PaddleHub负责模型的管理、获取和预训练模型的使用。
参考:https://github.com/PaddlePaddle/PaddleHub/tree/develop/modules/image/text_recognition/chinese_text_detection_db_server

import paddlehub as hub
import cv2
# from utils import cv_show
import numpy as np
def cv_show(img):
'''
展示图片
@param img:
@param name:
@return:
'''
cv2.namedWindow('name', cv2.WINDOW_KEEPRATIO) # cv2.WINDOW_NORMAL | cv2.WINDOW_KEEPRATIO
cv2.imshow('name', img)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 输入图片路径
image_path = 'pic/img.jpg'
image = cv2.imread(image_path)
gray = cv2.cvtColor(image,cv2.COLOR_BGR2GRAY)
gray_padding = cv2.cvtColor( np.pad(gray, ((100, 100), (0, 0)), 'constant', constant_values=(255)), cv2.COLOR_GRAY2BGR)
# 检测+识别
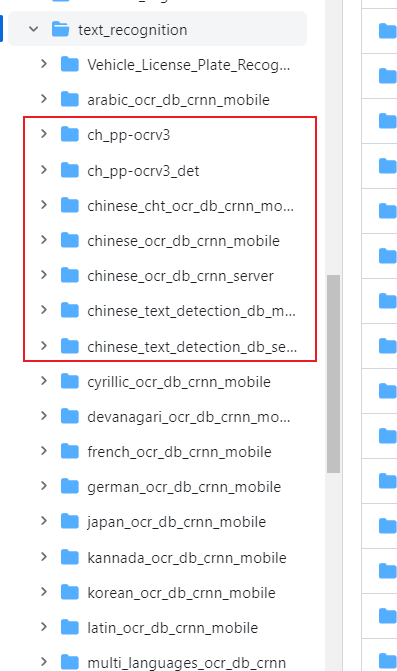
paddle_ocr = hub.Module(name="ch_pp-ocrv3") #SVTR_LCNet # mkldnn加速仅在CPU下有效 , enable_mkldnn=True
paddle_ocr.recognize_text(images=[gray_padding] )
ocr = hub.Module(name="chinese_ocr_db_crnn_server")#CRNN
r = ocr.recognize_text(images=[cv2.cvtColor(gray[:,:1250], cv2.COLOR_GRAY2BGR)],
# paths=[],
use_gpu=False,
output_dir='ocr_result',
visualization=True,
box_thresh=0.5,
text_thresh=0.5,
angle_classification_thresh=0.9)
# def recognize_text(images=[],
# paths=[],
# use_gpu=False,
# output_dir='ocr_result',
# visualization=False,
# box_thresh=0.6,
# text_thresh=0.5,
# angle_classification_thresh=0.9,
# det_db_unclip_ratio=1.5,
# det_db_score_mode="fast"):
# print('text',[[''.join(y['text'] for y in x['data'])] for x in results])
# 检测
text_detector_v3 = hub.Module(name="ch_pp-ocrv3_det")
result = text_detector_v3.detect_text(images=[gray_padding],
output_dir='detection_result',
box_thresh=0.6,
visualization=True,
det_db_unclip_ratio=2,#1.5
det_db_score_mode='slow',
)
box = result[0]['data'][1]
cv_show( gray_padding[box[0][1]:box[2][1],box[0][0]:box[1][0]])
text_detector = hub.Module(name='chinese_text_detection_db_server')
result = text_detector.detect_text(images=[gray_padding] ,
output_dir='detection_result',
visualization = 'True',
box_thresh=0.5,#0.6
text_thresh=0.5,#0.6
)
#det_db_thresh=0.1, det_db_box_thresh=0.4, det_db_unclip_ratio=2.0,det_db_score_mode='slow', use_dilation='True'
# def detect_text(images=[],
# paths=[],
# use_gpu=False,
# output_dir='detection_result',
# visualization=False,
# box_thresh=0.6,
# det_db_unclip_ratio=1.5,
# det_db_score_mode="fast")
#可视框
for box in result[0]['data']:
img = gray_padding[box[0][1]:box[2][1],box[0][0]:box[1][0]]
cv_show(img)
# for result in results:
# data = result['data']
# save_path = result['save_path']
# for infomation in data:
# print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])