文章目录
- 1、垃圾回收器
- 2、Serial + Serial Old
- 3、ParNew回收器
- 4、CMS回收器
- 5、Parallel Scavenge + Parallel Old
- 6、G1垃圾回收器
- 7、G1的回收流程:Young GC
- 8、G1的回收流程:Mixed GC
- 9、回收器的选择
1、垃圾回收器
对回收算法落地,出现了多种垃圾回收器:
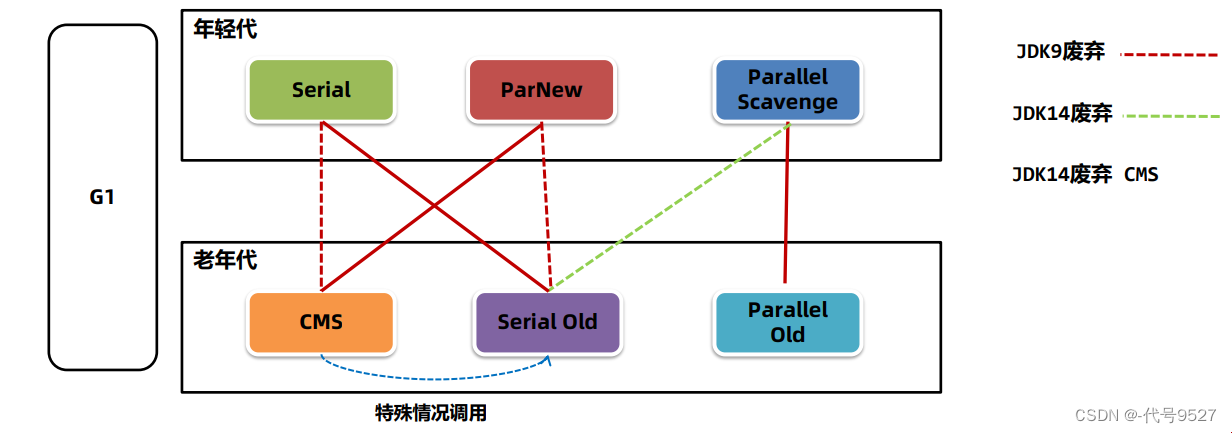
搭配有:
- G1用于年轻代和老年代
- Serial + Serial Old
- ParNew + CMS
- Parallel Scavenge + Parallel Old
图中虚线为对应版本的废弃组合。
2、Serial + Serial Old
Serial:
- 串行、单线程的年轻代垃圾回收器
- 算法:复制算法
- 优点:单CPU下吞吐高
- 缺点:堆内存大时,会让用户线程长期等待,多CPU下性能差
- 场景:单CPU,硬件配置有限

Serial Old:
- Serial回收器的老年代版本
- 依旧串行、单线程回收
- 算法:标记整理算法
添加JVM参数:
-XX:+UseSerialGC
新生代、老年代即使用Serial + Serial Old回收器组合。
3、ParNew回收器
- 实质是对Serial在多CPU下的优化,作用于年轻代
- 使用多线程进行垃圾回收
- 算法:复制
- 优点:多CPU下STW时间短
- 缺点:回收过程相对粗暴,吞吐和STW都不如G1
- 场景:搭配老年代的CMS
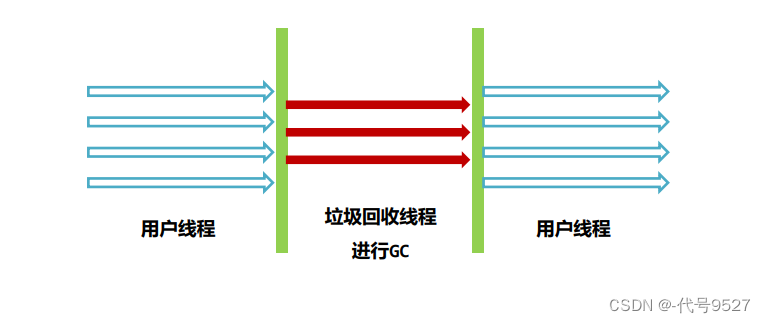
添加JVM参数:
-XX:+UseParNewGC
此参数对应的组合是:ParNew + Serial Old(已过时的组合)

4、CMS回收器
- Concurrent Mark Sweep
- 老年代的回收器
- 算法:标记清除算法
- 优点:STW时间短
- 场景:用户请求数据量大、频率高的场景,比如订单接口、商品接口等
CMS步骤:
- 初始标记:标记和GC Root 直接关联 的对象(不是遍历所有的引用链,因此耗时极短),此过程STW
- 并发标记:并发标记所有对象,此过程不用暂停用户线程(不用STW)
- 重新标记:上面并发时,有些对象的状态发生了变化,可能漏标或者错标(死了的又活了,活着的快死了),需要重标,此过程STW(但大部分对象上一步并发标记已经处理完了,漏标的占少数,所以这步STW时间短)
- 并发清理:清理死亡对象,用户线程不用暂停(不用STW)
整个过程,有两个步骤需要STW,而这两步又耗时最短,因此,CMS的SWT短
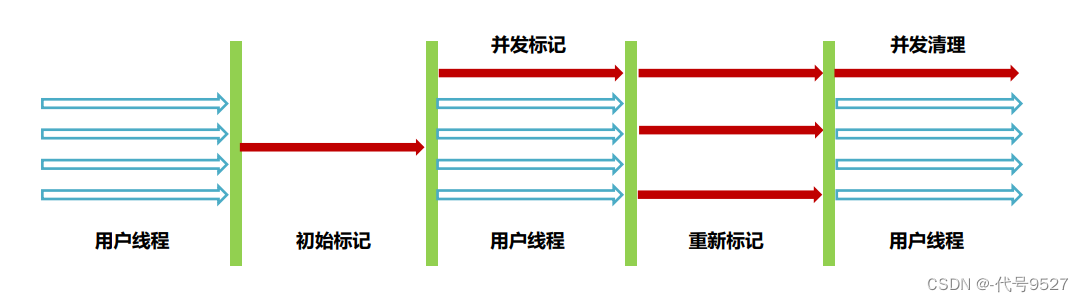
CMS的缺点:
- 内存碎片化问题:标记清除算法下产生的,CMS垃圾回收器会在Full GC后进行碎片整理,此过程STW
//调整多少次Full GC后进行整理
-XX:CMSFullGCsBeforeCompaction=N 参数(默认0)
- 浮动垃圾问题:最后一步并发清理的时候,用户线程可能又产生了垃圾,这些只能等下波了
- 退化问题:老年代内存不足时,会退化为Serial Old
- 线程资源争抢问题:一定的CPU核数下,并发时,CMS标记或清理线程多了,其余执行用户代码的线程就少了(CMS并发线程数可设置)

基于以上缺点,JDK14后废弃CMS。添加JVM参数:
-XX:+UseParNewGC -XX:+UseConcMarkSweepGC
新老两块的回收器搭配就是ParNew + CMS
5、Parallel Scavenge + Parallel Old
Parallel Scavenge:
- JDK8默认的年轻代垃圾回收器
- 多线程并行回收,关注吞吐量(用户代码执行时间/用户时间+GC时间)
- 可自动调整堆的大小
- 算法:复制算法
- 优点:吞吐量高且开发者可控吞吐(JVM动态调整堆的大小来满足设置的吞吐)
- 缺点:不保证单次停顿时间(STW不保证)
- 场景:用于大数据的处理、大文件的导出(和用户没交互,容易产生大量对象)
Parallel Old:
- Parallel Scavenge的老年代版本
- 依旧多线程
- 算法:标记清除、整理
添加如下JVM参数,可以使用Parallel Scavenge + Parallel Old组合:
-XX:+UseParallelGC 或
-XX:+UseParallelOldGC
最大暂停时间参数:
//毫秒
-XX:MaxGCPauseMillis=n
吞吐的设置:
-XX:GCTimeRatio=n
//吞吐为n,则用户线程执行时间 = n/n + 1,n=99,则99%的时间执行用户代码
开启自动调整内存大小(默认):
//JVM根据吞吐和STW最大时间自动调整堆大小
-XX:+UseAdaptiveSizePolicy
注意最大时间和吞吐两项是矛盾的,最大暂停时间极小,吞吐量又设置很大,后者可能得不到保证。添加如下JVM参数,程序启动的时候,打印所有配置项的值:
-XX:+PrintFlagsFinal
指定使用PS+PO组合,看下他们的默认配置:发现默认吞吐为99,即用户线程执行99%的时间,执行GC时间占1%,最大暂停时间则很大,相当于没有设置



PS:
//终端执行以下指令,打印默认参数配置项
java -XX:+PrintCommandLineFlags -version

6、G1垃圾回收器
关于G1:
- G1,Garbage First,作用于年轻代+老年代
- JDK9之后的默认垃圾回收器
- 支持多CPU并行垃圾回收
- 可设置最大停顿时间(最大的STW)
- 算法:复制算法
优点:
- 巨大的堆空间下回收也有高吞吐
- 不会产生内存碎片
缺点:
- JDK8之前带的G1还不够完善
G1前,堆内存的划分是连续的
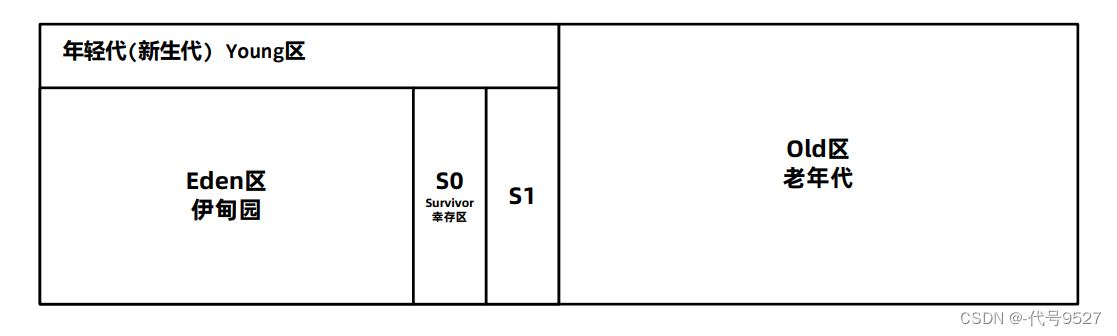
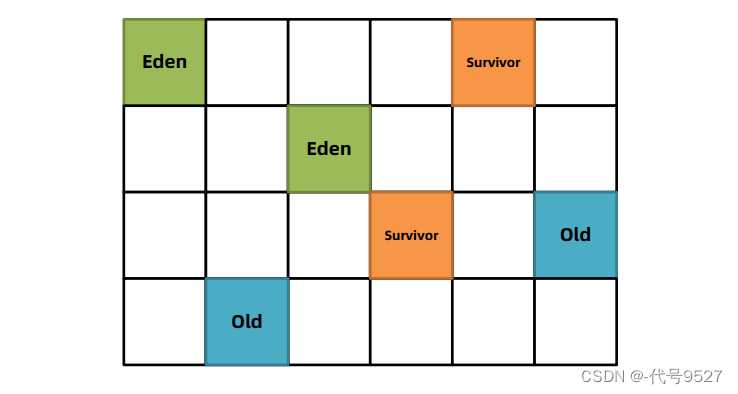
G1下,堆被分为一块块大小相等的区Region:
- 划分不再要求连续,比如下面两部分绿色的Eden
- 每块面积默认 = 堆空间大小/2048
-XX:G1HeapRegionSize=32m可设置每块的大小,但值必须为2次幂,且在1~32之间(2、4、8、16、32)- 相对应的回收:年轻代回收(Young GC)、混合回收(Mixed GC)
使用G1需要添加JVM参数(JDK9及以后版本不用):
-XX:+UseG1GC
设置最大暂停时间:
-XX:MaxGCPauseMillis=毫秒值
7、G1的回收流程:Young GC
- 对象新new出来依旧安置到年轻代的Eden区
- G1判断出年轻代超过堆的max值(默认60%)时,触发Young GC
- 标记Eden + 幸存区的存活对象
- 根据开发者配置的最大暂停时间,选择性的将其中某一部分区域A中存活对象复制到新的幸存者区(对象头年龄+1),清空区域A
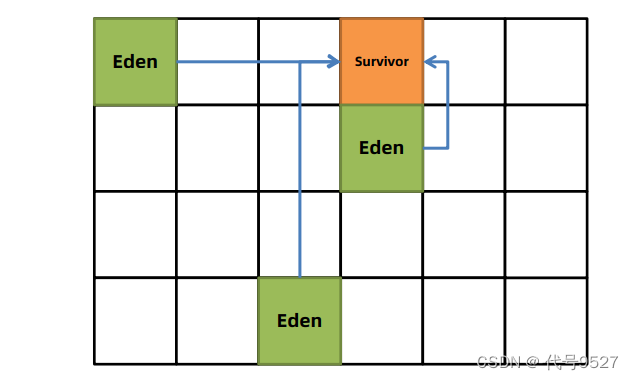
⚫ 这个选择一部分区域的实现思路是:G1下的Young GC,会记录回收每个区Region(Eden和幸存者区)的平均耗时,做为下次回收的依据,默认-XX:MaxGCPauseMillis=200,如果计算每块Region平均耗时为40ms,则每次触发Young GC时,就最多干掉四块
- 后续再触发GC,就是把Eden和上次的S区存活对象复制到另一块S区
- 某个对象年龄到达阈值(默认15),依旧放入老年代
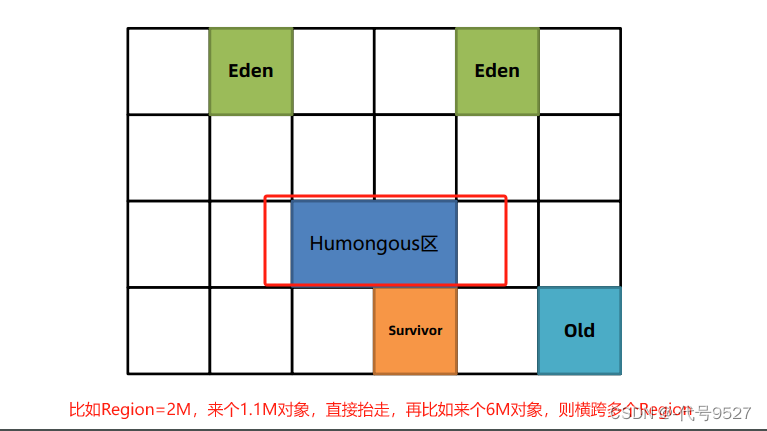
- 此外,对象大小超过50%的Region空间时,直接进老年代(这类特殊的老年代叫Humongous区)
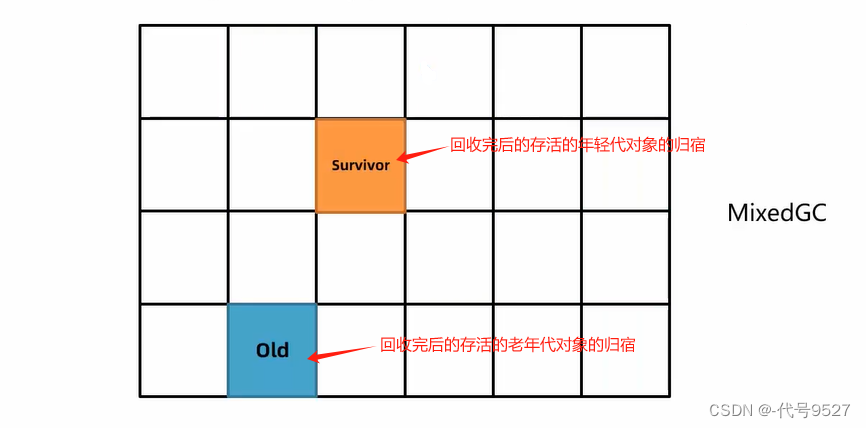
- 多次回收后,当堆的使用率达到阈值,触发混合回收MixedGC,用复制算法回收一轮所有年轻代、部分老年代、大对象区
//阈值默认45%,可改
-XX:InitiatingHeapOccupancyPercent默认45%
8、G1的回收流程:Mixed GC
- 初始标记(initial mark)
- 并发标记(concurrent mark)
- 最终标记(remark或者Finalize Marking)
- 并发清理(cleanup)
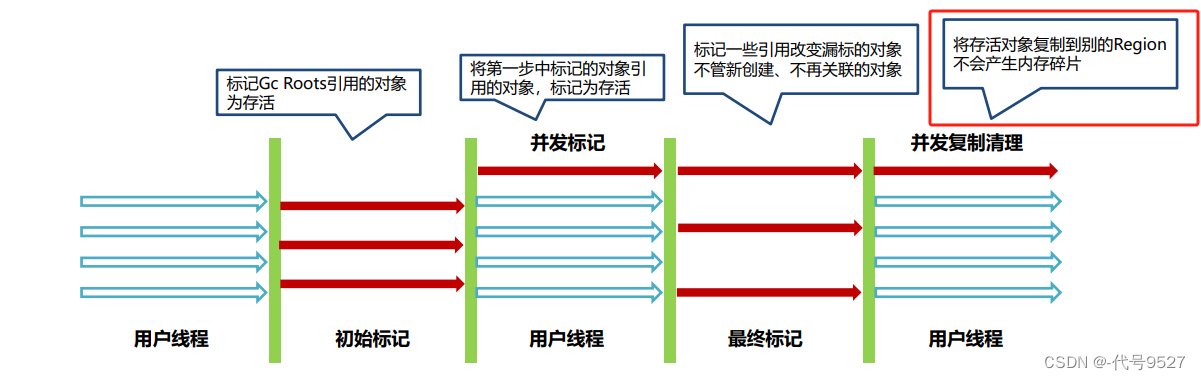
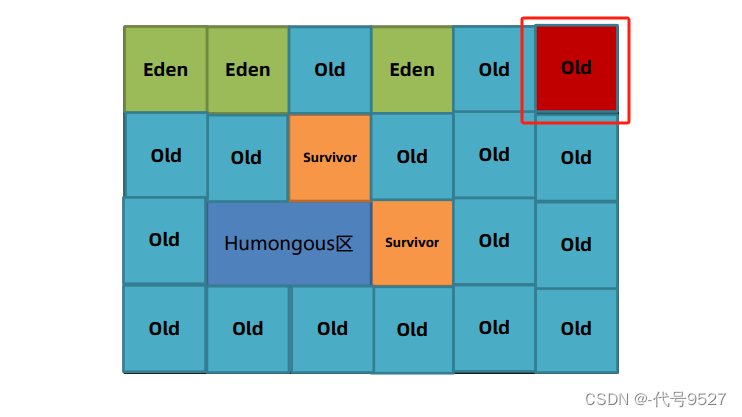
注意和CMS的区别,流程像,但干的活儿不一样,且最后清理时,采用的算法也不一样。此外,G1对老年代的清理会选择存活度最低的区域来进行回收,以保证回收效率。
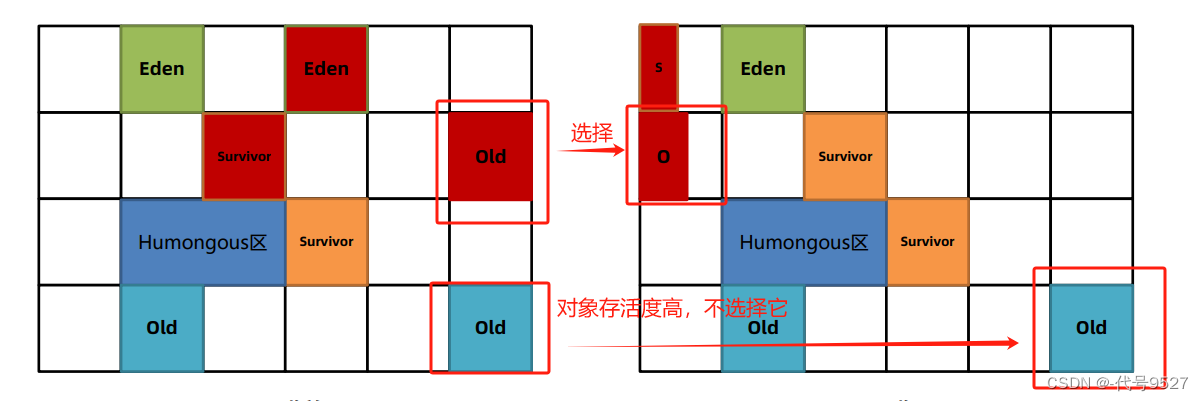
最后,因为清理是复制算法,如果清理时发现没有空Region去存放转移的对象(没地儿复制了),则转为单线程执行标记-整理算法进行Full GC,此时会导致用户线程的暂停。
9、回收器的选择
JDK8及之前:
- 关注暂停时间:选ParNew + CMS
- 关注吞吐:Parallel Scavenge + Parallel Old
JDK9及以后:
- G1,适用较大堆并且关注暂停时间






![[答疑]漏斗图,领域驱动设计叒创新了?](https://img-blog.csdnimg.cn/img_convert/975ef8bc3c255ec040cecdfab4554c7c.png)