先看一个题目:题目描述
题目描述:给你一个字符串 s 、一个字符串 t 。返回 s 中涵盖 t 所有字符的最小子串。如果 s 中不存在涵盖 t 所有字符的子串,则返回空字符串 "" 。
例如:
输入:s = "ADOBECODEBANC", t = "ABC" 输出:"BANC" 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
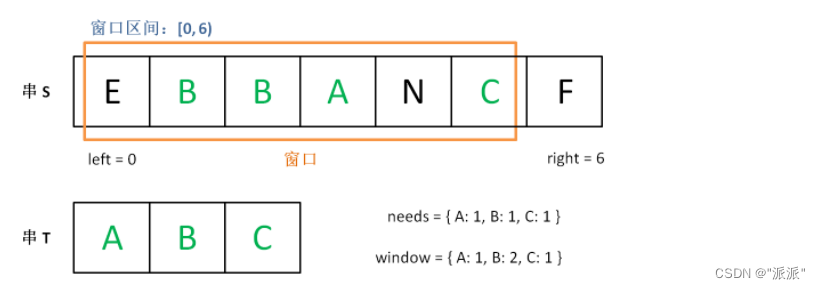
思路:在字符窜s中通过left,right指针来维护s中的一段区域,这里叫做窗口。开始时right指针右移,同时去比较right指向的元素是否存在于t字符窜中。当s那段窗口包含了所有t中的字符,说明就已经找到了一段符合的区间。当那段区间已经满足条件时,left指针再右移,再去判断是否满足。若不满足,此时肯定要扩大区间范围,right指针右移。满足,则继续缩小区间范围,left指针右移。
例如:
开始时:

找到了一段区间:
代码示例:
class Solution {
public:
string minWindow(string s, string t) {
unordered_map<char, int> need, window;
for (char c : t)
need[c]++;
int left = 0;
int right = 0;
int valid = 0; //记录t中字符种类,判断是否满足条件
int start = 0;
int len = INT_MAX;
while (right < s.size())
{
char c = s[right]; //左移窗口
right++;
if (need.count(c)) //这个字符存在于t中
{
window[c]++;
if (window[c] == need[c]) //t中的一个字符已满足
valid++;
}
while (valid == need.size()) // 判断左侧窗口是否要收缩
{
if (right - left < len) //更新最小覆盖子串
{
start = left;
len = right - left;
}
char d = s[left]; //右移窗口
left++;
if (need.count(d))
{
if (window[d] == need[d]) //窗口字符中被移除前,那个字符在window中的数量刚好
// 与need中的相同
valid--;
window[d]--;
}
}
}
return len == INT_MAX ?"" : s.substr(start, len);
}
};再看一个类似题型:题目描述
题目描述:给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
例如:
输入: s = "cbaebabacd", p = "abc" 输出: [0,6] 解释: 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
思路是完全一样的。
class Solution {
public:
vector<int> findAnagrams(string s, string p) {
unordered_map<char,int> window,need;
for(char ch: p) //先记录p中每个字符及其数量
need[ch]++;
int left,right;
left=right=0;
int count=0; //记录window区间是否满足条件
vector<int> v;
while(right<s.size())
{
char c=s[right]; //right右移,窗口增大
window[c]++;
right++;
if(need.count(c))
{
if(window[c]==need[c])
count++;
}
while(count==need.size())
{
if(right-left==p.size()) //将满足条件的区间放入vector中
{
v.push_back(left);
}
char c=s[left];
left++;
if(need.count(c)) //left右移,窗口减小
{
if(window[c]==need[c])
count--;
}
window[c]--;
}
}
return v;
}
};