本文由清华大学与腾讯 AI Lab、香港中文大学合作。 零样本说话人自适应(zero-shot speaker adaptation),或称为零样本声音克隆,旨在根据任意一条参考语音(reference speech)合成训练过程中从未见过的说话人(unseen speaker)的声音。 以往的工作大多从参考语音中提取一个 固定维度的向量 作为说话人表征,该思路虽然能较好地表示说话人的音色、整体说话方式,但其有限且粗粒度的信息限制了对说话人细节发音特点的建模和迁移能力。 针对该问题,本文提出了一种内容相关的细粒度说话人表征(Content-Dependent Fine-Grained Speaker Embedding, CDFSE)方法。 与以往的工作相比,该方法根据 输入待合成文本的实际发音内容 从参考语音中提取 音素级说话人表征序列 ,代替传统的全局/话语级定长说话人表征,以建模和迁移 目标说话人更加细节的声音风格和个人发音习惯 。 在 AISHELL-3 中文多说话人数据集上进行实验,主观和客观实验结果均表明所提方法相比于基线模型能够提升合成语音的说话人声音相似度,在未见说话人上效果显著、SMOS有 0.2以上 的提升。
扫码阅读论文
https://www.isca-speech.org/archive/interspeech_2022/zhou22d_interspeech.html
合成样例试听及开源代码获取
https://thuhcsi.github.io/interspeech2022-cdfse-tts/
01 背景动机
文本转语音(Text-to-Speech,TTS),又称为语音合成,旨在对给定文本生成接近人声的自然语音。 在具有充足且高质量的训练数据时,目前基于神经网络的TTS系统已能够合成流畅自然的语音波形; 但要是对每个新说话人都去录制收集满足该要求的训练语料,是非常昂贵且耗时费力的。 所以如何 仅用一个新说话人的少量语音样本让TTS模型学会合成该说话人的声音(说话人自适应,声音克隆) ,是当前学术界和工业界研究的热点。
对于该目标,现今的主流研究路线一般可分为两条: 1)对TTS模型整体或部分结构参数做 微调(fine-tuning) ; 2)对参考语音做 说话人编码(speaker encoding) ,提取其中的说话人信息来指导TTS模型。 前者主要探究如何更好地用新说话人的数据来调整TTS预训练模型的参数,代表作如AdaSpeech系列。 该类微调方法一般可以达到相对可观的合成质量,但也存在着一些缺陷,包括需要额外的训练时间和参数、自适应效果受限于语音样本数量等。 而后者则不受这些限制,说话人编码方法可以从任意说话人提供的一条参考语音中提取说话人表征,然后直接传递给TTS模型做实时推理。 当参考语音来自于训练阶段从未见过的说话人时称之为 零样本说话人自适应(zero-shot speaker adaptation) ,或称为零样本声音克隆,这种场景显然更具有泛用性和吸引力,当然也更有挑战性。 这方面的研究有很多,它们大多集中于如何设计合适的说话人编码器,以从参考语音中提取构建更有效、更具泛化性的说话人表征。
但我们发现,目前的方法大多仍是从参考语音中提取一个固定维度的定长向量作为说话人表征,该思路虽然能较好地表示说话人的音色或整体说话方式,但还存在缺陷—— 因为一个人的声音特点不仅指整体性的音色风格,还包括一些更加细粒度的局部发音习惯,比如在某些发音咬字上具有鲜明的个人特色 。 目标说话人提供的参考语音中实际上蕴含着这些丰富信息,而只用单一向量来描述它们显然不够全面,并且由于TTS模型未见过该说话人、也很难仅依靠单一向量来推断出很多具体的个人发音细节,这就导致在听感上合成语音与目标说话人的声音相似度不尽人意。 另外,尽管也有方法考虑了更加细粒度的说话人表征,如Attentron提出了一种基于注意力的变长嵌入(variable-length embedding)方法,但它只是从参考语音中简单地抽取了一组嵌入序列,并未显现出迁移个人细节发音模式、发音习惯的能力。
02贡献
本文提出了一种与发音内容相关的细粒度说话人表征方法,以提升语音合成零样本说话人自适应的说话人声音相似度。 与以往的工作相比,该方法根据输入待合成文本的实际发音内容从参考语音中提取音素级说话人表征序列,代替传统的全局/话语级单一说话人表征,以建模和迁移目标说话人更加细节的声音风格和个人发音习惯。 具体而言,该方法首先通过下采样编码器从参考语音中提取一组成对的局部内容嵌入和局部说话人嵌入; 然后,基于TTS模型音素编码器输出(来自待合成文本)和局部内容嵌入(来自参考语音)的内容相关性,采用一个参考注意力模块获取与文本内容匹配的音素级细粒度说话人表征序列,并将其作用到音素编码器输出的序列上; 此外,为了避免参考注意力模块误建模文本与音频的时序相关性,在训练时引入对参考语音mel谱按音素边界分割、随机打乱重排的操作。 在 AISHELL-3 上的主观及客观实验表明,所提的 CDFSE 能够提升合成语音的说话人相似度,特别是对于unseen speaker而言; 另外,样例分析也证实了该方法确实具有建模个人细粒度发音特点的能力。
03 解决方案
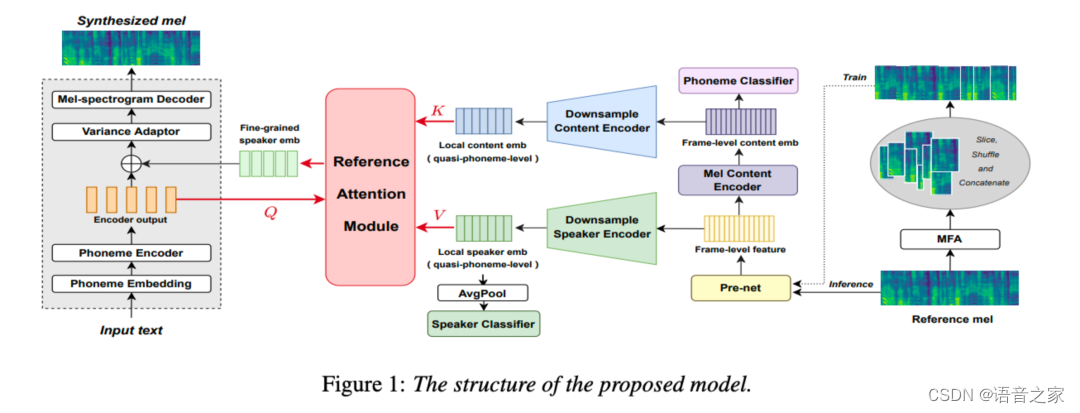
本文提出的模型如上图所示,为了有效建模细粒度说话人表征,我们基于 FastSpeech 2 声学框架额外扩展设计了几个音频编码器及一个参考注意力模块。 模型总体流程如下: 首先参考语音经过一系列编码器处理、提取出一组对应的局部内容嵌入和局部说话人嵌入,然后局部内容嵌入(作为key)和局部说话人嵌入(作为value)被送入参考注意力模块,与来自FastSpeech 2的音素编码器输出(作为query)进行注意力计算,得到音素级细粒度说话人表征,并被加回到音素编码器输出上送给方差适配器(Variance Adaptor),以合成与参考音频说话人声音一致的语音。
提取局部内容和局部说话人表示
为了建模和迁移个人细粒度声音特点,我们首先从参考语音mel谱中提取一组对应的局部内容嵌入和局部说话人嵌入。
如模型图中所示,参考语音的mel谱首先被传给由2个一维卷积层(包含512组滤波器,卷积核为5×1)组成的pre-net,得到帧级特征(frame-level feature)。 为了建模内容信息,帧级特征接着被传给由4个Transformer block组成的音频内容编码器(mel content encoder),得到帧级内容嵌入(frame-level content embedding),并且我们在其后接了一个音素分类器(phoneme classifier)用来做监督训练。 然后,帧级内容嵌入被传递给下采样内容编码器(downsample content encoder),同时之前的帧级特征被传递给下采样说话人编码器(downsample speaker encoder)。 这两个下采样编码器都由4个一维卷积层(分别包含128、256、512、512个滤波器,卷积核为3×1)和一个全连接输出层组成,并且每个卷积层后接一个核为2的平均池化层,即整个参考语音帧序列在时间维度上 缩减了16倍 ——这样可认为该序列变成了准音素级(quasi-phoneme level)。 局部内容嵌入(local content embedding)和局部说话人嵌入(local speaker embedding)分别从两个下采样编码器获得。 另外再用平均池化操作(average pooling)在时间维度上汇总局部说话人嵌入,后接一个说话人分类器(speaker classifier)监督训练。
由于局部说话人嵌入和局部内容嵌入是来自同一个参考语音、且具有完全一致的下采样编码结构及尺度,它们在参考语音中是一一对应的。 因此每个局部说话人嵌入可被视为对应于某个发音内容(音素)的细粒度说话人特征。
内容相关的参考注意力模块
一个人的声音特点不仅仅指其整体性的音色风格,还包括在一些局部发音上的细节变化。 这些局部变化主要是受个人发音习惯影响,一般在音素尺度内起作用。 举例而言,一个人发“/æ/”的音和他发“/i:/”的音在风格模式上是有区别的,并且不同人的发音习惯和模式也存在差异。 所以为了提高声音克隆的相似度,我们需要对合成文本中的每个音素分配更加精细、合适的细粒度说话人特征。
在实际合成中,参考语音和输入文本的内容往往是不一致的——即音素在排列和组合上都不同。 因此我们不能将上述提取的局部说话人嵌入直接添加到TTS模型的音素编码器输出上,而是要找到一个合理的分配关系。 由上一段的讨论自然想到,我们可以通过发音内容的相关性去寻找这种分配关系,于是我们便引入了一个内容相关的参考注意力模块: 音素编码器的输出被用作查询(Query),来自参考语音的所有局部内容嵌入被用作键(Key),它们之间的内容相关性用于指导细粒度说话人表征的选择,这也就意味着局部说话人嵌入是值(Value)。 通过这种方式,我们可以得到与音素编码序列 等长且适配 的细粒度说话人表征序列。
训练阶段预处理策略
由于本文所提的细粒度说话人特征十分多样(即使一个人说同样句子两次,也不能保证两条语音的说话风格和发音细节完全相同),在训练阶段参考语音和目标语音(对应输入文本)最好 保持一致 ,这样模型才能学习到正确的内容相关性和有意义的细粒度发音风格信息。 但是这样训练的后果是,参考注意力模块很容易误建模到文本与音频的时序相关性。 也就是说,获得的细粒度表征更像是在迁移时序上的韵律等信息。 而这并不适合本文的任务——当输入文本与参考语音内容不一致时这种迁移方式会让合成语音的韵律听起来奇怪、甚至因为内容泄漏导致语音混杂不可懂。
为了使模型更关注参考语音和输入文本之间的内容相关性,而不是简单的时序对齐,我们在训练阶段中引入了一些预处理操作。 参考语音的mel谱首先通过强制对齐(forced alignment)获得音素边界,然后根据音素边界进行切分,接着将这些小片段随机打乱并重新排列拼接,组成一个新的参考语音mel谱。 通过这样简单的预处理操作,我们既消除了输入文本与参考语音之间的时序一致性,同时也保留了语音中基本的音素单元,从而迫使模型去学习如何根据内容相关性查找合适的细粒度说话人表征。
04实验验证
实验数据
本文在一个经典的中文多说话人语料 AISHELL3 上进行训练和测试,该数据集包括来自218个中国人录制的约85小时录音,他们口音各异。 为了评估unseen speaker上的效果,我们选出其中8个说话人(4男4女)作为测试集,不参与模型的训练。 此外在推理时,每个说话人仅使用固定的一条音频作为该说话人的参考语音。
基线模型
我们实现了两种经典的定长说话人表征方法和一种基于 Attentron 的变长嵌入方法,为了公平对比所有方法都基于FastSpeech 2框架实现,具体细节如下:
GSE: 一种类似 GST 的全局说话人嵌入(Global Speaker Embedding)方法,使用一组基底向量和多头自注意机制来无监督地表示从参考语音中提取的说话人嵌入。
CLS: 一种结合说话人分类器(Speaker Classifier)的多任务学习或迁移学习方法,为了与所提模型有效对比,我们使用和图1相同的说话人编码器结构,用平均池化操作的结果作为说话人表征向量。
Attentron*: Attentron提出了一种基于注意力的变长嵌入方法。 其原始版本是基于Tacotron 2实现,由一个粗粒度的全局编码器和带有注意力机制的细粒度编码器组成,从参考语音中分别提取话语级和帧级嵌入。 为了公平对比,我们采用原论文中的 Attentron(1-1) 模式,并将其主要实现迁移到FastSpeech 2框架。
主观实验
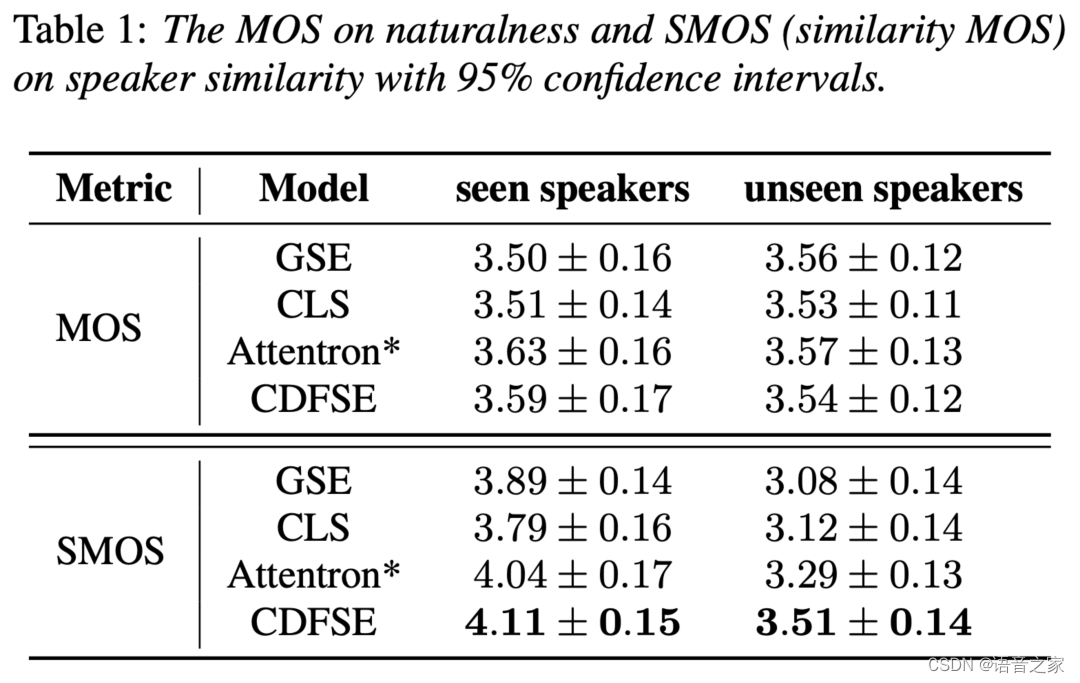
为了验证本文所提的内容相关细粒度说话人表征(CDFSE)方法的有效性,我们采用平均意见得分(Mean Opinion Score,MOS)对合成语音的自然度(MOS)和说话人相似度(SMOS)进行了主观评估,如下表所示。 在说话人相似度方面,CDFSE在seen speakers上的SMOS为4.11,在unseen speakers上的SMOS为3.51,并且Attentron*也比其他两个定长说话人表征模型要好。 从实验结果可以看出,CDFSE在SMOS上优于所有基线模型,且在unseen speakers上提升更显著、SMOS差距超过0.2, 这说明建模个人细粒度发音特点对于从听感上提升说话人声音相似度很有帮助。 在自然度方面,几个模型的结果相差无几,其中CDFSE相比Attentron*有略微下降,但在自然度和可懂度上仍可接受。
 结构探究及消融实验
结构探究及消融实验
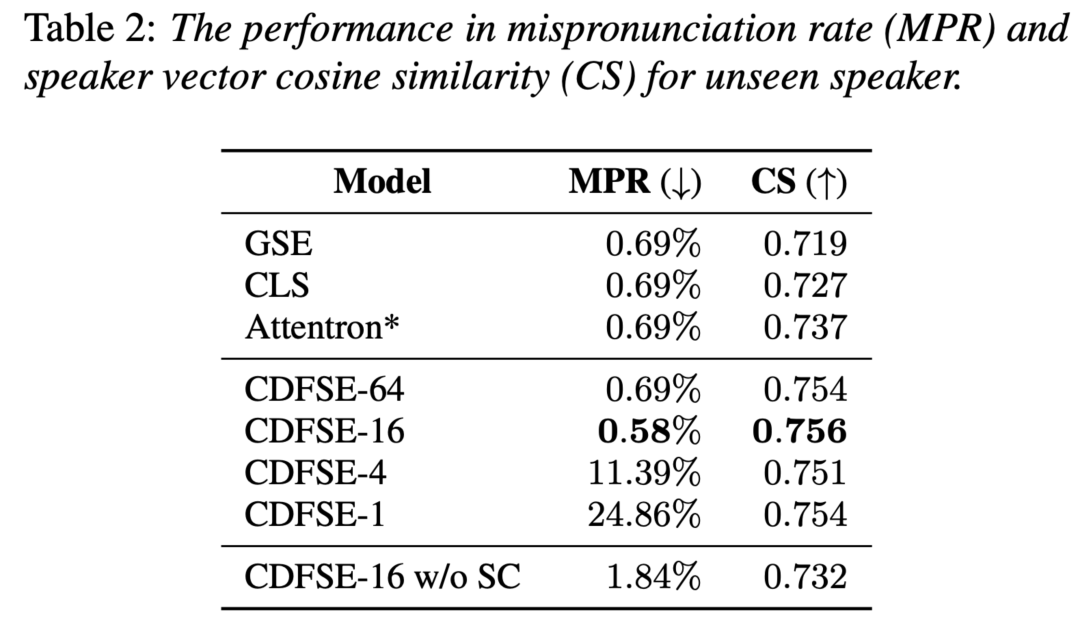
为了探究不同粒度的局部说话人嵌入对模型的影响,我们调整了下采样编码器中平均池化层的核大小。 如下表所示,“CDFSE-”后面的数字代表相对于原始帧级别语音序列的总体下采样尺度,我们上述提出的模型对应为CDFSE-16。
由于在该探究实验中我们发现一些合成语音的可懂度较差,这会影响对相似度的主观判断。 因此本部分采用客观指标评价: 1)为了评估合成语音的可懂度,对语音中发音错误的情况(不包括口音)进行人工测听统计,计算误发音率(MisPronunciation Rate, MPR); 2)为了评估合成语音的说话人相似度,我们使用预训练说话人验证系统来提取说话人向量并计算和真实语音间的余弦相似度(Cosine Similarity,CS)。
下表给出了不同粒度模型之间的性能比较,并给出了三个基线模型的客观指标结果供参考。 首先可以观察到所有模型中都存在一些发音错误的情况,这可能是由FastSpeech 2本身和训练数据引起。 其中CDFSE-16的发音错误率最低,说话人向量余弦相似度最高。 随着下采样倍数降低,合成语音的误发音率显著增加。 也就是说, 所提取的局部说话人嵌入的粒度对合成语音的可懂度和稳定性很重要,并不是越细粒度的说话人嵌入越好 。 此外,我们还进行了一些消融实验来证明部分模块设计的有效性: 当移除说话人分类器的监督时(CDFSE-16 w/o SC),发现两个客观指标均有下降, 说明引 入显式的说话人监督信息可以提高说话人相似度和合成稳定性 ; 当移除音素分类器的监督时,则发现会导致参考注意模块学不到发音内容对应关系, 说明需要显式内容监督信息来帮助建模文本和参考音频间的内容相关性 。
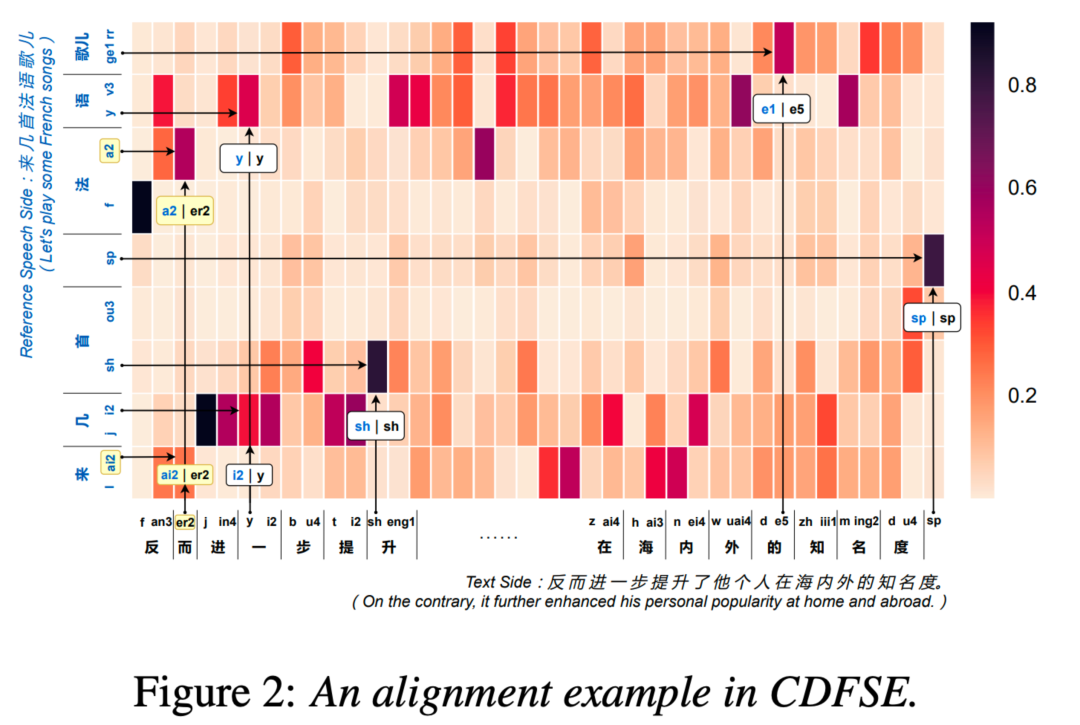
样例分析
为了清晰展示待合成文本和参考语音之间的发音内容相关性,我们画出了一个从 CDFSE 参考注意力模块取出的对齐图样例。 如下图所示,纵轴是参考语音的内容,横轴是输入的待合成文本。 当输入文本的音素存在于参考语音中时,参考注意力模块将倾向于直接关注语音中的对应片段 ,如“sh”这个发音; 当输入文本的音素不存在于参考语音中时,该模块则会去关注一些发音相似的片段 ,如文本中的“er2”这个音对应到参考语音中比较相近的“ai2”及“a2”。 图中另外还有很多这种现象,在此不多赘述。
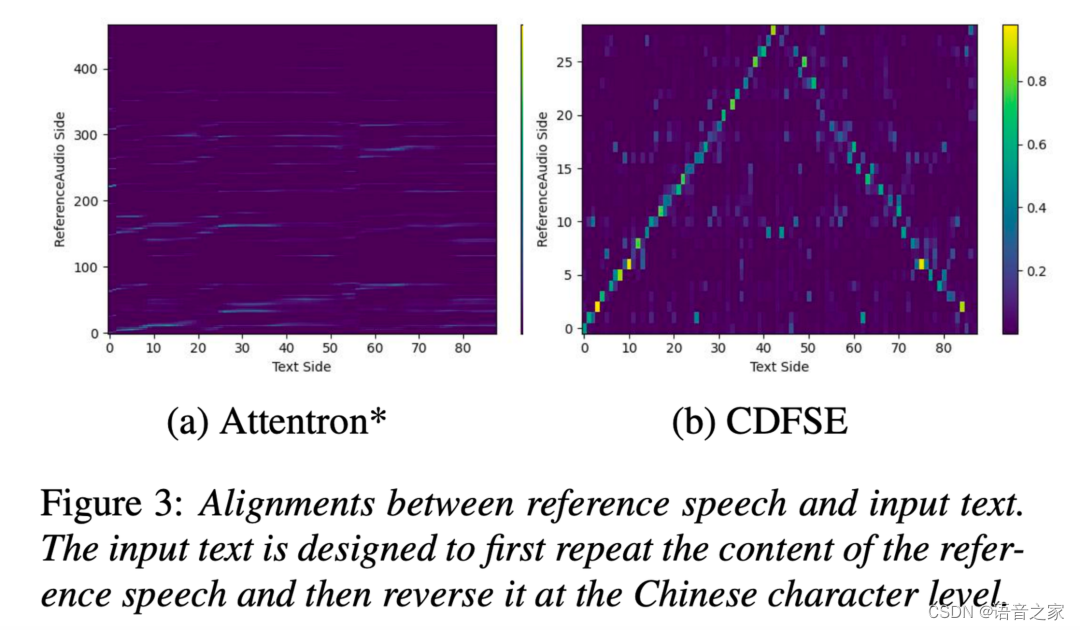
为了比较 CDFSE 和 Attentron* 两种方法建模发音内容相关性的能力,我们给出了另外一个经过特定设计输入文本的对齐图样例,其中输入待合成文本先是重复了一遍参考语音的内容、然后在汉字级别上做了一个反转。 如下图所示, CDFSE 的参考注意力模块成功学习到了正确的内容对齐 (其中反转部分的每个汉字内部音素顺序也得到了正确保留),而 Attentron* 则没有显现出这种能力。
我们进一步通过 2D t-SNE 可视化了测试阶段提取的细粒度说话人嵌入的空间分布,颜色代表说话人、文字代表对应音素。 如下图所示,来自同一个说话人的细粒度嵌入倾向于聚到一起、但同时也展现出一定程度的与音素内容相关的多样性,这说明 这些细粒度嵌入捕获到了个人的一些局部发音变化特点 。

05 结语
本文为语音合成零样本说话人自适应任务提出了一种内容相关的细粒度说话人表征(CDFSE)方法。 该方法考虑了参考语音和待合成文本之间的发音内容相关性,从而给TTS模型的每个音素编码结果生成更加合适精细的细粒度说话人表征。 主观及客观实验证明所提的 CDFSE 能够提升合成语音的说话人相似度,特别是对于unseen speaker而言; 另外,样例分析也证实了该方法确实具有建模个人细粒度发音特点的能力。