一、pymsql
pymsql 是 Python 中操作 MySQL 的原生模块,其使用方法和 MySQL 的SQL语句几乎相同
1、下载安装
pip3 install pymysql
2、执行SQL
执行 SQL 语句的基本语法:
需要注意的是:创建链接后,都由游标来进行与数据库的操作,当然,拿到数据也靠游标
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
# 创建连接
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passw='123', db='t1')
# 创建游标
cursor = conn.cursor()
# 执行SQL,并返回收影响行数
effect_row = cursor.execute("update hosts set host = '1.1.1.2'")
# 执行SQL,并返回受影响行数
#effect_row = cursor.execute("update hosts set host = '1.1.1.2' where nid > %s", (1,))
# 执行SQL,并返回受影响行数
#effect_row = cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
# 提交,不然无法保存新建或者修改的数据
conn.commit()
# 关闭游标
cursor.close()
# 关闭连接
conn.close()
3、获取新创建数据自增ID
可以获取到最新自增的ID,也就是最后插入的一条数据ID
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passw='123', db='t1')
cursor = conn.cursor()
cursor.executemany("insert into hosts(host,color_id)values(%s,%s)", [("1.1.1.11",1),("1.1.1.11",2)])
conn.commit()
cursor.close()
conn.close()
# 获取最新自增ID
new_id = cursor.lastrowid
4、获取查询数据
获取查询数据的三种方式:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passw='123', db='t1')
cursor = conn.cursor()
cursor.execute("select * from hosts")
# 获取第一行数据
row_1 = cursor.fetchone()
# 获取前n行数据
# row_2 = cursor.fetchmany(3)
# 获取所有数据
# row_3 = cursor.fetchall()
conn.commit()
cursor.close()
conn.close()
5、移动游标
操作都是靠游标,那对游标的控制也是必须的
注:在fetch数据时按照顺序进行,可以使用cursor.scroll(num,mode)来移动游标位置,如: cursor.scroll(1,mode='relative') # 相对当前位置移动 cursor.scroll(2,mode='absolute') # 相对绝对位置移动
6、fetch数据类型
默认拿到的数据是小括号,元祖类型,如果是字典的话会更方便操作,那方法来了:
# 关于默认获取的数据是元祖类型,如果想要或者字典类型的数据,即:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import pymysql
conn = pymysql.connect(host='127.0.0.1', port=3306, user='root', passw='123', db='t1')
# 游标设置为字典类型
cursor = conn.cursor(cursor=pymysql.cursors.DictCursor)
r = cursor.execute("call p1()")
result = cursor.fetchone()
conn.commit()
cursor.close()
conn.close()7、利用 with 自动关闭
每次连接数据库都需要连接和关闭,啊,好多代码,那么方法又来了:
是不是很屌啊?
# 利用with定义函数
@contextlib.contextmanager
def mysql(self, host='127.0.0.1', port=3306, user='nick', passw='', db='db1', charset='utf8'):
self.conn = pymysql.connect(host=host, port=port, user=user, passw=passwd, db=db, charset=charset)
self.cuersor = self.conn.cursor(cursor=pymysql.cursors.DictCursor)
try:
yield self.cuersor
finally:
self.conn.commit()
self.cuersor.close()
self.conn.close()
# 执行
with mysql() as cuersor:
print(cuersor)
# 操作MySQL代码块二、SQLAlchemy
SQLAlchemy 简称 ORM 框架,该框架建立在数据库的 API 之上,使用关系对象映射来进行数据库操作;
简言之便是:将类对象转换成 SQL 语句,然后使用数据 API 执行 SQL 语句并获取执行结果。
1、下载安装
pip3 install SQLAlchemy
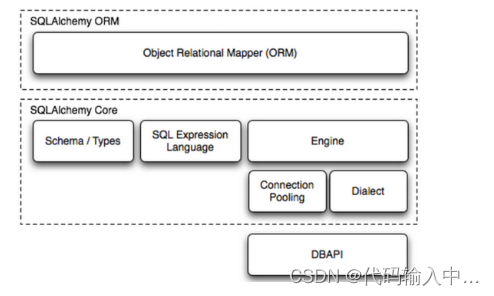
需要注意了:SQLAlchemy 自己无法操作数据库,必须结合 pymsql 等第三方插件,Dialect 用于和数据 API 进行交互,根据配置文件的不同调用不同的数据库 API,从而实现对数据库的操作,如:
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见:http://docs.sqlalchemy.org/en/latest/dialects/index.html
2、内部处理
使用 Engine/ConnectionPooling/Dialect 进行数据库操作,Engine使用ConnectionPooling连接数据库,然后再通过Dialect执行SQL语句。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy import create_engine
engine = create_engine("mysql+pymysql://root:123@127.0.0.1:3306/t1", max_overflow=5)
# 执行SQL
# cur = engine.execute(
# "INSERT INTO hosts (host, color_id) VALUES ('1.1.1.22', 3)"
# )
# 新插入行自增ID
# cur.lastrowid
# 执行SQL
# cur = engine.execute(
# "INSERT INTO hosts (host, color_id) VALUES(%s, %s)",[('1.1.1.22', 3),('1.1.1.221', 3),]
# )
# 执行SQL
# cur = engine.execute(
# "INSERT INTO hosts (host, color_id) VALUES (%(host)s, %(color_id)s)",
# host='1.1.1.99', color_id=3
# )
# 执行SQL
# cur = engine.execute('select * from hosts')
# 获取第一行数据
# cur.fetchone()
# 获取第n行数据
# cur.fetchmany(3)
# 获取所有数据
# cur.fetchall()3、ORM功能使用
使用 ORM/Schema Type/SQL Expression Language/Engine/ConnectionPooling/Dialect 所有组件对数据进行操作。
根据类创建对象,对象转换成SQL,执行SQL。
a、创建表
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
# 指定字符集、最大连接池数
engine = create_engine("mysql+pymysql://root:suoning@127.0.0.1:3306/suoning4?charset=utf8", max_overflow=5)
Base = declarative_base()
# 创建单表
class Users(Base):
# 表名
__tablename__ = 'users'
# 表字段
id = Column(Integer, primary_key=True) # 主键、默认自增
name = Column(String(32))
extra = Column(String(16))
__table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), # 唯一索引
Index('ix_id_name', 'name', 'extra'), # 普通索引
)
def __repr__(self):
# 查是输出的内容格式,本质还是对象
return "%s-%s" %(self.id, self.name)
# 一对多
class Favor(Base):
__tablename__ = 'favor'
nid = Column(Integer, primary_key=True)
caption = Column(String(50), default='red', unique=True) # 默认值、唯一索引
def __repr__(self):
return "%s-%s" %(self.nid, self.caption)
class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
favor_id = Column(Integer, ForeignKey("favor.nid"))
# 与生成表结构无关,仅用于查询方便
favor = relationship("Favor", backref='pers')
# 多对多
class ServerToGroup(Base):
# 关系表要放对应表上面,否则找不到
__tablename__ = 'servertogroup'
nid = Column(Integer, primary_key=True, autoincrement=True)
server_id = Column(Integer, ForeignKey('server.id')) # 外键
group_id = Column(Integer, ForeignKey('group.id'))
group = relationship("Group", backref='s2g')
server = relationship("Server", backref='s2g')
class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False) # 不能为空
port = Column(Integer, default=22)
# group = relationship('Group',secondary=ServerToGroup,backref='host_list')
class Server(Base):
__tablename__ = 'server'
id = Column(Integer, primary_key=True, autoincrement=True) # 自增
hostname = Column(String(64), unique=True, nullable=False)
def init_db():
# 创建表
Base.metadata.create_all(engine)
def drop_db():
# 删除表
Base.metadata.drop_all(engine)创建表
注:设置外检的另一种方式 ForeignKeyConstraint(['other_id'], ['othertable.other_id'])
b、操作表
操作表那必须导入模块,创建相应类,相应增\删\改\查的语法,详细见下code吧^^:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from sqlalchemy.ext.declarative import declarative_base
from sqlalchemy import Column, Integer, String, ForeignKey, UniqueConstraint, Index
from sqlalchemy.orm import sessionmaker, relationship
from sqlalchemy import create_engine
# 指定字符集、最大连接池数
engine = create_engine("mysql+pymysql://root:suoning@127.0.0.1:3306/suoning4?charset=utf8", max_overflow=5)
Base = declarative_base()
# 创建单表
class Users(Base):
# 表名
__tablename__ = 'users'
# 表字段
id = Column(Integer, primary_key=True) # 主键、默认自增
name = Column(String(32))
extra = Column(String(16))
__table_args__ = (
UniqueConstraint('id', 'name', name='uix_id_name'), # 唯一索引
Index('ix_id_name', 'name', 'extra'), # 普通索引
)
def __repr__(self):
# 查是输出的内容格式,本质还是对象
return "%s-%s" %(self.id, self.name)
# 一对多
class Favor(Base):
__tablename__ = 'favor'
nid = Column(Integer, primary_key=True)
caption = Column(String(50), default='red', unique=True) # 默认值、唯一索引
def __repr__(self):
return "%s-%s" %(self.nid, self.caption)
class Person(Base):
__tablename__ = 'person'
nid = Column(Integer, primary_key=True)
name = Column(String(32), index=True, nullable=True)
favor_id = Column(Integer, ForeignKey("favor.nid"))
# 与生成表结构无关,仅用于查询方便
favor = relationship("Favor", backref='pers')
# 多对多
class ServerToGroup(Base):
# 关系表要放对应表上面,否则找不到
__tablename__ = 'servertogroup'
nid = Column(Integer, primary_key=True, autoincrement=True)
server_id = Column(Integer, ForeignKey('server.id')) # 外键
group_id = Column(Integer, ForeignKey('group.id'))
group = relationship("Group", backref='s2g')
server = relationship("Server", backref='s2g')
class Group(Base):
__tablename__ = 'group'
id = Column(Integer, primary_key=True)
name = Column(String(64), unique=True, nullable=False) # 不能为空
port = Column(Integer, default=22)
# group = relationship('Group',secondary=ServerToGroup,backref='host_list')
class Server(Base):
__tablename__ = 'server'
id = Column(Integer, primary_key=True, autoincrement=True) # 自增
hostname = Column(String(64), unique=True, nullable=False)
def init_db():
# 创建表
Base.metadata.create_all(engine)
def drop_db():
# 删除表
Base.metadata.drop_all(engine)
# 先实例化sessionmaker类,Session对象加括号执行类下的__call__方法,
# 得到session对象,所以session可以调用Session类下的add,add_all等方法
Session = sessionmaker(bind=engine) # 指定引擎
session = Session()
# 增
# 添加一条
obj = Users(name="张三", extra='三儿')
session.add(obj)
# 添加多条
session.add_all([
Users(name="李四", extra='四儿'),
Users(name="汪五", extra='五儿'),
])
# 提交
session.commit()
# 删
session.query(Users).filter(Users.id > 2).delete()
session.query(Users).filter_by(id = 1).delete()
session.commit()
# 改
session.query(Users).filter(Users.id > 2).update({"name" : "nick"})
session.query(Users).filter(Users.id > 2).update({"name" : "nick", "extra":"niubily"})
session.query(Users).filter(Users.id > 2).update({Users.name: Users.name + "Suo"}, synchronize_session=False)
session.query(Users).filter(Users.id > 2).update({"num": Users.num + 1}, synchronize_session="evaluate")
session.commit()
# 查
# all()结果为对象列表,first()为具体对象
ret = session.query(Users).all()
ret = session.query(Users.name, Users.extra).all()
ret = session.query(Users).filter_by(name='nick').all()
ret = session.query(Users).filter_by(name='nick').first()
print(ret)
那如何加限制条件等,我要更灵活使用,好吧,还是见下 code:
# 条件
ret = session.query(Users).filter_by(name='nick').all()
ret = session.query(Users).filter(Users.id > 1, Users.name == 'nick').all()
ret = session.query(Users).filter(Users.id.between(1, 3), Users.name == 'nick').all()
ret = session.query(Users).filter(Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(~Users.id.in_([1,3,4])).all()
ret = session.query(Users).filter(Users.id.in_(session.query(Users.id).filter_by(name='nick'))).all()
from sqlalchemy import and_, or_ # 导入模块
ret = session.query(Users).filter(and_(Users.id > 3, Users.name == 'nick')).all()
ret = session.query(Users).filter(or_(Users.id < 2, Users.name == 'nick')).all()
ret = session.query(Users).filter(
or_(
Users.id < 2,
and_(Users.name == 'nick', Users.id > 3),
Users.extra != ""
)).all()
# 通配符
ret = session.query(Users).filter(Users.name.like('n%')).all()
ret = session.query(Users).filter(~Users.name.like('n%')).all()
# 限制
ret = session.query(Users)[1:2]
# 排序
ret = session.query(Users).order_by(Users.name.desc()).all()
ret = session.query(Users).order_by(Users.name.desc(), Users.id.asc()).all()
# 分组
from sqlalchemy.sql import func # 导入模块
ret = session.query(Users).group_by(Users.extra).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).all()
ret = session.query(
func.max(Users.id),
func.sum(Users.id),
func.min(Users.id)).group_by(Users.name).having(func.min(Users.id) >2).all()
# 连表
ret = session.query(Users, Favor).filter(Users.id == Favor.nid).all()
ret = session.query(Person).join(Favor).all()
ret = session.query(Person).join(Favor, isouter=True).all()
# isouter=True 理解为 left join ,如果不写为 inner join
# 组合
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union(q2).all()
q1 = session.query(Users.name).filter(Users.id > 2)
q2 = session.query(Favor.caption).filter(Favor.nid < 2)
ret = q1.union_all(q2).all()