref="fileAppender"/>
</logger>
</configuration>
-
log4j2日志
pom.xml添加依赖
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-log4j-2.x</artifactId>
<version>8.13.0</version>
</dependency>
log4j2.xml
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="WARN">
<Appenders>
<Console name="Console" target="SYSTEM_OUT">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%traceId] %-5level %logger{36} - %msg%n"/>
</Console>
<GRPCLogClientAppender name="grpc-log">
<PatternLayout pattern="%d{HH:mm:ss.SSS} [%traceId] %-5level %logger{36} - %msg%n"/>
</GRPCLogClientAppender>
<RandomAccessFile name="fileAppender" fileName="/tmp/skywalking-logs/log4j2/e2e-service-provider.log" immediateFlush="true" append="true">
<PatternLayout>
<Pattern>[%sw_ctx] [%p] %d{yyyy-MM-dd HH:mm:ss.SSS} [%traceId] %c:%L - %m%n</Pattern>
</PatternLayout>
</RandomAccessFile>
</Appenders>
<Loggers>
<Root level="info">
<AppenderRef ref="Console"/>
<AppenderRef ref="grpc-log"/>
</Root>
<Logger name="fileLogger" level="info" additivity="false">
<AppenderRef ref="fileAppender"/>
</Logger>
</Loggers>
</Configuration>
-
日志上报
agent配置
1. 进入到skywalking-agent\config目录
2. 可修改如下配置:
log.max_message_size=${SW_GRPC_LOG_MAX_MESSAGE_SIZE:10485760}
-
logback.xml
<appender name="grpc-log" class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.log.GRPCLogClientAppender">
<encoder class="ch.qos.logback.core.encoder.LayoutWrappingEncoder">
<layout class="org.apache.skywalking.apm.toolkit.log.logback.v1.x.mdc.TraceIdMDCPatternLogbackLayout">
<Pattern>%d{yyyy-MM-dd HH:mm:ss.SSS} [%X{tid}] [%thread] %-5level %logger{36} -%msg%n</Pattern>
</layout>
</encoder>
</appender>
③ 自定义链路追踪
某些业务中需要在具体的执行方法上加入链路
pom.xml添加依赖
<dependency>
<groupId>org.apache.skywalking</groupId>
<artifactId>apm-toolkit-trace</artifactId>
<version>8.13.0</version>
</dependency>
使用方式
/**
* 注意要加在业务方法上
* @Trace 标注改方法加入链路
* @Tags 记录多个参数
* @Tag 记录方法入参和返回值
* key 可以指定为方法名或参数名(自定义)
* value agr[0] 标识下标为0的参数,returnedObj 表示返回值(不能随便写)
*/
@Override
@Trace
@Tags({@Tag(key = "param", value = "arg[0]"), @Tag(key = "selectOrders", value = "returnedObj")})
public List<Order> selectOrders(Long id) {
return orderMapper.selectOrders(id);
}
代码中获取
traceId
String traceId = TraceContext.traceId();
④ skywalking采集gateway链路
skywalking默认情况下是不会采集gateway链路的,需要进行插件安装
1. 拷贝skywalking-agent/optional-plugins目录中的
apm-spring-webflux-5.x-plugin-8.13.0.jar
apm-spring-cloud-gateway-3.x-plugin-8.13.0.jar
到pulgins目录下
2. 重新启动gateway,查看UI控制台是否上报链路
⑤ 自定义忽略路径
官方文档 官方文档

-
忽略的端点
很多插件包含心跳请求,导致APM上传了很多不需要的监控端点。可以通过插件配置忽略这些端点
向注册中心拉取配置列表 向配置中心拉取配置 向基础组件发送心跳包 服务状态端点检查等
-
插件配置
1. 拷贝skywalking-agent/optional-plugins目录中的
apm-trace-ignore-plugin-8.13.0.jar
到pulgins或activations目录下
2. agent会扫描这两个路径下的插件。配置位置为 config/agent.config
plugin.mount=${SW_MOUNT_FOLDERS:plugins,activations}
-
路径匹配规则
# Ant 匹配模式,多个规则使用逗号“,”分割。
/path/? 单个字符
/path/* 多个字符
/path/** 多个字符和多级路径
-
插件使用
方案一
# 通过配置文件指定
1. 在agent/config目录下新建配置文件:apm-trace-ignore-plugin.config
2. 在其中配置忽略的路径
trace.ignore_path=${SW_AGENT_TRACE_IGNORE_PATH:GET:/actuator/**,/actuator/**,/eureka/**,Druid/**,Mysql/**,Lettuce/**,Gson/**,HikariCP/**}
方案二
# 在javaagent参数中指定忽略路径
-javaagent:D:/Company/apache-skywalking-java-agent-8.13.0/skywalking-agent/skywalking-agent.jar
-Dskywalking.collector.backend_service=192.168.100.71:32119
-Dskywalking.plugin.kafka.bootstrap_servers=192.168.100.71:30094
-Dskywalking.agent.instance_name=192.168.56.1@gateway-server
-Dskywalking.agent.service_name=gateway-server
-Dskywalking.trace.ignore_path=/eureka/**,actuator/**,durid/**
九、跨线程传递traceId
skywalking-trace提供了异步任务包装类来实现跨线程链路traceId的传递。
RunnableWrapper:Ruannable 接口 的包装类
CallableWrapper:Callable 接口 的包装类
ConsumerWrapper:函数式接口 Consumer 的包装类
SupplierWrapper:函数式接口 Supplier 的包装类
FunctionWrapper:函数式接口 Function 的包装类
-
使用示例
@GetMapping("/{licenseId}")
public LicenseDTO getLicense(@PathVariable("licenseId") String licenseId) {
log.info("licenseId: {}" ,licenseId);
ExecutorService executorService = Executors.newSingleThreadExecutor();
executor.submit(new RunnableWrapper(() -> {
log.info("RunnableWrapper ...");
}));
return licenseService.getLicense(organizationId, licenseId);
}
-
跨线程包装类原理
skywalking通过字节码增强类将@TraceCrossThread注解做为增强类切入点,进行字节码增强实现跨线程传递trace功能。
@TraceCrossThread
public class RunnableWrapper implements Runnable {
final Runnable runnable;
public RunnableWrapper(Runnable runnable) {
this.runnable = runnable;
}
public static RunnableWrapper of(Runnable r) {
return new RunnableWrapper(r);
}
public void run() {
this.runnable.run();
}
}
十、告警
官网
6.x后版本支持告警,核心由一组告警规则来驱动。规则目录:config/alarm-settings.yml
# 默认支持的告警规则
1. 过去3分钟内服务平均响应时间超过1秒
2.过去2分钟服务成功率低于80%
3.过去3分钟内服务响应时间超过1s的百分比
4. 服务实例在过去2分钟内平均响应时间超过1s.并且实例名称与正则表达式匹配
5.过去2分钟内端点平均响应时间超过1秒
6.过去2分钟内数据库访问平均炯应时间超过1秒
7.过去2分钟内端点关系平均响应时间超过1秒。
规则配置说明
1. Rule name: 规则名称,告警信息中显示的唯一名称。必须以过_rule 结尾,前綴可自定义
2. Metrics name:度量名称配置时只需要取_rule前的名称,取值为oal脚本中的度量。
3. Include names:该规则作用于哪些实体名称,比如服务名,终端名(可选,默认为全部〕
4. Exclude names:该规则作不用于哪些实体名称,比如服务名,终惴名(可选,默认为空)
5. Threshold:阈值, 例如2000为2s
6. OP:操作符,目前支持> < =
7. Period:多久告警规则需要被核实一下。这是一个时间窗囗,与后端部署环境时间相匹配
8. Count: 在一个Period窗口中,如值values超过Threshold值(按op) 达到count值需要发送警报
9. Silence period : 在时间N中 触发报警后,在TN->TN+ period 这个阶段不告警 ,默认情况下 它和period一样,意味着相同的告警 在同一个period内只会触发一次
10. message: 告警提示信息
原始配置
rules:
# Rule unique name, must be ended with `_rule`.
service_resp_time_rule:
metrics-name: service_resp_time
op: ">"
threshold: 1000
period: 10
count: 3
silence-period: 5
message: Response time of service {name} is more than 1000ms in 3 minutes of last 10 minutes.
service_sla_rule:
# Metrics value need to be long, double or int
metrics-name: service_sla
op: "<"
threshold: 8000
# The length of time to evaluate the metrics
period: 10
# How many times after the metrics match the condition, will trigger alarm
count: 2
# How many times of checks, the alarm keeps silence after alarm triggered, default as same as period.
silence-period: 3
message: Successful rate of service {name} is lower than 80% in 2 minutes of last 10 minutes
webhooks钩子
# 配置告警触发时的回调钩子,当告警触发后会请求该地址。业务方接受到回调后可发送短信、邮件等形式进行告警通知
# 请求方式:http post Content-type:application/json
webhooks:
# - http://127.0.0.1/notify/
# - http://127.0.0.1/go-wechat/
请求参数示例
@Setter
@Getter
public class AlarmMessage {
private int scopeId;
private String scope;
private String name;
private String id0;
private String id1;
private String ruleName;
private String alarmMessage;
private List<Tag> tags;
private long startTime;
private transient int period;
private transient boolean onlyAsCondition;
}
-
邮件告警示例
pom.xml依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-mail</artifactId>
</dependency>
邮件配置
spring:
mail:
host: smtp.qq.com
#发送者邮箱账号
username: 你的邮箱@xx.com
#发送者密钥
password: 你的邮箱服务密钥
default-encoding: utf-8
port: 465 #端口号465或587
protocol: smtp
properties:
mail:
debug:
false
smtp:
socketFactory:
class: javax.net.ssl.SSLSocketFactory
接收数据实体
@Setter
@Getter
public class SwAlarmDTO {
private int scopeId;
private String scope;
private String name;
private String id0;
private String id1;
private String ruleName;
private String alarmMessage;
private long startTime;
private transient boolean onlyAsCondition;
}
接口实现
import com.tuling.alarm.domain.SwAlarmDTO;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.mail.SimpleMailMessage;
import org.springframework.mail.javamail.JavaMailSender;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/alarm")
public class AlarmController {
private final JavaMailSender sender;
@Value("${spring.mail.username}")
private String from;
@PostMapping("/receive")
public void receive(@RequestBody List<SwAlarmDTO> alarmList){
alarmList.forEach(alarm -> log.info(alarm.toString()));
SimpleMailMessage message = new SimpleMailMessage();
// 发送者邮箱
message.setFrom(from);
// 接收者邮箱
message.setTo(from);
// 主题
message.setSubject("告警邮件");
String content = getContent(alarmList);
// 邮件内容
message.setText(content);
sender.send(message);
log.info("告警邮件已发送...");
}
private String getContent(List<SwAlarmDTO> alarmList) {
StringBuilder sb = new StringBuilder();
for (SwAlarmDTO dto : alarmList) {
sb.append("scopeId: ").append(dto.getScopeId())
.append("\nscope: ").append(dto.getScope())
.append("\n目标 Scope 的实体名称: ").append(dto.getName())
.append("\nScope 实体的 ID: ").append(dto.getId0())
.append("\nid1: ").append(dto.getId1())
.append("\n告警规则名称: ").append(dto.getRuleName())
.append("\n告警消息内容: ").append(dto.getAlarmMessage())
.append("\n告警时间: ").append(dto.getStartTime())
.append("\n\n---------------\n\n");
}
return sb.toString();
}
}
webhook配置
[root@ip-236-048 skywalking]# vim config/alarm-settings.yml
webhooks:
- http://127.0.0.1:8088/alarm/receive
十一、性能分析
这里引用
CSDN一篇文档,实际结果任需进行压测分析。 官方性能测试
-
说明
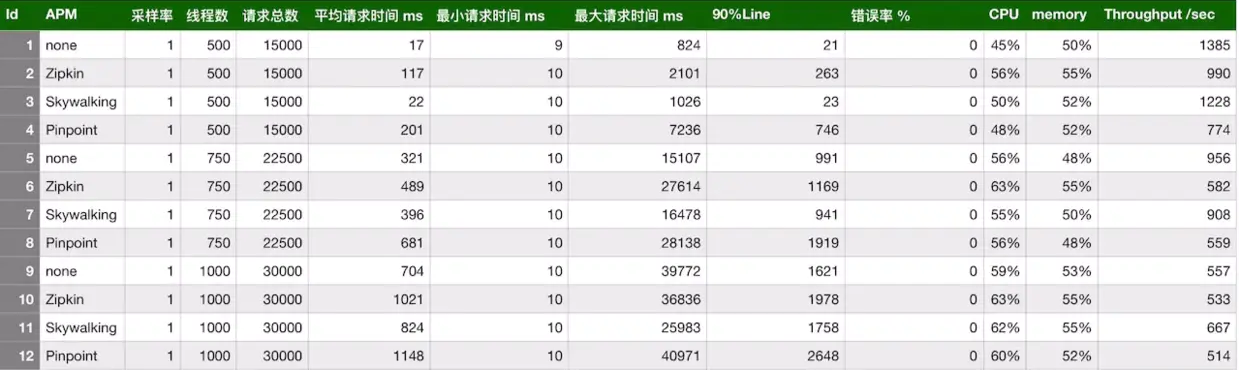
对 skywalking、zipkin、pinpoint 进行了压测,并与基线(未使用探针)的情况进行了对比。
模拟了三种并发用户:500,750,1000。使用jmeter测试,每个线程发送30个请求,设置思考时间为10ms。使用的采样率为1,即100%。
pinpoint默认的采样率为20,即50%,通过设置agent的配置文件改为100%。zipkin默认也是1。
组合起来,一共有12种。下面看下汇总表:
-
结论
skywalking的探针对吞吐量的影响最小,zipkin的吞吐量居中,pinpoint的探针对吞吐量的影响较为明显。
十二、接入skywalking的方式
skywalking的数据采集主要通过业务探针的方式(agent)来实现,针对不同的语言skywalkign提供了对应的agent实现。
-
java接入skywalking的三种方式
需要
java服务在启动阶段通过-javaagent:/xx/xx/skywalking-agent.jar进行参数指定。
# 前两种方式主要通过在构建Docker镜像的过程中将agent打包集成到Java服务镜像中,sidercar模式则是利用k8s的特性,通过共享的volume来实现
1. 使用官方提供的基础镜像
2. 将agent构建到已存在的基础镜像中
3. 通过sidecar模式挂载agent
十三、自定义agent镜像
官网提供的
agent镜像不支持kafka-fetcher和ingore-plugins插件,故需要来自定义镜像
步骤
1. 下载挂网agent包,这里以8.13.0版本为例
2. 拷贝skywalking-agent/ooptional-reporter-plugins目录中的
kafka-reporter-plugin-8.13.0.jar
到plugins目录,以支持kafka
3. 解压后,拷贝skywalking-agent/optional-plugins目录中的
apm-trace-ignore-plugin-8.13.0.jar
到pulgins或activations目录下,以支持忽略插件
4. 在config目录中新建
apm-trace-ignore-plugin.config
文件存放忽略端点配置
apm-trace-ignore-plugin.config
trace.ignore_path=${SW_AGENT_TRACE_IGNORE_PATH:GET:/actuator/**,/actuator/**,/eureka/**,Druid/**,Mysql/**,Lettuce/**,Gson/**}
Dockerfile
FROM 192.168.100.86/library/busybox:1.31.1
LABEL maintainer georgeyan
ENV LANG=C.UTF-8
RUN set -eux && mkdir -p /skywalking/agent/
ADD ./skywalking-agent/ /skywalking/agent/
WORKDIR /
build.sh
#!/bin/sh
# version
SKYWALKING_AGENT=8.13.0
SKYWALKING_AGENT_REPO=192.168.100.86/library/skywalking-agent:$SKYWALKING_AGENT
docker build -t $SKYWALKING_AGENT_REPO .
docker push $SKYWALKING_AGENT_REPO
项目集成
apiVersion: v1
kind: Pod
metadata:
name: agent-as-sidecar
spec:
replicas: 1
restartPolicy: Never
template:
metadata:
labels:
app: agent-as-sidecar
volumes:
- name: skywalking-agent
emptyDir: { }
initContainers:
- name: agent-container
image: 192.168.100.86/library/skywalking-agent:8.13.0
volumeMounts:
- name: skywalking-agent
mountPath: /agent
command: [ "/bin/sh" ]
args: [ "-c", "cp -R /skywalking/agent /agent/" ]
containers:
- name: app-container
image: springio/gs-spring-boot-docker
volumeMounts:
- name: skywalking-agent
mountPath: /skywalking
env:
- name: APP_NAME
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: 'metadata.labels[''app'']'
- name: MY_POD_IP
valueFrom:
fieldRef:
apiVersion: v1
fieldPath: status.podIP
- name: JAVA_TOOL_OPTIONS
value: "-javaagent:/skywalking/agent/skywalking-agent.jar"
- name: JAVA_OPTS
value: '-Duser.timezone=GMT+8 -Xms2048m -Xmx2048m'
- name: SW_AGENT_NAME
value: k8s::$(APP_NAME)
- name: SW_AGENT_INSTANCE_NAME
value: $(MY_POD_IP)@$(APP_NAME)
- name: SW_LOGGING_FILE_NAME
value: skywalking-api-lecshop-sales.log
- name: SW_AGENT_COLLECTOR_BACKEND_SERVICES
value: 10.60.30.155:11800 # FQDN: servicename.namespacename.svc.cluster.local
- name: SW_KAFKA_BOOTSTRAP_SERVERS
value: 192.168.100.71:30094
- name: SW_MOUNT_FOLDERS
value: plugins,activations
- name: SW_AGENT_TRACE_IGNORE_PATH
value: 'GET:/actuator/**,Lettuce/**,Druid/**'
十四、elasticsearch优化
-
开启高性能写模式
skywalking使用elasticsearch来做存储,但elasticsearch本身是有写入瓶颈的。一旦写入过多可能会报:429 Too many requsts错误
elasticsearch提升写入速度的几个方面
1. 加大 translog flush ,目的是降低 iops,writeblock
2. 加大 index refresh间隔, 目的除了降低 io, 更重要的降低了 segment merge 频率
3. 调整 bulk 线程池和队列
4. 优化磁盘间的任务均匀情况,将 shard 尽量均匀分布到物理主机的各磁盘
5. 优化节点间的任务分布,将任务尽量均匀的发到各节点
6. 优化 lucene 层建立索引的过程,目的是降低 CPU 占用率及 IO
elasticsearch.yml
# 锁定物理内存地址,防止elasticsearch内存被交换出去,也即是避免es使用swap交换分区
bootstrap.memory_lock: true
# 增大队列大小,建立索引的过程偏计算密集型任务,应该使用固定大小的线程池配置,来不及处理的放入队列,线程数量配置为 CPU 核心数+1,避免过多的上下文切换.队列大小可以适当增加
thread_pool.index.queue_size: 1000
thread_pool.write.queue_size: 1000
-
设置合理磁盘限额水位线
十五、优化Agent启动耗时
Agent是通过启动时挂载的,在启动阶段会判断新加载的类是否需要进行字节码增强,如果需要则通过增强逻辑修改字节码,之后JVM使用修改后的字节码创建对象。此过程中类的加载和类增强会比较耗时且不可避免。

-
优化方向
1. 如果在Agent端使用了Kafka来上报采集数据,Kafka的引入会带来较多的启动耗时。其中关于Topic的检查部分可以考虑移除,毕竟Kafka中Topic的准备应该是一次性的预处理工作。
2. 不需要增强的类。Agent提供的插件总数也不过十几个,那么插件中需要增强处理的类其实也可能就十几个,那么除了公司package命名规范的类和插件需要增强处理的类,其它都可以忽略。
3. 移除未使用到的插件,避免不必要的匹配逻辑。
十六、直播课程
平安健康千亿级全链路追踪系统的建设与实践

十七、参考文档
官网文档
Skywalking使用Kafka从Agent向服务端传输数据
Skywalking使用Zookeeper动态分配agent配置
SkyWalking 实现跨线程 Trace 传递
微服务平台之全链路追踪
Skywalking UI使用攻略
本文由 mdnice 多平台发布