力扣labuladong一刷day54天前缀树
文章目录
- 力扣labuladong一刷day54天前缀树
- 一、208. 实现 Trie (前缀树)
- 二、648. 单词替换
- 三、211. 添加与搜索单词 - 数据结构设计
- 四、1804. 实现 Trie (前缀树) II
- 五、677. 键值映射
一、208. 实现 Trie (前缀树)
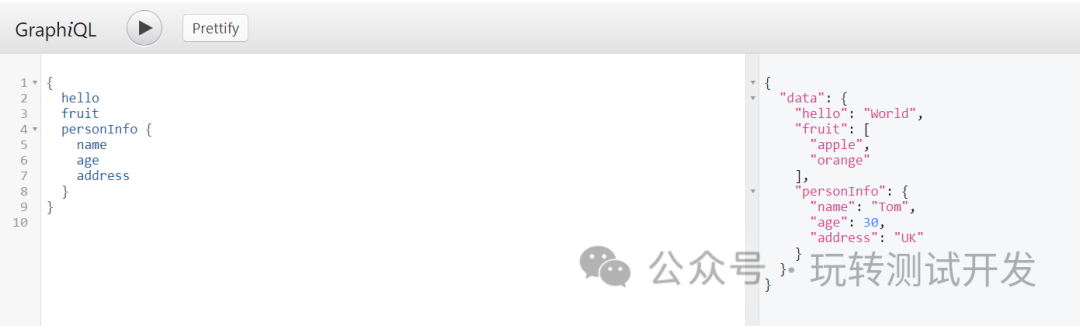
题目链接:https://leetcode.cn/problems/implement-trie-prefix-tree/description/?utm_source=LCUS&utm_medium=ip_redirect&utm_campaign=transfer2china
思路:类似于下图就是前缀树,本质是多叉树,只不过表示子节点的数组是通过字母进行索引的,叶子节点有值来表示。

class Trie {
Node root = null;
class Node{
int v = 0;
Node[] child = new Node[26];
}
public Trie() {
}
public void insert(String word) {
if (search(word)) {
return;
}
root = addNode(root, word, 0);
}
public boolean search(String word) {
Node node = getNode(root, word);
if (node == null || node.v == 0) {
return false;
}
return true;
}
public boolean startsWith(String prefix) {
return getNode(root, prefix) != null;
}
Node getNode(Node node, String word) {
Node p = node;
for (int i = 0; i < word.length(); i++) {
if (p == null) {
return null;
}
p = p.child[word.charAt(i)-'a'];
}
return p;
}
Node addNode(Node node, String word, int i) {
if (node == null) {
node = new Node();
}
if (i == word.length()) {
node.v = 1;
return node;
}
int c = word.charAt(i) - 'a';
node.child[c] = addNode(node.child[c], word, i+1);
return node;
}
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* boolean param_2 = obj.search(word);
* boolean param_3 = obj.startsWith(prefix);
*/
二、648. 单词替换
题目链接:https://leetcode.cn/problems/replace-words/description/?utm_source=LCUS&utm_medium=ip_redirect&utm_campaign=transfer2china
思路:和上题一样,也是前缀树的应用,只不过多了一个最短前缀替换。
class Solution {
public String replaceWords(List<String> dictionary, String sentence) {
Trie trie = new Trie();
for (String s : dictionary) {
trie.insert(s);
}
String[] split = sentence.split(" ");
StringBuilder bf = new StringBuilder();
for (String s : split) {
String ms = trie.minSearch(s);
if ("".equals(ms)) {
bf.append(s);
}else {
bf.append(ms);
}
bf.append(" ");
}
bf.deleteCharAt(bf.length()-1);
return bf.toString();
}
class Node {
int v = 0;
Node[] child = new Node[26];
}
class Trie {
Node root = null;
void insert(String word) {
root = addNode(root, word, 0);
}
String minSearch(String word) {
Node p = root;
for (int i = 0; i < word.length(); i++) {
if (p == null) return "";
if (p.v == 1) {
return word.substring(0, i);
}
p = p.child[word.charAt(i)-'a'];
}
if (p != null && p.v == 1) return word;
return "";
}
boolean search(String word) {
Node node = getNode(word);
if (node == null || node.v == 0) return false;
return true;
}
Node getNode(String word) {
Node p = root;
for (int i = 0; i < word.length(); i++) {
if (p == null) return null;
p = p.child[word.charAt(i)-'a'];
}
return p;
}
Node addNode(Node node, String word, int i) {
if (node == null) {
node = new Node();
}
if (i == word.length()) {
node.v = 1;
return node;
}
int c = word.charAt(i)-'a';
node.child[c] = addNode(node.child[c], word, i+1);
return node;
}
}
}
三、211. 添加与搜索单词 - 数据结构设计
题目链接:https://leetcode.cn/problems/design-add-and-search-words-data-structure/description/
思路:本题还是前缀树,和上一题类似,唯一不同的点是多了一个模式串匹配。
class WordDictionary {
Node root = null;
public WordDictionary() {
}
public void addWord(String word) {
root = addNode(root, word, 0);
}
public boolean search(String word) {
return traverse(root, word, 0);
}
boolean traverse(Node node, String word, int i) {
if (node == null) return false;
if (i == word.length()) {
return node.v == 1;
}
if ('.' == word.charAt(i)) {
for (int j = 0; j < 26; j++) {
boolean flag = traverse(node.child[j], word, i + 1);
if (flag) return flag;
}
}else {
return traverse(node.child[word.charAt(i)-'a'], word, i+1);
}
return false;
}
Node addNode(Node node, String word, int i) {
if (node == null) {
node = new Node();
}
if (i == word.length()) {
node.v = 1;
return node;
}
int c = word.charAt(i)-'a';
node.child[c] = addNode(node.child[c], word, i+1);
return node;
}
}
class Node {
int v;
Node[] child = new Node[26];
}
/**
* Your WordDictionary object will be instantiated and called as such:
* WordDictionary obj = new WordDictionary();
* obj.addWord(word);
* boolean param_2 = obj.search(word);
*/
四、1804. 实现 Trie (前缀树) II
题目链接:https://leetcode.cn/problems/implement-trie-ii-prefix-tree/description/?utm_source=LCUS&utm_medium=ip_redirect&utm_campaign=transfer2china
思路:本题的前缀树多增加了一个功能就是删除节点,删除节点要考虑的就比较多了,到达value的位置要把数量减一,然后在后序位置删除,如果值大于0直接返回就行,不用删除节点,如果值不大于0就需要看该节点的child是否全为null,如果是返回Null就删除了,不是的话保留。
class Trie {
Node root;
public Trie() {
}
public void insert(String word) {
root = addNode(root, word, 0);
}
public int countWordsEqualTo(String word) {
Node node = getNode(word);
if (null == node) return 0;
return node.v;
}
public int countWordsStartingWith(String prefix) {
Node node = getNode(prefix);
if (node == null) return 0;
return traverse(node, 0);
}
public void erase(String word) {
if (getNode(word) == null) return;
root = deleteNode(root, word, 0);
}
Node deleteNode(Node node, String word, int i) {
if (node == null) return null;
if (i == word.length()) {
if (node.v > 0) node.v--;
}else {
int c = word.charAt(i)-'a';
node.child[c] = deleteNode(node.child[c], word, i+1);
}
if (node.v > 0) return node;
for (int j = 0; j < 26; j++) {
if (node.child[j] != null) {
return node;
}
}
return null;
}
int traverse(Node node, int num) {
if (node == null) return 0;
num = node.v;
for (int i = 0; i < 26; i++) {
num += traverse(node.child[i], num);
}
return num;
}
Node addNode(Node node, String word, int i) {
if (node == null) {
node = new Node();
}
if (i == word.length()) {
node.v += 1;
return node;
}
int c = word.charAt(i)-'a';
node.child[c] = addNode(node.child[c], word, i+1);
return node;
}
Node getNode(String word) {
Node p = root;
for (int i = 0; i < word.length(); i++) {
if (p == null) return null;
p = p.child[word.charAt(i)-'a'];
}
return p;
}
}
class Node{
int v = 0;
Node[] child = new Node[26];
}
/**
* Your Trie object will be instantiated and called as such:
* Trie obj = new Trie();
* obj.insert(word);
* int param_2 = obj.countWordsEqualTo(word);
* int param_3 = obj.countWordsStartingWith(prefix);
* obj.erase(word);
*/
五、677. 键值映射
题目链接:https://leetcode.cn/problems/map-sum-pairs/description/?utm_source=LCUS&utm_medium=ip_redirect&utm_campaign=transfer2china
思路:关键点是前缀查询,先获取到前缀的节点,然后广度优先遍历,前序位置记录节点位置。
class MapSum {
Node root = null;
public MapSum() {
}
public void insert(String key, int val) {
root = addNode(root, key, val, 0);
}
public int sum(String prefix) {
Node node = getNode(prefix);
if (node == null) return 0;
return traverse(node, 0);
}
int traverse(Node node, int num) {
if (node == null) return 0;
num = node.v;
for (int i = 0; i < 26; i++) {
num += traverse(node.child[i], num);
}
return num;
}
Node getNode(String word) {
Node p = root;
for (int i = 0; i < word.length(); i++) {
if (p == null) return null;
p = p.child[word.charAt(i)-'a'];
}
return p;
}
Node addNode(Node node, String word, int value, int i) {
if (node == null) {
node = new Node();
}
if (i == word.length()) {
node.v = value;
return node;
}
int c = word.charAt(i) - 'a';
node.child[c] = addNode(node.child[c], word, value, i+1);
return node;
}
}
class Node {
int v = 0;
Node[] child = new Node[26];
}
![[答疑]漏斗图,领域驱动设计叒创新了?](https://img-blog.csdnimg.cn/img_convert/975ef8bc3c255ec040cecdfab4554c7c.png)









![[AutoSar]基础部分 RTE 05 Port的实例化和初始化](https://img-blog.csdnimg.cn/direct/bd03a146e3c74accaf19538dcb1261ef.png)