最近 GPT 模型在 NLP 领域取得了巨大成功。GPT 模型首先在大规模的数据上预训练,然后在特定的下游任务的数据上微调。大规模的预训练能够帮助模型学习可泛化的特征,进而让其轻松迁移到下游的任务上。
但相比自然语言数据,机器人数据是十分稀缺的。而且机器人数据包括了图片、语言、机器人状态和机器人动作等多种模态。为了突破这些困难,过去的工作尝试用 contrastive learning [1] 和 masked modeling [2] 等方式来做预训练以帮助机器人更好的学习。
在最新的研究中,ByteDance Research 团队提出 GR-1,首次证明了通过大规模的视频生成式预训练能够大幅提升机器人端到端多任务操作方面的性能和泛化能力。实验证明这种预训练方法可以大幅提升模型表现。在极具挑战的 CALVIN 机器人操作仿真数据集上,GR-1 在 1) 多任务学习 2) 零样本场景迁移 3) 少量数据 4) 零样本语言指令迁移上都取得了 SOTA 的结果。在真机上,经过视频预训练的 GR-1 在未见过的场景和物体的表现也大幅领先现有方法。
方法
GR-1 是一个端到端的机器人操作模型,采用了 GPT 风格的 transformer 作为模型架构。GR-1 首先在大规模视频数据上进行视频预测的预训练。预训练结束后,GR-1 在机器人数据上微调。微调的训练任务包含未来帧的预测和机器人动作的预测。

GR-1 用来自 Ego4D [3] 数据的 8M 图片来做视频生成式预训练。在预训练阶段,GR-1 的输入包括视频片段和描述视频的文字。文字信息用 CLIP [4] 的文字编码器编码。视频中的图片用 MAE [5] 编码,然后通过 perciever resampler [6] 来减少 token 的个数。输出端 GR-1 在每一个时间戳通过学习 [OBS] token 来输出未来帧的图片。[OBS] 对应的输出通过一个 transformer 来解码成图片。在预训练阶段,GR-1 采用了 mean squared error (MSE) 的损失函数。
在机器人数据微调阶段,GR-1 的输入包括任务语言指令,机器人状态和观测图片。其中机器人状态包括 6 维机器人位姿和夹抓的开闭状态。机器人状态通过 MLP 来编码。输出包括未来帧的图片和机器人动作。语言和图片的编码方式与预训练阶段相同。输出端 GR-1 通过学习 [ACT] token 来预测下一个时间戳机器人的动作。机械臂动作的损失函数采用 smooth L1 loss;夹抓动作的损失函数采用 binary cross entropy loss。
实验
作者在 CALVIN 仿真平台上做了大量实验来验证 GR-1 的性能。CALVIN 是一个极具挑战性的机器人多任务操作仿真平台。其中包括 34 个通过语言指令的操作任务和 A, B, C, D 四个不同的环境。
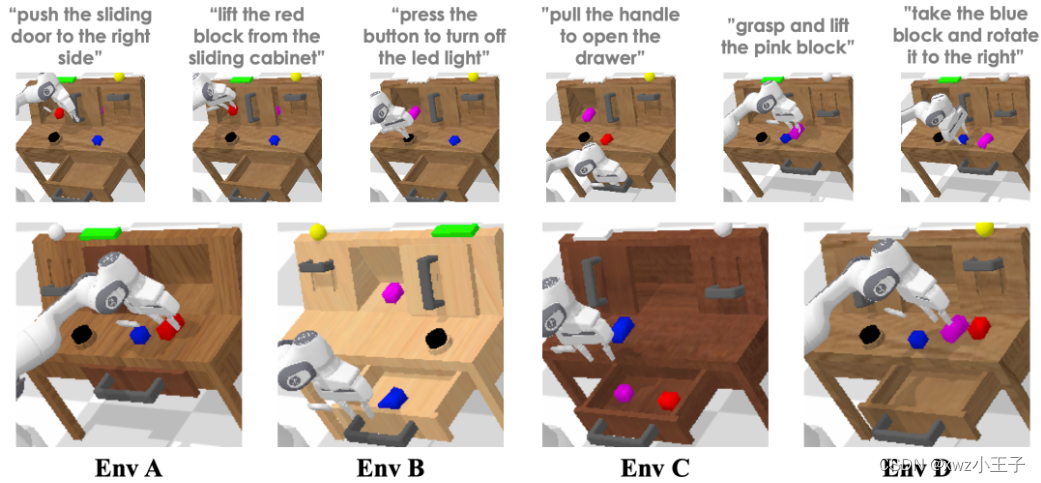
在 ABCD->D 实验中,机器人在来自 A, B, C, D 四个环境的数据上训练,并在 D 中测试。在 ABC->D 实验中,机器人在来自 A, B, C 三个环境的数据上训练,并在 D 中测试。这个实验旨在测试 GR-1 应对零样本场景迁移的能力。测试中,机器人需要连续完成 5 个任务。表中展示了不同方法在连续完成 1,2,3,4,5 个任务的成功率和平均完成的任务数量。GR-1 在两个实验中都超过了现有方法并在零样本场景迁移上大幅领先。
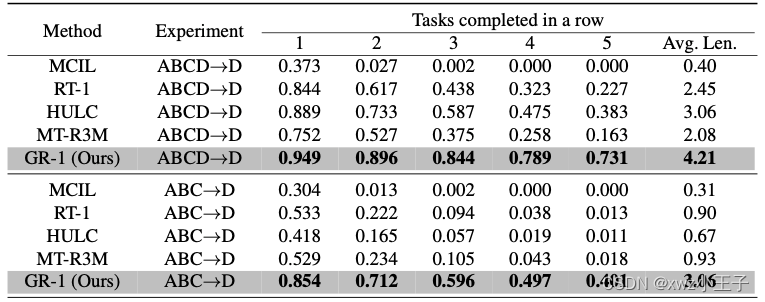
该工作还进行了小数据集的实验以理解 GR-1 在数据比较少的时候的表现。在 10% data 实验中,作者把 34 个任务中的每个任务的训练轨迹控制在 66 条。总轨迹数约为 ABCD->D 实验中的 10%。为了测试 GR-1 应对未知语言的能力,作者用 GPT-4 为每个任务生成了 50 条新的未见过的语言指令来测试。GR-1 在小数据集和未知语言指令的设置中都超越了现有方法。
GR-1 真机实验包括了移动物体和开关抽屉,如下图所示:
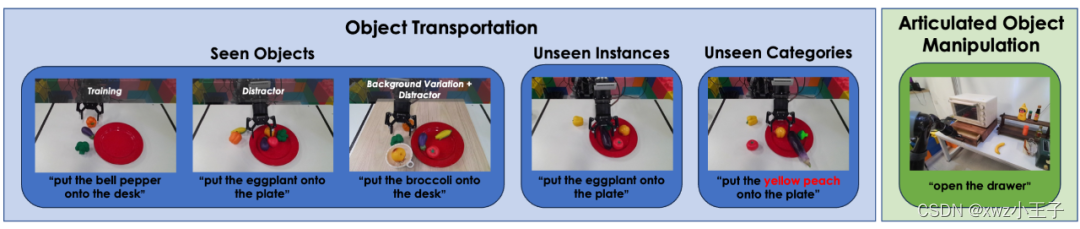
移动物体实验指令包括将物体移动到盘子 / 桌面上。训练数据中包括移动一个茄子、西兰花和彩椒(如上图最左所示)。作者首先在这些训练数据中见过的物体上做实验。在这个设置下,作者还测试了加入了干扰物和背景变化的实验。

作者还在训练数据中未见过的物体上做了实验。未见的物体包括未见过的物体实例(一组在训练数据中未见过的茄子、西兰花和彩椒)和未见过的物体种类(西红柿和黄桃)。

以下为开关抽屉的实验:

如下表所示,GR-1 在真机实验中大幅领先对比的现有方法。
在消融实验中,作者对比了去掉未来帧预测和保留未来帧预测但去掉预训练的模型的能力。结果表明预测未来帧和预训练两者都对 GR-1 学习鲁棒的机器人操作起到了关键作用。在预测动作的同时加入未来帧的预测能帮助 GR-1 学习根据语言指令来预测未来场景变化的能力。这种能力正是机器人操作中需要的:根据人的语言指令来预测场景中应用的变化能够指导机器人动作的生成。而大规模视频数据的预训练则能帮助 GR-1 学习鲁棒可泛化的预测未来的能力。
结论
GR-1 首次证明了大规模视频生成式预训练能帮助机器人学习复杂的多任务操作。GR-1 首先在大规模视频数据上预训练然后在机器人数据上进行微调。在仿真环境和真机实验中,GR-1 都取得了 SOTA 的结果,并在极具挑战的零样本迁移上表现出鲁棒的性能。