【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax概述
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax快速入门
【大数据进阶第三阶段之Datax学习笔记】阿里云开源离线同步工具Datax类图
【大数据进阶第三阶段之Datax学习笔记】使用阿里云开源离线同步工具Datax实现数据同步
目录
1、Datax概览
1.1 DataX
1.2 DataX 商业版本
1.3 Features
1.4 DataX的设计
1.5 DataX3.0框架设计
1.6 DataX3.0插件体系
1.7 Datax3.0核心架构及运行原理
1.8 核心优势
1.8.1 可靠的数据质量监控
1.8.2 丰富的数据转换功能
1.8.3 精准的速度控制
1.8.4 强劲的同步性能
1.8.5 健壮的容错机制
1.8.6 极简的使用体验
1、Datax概览
1.1 DataX
DataX 是阿里云 DataWorks数据集成 的开源版本,在阿里巴巴集团内被广泛使用的离线数据同步工具/平台。DataX 实现了包括 MySQL、Oracle、OceanBase、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、Hologres、DRDS, databend 等各种异构数据源之间高效的数据同步功能。
1.2 DataX 商业版本
阿里云DataWorks数据集成是DataX团队在阿里云上的商业化产品,致力于提供复杂网络环境下、丰富的异构数据源之间高速稳定的数据移动能力,以及繁杂业务背景下的数据同步解决方案。目前已经支持云上近3000家客户,单日同步数据超过3万亿条。DataWorks数据集成目前支持离线50+种数据源,可以进行整库迁移、批量上云、增量同步、分库分表等各类同步解决方案。2020年更新实时同步能力,支持10+种数据源的读写任意组合。提供MySQL,Oracle等多种数据源到阿里云MaxCompute,Hologres等大数据引擎的一键全增量同步解决方案。
商业版本参见: DataWorks_大数据开发治理平台_阿里巴巴数据治理最佳实践-阿里云
1.3 Features
DataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上DataX框架可以支持任意数据源类型的数据同步工作。同时DataX插件体系作为一套生态系统, 每接入一套新数据源该新加入的数据源即可实现和现有的数据源互通。
1.4 DataX的设计
为了解决异构数据源同步问题,DataX将复杂的网状的同步链路变成了星型数据链路,DataX作为中间传输载体负责连接各种数据源。当需要接入一个新的数据源的时候,只需要将此数据源对接到DataX,便能跟已有的数据源做到无缝数据同步。

1.5 DataX3.0框架设计
DataX本身作为离线数据同步框架,采用Framework + plugin架构构建。将数据源读取和写入抽象成为Reader/Writer插件,纳入到整个同步框架中。

DataX在设计之初就将同步理念抽象成框架+插件的形式.框架负责内部的序列化传输,缓冲,并发,转换等而核心技术问题,数据的采集(Reader)和落地(Writer)完全交给插件执行。
- Read 数据采集模块,负责采集数据源的数据,将数据发送至FrameWork。
- Writer 数据写入模块,负责不断的向FrameWork取数据,并将数据写入目的端。
- FrameWork 用于连接reader和write,作为两者的数据传输通道,处理缓冲,流控,并发,转换等核心技术问题。
1.6 DataX3.0插件体系
DataX目前已经有了比较全面的插件体系,主流的RDBMS数据库、NOSQL、大数据计算系统都已经接入,目前支持数据如下图:
| 类型 | 数据源 | Reader(读) | Writer(写) | 文档 |
|---|---|---|---|---|
| RDBMS 关系型数据库 | MySQL | √ | √ | 读 、写 |
| Oracle | √ | √ | 读 、写 | |
| OceanBase | √ | √ | 读 、写 | |
| SQLServer | √ | √ | 读 、写 | |
| PostgreSQL | √ | √ | 读 、写 | |
| DRDS | √ | √ | 读 、写 | |
| Kingbase | √ | √ | 读 、写 | |
| 通用RDBMS(支持所有关系型数据库) | √ | √ | 读 、写 | |
| 阿里云数仓数据存储 | ODPS | √ | √ | 读 、写 |
| ADB | √ | 写 | ||
| ADS | √ | 写 | ||
| OSS | √ | √ | 读 、写 | |
| OCS | √ | 写 | ||
| Hologres | √ | 写 | ||
| AnalyticDB For PostgreSQL | √ | 写 | ||
| 阿里云中间件 | datahub | √ | √ | 读 、写 |
| SLS | √ | √ | 读 、写 | |
| 图数据库 | 阿里云 GDB | √ | √ | 读 、写 |
| Neo4j | √ | 写 | ||
| NoSQL数据存储 | OTS | √ | √ | 读 、写 |
| Hbase0.94 | √ | √ | 读 、写 | |
| Hbase1.1 | √ | √ | 读 、写 | |
| Phoenix4.x | √ | √ | 读 、写 | |
| Phoenix5.x | √ | √ | 读 、写 | |
| MongoDB | √ | √ | 读 、写 | |
| Cassandra | √ | √ | 读 、写 | |
| 数仓数据存储 | StarRocks | √ | √ | 读 、写 |
| ApacheDoris | √ | 写 | ||
| ClickHouse | √ | √ | 读 、写 | |
| Databend | √ | 写 | ||
| Hive | √ | √ | 读 、写 | |
| kudu | √ | 写 | ||
| selectdb | √ | 写 | ||
| 无结构化数据存储 | TxtFile | √ | √ | 读 、写 |
| FTP | √ | √ | 读 、写 | |
| HDFS | √ | √ | 读 、写 | |
| Elasticsearch | √ | 写 | ||
| 时间序列数据库 | OpenTSDB | √ | 读 | |
| TSDB | √ | √ | 读 、写 | |
| TDengine | √ | √ | 读 、写 |
1.7 Datax3.0核心架构及运行原理
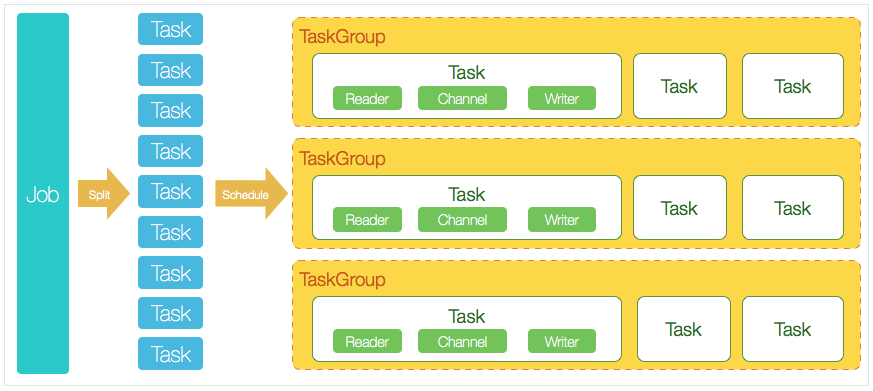
- Job 完成单个数据同步的作业称之为job。DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。负责数据清理,子任务划分,TaskGroup监控管理。
- Task 由Job切分而来,是DataX作业的最小单元,每个Task负责一部分数据的同步工作。
- Schedule 将Task组成TaskGroup,默认单个任务组的并发数量为5。
- TaskGroup 负责启动Task。
详细解说:DataX完成单个数据同步的作业,我们称之为Job,DataX接受到一个Job之后,将启动一个进程来完成整个作业同步过程。DataX Job模块是单个作业的中枢管理节点,承担了数据清理、子任务切分(将单一作业计算转化为多个子Task)、TaskGroup管理等功能。DataXJob启动后,会根据不同的源端切分策略,将Job切分成多个小的Task(子任务),以便于并发执行。Task便是DataX作业的最小单元,每一个Task都会负责一部分数据的同步工作。切分多个Task之后,DataX Job会调用Scheduler模块,根据配置的并发数据量,将拆分成的Task重新组合,组装成TaskGroup(任务组)。每一个TaskGroup负责以一定的并发运行完毕分配好的所有Task,默认单个任务组的并发数量为5。每一个Task都由TaskGroup负责启动,Task启动后,会固定启动Reader—>Channel—>Writer的线程来完成任务.
DataX调度流程
举例来说,用户提交了一个DataX作业,并且配置了20个并发,目的是将一个100张分表的mysql数据同步到odps里面。 DataX的调度决策思路是:
- 1 DataXJob根据分库分表切分成了100个Task。
- 2 根据20个并发,默认单个任务组的并发数量为5,DataX计算共需要分配4个TaskGroup。
- 3 这里4个TaskGroup平分切分好的100个Task,每一个TaskGroup负责以5个并发共计运行25个Task。
1.8 核心优势
1.8.1 可靠的数据质量监控
-
完美解决数据传输个别类型失真问题
DataX旧版对于部分数据类型(比如时间戳)传输一直存在毫秒阶段等数据失真情况,新版本DataX3.0已经做到支持所有的强数据类型,每一种插件都有自己的数据类型转换策略,让数据可以完整无损的传输到目的端。
-
提供作业全链路的流量、数据量运行时监控
DataX3.0运行过程中可以将作业本身状态、数据流量、数据速度、执行进度等信息进行全面的展示,让用户可以实时了解作业状态。并可在作业执行过程中智能判断源端和目的端的速度对比情况,给予用户更多性能排查信息。
-
提供脏数据探测
在大量数据的传输过程中,必定会由于各种原因导致很多数据传输报错(比如类型转换错误),这种数据DataX认为就是脏数据。DataX目前可以实现脏数据精确过滤、识别、采集、展示,为用户提供多种的脏数据处理模式,让用户准确把控数据质量大关!
1.8.2 丰富的数据转换功能
DataX作为一个服务于大数据的ETL工具,除了提供数据快照搬迁功能之外,还提供了丰富数据转换的功能,让数据在传输过程中可以轻松完成数据脱敏,补全,过滤等数据转换功能,另外还提供了自动groovy函数,让用户自定义转换函数。详情请看DataX3的transformer详细介绍。
1.8.3 精准的速度控制
还在为同步过程对在线存储压力影响而担心吗?新版本DataX3.0提供了包括通道(并发)、记录流、字节流三种流控模式,可以随意控制你的作业速度,让你的作业在库可以承受的范围内达到最佳的同步速度。
"speed": {
"channel": 5,
"byte": 1048576,
"record": 10000
}1.8.4 强劲的同步性能
DataX3.0每一种读插件都有一种或多种切分策略,都能将作业合理切分成多个Task并行执行,单机多线程执行模型可以让DataX速度随并发成线性增长。在源端和目的端性能都足够的情况下,单个作业一定可以打满网卡。另外,DataX团队对所有的已经接入的插件都做了极致的性能优化,并且做了完整的性能测试。性能测试相关详情可以参照每单个数据源的详细介绍:DataX数据源指南
1.8.5 健壮的容错机制
DataX作业是极易受外部因素的干扰,网络闪断、数据源不稳定等因素很容易让同步到一半的作业报错停止。因此稳定性是DataX的基本要求,在DataX 3.0的设计中,重点完善了框架和插件的稳定性。目前DataX3.0可以做到线程级别、进程级别(暂时未开放)、作业级别多层次局部/全局的重试,保证用户的作业稳定运行。
-
线程内部重试
DataX的核心插件都经过团队的全盘review,不同的网络交互方式都有不同的重试策略。
-
线程级别重试
目前DataX已经可以实现TaskFailover,针对于中间失败的Task,DataX框架可以做到整个Task级别的重新调度。
1.8.6 极简的使用体验
易用:下载即可用,支持linux和windows,只需要短短几步骤就可以完成数据的传输。请点击:Quick Start
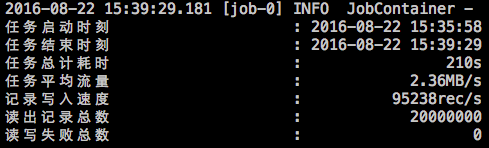
详细:DataX在运行日志中打印了大量信息,其中包括传输速度,Reader、Writer性能,进程CPU,JVM和GC情况等等。
传输过程中打印传输速度、进度

传输过程中会打印进程相关的CPU、JVM

任务结束后,打印总体运行情况
参考:
GitHub - alibaba/DataX: DataX是阿里云DataWorks数据集成的开源版本。

![[嵌入式AI从0开始到入土]10_yolov5在昇腾上应用](https://img-blog.csdnimg.cn/direct/b9b59b34925e4cf7ada2c8381330999f.png)

![[C#]Onnxruntime部署Chinese CLIP实现以文搜图以文找图功能](https://img-blog.csdnimg.cn/direct/6cfab5ee5cb544d7b536b28bad953ba0.jpeg)