近日,2023 CCF国际AIOps挑战赛决赛暨“大模型时代的AIOps”研讨会在北京成功举办,活动吸引了来自互联网、运营商、科研院所、高校、软硬件厂商等领域多名专家学者参与,为智能运维的前沿学术研究、落地生产实践打开了新思路。决赛中,从初赛两百多支队伍中脱颖而出的十支入围队伍分别展示了各自的方案,并进行了现场答辩,评审专家从选题方向、创新性、实用性、完整度和实验复现结果等多角度进行了综合评定,最终,来自字节跳动基础架构-SRE 团队的 SRE-Copilot战队,以“SRE-Copilot:基于 LLM 的多场景智能运维”,获得本届大赛冠军。

CCF国际AIOps挑战赛由中国计算机学会(CCF)、清华大学和南开大学联合发起,旨在借助社区力量,运用人工智能算法解决各类运维难题。自2017年底首次举办,迄今为止已经成功举办六届,吸引了大量AIOps从业者和关注者,赛事规模和影响力不断扩大,是智能运维领域极具影响力的专业赛事。本届CCF国际AIOps挑战赛共有来自265支队伍的677名选手报名参赛,决赛现场有超300人线下参会,同时有近5万人次观看线上直播。
CCF国际AIOps挑战赛自创办以来,赛题覆盖了不同的运维场景、运维数据、故障来源、应用类型。本届大赛赛题全新升级,首次采用开放式赛题,基于建行云龙舟运维平台的稳定性工具和多维监控系统,由参赛选手自主确定需要解决的运维问题,并对主办方提供的交易、日志、调用链、监控指标等一种或多种模态数据进行故障检测、定位、根因分析、影响分析等。本次赛题不再局限于单个运维场景,而是模拟了企业运维团队面临的系统架构复杂、数据规模庞大、数据种类繁多等一系列需要解决的运维挑战,使AIOps生态里的所有产、学、研、用各方,都可以基于同样的数据,展开竞赛,并鼓励参赛选手探索大语言模型(LLM)在智能运维领域的应用。
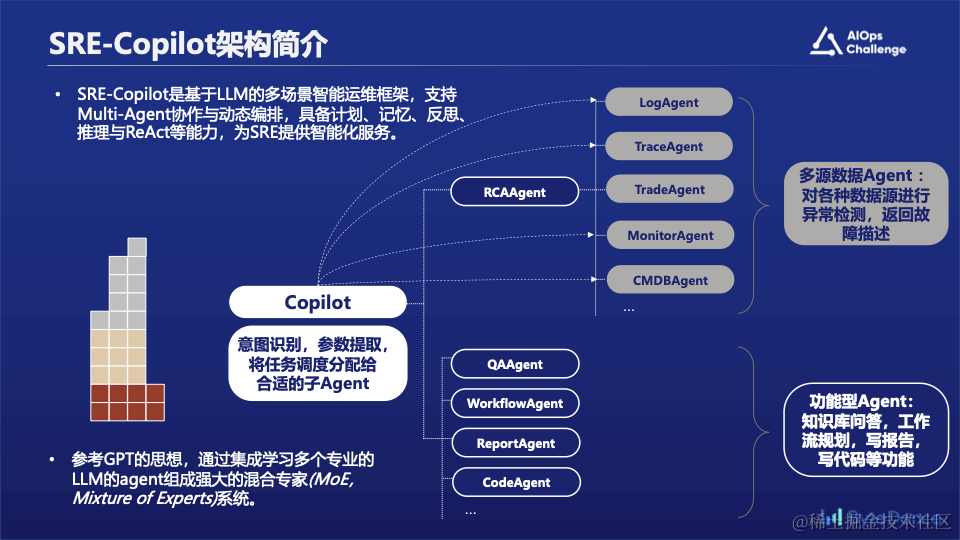
为拥抱这一变化,SRE-Copilot战队提出了一套基于大语言模型的多场景智能运维框架——SRE-Copilot,该框架参考了GPT的思想,即通过集成学习的方式,用多个专业的子Agent组合成强大的混合专家(MoE,Mixture of Experts)系统,支持多个智能体Agent的协作与动态编排调度,有计划、记忆、反思与推理等能力,为SRE提供智能化服务,切实提升SRE工作效率。其技术性和创新性主要体现在以下几个方面:
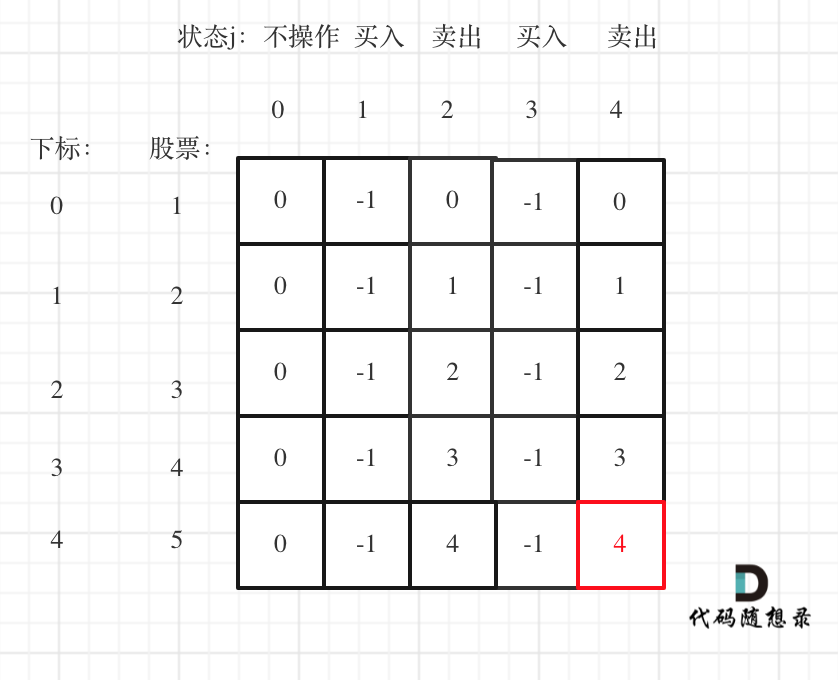
1、基于 ReAct 框架和CoT思维链的 Multi-Agent 编排调度,实现了多模态数据按需异常检测
ReAct的思想参考自论文ReAct: Synergizing Reasoning and Acting in Language Models,包括推理(Reasoning)和行动(Action),推理帮助模型生成、追踪和更新计划并处理异常,行动允许模型与外部环境交互以获取更多信息Observation,提升准确率与适应性。

在异常检测场景中,首先定义多数据源Agent,分别负责选择合适的算法对不同模态数据进行异常检测与检索,主持人Copilot负责解析用户意图,RCAAgent负责收集其他Agent检测到的异常结果与链路、配置信息,进行根因定位。如上图所示,用户提问中提到“交易大量失败”,此时模型会将问题交给负责交易数据的TradeAgent进行检测,TradeAgent检测得出“交易性能下降”,则问题会进一步交给负责性能数据的MonitorAgent。通过这种模式,将排障流程进行下去,每个Agent的检测顺序及内容均根据检测到的异常动态编排。RCAAgent负责收敛协作轮次,并根据反馈决定下一步分析与下钻的方向,当没有额外信息时,就会停止检测,进行根因定位。
SRE-Copilot模拟了真实的大规模云平台跨组件协同定位,利用多个Agent替代多个组件运维团队,发挥各自所长,并动态编排决定排查方向;同时,SRE-Copilot更关注多个组件(多个数据)的表现形态,而非根据单一组件(单一数据)判断是否异常,降低噪声,具有更高的鲁棒性。
2、基于 RAG 检索增强的框架进行根因推理
检索增强生成 (RAG) 是使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(用于搜索大型数据集或知识库)和生成模型(使用检索到的信息生成可供阅读的文本回复)结合在一起,通过从更多数据源添加背景信息,比如训练 LLM 时并未用到的互联网上的新信息、专有商业背景信息或者属于企业的内部文档等,来补充LLM原始知识库,改善大型语言模型的输出,使生成的答案更可靠,还有助于缓解“幻觉”问题,且不需要重新训练。
根因定位过程主要包含以下过程:
知识库构建:需要提前定义一些专家诊断经验和历史故障库,并将信息转化为高维度空间中的向量,存储在向量数据库中。专家经验可以由运维工程师或者业务专家来定义,比如:流量突增,内存打满,服务不可用,对应的可能是大量访问带来的问题,此时应该扩容或重启等。
RAG检索增强:使用异常检测生成的故障摘要作为输入,对历史故障、专家经验、知识库文档等进行检索,检索的TopN结果作为上下文和原始提示词组合,再提交给LLM进行根因定位。LLM的参数化知识是静态的,RAG让LLM不用重新训练就能获取最新相关信息,提升了模型的准确性和实时性。
推理与反思:由于本次比赛使用的是6b的小模型(兼容本地化部署环境),推理稳定性较差,因此引入“反思”机制,让模型对自己诊断的根因进行再次判断,进一步提高了根因定位的准确度。
学习新的策略:每次诊断结果既会生成诊断报告,也会加入模型记忆,再次诊断时对最相近的专家经验与诊断结果进行推理,让模型获得持续学习与迭代的能力。
基于RAG,即使是小模型,在没有专家经验和历史故障的输入时,仍然能对一些简单问题进行根因推断,例如:磁盘写满故障、java虚拟机GC问题等等。通过让模型进行自我评估和自我反省,能够将模型推理根因的准确率进一步提升30%以上 。模型在诊断过程中能够不断迭代、持续学习,随着学习和推理的逐渐完善,SRE-Copilot故障诊断的能力也将不断提升。
3、沿着稳定性全生命周期管理,提供多种运维能力

基于大语言模型使用tools的能力,把散落的各个运维场景进行统一集成,理解、拆分用户意图,编排调用不同工具,提供稳定性建设全流程的智能运维能力。用户可通过自然语言提问方式使用SRE-Copilot框架的以下运维能力:
运维计划:解析用户运维需求,生成自然语言的工作流,并从系统可调用的组件中选择合适组件,动态生成可执行的工作流;
运维可视化:通过自然语言交互,自动执行简易的数据查询/分析,对故障数据进行可视化;
异常检测:支持多模态数据类型,灵活拓展,通过多Agent协同编排,整合不同平台数据,极大缩短MTTR;
根因定位:无监督,支持专家经验、历史故障输入,对已知故障准确率高,对于未知故障可推理;
故障分类:根据专家经验和历史故障所属类别,以及本次故障表现,对故障进行分类,有助于后续按组织或改进措施推进复盘与优化;
故障自愈:在推理得到故障根因和故障分类后,可以推荐合适的自愈措施,流程自动化,让运维人员集中精力,无需频繁切换上下文,确保响应和处理的及时性和准确性 ;
代码生成:基于用户的提示生成代码,将复杂脚本的调试开发时间从几小时缩短到几分钟;
故障报告:利用LLM自动生成故障诊断报告,以自然语言方式表述5W问题:When-Where-Who-What-Why,显著提升故障诊断报告的效率与质量,方便团队积累经验和知识库 ;
知识库问答:基于本地知识库进行私域知识问答,提升应答准确率,减少Oncall系统人力投入。
综上所述,SRE-Copilot框架将大语言模型引入AIOps领域,解决了一些传统AIOps的痛点问题,具有以下优势:
首先,当前各公司系统架构愈发复杂,各种组件依赖越来越多,很难有一个运维团队精通全部架构及组件的技术细节。而LLM可以学习近乎无限的知识,也可以通过设计多个专家Agent的方式进行编排调度无限拓展,读取、检测不同系统不同数据源的异常信息,并将多模态异常都转化为LLM可理解的半结构化或结构化语言形式,交由LLM分析诊断,提升了故障处理效率。
其次,传统AIOps算法大多是单场景、单AI、解决单个问题,且异常检测和根因诊断大部分算法都依赖于数据的标注。而LLM基于检索增强的方式,不需要或者很少用人工标注的数据进行训练,很大程度上解决了传统AIOps领域人工标注的成本高、周期长、精确度受限等问题,减少了训练所需的数据量。
同时,在接入维护方面,传统AIOps当遇到新客户、私域知识、业务经验、数据变动等情况时,通常只能重新训练,而LLM的泛化能力、自监督学习能力与交互形式,让开发者与客户可以一定程度上松耦合:开发者降低了对客户数据的依赖程度,用统一的大模型或预训练的行业大模型,就能解决客户大部分问题;而客户仅需要了解自己的系统逻辑,通过简单微调就能获得模型的通用能力,通过多Agent的方式,甚至可以将自己的逻辑经验轻松接入,降低了接入成本。
接着,LLM已经在其他领域出现了涌现和推理能力,通过对通用知识的学习,可以对未知故障进行推断,人工确认后加入知识库或记忆来实现模型演进,这似乎是解决新故障诊断的最佳选择。
最后,LLM都是自然语言的形式交互,无需严格传参,降低了使用成本,其精调和上下文学习的语料也都是语言形式,业务SRE可以一起参与共建。
团队介绍:
基础架构-SRE,负责字节跳动基础架构部门所有组件的SRE工作,沿着成本、稳定性、效率、服务四条主线,致力于打造高扩展、高可用的生产系统。基础架构-SRE-数据化团队,负责SRE的数据化运营及智能化探索,数据化产品包括基础架构离线数仓与数据门户、资源交付数据化运营系统;智能化方向涵盖异常检测、智能变更、故障诊断、智能限流、运筹优化与大语言模型应用。协同和赋能SRE从DataOps向AIOps和ChatOps转变,是我们一直努力的方向。欢迎加入,共同探索大模型在智能运维领域中的落地应用:https://jobs.bytedance.com/experienced/position/7262287728477751589/detail








![[MySQL]视图索引以及连接查询案列](https://img-blog.csdnimg.cn/direct/ddfc2e01211c4935934e7daaf4cd67de.png)