文章目录
- 性能测试
- 运行速度
- 内存消耗
- 并行加速
- 分布式
- 并行
- 多线程
- 多进程
- 框架
- 即时编译
- njit
- case1 计算熵
- case2 找到最大概率类别
- case3 计算两两准确率
- GPU
- 使用工具
关于程序优化的第一个准则是“不要优化”,第二个准则是“不要优化那些无关紧要的部分”。
性能测试
性能测试是做性能调优前最重要的工作。比如 python 本地程序一定要有时间和调用次数的打点,我们才能确定是 io 瓶颈还是计算瓶颈,还是算法复杂度自身有问题。再比如 mr 任务的话,要合理利用平台功能,监控 cpu 利用率和 memory 利用率,cpu 利用率低,可以降低资源申请或者提高异步;如果 memory 利用率低,通常就是降低资源申请。往往降低资源利用率也可以侧面的提供更高的并发可能性。
运行速度
# opti exe-time
# 参考:https://zhuanlan.zhihu.com/p/53760922
import cProfile, pstats, io, sys
from decorator import decorator
@decorator
def profile_time(func, *args, **kw):
# pre
pr = cProfile.Profile()
pr.enable()
# main func
result = func(*args, **kw)
# post
pr.disable()
s = io.StringIO()
# tottime,指的是函数本身的运行时间,扣除了子函数的运行时间
# cumtime,指的是函数的累计运行时间,包含了子函数的运行时间
sortby = "cumtime" # 仅适用于 3.6, 3.7 把这里改成常量了
ps = pstats.Stats(pr, stream=s).sort_stats(sortby)
ps.print_stats()
sys.stderr.write("{}\n".format(s.getvalue()))
pr.dump_stats("pipeline.prof")
return result
上面这个装饰器直接装饰到需要计时的函数上就好了。上面这个装饰器还是顺便在当前路径生成一个 profile 文件,需要的话,调用该工具:flameprof pipeline.prof > pipeline.svg,就可以在浏览器中打开火焰图可视化了。
内存消耗
这个可以用 tracemalloc 工具,使用非常容易上手,因此这里不展开篇幅介绍了。
并行加速
分布式
这个我比较熟悉也是也借用的比较多的工具就是mapreduce 了,这里也不过多做介绍了。不过最近在整理 mapreduce 的相关零碎知识点,这里先挖个坑,后面会单独整理一下工作中遇到 mapreduce 的技巧和坑。
需要注意的是,因为 map->reduce阶段框架已经做了 shuffle+sort,因此,reducer 可以注意要尽可能的使用流式计算的逻辑。全局状态尽可能的少存,及时要存,我们也尽可能的使用流式算法。可以参考《互联网大规模数据挖掘与分布式处理》这本书。
并行
可以参考这一本小书:https://python-parallel-programmning-cookbook.readthedocs.io/zh_CN/latest/index.html
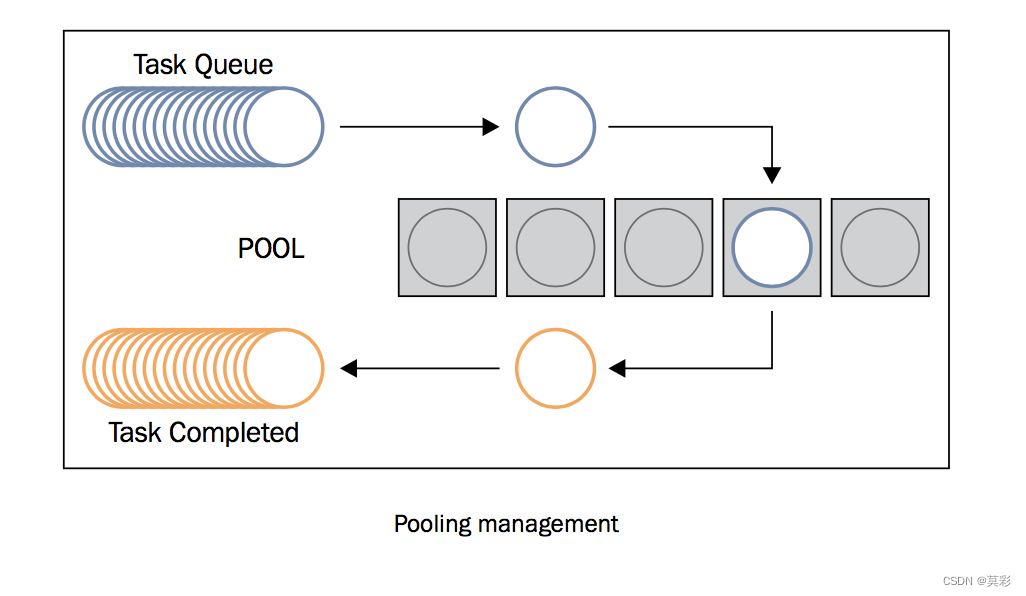
多线程
还有一点要注意的是,线程不是专门用来优化性能的。 一个CPU依赖型程序可能会使用线程来管理一个图形用户界面、一个网络连接或其他服务。 这时候,GIL会产生一些问题,因为如果一个线程长期持有GIL的话会导致其他非CPU型线程一直等待。 事实上,一个写的不好的C语言扩展会导致这个问题更加严重, 尽管代码的计算部分会比之前运行的更快些。
…
通过使用一个技巧利用进程池解决了GIL的问题。 当一个线程想要执行CPU密集型工作时,会将任务发给进程池。 然后进程池会在另外一个进程中启动一个单独的Python解释器来工作。 当线程等待结果的时候会释放GIL。 并且,由于计算任务在单独解释器中执行,那么就不会受限于GIL了。 在一个多核系统上面,你会发现这个技术可以让你很好的利用多CPU的优势。
其实这里我叫多线程,一般我只会用到两个线程。一个处理 io 秘籍的部分,一个处理 cpu 密集的部分。比如,数据处理任务经常遇到的场景是读取数据,然后进行处理,常为流式计算(比如特征转换)或者批式(比如统计全局信息)。那么我们就可以批量读取,然后批量计算,并且这两个之间可以异步。
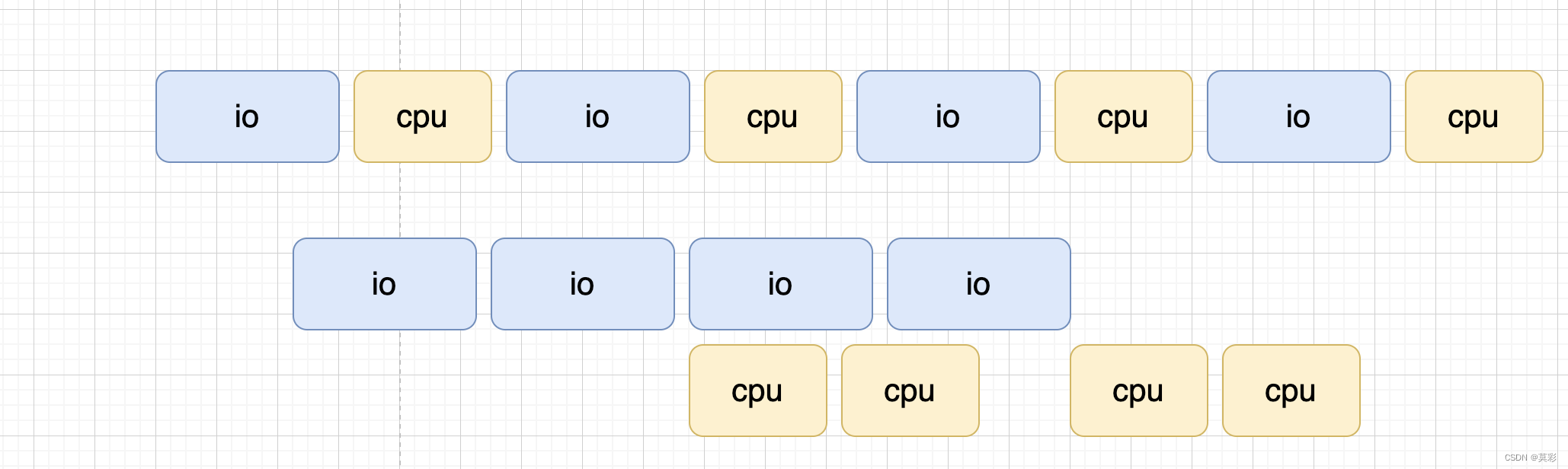
上图展示的是 io 比 cpu 处理时间长的场景,如果 cpu 处理时间更长,那么还可以对于 cpu 密集部分进行并发计算。(注意,调度起 cpu 是一个线程,并发是使用多个进程)。
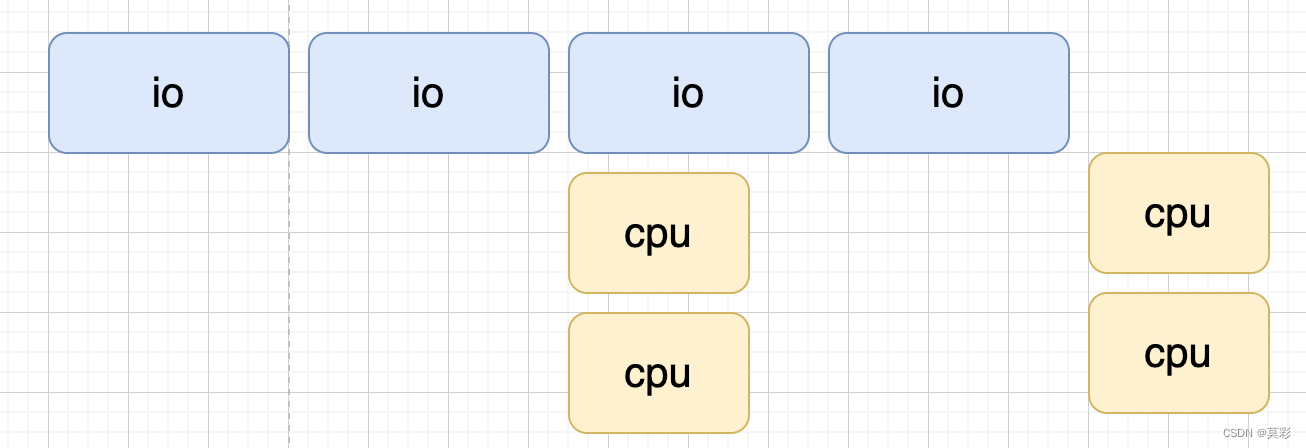
多进程
并发一般使用多进程的方式是 python 中 GIL 的存在。有很多方式可以实现多进程,我们这里只给出一个我常用的方式:
import concurrent
import concurrent.futures
input_queue = [......]
def mapper_concurrent_op(input_data):
// ....
return output_data
executor = concurrent.futures.ProcessPoolExecutor(max_workers=4)
result_iter = executor.map(mapper_concurrent_op, input_queue)
result_list = list(result_iter) # input_queue 处理后的结果
对于使用 ProcessPoolExecutor 时,这个方法会将 iterables 分割任务块并作为独立的任务并提交到执行池中。这些块的大概数量可以由 chunksize 指定正整数设置。 对很长的迭代器来说,使用大的 chunksize 值比默认值 1 能显著地提高性能。 chunksize 对 ThreadPoolExecutor 没有效果。参考python官方文档和Python并行编程 中文版
框架
这里可以给出一个现实中可行的框架设计。对于这种【读入数据】=>【处理】=>【输出】的处理流程,可以结合上面的 io+cpu 异步和并发计算密集部分的原理,给出下面的抽象。大致的业务函数只有标灰的 5 处。
- 输入:定义如何生成待处理的数据
- 处理:定义如何把输入加工为输出
- 输出有三部分:(1)每个数据如何输出(2)如何更新全局状态(3)全局状态如何输出。
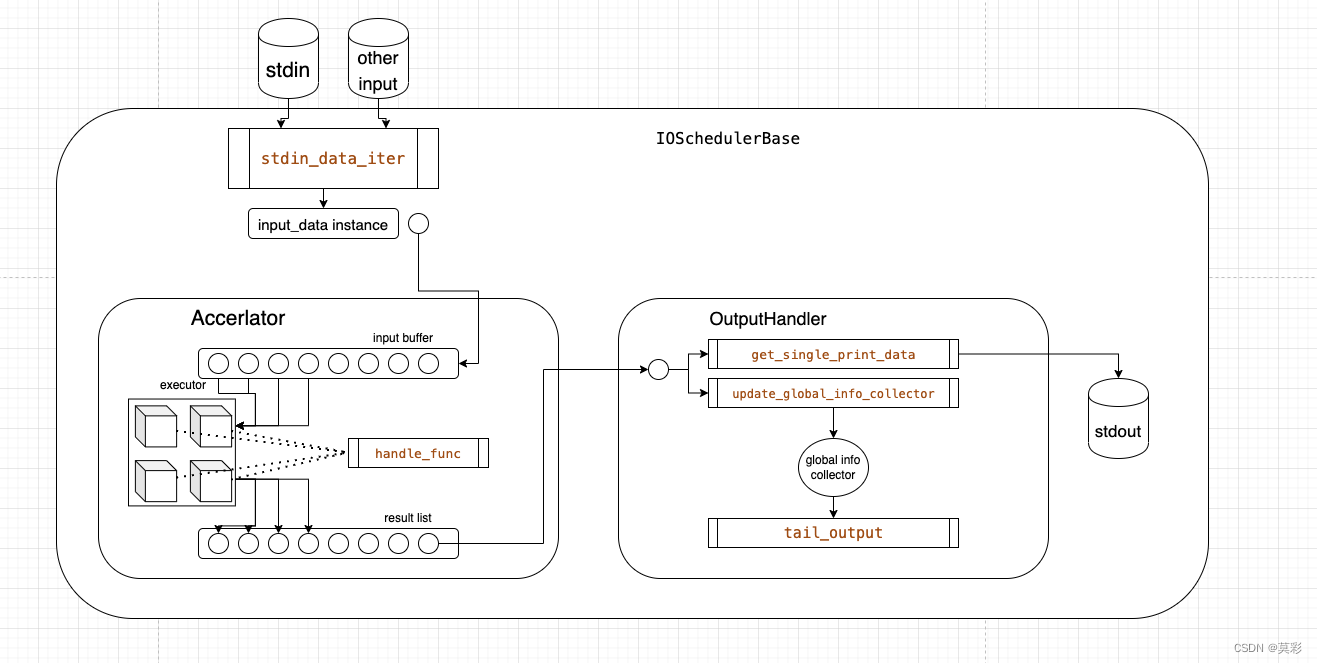
代码实现我这里先不给出,读者可以自己尝试一下如何实现,其实并不复杂。
即时编译
这个我常用的工具是 numba。
njit
一般想想要发挥比较好的性能提升的话,尽量都使用 nopython 模式。我们展开个例子讲一下。
case1 计算熵
先给出计算熵的例子,先用 numpy 实现一个常规版本,这个版本其实日常用不追求性能完全足够了。
def entropy(data):
sum_ = np.sum(data)
probs = data / sum_
log_probs = np.log2(probs)
ent = -1 * np.sum(probs * log_probs)
return ent
a = np.array(np.random.randint(0, 100, (500,)), np.float64)
%timeit entropy(a) # 19.5 µs ± 181 ns
下面是 njit 编译的版本,去掉编译时间,可以看到时间明显变短
@nb.njit
def entropy_fast(data):
#sum_ = np.sum(data)
sum_ = 0
for i in data:
sum_ += i
# probs = []
# log_probs = []
ent = 0
for i in data:
p = i/sum_ + 1e-5
# probs.append(p)
# log_probs.append(math.log2(p))
ent += p * np.log2(p)
# ent = -1 * np.sum(probs * log_probs)
return ent * -1
entropy_fast(a) # 触发编译
%timeit entropy_fast(a) # 4.18 µs ± 26.2 ns
我们也可以使用手动签名的 njit,如这样:@nb.njit("float64(float64[:])"),这样会加快编译速度,但是运行速度几乎不变。
case2 找到最大概率类别
a = np.array(np.random.randint(0, 1100, (1500,)), np.str)
b = np.array(np.random.randint(0, 1100, (1500,)), np.float64)
def get_max_ratio(keys, values):
idx = np.argmax(values)
sum_ = np.sum(values)
return keys[idx], values[idx] / sum_
%timeit get_max_ratio(a,b) # 9.17 µs ± 452 ns
这个有一个问题,就是貌似 numba 不接受 str 类型的参数,一般可以通过外部封装一层的方式解决。
def get_max_ratio_fast(k,v):
idx, ratio = get_max_ratio_fast_(v)
return k[idx], ratio
def get_max_ratio_fast(k,v):
idx, ratio = get_max_ratio_fast_(v)
return k[idx], ratio
@nb.njit("Tuple((int64,float64))(float64[:])")
def get_max_ratio_fast_(values:list):
max_idx = 0
max_value = 0
sum_ = 0
for i, v in enumerate(values):
if v > max_value:
max_idx = i
max_value = v
sum_ += v
return max_idx, max_value / sum_
%timeit get_max_ratio_fast(b) #2.04 µs ± 96.9 ns
可以参考看看这个文章:https://zhuanlan.zhihu.com/p/434078992
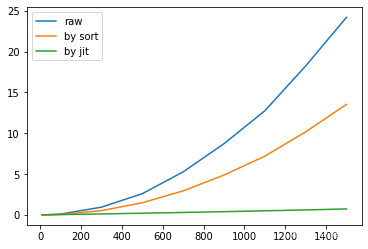
case3 计算两两准确率
前面两个场景都是 numpy 自身优化已经做得很不错了,使用 numba 有收益,但是除非在瓶颈时否则收益不大。这也是前面重点强调的: 第一个准则是“不要优化”,第二个准则是“不要优化那些无关紧要的部分” 的意思。
但是有一些场景,用 numpy 不好实现,或者说实现起来比较麻烦,那么此时我们就可以试试 numba 了,反正已经麻烦了,不如一步到位。
比如我这里举一个例子,也是工作中常常遇到的真实场景。比如我们有一组数据,我们要计算他们两两之间的关系,通常是类似偏序关系的指标计算,或者有向图相关的计算。我们就确定一个明确的案例,计算一组带 label 数据两两之间的准确率。因为这个问题需要双层循环,所以,numpy 实现起来还比较麻烦。(其实可以利用 numpy 的广播机制,不过可能很多同学想不到,双层循环式最直观的想法了)。
下面给出一个基础版本,应该很好理解。
def pair_acc(label:list, score:list) -> float:
assert len(label) == len(score)
length = len(label)
right = wrong = 0
for i in range(length):
for j in range(i+1, length):
if label[i] == label[j]:
continue
if label[i] > label[j] and score[i] > score[j] or\
label[i] < label[j] and score[i] < score[j]:
right += 1
else:
wrong += 1
return right / (right + wrong)
我们再给出一个从逻辑上简单优化的版本,大致思路是,两个数据 label 如果一致不需要比较,因此可以直接跳过(也就是上面的 continue 部分)。其实很有很多优化点,不过这里只是做一个好一点的baseline,不做过多探讨。
# 预排序加速版本
def pair_acc2(label, score):
assert len(label) == len(score)
length = len(label)
zip_list = list(zip(label, score))
zip_list.sort(key=lambda x:x[0])
label_, score_ = zip(*zip_list)
i = j = 0
right = error = 0
while i < length:
j = i
while j < length and label_[j] == label_[i]:
j += 1
while j < length:
if score_[j] > score_[i]:
right += 1
else:
error += 1
j += 1
i += 1
acc = right / (right + error)
return acc
然后就是给出 numba 版本,其实这种已经用循环方式写好的计算逻辑,特别容易转为 numba。我们直接看下代码,可以发现基本上就是 python 原始代码加了装饰器就可以。另外同样为了保证排序,这一步也是在 numba 版本函数外部封装了一层做到的。
# 加速2:jit编译
@nb.jit(nopython=True)
def pair_acc_fast_for_sorted(label_, score_):
#assert len(label) == len(score)
length = len(label_)
i = j = 0
right = error = 0
while i < length:
j = i
while j < length and label_[j] == label_[i]:
j += 1
while j < length:
if score_[j] > score_[i]:
right += 1
else:
error += 1
j += 1
i += 1
return right / (right + error)
# pair_acc_fast_for_sorted的外围函数,执行预排序的功能
def pair_acc_fast(label, score):
zip_list = list(zip(label, score))
zip_list.sort(key=lambda x:x[0])
label_, score_ = zip(*zip_list)
label_ = np.array(list(label_))
score_ = np.array(list(score_))
acc = pair_acc_fast_for_sorted(label_, score_)
return acc

GPU
【TODO】
使用工具
- 对于加载一个大文件内部转换为 dict 的场景可以转为使用 leveldb。
- regex 可以作为内置 re 包的无缝高性能替代。
- 大量的 json 解析和 dump 工作时可以使用第三方高效 json 包,ujson 是一个可以的选择。