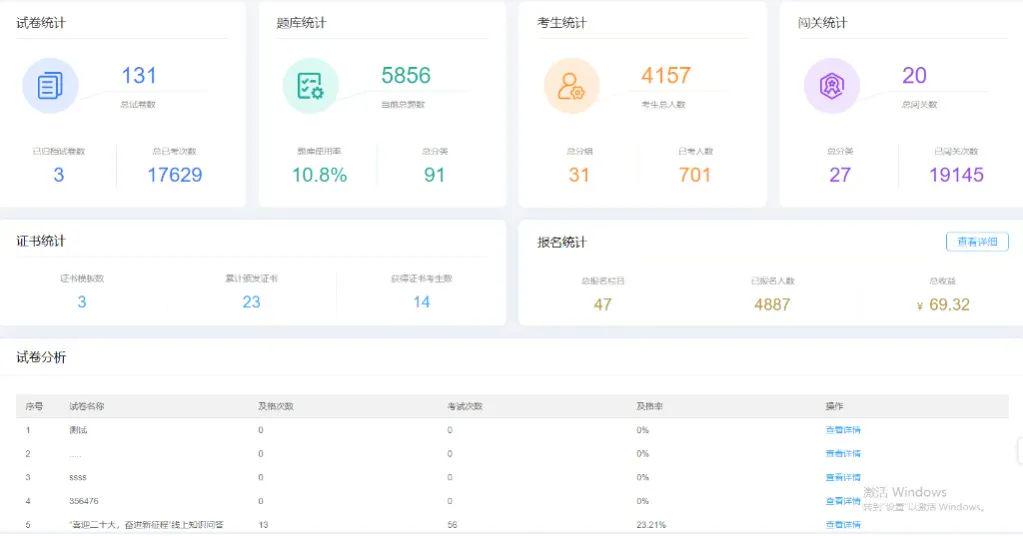
序:
为什么打算写Netty 相关的博客呢? Netty如今已经是应用非常广泛了, 很多框架底层都能看到他的影子,如Dubbo , Spring Gateway , RocketMQ、Elasticsearch、HBase 等比较出名的框架,在性能,稳定性方面,Netty 也做得足够的优秀,很多的好处这里也不再赘述,因此作为一个Java开发者,程序爱好者,如果不研究Netty,不研究其源码, 作为一个开发人员如朝菌不知晦朔,蟪蛄不知春秋 一样,即使在工作中开发项目开发得再好,也只不过会用而言,谈不上有自己的见解,因此我打算深入源码,周边同事很少有人愿意去研究源码,这也只能让我一个人在技术研究的道路上踽踽独行,虽然有点孤独, 但前辈们留下来的书籍照亮我前行的道路,其中 《netty-redis-zookeeper高并发实战》 和 《Netty源码剖析与应用》 这两本书,从中受溢非浅, 有兴趣的小伙伴建议去看看。 当然这里也讲到了一种源码的方法 ,不要一上来拿着一个例子就去阅读源码,这样做你很可能就会从入门到放弃 ,可以先花一段时间了解源码框架的使用,再找一两本书,去看看书上对框架的描述,使用,特殊类的解释, 如果你从来没有研究过, 可能你看到的所有的东西都是陌生的,但不要着急,先混个脸熟, 一回生,二回熟,多看几遍,其意自见, 再看看框架的使用,对各种使用方式了解之后,就可以尝试看源码,当然看不懂,先放一边。 当看到书本上看到的类或方法时,再次来看书本,经过一段时间的研究,相信你会越来越自信,最后从入门到精通 。
第二章
2.1 IO读写的基本原理
大家都知道,用户程序的进行IO 的读写,依赖于底层的IO读写, 基本上会用上底层的read&write两大系统调用,在不同的操作系统中, IO 读写的系统调用名称可能不完全一样, 但是基本功能是一样的。
这里涉及一个基础知识,read系统调用,并不是直接从物理设备上把数据读取到内存中, write系统调用,也不是直接把数据写入到物理设备中, 上层应用无论是调用操作系统的read还是调用操作系统的write,都会涉及到缓冲区, 具体来说, 调用操作系统的read ,是把数据从内核缓冲区复制到进程缓冲区,而write系统调用,是把数据从进程缓冲区复制到内核缓冲区。
也就是说, 上层程序的IO 操作,实际上不是物理设备级别的读写,而是缓存的复制,read&write两大系统调用,都不负责数据在内核缓冲区和物理设备(如磁盘)之间的交换,这项底层的读写交换是由操作系统内核(Kernel) 来完成的,注:本书后面如果没有特别说明,内核即操作系统内核 。
在用户程序中,无论是Socket 的IO ,还是文件IO操作,都属于上层应用的开发,它们输入(Input)和输出(Output) 的处理, 在编程的流程上, 都是一致的。
2.1.1 内核缓冲区与进程缓冲区
为什么设置那么多的缓冲区,为什么要那么麻烦呢?缓冲区的目的是,为了减少频繁地与设备之间的物理交换,大家都知道,外部设备的直接读写, 涉及操作系统的中断,发生系统中断时,需要保存之前的进程数据和状态等信息,而结束中断之后,还需要恢复之前的进程数据和状态等信息,为了减少这种底层系统的时间损耗,性能损耗,于是出现了内存缓冲区。
有人内存缓冲区,上层应用使用了read系统调用时, 仅仅把数据从内核缓冲区复制到上层应用的缓冲区(进程缓冲区) ,上层应用使用write系统调用时,仅仅把数据从进程缓冲区复制到内核缓冲区,底层操作会对内核缓冲区进行监控,等待缓冲区达到一定数据的时候,再进行IO设备的中断处理,集中执行物理设备的实际IO 操作,这种机制提升了系统的性能,至于什么时候中断,读中断,写中断,由操作系统内核来房室,用户程序则不关心。
从数量上来说,在Linux 系统中,操作系统内核只有一个内核缓冲区,而每个用户程序进程,有自己独立的缓冲区,叫作进程缓冲区,所以,用户程序的IO 读写程序,在大多数情况下, 并没有进行实际的IO操作,而是在进程缓冲区和内核缓冲区之间直接进行数据的交换 。
2.1.2 详解典型的系统调用流程
前面讲到,用户程序所使用的系统调用read&write,它们不等价于数据在内核缓冲区和磁盘之间的交换,read把数据从内核缓冲区复制到进程缓冲区,write把数据从进程缓冲区复制到内核缓冲区,具体流程如下:如下图所示 。
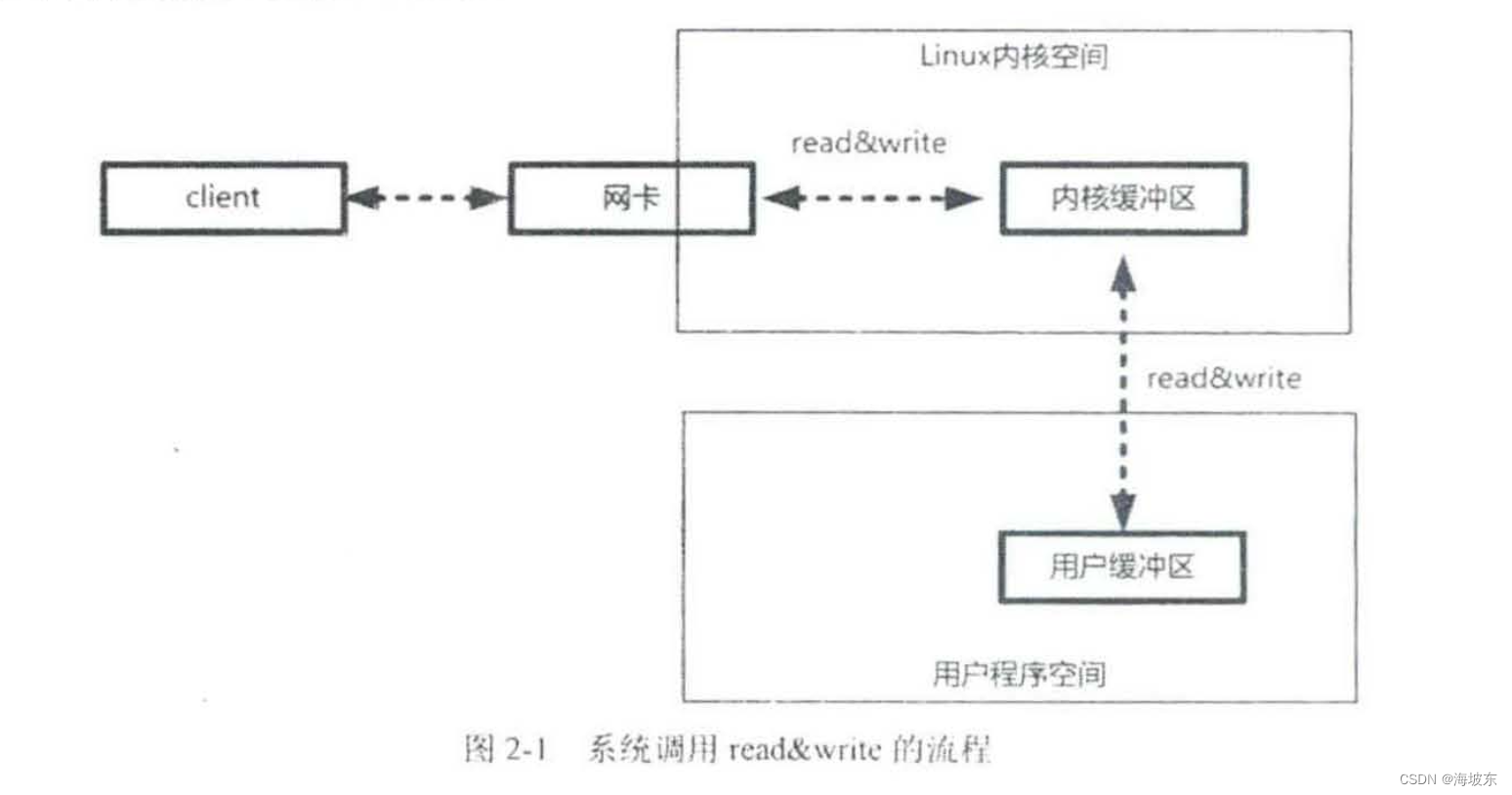
这里以read系统调用为例,先看一下一个完整的输入流程的两个阶段:
- 等待数据准备好
- 从内核向进程复制数据
如果是read一个socket(套接字),那么以上两个阶段的具体处理流程如下:
- 第一阶段,等待数据从网络中到达网上,当所等待的分组到达时, 它被复制到内核中的某个缓冲区,这个工作由操作系统完成,用户程序无法感知。
- 第二阶段,就是把数据从内核缓冲区复制到应用进程缓冲区。
再具体一点,如果是在Java服务器端,完成一次socket的请求和响应,完整的流程如下:
- 客户端请求: Linux 通过网卡读取客户端请求数据,将数据读取到内核缓冲区。
- 获取请求数据: Java 服务器通过read 系统调用,从Linux 内核缓冲区读取数据,再送入到Java 进程缓冲区。
- 服务器端业务处理: Java 服务器在自己的用户空间处理客户端请求。
- 服务器端返回数据: Java 服务器完成处理后,构建好响应数据,将数据从用户缓冲区写入到内核缓冲区,这里用到了write系统调用 。
- 发送给客户端:Linux 内核通过网络IO, 将内核缓冲区的数据写入到网卡, 网卡通过底层的通信协议,会将数据发送给目标客户端 。
2.2 四种主要的IO模型
同步阻塞IO(Blocking IO)
首先,解释一下这里的阻塞与非阻塞:
阻塞IO,指的是需要内核IO操作彻底完成后,才返回到用户空间执行用户的操作,阻塞指的是用户空间程序的执行状态,传统的IO 模型是同步阻塞IO,在Java中,默认的创建的socket都是阻塞的。
再来看一下同步也异步
同步IO ,是一种用户空间与内核空间的IO发起方式,同步IO是指用户空间的线程是主动发起的IO请求一方, 内核空间是被动接受方, 异步IO 则反过来,是指系统内核是主动发起的IO请求的一方,用户空间是线程是被动接受方。
同步非阻塞IO(Non-blocking IO)
非阻塞IO , 指的是用户空间的程序不需要等待内核IO操作彻底完成,可以立即返回用户空间执行用户操作,即处于非阻塞状态,与此同时内核会立即返回给用户一个状态值 。
简单来说, 阻塞是指用户空间(调用线程) 一直等待,而不能做其他事情,非阻塞是指用户空间(调用线程)拿到内核返回状态值就返回自己的空间,IO 操作可以做就做,也可以不做就不做 。
非阻塞IO 要求 socket被设置为NONBLOCK。
强调一下,这里所说的NIO 同步非阻塞IO 模型,并非Java 的NIO(New IO)库。
3.IO 多路复用(IO Multiplexing)
即经典的Reactor反应器设计模式,有时也称为异步阻塞IO,Java中的Selector 选择器和Linux中的epoll 都是这种类型。
- 异步IO(Asynchronous IO)
异步IO,指的是用户空间与内核空间调用方式反过来,用户空间的线程变成了被动接受者,而内核空间成了主动调用者, 这有点类似于Java中比较典型的回调模式,用户空间的线程向内核空间注册了各种IO 事件的回调函数,由内核主动去调用 。
2.2.1 同步阻塞IO(Blocking IO)
在Java 应用程序进程中,默认的情况下,所有的socket 连接都是IO 操作都是同步阻塞IO(Blocking IO) , 在阻塞式IO 模型中,Java应用程序从IO系统调用开始,直到系统调用返回,在这段时间内,Java 进程是阻塞的,返回成功后,应用进程开始处理用户空间的缓存区数据 。
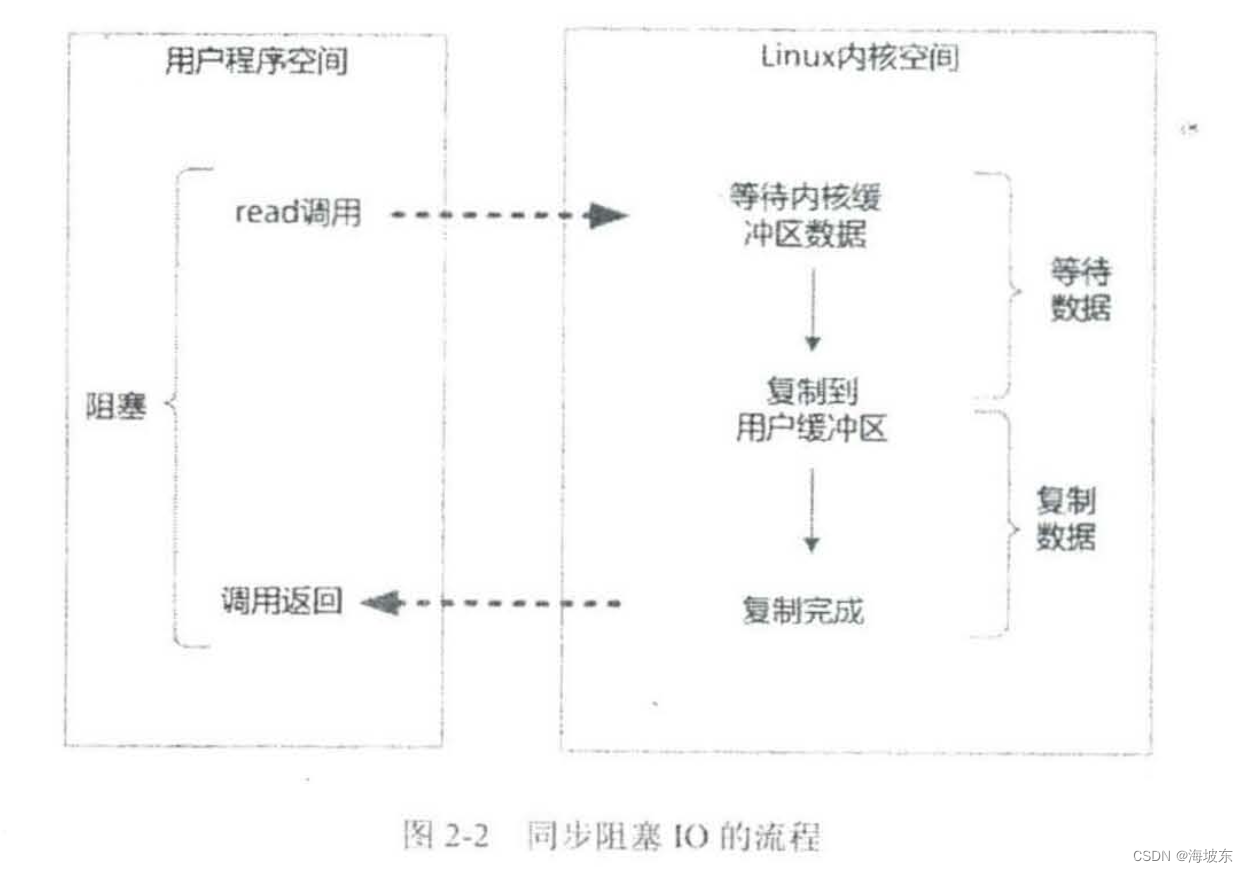
举个例子,在Java 中发起一个socket的read读操作的系统调用,流程大致如下:
- 从Java启动IO读的read系统调用开始,用户线程就进入阻塞状态 。
- 当系统内核收到read系统调用,就开始准备数据,一开始,数据可能还没有达到内核缓冲区(例如,还没有收到一个完整的socket数据包)这个时候内核就要等待。
- 内核一直等到完整的数据到达,就会将数据从内核缓冲区复制到用户缓冲区(用户空间的内存),然后内核返回结果(例如返回复制用的用户缓冲区中的字节数)
- 直接内核返回后,用户线程才会解除阻塞的状态,重新运行起来 。
总之,阻塞IO 的特点是,在内核进行IO 执行的两个阶段,用户线程都被阻塞了。
阻塞IO的优点是,应用程序开发非常简单,在阻塞等待数据期间,用户线程挂起,在阻塞期间,用户线程基本不会占用CPU 资源 。
阻塞IO 的缺点是:一般情况下,会为每个连接配备一个独立的线程, 反过来说,就是一个线程维护一个连接的IO操作,在并发量小的情况下,这样做没有什么问题, 但是在高普世物应用场景下,需要大量的的线程来维护大量的网络连接,内存,线程切换开销会非常巨大,因此,基本上阻塞IO 模型在高并发的场景下是不可用的。
2.2.2 同步非阻塞NIO(None Blocking IO)
socket连接默认是阻塞模式,在Linux 系统下, 可以通过设置将socket变为非阻塞模式(Non-Blocking)使用非阻塞模式的IO读写, 叫做同步非阻塞IO(None Blocking IO) ,简称为NIO 模式, 在NIO 模型中,应用程序一旦开始IO系统调用,会出现以下两种情况 。
- 在内核缓冲区中没有数据的情况下,系统调用会立即返回,返回一个调用失败的信息。
- 在内核缓冲区中有数据的情况下, 是阻塞的, 直到数据从内核缓冲复制到用户进程缓冲,复制完成后,系统调用返回成功, 应用程序开始处理用户空间缓冲数据 。
同步阻塞IO的流程,如图2-3所示 。
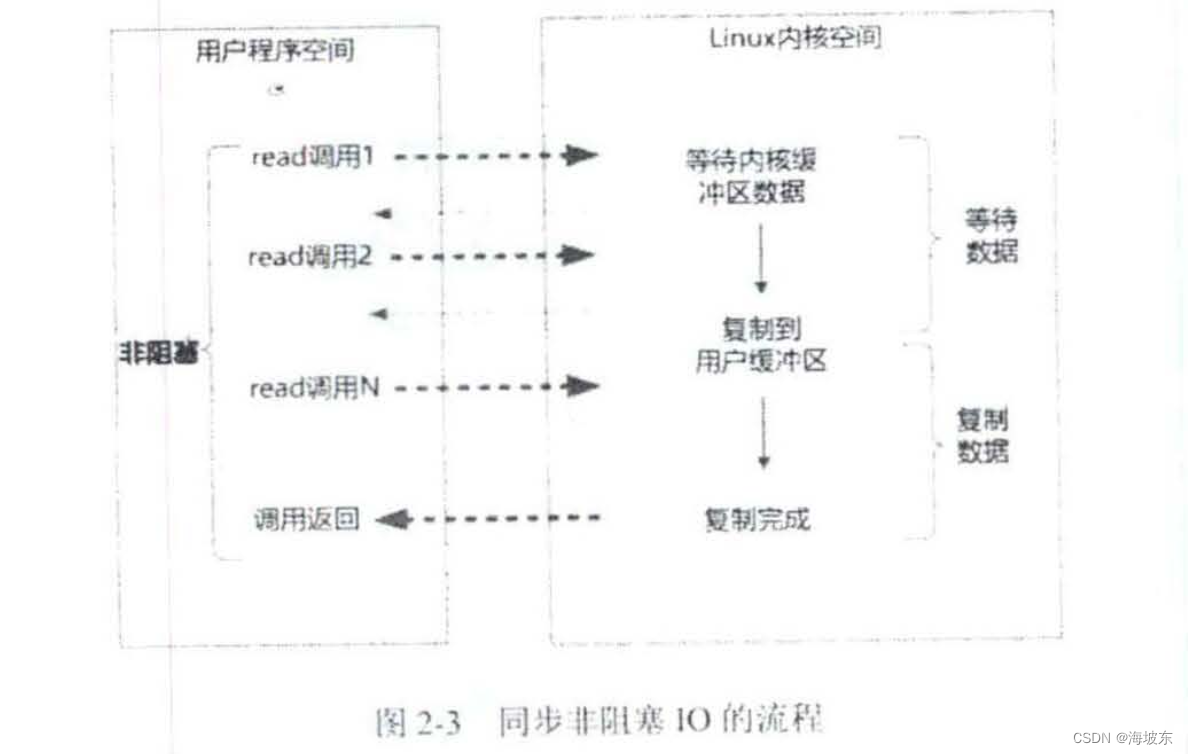
举个例子,发起一个非阻塞socket的read操作系统调用,流程如下 。
- 在内核数据没有准备好的阶段,用户线程发起IO 请求时, 立即返回,所以为了读取到最终的数据,用户线程需要不断的发起IO 系统调用 。
- 内核数据到达后,用户线程发起了系统调用,用户线程阻塞,内核开始复制数据,它会将数据从内核缓冲区复制到用户缓冲区,(用户空间的内存) 然后内核返回结果例如返回复制到用户缓冲区的字节数。
- 用户线程读到数据后,才会解除阻塞状态,重新运行起来,也就是说,用户进程需要经过多次尝试,才能保证最终真正的数据,而后继续执行。
同步非阻塞IO的特点,应用程序的线程需要不断的进行IO系统调用,轮询数据是否已经准备好,如果没有准备好,就继续轮询,直到完成IO 系统调用为止。
同步非阻塞的优点,每次发起IO 系统调用,在内核等待数据过程中可以立即返回,用户线程不会阻塞,实时性好。
同步非阻塞的IO的缺点,不断的轮询内核,将占用大量的CPU时间,效率低下。
总体来说,在高并发应用场景下, 同步非阻塞IO也是不可用的,一般Web 服务器不使用这种IO 模型,这种IO 模型一般很少直接使用,而是在其他的IO 模型中使用非阻塞IO这一特点,在Java 的实际开发中,也不会涉及这种IO 模型 。
这里说明一下,同步非阻塞IO,可以简称为NIO,但是,它不是Java 中的NIO, 虽然它们英文缩写一样, 希望大家不要混淆,Java 的NIO (New IO) ,对应的不是四种基本的IO模型中的NIO(None Blocking IO)模型,而是另外一种模型,叫做IO 多路复用模型 (IO Multiplexing) 。
2.2.3 IO 多路复用模型 (IO Multiplexing)
如何避免同步非阻塞IO 模型中轮询等待的问题呢?这就是IO多路复用模型 。
在IO 多路复用模型中, 引入了一种新的系统调用,查询IO 的就绪状态,在Linux系统中,对应的系统调用为select/epoll系统调用,通过该系统调用,一个进程可以监控多个文件描述符,一旦某个描述符就绪(一般是内核缓冲区可读/可写),内核能够将就绪状态返回给应用程序,随后,应用程序根据就绪的状态,进行相应的IO 系统调用 。
目前支持IO 多路利用的系统调用,有select,epoll等等,几乎所有的操作系统都支持,具有良好的跨平台性,epoll是在Linux 2.6 内核中提出的, 是select系统调用的linux增强版本。
在IO多路利用模型中通过select/epoll系统调用,单个应用程序的线程,可以不断的软座成千上万的socket连接,当某个或者某些socket网络连接有了IO就绪的状态,就返回对应的可执行读写操作。
举个例子来说IO多路利用模型的流程,发起一个多路利用IO的read读操作是系统调用流程如下:
- 选择器注册,在这种模式下,首先,将需要read操作的目标socket网络连接,提前注册到select/epoll 选择器中, Java 中对应的选择器是Selector 类,然后才可以开启整个IO 多路利用模型的轮询流程。
- 就绪状态的轮询,通过选择器查询方法,查询注册过的所有socket连接的就绪状态,通过查询的系统调用,内核会返回一个就绪socket 列表,当任何一个注册过的socket中的数据准备好了,内核缓冲区有数据就绪了,内核就将该socket加入到就绪的列表 中。 当用户进程调用了select查询方法,那么整个线程会被阻塞掉。
- 用户线程获得了就绪状态的列表后,根据其中的socket连接,发起read系统调用,用户线程阻塞,内核开始复制数据,将数据从内核缓冲区复制到用户缓冲区。
- 复制完成后,内核返回结果,用户线程才会解除阻塞状态,用户线程读取到的数据继续执行。
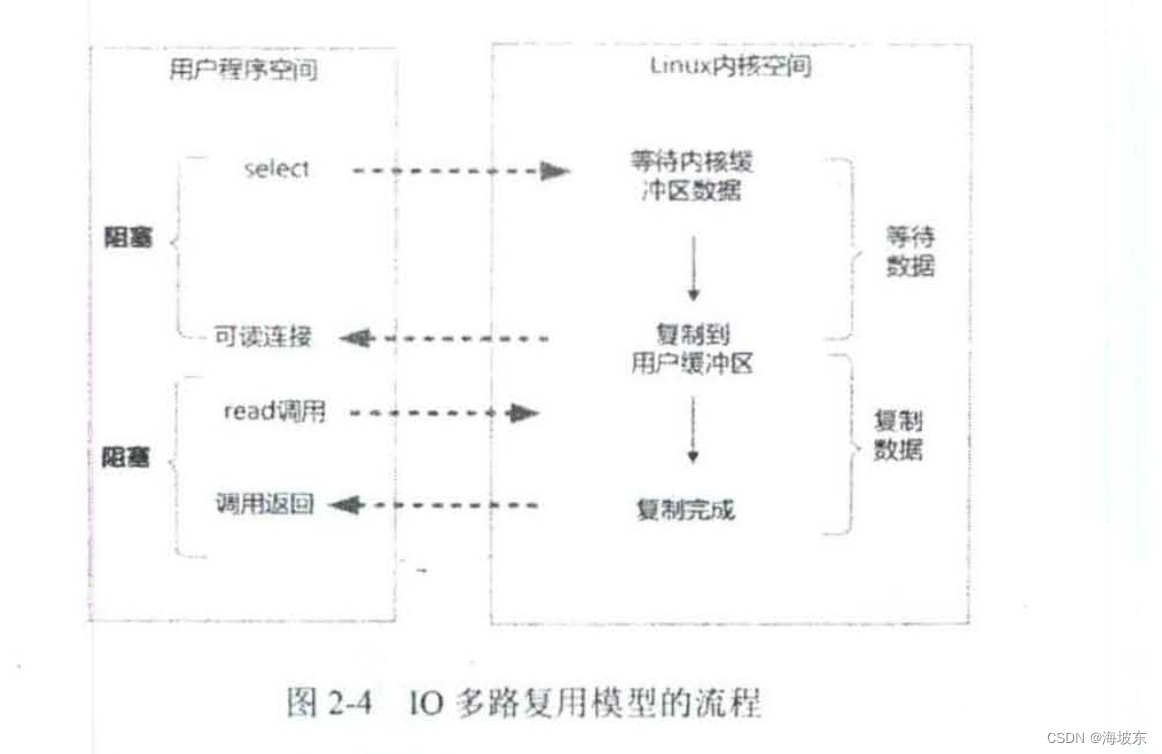
IO 多路复用模型的特点,IO 多路复用模型的IO 涉及两种系统调用(System Call) ,另外一种是select/epoll(就绪查询),一种是IO 操作,IO 多路复用模型建立在操作系统基础设施之上,即操作系统的内核必须能够提供多路分享的系统调用select/ epoll 。
和NIO 模型相似,多路复用IO 也需要轮询,负责select/epoll状态查询调用线程,需要不断的进行select/epoll轮询,查找出达到IO 操作就绪的socket连接 。
IO 多路复用模型的优点: 与一个线程维护一个连接的阻塞IO模型相比,使用select/epoll的最大优势在于,一个选择器的查询可以同时处理成千上万个连接Connection , 系统不必创建大量的线程,也不必维护这些线程, 从而大大的减少了系统的开销。
Java语言的NIO New IO技术,使用的就是IO 多路复用模型,在Linux 系统上,使用的就是epoll系统调用 。
IO 多路复用模型的缺点:本质上,select/epoll 系统调用是阻塞式的,属于同步IO ,都需要在读写事件就绪后,由系统调用本身负责进行读写, 也就是说这个读写过程是阻塞的。
如何做到彻底解除线程阻塞呢?就必须使用异步IO模型 。
2.2.4 异步IO模型 (Asynchronozus IO )
异步IO模型(Asynchronous IO ,简称为AIO ),AIO 的基本流程是,用户线程通过系统调用,向内核注册某个IO操作, 内核在整个IO 操作(包括数据准备,数据复制)完成后,通知用户程序,用户执行后续业务操作。
异步 IO 模型中, 在整个内核的数据处理过程中, 包括内核将数据从网络物理设备(网卡) 读取到内核缓冲区,将内核缓冲区的数据复制到用户缓冲区,用户程序都不需要阻塞 。
异步 IO 模型的流程,如图2-5所示 。
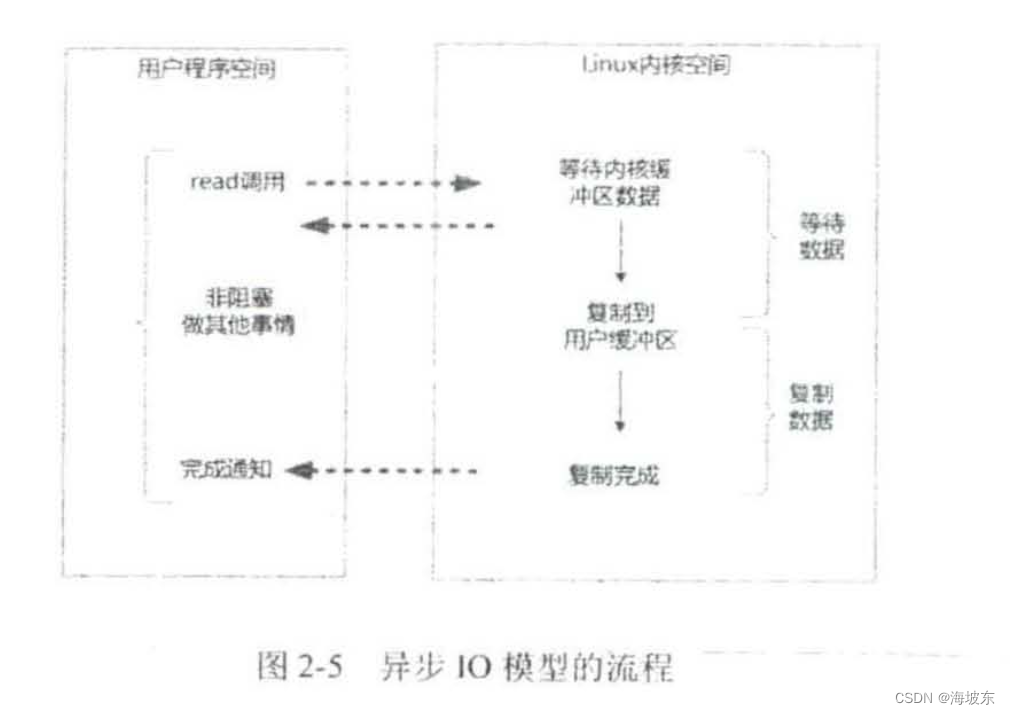
举个例子,发起一个异步IO 的read 读操作是系统调用,流程如下:
- 当用户线程发起了read系统调用,立刻就开始去做其他事情,用户线程不阻塞 。
- 内核就开始了IO的第一阶段,准备数据,等数据准备好了,内核就会将数据从内核缓冲区复制到用户缓冲区(用户空间的内存)。
- 内核会给用户发送一个信息(Signal),或者回调用户线程注册的回调接口,告诉用户线程read操作已经完成了。
- 用户线程读取用户缓冲区的数据,完成后续的业务操作。
异步IO模型的特点,在内核等待数据复制数据两个阶段,用户线程都不是阻塞的, 用户线程需要接收到内核的IO 操作完成的事件,或者用户线程需要注册一个IO操作完成回调函数,正因如此,异步IO 有的时候也被称为信号驱动IO .
异步IO 模型的缺点,应用程序仅需要进行事件的注册与接收,其余的工作都留给了操作系统,也就是说,需要底层内核提供支持。
就目前而言,window 系统下通过IOCP实现真正的异步IO, 而linux 系统下,异步 IO 模型有2.6版本才引入,目前不完善,其底层实现仍然使用epoll,而IO 多路复用相同,因此在性能上没有明显的优势 。
大多数高并发的服务器端的程序,一般都是基于Linux 系统的, 因而,目前这类高并发网络应用程序开发,大多数采用的是IO 多路复用模型 。
Netty 框架,使用的就是IO 多路复用模型,而不是异步IO 模型 。
Java NIO 通信基础详解
Java NIO 简介
在1.4 版本之前,Java IO 类库是阻塞IO,从1.4版本开始,引进了新的异步IO库,被称为Java New IO类库,简称为Java NIO ,New IO 类库的目标,就是要让Java 支持非阻塞IO ,基于这个原因,更多的人喜欢称Java NIO为非阻塞IO(Non Block IO) ,称为老的 阻塞式 Java IO 为 OIO , 总体来说,NIO 弥补了原来面向流的OIO 同步阻塞的不足,它的标准Java 代码提供了调整,面向缓冲区IO 。
Java NIO 由以下三个核心组件组成 。
- Channel 通道
- Buffer缓冲区
- Selector 选择器
Java NIO 和OIO 的简单对比 。
3.1.1 NIO 和OIO 的对比
在Java 中,NIO 和OIO 的区别,主要体现在三个方面 。
- OIO 是面向流(Stream Oriented)的,NIO是面向缓冲区(Buffer Oriented)的。
- 何谓面向流,何谓面向缓冲区呢?
OIO 是面向字节流或字符流的, 在一般的OIO操作中, 我们以流式方式顺序地从一个流(Stream) 中读取一个或多个字节,因此,我们不能随意的改变读取指针的位置,而是NIO操作中则不同,NIO 中引入Channel(通道)和Buffer 缓冲区的概念,读取和写入,只要从通道中读取数据到缓冲区中, 或将数据从缓冲区中写入通道,NIO 不像OIO 那样是顺序操作的。可以随意的读取Buffer中任意位置的数据 。
- OIO 的操作是阻塞的,而NIO 的操作是非阻塞的。
NIO 如何做到非阻塞的呢?大家都知道,OIO 操作是阻塞的,例如,我们调用一个read方法读取一个文件内容时,那么调用read线程会被阻塞住,直到read操作完成 。
而是在NIO的非阻塞模式中, 当我们调用read方法时,如果此时有数据,则read读取数据并返回,如果此时没有数据,则read直接返回,而不会阻塞当前的线程,NIO 的非阻塞,是如何做到的呢?其实之前也说过, NIO 使用了通道和通道的多路复用技术 。
- OIO 没有选择器(Selector)概念,而NIO 有选择器的概念。
NIO 的实现,是基于底层选择器的系统调用,NIO的选择器, 需要底层操作系统提供支持。 而OIO 不需要复用选择器。
3.1.2 通道(Channel)
在OIO 中,同一个网络连接会关联到两个流,一个输入流(InputStream ),另外一个输出流(Output Stream) ,通过这两个流,不断的进行输入和输出的操作。
NIO中,同一个网络连接使用了一个通道表示,所有的NIO 的IO操作都是从通道开始的, 一个通道类似于OIO 中两个流的结合体,既可以从通道中读取,也可以从通道中写入。
3.1.3 Selector选择器
首先,回顾一下基础的问题, 什么时IO多路复用?指的是一个进程/线程同时可以监视多个文件描述符(一个网络连接,操作系统底层使用一个文件描述符来表示),一旦其中的一个或者多个文件描述符可读或可写, 系统内核就通知该进程或线程,在Java 应用层面,如何实现对多个文件描述符的监视呢? 需要用到一个非常重要的Java NIO组件-Selector 选择器。
选择器的神奇功能是什么呢? 它一个IO事件查找器,通过选择器,一个线程可以查询多个IO事件的就绪状态 。
实现IO多路复用,从具体的开发层面上来说,首先通道注册到选择器上,然后通过选择器内部机制,可以查询(select)这些注册的通道是否已经就绪的IO事件 (例如可读,可写,网络 连接完成)。
一个选择器需要一个线程进行监控,换句话说,我们可以很简单的使用一个线程,通过选择器去管理多个通道,这是非常高效的,这种高效来自于Java 选择器组件Selector ,以及其背后的操作系统底层的IO多路复用的支持。
与OIO 相比,使用选择器的最大优势,系统开销小, 系统不必为每一个网络连接(文件描述符)创建进程/线程,从而大大的减少了系统开销。
3.1.4 缓冲区(Buffer)
应用程序与通道(Channel) 的主要交互操作, 就是进行数据的read 读取和write写入, 为了完成如此大任, NIO为大家准备了第三个重要的组件–NIO Buffeer(NIO缓冲区) , 通道读取,就是将数据从通道读取到缓冲区中, 通道的写入,就是将数据从缓冲区中写入到通道中。
缓冲区的使用, 是面向流的OIO所没有的,也就是NIO 非阻塞的重要前提和基础 。
下面从缓冲区开始,详细的介绍NIO的Buffer(缓冲区), Channel(通道), Selector(选择器)三大核心组件 。
3.2 详解NIO Buffer 类及其属性。
NIO 的Buffer 缓冲区本质上是一个内存块, 即可以写入数据, 也可以从中读取数据,NIO的Buffer类,是一个抽象类, 位于 java.nio 包中, 其中内部是一个内存块(数组) 。
NIO 的Buffer 与普通的内存块,如果要有内存块 (Java 数组) 不同的是, NIO Buffer 对象 , 提供了一组更加有效的方法,用来进行写入和读取交替访问 。
需要强调的是, Buffer 类是一个非线程安全类。
3.2.1 Buffer类
Buffer类是一个抽象类, 对于 Java 的主要数据类型,在NIO 的8种缓冲区类中,分别如下 , ByteBuffer , CharBuffer , DoubleBuffer , FloatBuffer , LongBuffer , ShortBuffer , MappedByteBuffer 。
前7种Buffer 类型,覆盖了能在IO 中传输的所有的Java 基本数据类型,第8种类型MappedByteBuffer 是专门用于映射一种ByteBuffer类型。
实际上, 使用最多的还是ByteBuffer二进制字节缓冲区类型。
3.2.2 Buffer类的重要属性
Buffer 类在其内部,有一个byte []数组内存块, 作为内存缓冲区,为了记录读写状态和位置,Buffer 类提供了一些重要的属性, 其中 ,有三个重要的成员属性,capacity(容量 ) ,position(读写位置 ), limit(读写限制 )。
除此之外,还有一个标记属性, mark(标记),可以将当前的position临时存入到mark中,需要的时候,可以再从mark标记恢复到position位置 。
- capacity属性
Buffer类的capacity属性,表示内部容量的大小, 一旦写入到对象的数量超过capacity容量,缓冲区就满了, 不能再写入了 。
Buffer类的capacity属性一旦初始化,就不能再改变, 原因是什么呢? Buffer 类的对象在初始化时, 会按照capacity分配的内存,在内存分配好之后,它的大小当前就不能改变了。
再强调一下, capacity容量不是指内存块byte[] 数组的字节的数量 capacity容量指指的是写入的数据对象的数量 。
前面讲到,Buffer 类是一个抽象类,Java 不能直接用来新建对象,使用的时候 , 必须使用Buffer 的某个子类,例如使用DoubleBuffer ,则写入的数量是double类型, 如果capacity是100,那么我们最多可写入100个double数据 。
- position属性
Buffer 类的position属性, 表示当前的位置 , position属性与缓冲区的读写模式有关, 在不同的模式下, position属性值是不同的, 当缓冲区进行读写模式改变时, position 会进行调整。
在写模式下,position 的值的变化规则如下,1 在刚刚进入写模式时, position的值为0 , 表示当前的写入位置从头开始,2,当一个数据写入到缓冲区之后,position会向后移动到一一个可写的位置 , 3. 初始化的position 值为0 , 最大可写值position 为limit -1 ,当position值达到了limit时, 缓冲区就已经无空间可写了。
在读模式下,position的值的变化规则如下 , 1 当缓冲区刚开始进入读模式时, position会被重置为0 , 2. 当缓冲区读取时,也从position开始读,读取到数据后,position向前移动一下可读位置 , 3. position 的最大值为最大可读跟上limit , 当position达到limit时, 表明缓冲区已经无数据可读。
起点在哪里呢 ? 当新建一个缓冲区时, 缓冲区处于写入模式,这时是可以写入数据的, 数据写入后,如果要从缓冲区读取数据,就需要进行模式的切换,可以使用即调用flip()翻转方法 , 将缓冲区变成了读取模式 。
在这个flip()翻转过程中, position 会进行非常巨大的调整, 具体的规则是position由原来的写位置 , 变成 了新的可读位置 , 也就是0 , 表示可以从头开始读, flip()翻转的另外一半工作 , 就是要调整limit的值 。
- limit 属性
Buffer 类的limit属性,表示读写的最大上限,limit属性,也与缓冲区的读写模式有关, 在不同的模式下,limit的值含义是不同的。
在写模式下,limit属性值的含义为何可以写入数据的最大上限,在刚进入到写模式时,limit的值会被设置成缓冲区的capacity容量值,表示可以一直将缓冲区的容量写满 。
在读模式下,limit的值含义为最多能从缓冲区中读取多少数据 。
一般来说,是先写入再读取,当缓冲区写入完成后,就可以开始从Buffer 读取数据,可以使用flip翻转方法 , 这时,limit的值就会进行非常大的调整。
具体是如何调整的呢? 将写模式下的position的值 , 设置成读模式下的limit的值,也就是说,将之前写入的最大数量,作为可读取的上限值 。
在flip()翻转时 , 属性的调整,将涉及到position , limit 两个属性, 这种调整比较微妙, 不是太好理解 , 举一个简单的例子。
首先,创建缓冲区,刚开始时,缓冲区处理写模式,position为0 , limit的最大容量值 , 然后向缓冲区中写数据 , 每写入一个数据,position的值就移动一个位置 。 也就是position的值+ 1 , 假定写入了5个数,当写入完成后,position的值为5 。
这时,使用即调用flip()方法 , 将缓冲区切换到读模式,limit的值,先会被设置成写模式时的position值, 这里新的limit是5 , 表示可以读取的最大上限值是5, 同时新的position会被重置为0 , 表示可以从0开始读取。
3.2.3 4个属性的小结
除了上面3个属性,第4个属性mark(标记)比较简单, 就相当于一个存储属性, 暂时保存了position的值 , 方便后面重复使用position的值 。
下面一个表示总结一下4 个Buffer的4个重要属性, 参见表3-1
| 属性 | 说明 |
|---|---|
| capacity | 容量,即可以容纳的最大数据量, 在缓冲区创建时设置并且不能改变 |
| limit | 上限,缓冲区中当前的数据量 |
| position | 位置 , 缓冲区中下一个要被读或写的元素索引 |
| mark | 调用mark() 方法来设置mark=position , 再调用reset()方法可以让position恢复到mark标记的位置 即position = mark |
3.3 详解NIO Buffer 类的重要方法
3.3.1 allocate() 创建缓冲区
在使用Buffer缓冲区之前 , 我们首先要获得Buffer子类的实例对象, 并且分配内存空间。
为了获取一个Buffer实例对象, 这里并不是使用子类构造器new来创建一个实例对象, 而是调用子类 allocate()方法 。
下面程序片断就是用来获取一个整型Buffer 类的缓冲区实例对象,代码如下
public class UserBuffer {
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
}
例子中, IntBuffer 是具体的Buffer子类,通过调用IntBuffer.allocate(20) , 创建了一个IntBuffer实例对象,并且分配了20 * 4 个字节的内存空间。
after allocat =====
position = 0
limit = 20
capacity = 20
从上面运行结果可以看出 。
一个缓冲区在新建后,处于写入模式,position写入位置为0 , 最大可写入上限 。
3.3.2 put() 写入到缓冲区
在调用allocate方法分配内存,返回了实例对象之后,缓冲区实例对象处于写模式,可以写入对象,要写入到缓冲区,需要调用put()方法,put()方法简单,只有一个参数,即为所需要写入的对象,不过,写入数据类型要求与缓冲区的类型一致。
按前面的例子,向刚刚创建intBuffer缓存实例对象,写入5个整数,代码如下 。
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
for(int i = 0 ; i < 5 ;i ++){
// 写入一个整数到缓冲区
intBuffer.put(i);
}
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
写入了5个元素后,同样输出缓冲区主要属性值,输出的结果如下所示 。
after allocat =====
position = 5
limit = 20
capacity = 20
从结果可以看到,position 变成了5 , 指向了第6个写入的元素位置,而limit 最大写入元素的上限,capacity 最大容量值,并没有发生变化。
3.3.3 flip() 翻转
向缓冲区写入数据之后,是否可以直接从缓冲区中读取数据呢?不能。
这里缓冲区还处于写模式,如果需要读取数据,还需要将缓冲区转换成读模式,flip()翻转方法是Buffer类提供的一个模式转变的重要方法 , 它的作用就是将写入的模式翻转成读取模式 。
接下来看flip()方法的使用:
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
for(int i = 0 ; i < 5 ;i ++){
// 写入一个整数到缓冲区
intBuffer.put(i);
}
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
// 翻转缓冲区, 从写模式翻转成读模式
intBuffer.flip();
// 输出缓冲区的主要属性值
System.out.println("=================after flip ====================");
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
调用flip()方法后,之前写入的模式下的position值5,变成了可读上限limit值5 , 而新的读取模式下position的值,简单粗暴地变成了0 , 表示从头开始读取 。
最后,清除之前的mark标记,因为mark保存的是写模式下临时位置,在读模式下,如果继续使用旧的mark标记,会千万位置混乱 。
在关上面的三步, 其实可以查看flip()方法的源代码 , Buffer.flip9)方法的源代码如下 。
public final Buffer flip() {
limit = position; // 设置可读的长度上限,limit ,为写入的postion
position = 0; // 把读的起始位置position 的值设置为0 , 表示从头开始读
mark = -1; // 清除之前的mark标记
return this;
}
至此,大家都知道了,如何将缓冲切换成读取模式 。
新的问题来了,在读取完成之后,如何再一次将缓冲区切换成写入模式呢? 可以调用Buffer.clear()清空或者Buffer.compact()压缩方法,它们可以将缓冲区转换为写模式 。
Buffer 的模式转换,大致如下图3-1所示 。
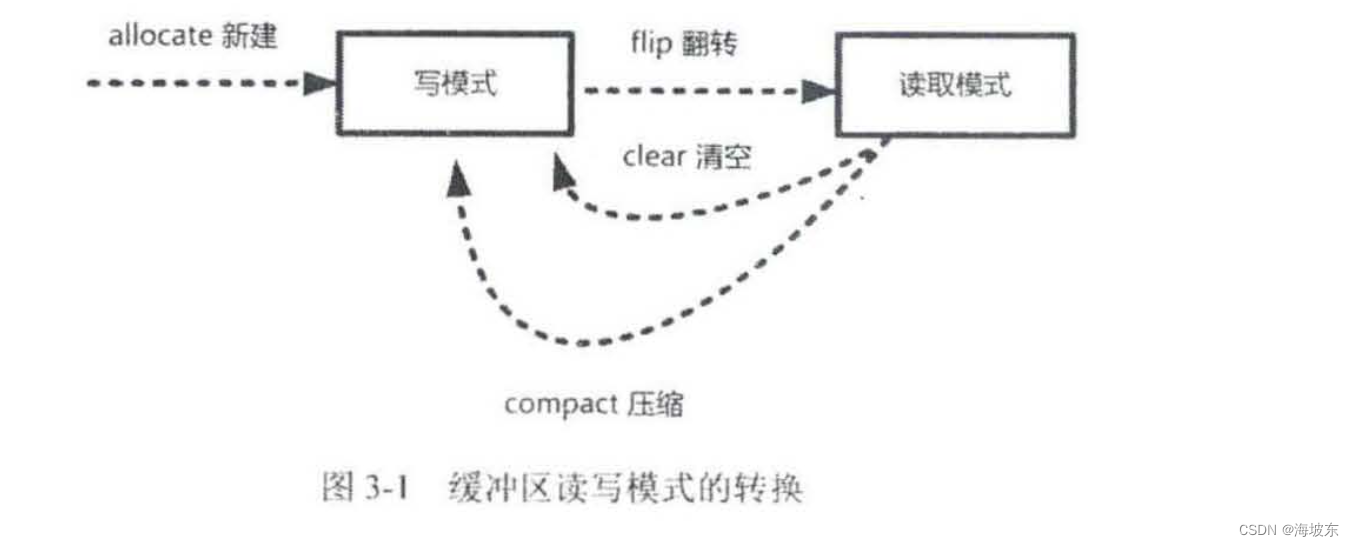
3.3.4 get()从缓冲区读取
调用flip方法,将缓冲区切换成读取模式,这时,可以开始从缓冲区进行数据读取了, 读取数据很简单,调用get方法,每次从position的位置中读取一个数据,并且进行相应的缓冲区属性的调整。
接着前面的flip的使用实例, 演示了下一个缓冲区读写操作,代码如下 :
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
for(int i = 0 ; i < 5 ;i ++){
// 写入一个整数到缓冲区
intBuffer.put(i);
}
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
for(int i = 0 ;i < 2 ;i ++){
int j = intBuffer.get();
System.out.println("j = " + j );
}
System.out.println("========after get 2 int ===================");
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
// 再读取3个
for(int i = 0 ;i < 3 ;i ++){
int j = intBuffer.get();
System.out.println("j = " + j );
}
System.out.println("========after get 3 int ===================");
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
after allocat =====
position = 5
limit = 20
capacity = 20
j = 0
j = 0
========after get 2 int ===================
position = 7
limit = 20
capacity = 20
j = 0
j = 0
j = 0
========after get 3 int ===================
position = 10
limit = 20
capacity = 20
从程序的输出结果,我们可以看到,读取操作会改变可读位置position的值,而limit 值不会改变,如果position值和limit的值相等,表示所有的数据读取完, position指向了一个没有数据的元素位置,已经不能再读了, 此时,再读取,会抛出BufferUnderFlowException异常。
这里强调一下, 在读完之后,是否可以立即进入写模式呢? 不能,现在还处于读取模式,我们必须调用Buffer.clear()或Buffer.compact(),即清空或者压缩缓冲区, 才能写入模式,让其可以重新写。另外还有一个问题,缓冲区是不是可以重复读呢? 答案是可以的。
3.3.5 rewind()倒带
已经读取完数据, 如果需要再读一遍,可以调用rewind()方法,rewind()方法叫倒带, 就像播放磁带一样倒回去,再重新播放。
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
for(int i = 0 ; i < 5 ;i ++){
// 写入一个整数到缓冲区
intBuffer.put(i);
}
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
for(int i = 0 ;i < 2 ;i ++){
int j = intBuffer.get();
System.out.println("j = " + j );
}
System.out.println("========after get 2 int ===================");
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
System.out.println("========rewind() ===================");
intBuffer.rewind();
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
after allocat =====
position = 5
limit = 20
capacity = 20
j = 0
j = 0
========after get 2 int ===================
position = 7
limit = 20
capacity = 20
========rewind() ===================
position = 0
limit = 20
capacity = 20
rewind()方法,主要调整缓冲区的position的属性,具体的调整规则如下
1. position 重置为0 , 所以可以重新读取缓冲区中的所有数据 。
2. limit 保持不变 , 数据量还是一样, 仍然表示能从缓冲区中读取多少个元素 。
3. mark标记被清理,表示之前的临时位置不能再用了。
public final Buffer rewind() {
position = 0; // 重置为0 , 所以可以重新读取缓冲区中的所有数据
mark = -1; // mark 标记被清理 , 表示之前的临时位置不能再用了。
return this;
}
通过源代码,我们可以看出 , rewind()方法与flip()方法相似 , 区别在于,rewind()不会影响limit 属性值 , 而flip()会重设limit属性值 。
3.3.6 mark() 和reset()
Buffer.mark()方法的作用是将当前position的值保存起来 , 放在mark属性中,让mark属性记住这个临时位置,之后,可以调用Buffer.reset()方法将mark的值恢复到position中。
也就是说,Buffer.mark()和Buffer.reset()方法是配套使用的,两种方法都需要内部mark属性的支持。
在前面重复读取缓冲区中的示例代码中, 读取到第3个元素i == 2 时,调用mark()方法,把当前位置position的值保存到mark属性中, 这时mark的属性值为2 。
接下来, 就可以调用reset方法,将mark的属性值恢复到position中,然后可以从位置 2 开始读取 。
继续接着前面的重复读取的代码,进行reset的示例。
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
for(int i = 0 ; i < 5 ;i ++){
// 写入一个整数到缓冲区
intBuffer.put(i);
}
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
intBuffer.mark();
for(int i = 0 ;i < 2 ;i ++){
int j = intBuffer.get();
System.out.println("j = " + j );
}
System.out.println("========after get 2 int ===================");
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
System.out.println("========reset() ===================");
intBuffer.reset();
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
after allocat =====
position = 5
limit = 20
capacity = 20
j = 0
j = 0
========after get 2 int ===================
position = 7
limit = 20
capacity = 20
========reset() ===================
position = 5
limit = 20
capacity = 20
在上面的代码中,首先调用reset()把mark的值恢复到position的位置 。 因此读取的位置position的值就是5 。
3.3.7 clear()清空缓冲区
在读模式下, 调用clear()方法将缓冲区切换为写入模式, 此方法会将position清零, limit设置为capacity最大容量值 , 可以一直写入, 直到缓冲区写满 。
public static void main(String[] args) {
// 调用allocate 方法,而不是new
IntBuffer intBuffer = IntBuffer.allocate(20);
for(int i = 0 ; i < 5 ;i ++){
// 写入一个整数到缓冲区
intBuffer.put(i);
}
// 输出buffer的主要属性值
System.out.println("after allocat =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
intBuffer.flip();
System.out.println("==========after flip =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
intBuffer.clear();
System.out.println("==========after clear =====" );
System.out.println("position = " + intBuffer.position());
System.out.println("limit = " + intBuffer.limit());
System.out.println("capacity = " + intBuffer.capacity());
}
after allocat =====
position = 5
limit = 20
capacity = 20
==========after flip =====
position = 0
limit = 5
capacity = 20
==========after clear =====
position = 0
limit = 20
capacity = 20
在缓冲区处于读取模式时, 调用clear(),缓冲区会被切换成写入模式,调用clear()之后,我们可以看到清空了position的值 , 即设置了写入起始位置为0 , 并且写入的上限为最大容量 。
3.3.8 使用Buffer 类的基本步骤
总体来说, 使用Java NIO Buffer 类的基本步骤如下 :
- 使用创建的子类实例对象的allocate()方法,创建一个Buffer 类的实例对象 。
- 调用put()方法,将数据写入到缓冲区中。
- 写入完成之后,在开始读取数据之前 , 调用Buffer.flip()方法,将缓冲区转换为读模式
- 调用get()方法,从缓冲区中读取数据 。
- 读取完之后,调用Buffer.clear()或Buffer.compact()方法,将缓冲区转换为写入模式 。
3.4 详解NIO Channel(通道)类
前面讲到,NIO 中一个连接就用一个Channel 通道来表示 , 大家都知道,从更广泛的层面上来说,一个通道可以表示一个底层的文件描述符,例如硬件设备 , 文件,网络连接等,然而,远远不及如此,除了可以对应底层的文件描述符,Java NIO 的通道还可以更加细化,例如,对应不同的网络传输协议类型,Java 中都有不同的NIO Channel 通道实现。
3.4.1 Channel 通道的主要类型
这里不对繁复的Java NIO 通道类型进行过多的描述 ,仅仅聚焦于介绍最为重要的4种Channel 通道的实现, FileChannel , SocketChannel , ServerSocketChannel , DatagramChannel 。
对于以上的四种通道,用于文件的数据读写。
- FileChannel 文件通道,用于文件的数据读写。
- SocketChannel 套接字通道, 用于Socket套接字TCP连接的数据读写。
- ServerSocketChannel 服务器嵌套字通道 , 或服务器监听通道 , 允许我们监听 TCP 连接的请求, 为每个监听到的请求,创建一个SocketChannel 套接字通道 。
- DatagramChannel 数据报通道,用于UDP 协议的数据读写。
这四种通道,涵盖了文件IO ,TCP 网络,UDP IO 基础IO ,下面从Channel 通道的获取,读取,写入,关闭四个重要的操作,来对四种通道进行简单的介绍 。
3.4.2 FileChannel 文件通道
FileChannel 是专门操作文件的通道,通过FileChannel ,既可以从一个文件中读取数据,也可以将数据写入到一个文件中, 特别申明一下, FileChannel 为阻塞模式,不能设置为非阻塞模式 。
下面介绍,FileChannel 的获取,读取,写入,关闭四个操作。
- 获取FileChannel通道
可以通过文件的输入流,输出流获取FileChannel 文件通道 , 示例如下 。
// 创建一条文件输入流
FileInputStream fis = new FileInputStream("srcFile");
// 获取文件流的通道
FileChannel fileChannel = fis.getChannel();
// 创建一条文件输出流
FileOutputStream fos = new FileOutputStream("destFile");
// 获取文件流的通道
FileChannel outChannel = fos.getChannel();
// 也可以通过RandomAccessFile 文件随机访问类, 获取FileChannel 文件通道
// 创建RandomAccessFile 随机访问对象
RandomAccessFile file = new RandomAccessFile("filename.txt","rx");
// 获取文件流的通道
FileChannel lineChannel = file.getChannel();
- 读取FileChannel通道
大部分应用场景 , 从通道读取数据都会调用通道的int read(ByteBuffer buf) 方法,它从通道读取到数据写入到ByteBuffer缓冲区, 并且返回读取的数量值 。
RandomAccessFile aFile = new RandomAccessFile(“fileName”,“rw”);
// 获取通道
FileChannel inChannel = aFile.getChannel();
// 获取一个字节缓冲区
ByteBuffer buf = ByteBuffer.allocate(1024);
int length = 1 ;
// 调用通道的read方法,读取数据并买入字节类型的缓冲区
while((length = inChannel.read(buf)) != -1 ){
// 省略,处理读取buf中的数据
}
// 【注意 】: 虽然对于通道来说是读取数据,但对于ByteBuffer来说,缓冲区来说是写入数据 , 这里,ByteBuffer 缓冲区处于写入模式 。
- 写入FileChannel通道
写入数据到通道,在大部分应用场景 , 都会调用通道的int write(ByteBuffer buf ) 方法,此方法的参数,ByteBuffer 缓冲区, 是数据的来源 , write方法的作用, 是从ByteBuffer 缓冲区中读取数据 , 然后写入到通道自身, 而返回的值是写入成功的字节数。
// 如果buf 刚写完数据 , 需要flip翻转buf , 使其变成读取模式
buf.flip();
int outlength = 0 ;
// 调用write方法,将buf 的数据写入通道
while((outlength = outChannel.write(buf)) != 0 ) {
System.out.println(“写入的字节数:” + outlength);
}
- 关闭通道
当通道使用完成后,必须将其关闭,关闭非常简单,调用close()方法即可。
// 关闭通道
channel.close();
- 强制刷新磁盘
在将缓冲区写入通道时, 出于性能原因,操作系统不可能每次都实时的将数据写入到磁盘, 如果需要保证写入通道的缓冲区数据 , 最终都真正的写入磁盘,可以调用FileChannel 的force()方法 。
// 强制刷新到磁盘
channel.force(true);
3.4.4 SocketChannel 套接字通道
在NIO中, 涉及网络连接的通道有两个, 一个是SocketChannel 负责连接传输,另一个是ServerSocketChannel 负责连接监听 。
NIO 中的SocketChannel 传输通道,与OIO中Socket类对就。
NIO中的ServerSocketChannel 监听通道 , 对应于OIO 的ServerSocket类。
ServerSocketChannel 应用于服务器, 而SocketChannel 同时处于服务器端和客户端 , 换名话说, 对于一个连接,两端都有一个负责传输的SocketChannel传输通道 。
无论是ServerSocketChannel,还是SocketChannel,都支持阻塞和非阻塞两种模式, 如何进行模式的设置呢? 调用configureBlocking方法,具体如下 。
- socketChannel.configureBlocking(false) 设置为非阻塞模式 。
- socketChannel.configureBlocking(true) 设置为阻塞模式 。
在阻塞模式下,SocketChannel 通道的connect 连接,read读,write写操作, 都是同步的和阻塞式的, 在效率上与Java 旧的OIO 的面向流的阻塞式读写操作相同 , 因此,在这里不介绍阻塞模式下的通道的具体操作, 在非阻塞模式下, 通道的操作是异步 ,高效率的,这也是相对于传递的OIO 的优势所在。
1. 获取SocketChannel 传输通道
在客户端,先通过SocketChannel 静态方法open() 获得一个套接字传输通道,然后,将socket套接字设置为非阻塞模式,最后,通过connect() 实例方法, 对服务器的IP和端口发起连接 。
// 获得一个套接字传输通道
SocketChannel socketChannel = SocketChannel.open();
// 设置为非阻塞模式
socketChannel.configureBlocking(false);
// 对服务器的IP和端口发起连接
socketChannel.connect(new InetSocketAddress(“127.0.0.1”),80);
在非阻塞情况下, 与服务器连接可能还没有真正的建立,socketChannel.connect方法就返回了, 因此需要不断的自旋,检查当前是否连接到主机 。
while(!socketChannel.finishConnect()) {
// 不断的自旋, 等待,或者做一些其他的事情
}
在服务端,如何获取传输的套接字呢?
当新链接事件到来时, 在服务端的ServerSocketChannel 能成功的查询出一个新连接事件,并且通过调用服务器端ServerSocketChannel监听套接字accept()方法 , 来获取新连接的套接字通道 :
// 新连接事件到来,首先通过事件,获取服务器监听通道 。
ServerSocketChannel server = (ServerSocketChannel)key.channel();
// 获取新连接套接字通道
SocketChannel socketChannel = server.accept();
// 设置为非阻塞模式
socketChannel.configureBlocking(false);
强制一下, NIO 套接字通道,主要用于非阻塞场景,所以,需要调用configureBlocking(false),从阻塞模式设置为非阻塞模式 。
- 读取SocketChannel 传输通道
当SocketChannel 通道可读时, 可以从SocketChannel 读取数据, 具体方法与前面的文件通道读取方法是相同的, 调用read方法,将数据读入缓冲区ByteBuffer 。
ByteBuffer buf = ByteBuffer.allocate(1024) ;
int byteRead = socketChannel.read(buf);
在读取时, 因为是异步,因此我们必须检测read的返回值, 以便判断当前是否读取到了数据,read()方法的返回值,是读取的字节数, 如果返回-1 , 那么表示读取到对方输出结束标志, 对方已经输出结束,准备关闭连接,实际上, 通过read方法读数据,本身很简单,比较困难的是, 在非阻塞模式下, 如何知道通道何时是可读的呢? 这就需要用到NIO 的新组件,Selector通道选择器,稍后介绍 。
3. 写入到SocketChannel 传输通道
和前面把数据写入到FileChannel 文件通道一样,大部分应用场景都调用通道的int write(ByteBuffer )方法 。
// 写入前需要读取缓冲区, 要求ByteBuffer 是读取模式 。
buffer.flip() ;
socketChannel.write(buffer) ;
4. 关闭SocketChannel传输通道
在关闭SocketChannel 传输通道前, 如果传输通道用来写入数据,则建议调用一次shutdownOutput()终止输出方法,向对方发送一个输出的结束标志(-1), 然后调用socketChannel.close()方法,关闭套接字连接 。
// 终止输出方法中,向对方发送一个输出的结束标志。
socketChannel.shutdownOutput();
关闭套接字连接
IOUtil.closeQuietly(socketChannel) ;
/**
* 构造函数
* 与服务器建立连接
*/
public NioSendClient() {
}
private Charset charset = Charset.forName("UTF-8");
/**
* 向服务端传输文件
*/
public void sendFile() {
try {
String sourcePath = NioDemoConfig.SOCKET_SEND_FILE;
String srcPath = IOUtil.getResourcePath(sourcePath);
Logger.debug("srcPath=" + srcPath);
String destFile = NioDemoConfig.SOCKET_RECEIVE_FILE;
Logger.debug("destFile=" + destFile);
File file = new File(srcPath);
if (!file.exists()) {
Logger.debug("文件不存在");
return;
}
FileChannel fileChannel = new FileInputStream(file).getChannel();
SocketChannel socketChannel = SocketChannel.open();
socketChannel.socket().connect(
new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_IP
, NioDemoConfig.SOCKET_SERVER_PORT));
socketChannel.configureBlocking(false);
Logger.debug("Cliect 成功连接服务端");
while (!socketChannel.finishConnect()) {
//不断的自旋、等待,或者做一些其他的事情
}
//发送文件名称
ByteBuffer fileNameByteBuffer = charset.encode(destFile);
socketChannel.write(fileNameByteBuffer);
//发送文件长度
ByteBuffer buffer = ByteBuffer.allocate(NioDemoConfig.SEND_BUFFER_SIZE);
buffer.putLong(file.length());
buffer.flip();
socketChannel.write(buffer);
buffer.clear();
//发送文件内容
Logger.debug("开始传输文件");
int length = 0;
long progress = 0;
while ((length = fileChannel.read(buffer)) > 0) {
buffer.flip();
socketChannel.write(buffer);
buffer.clear();
progress += length;
Logger.debug("| " + (100 * progress / file.length()) + "% |");
}
if (length == -1) {
IOUtil.closeQuietly(fileChannel);
// 在SocketChannel传输通道关闭前, 尽量发送一个输出结束标志到对端
socketChannel.shutdownOutput();
IOUtil.closeQuietly(socketChannel);
}
Logger.debug("======== 文件传输成功 ========");
} catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
NioSendClient client = new NioSendClient(); // 启动客户端连接
client.sendFile(); // 传输文件
}
以上代码中的文件发送过程 , 首先发送的目标文件名称(不带路径),然后发送文件长度,最后是发送文件内容,代码中的配置项,如服务器IP ,服务器端口,待发送的源文件名称(带路径 ),远程的目标文件名称等配置信息, 都是从system.properties配置文件中读取的,通过自定义的NioDemoConfig配置类来完成配置。
在运行以上客户端的程序之前,需要先运行服务器端的程序,服务器端的类与客户端源代码在同一个包下, 类名为NioReceiveServer 。
public class UDPServer {
public void receive() throws IOException {
//操作一:获取DatagramChannel数据报通道
DatagramChannel datagramChannel = DatagramChannel.open();
datagramChannel.configureBlocking(false); // 设置为非阻塞模式
datagramChannel.bind(new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_IP, NioDemoConfig.SOCKET_SERVER_PORT)); // 绑定监听地址
Print.tcfo("UDP 服务器启动成功!");
Selector selector = Selector.open(); // 开启一个通道选择器
datagramChannel.register(selector, SelectionKey.OP_READ); // 将通道注册到选择器
while (selector.select() > 0) { // 通过选择器,查询IO事件
Iterator<SelectionKey> iterator = selector.selectedKeys().iterator();
ByteBuffer buffer = ByteBuffer.allocate(NioDemoConfig.SEND_BUFFER_SIZE);
while (iterator.hasNext()) { //迭代IO事件
SelectionKey selectionKey = iterator.next();
if (selectionKey.isReadable()) { // 可读事件,有数据到来
//操作二:读取DatagramChannel数据报通道数据
SocketAddress client = datagramChannel.receive(buffer);
buffer.flip();
Print.tcfo(new String(buffer.array(), 0, buffer.limit()));
buffer.clear();
}
}
iterator.remove();
}
selector.close(); // 关闭选择器和通道
datagramChannel.close();
}
public static void main(String[] args) throws IOException {
new UDPServer().receive();
}
}
在服务器端,首先调用bind方法绑定datagramChannel 的监听端口, 当数据到来后,调用了receive方法,从datagramChannel数据包通道中接收到数据 , 再写入到ByteBuffer 缓冲区。
3.5 详解NIO Selector 选择器
Java NIO 的三大核心组件,Channel 通道,Buffer 缓冲区, Selector 选择器,其中通道和缓冲区,二者联系也比较密切,数据总是从通道读到缓冲区内,或者从缓冲区内写入到通道中, 至此,前面两组已经介绍完毕 。
3.5.1 选择器以及注册
选择器(Selector) 是什么呢? 选择器和通道的关系又是什么呢?
简单的说, 选择器的使命就是完成IO 多路复用,一个通道代表一条连接通路,通过选择器可以同时监控多个通道的IO (输入输出)状况,选择器和通道之间的关系,是监控和被监控的关系 。
选择器提供了独特的API 方法,能够选出(select)所监控的通道拥有哪些已经准备好的,就绪的IO 操作事件 。
一般来说,一个单一的线程处理一个选择器, 一个选择器可以监控很多的通道,通过选择器,一个单线程可以处理数百,数千,数万,甚至更多的通道,在极端情况下(数万连接),只用一个线程就可以处理所有的通道,这样会大量的减少线程之间上下文切换的开销。
通道和选择器之间的关系,通过register(注册)的方式完成,调用通道的Channel.register(Selector sel, int ops) 方法,可以将通道实例注册到一个选择器中,register()方法有两个参数,第一个参数,指定通道注册到选择器实例,第二个参数,指定选择器要监控的IO事件类型。
可供选择器监控的通道IO事件类型,包括以下四种。
- 可读:SelectionKey.OP_READ
- 可写: SelectionKey.OP_WRITE
- 连接:SelectionKey.OP_CONNECT
- 接收:SelectionKey.OP_ACCEPT
事件类型的定义在SelectionKey 类中, 如果选择器要监控通道的多种事件,可以用按位或运算符来实现,例如,同时监控可读和可写IO 事件 :
// 监控通道的多种事件,用按位或 运算符来实现。
int key = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
什么是IO事件呢? 这个概念容易混淆,这里特别说明一下, 这里的IO 事件不是能通道的IO 操作, 而是通道的某个IO 操作一种就绪状态,表示通道具备完成某个IO 操作的条件 ,而是通道的某个IO 操作的一种就绪状态,表示通道具备完成某个IO 操作的条件 。
比方说, 某个SocketChannel 通道,完成了和对端的握手连接,则处于连接就绪(OP_CONNECT)状态 。
再比方说, 某个ServerSocketChannel 服务器通道,监听到一个新连接到来,则处于接收 就绪 (OP_ACCEPT)状态 。
还比方说,一个有数据可读的SocketChannel通道,处于读就绪(OP_READ)状态,一个等待写入数据的,处于写就绪状态(OP_WRITE) 状态 。
3.5.2 SelecttableChannel 可选择通道
并不是所有的通道,都可以被选择器监控或者选择的,比方说, FileChannel 文件通道就不能被选择器复用,判断一个通道能否被选择器监控或者选择,有一个前提,判断它是否继承了抽象类SelectableChannel(可选择通道),如果继承了SelectableChannel ,则可以被选择,否则不能。 简单的来说,一条通道若能被选择,必须继承SeletableChannel 类。
简单的说,一条通道若能被选择,必须继承SeletableChannel类。
SelectableChannel类是何方神圣呢? 它提供了实现通道的可选择性需要的公共方法,Java NIO 中所有的网络连接Socket套接字通道,都继承了SelectableChannel类, 都是可以选择的,而FileChannel文件通道,并没有继承SelectableChannel ,因此不是可选择通道。
3.5.3 SelectionKey 选择键
通道和选择器的监控关系注册成功后,就可以选择就绪事件,具体的选择工作,和调用选择器Selector的select()方法来完成,通过select方法,选择器可以不断的选择通道中所发生操作的就绪状态,返回注册过后感兴趣的那些IO事件,换句话说,一旦在通道中发生了某些IO 事件,就绪状态达成,并且是在选择器中注册过的IO事件,就会被选择器选中,并放入到SelectionKey 选择键集合中。
这里出现一个新的概念,SelectionKey 选择键,SelectionKey 选择键是什么呢?简单的来说,SelectionKey 选择键就是那些被选择器选择的IO事件,前面讲到,一个IO 事件发生 (就绪状态达成)后,如果之前在选择器中注册过, 就会被选择器选中, 并放入到SelectionKey 选择键集合中, 如果之前没有注册过, 即使发生了IO事件,也不会被选择器选择,SelectionKey选择键和IO的关系,可以简单的理解为,选择键,就是被选中的IO事件。
有编程时, 选择键的功能是很强大的,通过SelectionKey 选择键,不仅仅可以获得通道的IO事件类型,比方说,SelectionKey.OP_READ ,还可以获得发生IO事件 所在的通道,另外,也可以获得选出选择键的选择器实例。
3.5.4 选择器的使用流程
使用选择器,主要有以下三步
1. 获取选择器实例,2 将通道注册到选择器中,3轮询感兴趣的IO就绪事件(选择器集合)。
第一步获取选择器实例
选择器的实例是通过调用静态方法open()来获取的,具体如下:
// 调用静态工厂方法open()来获取Selector实例
Selector selector = Selector.open();
Selector 选择器类方法open()的内部,是向选择器SPI(SelectorProvider)发出请求,通过默认的SelectorProvider(选择器提供者) 对象,获取一个新的选择器实例,Java 中SPI全称(Service Provider Interface,服务提供者接口),是JDK 的一种可扩展的服务提供和发现机制,Java 通过SPI 的方式,提供选择器默认的实现版本,也就是说,其他的服务提供商可以通过SPI 的方式,提供定制化版本的选择器动态替换或者扩展。
第二步:将通道注册到选择器实例
要实现选择器管理通道,需要将通道注册到相应的选择器上, 简单的示例代码如下
// 2 获取通道
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 3 设置为非阻塞
serverSocketChannel.configureBlocking(false);
// 绑定连接
serverSocketChannel.bind(new InetSocketAddress(8080));
// 5 将通道注册到选择器上, 并制定监听器事件为接收连接的事件
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
上面通过调用通道的register()方法,将ServerSocketChannel 通道注册到一个选择器上, 当然,在注册之前,首先要准备好通道 。
这里需要注意,注册到选择器的通道,必须处于非阻塞模式下,否则将抛出IllegalBlockingModeException异常。 这意味着FileChannel文件通道不能与选择器一起使用,因为FileChannel 文件通道只有阻塞模式,不能切换到非阻塞模式,而Socket套接字相关的所有通道都可以。
其次,还需要注意,一个通道,并不一定要支持所有的四种IO事件,例如,服务器监听通道ServerSocketChannel ,仅仅支持Accept(接收到新连接)IO事件,而SocketChannel 传输通道,则不支持Accept(接收到新连接)IO事件 。
如何判断通道支持哪些事件呢? 可以在注册之前,可以通过通道validOps()方法,来获取该通道所有支持的IO事件集合。
第三步,选出感兴趣的IO就绪事件(选择键集合)
通过Selector 选择器的select()方法,选出已经注册的,已经就绪的IO 事件,保存到SelectionKey选择键集合中, SelectionKey 集合保存在选择器实例内部,是一个元素的SelectionKey类型的集合(Set) ,调用选择器SelectionKeys()方法,可以取得选择键集合。
接下来,需要迭代集合中每一个选择键,根据具体的IO 事件类型,执行对应的业务操作,大致处理流程如下 :
// 轮询,选择感兴趣的IO 就绪事件(选择键集合)
while(selector.select() > 0 ){
Set selectionKeys = selector.selectedKeys();
Iterator keyIteractor = selectionedKeys.iterator();
while(keyIteractor.hasNext()){
SelectionKey key = keyIterator.next();
//根据具体的IO 事件类型,执行对应的业务操作
if(key.isAcceptable()){
//IO事件,ServerSocketChannel服务器监听通道有新连接
}else if(key.isConnectable()){
// IO事件,传输通道连接成功
}else if (key.isReadable()){
//IO事件,传输通道是否可读
}else if (kye.isWritable()){
// IO事件,传输通道可写
}
// 处理完成后,移除选择键
}
}
处理完成后,需要将选择键从SelectionKey 集合中移除,防止下一次循环的时候,被重复的处理,SelectionKey 集合不能添加元素,如果试图向SelectionKey选择键集合中添加元素,则抛出java.lang.UnsupportedOperationException异常。
用于选择就绪的IO事件的select()方法,有多个重载的实例同版本,具体如下 。
- select() 阻塞调用,一直到至少有一个通道发生 了注册的IO事件 。
- select(long timeout) : 和select()一样, 但最长阻塞时间为timeout指定的毫秒数。
- selectNow() : 非阻塞,不管有没有IO事件,都会立刻返回 。
select()方法返回的整数值(int 整数类型),表示发生了IO事件的通道数量,更准确的说,是从上一次select到这一次select 之间,有多少通道发生了IO 事件,强调一下, select()方法返回的数量,指的是通道数,而不是IO 事件数,准确的说,是指发生了选择器感兴趣的IO 事件的通道数。
3.5.5 使用NIO 实现Discard服务器的实践案例
Discard 服务器的功能很简单,仅仅读取客户端通道的输入数据,读取完之后,直接关闭客户端通道,并且读取到数据直接抛弃掉(Discard) ,Discard 服务器足够简单明了,作为第一个学习NIO 的通信实例, 较有参考价值 。
public class NioDiscardServer {
public static void startServer() throws IOException {
// 1、获取Selector选择器
Selector selector = Selector.open();
// 2、获取通道
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
// 3.设置为非阻塞
serverSocketChannel.configureBlocking(false);
// 4、绑定连接
serverSocketChannel.bind(new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_PORT));
Logger.info("服务器启动成功");
// 5、将通道注册到选择器上,并注册的IO事件为:“接收新连接”
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
// 6、轮询感兴趣的I/O就绪事件(选择键集合)
while (selector.select() > 0) {
// 7、获取选择键集合
Iterator<SelectionKey> selectedKeys = selector.selectedKeys().iterator();
while (selectedKeys.hasNext()) {
// 8、获取单个的选择键,并处理
SelectionKey selectedKey = selectedKeys.next();
// 9、判断key是具体的什么事件
if (selectedKey.isAcceptable()) {
// 10、若选择键的IO事件是“连接就绪”事件,就获取客户端连接
SocketChannel socketChannel = serverSocketChannel.accept();
// 11、切换为非阻塞模式
socketChannel.configureBlocking(false);
// 12、将该通道注册到selector选择器上
socketChannel.register(selector, SelectionKey.OP_READ);
} else if (selectedKey.isReadable()) {
// 13、若选择键的IO事件是“可读”事件,读取数据
SocketChannel socketChannel = (SocketChannel) selectedKey.channel();
// 14、读取数据
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
int length = 0;
while ((length = socketChannel.read(byteBuffer)) >0) {
byteBuffer.flip();
Logger.info(new String(byteBuffer.array(), 0, length));
byteBuffer.clear();
}
socketChannel.close();
}
// 15、移除选择键
selectedKeys.remove();
}
}
// 7、关闭连接
serverSocketChannel.close();
}
public static void main(String[] args) throws IOException {
startServer();
}
}
实现DiscardServer 一共分为16步, 其中第7步到第15步是循环执行的,不断的对感兴趣的IO事件到选择器的选择键集合中,然后通过selector.selectionKeys() 获取该选择键集合,并且进行迭代处理,对于新建立的socketChannel客户端传输通道,也要注册到同一个选择器上, 使用同一个选择线程,不断的对所有的注册通道进行选择键的选择。
在DiscardServer 程序中,涉及到两次选择注册,一次是注册serverChannel 服务器通道,另一次,注册接收到socketChannel 客户端传输通道,serverChannel 服务器通道注册的, 是新连接的IO 事件,SelectionKey.OP_ACCEPT, 客户端socketChannel 传输通道注册的,是可读IO事件SelectionKey.OP_READ。
Discard 在对选择键进行处理时, 通过能类型进行判断,然后进行相应的处理。
- 如果是SelectionKey.OP_ACCEPT新连接事件类型,代表serverChannel 服务器通道发生了新的连接事件,则通过服务器通道accept方法,获取新的socketChannel传输通道,并且将新通道注册到选择器上。
- 如果是SelectionKey.OP_READ可读事件类型,代表某个客户端通道有数据可读,则读取选择键中的socketChannel 传输通道的数据,然后丢弃。
public class NioDiscardClient {
/**
* 客户端
*/
public static void startClient() throws IOException {
InetSocketAddress address =
new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_IP,
NioDemoConfig.SOCKET_SERVER_PORT);
// 1、获取通道(channel)
SocketChannel socketChannel = SocketChannel.open(address);
// 2、切换成非阻塞模式
socketChannel.configureBlocking(false);
//不断的自旋、等待连接完成,或者做一些其他的事情
while (!socketChannel.finishConnect()) {
}
Logger.info("客户端连接成功");
// 3、分配指定大小的缓冲区
ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
byteBuffer.put("hello world".getBytes());
byteBuffer.flip();
socketChannel.write(byteBuffer);
socketChannel.shutdownOutput();
socketChannel.close();
}
// 如果需要执行整个程序,首先要执行前面的服务器程序,然后执行后面的客户端程序,通过Discard 服务器的开发实践,大家对
// NIO Selector 选择的使用iyck,应该已经非常清楚了。
public static void main(String[] args) throws IOException {
startClient();
}
}
如果需要执行整个程序,首先需要执行前面的服务器程序,然后,执行后面的客户端程序 。
通过Discard 服务器开发的实践,大家对NIO Selector 选择的使用流程,应该了解得非常清楚了 。
3.5.6 使用SocketChannel 在服务器端接收文件的实践案例
本示例中文件接收 , 这是服务器的程序 , 和前面介绍的文件发送SocketChannel 客户端程序一是相互配合使用的, 由于在服务器端,需要用到选择器, 所以在介绍完选择器后,才开始介绍NIO 文件传输Socket 服务器程序 , 服务器端接收文件的示例代码如下所示 。
public class NioReceiveServer {
private Charset charset = Charset.forName("UTF-8");
/**
* 服务器端保存的客户端对象,对应一个客户端文件
*/
static class Client {
//文件名称
String fileName;
//长度
long fileLength;
//开始传输的时间
long startTime;
//客户端的地址
InetSocketAddress remoteAddress;
//输出的文件通道
FileChannel outChannel;
}
private ByteBuffer buffer
= ByteBuffer.allocate(NioDemoConfig.SERVER_BUFFER_SIZE);
//使用Map保存每个客户端传输,当OP_READ通道可读时,根据channel找到对应的对象
Map<SelectableChannel, Client> clientMap = new HashMap<SelectableChannel, Client>();
public void startServer() throws IOException {
// 1、获取Selector选择器
Selector selector = Selector.open();
// 2、获取通道
ServerSocketChannel serverChannel = ServerSocketChannel.open();
ServerSocket serverSocket = serverChannel.socket();
// 3.设置为非阻塞
serverChannel.configureBlocking(false);
// 4、绑定连接
InetSocketAddress address
= new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_PORT);
serverSocket.bind(address);
// 5、将通道注册到选择器上,并注册的IO事件为:“接收新连接”
serverChannel.register(selector, SelectionKey.OP_ACCEPT);
Print.tcfo("serverChannel is linstening...");
// 6、轮询感兴趣的I/O就绪事件(选择键集合)
while (selector.select() > 0) {
// 7、获取选择键集合
Iterator<SelectionKey> it = selector.selectedKeys().iterator();
while (it.hasNext()) {
// 8、获取单个的选择键,并处理
SelectionKey key = it.next();
// 9、判断key是具体的什么事件,是否为新连接事件
if (key.isAcceptable()) {
// 10、若接受的事件是“新连接”事件,就获取客户端新连接
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = server.accept();
if (socketChannel == null) continue;
// 11、客户端新连接,切换为非阻塞模式
socketChannel.configureBlocking(false);
// 12、将客户端新连接通道注册到selector选择器上
SelectionKey selectionKey =
socketChannel.register(selector, SelectionKey.OP_READ);
// 余下为业务处理
Client client = new Client();
client.remoteAddress
= (InetSocketAddress) socketChannel.getRemoteAddress();
clientMap.put(socketChannel, client);
Logger.debug(socketChannel.getRemoteAddress() + "连接成功...");
} else if (key.isReadable()) {
processData(key); // 13. 若接收珠事件是数据可读事件,就读取客户端新连接
}
// NIO的特点只会累加,已选择的键的集合不会删除
// 如果不删除,下一次又会被select函数选中
it.remove();
}
}
}
/**
* 处理客户端传输过来的数据
*/
private void processData(SelectionKey key) throws IOException {
Client client = clientMap.get(key.channel());
SocketChannel socketChannel = (SocketChannel) key.channel();
int num = 0;
try {
buffer.clear();
while ((num = socketChannel.read(buffer)) > 0) {
buffer.flip();
//客户端发送过来的,首先是文件名
if (null == client.fileName) {
// 文件名
String fileName = charset.decode(buffer).toString();
String destPath = IOUtil.getResourcePath(NioDemoConfig.SOCKET_RECEIVE_PATH);
File directory = new File(destPath);
if (!directory.exists()) {
directory.mkdir();
}
client.fileName = fileName;
String fullName = directory.getAbsolutePath()
+ File.separatorChar + fileName;
Logger.debug("NIO 传输目标文件:" + fullName);
File file = new File(fullName);
FileChannel fileChannel = new FileOutputStream(file).getChannel();
client.outChannel = fileChannel;
}
//客户端发送过来的,其次是文件长度
else if (0 == client.fileLength) {
// 文件长度
long fileLength = buffer.getLong();
client.fileLength = fileLength;
client.startTime = System.currentTimeMillis();
Logger.debug("NIO 传输开始:");
}
//客户端发送过来的,最后是文件内容
else {
// 写入文件
client.outChannel.write(buffer);
}
buffer.clear();
}
key.cancel();
} catch (IOException e) {
key.cancel();
e.printStackTrace();
return;
}
// 调用close为-1 到达末尾
if (num == -1) {
IOUtil.closeQuietly(client.outChannel);
System.out.println("上传完毕");
key.cancel();
Logger.debug("文件接收成功,File Name:" + client.fileName);
Logger.debug(" Size:" + IOUtil.getFormatFileSize(client.fileLength));
long endTime = System.currentTimeMillis();
Logger.debug("NIO IO 传输毫秒数:" + (endTime - client.startTime));
}
}
/**
* 入口
*/
public static void main(String[] args) throws Exception {
NioReceiveServer server = new NioReceiveServer();
server.startServer();
}
}
由于客户端每次传输文件,都会分为多次传输。
- 首先传入文件名称
- 其次是文件大小
- 然后是文件内容
对应于每一个客户端socketChannel,创建一个Client 客户端对象,用于保存客户端状态,分别保存文件名, 文件大小,和写入的目标文件通道outChannel。
socketChannel和Client 对象之间是一对一的关系,建立连接的时候, 以socketChannel 作为键(Key) ,Client 对象作为值(Value) ,将Client 保存到Map 中,当socketChannel 传输通道有数据可读时, 通过选择键key.channel()方法,取出IO 事件所在socketChannel 通道,从map 中取到对应的Client对象 。
接收数据时, 如果文件名为空, 先处理文件名称,并且把名称保存到Client对象中,同时创建服务器上的目标文件,接下来再读取数据,说明接收到文件大小,把文件大小保存到Client对象,接下来,再接到数据,说明文件内容了, 则写入到Client 对象的outChannel 文件通道中,直到数据读取完毕 。
3.6 本章小结
与Java OIO 相比,Java NIO 编程大致的特点如下:
- 在NIO中, 服务器接收到连接工作,是异步进行的,不像Java 的OIO 那样, 服务器监听连接,是同步的,阻塞的,NIO 可以通过选择器(也可以说成是:多路复用器),后续不断的轮询选择器的选择集合,选择新来的连接 。
- 在NIO 中,SocketChannel 传输通道是读写操作都是异步的,如果没有可写的数据,负责IO 通信的线程不会同步等待,这样,线程就可以处理其他连接通道,不需要像OIO 那样,线程一直阻塞,等待所负责的连接可用为止。
- 在NIO中,一个选择器线程可以同时处理成千上万个客户端连接,性能不会随着客户端增加而线性下降。
总之,有了Linux底层的epoll 支持,有了Java NIO Selector 选择器这样的应用层IO复用技术,Java 程序从而可以实现IO 通信的高TPS ,高并发,使服务器具备并发数十万, 数百万的连接能力,Java的NIO技术非常适合用于高性能 , 高负载的网络服务器, 鼎鼎大名的通信服务器中间件Netty ,就是基于Java NIO技术实现的。
当然,Java NIO 技术仅仅是基础,如果要实现通信的高性能和高并发,还离不开高效率的设计模式 。 后面来分析Reactor反应器模式 。
第4章节
4.1.2 反应器模式简介
什么是反应器模式呢?
反应器模式由Reactor 反应器线程,Handlers 处理器两大角色组成 。
- Reactor 反应器线程的职责,负责响应IO事件,并且分发到Handlers 处理器。
- Handlers 处理器的职责,非阻塞的执行行业业务处理逻辑 。
4.1.3 多线程OIO的致命缺陷
Java的OIO编程中, 最初和最原始的网络服务器程序,是用一个while()循环,不断的监听端口是否有新连接,如果有,那么就调用一个处理函数来处理,示例代码如下
while(true){
socket = accept(); //阻塞,接收连接
handle(socket) ; //读取数据,业务处理, 写入结果
}
这种方法的最大问题是, 如果前一个网络连接handle(Socket) 没有处理完,那么后面的连接请求没法被接收,于是后面的请求通道会被阻塞住,服务器的吞吐量就太低了, 对于服务器来说,这是一个严重的问题。
为了解决这处严重的连接阻塞问题, 出现了一个极为经典的Connection PerThread 一个线程处理一个连接模式。
class ConnectionPerThread implements Runnable {
public void run() {
try {
ServerSocket serverSocket =
new ServerSocket(NioDemoConfig.SOCKET_SERVER_PORT); // 服务器监听socket
while (!Thread.interrupted()) {
Socket socket = serverSocket.accept(); // 接收到一个连接后,为socket连接,新建一个专属处理器对象
Handler handler = new Handler(socket);
//创建新线程来handle
//或者,使用线程池来处理
new Thread(handler).start(); // 创建新线程,专门负责一个连接的处理
}
} catch (IOException ex) { /* 处理异常 */ }
}
static class Handler implements Runnable {
final Socket socket;
Handler(Socket s) {
socket = s;
}
public void run() {
while (true) {
try {
byte[] input = new byte[NioDemoConfig.SERVER_BUFFER_SIZE];
/* 读取数据 */
socket.getInputStream().read(input);
/* 处理业务逻辑,获取处理结果 */
byte[] output =null;
/* 写入结果 */
socket.getOutputStream().write(output);
} catch (IOException ex) { /*处理异常*/ }
}
}
}
}
对于每一个新的网络连接都分配给一个线程,每个线程都独自的处理自己负责的输入和输出,当然,服务器的监听线程也是独立的,任何的socket 连接的输入和输出处理,不会阻塞到后面新socket连接的监听和建立,早期版本的Tomcat 服务器就是这样实现的。
ConnectionPerThread(模式 ) 一个线程处理一个连接,的优点是,解决了前面的新连接被严重阻塞的问题, 有一定程序上, 极大的提高了服务器的吞吐量。
这里还有一个问题,如果一个线程同时负责处理多个socket连接的输入和输出,行不行呢?
看上去,没有什么不可以,但是,实际上没有用,为什么呢?传统的OIO编程中每一个socket的IO 读写操作,都是阻塞的,在同一时刻,一个线程只能处理一个socket ,前一个socket阻塞了,后面连接的IO操作是无法被并发执行的,所以,无论怎样处理, OIO 中一个线程也只能处理一个连接的IO操作。
ConnectionPerThread模式的缺点是, 对应于大量的连接,需要耗费大量的线程资源,对线程资源的要求太高,在系统中,线程比较昂贵的系统资源,如果线程数量太多, 系统无法承受,而且,线程无法反复创建,销毁,线程的切换也需要代价,因此,在高并发应用场景下, 多线程的OIO的缺陷是致命的。
如何解决ConnectionPerThread模式的巨大缺陷呢? 一个有效的路径是, 使用Reactor反应器模式,用反应器模式对线程数量进行控制,做到一个线程处理大量的连接,它是如何做到的呢? 首先来看简单的版本,单线程的Reactor 反应器模式 。
4.2 单线程Reactor 反应器模式
总体来说,Reactor反应器模式有点类似于事件驱动模式 。
在事件驱动模式中,当有事件触发时,事件源会将事件dispatch分发到handler 处理进行事件处理,反应器模式中的反应器角色,类似于事件驱动模式中的dispatcher事件分发器角色 。
在前面已经提到过,在反应器模式中,有Reactor 反应器和Handler 处理器两个重要组件 。
- Reactor 反应器,负责查询IO 事件,当检测到一个IO 事件,将其发送给相应的Handler 处理器去处理,这里的IO事件,就是NIO中选择器监控的通道IO 事件 。
- Handler 处理器, 与IO 事件(或者选择键)绑定,负责IO 事件的处理, 完成真正的连接建立,通道的读写, 处理业务逻辑,负责将结果写出到通道等。
4.2.1 什么是单线程的Reactor反应器呢?
什么是间线程版本的Reactor 反应器模式呢? 最简单的说,Reactor 反应器Handlers 处于一个线程执行,它是最简单的反应器模式 , 如下图所示 。
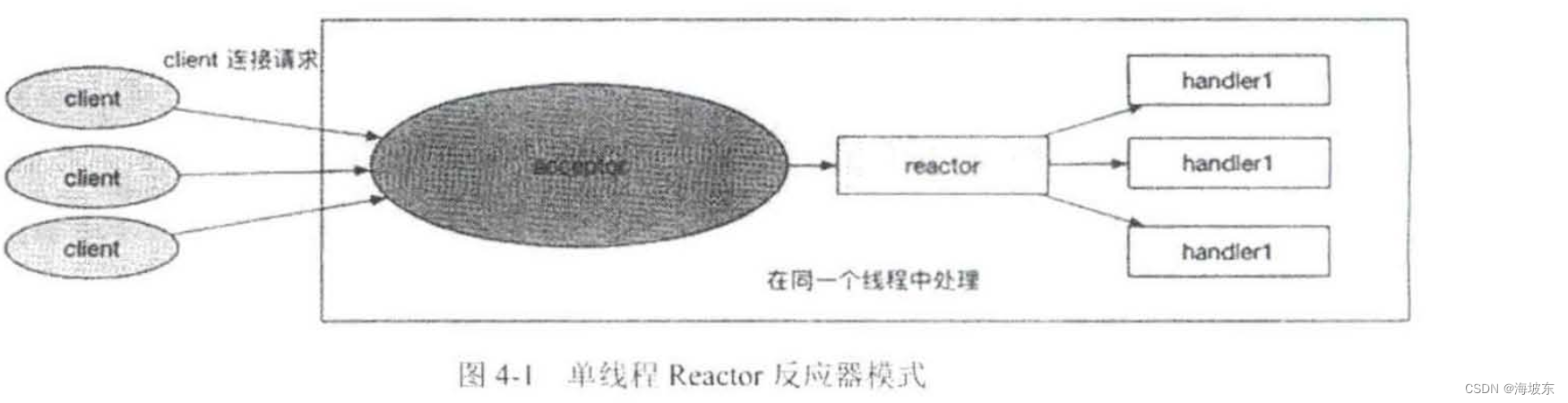
基于Java NIO ,如何实现简单的单线程版本的反应器模式呢? 需要用到SelectionKey 选择键的几个重要方法 。
方法1,void attach(Object o );
此方法可以将任何的Java POJO 对象,作为附件添加到SelectionKey实例,相当于附件属性的setter方法,这个方法非常重要,因为在单线程版本的反应器模式中,需要将Handler 处理器实例作为附件添加到SelectionKey实例。
方法二:Object attachment()
此方法的作用是取出之前的attach(Object o ) 添加到SelectionKey选择键实例的附件中, 相当于附件属性的getter方法,与attach(Object o)配套使用。
这个方法同样非常重要,当IO 事件发生,选择键被select方法选中,可以直接将事件的附件取出,也就是之前绑定的Handler 处理器实例,通过该Handler ,完成相应的处理。
总之,在反应器模式中, 需要进行attach和attachment结合使用,在选择键注册完成之后,调用attach方法,将Handler 处理器绑定到选择键,当事件发生时, 调用attachment方法,可以从选择键中取出Handler处理器,将事件分发到Handler 处理器中, 完成业务处理。
4.2.2 单线程Reactor 反应器参考代码
Doug Lea 在《Scalable IO in Java》中,实现了一个单线程Reactor 反应器模式的参考代码,这里,我们站在巨人的肩膀上, 借鉴Doug Lea 的实现, 对其进行介绍,为了方便说明,对Doug Lea 的参考代码进行一些适当的修改。
class EchoServerReactor implements Runnable {
Selector selector;
ServerSocketChannel serverSocket;
EchoServerReactor() throws IOException {
//Reactor初始化
selector = Selector.open();
serverSocket = ServerSocketChannel.open();
InetSocketAddress address =
new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_IP,
NioDemoConfig.SOCKET_SERVER_PORT);
serverSocket.socket().bind(address);
//非阻塞
serverSocket.configureBlocking(false);
//分步处理,第一步,接收accept事件,注册serverSocket的接受 (Accept)事件
SelectionKey sk =
serverSocket.register(selector, SelectionKey.OP_ACCEPT);
//attach callback object, AcceptorHandler 将新连接处理器作为附件,绑定到sk选择器
sk.attach(new AcceptorHandler());
}
public void run() {
// 选择器轮询
try {
while (!Thread.interrupted()) {
selector.select();
Set<SelectionKey> selected = selector.selectedKeys();
Iterator<SelectionKey> it = selected.iterator();
while (it.hasNext()) {
//Reactor负责dispatch收到的事件
SelectionKey sk = it.next();
dispatch(sk);
}
selected.clear();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
// 反应器的分发方法
void dispatch(SelectionKey sk) {
Runnable handler = (Runnable) sk.attachment();
//调用之前attach绑定到选择键的handler处理器对象
if (handler != null) {
handler.run();
}
}
// Handler:新连接处理器,
class AcceptorHandler implements Runnable {
public void run() {
try {
// 接受新连接
// 需要为新连接创建一个输入输出的Handler 处理器
SocketChannel channel = serverSocket.accept();
if (channel != null)
new EchoHandler(selector, channel);
} catch (IOException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException {
new Thread(new EchoServerReactor()).start();
}
}
class EchoHandler implements Runnable {
final SocketChannel channel;
final SelectionKey sk;
final ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
static final int RECIEVING = 0, SENDING = 1;
int state = RECIEVING;
EchoHandler(Selector selector, SocketChannel c) throws IOException {
channel = c;
c.configureBlocking(false);
//仅仅取得选择键,后设置感兴趣的IO事件
sk = channel.register(selector, 0);
//将Handler作为选择键的附件
sk.attach(this);
//第二步,注册Read就绪事件
sk.interestOps(SelectionKey.OP_READ);
selector.wakeup();
}
public void run() {
try {
if (state == SENDING) {
//写入通道
channel.write(byteBuffer);
//写完后,准备开始从通道读,byteBuffer切换成写模式
byteBuffer.clear();
//写完后,注册read就绪事件
sk.interestOps(SelectionKey.OP_READ);
//写完后,进入接收的状态
state = RECIEVING;
} else if (state == RECIEVING) {
//从通道读
int length = 0;
while ((length = channel.read(byteBuffer)) > 0) {
Logger.info(new String(byteBuffer.array(), 0, length));
}
//读完后,准备开始写入通道,byteBuffer切换成读模式
byteBuffer.flip();
//读完后,注册write就绪事件
sk.interestOps(SelectionKey.OP_WRITE);
//读完后,进入发送的状态
state = SENDING;
}
//处理结束了, 这里不能关闭select key,需要重复使用
//sk.cancel();
} catch (IOException ex) {
ex.printStackTrace();
}
}
}
以上两个类,一个是基于反应器模式的EchoServer回显服务器的完整实现, 它是一个单线程版本的反应器模式,Reactor反应器和所有的Handler 反应器,都执行在同一条线程中。
运行EchoServerReactor类中的main方法,可以启动回显服务器,如果要看到回显输出,还需要启动客户端,客户端的代码,在同一个包下, 类包为EchoClient,负责数据的发送 。
4.2.4 单线程Reactor 反应器模式的缺点
单线程Reactor反应器模式,是基于Java 的NIO 实现的,相对于传统的的多线程OIO,反应器模式不再需要启动成千上万条线程, 效率自然是大大的提升了。
在单线程反应器模式中,Reactor 反应器和Handler 处理器,都执行在同一条线程上, 这样带来了一个问题, 当其中的某个Handler 阻塞时,会导致其他所有的Handler都得不到执行,在这种场景下, 如果被阻塞的Hander 不仅仅负责输入和输出处理业务,还包括负责连接监听的AcceptorHandler 处理器, 这是个非常严重的问题。
为什么?一旦AcceptorHandler 处理器阻塞,会导致整个服务器不能接收到新连接呢?使得服务器变得不可用?因为这个缺陷,因此单线程反应器模型用得比较少。
另外,目前的服务器都是多核的,单线程反应器模式不能充分利用多核资源,总之, 在高性能的服务器应用场景中, 单线程反应器模式实际使用得很少。
4.3 多线程Reactor 反应器模式 。
既然Reactor 反应器模和Handler处理器,挤在一个线程会造成非常严重的缺陷,那么可以使用多线程,对基础的反应器模式进行发行和演进 。
4.3.1 多线程池Reactor 反应器演进
多线程池Reactor 反应器的演进,分为两个方法 。
- 首先是升级Handler ,既要使用多线程, 又要尽可能的高效率,则可以考虑使用线程池。
- 其次是升级Reactor 反应器,可以考虑引入多个Selector 选择器,提升选择大量通道的能力 。
总体来说,多线程池反应器模式,大致如下
- 将负责输入输出处理的IOHandler 处理器执行,放入到独立的线程池中,这样业务处理线程与负责服务监听和IO事件查询的反应器线程相隔离,避免服务器连接监听受到阻塞。
- 如果服务器为多核的CPU ,可以将反应器线程拆分为多个子反应器(SubReactor)线程,同时引入多个选择器,每一个SubReactor 子线程负责一个选择器,这样,充分释放了系统资源的能力,也提高了反应器管理大量的连接,提升选择大量通道的能力 。
4.3.2 多线程Reactor 反应器的实践案例
在前面的回显服务器(EchoServer) 的基础上, 完成多线程Reactor 反应器的升级,多线程反应器的实例案例实践如下:
- 引入多个选择器
- 设计一个新子反应器(SubReactor)类,一个子反应器负责查询一个选择器。
- 开启多个反应器的处理线程,一个线程负责执行一个子反应器(SubReactor) 。
class MultiThreadEchoServerReactor {
ServerSocketChannel serverSocket;
AtomicInteger next = new AtomicInteger(0);
//selectors集合,引入多个selector选择器
Selector[] selectors = new Selector[2];
//引入多个子反应器
SubReactor[] subReactors = null;
MultiThreadEchoServerReactor() throws IOException {
//初始化多个selector选择器
selectors[0] = Selector.open();
selectors[1] = Selector.open();
serverSocket = ServerSocketChannel.open();
InetSocketAddress address =
new InetSocketAddress(NioDemoConfig.SOCKET_SERVER_IP,
NioDemoConfig.SOCKET_SERVER_PORT);
serverSocket.socket().bind(address);
//非阻塞
serverSocket.configureBlocking(false);
//第一个selector,负责监控新连接事件
SelectionKey sk =
serverSocket.register(selectors[0], SelectionKey.OP_ACCEPT);
//附加新连接处理handler处理器到SelectionKey(选择键)
sk.attach(new AcceptorHandler());
//第一个子反应器,一子反应器负责一个选择器
SubReactor subReactor1 = new SubReactor(selectors[0]);
//第二个子反应器,一子反应器负责一个选择器
SubReactor subReactor2 = new SubReactor(selectors[1]);
subReactors = new SubReactor[]{subReactor1, subReactor2};
}
private void startService() {
// 一子反应器对应一条线程
new Thread(subReactors[0]).start();
new Thread(subReactors[1]).start();
}
//反应器
class SubReactor implements Runnable {
//每条线程负责一个选择器的查询
final Selector selector;
public SubReactor(Selector selector) {
this.selector = selector;
}
public void run() {
try {
while (!Thread.interrupted()) {
selector.select();
Set<SelectionKey> keySet = selector.selectedKeys();
Iterator<SelectionKey> it = keySet.iterator();
while (it.hasNext()) {
//Reactor负责dispatch收到的事件
SelectionKey sk = it.next();
dispatch(sk);
}
keySet.clear();
}
} catch (IOException ex) {
ex.printStackTrace();
}
}
void dispatch(SelectionKey sk) {
Runnable handler = (Runnable) sk.attachment();
//调用之前attach绑定到选择键的handler处理器对象
if (handler != null) {
handler.run();
}
}
}
// Handler:新连接处理器
class AcceptorHandler implements Runnable {
public void run() {
try {
SocketChannel channel = serverSocket.accept();
if (channel != null)
new MultiThreadEchoHandler(selectors[next.get()], channel);
} catch (IOException e) {
e.printStackTrace();
}
if (next.incrementAndGet() == selectors.length) {
next.set(0);
}
}
}
public static void main(String[] args) throws IOException {
MultiThreadEchoServerReactor server = new MultiThreadEchoServerReactor();
server.startService();
}
}
上面是反应器的演进代码,再来看看Handler 处理器的多线程演进实践。
4.3.3 多线程Handler 处理器的实践案例
基于前面的单线程反应器EchoHandler 回显处理器的程序代码,给以改进,新的回显处理器为MultiThreadEchoHandler ,主要是升级是引入了一个线程池(ThreadPool ),业务处理的代码执行在自己的线程池中,做到业务处理线程和反应器IO事件线程的完全隔离 ,这个实践案例代码如下 。
class MultiThreadEchoHandler implements Runnable {
final SocketChannel channel;
final SelectionKey sk;
final ByteBuffer byteBuffer = ByteBuffer.allocate(1024);
static final int RECIEVING = 0, SENDING = 1;
int state = RECIEVING;
//引入线程池
static ExecutorService pool = Executors.newFixedThreadPool(4);
MultiThreadEchoHandler(Selector selector, SocketChannel c) throws IOException {
channel = c;
c.configureBlocking(false);
//仅仅取得选择键,后设置感兴趣的IO事件
sk = channel.register(selector, 0);
//将本Handler作为sk选择键的附件,方便事件dispatch
sk.attach(this);
sk.interestOps(SelectionKey.OP_READ); //向sk选择键注册Read就绪事件
selector.wakeup();
}
public void run() {
//异步任务,在独立的线程池中执行
pool.execute(new AsyncTask());
}
//异步任务,不在Reactor线程中执行
public synchronized void asyncRun() {
try {
if (state == SENDING) {
//写入通道
channel.write(byteBuffer);
//写完后,准备开始从通道读,byteBuffer切换成写模式
byteBuffer.clear();
//写完后,注册read就绪事件
sk.interestOps(SelectionKey.OP_READ);
//写完后,进入接收的状态
state = RECIEVING;
} else if (state == RECIEVING) {
//从通道读
int length = 0;
while ((length = channel.read(byteBuffer)) > 0) {
Logger.info(new String(byteBuffer.array(), 0, length));
}
//读完后,准备开始写入通道,byteBuffer切换成读模式
byteBuffer.flip();
//读完后,注册write就绪事件
sk.interestOps(SelectionKey.OP_WRITE);
//读完后,进入发送的状态
state = SENDING;
}
//处理结束了, 这里不能关闭select key,需要重复使用
//sk.cancel();
} catch (IOException ex) {
ex.printStackTrace();
}
}
class AsyncTask implements Runnable {
public void run() {
MultiThreadEchoHandler.this.asyncRun();
}
}
}
代码中设计了一个内部类AsyncTask ,是一个简单的异步任务的提交类, 它使得异步业务asyncRun()方法,可以独立的提交到线程池中, 另外,既然业务处理异步执行,需要在asyncRun()方法的前面加上synchronized同步修饰符。
至此,多线程版本的反应器模式,实践案例的代码就演示完了, 执行新版本的多线程MultiThreadEchoServerReactor 服务器,可以使用之前的EchoClient客户端与之配置, 完成整个回显(echo) 的通信演示。
4.4 Reactor 反应器模式小结
1. 反应器模式和生产者消费者模式对比
相似之处,在一定程度上,反应器模式有点类似于生产者消费者模式,在生产者和消费者模式中, 一个或多个生产者将事件加入到一个队列中, 一个或多个消费者主动地从这个队列中提出(Pull)事件来处理。
不同之处在于,反应器模式是基于查询的, 没有专门的队列去缓冲存储IO事件,查询到IO事件之后,反应器会根据不同的IO 选择键(事件 ) 将其分发给对应的Handler 处理器来处理。
2. 反应器模式和观察者模式(Observer Pattern) 对比
相似之外:在于反应器模式中,当查询到IO事件后,服务处理程序使用单路/多路分发(Dispatch)策略,同步的分发这些IO事件,观察者模式(Observer Pattern) 也称为发布/订阅模式,它定义了一种依赖关系,让多个观察者同时监听某一处主题 (Topic) ,这个主题对象的状态发生变化时, 会通知所有的观察者,它们能够执行相应的处理。
不同之外在于,在反应器模式中, Handler处理器实例和IO事件 (选择键) 的订阅关系,基本上是一个事件绑定到一个Handler处理器,每一个IO 事件 (选择键)被查询后,反应器会将事件分发给所绑定的Handler处理器,而在观察者模式中,同一个时刻,同一个主题 可以被订阅过多个观察者处理。
最后,总结一下反应器模式的优点和缺点,作为高性能的IO模式,反应器模式的优点如下:
- 响应快,虽然同一反应器线程本身是同步的,但不会被单个连接的同步 IO所阻塞 。
- 编程相对简单,最大程序的避免了复杂的多线程同步,也避免了多线程的各个进行之间的切换开销。
- 可扩展,可以方便的通过增加反应器线程的个数来充分利用CPU资源 。
反应器模式的缺点如下 :
- 反应器模式增加了一定的复杂性,因而有一定的门槛,并且不易于调试
- 反应器模式需要操作系统底层的IO 多路复用,反应器模式不会有那么高效。
- 同一个Handler的业务线程中,如果出现一个长时间的数据读写,会影响这个反应器中其他的通道的IO 处理,例如,在大文件传输时,IO操作就会影响其他客户端(Client) 的响应时间,因而对于这种操作,还需要进一步对反应器模式进行改进 。
/**
* 之前提到,和Guava的FutureCallback一样,Netty新增加了一相接口来封装异步非阻塞的回调的逻辑中,它就是GenericFutureListener接口。
*/
public interface GenericFutureListener<F extends Future<?>> extends EventListener {
// 监听器的回调方法
// GenericFutureListener拥有一个回调方法,operationComplete,表示异步任务操作完成,在Future异步任务执行完后,将回调此方法,
// 在大多数情况下,Netty 的异步回调代码编写在GenericFutureListener 接口的实现类的operationComplete方法中。
// 说明一下,GenericFutureListener 的父接口EventListener 是一个空接口, 没有任何的抽象方法,是一个仅仅具有标识作用的接口。
void operationComplete(F future) throws Exception;
}
5.5.2 详解Netty的Future接口
Netty也对Java的Future接口进行了扩展, 并且名称没有变,也还是叫作Future接口,代码实现位于 io.netty.util.concurrent包中。
和Guava的ListenableFuture一样,Netty 的Future接口,扩展了一系列的方法,对执行过程进行了监听 ,对异步回调完成的事件进行了监听(Listen),Netty的Future接口的源代码如下 :
// Netty 也对Java Future 接口进行了扩展,并且名称没有变,还是叫Future接口, 代码实现位于 io.netty.util.concurrent包中
public interface Future<V> extends java.util.concurrent.Future<V> {
/**
* successfully.
* 判断异步执行是否成功
*/
boolean isSuccess();
/**
* 判断异步执行是否取消
*/
boolean isCancellable();
/**
* 获取异步任务异步的原因
*/
Throwable cause();
/**
* 增加了异步任务执行完成与否的监听器Listener
*/
Future<V> addListener(GenericFutureListener<? extends Future<? super V>> listener);
Future<V> addListeners(GenericFutureListener<? extends Future<? super V>>... listeners);
/**
* 移除异步任务执行完成与否的监听器Listener
*/
Future<V> removeListener(GenericFutureListener<? extends Future<? super V>> listener);
Future<V> removeListeners(GenericFutureListener<? extends Future<? super V>>... listeners);
Future<V> sync() throws InterruptedException;
Future<V> syncUninterruptibly();
Future<V> await() throws InterruptedException;
Future<V> awaitUninterruptibly();
}
Netty的Future接口一般不会直接使用,而是会使用子接口,Netty有一系列的子接口,代表不同的类型的异步任务,如ChannelFuture接口 。
ChannelFuture子接口表示通道的IO 操作异步任务,如果在通道的异步IO 操作完后,需要执行回调操作,就需要使用ChannelFuture接口。
5.5.3 ChannelFuture的使用
在Netty 的网络编程中, 网络连接通道的输入和输出处理都是异步进行的,都会返回一个ChannelFuture接口的实例,通过返回的异步任务实例,可以为它增加异步回调的监听器, 在异步任务真正的完成后,回调才会执行。
Netty的网络连接异步回调,实例代码如下:
// connect 是异步的,仅提交异步任务
ChannelFuture future = bootstrap.connect(new InetSocketAddress(“www.manning.com”,80));
// connect 的异步任务真正的执行完成后,future回调监听器才会执行
future.addListener(new ChannelFutureListener(){
@Overide
public void operationComplete(ChannelFuture channelFuture) throws Exception{
if(channelFuture.isSuccess()){
System.out.println(“connection established”);
}else {
System.out.println(“Connection attempt failed”);
channelFuture.cause().printStackTrace();
}
}
})
GenericFutureListener接口在Netty中是一个基础类型的接口,在网络编程的异步回调中,一般使用Netty中提供的某个子接口,如ChannelFutureListener接口,上面的代码使用这个子接口。
5.5.4 Netty出站和入站异步回调
Netty出站和入站操作都是异步的,异步回调方法,和上面的Netty 建立异步回调是一样的 。
以最经典的NIO出站操作,write为例,说明一下ChannelFuture的使用。
在调用write操作后,Netty 并没有完成对Java NIO 底层连接的写入操作,因为是异步执行代码如下 :
// write 输出方法,返回的是一个异步的任务
ChannelFuture future = ctx.channel.write(msg);
// 为异步任务,加上监听器
future.addListener(new ChannelFutureListener(){
public void operationComplete(ChannelFuture future) {
// write 操作完成后的回调代码
}
})
在调用write操作后,是立即返回,返回的是一个ChannelFuture接口的实例, 通过这个实例,可以绑定异步回调监听器, 这里的异步回调逻辑需要我们编写 。
如果大家运行以上EchoServer 实践案例,就会发现一个很大的问题,客户端接收到回显信息和发送到服务器的信息,不是一一对应的输出的, 看到比较多的情况,客户端发出很多次信息后,客户端才收到一次服务器的回显。
这是什么原因呢? 这就是网络通信中的粘包/半包问题,对于 这个问题的解决,在后面做了非常详细的解答,这里暂时搁置粘包/半包的问题出现,说明了一个问题,仅仅基于Java 的NIO 开发一套高性能的,没有Bug 的通信服务器程序,远远没有大家想像得简单,有一系列的坑, 一大堆的问题需要解决。
在进行大型的Java 通信程序的开发时, 尽量基于一些实现了成熟的,稳定的基础通信的Java 开源中间件(如Netty) ,这些中间件已经帮助大家解决了很多的基础问题, 如前面出现的粘包,半包问题。
至此,大家已经学习了Java NIO , Reactor 反应器模式,Future模式,这些都是学习Netty 用开发的基础,基础知识已经铺垫得差不多了,接下来,正式进入Netty 的学习阶段 。
第6章
Netty原理和基础
首先引用Netty 官网的内容对Netty 进行一个正式的介绍 。
Netty是为了快速开发可维护的高怪胎,高可扩展,网络服务器和客户端程序而提供的异步事件鸡翅基础框架和工具,换句话说,Netty 是一个Java NIO客户端/服务器框架,基于Netty ,可以快速轻松的开发网络服务器和客户端应用程序,与直接使用Java NIO 相比,Netty 给大家造出来的轮子更加优美,它可在大大的简化网络编程流程,例如,Netty 极大的简化了TCP ,UDP 套接字,HTTP WEB服务器程序开发 。
Netty 目标之一,是要使用开发可以做到快速的和轻松, 除了做到快速和轻松的开发TCP/UDP 等自定义的协议的通信程序之外,Netty 经过精心设计,还可以做到快速和轻松的开发应用层协议的程序,如FTP ,SMTP ,HTTP 以及其他传统应用层协议 。
Netty 的目标之二,是要做到高可扩展性, 基于Java 的NIO ,Netty 设计了一套优秀的的Reactor 反应器模式,后面会详细的介绍Netty 中的反应器模式的实现,是基于Netty 反应器模式实现中的Channel(通道 ),Handler(处理器)等基类,能快速的扩展以覆盖不同的协议,完成不同的业务处理的大量应用类。
public class NettyDiscardServer {
private final int serverPort = 8080;
ServerBootstrap b = new ServerBootstrap();
public NettyDiscardServer(int port) {
this.serverPort = port;
}
public void runServer() {
//创建reactor 线程组
EventLoopGroup bossLoopGroup = new NioEventLoopGroup(1);
EventLoopGroup workerLoopGroup = new NioEventLoopGroup();
try {
//1 设置reactor 线程组
b.group(bossLoopGroup, workerLoopGroup);
//2 设置nio类型的channel
b.channel(NioServerSocketChannel.class);
//3 设置监听端口
b.localAddress(serverPort);
//4 设置通道的参数
b.option(ChannelOption.SO_KEEPALIVE, true);
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
b.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
//5 装配子通道流水线
b.childHandler(new ChannelInitializer<SocketChannel>() {
//有连接到达时会创建一个channel
protected void initChannel(SocketChannel ch) throws Exception {
// pipeline管理子通道channel中的Handler
// 向子channel流水线添加一个handler处理器
ch.pipeline().addLast(new NettyDiscardHandler());
}
});
// 6 开始绑定server
// 通过调用sync同步方法阻塞直到绑定成功
ChannelFuture channelFuture = b.bind().sync();
Logger.info(" 服务器启动成功,监听端口: " + channelFuture.channel().localAddress());
// 7 等待通道关闭的异步任务结束
// 服务监听通道会一直等待通道关闭的异步任务结束
ChannelFuture closeFuture = channelFuture.channel().closeFuture();
closeFuture.sync();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 8 优雅关闭EventLoopGroup,
// 释放掉所有资源包括创建的线程
workerLoopGroup.shutdownGracefully();
bossLoopGroup.shutdownGracefully();
}
}
public static void main(String[] args) throws InterruptedException {
new NettyDiscardServer(8080).runServer();
}
}
如果是第一次开发Netty程序,上面的代码看得不懂,因为代码里边涉及很多的Netty组件 。
Netty是基于反应器模式实现的,还好,大家已经非常深入的了解了反应器模式,现在大家顺藤摸瓜学习Netty 就相对简单了。
首先要说的是Reactor 反应器,前面讲到,反应器的作用是进行一个IO事件的select查询和dispatch分发,Netty 中对应的反应器组件有多种,应用场景的不同,用到的反应器各不相同,一般来说,对应于多线程的Java NIO 通信的应用场景,Netty 的反应类型为NioEventLoopGroup 。
在上面的例子中, 使用了两个NioEventLoopGroup实例,每一个通常被称为“包工头” ,负责服务器通道新连接的IO事件监听,第二个通常被称为 “工人” , 主要负责传输通道的IO 事件处理。
其次要说的是Handler 处理器(也称为处理程序),Handler 处理器的作用是对应于IO事件,实现IO 事件的业务处理,Handler 处理器需要专门开发,稍后,将专门的对它进行介绍 。
再次,在上面的例子中,还用到了Netty 服务器启动类ServerBootstrap,它的职责是组装和集成器,将不同的Netty组件组装在一起, 另外,ServerBootstrap能够按照应用场景的需要,为组件设置好对应的参数,最后,实现Netty服务器的监听和启动,服务器类ServerBootstrap 也是本章重点之一,稍后,一小节进行详细的介绍 。
6.1.3 业务处理器NettyDiscardHandler
在反应器(Reactor)模式中,所有的业务处理都在Handler 处理器中完成,这里编写了一个新类NettyDiscardHandler,NettyDiscardHandler的业务处理很简单,把收到的任何内容直接丢弃(disacard) ,也不会回复任何消息。
public class NettyDiscardHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ByteBuf in = (ByteBuf) msg;
try {
Logger.info("收到消息,丢弃如下:");
while (in.isReadable()) {
System.out.print((char) in.readByte());
}
System.out.println();
} finally {
ReferenceCountUtil.release(msg);
}
}
}
首先说明一下,这里将引入一个新的概念,入站和出站,简单的来说,入站是指输入,出站指的是输出,后面也会有详细的介绍 。
Netty 的Handler 处理器需要处理多种IO 事件 。
Netty 的Handler 处理器需要处理多种IO 事件 (可读,可写),对应于不同的IO事件,Netty 提供了一些基础的方法,这些方法都已经提前封装好,后面直接继承或者实现即可, 比如,对应于处理入站的IO事件的方法,对应的接口为ChannelInBoundHandler 入站处理接口,而ChannelInboundHandlerAdapter 则是Netty 提供的入站处理的默认实现。
也就是说,如果要实现自己的入站处理器Handler ,只要继承ChannelInBoundHandlerAdapter入站处理器,再写入自己的入站处理的业务逻辑,如果要读取入站数据,只需要写入到入站处理方法ChannelRead中即可。
在上面的例子中channelRead 方法,它读取了Netty 的输入数据缓冲区ByteBuf ,Netty 中的ByteBuf 可以对应到前面的介绍的NIO 的数据缓冲区,它们的功能上是类似的,不过相对而言,Netty 的版本性能更好,但用也更加方便 。
6.1.4 运行NettyDiscardServer
在上面的例子中,出现了Netty 中各种组件,服务器启动,缓冲区,反应器,Handler 业务处理器,Future异步任务监听,数据传输通道等,这些Netty 组件都是需要掌握的 。
6.2 解密Netty 中的Reactor 反应器模式
6.2.1 回顾Reactor 反应器模式中IO事件处理流程
一个IO 事件从操作系统底层产生后,在Reactor 反应器模式中的处理流程如图6-1所示 。
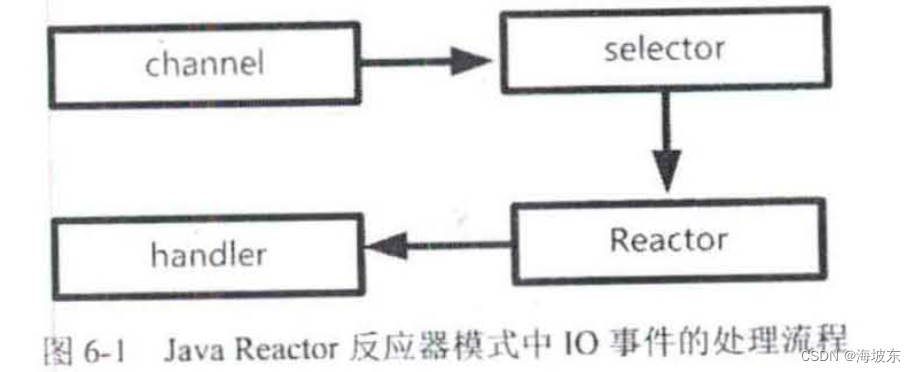
整个流程大致分为4步,具体如下 。
第一步:通道注册,IO源于通道(Channel) ,IO是和通道(对应于底层连接而言)强相关的, 一个IO事件,一定属于某个通道,但是,如果要查询通道的事件,首先要将通道注册到选择器上,只需要通道提前注册到Selector选择器即可, IO 事件会被选择器查询到。
第二步,查询选择器,在反应器模式中, 一个反应器(或者SubReactor子反应器)会负责一个线程,不断的轮询,查询选择器中的IO 事件(选择键) 。
第3步,事件分发,如果查询到IO事件,则分发给IO事件绑定关系的Handler 业务处理器。
第4步, 完成真正的IO 操作和业务处理, 这一步由Handler 业务处理器负责 。
以上4步,就是整个反应器模式的IO 处理流程, 其中 ,第1步和第2步,其实就是Java NIO 的功能,反应器模式仅仅是利用了Java NIO 的优势而已。
6.2.2 Netty 中的Channel通道组件
Channel通道组件是Netty 非常重要的组件,为什么首先要说的是Channel 通道组件呢?原因是,反应器模式和通道紧密相关,反应器查询和分发的IO事件来自于Channel 通道组件 。
Netty 中不直接使用Java NIO的Channel 通道组件,对Channel通道组件进行了自己的封装, 在Netty中,有一系列的Channel 通道组件,为了支持多种通信协议 , 换句话说,对于每一种通信连接协议,Netty 都实现了自己的通道 。
另外一点就是,除了Java NIO ,Netty 还能处理Java 的面向流的OIO(即传统的阻塞IO) 。
总结起来,Netty 中每一种协议的通道,都有NIO (异步IO)和OIO (阻塞式IO) 两个版本,对应于不同的协议,Netty 常见的通道类型如下 。
对应于不同的协议,Netty中常见的通道类型如下 。
- NioSocketChannel : 异步非阻塞TCP Socket传输通道 。
- NioServerSocketChannel: 异步非阻塞TCP Socket 服务器监听通道 。
- NioDatagramChannel : 异步非阻塞UDP传输通道 。
- NioSctpChannel : 异步非阻塞Sctp传输通道 。
- NioSctpServerChannel: 异步非阻塞Sctp 服务器端监听通道 。
- OioSocketChannel :同步阻塞式TCP Socket 传输通道 。
- OioServerSocketChannel : 同步阻塞式TCP Socket 服务器端监听通道 。
- OioDatagramChannel: 同步阻塞式UDP 传输通道 。
- OioSctpChannel :同步阻塞式Sctp 传输通道 。
- OioSctpServerChannel :同步阻塞式Sctp 服务器端监听通道 。
一般来说,服务器端编程用到最多的通信协议还是TCP 协议,对应的传输通道类型是NioSocketChannel类,服务器监听类为NioServerSocketChannel ,在主要使用的方法上,其他的通道类型和这个NioSocketChannel 类在原理上基本是相通的 。
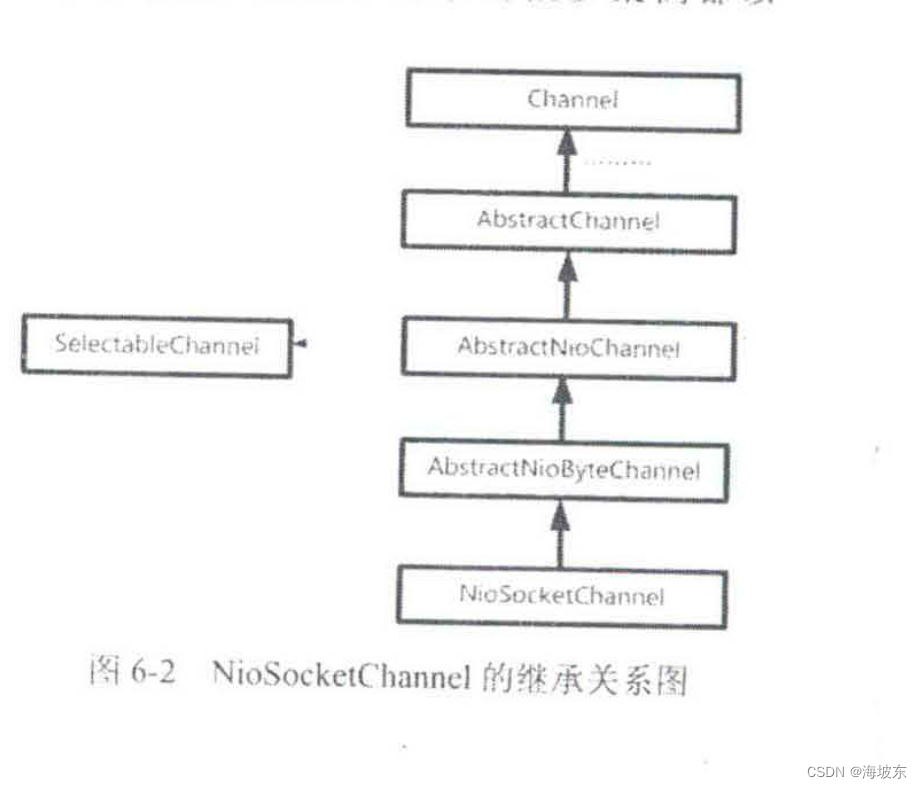
在Netty的NIoSocketChannel内部封装了一个Java NIO 的SelectableChannel成员,通过这个内部的Java NIO 通道,Netty 的NioSocketChannel通道上的IO操作,最终会落到Java NIO 的SelectableChannel底层通道,NioSocketChannel 的继承关系图,如图6-2所示 。
6.2.3 Netty中的Reactor 反应器
在反应器模式中,一个反应器(或者SubReactor子反应器)会负责一个事件处理线程,不断的轮询,通过Selector 选择器不断的查询注册过的IO 事件 (选择键),如果查询到IO事件,则分发给Handler业务处理器。
Netty中反应器有多个实现类, 与Channel通道类有关系,对于NioSocketChannel 通道的Netty 的返回器类,NioEventLoop 。
NioEventLoop类绑定了两个重要的属性,一个是Thread线程类成员,一个是Java NIO 选择器成员属性,NioEventLoop的继承关系和主要的成员属性,如下图6-3所示 。
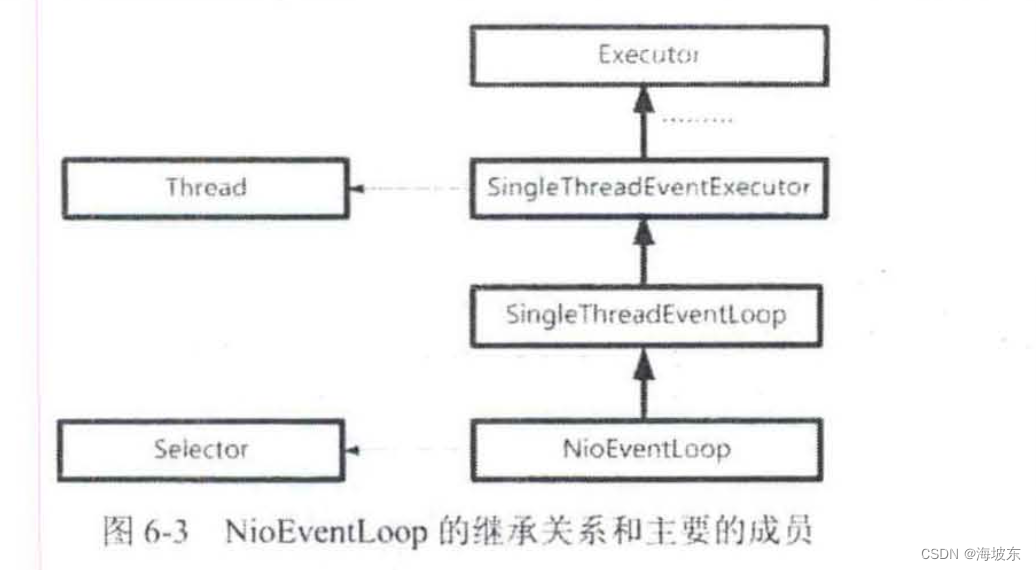
通过这个关系图,可以看出,NioEventLoop 和前面章节讲到的反应器,在思路上是一致的,一个NioEventLoop 拥有一个Thread 线程,负责一个Java NIO Selector选择器的IO事件轮询 。
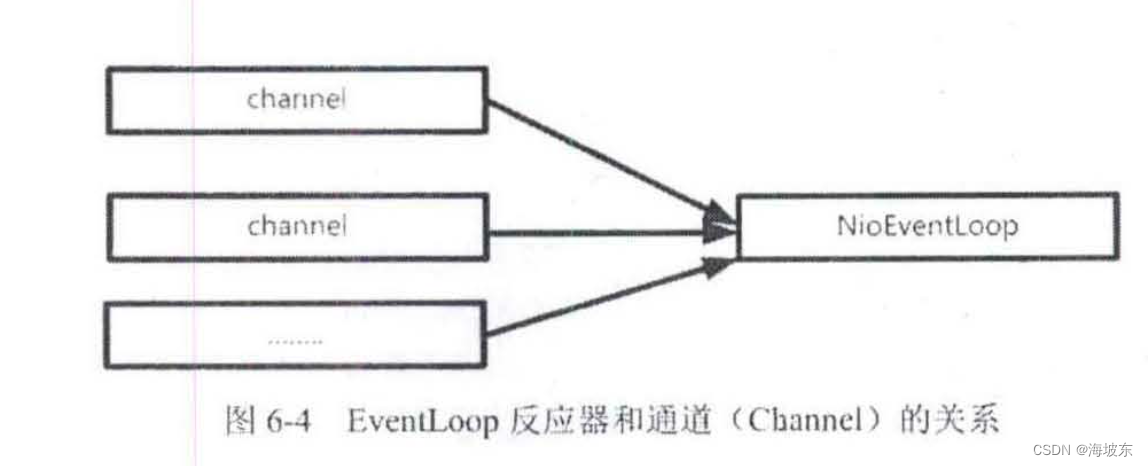
在Netty 中,EventLoop 反应器和Netty Channel 通道,关系如何呢? 理论上来说,一个EventLoopNetty 反应器和NettyChannel通道是一对多的关系,一个反应器可以注册成千上万的通道 。
6.2.4 Netty中的Handler处理器
解读Java NIO 的IO事件类型时讲到,可供选择器监控的通道IO事件类型包括以下4种。
- 可读:SelectionKey.OP_READ
- 可写:SelectionKey.OP_WRITE
- 连接:SelectionKey.OP_CONNECT
- 接收:SelectionKey.OP_ACCEPT
在Netty 中,EventLoop 反应器内部有一个Java NIO选择器成员执行以上事件查询,然后进行对应的事件分发,事件分发(Dispatch)的目标就是Netty 自己的Handler 处理器。
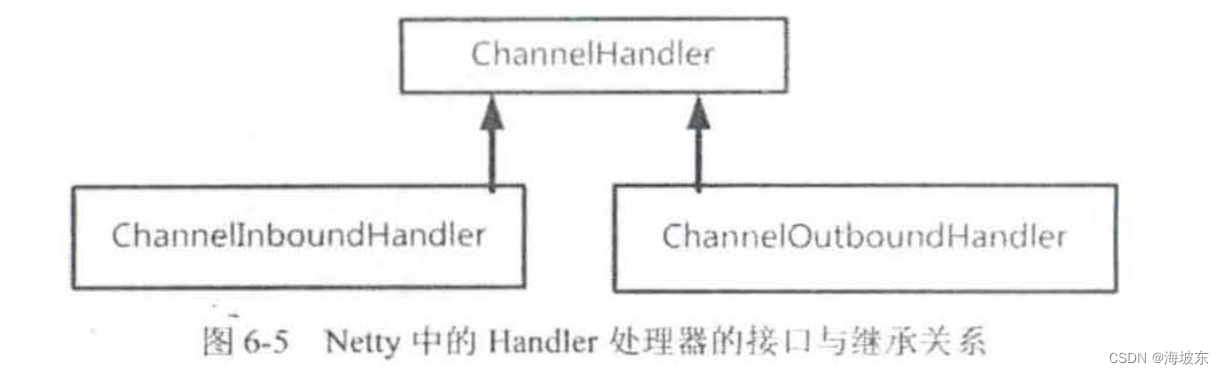
Netty 的Handler 处理器分为两大类, 第一类是ChannelInboundHandler 通道入站处理器,第二类是ChannelOutboundHandler 通道出站处理器,二者都继承了ChannelHandler处理器接口,Netty 的Handler 处理器的接口与继承之间的关系,如图6-5所示 。
Netty中的入站处理,不仅仅是OP_READ输入事件处理,还是从通道底层触发,由Netty通过层层传递,调用ChannelInboundHandler通道入站处理器进行某个处理,以底层的Java NIO 中的OP_READ输入事件为例,在通道中发生了OP_READ事件之后,会被EventLoop 查询到,然后分发给ChannelInboundHandler通道入站处理器,调用它的入站处理方法read, 在ChannelInBoundHandler通道入站处理器。 以底层的Java NIO 中的OP_READ 输入事件为例,在通道中发生了OP_READ事件后,会被EventLoop 查询到,然后分发给ChannelInboundHandler通道入站处理器,调用它的入站处理方法read, 在ChannelInboundHandler通道入站处理内部read方法可以从通道中读取数据 。
Netty中的入站处理器,触发的方向为,从通道到ChannelInboundHandler通道入站处理器。
Netty 中的出站处理,本来就包括Java NIO 的OP_WRITE可写事件,注意,OP_WRITE 可写事件是Java NIO 底层的概念,它和Netty 的出站处理的概念不是一个维度的, Netty 的出站处理是应用层维度的,那么,Netty 中的出站处理,具体指的是什么呢? 指的是从ChannelOutboundHandler通道出站处理器到通道某次IO操作,例如,在应用程序完成业务处理后,可以通过ChannelOutboundHandler 通道出站处理器将处理的结果写入到底层通道,它的最常用的一个方法就是write()方法,把数据写入到通道 。
这两个业务处理接口都有各自的默认实现, ChannelInBoundHandler 的默认实现为ChannelInboundHandlerAdapter,叫作通道入站处理适配器, ChannelOutboundHandler的默认实现为实现了入站操作和出站操作的基本功能,如果要实现自己的业务处理器,不需要从零开始去实现处理接口,只需要继承通道处理适配器即可。
6.2.5 Netty 流水线 (Pipeline)
来梳理一下Netty 的反应器模式中各个组件之间的关系 。
- 反应器(或者SubReactor子反应器)和通道之间是一对多的关系,一个反应器可以查询很多的通道的IO事件 。
- 通道和Handler 处理器实例之间,是多对多的关系,一个通道的IO事件被多个Handler 实例处理,一个Handler 处理器实例也能绑定到很多的通道,处理多个通道的IO事件 。
问题是,通道和Handler 处理器实例之间的绑定关系,Netty是如何组织的呢?
Netty设计了一个特殊的组件,叫作ChannelPipeline(通道流水线),它像一条通道,绑定到一个通道的多个Handler 处理器实例,串在一起,形成一条流水线,ChannelPipeline(通道流水线)默认实现,实际上被设计成一个双向链表,所有的Handler处理器实例被包装成了双向链表节点,被加入到ChannelPipeline(通道流水线中) 。
重点申明,一个Netty 通道拥有一条Handler 处理器流水线,成员的名称叫作pipeline。
问题来了,这里为什么将Pipeline翻译成流水线呢? 而不是翻译成管道呢?还有原因是,具体来说,与流水线内部的Handler 处理器之间处理IO事件的先后顺序有关。
以入站处理为例,每一个来自通道的IO事件,都会进入一次ChannelPipeline通道流水线,在进入第一个Handler 处理器后,这个IO事件将按照既定的从前往后次数,在流水线 中不断的向后流动,流向下一个Handler 处理器。
在向后流动的过程中, 会出现3种情况:
- 如果后面还有其他的Handler 入站处理器, 那么IO事件可以交给下一个Handler 处理器向后流动。
- 如果后面没有其他的入站处理器,这就意味着这个IO事件在此次流水线中的处理结束了。
- 如果在流水线中间需要终止流动,可以选择不同的IO事件交给下一个Handler处理器,流水线的执行也被终止了。
为什么说Handler 的处理是按照既定的次序,而不是从前到后的次序呢?Netty 是这样规定的,入站处理器Handler执行次序,从前到后,出站处理器Handler的执行次序,是从后到前, 总之,IO事件在流水线上的执行次序,与IO 事件的类型是有关的,如图6-6所示 。
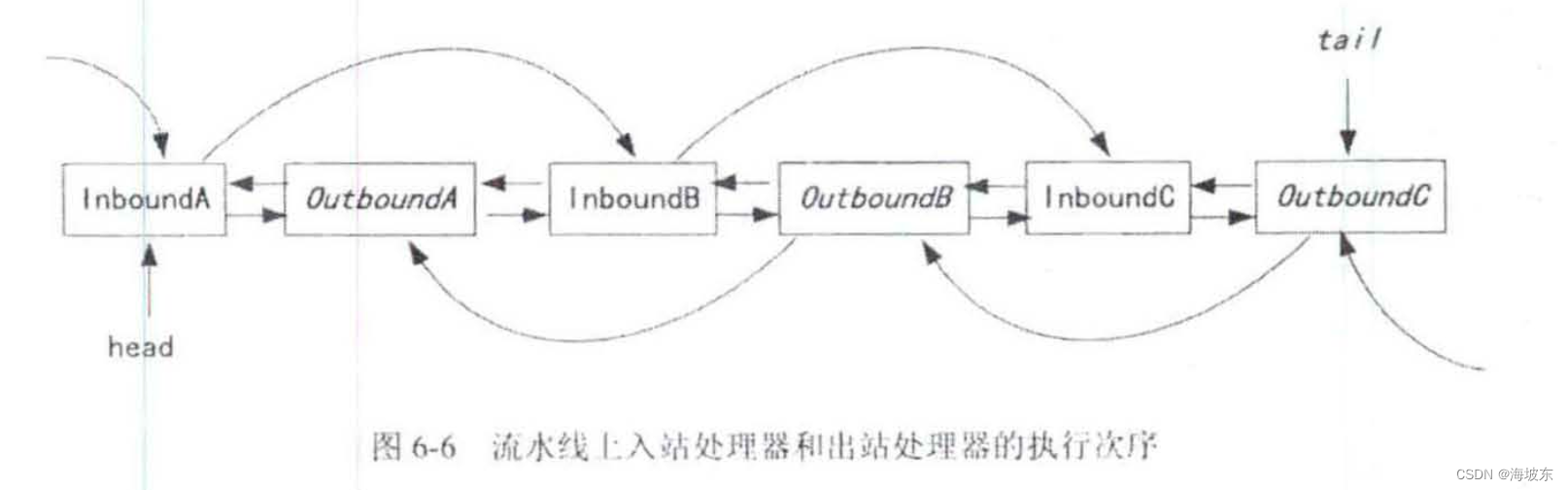
除了流动的方向与IO 操作的类型有关之外,流动过程中经过处理器节点的类型,也是与IO操作的类型有关, 入站的IO 操作只会且只能从Inbound入站处理器类型的Handler 流过,出站的IO操作只会且只能从Outbound出站处理器类型的Handler流过。
总之,流水线是通道的大管家,为通道管理好它的一大堆"Handler小弟" 。
了解完流水线之后,大家应该对Netty中的通道,EventLoop 反应器,Handler处理器,以及三者之间的协作关系,有了一个清晰的认知和了解,至此,大家基本上可以动手开发简单的Netty 程序了,不过,为了方便开发者开发,Netty 提供了一个类把上面的三个组件快速的组装起来,这个系统类叫Bootstrap启动类,严格的来说,不止一个类名字为Bootstrap,例如,服务器端的启动类叫作ServerBootstrap类。
6.3 详解Bootstrap启动器类
Bootstrap 类是Netty 提供了一个使得的工厂类,可以通过它来完成Netty 的客户端或者服务器端的Netty组装,以及Netty 程序的初始化,当然Netty 的官方解释是,完全可以不用这个Bootstrap启动类,但是,一点点的手动去创建通道,完成各种设置和启动,并且注册到EventLoop这个过程非常麻烦,通常情况下,还是使用这个使得的Bootstrap工具类会效率更高。
Netty中,有两个启动器类,分别用在服务器和客户端,如下图6-7所示 。
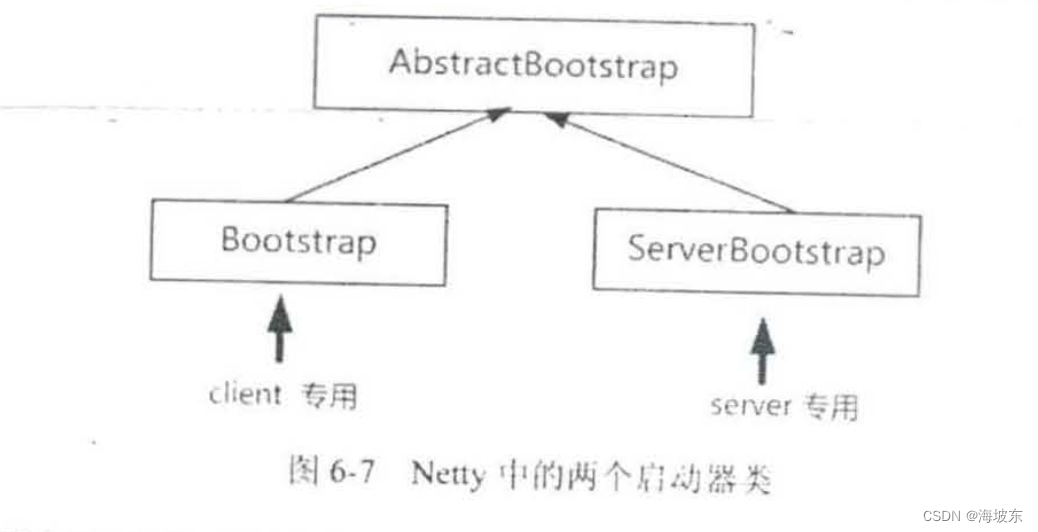
这两个启动器仅仅是使用地方不同,它们大致的配置和使用方法都是相同的,下面以ServerBootstrap 服务器启动类作为重点的介绍对象 。
在介绍ServerBootstrap 的服务器启动流程之前,首先介绍一下,涉及到的两个基本概念,父类通道,EventLoopGroup线程组(事件循环线程组)。
6.3.1 父子通道
在Netty 中,每一个NioSocketchannel 通道所土法的是Java NIO 通道,再往下就是对应的操作系统底层socket描述符,理论上来说,操作系统底层的socket描述符分为两类。
- 连接监听类型,连接监听类型的socket 描述符,放在服务器端,它负责接收客户端的套接字连接,在服务器端,一个连接监听类型,的socket描述符可以接受(Accept ) 成千上万的传输类的socket描述符。
- 传输数据类型,数据传输类的socket描述符负责传输数据,现一条TCP的Socket 传输链路,在服务器和客户端,都分别会有一个与之相应的数据传输类型socket描述符。
在Netty 中,异步非阻塞的服务器端监听通道NioServerSocketChannel ,封装在Linux 底层描述符,是连接监听类型,socket描述符,而NioSocketChannel异步非阻塞TCP Socket 传输通道,封装在底层的Linux描述符,是数据传输类型的socket描述符。
在Netty中,将有接收关系的NioServerSocketChannel和NioSocketChannel ,叫作父子通道,其中,NioServerSocketChannel 负责服务器连接监听和接收,也叫父通道(ParentChannel) , 对应每一个接收到的NioSocketChannle 传输类通道,也叫子通道ChildChannel 。
6.3.2 EventLoopGroup 线程组
Netty 中的Reactor 反应器模式,肯定不是单线程版本的反应器模式,而是多线程版本的反应器模式,Netty 的多线程版本的反应器模式是如何实现的呢?
在Netty 中,一个EventLoop相当于一个子反应器(SubReactor) , 大家已经知道,一个NioEventLoop子反应器拥有一个线程,同时拥有一个Java NIO选择器, Netty 是如何组织外层的反应器的呢? 答案是使用了EventLoopGroup线程组,多个EventLoop线程组成了一个EventLoopGroup线程组。
反过来说,Netty 的EventLoopGroup 线程组就是一个多线程版本的反应器,而其中单EventLoop线程对应于一个子反应器(SubReactor)。
Netty 的程序开发不会直接使用单个EventLoop线程,而是使用EventLoopGroup线程组,EventLoopGroup的构造函数有一个参数,用于指定内部的线程数,在构造器初始化时, 会按照传入的线程数量,在内部构造多个Thread 线程和多个EventLoop子反应器(一个线程对应一个EventLoop子反应器),进行多线程的IO 事件查询和分发。
如果使用了EventLoopGroup的无参数的构造函数,没有传入线程数或者传入的线程数为0 ,那么EventLoopGroup 内部的线程数到底是多少呢?默认的EventLoopGroup的内部线程数为最大可用CPU 处理数量的2倍 ,假设,电脑使用的是4核的CPU, 那么在内部会启动8个EventLoop 线程,相当于8个子反应器(SubReactor)实例。
从前文可知,为了及时接受(Accept) 到新连接,在服务器端,一般有两个独立的反应器,一个反应器负责新连接的监听和接受,另一个反应器负责IO 事件处理,对应到Netty 服务器程序中,则是设置两个EventLoopGroup 线程组,一个EventLoop负责新连接的监听和接受,一个EventLoopGroup负责IO事件的处理。
那么,两个反应器如何分工的呢? 负责新连接的监听和接受EventLoopGroup线程组,查询父通道的IO事件,有点像负责招工的包工头, 因此,可以形象的称为 “包工头”(Boss)线程组, 另一个EventLoopGroup线程组负责查询所有的子通道的IO 事件,并且执行Handler处理器中的业务处理,例如,数据的输入和输出 (有点像搬砖),这个线程组可以形象的称为"工人"(Worker)线程组。
6.3.3 Bootstrap的启动流程
Bootstrap的启动流程,也就是Netty组件的组装,配置, 以及Netty 服务器或者客户端的启动流程,在本节中对启动流程进行了梳理,大致分成8个步骤,本书仅仅演示了是服务器端启动器的使用,用到了启动器类为ServerBootstrap ,正式使用前,首先创建一个服务器端的启动器实例。
// 创建一个服务器端的启动器
ServerBootstrap b = new ServerBootstrap();
接下来,结合前面的NettyDiscardServer服务器的程序代码,给大家详细的介绍一下Bootstrap启动流程中精彩的8人步骤 。
第1步,创建反应器线程组,并赋值给ServerBootstrap 启动器实例。
// 创建反应器线程组
// boss线程组
EventLoopGroup bossLoopGroup = new NioEventLoopGroup(1);
// worker线程组
EventLoopGroup workerLoopGroup = new NioEventLoopGroup();
// 设置反应器线程组
b.group(bossLoopGroup, workerLoopGroup);
在设置反应器线程组之前,创建了两个NioEventLoopGroup线程组,一个负责处理连接监听的IO 事件,名为bossLoopGroup ,另一个负责数据的IO事件和Handler 业务处理,名为workerLoopGroup 。
在线程组创建完之后,就可以配置给启动器实例, 调用的方法是b.group(bossGroup , workerGroup) ,它一次性的给启动器配置了两大线程组。
不一定非得配置两个线程组,可以仅配置一个EventLoopGroup反应器线程组, 具体的配置方法是调用b.group(workerGroup),在这种模式下,连接监听IO 事件和数据传输IO事件可能被挤到在了同一个线程中处理, 这样会带来一定的风险,新连接的接受被更加耗时的数据传输或者业务处理所阻塞 。
在服务器端,建议设置成两个线程组的工作模式 。
第2步,设置通道的IO类型。
Netty 不止支持Java NIO ,也支持阻塞式OIO(也称为BIO,Block-IO,即阻塞式IO) ,下面配置的是Java NIO 类型的通道顾炎武,方法如下 :
// 2 设置NIO 类型的通道
b.channel(NioServerSocketChannel.class);
如果确实需要指定Bootstrap的IO 类型为BIO,那么这里配置上Netty 的OioServerSocketChannel.class类即可, 由于Nio的优势巨大,通常不会在Netty 中使用BIO 。
第3步,设置监听端口
b.localAddress(new InetSocketAddress(port));
第4步,设置传输通道的配置选项
b.option(ChannelOption.SO_KEEPALIVE,true);
b.option(ChannelOption.ALLOCATOR,PooledByteBufAllocator.DEFAULT);
这里用到了Bootstrap的option()选项的设置方法,对于服务器的Bootstrap而言,这个方法的作用是,给父通道(Parent Channel) 接收连接通道设置一些选项。
如果要给子通道(Child Channel) 设置一些通道选项,则需要用另外的childOption()设置方法 。
可以设置哪些通道选项呢(ChannelOption)呢?在上面的代码中, 设置了一个底层的TCP相关的选项ChannelOption.SO_KEEPALIVE,该选项表示,是否开启了TCP底层的心跳机制,true为开启,false为关闭。
第5步,装配子通道的Pipeline流水线
上一节介绍到,每一个通道的子通道,都用一条ChannelPipeline流水线,它的内部有一又向链表,装配流水线的方式是:将业务处理ChannelHandler实例加入到双向链表中。
装配子通道的Handler流水线调用childHandler()方法,传递一个ChannelInitializer通道的初始化类的实例,在父通道成功接收到一个连接 ,并创建成功一个子通道后,就会初始化子通道,这里配置了ChannelInitializer实例就会被调用 。
在ChannelInitalizer通道初始化类的实例中,有一个initChannel()初始化方法,在子通道创建后被执行到,向子通道流水线增加业务处理器。
// 5 装配子通道流水线
b.childHandler(new ChannelInitializer<SocketChannel>(){
// 有一个连接达到会创建一个通道的子通道,并初始化
protected void initChannel(SocketChannel ch) throws Exception(){
// 流水线管理子通道中的Handler业务处理器
// 向通道流水线添加一个Handler 业务处理器
ch.pipeline().addLast(new NettyDiscardHandler());
}
})
为什么仅装配子通道的流水线呢? 而不需要装配父通道的流水线呢? 原因是: 父通道也就是NioServerSocketChannel 连接接受通道,它的内部业务处理是固定的,接受新连接后,创建子通道然后初始化子通道,所以不需要特别的配置,如果需要完成特殊的业务处理,可以使用ServerBootstrap的handler(ChannelHandler handler)方法,为父通道设置ChannelInitializer初始化器。
说明一下,ChannelInitializer处理器有一个泛型参数SocketChannel,它代表需要通道类型,这个类型需要和前面的启动器中设置的通道类型,一一对应起来 。
第6步,开始绑定服务器新连接的监听端口
// 开始绑定端,通过调用sync()同步方法阻塞直到绑定成功
ChannelFuture channelFuture = b.bind().sync() ;
System.out.println(“服务器启动成功,监听端口:” + channelFuture.channel().localAddress());
这个方法很简单,b.bind()方法的功能,返回一个端口绑定Netty 的异步任务channelFuture,在这里,并没有给channelFuture异步任务增加回调监听器,而是阻塞channelFuture异步任务 ,直到端口绑定任务执行完成 。
在Netty中,所有的IO 操作都是异步执行的,这就意味着任何一个IO 操作会立刻返回,在返回的时候,异步任务还没有真正的执行,什么时候执行完成呢? Netty中的IO 操作,都会返回异步任务实例ChannelFuture实例,通过自我阻塞一直到ChannelFuture异步任务执行完成或者 ChannelFuture增加事件监听器两种方式,以获得Netty 中的IO操作真正的结果,上面使用了第一种。 到这里,服务器正式启动。
第7步,自我阻塞,直到通道关闭
// 7 等待通道关闭
// 自我阻塞,直到通道壮志凌云的异步任务结束
ChannelFuture closeFuture = channelFuture.channel().closeFuture() ;
closeFuture.sync();
如果要阻塞的当前线程直到通道关闭,可以使用通道的closeFuture()方法,以获取通道关闭的异步任务,当通道被关闭时, closeFuture实例的sync()方法会返回 。
第8步,关闭EventLoopGroup
Reactor 反应器线程组,同时会关闭内部的subReactor子反应器线程,也会关闭内部的Selector 选择器,内部的轮询线程以及负责查询的所有子通道,在子通道关闭后,会释放掉底层的资源,如TCP Socket文件描述符等。
6.3.4 ChannelOption 通道选项
无论是对于 NioServerSocketChannel父通道类型,还是对于 NioSocketChannel子通道类型,都可以设置一系列的ChannelOption选项,在ChannelOption 类中,定义了一大票通道选项,下面介绍一些常见的选项。
- SO_REVBUF,SO_SNDBUF
此为TCP参数,每个TCP socket(套接字)在内核中都有一个发送缓冲区和一个接收缓冲区,这两个选项就用来设置TCP 连接的两个缓冲区大小的,TCP 的全双工作模式以及TCP滑动容器便 是依赖于这两个独立的缓冲区及其填充的状态 。
- TCP_NODELAY
此为TCP参数,表示立即发送数据,默认值为True(Netty的默认为True,而操作系统默认为False),该值用于设置Nagle算法的启用,该算法将小的碎片数据连接成更大的报文(或数据包),来最小化所发送的报文数量,如果需要发送一些较小的报文,则需要禁用该算法,Netty 默认禁用该算法,从而最小化报文传输的延时。
说明一下,这个参数的值,与是否开启Nagle算法是相反的,设置为true表示关闭,设置为false表示开启,通俗地讲, 如果要求高实时性,有数据发送时就立刻发送,就设置为true,如果需要减少发送次数和减少网络交互次数,就设置为false。
- SO_KEEPALIVE
此为TCP 参数,表示底层的TCP 协议的心跳机制,true为连接保持心跳,默认为false,启用该功能,TCP 会主动探测空闲连接的有效性,可以将此功能视为TCP的心跳机制,需要注意的是,默认的心跳间隔是7200s 即2小时,Netty 默认关闭该功能 。
- SO_REFSEADDR
此为TCP参数,设置为true时表示地址复用,默认值为false,有四种情况需要用到这个参数设置 。
- 当有一个相同的本地地址和端口的socket1处于TIME_WAIT状态时,而我们希望启动程序的socket2要占用该地址和端口,例如在重启服务且保持先前的端口时。
- 有多块网上或用IP Alias技术的机器在同一个端口启动多个进程,但每个进程绑定的本地IP地址不能相同 。
- 单个进程绑定相同的端口到多个socket(套接字)上,但每个socket绑定的IP地址不同 。
- 完全相同的地址和端口重复绑定,但这里只用UDP的多播,不用于TCP 。
- SO_LINGER
此为TCP参数,表示关闭socket的延迟时间,默认值为-1,表示禁用该功能,-1 表示socket.close()方法立即返回,但操作系统底层会将发送到缓冲区全部发送到对端,0 表示socket.close()方法立即返回,操作系统放弃发送缓冲区的数据,操作系统放弃发送缓冲区的数据,直接向对端发送RST包,对端收到复位错误,非0整数值表示调用socket.close()方法的线程被阻塞,直到延迟时间到来,发送缓冲区中的数据发送完毕,若超时,则对端会收到复位错误 。
- SO_BACKLOG
此为TCP参数,表示服务器端接收连接的队列长度,如果队列已满,客户端连接将被拒绝默认值,在Windows中为200,其他操作系统为128 。
- SO_BROADCAST
此为TCP参数,表示设置广播模式 。
6.4 详解Channel 通道
先介绍一下,在使用Channel 通道的过程中所涉及的主要成员方法,然后,为大家介绍一下Netty 所提供的一个专门的单元测试通道–EmbeddedChannel(嵌入式通道)。
6.4.1 Channel通道的主要成员和方法
在Netty中,通道是其中的一个核心的概念之一,代表着网络连接,通道是通信的主题,由它负责同对端进行网络通信,可以写入数据到对端,也可以从对端读取数据 。
protected AbstractChannel(Channel parent) {
this.parent = parent; // 父通道
id = newId();
unsafe = newUnsafe(); // 底层的NIO通道,完成的实际的IO操作
pipeline = newChannelPipeline(); // 一条通道,拥有一条流水线
}
AbstractChannel内部有一个pipeline属性,表示处理器的流水线,Netty 在对通道进行初始化的时候,将pipeline属性初始化为DefaultChannelPipeline的实例, 这段代码也表明,每个通道拥有一条ChannelPipeline处理器流水线 。
AbstractChannel内部有一个parent属性,表示通道的父通道,对于连接监听通道(如NIOServerSocketChannel实例)来说,其父亲通道为null,而对于每一条传输通道(如NioSocketChannel实例),其parent属性的值为接收到该连接的服务器连接监听通道 。
几乎所有的通道实现类都继承了AbstractChannel抽象类,都拥有上面的parent和pipeline两个属性成员。
再来看一下,在通道接口中所定义的几个重要的方法 。
方法1,ChannelFuture connect(SocketAddress address);
此方法的作用为:连接远程服务器,方法的参数为远程服务器地址,调用后会立即返回,返回值为负责连接操作的异步任务ChannelFuture,此方法在客户端的传输通道中使用。
方法2,ChannelFuture bind(SocketAddress address)
此方法的作用为,连接远程服务器,方法的参数为远程服务器地址,调用后会立即返回,返回值为负责连接操作的异步任务ChannelFuture,此方法在客户端传输通道中使用。
方法3,ChannelFuture close()
此方法的作用为:关闭通道连接,返回连接关闭的ChannelFuture异步任务,如果需要在连接正式关闭后执行其他操作,则需要为异步任务设置回调方法,或者调用ChannelFuture异步任务sync()方法来阻塞当前线程,一直等到通道关闭的异步任务执行完毕 。
方法4,channel read()
此方法的作用为,读取通道数据,并且启动入站处理,具体来说,内部的Java NIO Channel通道读取数据,然后启动内部的Pipeline流水线,开启数据读取的入站处理, 此方法的返回通道自身用于链式调用 。
方法5 ChannelFuture write(Object o )
此方法的作用为,启程出站流水线处理, 把处理后的最终数据写到底层Java NIO 通道 , 此方法的返回值为出站处理异步处理任务 。
方法6 Channel flush()
此方法的作用为,将缓冲区中的数据立即写出到对端,并不是每一次write操作都是将数据直接写出到对端,write操作的作用在大部分情况下仅仅是写入到操作系统缓冲区,操作系统将会根据缓冲区的情况,决定什么时候把数据写到对端,而执行flush()方法方始将缓冲区的数据写到对端 。
上面的6种方法 ,仅仅是比较常见的方法,在Channel 接口中以及各种通道的实例同中,还定义了大量的通道操作方法 , 在一般的日常开发中在,如果需要用到,请直接查询 Netty API 文档或Netty 源代码 。
6.4.2 EmbeddedChannel 嵌入式通道
在Netty 的实际开发中,通道的基础工作,Netty 已经替大家完成 ,实际上, 大量的工作是设计和开发ChannelHandler 通道业务处理器,而不是开发Outbound出站处理器, 换句话说就是开发Inbound入站处理器,开发完成后,需要投入单元测试,单元测试的大致流程是,需要将Handler业务处理器加入到通道的Pipeline流水线中,接下来,先后启动Netty 服务器,客户端程序,相互发送消息,测试业务处理器的效果,如果每开发一个业务处理器都需要进行服务器和客户端的重复启动,整个过程是非常烦琐和浪费时间的, 如何解决这种徒劳的,低效率的重复工作呢?
Netty提供了一个专用的通道,名字叫EmbeddedChannel 嵌入式通道 。
EmbeddedChannel仅仅是 模拟入站与出站的操作,底层不进行实际的传输,不需要启动Netty服务器和客户端,除了不进行传输之外,EmbeddedChannel 的其他的事件机制和处理流程和真正的传输通道是一模一样的,因此,使用它, 开发人员可以在开发过程中方便,快速的进行ChannelHandler业务处理器单元测试 。
为了模拟数据的发送和接收 , EmbeddedChannel提供了一组专门的方法 , 具体如下所示 。
| 名称 | 说明 |
|---|---|
| writeInbound(…) | 向通道写入inbound入站数据,模拟通道收到的数据,也就是说,这些写入的数据会被流水线上的入站处理器处理。 |
| readInbound(…) | 从EmbeddedChannel 中读取入站数据,返回经过流水线最后一个入站处理器处理完成之后的入站数据,如果没有数据,则返回null |
| writeOutbound(…) | 向通道写入outbound出站数据,模拟通道发送的数据,也就是说,这些写入的数据会被流水线上的出站处理器处理 |
| readOutbound(…) | 从EmbeddedChannel 中读取出站数据,返回经过流水线最后一个出站处理器处理之后 的出站数据,如果没有数据,则返回null |
| finished() | 结束EmbeddedChannel,它会调用通道的close()方法 |
最为重要的两个方法 , writeInbound 和readOutbound()方法 。
方法1 writeInbound入站数据写到通道 ,它的使用场景是,测试入站处理器,在测试入站处理器时(例如测试,一个解码器),需要读取Inbound(入站)数据,可以调用writeInbound()方法,向EmbeddedChannel写入一个入站二进制ByteBuf 数据包, 模拟底层的入站包。
方法2 readOutbound读取通道的出站数据
它的使用场景是, 测试出站处理器,在测试出站处理器时(例如测试一个编码器),需要查看处理过的结果数据,可以调用readOutbound方法,读取通道的最终出站结果,它是经过流水线一系列的出站处理后,最后的出站数据包, 比较绕口,重复一遍,通过readOutbound,可以读取完成EmbeddedChannel最后一个出站处理器,处理ByteBuf 二进制包。
总之, 这个EmbeddedChannel 类,既具备通道的通用接口和方法 , 又增加了一些单元测试的辅助方法 , 在开发时是非常有用的, 它的具体方法 ,后面还会结合其他的Netty 组件的实例反复提到 。
6.5 详解Handler业务处理
在Reactor反应器经典的模型中,反应器查询到IO事件后,分发到Handler业务处理器,由Handler IO 操作和业务处理 。
整个IO 处理操作环境包括,从通道读数据包,数据包解码,业务处理, 目标数据编码,把数据包写到通道,然后由通道发送到对端,如图6-8所示 。
前后两个环节,从通道读取数据包和由通道发送到对端,由Netty 底层负责完成,不需要用户程序负责 。

用户程序主要在Handler 业务处理中,Handler涉及的环节为,数据包解码,业务处理,目标数据编码,把数据包写到通道中。
前面已经介绍过, 从应用程序开发人员的角度上来看,有入站和出站两种类型的操作。
- 入站处理,触发的方向为,自底向上,Netty的内部(如通道)到ChannelInboundHandler 入站处理器。
- 出站处理器,触发的方向为 ,自顶向下,从ChannelOutboundHandler出站处理器到Netty 内部如通道 。
按照这种方向来分,前面的数据包解码,业务处理两个环节,属于入站处理器的工作,后面目标数据编码,把数据包写到通道中两个环节,属于出站处理的工作 。
6.5.1 ChannelInboundHandler 通道入站处理器
当数据或信息入站到Netty 通道时, Netty 将触发入站入理器ChannelInboundHandler 所对应的入站API ,进行入站操作处理。
ChannelInboundHandler的主要操作,如图6-9所示 ,具体的介绍如下:
- channelRegistered
当通道注册完成后,Netty 会调用fireChannelRegistered,触发通道的注册事件,通道会启动该入站操作的流水线处理,在通道注册过的入站处理器Handler和channelRegistered方法,会被调用到。
- channelActive
当通道激活完成后,Netty 会调用fireChannelActive,触发通道的激活事件,通道会启动该入站操作的流水线处理,在通道注册过的入站处理器Handler的channelActive方法,会被调用到。
- 当channelRead
当通道缓冲区可读,Netty 会调用fireChannelRead ,触发通道可读事件,通道会启动该入站操作的流水线处理,在通道注册过的入站处理器Handler的channelRead方法,会被调用到。
- channelReadComplete
当通道缓冲区读完,Netty 会调用fireChannelReadComplete ,触发通道读取完事件,通道会启动入站操作的流水线处理,在通道注册过的入站处理器Handler 的channelReadComplete方法,会被调用到。
- channelInactive
当连接被断开或者不可用时, Netty 会调用fireChannelInactive,触发连接不可用事件,通道会启动对应的流水线处理,在通道注册过的入站处理器Handler 的ChannelInactive方法,会被调用到。
- exceptionCaught
当通道处理过程发生了异常时,Netty会调用fireExceptionCaught , 触发异常捕获事件,通道会启动异常捕获的流水线处理,在通道注册过的处理器Handler 的exceptionCaught方法,会被调用到,注意,这个方法是在通道处理器中ChannelHandler定义的方法,入站处理器,出站处理器接口都继承到该方法 。
上面介绍了并不是ChannelInboundHandler的全部方法,仅仅是介绍了其中几种比较重要的方法,在Netty中,它的默认实现为ChannelInboundHandlerAdapter,在实际开发中,只需要继承这个ChannelInboundHandlerAdapter默认实现重写自己需要的方法即可。
6.5.2 ChannelOutboundHandler 通道出站处理器
当业务处理完成后,需要操作Java NIO 通道时,通过一系列的ChannelOutboundHandler通道出站处理器,完成Netty 通道的底层通道操作,比方说建立底层的连接,断开底层的连接,写入底层的Java NIO 通道等, ChannelOutboundHandler接口定义了大部分的出站操作,如图6-10所示,具体的介绍如下 。
再强调一下,出站处理的方向,是通过上层Netty通道,去操作底层的Java IO通道,主要出站 (Outbound)操作如下 。
- bind
监听地址 (IP + 端口) 绑定: 完成底层的Java IO 通道的IP 地址绑定,如果使用了TCP 传输协议,这个方法用于服务端 。
- connect
连接服务端:完成底层的Java IO通道的服务器端的连接操作,如果使用了TCP 传输协议,这个方法用于客户端 。
- write
写数据到底层,完成Netty 通道向底层的Java IO通道的数据写入操作,此方法仅仅是触发一下操作而已,并不是完成实际的数据写入操作。
- flush
腾空缓冲区中的数据,把这些数据写到对端,将底层缓存区的数据腾空,立即写到对端 。
- read
从底层读取数据,完成Netty 通道从Java IO通道的数据读取 。
- disConnect
断开服务器连接,断开底层的Java IO 通道的服务器端连接,如果使用了TCP 传输协议,此方法主要用于客户端 。
- close
主动关闭通道,关闭底层的通道,例如服务器端的新连接监听通道 。
上面介绍的并不是ChannelOutboundHandler 的全部方法,仅仅介绍了其中几个比较重要的方法,在Netty中,它的默认实现为ChannelOutboundHandlerAdapter,在实际开发中,只需要继承这个ChannelOutboundHandlerAdapter 默认实现,重写自己需要的方法即可。
6.5.3 ChannelInitializer通道初始化处理器
在前面讲到,通道和Handler 业务处理器的关系是,一条Netty 通道拥有一条Handler 业务处理流水线,负责装配自己的Handler业务处理器,装配的Handler 的工作,发生在通道开始工作之前,现在的问题是,如何向流水线中装配业务处理器呢? 这就得借助通道的初始化类ChannelInitializer 。
首先回顾一下,NettyDiscardServer 丢弃服务器的代码,在给接收到新连接装配Handler业务处理器时, 使用childHandler()方法配置一个ChannelInitializer实例。
// 5 装配子通道流水线
b.childHandler(new ChannelInitializer<SocketChannel>(){
// 有连接到达时会创建一个通道
protected void initChannel(SocketChannel ch) throws Exception{
// 流水线管理子通道中的Handler 业务处理器
// 向子通道流水线添加一个Handler业务处理器
ch.pipeline().addLast(new NettyDiscardHandler());
}
})
上面的ChannelInitializer也是通道初始器,属于入站处理器类型,在示例代码中, 使用了ChannelInitializer的initChannel()方法,它是何方神圣呢?
initChannel()方法是ChannelInitializer定义的一个抽象方法,这个抽象方法需要开发人员自己实现,在父通道调用initChannel()方法时,会将新接收到通道作为参数,传递给initChannel()方法,initChannel()方法内部大致业务代码如下,拿到新连接通道作为实际参数,往它的流水线中装配Handler业务处理器。
6.5.4 ChannelInboundHandler 的生命周期的实战案例
为了弄清Handler 业务处理器各个方法执行顺序和生命周期,这里定义了一个简单的入站Handler 处理器,InHandlerDemo, 这个类继承于ChannelInboundHandlerAdapter 适配器, 它实现基类的大部分入站处理方法,并在每一个方法的实现代码中都加上必要的输出信息,以便观察方法是否被执行到。
public class InHandlerDemo extends ChannelInboundHandlerAdapter {
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
System.out.println("被调用:handlerAdded()");
super.handlerAdded(ctx);
}
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
System.out.println("被调用了:channelRegistered");
super.channelRegistered(ctx);
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
System.out.println(" 被调用:channelActive()");
super.channelActive(ctx);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("被调用channelRead()");
super.channelRead(ctx, msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
System.out.println("被调用:channelReadCompelete()");
super.channelReadComplete(ctx);
}
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
System.out.println("被调用:channelInactive()");
super.channelInactive(ctx);
}
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception {
System.out.println("被调用 channelUnregistered()");
super.channelUnregistered(ctx);
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
System.out.println("被调用:handlerRemoved()");
super.handlerRemoved(ctx);
}
}
为了演示这个入站处理器,需要编写一个单元测试代码,将上面的Inhandler 入站处理器加入到一个EmbeddedChannel 嵌入式通道的流水线中,接着,通过writeInbound 方法写入ByteBuf 数据包,InHandlerDemo作为一个入站处理器,会处理从通道到流水线的入站报文,ByteBuf 数据包单元测试代码如下 :
public static void main(String[] args) throws Exception {
final InHandlerDemo inHandlerDemo = new InHandlerDemo();
ChannelInitializer initializer = new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(inHandlerDemo);
}
};
// 创建嵌入式通道
EmbeddedChannel channel = new EmbeddedChannel();
ByteBuf buf = Unpooled.buffer();
buf.writeInt(1);
channel.writeInbound(buf); // 模拟入站,写入一个入站数据包
channel.flush();
// 通道关闭
channel.close();
Thread.sleep(Integer.MAX_VALUE);
}

在讲解上面的方法之前,首先对方法进行分类,1,生命周期方法,2 入站回调方法,上面的几个方法中,ChannelRead ,channelReadComplete是入站处理方法,而其他的6个方法是入站处理器的周期方法 。
从输出的结果可以看出,ChannelHandler 中的回调方法的执行顺序为,handlerAdded() ->channelRegisterd()->channelActive()-> 入站方法回调,channelInactive()->channelUnregistered()->channelRemoved() ,其中,读数据入站回调为channelRead()->channelReadComplete() ,入站方法会多次调用,每一次有ByteBuf 数据包入站都会调用到。
除了两个入站回调方法外,其余的6个方法都和ChannelHandler的生命周期有关,具体的介绍如下。
- handlerAdded(): 当业务处理器加入到流水线之后,此方法被回调,也就是在完成ch.pipeline().addLastHandler(handler) 语句之后,会回调handlerAdded()。
- channelRegistered() :当通道成功绑定一个NioEventLoop线程后,会通过流水线回调所有的业务处理器channelRegistered()方法 。
- channelActive(): 当通道激活成功后,会通过流水线回调所有的业务处理器的channelActive()方法,通过激活成功指的是,所有的业务处理器添加,注册的异步任务完成,并且 NioEventLoop线程绑定的异步任务完成 。
- channelInactive(): 当通道的底层连接已经不是ESTABLISH状态,或者底层连接已经关闭时,会首先回调所有的业务处理器的channelInactive()方法 。
- channelUnregistered(): 通道和NioEventLoop线程解除绑定,移除掉对这条通道的事件处理之后,回调所有的业务处理器的channelUnregistered()方法 。
- handlerRemoved(): 最后,Netty 会移除掉通道上所有的业务处理器,并且回调所有的业务处理器的handlerRemoved()方法 。
- 在上面6个生命周期方法中,前面3个通道创建时候被先后回调,后面个通道关闭时会先后回调。
除了生命mfkadlkym,就是入站和出站处理回调, 对于InHandler入站处理器,有两个很重要的回调方法为:
- channelRead():有数据包入站,通道可读,流水线会启动入站处理流程,从前向后,入站处理器的channelRead()方法被依次回调到。
- channelReadComplete():流水线完成入站处理后,会从前向后,依次回调每个入站处理器的channelReadComplete()方法,表示数据读取完毕 。
至此,大家对ChannelInboundHandler的生命周期和入站业务处理, 有了一个非常清楚的了解了 。
上面的入站处理器实践案例InHandlerDemo,演示的是入站处理器的工作流程,对于出站处理器ChannelOutboundHandler的生命周期以及回调顺序,与入站处理器是大致相同的,不同的是,出站处理器的业务处理方法 。
在实践案例Maven 源码工程中,有一个关于出站处理器的实践案例,OutHandlerDemo 它的代码,包名和上面类似,大家可以自己去运行和学习,这里就不再赘述了。
6.6 详解Pipeline流水线
前面讲到,一条Netty 通道需要很多的Handler 业务处理器业处理业务,每条通道内部都有一条流水线Pipeline 将Handler 装配起来,Netty 的业务处理器流水线ChannelPipeline是基于责任链设计模式(Chain of Responsibility来设计 的,内部是一个双向链表结构,能够支持动态的添加和删除Handler 业务处理器,首先看一下流水线的入站处理流程。
6.6.1 Pipeline入站处理流程
为了完整的演示Pipeline 入站处理流程,将新建三个极为简单的入站处理器,在ChannelInitializer 通道初始化处理器的initChannel方法中把它们加入到流水线中, 三个入站处理器分别为:SimpleInHandlerA , SimpleInHandlerB,SimpleInHandlerC , 添加的顺序为A->B->C ,实践代码如下:
public class InPipeline {
static class SimpleInhandlerA extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("入站处理器, A : 被回调");
super.channelRead(ctx, msg);
}
}
static class SimpleHandleB extends ChannelInboundHandlerAdapter{
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("入站处理器 B: 被回调");
// 不调用基类的channelRead,终止流水线的执行
// super.channelRead(ctx, msg);
}
}
static class SimpleHandleC extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("入站处理器C : 被 回调");
super.channelRead(ctx, msg);
}
}
public static void main(String[] args) {
ChannelInitializer initializer = new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(new SimpleInhandlerA());
ch.pipeline().addLast(new SimpleHandleB());
ch.pipeline().addLast(new SimpleHandleC());
}
};
EmbeddedChannel channel = new EmbeddedChannel();
ByteBuf buf = Unpooled.buffer();
buf.writeInt(1);
channel.writeInbound(buf); // 向通道写入一个入站报文 ,数据包
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
在channelRead()方法中,我们打印当前的Handler 业务处理器的信息,然后调用父类的channelRead()方法,而父类的channelRead()方法会自动调用下一个inBoundHandler的channelRead()方法,并且会把当前的inBoundHandler入站处理器中处理完毕对象传递到下一个inBoundHandler入站处理器,我们的示例程序中传递对象都是同一个信息(msg)。

我们可以看到,入站处理器的流动次序是, 从前到后,加在前面的,执行也在前面,具体如图6-11所示 。
6.6.2 Pipeline出站处理流程
为了完整的演示Pipeline出站处理流程,将新建三个级为简单的出站处理器,在ChannelInitializer通道初始化处理器的initChannel()方法中,把它们加入到流水线中,三个出站处理器分别为,SimpleOutHandlerA,SimpeOutHandlerB, SimpleOutHandlerC,添加的顺序为A->B->C ,实践案例的代码如下:
public class OutPipeline {
static class SimpleOutHandlerA extends ChannelOutboundHandlerAdapter {
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
System.out.println("出站处理器A: 被回调");
super.write(ctx, msg, promise);
}
}
static class SimpleOutHandlerB extends ChannelOutboundHandlerAdapter{
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
System.out.println("出站处理器B : 被回调");
super.write(ctx, msg, promise);
}
}
static class SimpleOutHandlerC extends ChannelOutboundHandlerAdapter{
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
System.out.println("出站处理器C : 被回调");
super.write(ctx, msg, promise);
}
}
public static void main(String[] args) {
ChannelInitializer initializer = new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(new SimpleOutHandlerA());
ch.pipeline().addLast(new SimpleOutHandlerB());
ch.pipeline().addLast(new SimpleOutHandlerC());
}
};
EmbeddedChannel channel = new EmbeddedChannel();
ByteBuf buf = Unpooled.buffer();
buf.writeInt(1);
// 向通道写一个出站报文 (或数据包)
channel.writeInbound(buf);
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}

从代码中,通过pipeline.addLast()方法中添加OutBoundHandler出站处理器的顺序为A->B->C,从结果可以看出 ,出站流水线处理次序伙从后向前, C->B-A,最后加入到出站处理器的执行在最前面,这一点和Inbound入站处理器次序刚好是相反的,具体如图6-12所示 。
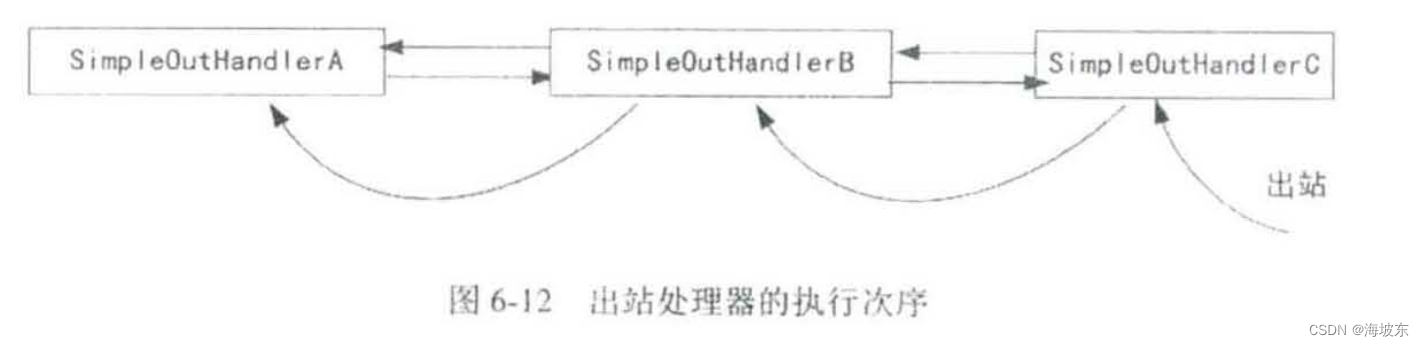
不管我们定义的是哪种类型的Handler 业务处理器,最终它们都以双向链表的方式保存在流水线中,这里流水线的节点类型,并不是前面Handler 业务处理器基类,而是一个新的Netty类型:ChannelHandlerContext 通道处理器上下文类,ChannelHandlerContext 又是何方神圣呢?
在Handler 业务处理器被添加到流水线中时,会创建一个通道处理器上下文ChannelHandlerContext ,它代表了ChannelHandler通道处理器和ChannelPipeline通道流水线之间的关联 。
ChannelHandlerContext中包含了许多的方法,主要可以分为两类,第一类是获取上下文所关联的Netty 组件实例,如所关联的通道,所关联的流水线,上下文内部Handler业务处理实现等,第二类是入站和出站处理方法 。
Channel ,Handler ,ChannelHandlerContext三者关系为:Channel 通道拥有一条ChannelPipeline通道流水线,每一条流水线节点为一个ChannelHandlerContext通道处理器上下文对象,每一个上下文中包裹了一个ChannelHandler通道处理器,在ChannelHandler通道处理器的入站出站处理方法中, Netty 都会传递一个Context 上下文实例作为实际参数,通过Context 实例的实参,在业务处理中,可以获取ChannelPipeline通道流水线的实例或者Channel通道实例。
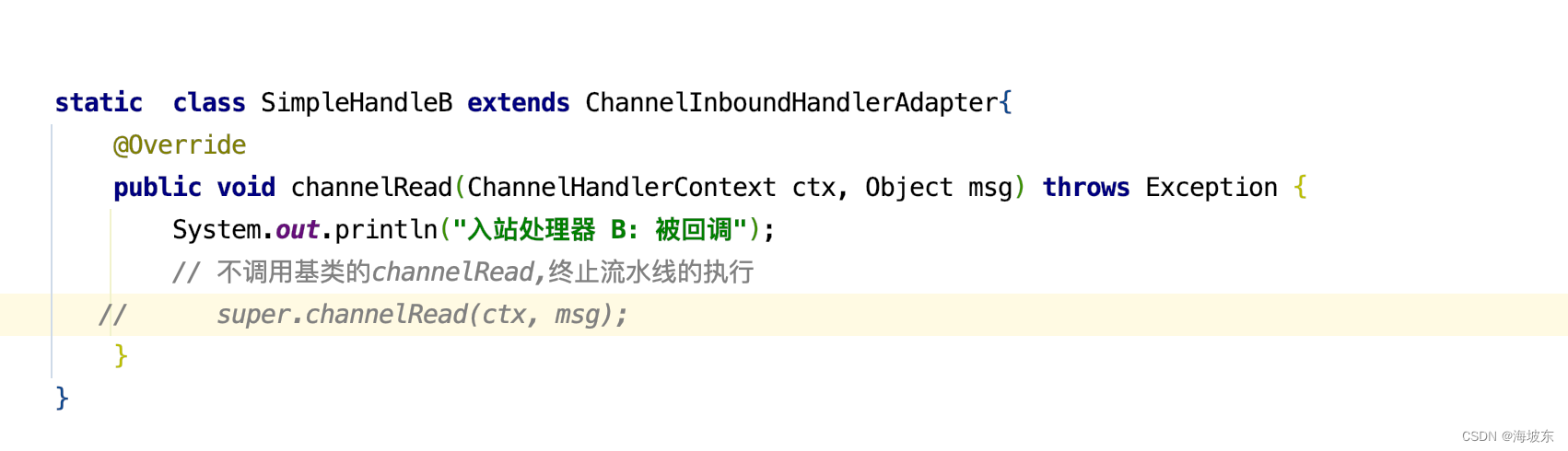
同样是3个业务处理器,只有中间的业务处理器SimpleHandlerB2 没有调用父类的super.channelRead()方法,运行结果如下:

从运行结果可以看出,入站处理器C 没有执行到,说明通过没有调用父类的super.channelRead()方法,处理流水线被成功的截断了,如图6-13所示 。
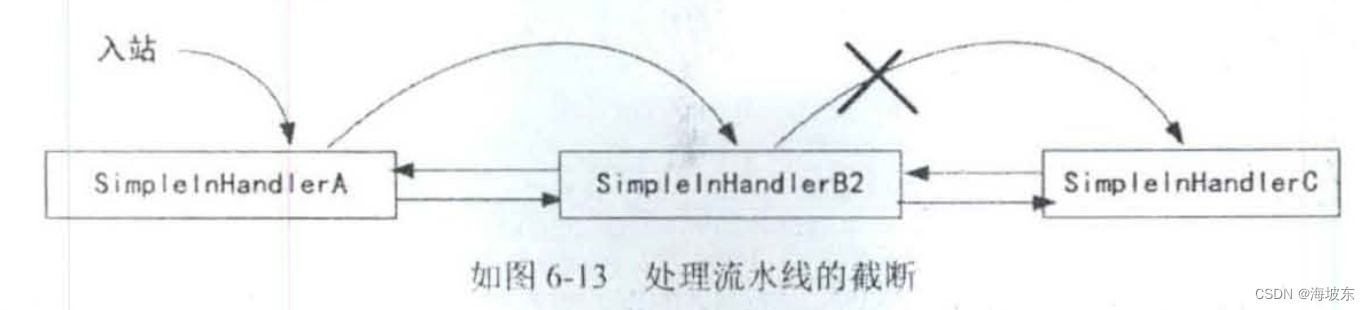
在channelRead()方法中,入站处理传入了下一站还有一种方法,调用Context 上下文 ctx.fireChannelRead(msg)方法,如果要截断流水线处理,很显然,就不能调用ctx.fireChannelRead(msg)方法 。
上面的channelRead()通道读操作流程的截断,仅仅是一个示例,如果要截断其他的入站处理的流水线操作,也可以同样处理。
- 不可调用supper.channelXXX(ChannelHandlerContext …);
- 也不可调用ctx.fireChannelXxx()
如何截断出站处理呢?结论是,出站处理流程只要开始执行,就不能被截断,强行截断的话,Netty 会抛出异常,如果业务条件不满足,可以不启动出站处理 。
public interface ChannelPipeline
extends ChannelInboundInvoker, ChannelOutboundInvoker, Iterable<Entry<String, ChannelHandler>> {
ChannelPipeline addFirst(String name, ChannelHandler handler);
ChannelPipeline addFirst(EventExecutorGroup group, String name, ChannelHandler handler);
ChannelPipeline addLast(String name, ChannelHandler handler);
ChannelPipeline addLast(EventExecutorGroup group, String name, ChannelHandler handler);
/**
* 在baseName处理器前增加一个业务处理器,名字由name指定
*/
ChannelPipeline addBefore(String baseName, String name, ChannelHandler handler);
ChannelPipeline addBefore(EventExecutorGroup group, String baseName, String name, ChannelHandler handler);
/**
* 在baseName处理器的后面增加一个业务处理器, 名字由name指定
*/
ChannelPipeline addAfter(String baseName, String name, ChannelHandler handler);
ChannelPipeline addAfter(EventExecutorGroup group, String baseName, String name, ChannelHandler handler);
/**
* 在头部增加一个业务处理器, 名字由name指定
*/
ChannelPipeline addFirst(ChannelHandler... handlers);
ChannelPipeline addFirst(EventExecutorGroup group, ChannelHandler... handlers);
/**
* 在尾部增加一个业务处理器, 名字由name指定
*/
ChannelPipeline addLast(ChannelHandler... handlers);
ChannelPipeline addLast(EventExecutorGroup group, ChannelHandler... handlers);
/**
* 删除一个业务处理器实例
*/
ChannelPipeline remove(ChannelHandler handler);
ChannelHandler remove(String name);
<T extends ChannelHandler> T remove(Class<T> handlerType);
/**
* 删除第一个业务处理器实例
*/
ChannelHandler removeFirst();
/**
* 删除最后一个业务处理器实例
*/
ChannelHandler removeLast();
}
下面的这个示例,调用流水线实现的remove(Channel Handler) 方法,从流水线动态的删除一个Handler实例。
public class PipelineHotOperateTester {
static class SimpleInHandlerA extends ChannelInboundHandlerAdapter{
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("入站处理器A : 被回调");
super.channelRead(ctx, msg);
// 从流水线删除当前业务处理器。
ctx.pipeline().remove(this);
}
}
static class SimpleInHandlerB extends ChannelInboundHandlerAdapter{
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("入站处理器B : 被回调");
super.channelRead(ctx, msg);
}
}
static class SimpleInHandlerC extends ChannelInboundHandlerAdapter{
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
System.out.println("入站处理器C : 被回调");
super.channelRead(ctx, msg);
}
}
public static void main(String[] args) {
ChannelInitializer initializer = new ChannelInitializer() {
@Override
protected void initChannel(Channel ch) throws Exception {
ch.pipeline().addLast(new SimpleInHandlerA());
ch.pipeline().addLast(new SimpleInHandlerB());
ch.pipeline().addLast(new SimpleInHandlerC());
}
};
EmbeddedChannel channel = new EmbeddedChannel();
ByteBuf buf = Unpooled.buffer();
buf.writeInt(1);
// 第一次向通道中写入报文(或数据包)
channel.writeInbound(buf);
// 第二次向通道中写入报文 (或数据包)
channel.writeInbound(buf);
// 第三次向通道中写入报文(或数据包)
channel.writeInbound(buf);
try {
Thread.sleep(Integer.MAX_VALUE);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
// 入站处理器A : 被回调
// 入站处理器B : 被回调
// 入站处理器C : 被回调
// 入站处理器B : 被回调
// 入站处理器C : 被回调
// 入站处理器B : 被回调
// 入站处理器C : 被回调
}
从运行结果来看,在SimpleInHandlerA 从流水线中删除后,在后面的入站流水线处理中,SimpeInHandlerA 已经不再被调用 。
总结
通过对《netty-redis-zookeeper高并发实战》这本书前几章的学习,我们大致知道了Netty当中的ServerSocket,ServerSocketChannel,Selector,SelectionKey,等基本概念,但看了这些概念之后有什么深刻的理解没有呢?依然没有,但从以往的学习经验告诉我,经过这段时间的学习,从书本上,已经很难再获得更多的理论知识,Netty的理论知识就那么多吧,因此接下来可能会深入源码的学习了,但在深入源码之前,先来看几个例子,从这几个例子中,看到我们自己写的程序的不足,从而激发为什么要去使用Netty,当然使用过后,就是去研究Netty源码了,在研究源码过程中,可能会再回头来看这些理论知识,从而达到融汇贯通的境界了。 当然啦,建议去看《netty-redis-zookeeper高并发实战》这本书原书,我可能有些漏掉的部分,原书更加详细 。
1. 先来看BIO的第一个例子
public class BioSocketServer {
public static void main(String[] args) throws Exception {
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
System.out.println("等待连接。。");
//阻塞方法
Socket clientSocket = serverSocket.accept();
System.out.println("有客户端连接了。。");
handler(clientSocket);
}
}
private static void handler(Socket clientSocket) throws Exception {
byte[] bytes = new byte[1024];
System.out.println("准备read。。");
//接收客户端的数据,阻塞方法,没有数据可读时就阻塞
int read = clientSocket.getInputStream().read(bytes);
System.out.println("read完毕。。");
if (read != -1) {
System.out.println("接收到客户端的数据:" + new String(bytes, 0, read));
}
clientSocket.getOutputStream().write("HelloClient".getBytes());
clientSocket.getOutputStream().flush();
}
}
这个程序很简单,启动9000端口,阻塞等待客户端连接,当有客户端链接时,阻塞等待客户端数据输入,当接收到客户端数据时,回写HelloClient字符串到客户端。
-
程序启动
-
输入 telnet 127.0.0.1 9000 连接服务器端
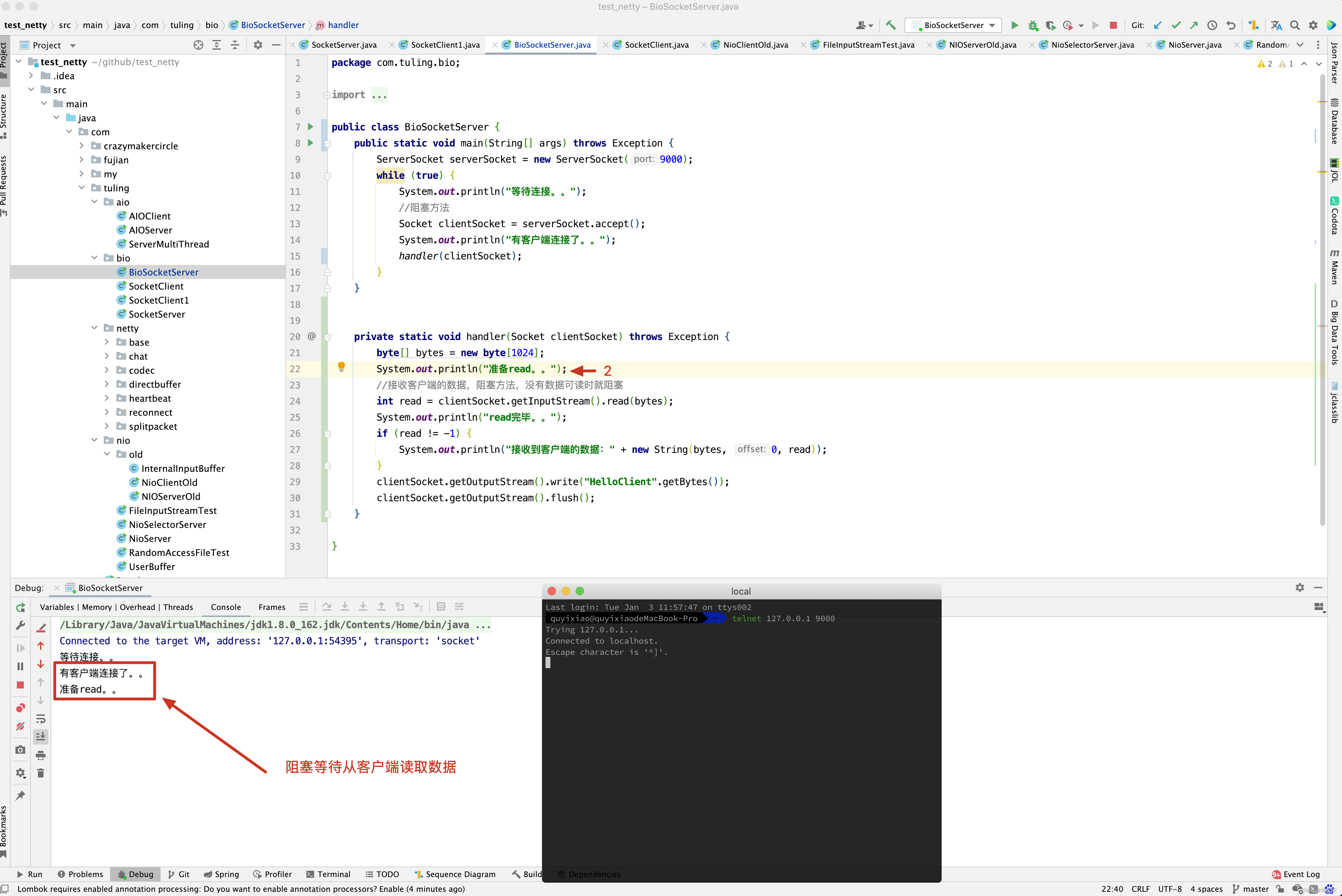
-
从客户端输入“111”,服务器接收到数据,打印出"111" ,并回写HelloClient到客户端。
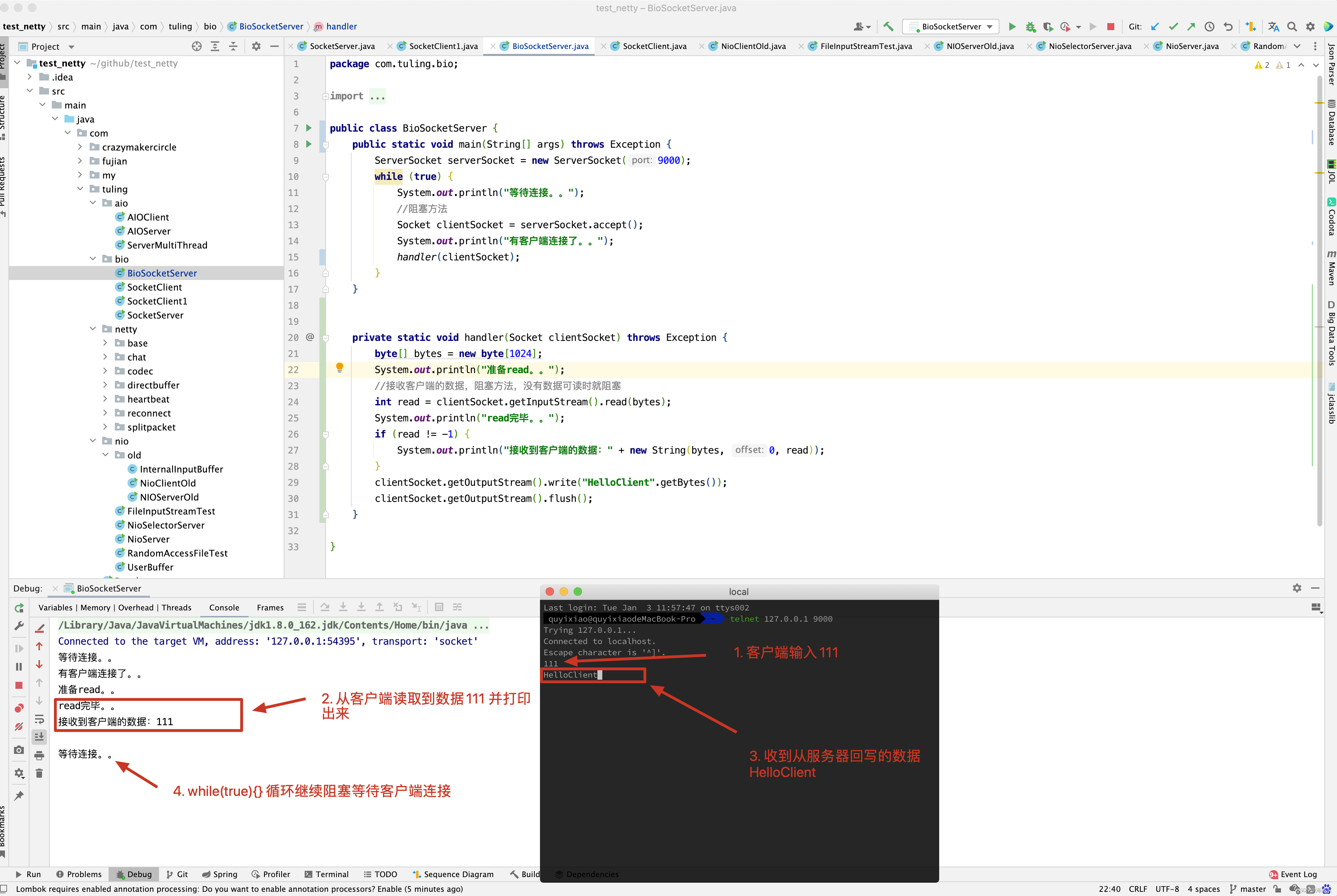
当然,从上面的测试好像没有什么问题啊, 我打开两个telnet试试 。 这个实验怎么做呢? 先打开一个本地窗口1 ,输入telnet 127.0.0.1 9000,再打开另一个窗口2 ,输入127.0.0.1 9000
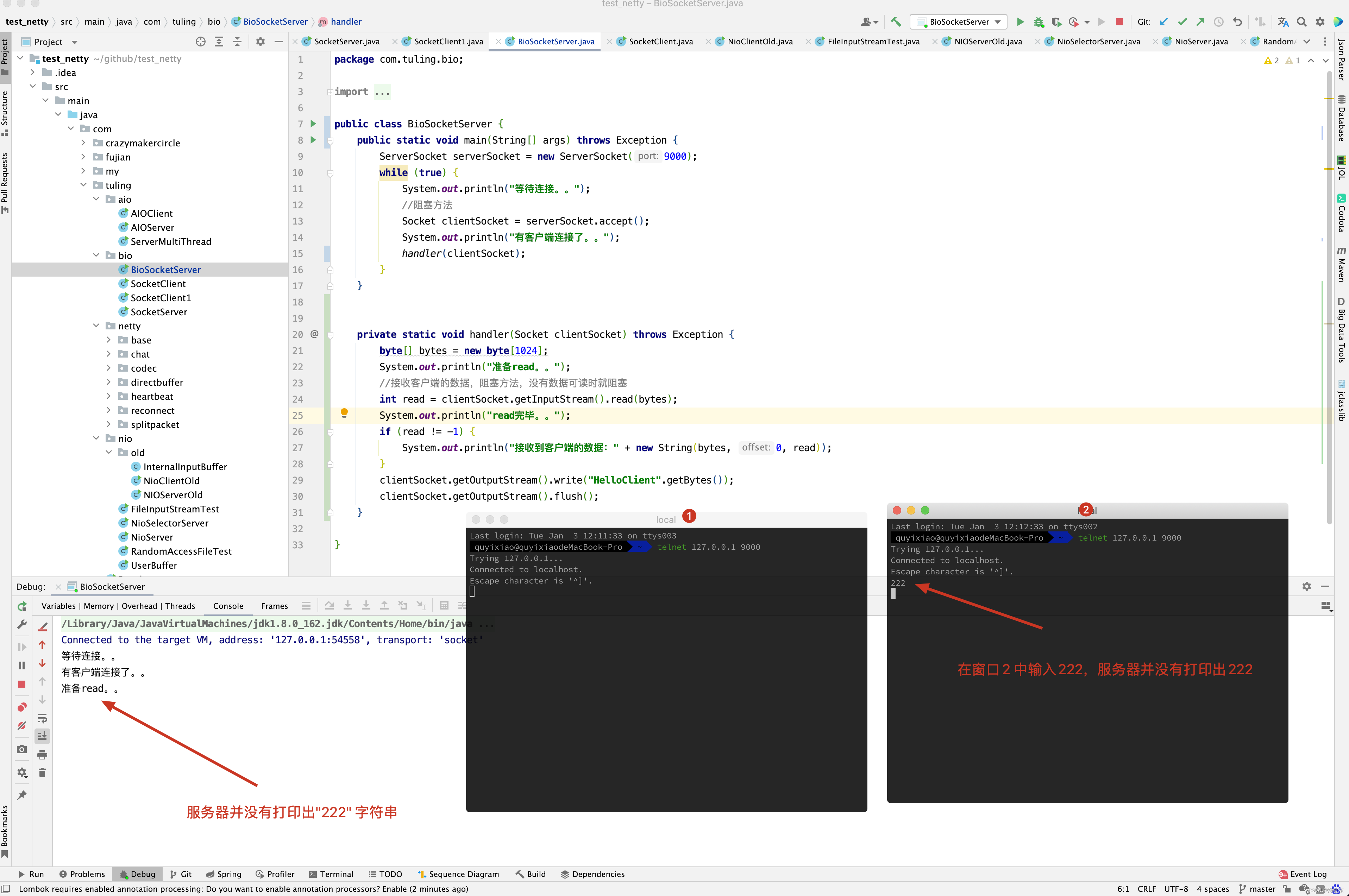
从实验结果中可以看出,在服务器端并没有打印出222字符串,如果此时在窗口1中输入111,看服务器输出。
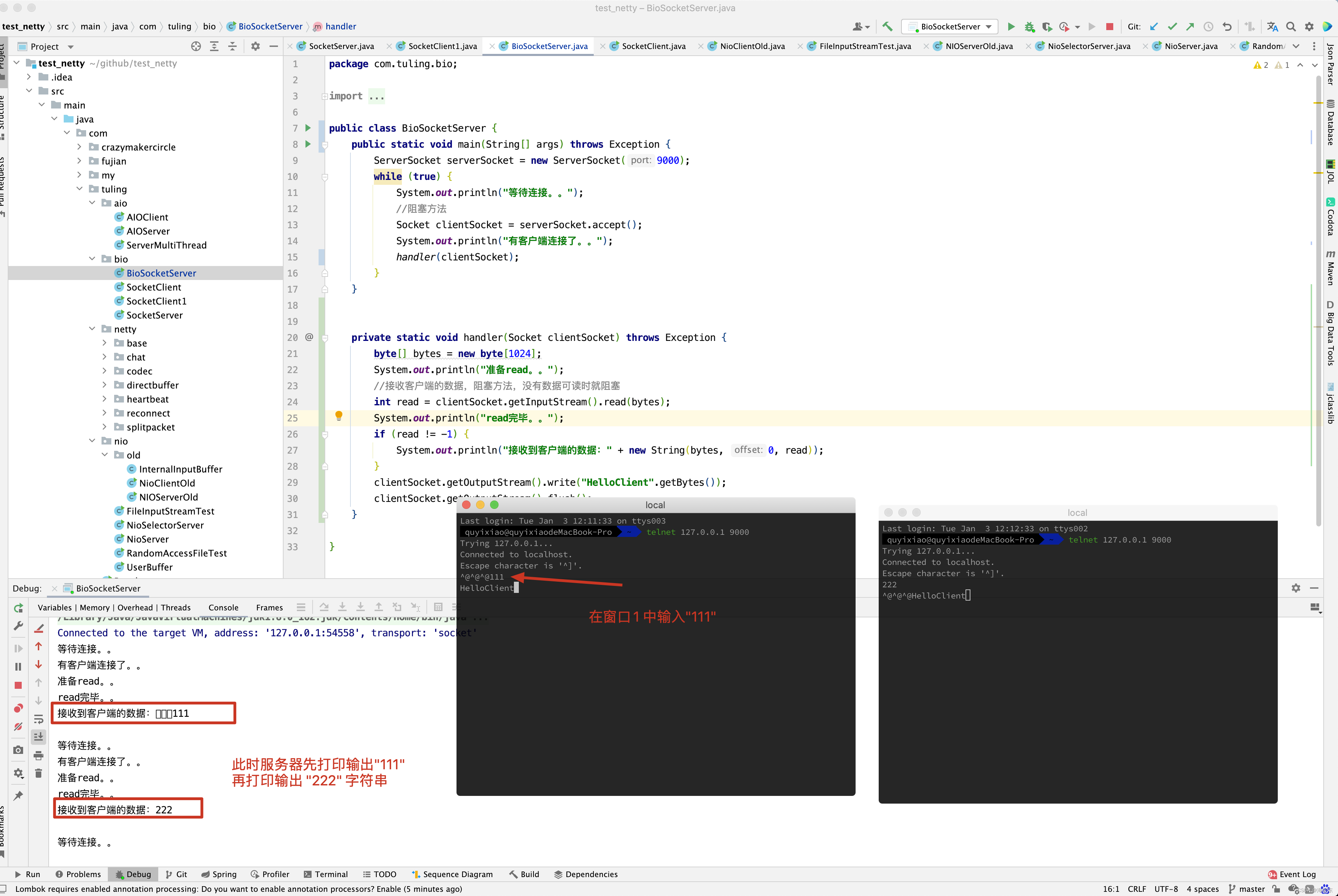
当在窗口1中输入"111"字符串,此时服务器先输出 “111” 再输出 “222” ,为什么会出现这种现象呢?回头看程序就知道,BioSocketServer 的main()方法是一个单线程程序,当窗口1连接成功后,线程阻塞在int read = clientSocket.getInputStream().read(bytes);这一行代码,等待窗口1输入,当服务器没有接收到窗口1输入时,将一直阻塞等待,此时即使打开窗口2,输入telnet 127.0.0.1 9000后,再输入 “222” 字符串并且回车 。

因为服务器代码一直阻塞在int read = clientSocket.getInputStream().read(bytes);这一行代码,无法调用Socket clientSocket = serverSocket.accept(); 这一行代码接收客户端连接,因此此时看到的窗口2 ,其实是一个假窗口,我们的服务器代码并没有接收到客户端连接,当在窗口1输入了 “111” 字符串,此时服务器的int read = clientSocket.getInputStream().read(bytes);这一行代码将不进行阻塞,并且将客户端输入的 “111” 以字节的形式写入到bytes数组中,服务器打印bytes数组内容,同时回写"HelloClient"字符串给窗口1的客户端,第一轮while(true){} 循环执行完毕,此时再次调用Socket clientSocket = serverSocket.accept();代码,当然发现窗口2客户端连接,当然连接成功,此时第二轮循环继续调用 int read = clientSocket.getInputStream().read(bytes); 代码,但窗口2已经输入了"222" 并且发送了数据,此时 int read = clientSocket.getInputStream().read(bytes); 代码将不再进行阻塞,将 “222” 字符串以字节的形式写入到bytes数组中,服务器打印 "222"字符串,并回写HelloClient给窗口2的客户端。 因此最终打印结果如下。
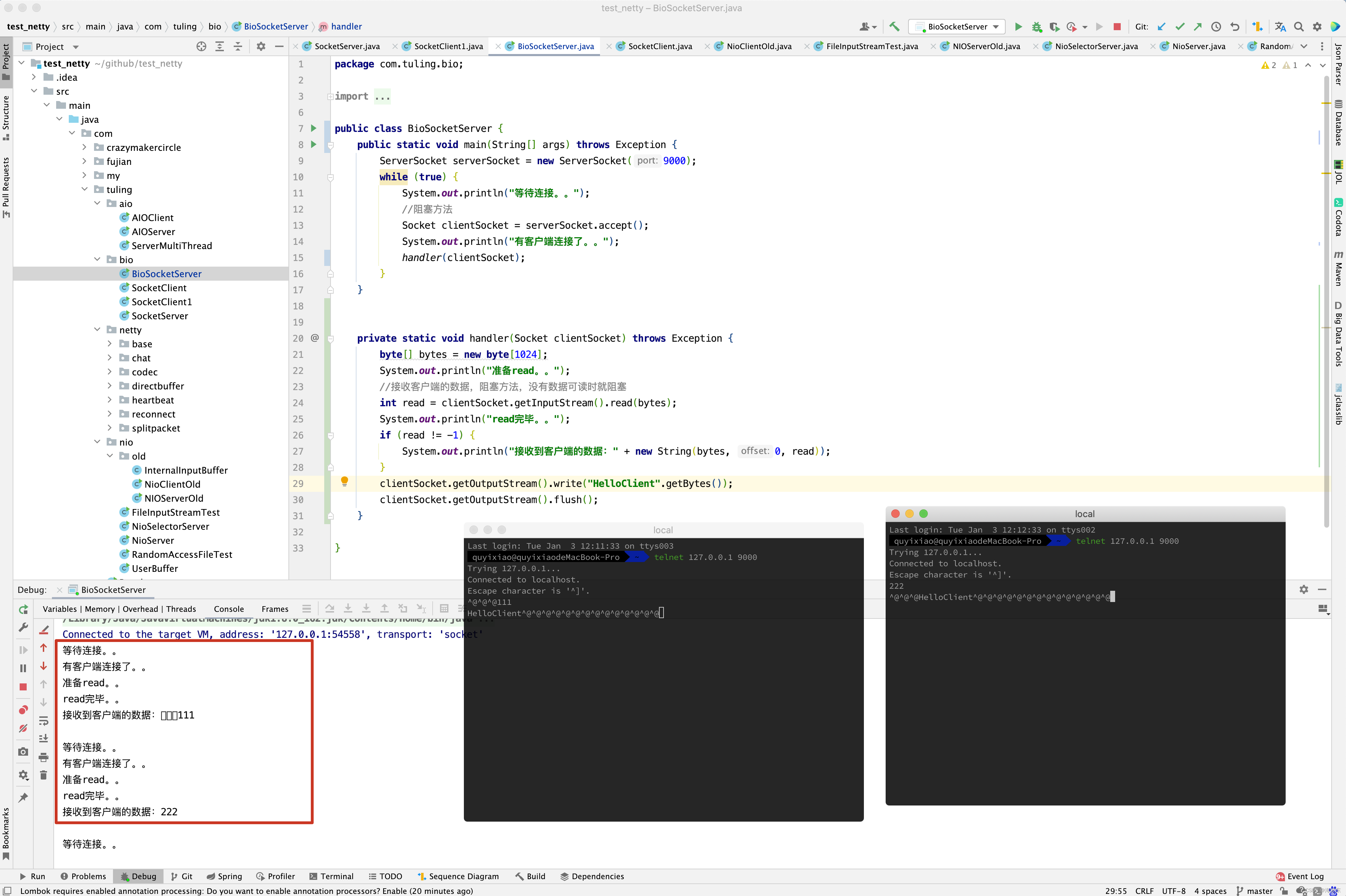
通过这个例子,大家发现一个问题没有,假如在客户端容器1 的业务处理中加一个模拟耗时操作。
// 接收到客户端数据,模拟处理业务代码
Thread.sleep(100000000l);
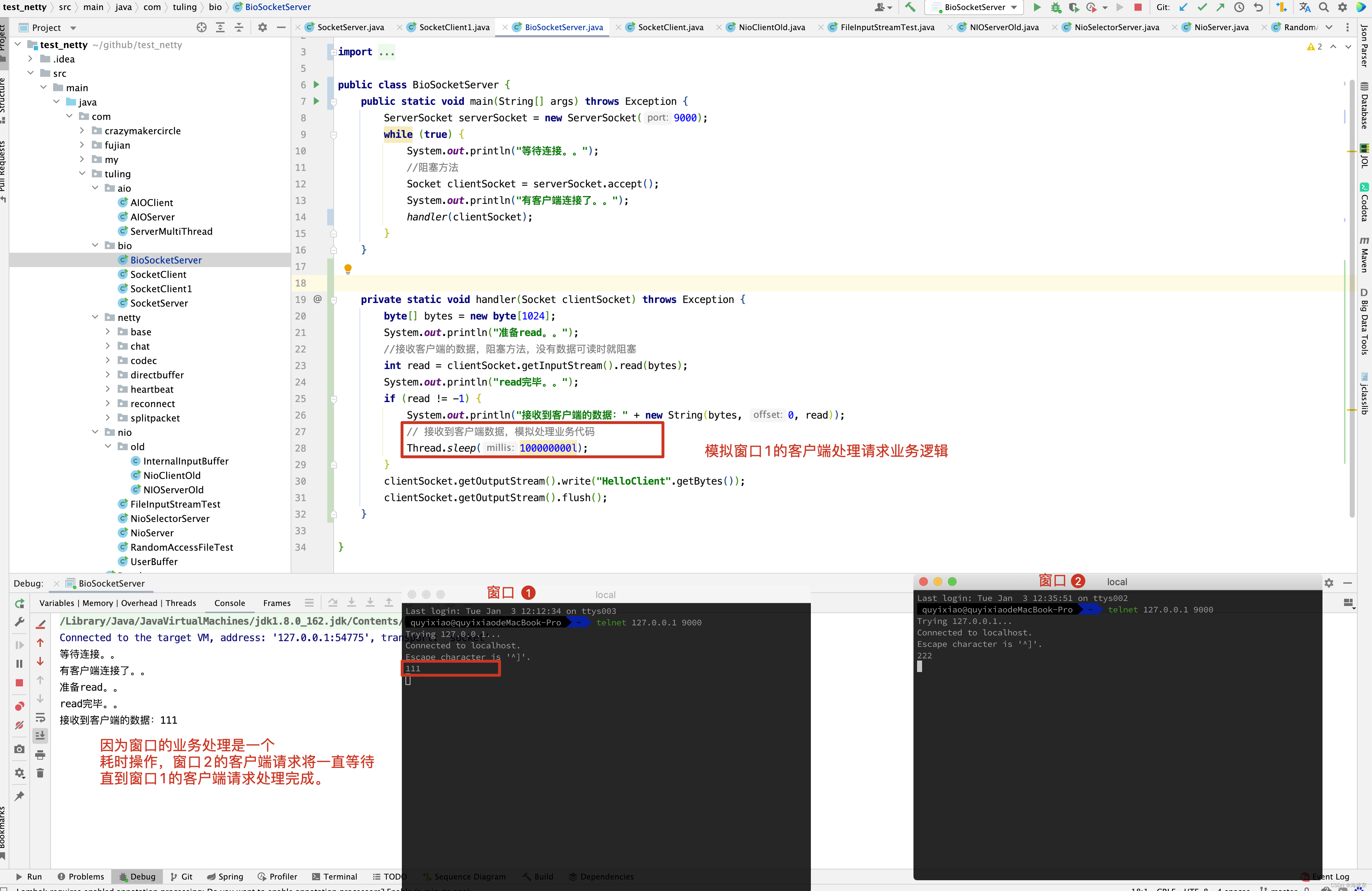
此时窗口2的客户端请求将得不到处理,直到窗口1的客户端请求处理完成,这种服务器代码显然有很大的问题,假如两个客户端请求,第一个客户端的请求是一个耗时操作,第二个客户端需要等待第一个客户端处理完成之后才能得到服务器的响应,如果是服务器是这样处理的,那淘宝生意没法做了,你去网上买个东西,比一230六抢票还难了,显然这种代码不切实际 。 当然,肯定有人会想,那我用多线程来处理接收数据和处理请求这一块不就可以了,当然,先来看使用多线程接收处理和处理请求如何改写。
public class BioSocketServer2 {
public static void main(String[] args) throws IOException {
ServerSocket serverSocket = new ServerSocket(9000);
while (true) {
System.out.println("等待连接。。");
//阻塞方法
Socket clientSocket = serverSocket.accept();
System.out.println("有客户端连接了。。");
new Thread(new Runnable() {
@Override
public void run() {
try {
handler(clientSocket);
} catch (IOException e) {
e.printStackTrace();
}
}
}).start();
}
}
private static void handler(Socket clientSocket) throws IOException {
byte[] bytes = new byte[1024];
System.out.println("准备read。。");
//接收客户端的数据,阻塞方法,没有数据可读时就阻塞
int read = clientSocket.getInputStream().read(bytes);
System.out.println("read完毕。。");
if (read != -1) {
System.out.println("接收到客户端的数据:" + new String(bytes, 0, read));
}
clientSocket.getOutputStream().write("HelloClient".getBytes());
clientSocket.getOutputStream().flush();
}
}
此时再来看测试效果,当打开两个窗口,窗口1 先输入telnet 127.0.0.1 9000,再窗口2输入telnet 127.0.0.1 9000,此时服务器都接收到了窗口1和窗口2的连接,并都进入了准备read。。的阻塞等待,如下图所示 。
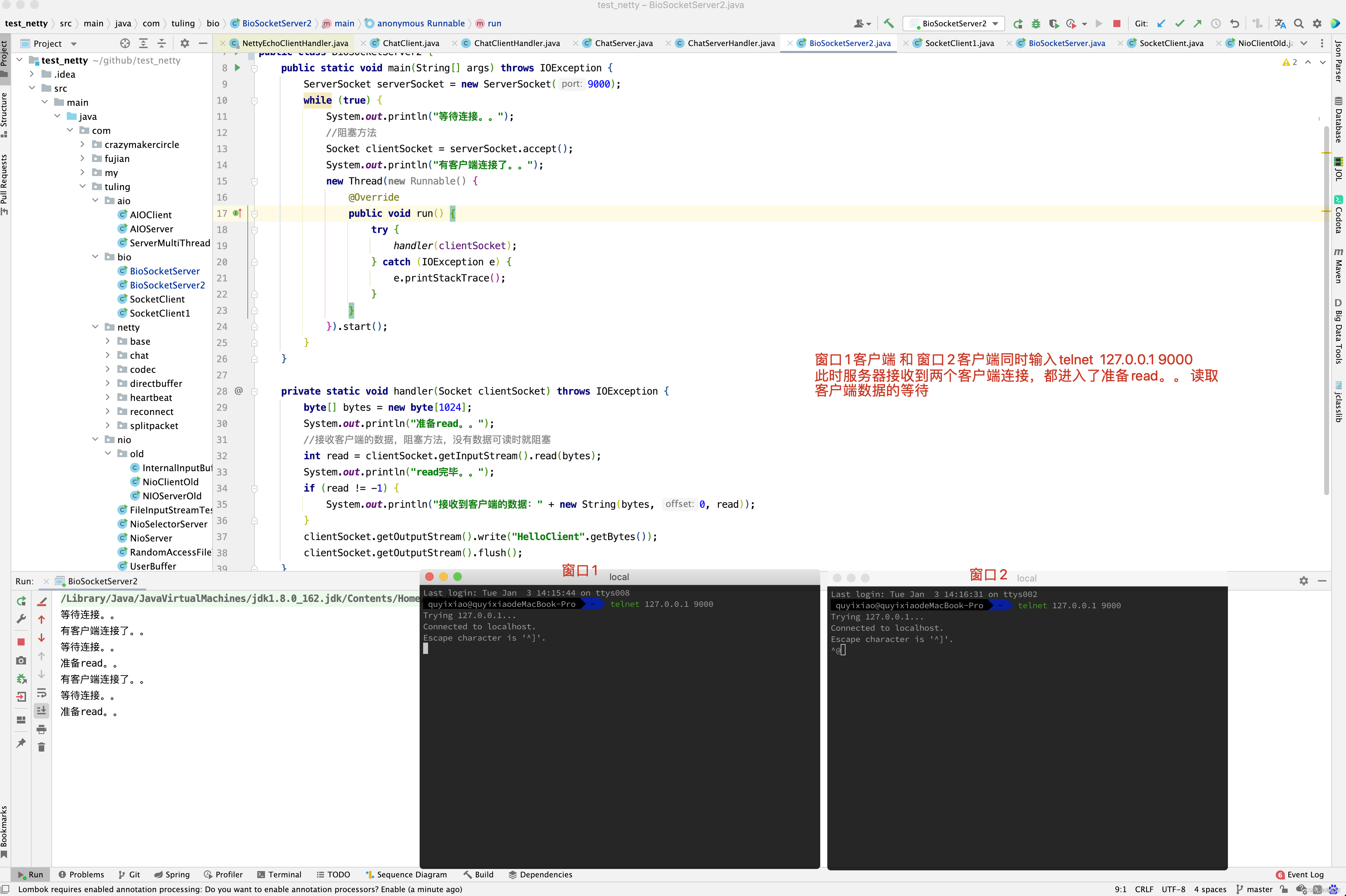
此时在窗口2中输入“222”字符串,服务器并没有因为窗口1客户端没有发送客户端信息而阻塞窗口2的客户端请求信息,在服务器端打印出窗口2的发送信息。并回显给窗口2
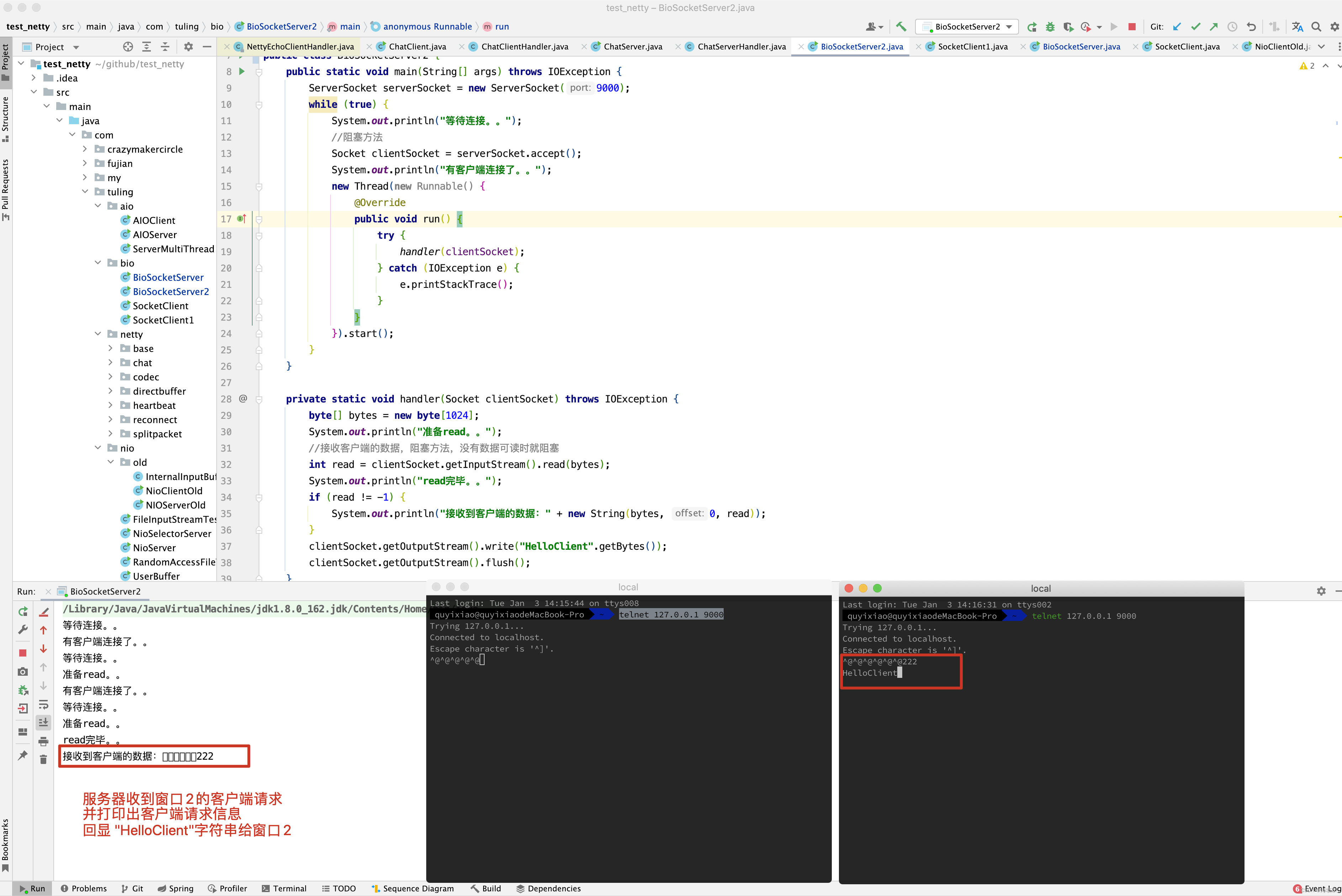
是不是这种方案就能解决因为某个客户端请求处理被阻塞而影响到其他客户端的情况呢?显然解决了,而且早期的Tomcat BIO 方式处理请求就是这种方式。
当然,Tomcat 比我们做得更加复杂一些,不是直接用线程,而是用线程池。 默认最大处理请求的线程池中线程个数为200。
用BIO+多线程的处理模式有什么缺点呢?
缺点:
- IO代码里read操作是阻塞操作,如果连接不做数据读写操作会导致线程阻塞,浪费资源
- 如果线程很多,会导致服务器线程太多,压力太大,比如C10K问题
NIO(Non Blocking IO)
同步非阻塞,服务器实现模式为一个线程可以处理多个请求(连接),客户端发送的连接请求都会注册到多路复用器selector上,多路复用器轮询到连接有IO请求就进行处理,JDK1.4开始引入。
应用场景:
NIO方式适用于连接数目多且连接比较短(轻操作) 的架构, 比如聊天服务器, 弹幕系统, 服务器间通讯,编程比较复杂。
public class NioServer {
// 保存客户端连接
static List<SocketChannel> channelList = new ArrayList<>();
public static void main(String[] args) throws IOException {
// 创建NIO ServerSocketChannel,与BIO的serverSocket类似
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(9000));
// 设置ServerSocketChannel为非阻塞
serverSocket.configureBlocking(false);
System.out.println("服务启动成功");
while (true) {
// 非阻塞模式accept方法不会阻塞,否则会阻塞
// NIO的非阻塞是由操作系统内部实现的,底层调用了linux内核的accept函数
SocketChannel socketChannel = serverSocket.accept();
if (socketChannel != null) { // 如果有客户端进行连接
System.out.println("连接成功");
// 设置SocketChannel为非阻塞
socketChannel.configureBlocking(false);
// 保存客户端连接在List中
channelList.add(socketChannel);
}
// 遍历连接进行数据读取
Iterator<SocketChannel> iterator = channelList.iterator();
while (iterator.hasNext()) {
SocketChannel sc = iterator.next();
ByteBuffer byteBuffer = ByteBuffer.allocate(128);
// 非阻塞模式read方法不会阻塞,否则会阻塞
int len = sc.read(byteBuffer);
// 如果有数据,把数据打印出来
if (len > 0) {
System.out.println("接收到消息:" + new String(byteBuffer.array()));
} else if (len == -1) {// 如果客户端断开,把socket从集合中去掉
iterator.remove();
System.out.println("客户端断开连接");
}
}
}
}
}
缺点
如果连接数太多的话,会有大量的无效遍历,假如有10000个连接,其中只有1000个连接有写数据,但是由于其他9000个连接并 没有断开,我们还是要每次轮询遍历一万次,其中有十分之九的遍历都是无效的,这显然不是一个让人很满意的状态。
NIO引入多路复用器代码示例:
public class NioSelectorServer {
public static void main(String[] args) throws IOException {
// 创建NIO ServerSocketChannel
ServerSocketChannel serverSocket = ServerSocketChannel.open();
serverSocket.socket().bind(new InetSocketAddress(9000));
// 设置ServerSocketChannel为非阻塞
serverSocket.configureBlocking(false);
// 打开Selector处理Channel,即创建epoll
Selector selector = Selector.open();
// 把ServerSocketChannel注册到selector上,并且selector对客户端accept连接操作感兴趣
SelectionKey selectionKey = serverSocket.register(selector, SelectionKey.OP_ACCEPT);
System.out.println("服务启动成功");
while (true) {
// 阻塞等待需要处理的事件发生
selector.select();
// 获取selector中注册的全部事件的 SelectionKey 实例
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
// 遍历SelectionKey对事件进行处理
while (iterator.hasNext()) {
SelectionKey key = iterator.next();
// 如果是OP_ACCEPT事件,则进行连接获取和事件注册
if (key.isAcceptable()) {
ServerSocketChannel server = (ServerSocketChannel) key.channel();
SocketChannel socketChannel = server.accept();
socketChannel.configureBlocking(false);
// 这里只注册了读事件,如果需要给客户端发送数据可以注册写事件
SelectionKey selKey = socketChannel.register(selector, SelectionKey.OP_READ);
System.out.println("客户端连接成功");
} else if (key.isReadable()) { // 如果是OP_READ事件,则进行读取和打印
SocketChannel socketChannel = (SocketChannel) key.channel();
ByteBuffer byteBuffer = ByteBuffer.allocateDirect(128);
int len = socketChannel.read(byteBuffer);
// 如果有数据,把数据打印出来
if (len > 0) {
System.out.println("接收到消息:" + new String(byteBuffer.array()));
} else if (len == -1) { // 如果客户端断开连接,关闭Socket
System.out.println("客户端断开连接");
socketChannel.close();
}
}
//从事件集合里删除本次处理的key,防止下次select重复处理
iterator.remove();
}
}
}
}
NIO 有三大核心组件: Channel(通道), Buffer(缓冲区),Selector(多路复用器)
- channel 类似于流,每个 channel 对应一个 buffer缓冲区,buffer 底层就是个数组
- channel 会注册到 selector 上,由 selector 根据 channel 读写事件的发生将其交由某个空闲的线程处理
- NIO 的 Buffer 和 channel 都是既可以读也可以写
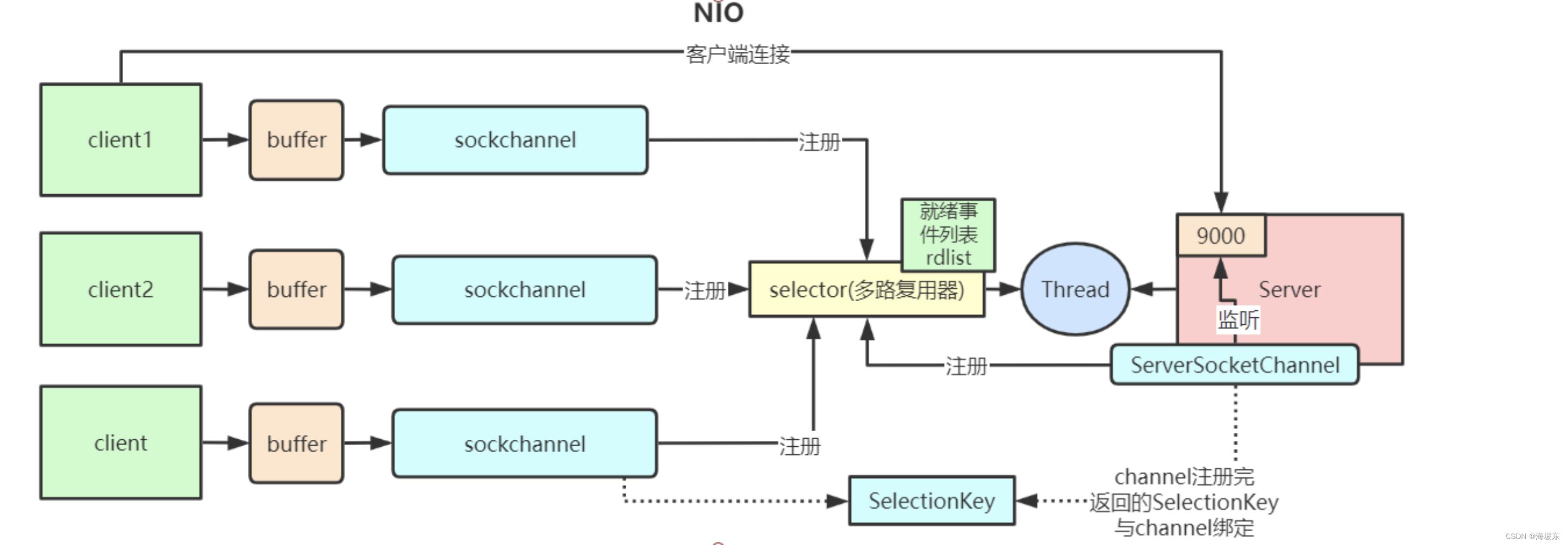
NIO底层在JDK1.4版本是用linux的内核函数select()或poll()来实现,跟上面的NioServer代码类似,selector每次都会轮询所有的 sockchannel看下哪个channel有读写事件,有的话就处理,没有就继续遍历,JDK1.5开始引入了epoll基于事件响应机制来优化NIO。
NioSelectorServer 代码里如下几个方法非常重要,我们从Hotspot与Linux内核函数级别来理解下
Selector.open()//创建多路复用器
socketChannel.register()//将channel注册到多路复用器上 3 selector.select()//阻塞等待需要处理的事件发生
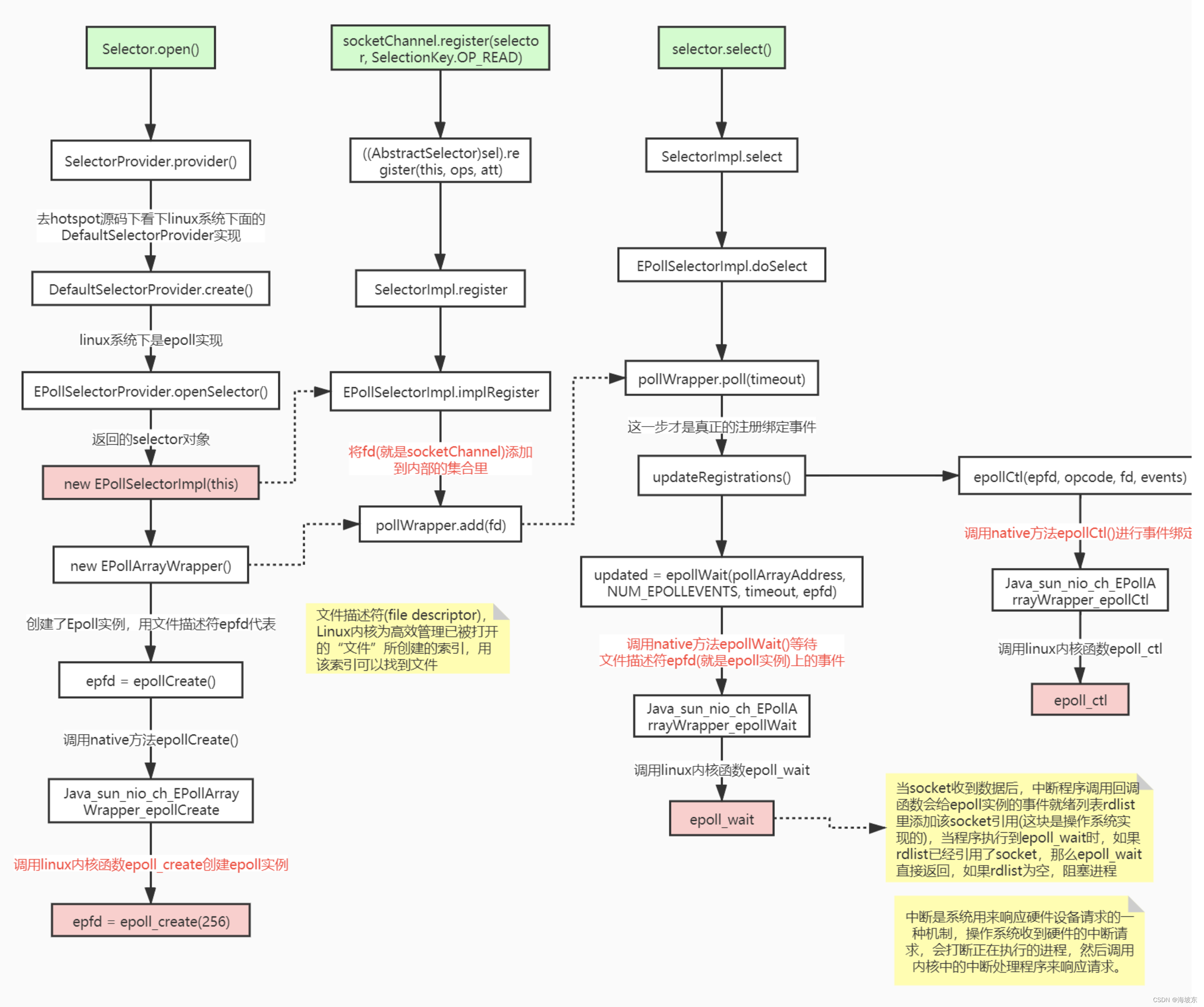
I/O多路复用底层主要是用Linux 内核函数(select ,poll,epoll )来实现, windows不支持epoll实现,windows底层是基于winsock2的
select函数实现的(不开源)。
| select | poll | epoll(jdk 1.5 及以上) | |
|---|---|---|---|
| 操作方式 | 遍历 | 遍历 | 回调 |
| 底层实现 | 数组 | 链表 | 哈希表 |
| IO效率 | 每次调用都进行线程遍历,时间复杂度为O(n) | 每次调用都进行线程遍历,时间复杂度为O(n) | 事件通知方式,每当有IO事件就绪,系统注册的回调函数就会被调用,时间复杂度为O(1) |
| 最大连接 | 有上限 | 无上限 | 无上线 |
Redis线程模型
Redis 就是典型的基于epoll的NIO线程模型(nginx也是),epoll实例收集所有的事件(连接与读写事件 ),由一个服务端线程连续处理所有的事件命令。
Redis底层关于epoll的源码实现的redis的src源码目录的ae_epoll.c文件里,感兴趣可以自行研究 。
AIO(NIO 2.0)
异步非阻塞,由操作系统完成后回调通知服务器程序启动线程去处理,一般用于连接数较多且连接时间较长的应用 。
应用场景:
AIO方式适用于连接数目多且连接比较长(重操作)的架构,JDK 7 开始支持。
AIO 代码示例
public class AIOServer {
public static void main(String[] args) throws Exception {
final AsynchronousServerSocketChannel serverChannel =
AsynchronousServerSocketChannel.open().bind(new InetSocketAddress(9000));
serverChannel.accept(null, new CompletionHandler<AsynchronousSocketChannel, Object>() {
@Override
public void completed(AsynchronousSocketChannel socketChannel, Object attachment) {
try {
System.out.println("2--"+Thread.currentThread().getName());
// 再此接收客户端连接,如果不写这行代码后面的客户端连接连不上服务端
serverChannel.accept(attachment, this);
System.out.println(socketChannel.getRemoteAddress());
ByteBuffer buffer = ByteBuffer.allocate(1024);
socketChannel.read(buffer, buffer, new CompletionHandler<Integer, ByteBuffer>() {
@Override
public void completed(Integer result, ByteBuffer buffer) {
System.out.println("3--"+Thread.currentThread().getName());
buffer.flip();
System.out.println(new String(buffer.array(), 0, result));
socketChannel.write(ByteBuffer.wrap("HelloClient".getBytes()));
}
@Override
public void failed(Throwable exc, ByteBuffer buffer) {
exc.printStackTrace();
}
});
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void failed(Throwable exc, Object attachment) {
exc.printStackTrace();
}
});
System.out.println("1--"+Thread.currentThread().getName());
Thread.sleep(Integer.MAX_VALUE);
}
}
public class AIOClient {
public static void main(String... args) throws Exception {
AsynchronousSocketChannel socketChannel = AsynchronousSocketChannel.open();
socketChannel.connect(new InetSocketAddress("127.0.0.1", 9000)).get();
socketChannel.write(ByteBuffer.wrap("HelloServer".getBytes()));
ByteBuffer buffer = ByteBuffer.allocate(512);
Integer len = socketChannel.read(buffer).get();
if (len != -1) {
System.out.println("客户端收到信息:" + new String(buffer.array(), 0, len));
}
}
}
BIO ,NIO ,AIO对比
| BIO | NIO | AIO | |
|---|---|---|---|
| IO 模型 | 同步阻塞 | 同步非阻塞(多路利用) | 异步非阻塞 |
| 编程难度 | 简单 | 复杂 | 复杂 |
| 可靠性 | 差 | 好 | 好 |
| 吞吐量 | 低 | 高 | 高 |
为什么Netty 使用NIO而不是AIO呢?
在Linux系统上,AIO 的底层实现仍然使用Epoll,没有很好的实现AIO,因此在性能上没有明显的优势,而且被JDK封装了一层不容易深度优化,Linux上AIO还不够成熟,Netty是异步非阻塞框架,Netty在NIO上做了很多异步封装。
我们可以通过一个简单的生活场景来理解BIO,NIO,和AIO 。
BIO 模式:你去工厂食堂打饭,因为煮饭时间有偏差,你到了食堂,可能就需要不断的观望打饭窗口阿姨饭有没有剩出来,如果剩出来了,你就屁颠屁颠跑到打饭窗口让阿姨帮你打饭。
NIO模式: 你去肯德基吃奥良烤翅,当你扫码点餐之后,会给你一张小票 A009号,你就可以找们位置坐下来,此时,你可以打开电脑继续写代码,也可以微信聊天,或者看抖音,当你点的烤翅好了,此时,肯德基会播报 A009 号点餐已经准备好,你拿着小票到前台去拿烤翅即可。
AIO : 你去高端饭店吃饭,你先找个位置座下来,打开微信APP,扫码点餐,当饭菜好后,此时你依然可以忙你自己的事情,当饭菜好后,服务员会将饭菜端到你餐桌上,你直接吃即可。
当然,对客户而言,最好的是第三种方式,完全可以去做自己的事情,只需要食物送上来即可。
总节:
当然,理论知识到这里已经分享得差不多了,其实基本上来源于书本和图灵学院的资料,当然,我还是那个观点,如果真的工作了,又不能静下心来去学习,通过外界的方式来督促自己学习也好的,总之不要浪费时间就好。 下一篇博客将深入源码来学习,而这篇博客的很多理论知识又是绕不开的话题,如果连这些基础知识,概念都不明白,再去研究源码,也只能从入门到放弃了,因此建议在学习源码之前,将基础的概念先有一个大概的理解,再去研究源码,这样才有效果,不然,研究源码之后,源码还是那套源码,自己也似懂非懂,其实就是不懂,这样既浪费时间,也没有意义,学习一个知识点,重点是自己真正的得到了多少,而不是人云亦云,学习方法就不多说了 。 本篇博客的源码如下。
github
https://github.com/quyixiao/test_netty.git
码云
https://gitee.com/quyixiao/netty-netty-4.1.38.Final.git