[嵌入式AI从0开始到入土]嵌入式AI系列教程
注:等我摸完鱼再把链接补上
可以关注我的B站号工具人呵呵的个人空间,后期会考虑出视频教程,务必催更,以防我变身鸽王。
第一章 昇腾Altas 200 DK上手
第二章 下载昇腾案例并运行
第三章 官方模型适配工具使用
第四章 炼丹炉的搭建(基于Ubuntu23.04 Desktop)
第五章 Ubuntu远程桌面配置
第六章 下载yolo源码及样例运行验证
第七章 转化为昇腾支持的om离线模型
第八章 jupyter lab的使用
第九章 yolov5在昇腾上推理
第十章 yolov5在昇腾上应用
未完待续…
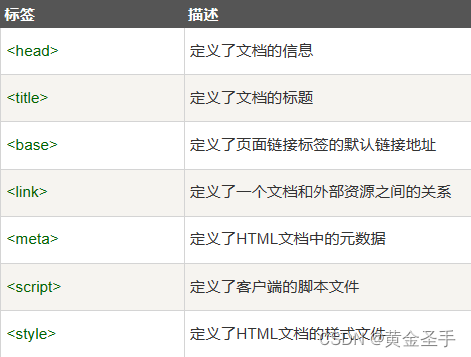
文章目录
- [嵌入式AI从0开始到入土]嵌入式AI系列教程
- 前言
- 一、获取案例
- 1、获取系统镜像
- 2、获取案例
- 3、原始案例
- 二、修改案例
- 1、打开jupyter
- 2、atc转换模型
- 3、安装依赖
- 4、修改预处理函数
- 5、修改模型和标签路径
- 6、选择你需要的推理模式
- 三、问题
- 1、No module named 'scikit'
- 2、No module named 'ais_bench'
- 3、 InputTensor Data Type mismatches.
- 1、怀疑导出onnx模型问题
- 2、怀疑版本问题
- 3、om模型有问题!!!
- 4、预测框错乱
- 总结
前言
注:本文基于Atlas 200 Dk编写,其他版本可能会有版本依赖问题
上一节中,我们已经完成了图片推理,但是仅仅图像的推理怎么够,起码得视频或者摄像头吧。因此我参考了案例,进行了修改。
一、获取案例
我扒了200i DK A2的案例下来(似乎官方没有给案例的下载地址),当然你也可以使用上一节的资源包,然后新建这个案例文件。
当然你可以使用我本文置顶的资源,都是我测试完成的。
1、获取系统镜像
下载地址:https://ascend-repo.obs.cn-east-2.myhuaweicloud.com/Atlas%20200I%20DK%20A2/DevKit/images/23.0.RC3/1.2.3/A200I-DK-A2_desktop-image_1.2.3_ubuntu22.04-aarch64.img.xz
2、获取案例
下载完后,解压,在Ubuntu中挂载A200I-DK-A2_desktop-image_1.2.3_ubuntu22.04-aarch64.img镜像文件,案例在root_fs/home/HwHiAiUser/samples/notebooks下。这次我们取第一个案例即可。
复制出来,上传到200DK。
3、原始案例
这里贴一份出来,毕竟镜像有一点点大。挂资源大概率过不了审核。
# 导入代码依赖
import cv2
import numpy as np
import ipywidgets as widgets
from IPython.display import display
import torch
from skvideo.io import vreader, FFmpegWriter
import IPython.display
from ais_bench.infer.interface import InferSession
from det_utils import letterbox, scale_coords, nms
def preprocess_image(image, cfg, bgr2rgb=True):
"""图片预处理"""
img, scale_ratio, pad_size = letterbox(image, new_shape=cfg['input_shape'])
if bgr2rgb:
img = img[:, :, ::-1]
img = img.transpose(2, 0, 1) # HWC2CHW
img = np.ascontiguousarray(img, dtype=np.float32)
return img, scale_ratio, pad_size
def draw_bbox(bbox, img0, color, wt, names):
"""在图片上画预测框"""
det_result_str = ''
for idx, class_id in enumerate(bbox[:, 5]):
if float(bbox[idx][4] < float(0.05)):
continue
img0 = cv2.rectangle(img0, (int(bbox[idx][0]), int(bbox[idx][1])), (int(bbox[idx][2]), int(bbox[idx][3])),
color, wt)
img0 = cv2.putText(img0, str(idx) + ' ' + names[int(class_id)], (int(bbox[idx][0]), int(bbox[idx][1] + 16)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
img0 = cv2.putText(img0, '{:.4f}'.format(bbox[idx][4]), (int(bbox[idx][0]), int(bbox[idx][1] + 32)),
cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 1)
det_result_str += '{} {} {} {} {} {}\n'.format(
names[bbox[idx][5]], str(bbox[idx][4]), bbox[idx][0], bbox[idx][1], bbox[idx][2], bbox[idx][3])
return img0
def get_labels_from_txt(path):
"""从txt文件获取图片标签"""
labels_dict = dict()
with open(path) as f:
for cat_id, label in enumerate(f.readlines()):
labels_dict[cat_id] = label.strip()
return labels_dict
def draw_prediction(pred, image, labels):
"""在图片上画出预测框并进行可视化展示"""
imgbox = widgets.Image(format='jpg', height=720, width=1280)
img_dw = draw_bbox(pred, image, (0, 255, 0), 2, labels)
imgbox.value = cv2.imencode('.jpg', img_dw)[1].tobytes()
display(imgbox)
def infer_image(img_path, model, class_names, cfg):
"""图片推理"""
# 图片载入
image = cv2.imread(img_path)
# 数据预处理
img, scale_ratio, pad_size = preprocess_image(image, cfg)
# 模型推理
output = model.infer([img])[0]
output = torch.tensor(output)
# 非极大值抑制后处理
boxout = nms(output, conf_thres=cfg["conf_thres"], iou_thres=cfg["iou_thres"])
pred_all = boxout[0].numpy()
# 预测坐标转换
scale_coords(cfg['input_shape'], pred_all[:, :4], image.shape, ratio_pad=(scale_ratio, pad_size))
# 图片预测结果可视化
draw_prediction(pred_all, image, class_names)
def infer_frame_with_vis(image, model, labels_dict, cfg, bgr2rgb=True):
# 数据预处理
img, scale_ratio, pad_size = preprocess_image(image, cfg, bgr2rgb)
# 模型推理
output = model.infer([img])[0]
output = torch.tensor(output)
# 非极大值抑制后处理
boxout = nms(output, conf_thres=cfg["conf_thres"], iou_thres=cfg["iou_thres"])
pred_all = boxout[0].numpy()
# 预测坐标转换
scale_coords(cfg['input_shape'], pred_all[:, :4], image.shape, ratio_pad=(scale_ratio, pad_size))
# 图片预测结果可视化
img_vis = draw_bbox(pred_all, image, (0, 255, 0), 2, labels_dict)
return img_vis
def img2bytes(image):
"""将图片转换为字节码"""
return bytes(cv2.imencode('.jpg', image)[1])
def infer_video(video_path, model, labels_dict, cfg):
"""视频推理"""
image_widget = widgets.Image(format='jpeg', width=800, height=600)
display(image_widget)
# 读入视频
cap = cv2.VideoCapture(video_path)
while True:
ret, img_frame = cap.read()
if not ret:
break
# 对视频帧进行推理
image_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg, bgr2rgb=True)
image_widget.value = img2bytes(image_pred)
def infer_camera(model, labels_dict, cfg):
"""外设摄像头实时推理"""
def find_camera_index():
max_index_to_check = 10 # Maximum index to check for camera
for index in range(max_index_to_check):
cap = cv2.VideoCapture(index)
if cap.read()[0]:
cap.release()
return index
# If no camera is found
raise ValueError("No camera found.")
# 获取摄像头
camera_index = find_camera_index()
cap = cv2.VideoCapture(camera_index)
# 初始化可视化对象
image_widget = widgets.Image(format='jpeg', width=1280, height=720)
display(image_widget)
while True:
# 对摄像头每一帧进行推理和可视化
_, img_frame = cap.read()
image_pred = infer_frame_with_vis(img_frame, model, labels_dict, cfg)
image_widget.value = img2bytes(image_pred)
cfg = {
'conf_thres': 0.4, # 模型置信度阈值,阈值越低,得到的预测框越多
'iou_thres': 0.5, # IOU阈值,高于这个阈值的重叠预测框会被过滤掉
'input_shape': [640, 640], # 模型输入尺寸
}
model_path = 'yolo.om'
label_path = './coco_names.txt'
# 初始化推理模型
model = InferSession(0, model_path)
labels_dict = get_labels_from_txt(label_path)
infer_mode = 'video'
if infer_mode == 'image':
img_path = 'world_cup.jpg'
infer_image(img_path, model, labels_dict, cfg)
elif infer_mode == 'camera':
infer_camera(model, labels_dict, cfg)
elif infer_mode == 'video':
video_path = 'racing.mp4'
infer_video(video_path, model, labels_dict, cfg)
二、修改案例
1、打开jupyter
在yolov5_ascend_example文件夹下打开终端,输入
jupyter lab --ip 192.168.3.2 --allow-root
电脑浏览器访问http://192.168.3.2:8888,右侧打开我们的mian.ipynb文件。
2、atc转换模型
200DK照抄,200I DK A2最后改成Ascend 310B1
atc --model=models/best.onnx --framework=5 --output=models/mymodel --input_format=NCHW --input_shape="images:1,3,640,640" --input_fp16_nodes=images --log=error --soc_version=Ascend310
运行结果如下,大约5到10分钟。当然,你也可以用ubuntu主机去做,会快很多,我用pc转换只需要半分钟左右,还是一台4代i7的老年机。

3、安装依赖
使用我的案例代码的直接运行即可
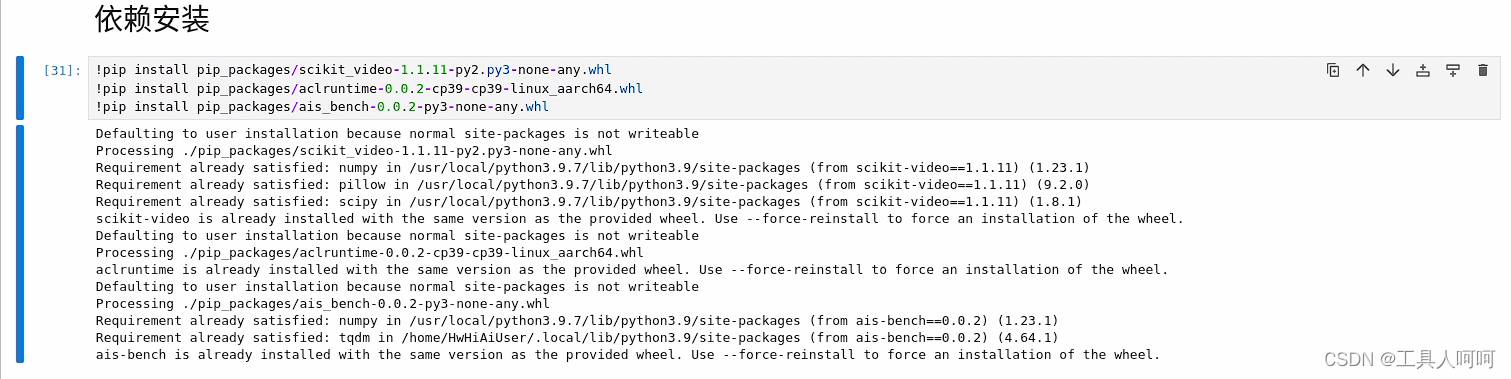
其他的请按照以下方法安装
!pip install scikit_video
!pip install pip_packages/aclruntime-0.0.2-cp39-cp39-linux_aarch64.whl
!pip install pip_packages/ais_bench-0.0.2-py3-none-any.whl
注意,aclruntime和ais_bench推理程序的whl包请前往昇腾gitee仓库下载。
4、修改预处理函数
这里我们使用自己训练的模型,需要做如下修改。
将img = np.ascontiguousarray(img, dtype=np.float32)改为img = np.ascontiguousarray(img, dtype=np.float16)/255.0
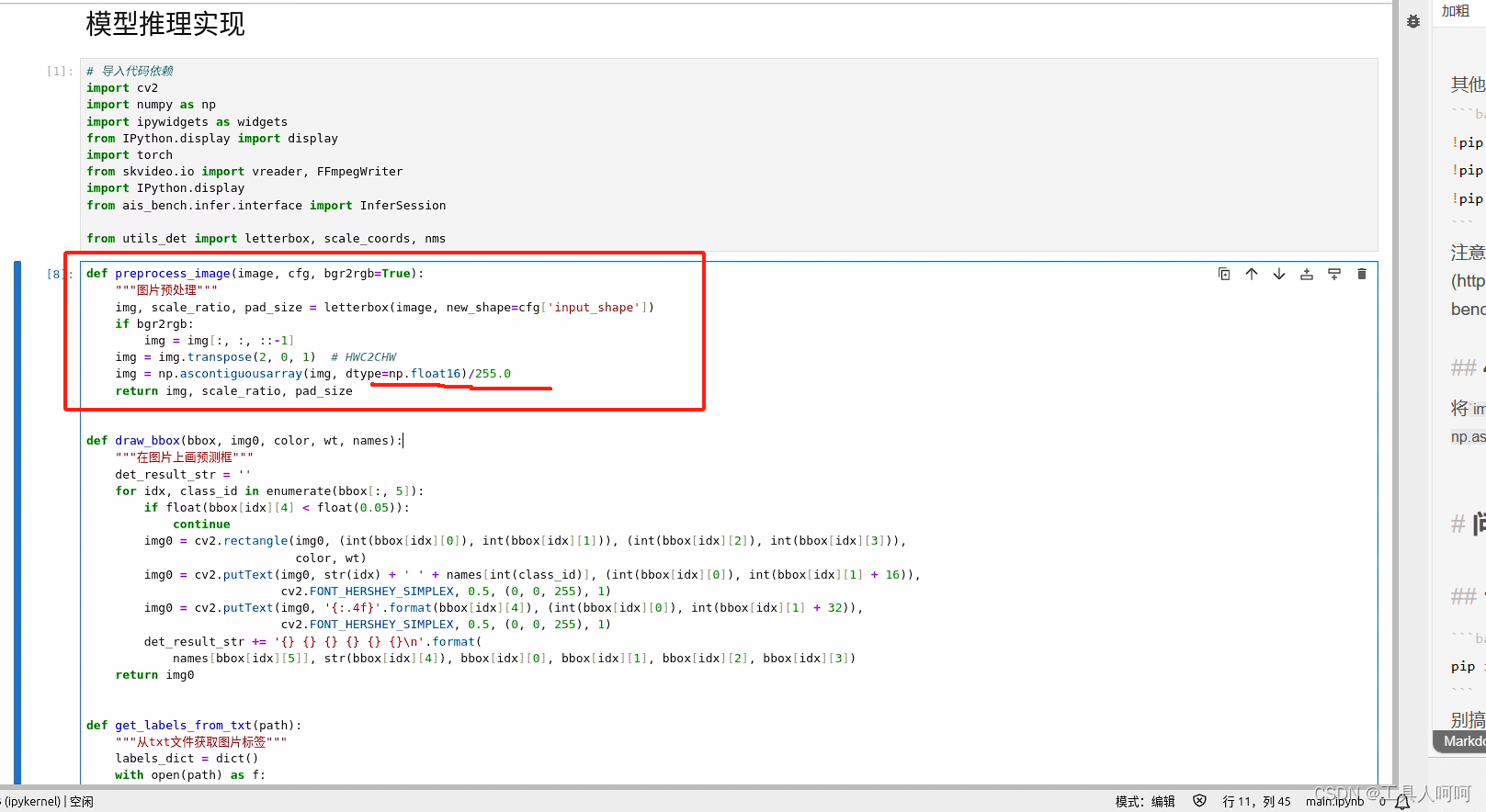
5、修改模型和标签路径

6、选择你需要的推理模式

这里务必注意,如果是在vscode里远程打开main.ipynb的,不要推理视频!!! 不仅不显示推理的图像,还会导致内存占用不断升高,且无法终止内核,甚至杀不死进程,最后爆内存断开ssh连接。最终我只能按下复位。
三、问题
1、No module named ‘scikit’
pip install scikit-video
别搞错名字就行。
2、No module named ‘ais_bench’
访问Gitee仓库,这里有三种方法,作为懒人肯定是选择whl包安装啦。
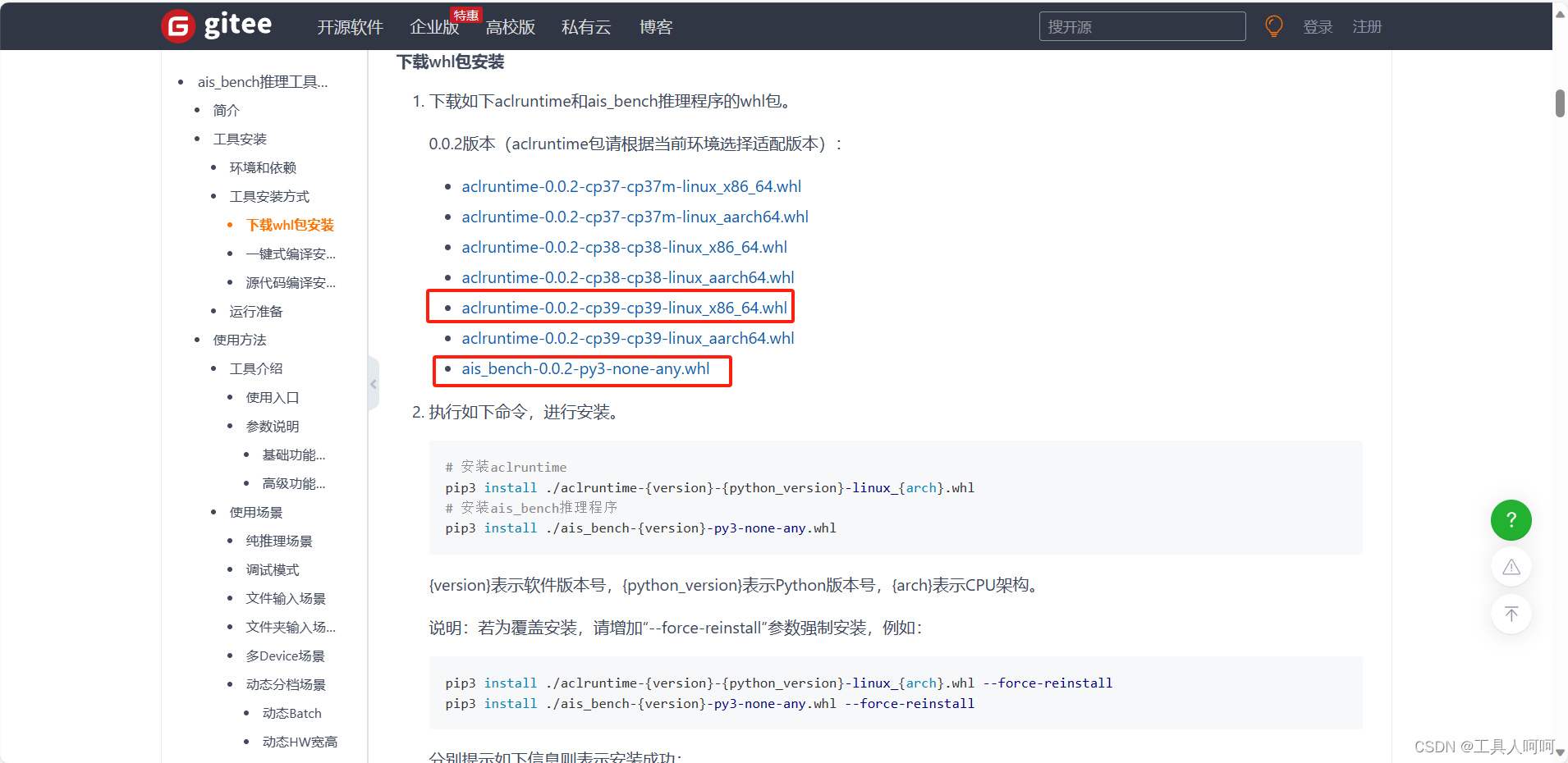
我的pc机python是3.9,所以下载这两个,按照下方说明进行安装就行。
咱就粗暴一点,强制覆盖安装啦。
pip3 install ./aclruntime-{version}-{python_version}-linux_{arch}.whl --force-reinstall
pip3 install ./ais_bench-{version}-py3-none-any.whl --force-reinstall
安装成功会提示
# 成功安装aclruntime
Successfully installed aclruntime-{version}
# 成功安装ais_bench推理程序
Successfully installed ais_bench-{version}
安装失败的话检查版本然后祭出重启大法。
3、 InputTensor Data Type mismatches.

这里是折磨了我三天的问题,甚至进行了一下几个可能的排列组合(请不要笑)
1、怀疑导出onnx模型问题
我对比了两个onnx模型结构
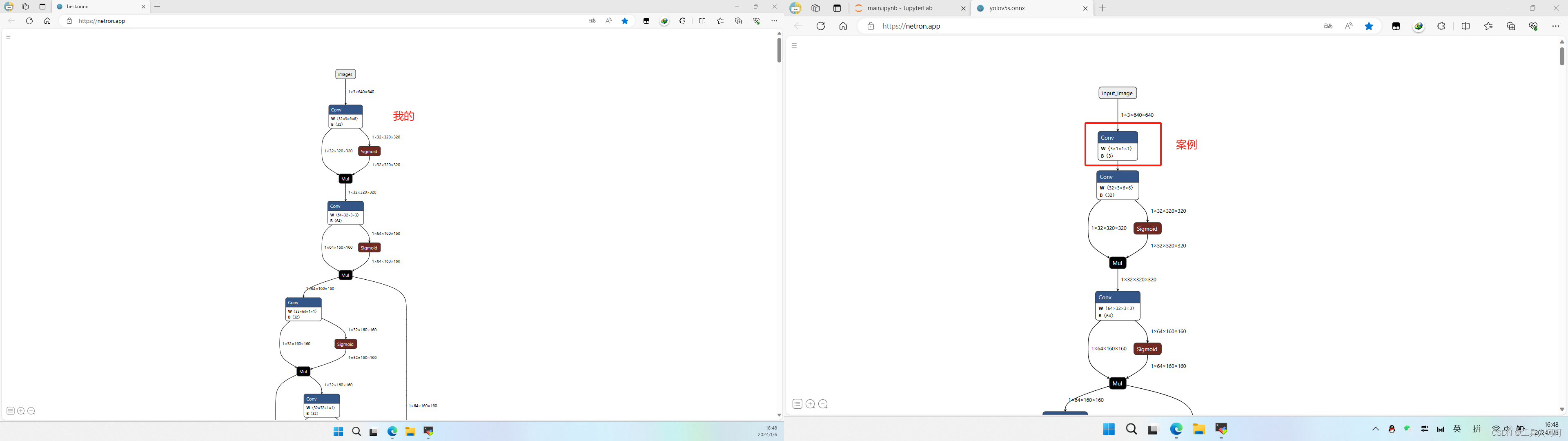
发现只有这里不一样,但是不应该会导致这个问题啊
2、怀疑版本问题
这里怀疑的是转换时的版本问题。因此进行了一波友好的控制变量法测试(手动狗头)。键盘差点不保!
- pc机cann7.0
- 200dkcann5.1
- best.onnx我自己的模型
- yolov5s.onnx 200i案例的模型
- yolo.om 200i案例的模型
- best.om我pc机转的模型
- mymodel.om 200dk转的模型
最终,耗时一下午,还是失败了。
3、om模型有问题!!!
最后,只能怀疑是om模型有问题,于是我使用atc指令查询其信息,果然发现了问题所在。关于用法请参考文档。
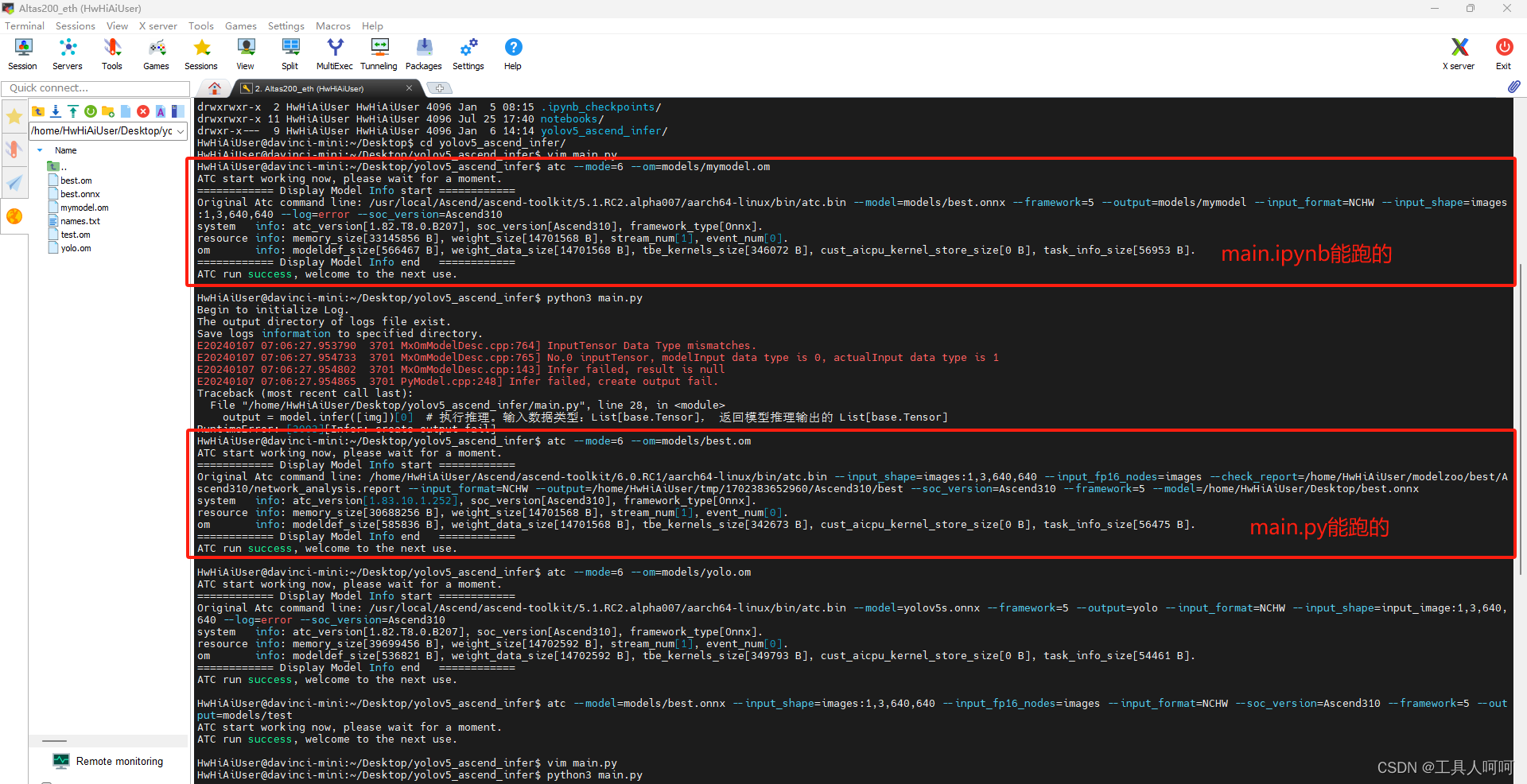
对比两个模型,在Atc command line中best.om多了--input_fp16_nodes=images。我回去一查,嘿,mindx似乎只能用fp16做输入,而我之后转换的模型都是fp32的,怪不得main.py报错。但是,这时ais_bench推理的main.ipynb又报错了,我们只需要把这个32改成16.
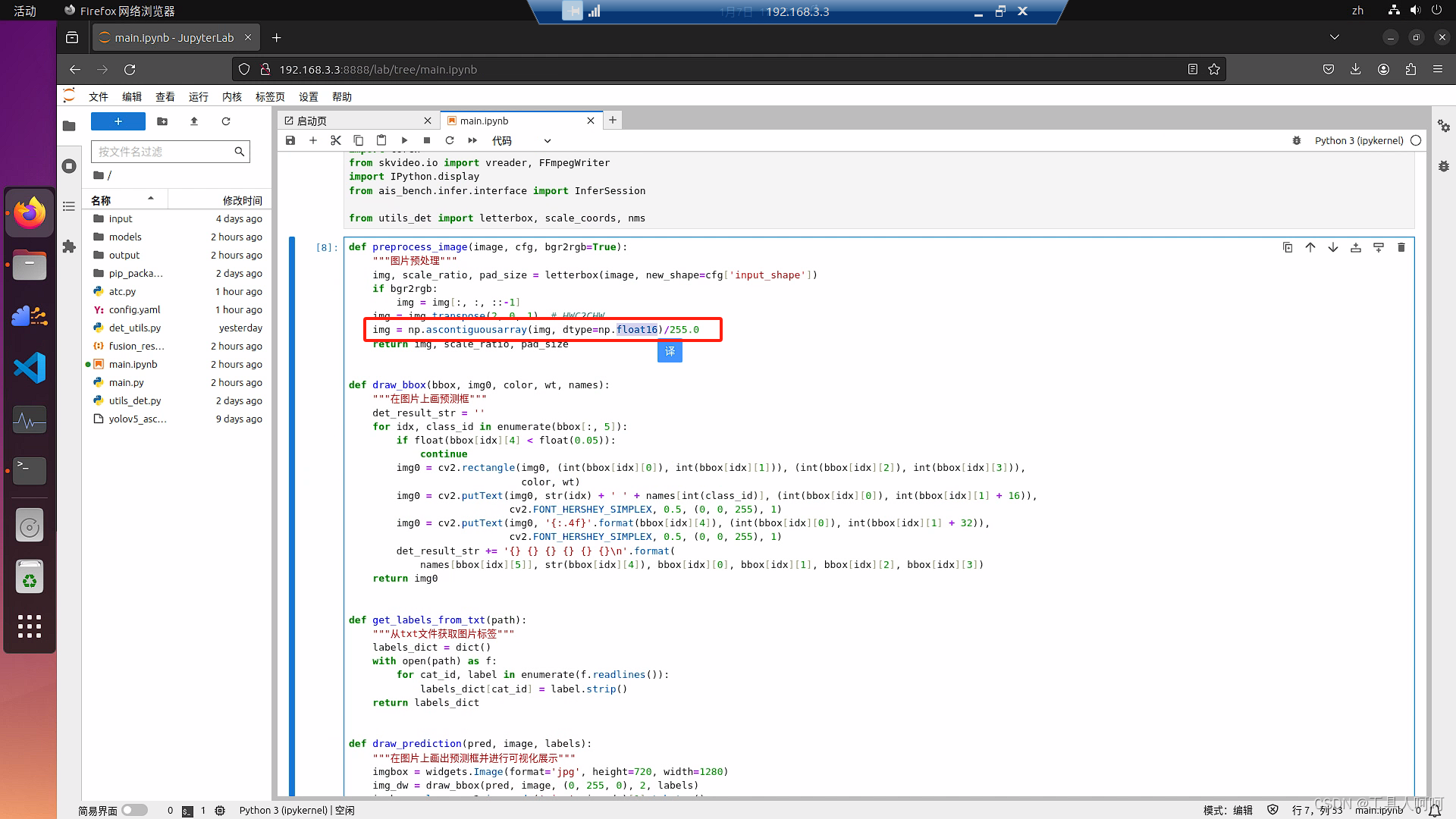
4、预测框错乱
这里在经过我刨地三尺,翻了三遍论坛,终于找到了罪魁祸首。详情请参考原文链接。
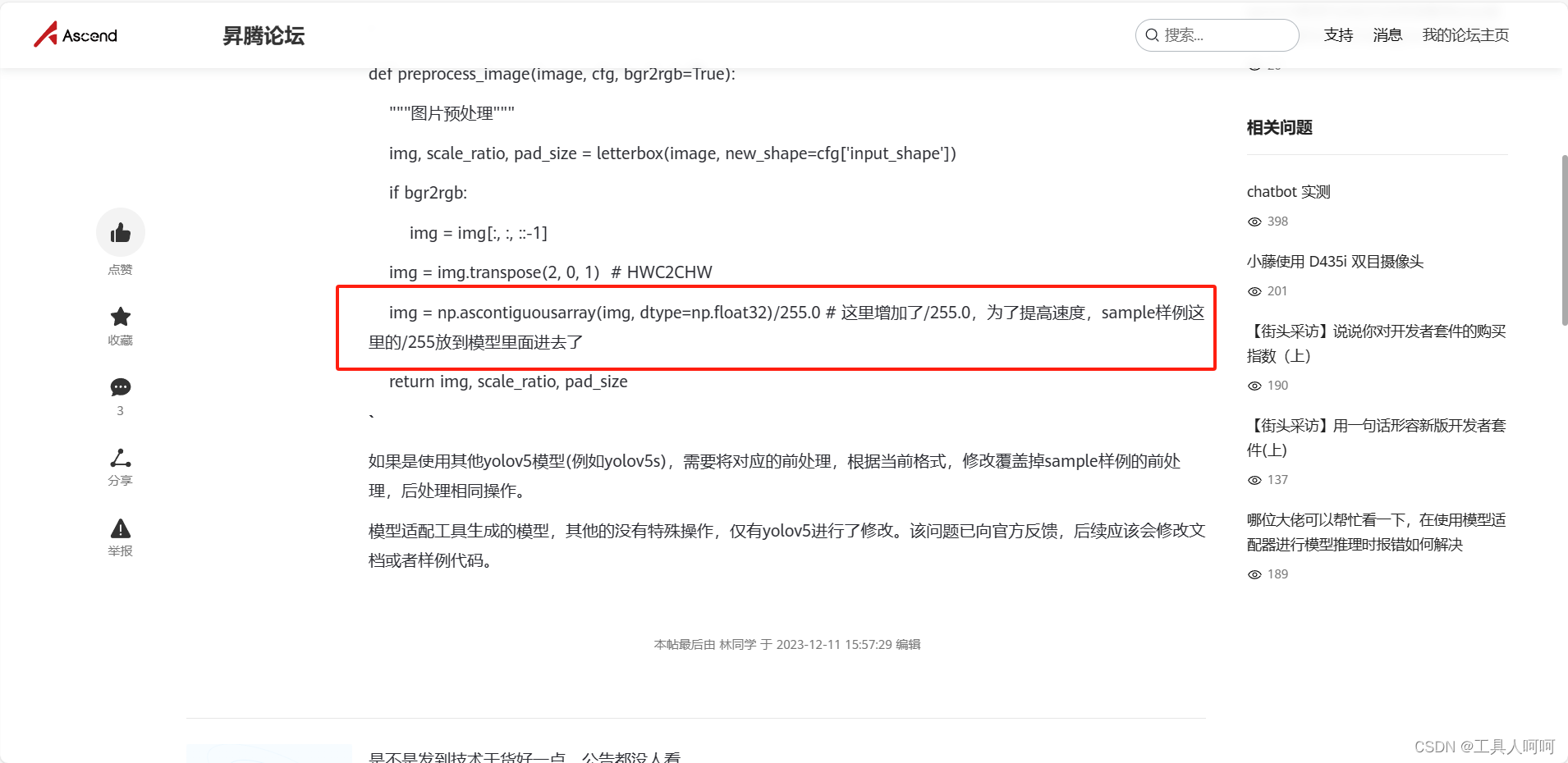
我们只需要在这个案例这一行后面添加/255.0即可。
总结
不要问我为什么放鸽子,当你被bug折磨,别说解决方案了,甚至这个报错百度都搜不到,那是心态直接爆炸啊。
强烈建议直接使用我置顶提供的案例文件,避免踩坑,从我做起!!!
我是替你们踩坑的工具人呵呵,下期继续,希望能尽快爬出来吧。

![[C#]Onnxruntime部署Chinese CLIP实现以文搜图以文找图功能](https://img-blog.csdnimg.cn/direct/6cfab5ee5cb544d7b536b28bad953ba0.jpeg)