MYSQL学习之buffer pool的理论学习
by 小乌龟
文章目录
- MYSQL学习之buffer pool的理论学习
- 前言
- 一、buffer pool是什么?
- 二、buffer pool 的内存结构
- 三、buffer pool 的初始化和配置
- 初始化
- 配置
- 四、buffer pool 空间管理
- LRU淘汰法
- 冷热数据分离的LRU算法
- 1.引入库
- 2.读入数据
- 总结
前言
提示:这里可以添加本文要记录的大概内容:
例如:随着人工智能的不断发展,机器学习这门技术也越来越重要,很多人都开启了学习机器学习,本文就介绍了机器学习的基础内容。
提示:以下是本篇文章正文内容,下面案例可供参考
一、buffer pool是什么?
我们都知道,MySQL的数据都是存储在磁盘空间中的,但是操作系统与磁盘的交互是比较耗时的,势必会影响MySQL的性能,如果要提高MySQL的性能,势必要解决交互的速度问题,为了解决这一问题,buffer pool 应运而生。buffer pool 是MySQL在内存中专门为自己开辟的内存空间,相当于数据缓存,主要目的是暂存一些使用频率较高的一些,以达到提高MySQL性能的。
二、buffer pool 的内存结构
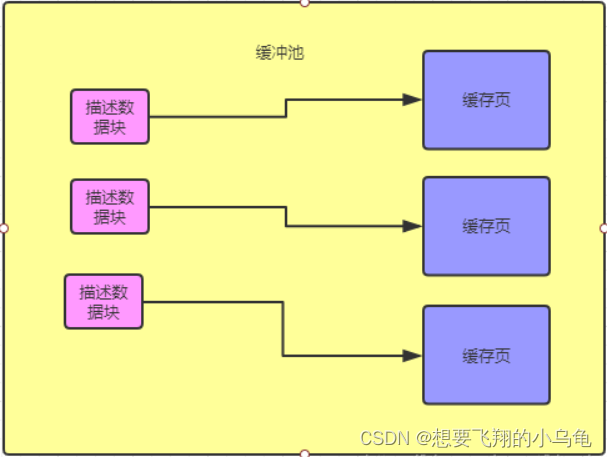
buffer pool 中主要包含两部分:数据页和数据块,数据页主要存储MySQL的数据,数据块主要存储和数据也相关的信息,两者一一对应;
-
数据页:存储MySQL中的真实数据,每一页的默认大小为16KB。
-
数据块:存储数据页的页码,在buffer pool中的地址以及数据页所属的表空间等数据,大约为数据页大小的5%,816个字节左右。
三、buffer pool 的初始化和配置
初始化
1、MySQL 启动时,会根据参数 innodb_buffer_pool_size 的值来为 Buffer Pool 分配内存区域。
2、然后会按照缓存页的默认大小 16k 以及对应的描述数据块的 800个字节 左右大小,在 Buffer Pool 中划分中一个个的缓存页和一个个的描述数据库块。
此时的缓存页和描述数据块都是空的,毕竟才刚启动 MySQL
配置
?
四、buffer pool 空间管理
缓冲池的大小是有限的,当数据页不断被复制到缓冲池中时,必然会出现溢出的情况,因此要存在相应的淘汰策略去不断淘汰到缓冲池中的数剧,同时还要保证常用的数据能够保存在缓冲池中。buffer pool采用LRU方法进行数据页的数据页的淘汰管理,(LRU,全称是 Least Recently Used,中文名字叫作「最近最少使用」)顾名思义,淘汰最近最少使用的数据页。
但是呢,如果基于此算法,当遇到全表扫描时,此时缓存池中会加载大量的新的数据页,从而将缓存池中的已存在的且被频繁访问的数据页替换出去,从而也影响了MySQL的性能,因此,基于冷热数据分离的LRU算法登场;
LRU淘汰法
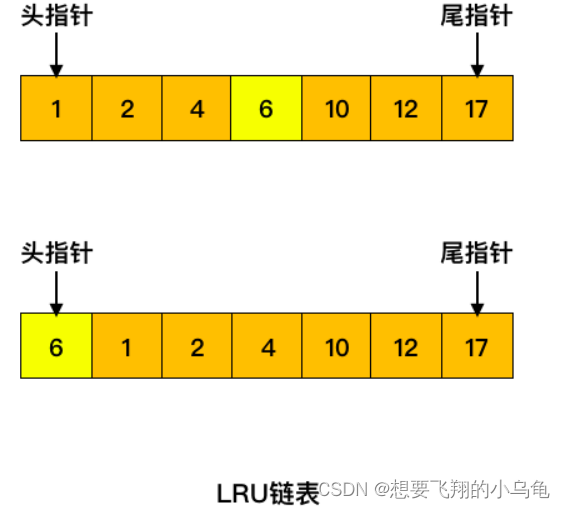
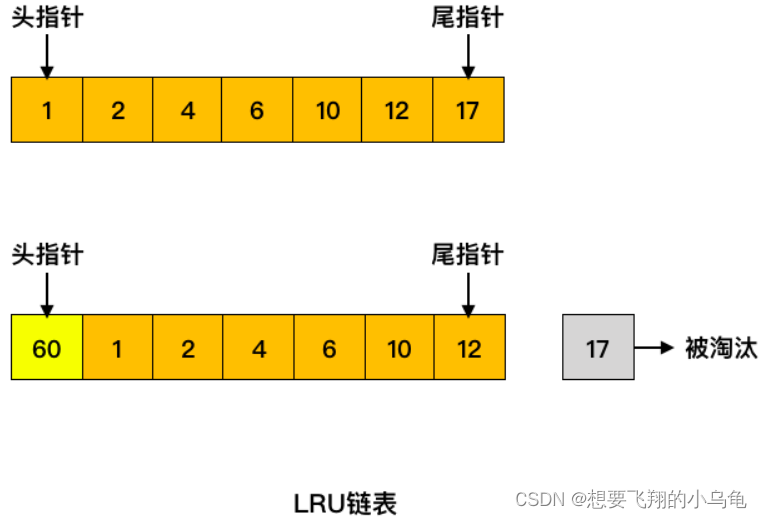
首先,为了能够完成LRU算法,底层采用链表的形式存储数据的地址,链表中每一个节点存储的是该节点所指向数据页的地址(此节点也称为称为控制块),当有一个数据页被访问时,此节点会移动到表头,基于此算法,表尾的节点自然就成为了最少使用的节点,当要进行淘汰数据页操作时时,将表尾节点所指向的内存替换即可,同时删掉此链表的结尾结点。通常我们此链表称为LRU链表
1. 缓存页已在缓冲池中
这种情况下会将对应的缓存页放到 LRU 链表的头部,无需从磁盘再进行读取,也无需淘汰其它缓存页。
如下图所示,如果要访问的数据在 6 号页中,则将 6 号页放到链表头部即可,这种情况下没有缓存页被淘汰。
2. 缓存页不在缓冲池中
缓存页不在缓冲中,这时候就需要从磁盘中读入对应的数据页,将其放置在链表头部,同时淘汰掉末尾的缓存页
如下图所示,如果要访问的数据在 60 号页中,60 号页不在缓冲池中,此时加载进来放到链表的头部,同时淘汰掉末尾的 17 号缓存页。
冷热数据分离的LRU算法
冷人数据分离的LRU算法就是将 LRU 链表分为两部分,一部分为热数据区域,一部分为冷数据区域。
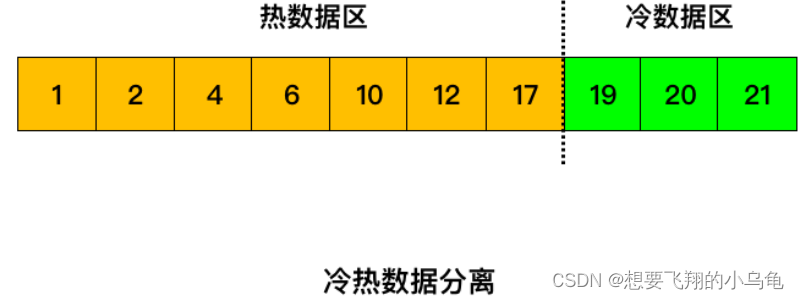
当数据页第一次被加载到缓冲池中的时候,先将其放到冷数据区域的链表头部,1s(由 innodb_old_blocks_time 参数控制) 后该缓存页被访问了再将其移至热数据区域的链表头部。
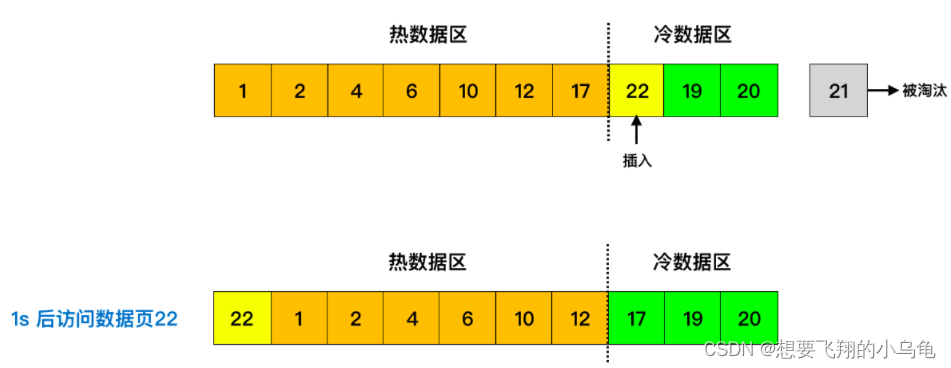
基于此算法,当遇到全表扫描时,新数据只会在冷数据区进行频繁的淘汰替换,并不会全部占满缓冲池,因此有效的保证了其他真正频繁被使用的数据;那么为什么是大于1秒呢?要知道,缓冲区中冷数据替换是相对较快的,如果大于了1s后又被访问到,说明此数据有足够的的资格被列为频繁被访问的数据。就好像我们高中时后的尖子生班和中等班的流动名额,尖子升班最后几名的是替换的非常快的,如果最后几名中有一名同学在经过很多轮的考试后,依然挺拔且坚定的的矗立在尖子上里,即使是在最后的角落里,那么此同学是不是也是一名强者,有资格被认定为尖子生!!(为尖子生鼓掌)
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。

![[嵌入式AI从0开始到入土]10_yolov5在昇腾上应用](https://img-blog.csdnimg.cn/direct/b9b59b34925e4cf7ada2c8381330999f.png)

![[C#]Onnxruntime部署Chinese CLIP实现以文搜图以文找图功能](https://img-blog.csdnimg.cn/direct/6cfab5ee5cb544d7b536b28bad953ba0.jpeg)