问题复现
现在有这么一种业务场景,需要将海量的数据通过Hive进行数据清洗并统计,最后落库到ES中,因为需要支持大数据量的分词,模糊搜索,所以考虑用ES而不直接放到Mysql中,前端需要直接对数据进行交互,当通过后端请求向ES中新增一条数据时,页面数据刷新不会立即查询出新增的数据,即ES中的数据会存在延迟刷新
原因分析
这里先讲下ES中的一些基础概念,Shard(片)、Segment(段)、 In-memory buffer(内存索引缓存区)。
ES中的文档,是被组织在一个个片中的,一个索引可以分成多个分片,这个分片的数量在创建索引时,就要确定好。而每个片,是由多个Segment组成的,也就是说,ES存储数据的基本物理单元是Segment。
新增或修改一个文档的操作是这样的:
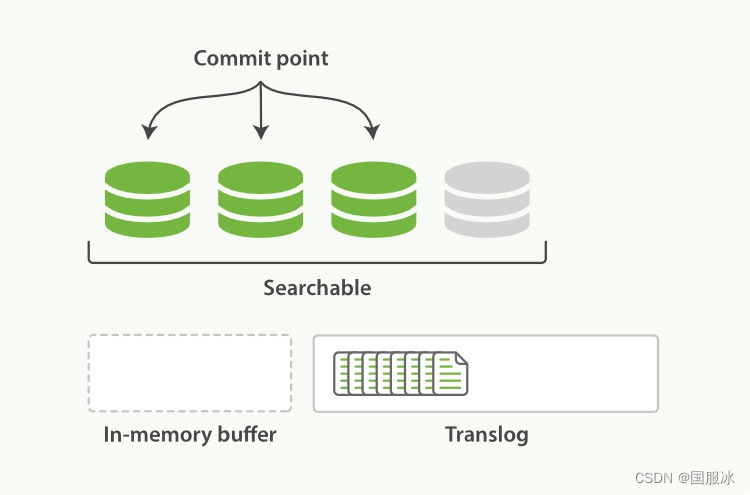
客户端对文档的修改,会放到内存索引缓存区中,在内存索引缓存区中会将这些修改组织成一个Segment,然后将这个Segment持久化到磁盘中。一旦Segment持久化成功,该文档的修改对客户端才可见。

如图:In-memory buffer就是内存索引缓存区,这里的内容将会组织成一个个Segment,此时它还不可搜索。
矛盾来了,Segment持久化就要写磁盘,而写磁盘是非常耗性能的。
因此,ES引入一个FileSystem Cache(文件系统缓存)的概念。
In-memory buffer 中的内容,先不持久化到磁盘,而是先写入FileSystem Cache,一旦写入FileSystem Cache ,则这些内容也可以索引到了。当FileSystem Cache 达到一定数量级,或者达到某个时间点,它会调用写磁盘的操作,把它的内容写入磁盘(这一点在下文持久化中详细说明)。这样,就不会频繁写入磁盘了。
写入FileSystem Cache 是一个比较轻量级的操作,In-memory buffer 写入FileSystem Cache 的频率可以控制,默认是1s写入一次。
这也解释了开头说的ES近实时性。即对文档的修改,默认最多等 1s,就可以索引到了。
In-memory buffer 写入FileSystem Cache 的动作,称为Refresh。
Refresh的频率可以调整,对于迁移旧索引文件的操作,则可以把Refresh频率设置更长时间,比如30s,因为你对实时性要求并不高。
如果你实时性要求很高,也可以手工调用Refresh进行数据的刷新。
这里,官网有这么一段话:
尽管刷新是比提交轻量很多的操作,它还是会有性能开销。当写测试的时候, 手动刷新很有用,但是不要在生产环境下每次索引一个文档都去手动刷新。 相反,你的应用需要意识到 Elasticsearch 的近实时的性质,并接受它的不足。
解决思路
问题是elasticsearch中更新数据后有延迟
① 解决方案1 :
在新增一条文档数据,返回响应数据之前,让线程睡眠1秒钟,然后再返回响应数据,发现页面在新增文档跳转到文档列表页面后可以看到新增的文档数据了,但是休眠1S也可能会出现无法正常响应的结果;
② 解决方法2:indexRequest.setRefreshPolicy(WriteRequest.RefreshPolicy.IMMEDIATE);
Elasticsearch 刚索引的文档并不是立即对搜索可见,它们会先在内存buffer中,待buffer 数据满后或主动刷新操作才会写入到文件缓存区中,便可以搜索。通过设置参数手动让内存buffer中的数据立即Refresh到FileSystem Cache中,便可实时操作文档数据,但是从前面的分析可见,会影响性能;
持久化
上面仔细看的同学,可能会注意到,FileSystem Cache之所以快,是因为他是内存的写入,没有及时提交到磁盘。如果FileSystem Cache在提交前,ES崩了,那数据不是丢失了吗?
因此,ES又引入一个概念:translog(事务日志)
每一次对 Elasticsearch 进行操作时均会进行translog的记录。所以,引入translog后的写数据过程,是这样的:
- 一个文档被索引之后,就会被添加到内存缓冲区(In-memory buffer),并且 追加到了translog 。
如下图所示:

- 每秒钟通过refresh,会将In-memory buffer 中的数据写入FileSystem Cache,并清空In-memory
buffer,注意,此时并不会清空translog,如下图所示:
- 这个进程不断工作,Translog大小不断增加;此时,ES会执行一个Flush操作,该操作可以将Translog截断,清空原来的Translog区,并且,此时FileSystem Cache 中的内容也会持久化到磁盘。
Flush操作的频率可以设置 ,默认是每30分钟一次,或者是当Translog大小达到一定阈值,也会触发Flush操作,这些都可以设置 。
注意,这里的Flush操作并没有涉及到translog的提交。那translog是什么时候提交的呢?我们通过translog来保证持久化,那它本身是否是安全的呢?
这里引用官网的一段话:
translog 的目的是保证操作不会丢失。这引出了这个问题: Translog 有多安全?
在文件被 fsync 到磁盘前,被写入的文件在重启之后就会丢失。默认 translog 是每 5 秒被 fsync 刷新到硬盘, 或者在每次写请求完成之后执行(e.g. index, delete, update, bulk)。这个过程在主分片和复制分片都会发生。最终,基本上,这意味着在整个请求被 fsync 到主分片和复制分片的translog之前,你的客户端不会得到一个 200 OK 响应。
在每次请求后都执行一个 fsync 会带来一些性能损失,尽管实践表明这种损失相对较小(特别是bulk导入,它在一次请求中平摊了大量文档的开销)。
但是对于一些大容量的偶尔丢失几秒数据问题也并不严重的集群,使用异步的 fsync 还是比较有益的。比如,写入的数据被缓存到内存中,再每5秒执行一次 fsync 。
这个行为可以通过设置 durability 参数为 async 来启用:
PUT /my_index/_settings
{
“index.translog.durability”: “async”,
“index.translog.sync_interval”: “5s”
}
这个选项可以针对索引单独设置,并且可以动态进行修改。如果你决定使用异步 translog 的话,你需要 保证 在发生crash时,丢失掉 sync_interval 时间段的数据也无所谓。请在决定前知晓这个特性。如果你不确定这个行为的后果,最好是使用默认的参数( “index.translog.durability”: “request” )来避免数据丢失。
可以看到translog默认是每次写入数据并返回客户端前,会写入成功translog。只有写入translog成功了,才会跟客户端说写入成功。
这跟mysql的redo日志有点相似 。所以说,translog是安全的。
Segment
上面我们提到,ES对索引的修改会在In-memory buffer中,每隔一秒形成一个段提交到FileSystem Cache中,这样不久,segment 的数量会很多。而段数目太多会带来较大的麻烦。 每一个段都会消耗文件句柄、内存和cpu运行周期。更重要的是,每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
Elasticsearch通过在后台进行段合并来解决这个问题。小的段被合并到大的段,然后这些大的段再被合并到更大的段。
段合并的时候会将那些旧的已删除文档从文件系统中清除。被删除的文档(或被更新文档的旧版本)不会被拷贝到新的大段中。
注意:ES对于文档的删除,是将此文档打上一个.del的标,在段合并时,才会真正将此段删除。
段合并的过程,是ES自动完成的,我们无须进行干预。