文章目录
- 1 云主机使用网络存储 io 流程
- 2 multipath 介绍
1 云主机使用网络存储 io 流程
对于一个云服务环境,大致会有网络节点,存储节点,计算节点,控制节点,其中虚拟云主机在计算节点工作,而虚拟云主机(qemu 虚机)使用的存储一般通过 ceph,drbd,mulitpch,iscsi 使其在存储节点存储。
(1)计算节点云主机访问本地 /dev/vda,/dev/vdb … 块设备,实际访问的是 dm-mulitpath 管理的计算节点的 /dev/dm-0…1,2,3 设备。
/dev/vda
-> virtio_blk
-> virtio_pci
-> 虚拟主机(qemu vhost)
-> 本地节点 tcm_vhost
-> target_core_mod
-> target_core_iblock/target_core_pscsi
-> 计算节点 /dev/dm-0
(2)/dev/dm-0 实际由 iscsi 客户端管理的 /dev/sda 和 /dev/sdb 聚合而成,可实现故障路径切换,io 负载均衡等能力,实际 io 数据会通过 iscsi_tcp(如果是 fc 服务,则是走光纤通道)到达存储节点的 /dev/drbd0。如果主路径故障,通路不同则会由 multipath 切换到备用路径(这里是/dev/sdb),等待恢复后切换回主路径(回到/dev/sda)。这里假设走的主路径:
/dev/dm-0
-> /dev/sda
-> iscsi_tcp/fc
-> 到达存储节点 iscsi_target_mod/tcm_fc
-> target_core_mod
-> target_core_iblock/target_core_pscsi
-> /dev/drbd0 (drbd 模块)
(3)存储节点的/dev/drbd0由 drbd 内核模块配置,实现块数据拷贝同步到后端存储设备。后端存储设备为/dev/alcache0,该设备实际是一块高速 SSD 设备(如 nvme),实现数据的高速缓存。
(4)/dev/alcache0由 bcache 配置管理,实际对应后端存储为/dev/rbd0。bcache 实现将 nvme 作为高速缓存将数据同步到 /dev/rbd0 中。
(5)/dev/rbd0 设备由 ceph rbd 管理,该模块提供了分布式存储管理能力,如 io 调度等,通过 rbd,数据 io 会实际到达 HHD 等大容量存储设备。
/dev/rbd0
-> rbd 模块(ceph 网络协议转发数据)
-> ceph rbd 管理(分布式存储管理实际物理磁盘)
2 multipath 介绍
可以看到上述路径中在计算节点使用了 mutlipath 聚合路径来实现负载均衡和路径切换等。
用户态工具相关:
启动脚本
/usr/lib/systemd/system/multipathd.service
udev 命令规则
/usr/lib/udev/rules.d/11-dm-mpath.rules
/usr/lib/udev/rules.d/62-multipath.rules
用户工具
/usr/sbin/multipathd 守护进程,监听系统中路径状态的变化,并做相应的处理。
/usr/sbin/mpathpersist SCSI PR命令工具,主要用于隔离。
/usr/sbin/mpathconf 修改多路径配置
/usr/sbin/kpartx DeviceMapper虚拟设备创建工具
/usr/sbin/multipath 多路径命令工具
查看 device mapper 映射表
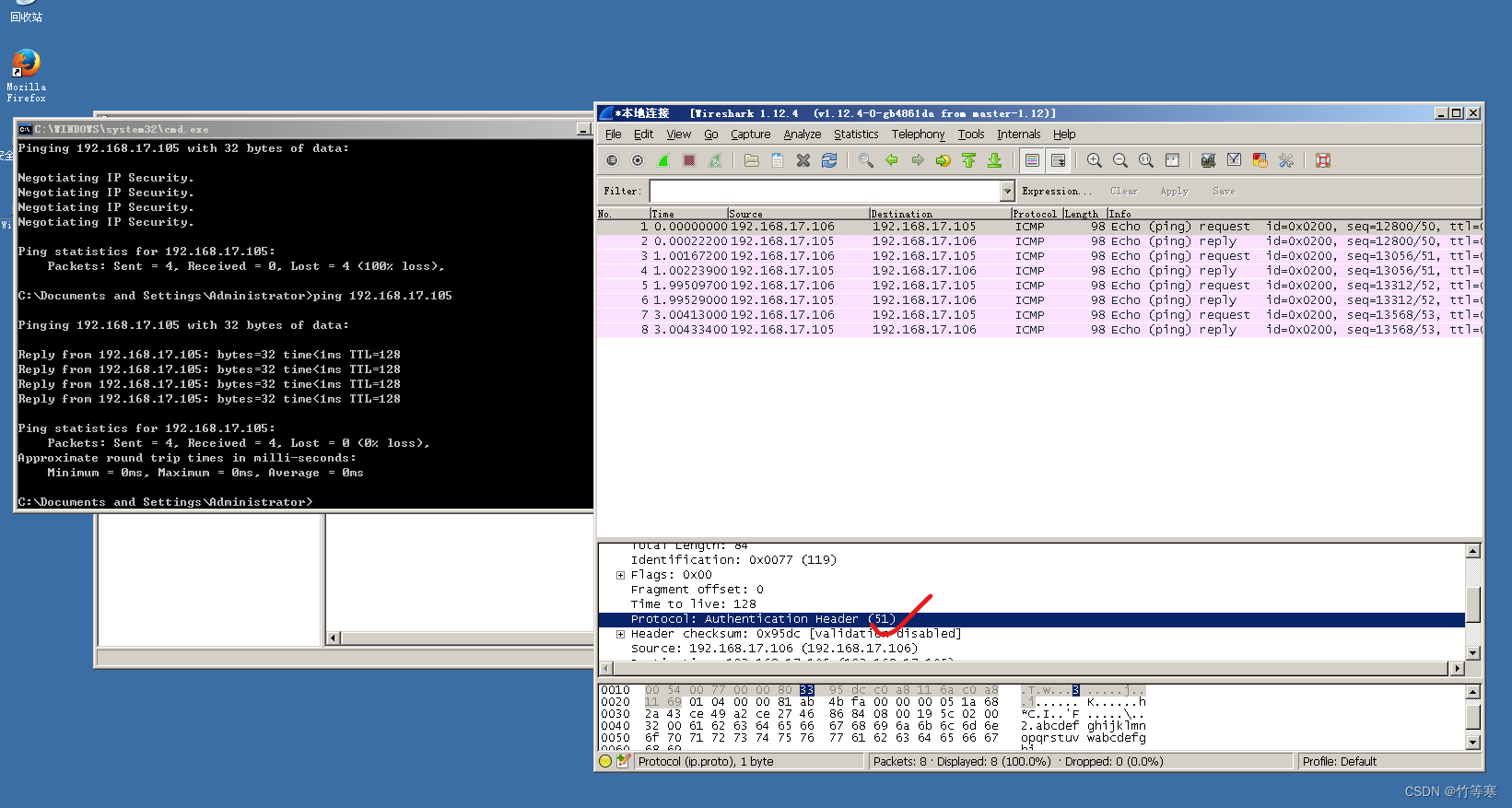
[wings-client@fedora sections]$ sudo dmsetup table
mpatha: 0 41940992 multipath 1 queue_if_no_path 1 alua 1 1 service-time 0 2 2 8:0 1 1 8:16 1 1
[wings-client@fedora sections]$ ll /dev/sd*
brw-rw----. 1 root disk 8, 0 10月16日 15:29 /dev/sda
brw-rw----. 1 root disk 8, 16 10月16日 15:29 /dev/sdb
查看被映射的多路径设备
[wings-client@fedora sections]$ ll /dev/dm-*
brw-rw----. 1 root disk 253, 0 10月16日 15:29 /dev/dm-0
[wings-client@fedora sections]$
多路径创建的 dm 设备的主设备号都是 253。
查看设备的 wwid
[wings-client@fedora sections]$ lsscsi -i
[0:0:0:0] cd/dvd QEMU QEMU DVD-ROM 2.5+ /dev/sr0 -
[6:0:0:0] disk LIO-ORG block1 4.0 /dev/sdb 3600140554012e51273044299221f2903
[7:0:0:0] disk LIO-ORG block1 4.0 /dev/sda 3600140554012e51273044299221f2903
[wings-client@fedora sections]$
同一个设备的两条路径,以及被映射的新设备的 wwid 相同
查看当前多路径信息
[wings-client@fedora sections]$ sudo multipath -ll
mpatha (3600140554012e51273044299221f2903) dm-0 LIO-ORG,block1
size=20G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 7:0:0:0 sda 8:0 active ready running
`- 6:0:0:0 sdb 8:16 active ready running
[wings-client@fedora sections]$
多路径软件读取/etc/multipath.conf文件,并根据 wwid 将相同设备聚合成一个虚拟设备。
内核中 dm-multipath 源码实现主要在linux/drivers/md/dm-*中。
dm-multipath 模块属于 md 模块的一个后端部分。
md 是多个设备的内核 RAID 实现,其中 dm 是设备映射器实现,允许将一个设备映射到另一个设备(一个或者多个)上,这可用作创建在/dev/mapper 目录中访问的虚拟设备(映射设备)。该设备的所有 IO 都将映射到其他设备。
RAID 控制器
RAID控制器是一种硬件设备或软件程序,用于管理计算机或存储阵列中的硬盘驱动器(HDD)/固态硬盘(SSD),以便它们能如逻辑部件一样工作,各施其职。RAID控制器的功能既可以由硬件也可以由软件来实现。硬件RAID一般用于处理大量数据的RAID模式。随着处理器的能力的不断增强,软件RAID功能已经成为可能,不过当处理大量数据时CPU仍然会显得力不从心。一般的中高档服务器多使用硬件RAID控制器,但是由于硬件RAID控制器的价格昂贵,导致系统成本大大增加。而随着处理器的性能快速发展,使得软件RAID的解决方法得到人们的重视。在这里,我们使用的是软件RAID。
在Linux系统中目前以MD (Multiple Devices)虚拟块设备的方式实现软件RAID,利用多个底层的块设备虚拟出一个新的虚拟块设备,并且利用条带化(stripping)技术将数据块均匀分布到多个磁盘上来提高虚拟设备的读写性能,利用不同的数据冗余算法来保护用户数据不会因为某个块设备的故障而完全丢失,而且还能在设备被替换后将丢失的数据恢复到新的设备上。
MD (Multiple Devices)框架
Multiple Devices虚拟块设备(利用底层多个块设备虚拟出一个新的虚拟块设备)。目前MD支持linear, multipath, raid0 (stripping), raid1 (mirror), raid4, raid5, raid6, raid10等不同的冗余级别和组成方式,当然也能支持多个RAID阵列的层叠组成raid1+0, raid5+1等类型的阵列。
dm 整体框架大致如下:
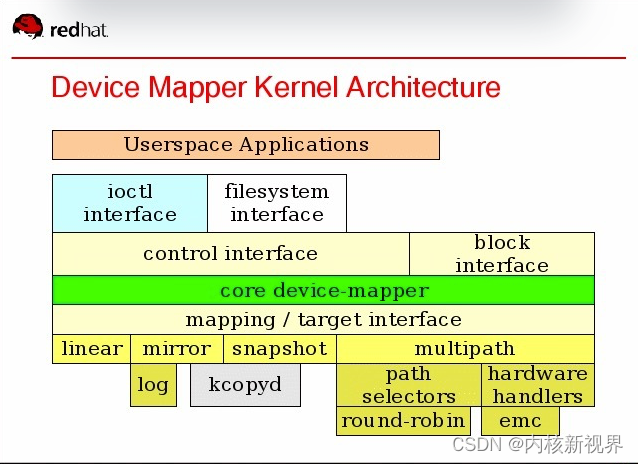
这里主要关心 multipath 部分。
内核选中 DM_MULTIPATH 即可启用 multipath 相关内核支持。
DM_MULTIPATH_QL 和 DM_MULTIPATH_ST 为两种可选的路径选择算法。
dm-mpath.c是多路径驱动的核心,负责初始化相关数据结构,以及向 mapping/target interface 注册 dm 的 target type 回调。
dm-selector.c是负责管理路径选择算法的苦函数。
dm-round-robin.c是必备的路径选择算法:在一条路径上完成指定的 IO 次数后就切换到下一条路径,不断循环。
另外两种是可选算法,见上述 Kconfig:
1)dm-service-time.c算法:根据路径的吞吐量以及完成的字节数选择负载较轻的路径。
2)dm-queue-length.c算法:根据正在处理的 IO 个数较少的路径。
dm-mapth.c核心:
/*-----------------------------------------------------------------
* Module setup
*---------------------------------------------------------------*/
static struct target_type multipath_target = {
.name = "multipath",
.version = {1, 13, 0},
.features = DM_TARGET_SINGLETON | DM_TARGET_IMMUTABLE |
DM_TARGET_PASSES_INTEGRITY,
.module = THIS_MODULE,
.ctr = multipath_ctr,
.dtr = multipath_dtr,
.clone_and_map_rq = multipath_clone_and_map,
.release_clone_rq = multipath_release_clone,
.rq_end_io = multipath_end_io,
.map = multipath_map_bio,
.end_io = multipath_end_io_bio,
.presuspend = multipath_presuspend,
.postsuspend = multipath_postsuspend,
.resume = multipath_resume,
.status = multipath_status,
.message = multipath_message,
.prepare_ioctl = multipath_prepare_ioctl,
.iterate_devices = multipath_iterate_devices,
.busy = multipath_busy,
};
static int __init dm_multipath_init(void)
{
int r;
kmultipathd = alloc_workqueue("kmpathd", WQ_MEM_RECLAIM, 0);
if (!kmultipathd) {
DMERR("failed to create workqueue kmpathd");
r = -ENOMEM;
goto bad_alloc_kmultipathd;
}
/*
* A separate workqueue is used to handle the device handlers
* to avoid overloading existing workqueue. Overloading the
* old workqueue would also create a bottleneck in the
* path of the storage hardware device activation.
*/
kmpath_handlerd = alloc_ordered_workqueue("kmpath_handlerd",
WQ_MEM_RECLAIM);
if (!kmpath_handlerd) {
DMERR("failed to create workqueue kmpath_handlerd");
r = -ENOMEM;
goto bad_alloc_kmpath_handlerd;
}
r = dm_register_target(&multipath_target);
if (r < 0) {
DMERR("request-based register failed %d", r);
r = -EINVAL;
goto bad_register_target;
}
return 0;
bad_register_target:
destroy_workqueue(kmpath_handlerd);
bad_alloc_kmpath_handlerd:
destroy_workqueue(kmultipathd);
bad_alloc_kmultipathd:
return r;
}
在启动阶段dm_multipath_init向 dm 的 mapping/target interface 注册 target type,并且申请两个工作队列,用于异步执行耗时的 IO 操作。
使用的数据结构struct target_type:
struct target_type {
uint64_t features;
const char *name;
struct module *module;
unsigned version[3];
dm_ctr_fn ctr;
dm_dtr_fn dtr;
dm_map_fn map;
dm_clone_and_map_request_fn clone_and_map_rq;
dm_release_clone_request_fn release_clone_rq;
dm_endio_fn end_io;
dm_request_endio_fn rq_end_io;
dm_presuspend_fn presuspend;
dm_presuspend_undo_fn presuspend_undo;
dm_postsuspend_fn postsuspend;
dm_preresume_fn preresume;
dm_resume_fn resume;
dm_status_fn status;
dm_message_fn message;
dm_prepare_ioctl_fn prepare_ioctl;
#if 1 /* CONFIG_BLK_DEV_ZONED */
dm_report_zones_fn report_zones;
#endif
dm_busy_fn busy;
dm_iterate_devices_fn iterate_devices;
dm_io_hints_fn io_hints;
dm_dax_direct_access_fn direct_access;
dm_dax_copy_iter_fn dax_copy_from_iter;
dm_dax_copy_iter_fn dax_copy_to_iter;
/* For internal device-mapper use. */
struct list_head list;
};
ctr = multipath_ctr
当用户程序加载 DeviceMapper 映射表时,如果其中的映射类型为 multipath,则会根据映射表中的参数调用此函数,
用于构建一个 Target Device:
申请该实例内存,并进行简单初始化;
解析参数,并根据参数创建优先级组,解析每个优先级组的路径算法;
设置一些基本的 DeviceMapper 属性;
一个设备的多路径可以使用不同类型,划分成多个优先组,每个组需要包含一个路径选择器(路径选择算法)以及至少一条路径。
参数组成部分:
特性参数 硬件参数 优先级组以及路径参数
参数解析实例:
mpatha: 0 41940992 multipath 1 queue_if_no_path 1 alua 1 1 service-time 0 2 2 8:0 1 1 8:16 1 1
其中 "1 queue_if_no_path 1 alua 1 1 service-time 0 2 2 8:0 1 1 8:16 1 1" 为传递给驱动的参数。
1:表示特性参数,后跟特性参数,反之为 0,不跟参数
1: 表示硬件参数,后跟硬件参数(alua),反之为 0,不跟参数
1: 表示优先级组个数
1: 下一个优先级组序号,主要用于解析优先级组时使用
service-time:当前的优先组使用 service-time 算法
0: 算法的参数个数为 0
2: 该优先组包含两条路径
2: 每条路径的参数有两个
8:0 1 1: 第一条路径的设备号为 8:0,每进行 1 次 IO 就切换路径,路径的吞吐量权重为 1
8:16 1 1: 第一条路径的设备号为 8:16,每进行 1 次 IO 就切换路径,路径的吞吐量权重为 1
最终用户态程序看到的结果就是:
mpatha (3600140554012e51273044299221f2903) dm-0 LIO-ORG,block1
size=20G features='1 queue_if_no_path' hwhandler='1 alua' wp=rw
`-+- policy='service-time 0' prio=50 status=active
|- 7:0:0:0 sda 8:0 active ready running
`- 6:0:0:0 sdb 8:16 active ready running
clone_and_map_rq = multipath_clone_and_map(IO 映射)
判断是否需要切换路径,并获取当前可用路径,把路径信息保存在请求的私有数据中
根据路径信息重定向请求,设置其目的队列
调用路径算法的 start_io 函数。
如果成功则返回 DM_MAPIO_REMAPPED,表明映射成功,通知 dm 框架重新投递请求。
rq_end_io = multipath_end_io
映射完成后,进行 IO 结束时会调用 multipath_end_io 函数进行资源回收,
如果 IO 错误且 pgpath 不为空则使用 fail_path 函数通过 uevent 通知用户层此路径已经失效。
如果设置了 queue_if_no_path 为 0,则会返回 DM_ENDIO_REQUEUE,dm 会把这个请求重新加入队列,
否则直接返回 EIO 错误,最后清除在开始映射时创建的上下文信息,并调用路径选择算法的 end_io 函数。
message = multipath_message
多路径驱动除了根据在给定的算法和配置下进行 IO 错误时以外,并不主动探测路径的状态,增加减少路径,
以及状态改变,这些都是由用户态的 multipathd 和 multipath 来控制完成,然后通过 dm 框架提供的接口,
调用 target type 驱动的 message 函数来完成。这里实现了切换优先组,失效以及使能路径等功能。
dm-path-selector.c路径选择算法管理库
使用链表对路径算法进行管理,注册,取消注册,获取,释放等。
/* Register a path selector */
int dm_register_path_selector(struct path_selector_type *type);
/* Unregister a path selector */
int dm_unregister_path_selector(struct path_selector_type *type);
/* Returns a registered path selector type */
struct path_selector_type *dm_get_path_selector(const char *name);
/* Releases a path selector */
void dm_put_path_selector(struct path_selector_type *pst);
每个路径算法实现下面的结构回调:
/* Information about a path selector type */
struct path_selector_type {
char *name;
struct module *module;
unsigned int table_args;
unsigned int info_args;
/*
* Constructs a path selector object, takes custom arguments
*/
int (*create) (struct path_selector *ps, unsigned argc, char **argv);
void (*destroy) (struct path_selector *ps);
/*
* Add an opaque path object, along with some selector specific
* path args (eg, path priority).
*/
int (*add_path) (struct path_selector *ps, struct dm_path *path,
int argc, char **argv, char **error);
/*
* Chooses a path for this io, if no paths are available then
* NULL will be returned.
*/
struct dm_path *(*select_path) (struct path_selector *ps,
size_t nr_bytes);
/*
* Notify the selector that a path has failed.
*/
void (*fail_path) (struct path_selector *ps, struct dm_path *p);
/*
* Ask selector to reinstate a path.
*/
int (*reinstate_path) (struct path_selector *ps, struct dm_path *p);
/*
* Table content based on parameters added in ps_add_path_fn
* or path selector status
*/
int (*status) (struct path_selector *ps, struct dm_path *path,
status_type_t type, char *result, unsigned int maxlen);
int (*start_io) (struct path_selector *ps, struct dm_path *path,
size_t nr_bytes);
int (*end_io) (struct path_selector *ps, struct dm_path *path,
size_t nr_bytes);
};
create:实例化一个选择器
destroy:销毁一个选择器
add_path:向该选择器增加一条路径
select_path:选择进行 IO 的路径
fail_path:告诉选择器该路径失效
reinstate_path:告诉选择器该路径可用
status:返回选择器的状态
start_io:使用者进行 IO 前必须调用该函数(如路径算法记录 IO 次数)
end_io:使用者完成 IO 后必须调用该函数
round-robin路径选择器
每条路径只有一个参数,就是每条路径执行多少次 IO 后切换路径。
添加一条路径:
static int rr_add_path(struct path_selector *ps, struct dm_path *path,
int argc, char **argv, char **error)
{
struct selector *s = ps->context;
struct path_info *pi;
unsigned repeat_count = RR_MIN_IO;
char dummy;
unsigned long flags;
if (argc > 1) {
*error = "round-robin ps: incorrect number of arguments";
return -EINVAL;
}
/* First path argument is number of I/Os before switching path */
if ((argc == 1) && (sscanf(argv[0], "%u%c", &repeat_count, &dummy) != 1)) {
*error = "round-robin ps: invalid repeat count";
return -EINVAL;
}
if (repeat_count > 1) {
DMWARN_LIMIT("repeat_count > 1 is deprecated, using 1 instead");
repeat_count = 1;
}
/* allocate the path */
pi = kmalloc(sizeof(*pi), GFP_KERNEL);
if (!pi) {
*error = "round-robin ps: Error allocating path context";
return -ENOMEM;
}
pi->path = path;
pi->repeat_count = repeat_count;
path->pscontext = pi;
spin_lock_irqsave(&s->lock, flags);
list_add_tail(&pi->list, &s->valid_paths);
spin_unlock_irqrestore(&s->lock, flags);
return 0;
}
路径选择策略:
在每条路径进行repeat_count次 IO 后就切换到下一条路径,不断循环。(目前已经废弃,总是 1 次后就切换)
static struct dm_path *rr_select_path(struct path_selector *ps, size_t nr_bytes)
{
unsigned long flags;
struct selector *s = ps->context;
struct path_info *pi = NULL;
spin_lock_irqsave(&s->lock, flags);
if (!list_empty(&s->valid_paths)) {
pi = list_entry(s->valid_paths.next, struct path_info, list);
list_move_tail(&pi->list, &s->valid_paths);
}
spin_unlock_irqrestore(&s->lock, flags);
return pi ? pi->path : NULL;
}
service-time 路径选择器
添加一条路径:
static int st_add_path(struct path_selector *ps, struct dm_path *path,
int argc, char **argv, char **error)
{
struct selector *s = ps->context;
struct path_info *pi;
unsigned repeat_count = ST_MIN_IO;
unsigned relative_throughput = 1;
char dummy;
unsigned long flags;
...
...
每条路径需要指定它的重复次数repeat_count,以及吞吐量权重值relative_throughput。
路径选择策略:
在 IO 开始与结束时,分别增加和减少该路径正在处理的 IO 字节数:
static int st_start_io(struct path_selector *ps, struct dm_path *path,
size_t nr_bytes)
{
struct path_info *pi = path->pscontext;
atomic_add(nr_bytes, &pi->in_flight_size);
return 0;
}
static int st_end_io(struct path_selector *ps, struct dm_path *path,
size_t nr_bytes)
{
struct path_info *pi = path->pscontext;
atomic_sub(nr_bytes, &pi->in_flight_size);
return 0;
}
在多个路径中,选择正在处理的数据量与吞吐量比值最小的那条路径
static int st_compare_load(struct path_info *pi1, struct path_info *pi2,
size_t incoming)
{
size_t sz1, sz2, st1, st2;
sz1 = atomic_read(&pi1->in_flight_size);
sz2 = atomic_read(&pi2->in_flight_size);
/*
* Case 1: Both have same throughput value. Choose less loaded path.
*/
if (pi1->relative_throughput == pi2->relative_throughput)
return sz1 - sz2;
...
...
static struct dm_path *st_select_path(struct path_selector *ps, size_t nr_bytes)
{
struct selector *s = ps->context;
struct path_info *pi = NULL, *best = NULL;
struct dm_path *ret = NULL;
unsigned long flags;
spin_lock_irqsave(&s->lock, flags);
if (list_empty(&s->valid_paths))
goto out;
list_for_each_entry(pi, &s->valid_paths, list)
if (!best || (st_compare_load(pi, best, nr_bytes) < 0))
best = pi;
if (!best)
goto out;
/* Move most recently used to least preferred to evenly balance. */
list_move_tail(&best->list, &s->valid_paths);
ret = best->path;
out:
spin_unlock_irqrestore(&s->lock, flags);
return ret;
}
queue-length 路径选择器:
添加一条路径:
只需要指定repeat_count即可
static int ql_add_path(struct path_selector *ps, struct dm_path *path,
int argc, char **argv, char **error)
{
struct selector *s = ps->context;
struct path_info *pi;
unsigned repeat_count = QL_MIN_IO;
char dummy;
unsigned long flags;
...
...
路径选择策略:
在 IO 开始和结束时,分别增加和减少正在处理的 IO 个数:
static int ql_start_io(struct path_selector *ps, struct dm_path *path,
size_t nr_bytes)
{
struct path_info *pi = path->pscontext;
atomic_inc(&pi->qlen);
return 0;
}
static int ql_end_io(struct path_selector *ps, struct dm_path *path,
size_t nr_bytes)
{
struct path_info *pi = path->pscontext;
atomic_dec(&pi->qlen);
return 0;
}
选择正在处理的 IO 个数最少的那条路径
static struct dm_path *ql_select_path(struct path_selector *ps, size_t nr_bytes)
{
struct selector *s = ps->context;
struct path_info *pi = NULL, *best = NULL;
struct dm_path *ret = NULL;
unsigned long flags;
spin_lock_irqsave(&s->lock, flags);
if (list_empty(&s->valid_paths))
goto out;
list_for_each_entry(pi, &s->valid_paths, list) {
if (!best ||
(atomic_read(&pi->qlen) < atomic_read(&best->qlen)))
best = pi;
if (!atomic_read(&best->qlen))
break;
}
if (!best)
goto out;
/* Move most recently used to least preferred to evenly balance. */
list_move_tail(&best->list, &s->valid_paths);
ret = best->path;
out:
spin_unlock_irqrestore(&s->lock, flags);
return ret;
}