文章目录
- 第一节:汇编指令格式讲解
- 1. 汇编指令格式
- 2. 生成汇编方法
- 第二节:汇编常用指令讲解
- 1. 相关寄存器
- 2. 常用指令
- 3. 条件码
- 第三节:各种变量赋值汇编实战
- 1. 各种变量赋值汇编实战解析
- 第四节:选择循环汇编实战
- 1. 选择循环汇编实战解析
- 第五节:函数调用汇编
- 1. 函数调用汇编实战
- 2. 机器码
第一节:汇编指令格式讲解
1. 汇编指令格式
CPU是如何执行我们的程序的?

我们编译后的可执行程序,也就是main.exe,是放在代码段的,PC指针寄存器存储了一个指针,始终指向要执行的指令,读取了代码段的某一条指令后,会交给译码器来解析,这时候译码器就知道要做什么事了,CPU中的计算单元,加法器不能直接对栈上的某个变量a,直接做加1的操作,需要首先将栈,也就是内存上的数据,加载到寄存器中,然后再利用加法器加1操作,在从寄存器搬到内存上去。
CPU读写寄存器的速度比读写内存的速度要快很多。
操作码字段:表征指令的操作特征与功能(指令的唯一标识),不同的指令操作码不能相同。
地址码字段:指定参与操作的操作数的地址码。
指令中指定操作数存储位置的字段称为地址码,地址码中可以包含存储区地址。也可以包含寄存器编号。
指令中可以有一个、两个或者三个操作数,也可以没有操作数,根据一条指令有几个操作数地址,可以将指令分为零地址指令,一地址指令,二地址指令,三地址指令。4个地址码的指令很少被使用。

零地址指令:只有操作码,没有地址码(空操作,停止等)。
一地址指令:指令编码中只有一个地址码,指出了参加操作的一个操作数的存储位置,如果还有另一个操作数则隐含在累加器中。
二地址指令:指令编码中有两个地址,分别指出了参加操作的两个操作数的存储位置,结果存储在其中一个地址中。
三地址指令:指令编码中有3个地址码,指出了参加操作的两个操作数的存储位置和一个结果的地址。
二地址指令格式中,从操作数的物理位置来说可归为三种类型。
寄存器英文:register
存储器英文:storage
寄存器-寄存器(RR)型指令:需要多个通用寄存器或个别专用寄存器,从寄存器中取操作数,把操作结果放入到另一个寄存器,执行速度非常快,不需要访问内存。
寄存器-存储器(RS)型指令:执行此类指令时,既要访问内存单元,又要访问寄存器。
存储器-存储器(SS)型指令:操作时都是涉及内存单元,参与操作的数都是放在内存里,从内存某单元中取操作数,操作结果存放至内存另一个单元中,因此机器执行此指令需要多次访问内存。
复杂指令集:变成 x86 CISI (一般是PC端)
精简指令集:等长 arm TISI (一般是手机端)
2. 生成汇编方法
编译过程:
第一步:main.c --> 编译器 --> main.s 文件(.s文件就是汇编文件,文件内是汇编代码)
第二步:main.s 汇编文件 --> 汇编器 --> main.obj 文件
第三步:main.obj文件 --> 链接器 --> 可执行文件 exe
方法步骤:(以CLion为例)
1.配置环境变量。

说明:Mac电脑无需设置环境变量,直接进行下面的操作。
2.完成C代码的编写,在终端窗口输入gcc -S -fverbose-asm main.c,就可以生成汇编文件main.s。

说明:安装MC68000插件,汇编代码即可高亮显示。

第二节:汇编常用指令讲解
1. 相关寄存器

除EBP和ESP外,其他几个寄存器的用途是比较任意的,也就是什么都可以存。
2. 常用指令
汇编指令通常可以分为数据传送指令、逻辑计算指令和控住流指令。以Interl为例:

<1>数据传送指令:
1)mov指令。将第二个操作数(寄存器的内容,内存中的内容或常数值)复制到第一个操作数(寄存器或内存),但不能直接从内存复制到内存。
语法如下:
mov <reg>,<reg>
mov <reg>,<mem>
mov <men>,<reg>
mov <reg>,<con>
mov <mem>,<con>
举例:
mov eax, ebx # 将ebx值复制到eax
mov byte prt [var],5 # 将5保存到var值指示的内存地址的一字节中
2)push指令。将操作数压入内存的栈,常用于函数调用。ESP是栈顶,压栈前先将ESP值减4(栈增长方向与内存地址增长方向相反),然后将操作数压入ESP指示的地址。
语法如下:
push <reg32>
push <mem>
push <con32>
举例:(注意,栈中元素固定为32位)
push eax # 将eax压入栈
push [var] # 将var值指示的内存地址的4字节值压入栈
3)pop指令。与push指令相反,pop指令执行的是出栈工作,出栈前先将ESP指示的地址中的内容出栈,然后将ESP值加4.
语法如下:
pop edi # 弹出栈顶元素送到edi
pop [ebx] # 弹出栈顶元素送到ebx值指示的内存地址的4字节中
<2>算术和逻辑指令:
1)add/sub指令。add指令将两个操作数相加,相加的结果保存到第一个操作数中。sub指令用于两个操作数相减,相减的结果保存到第一个操作数中。
语法如下:
add <reg>,<reg> / sub <reg>,<reg>
add <reg>,<mem> / sub <reg>,<mem>
add <mem>,<reg> / sub <mem>,<reg>
add <reg>,<con> / sub <reg>,<con>
add <mem>,<con> / sub <mem>,<con>
举例:
sub eax,10 # eax <- eax-10
add byte prt [var],10 # 10与var值指示的内存地址的一字节值相加,并将结果保存在var值指示的内存地址的字节中
2)inc/dec指令。inc、dec指令分别表示将操作数自加1、自减1。
语法如下:
inc <reg> / dec <reg>
inc <mem> / dec <mem>
举例:
dec eax # eax值自减1
inc dword ptr [var] # var值指示的内存地址的4字节值加1
3)imul指令。带符号整数乘法指令,有两种形式:1.两个操作数。将两个操作数相乘,将结果保存在第一个操作数中,第一个操作数必须为寄存器。2.三个操作数。将第二个和第三个操作数相乘,将结果保存在第一个操作数中,第一个操作数必须为寄存器。
语法如下:
imul <reg32>,<reg32>
imul <reg32>,<mem>
imul <reg32>,<reg32>,<con>
imul <reg32>,<mem>,<con>
举例:
imul eax,[var] # eax <- eax * [var]
imul esi,edi,25 # esi <- edi * 25
乘法操作结果有可能溢出,则编译器溢出标志OF=1,以使CPU调出溢出异常处理程序。
4)idiv指令。带符号整数除法指令,它只有一个操作符,即除数,而被除数则为edx:eax中的内容(64位整数),操作符结果有两部分:商和余数,商送到eax,余数送到edx。
语法如下:
idiv <reg32>
idiv <mem>
举例:
idiv ebx
idiv dword ptr [var]
5)and/or/xor指令。and、or、xor指令分别是按位与、按位或、按位异或操作指令,用于操作数的位操作(按位与、按位或、异或),操作结果放在第一个操作符中。
语法如下:
and <reg>,<reg> / or <reg>,<reg> / xor <reg>,<reg>
and <reg>,<mem> / or <reg>,<mem> / xor <reg>,<mem>
and <mem>,<reg> / or <mem>,<reg> / xor <mem>,<reg>
and <reg>,<con> / or <reg>,<con> / xor <reg>,<con>
and <mem>,<con> / or <mem>,<con> / xor <mem>,<con>
举例:
and eax,0fH # 将eax中的前28位全部置为0,最后4位保持不变
xor edx,edx # 置edx中的内容为0
6)not指令。为翻转指令,将操作数中的每一位翻转,即0->1,1->0。
语法如下:
not <reg>
not <mem>
举例:
not byte ptr [var] # 将var值指示的内存地址的一字节的所有位翻转
7)neg指令。取负指令。
语法如下:
neg <reg>
neg <mem>
举例:
neg eax # eax <- -eax
8)shl/shr指令。逻辑移位指令,shl为逻辑左移,shr为逻辑右移,第一个操作数表示被操作数,第二个操作数指示位移的位数。
语法如下:
shl <reg>,<con8> / shr <reg>,<con8>
shl <mem>,<con8> / shr <mem>,<con8>
shl <reg>,<cl> / shr <reg>,<cl>
shl <mem>,<cl> / shr <mem>,<cl>
举例:
shl eax,1 # 将eax值左移1位,相当于乘以2
shr ebx,cl # 将ebx值右移n位(n为cl中的值),相当于除以2的n次方
9)lea指令。地址传送指令,将有效地址传送到指定的寄存器。
lea eax,DWORD PTR_arr$[ebp]
lea指令的作用,是DWORD PTR_arr$[ebp]对应空间的内存地址值放到eax中。
<3>控制流指令:
x86处理器维持着一个指示当前执行指令的指令指针(IP),当一条指令执行后,此指针自动指向向下一条指令。IP寄存器不能直接操作,但可以用控制流指令更新。通常用标签(label)指示程序中的指令地址,在x86汇编代码中,可在任何指令前加入标签。例如:
mov esi,[ebp+8]
begin: xor ecx,ecx
mov eax,[esi]
这样就用begin(begin代表标签名,可以为别的名字)指示了第二条指令,控制流指令通过标签可以实现实现指令的跳转。
1)jmp指令。jmp指令控制IP转移到label所指示的地址(从label中取出指令执行)。
语法如下:
jmp <label>
举例:
jmp begin # 跳转到begin标记的指令执行
2)jcondition指令。条件转移指令,依据CPU状态字中的一系列条件状态转移,CPU状态字中包括指示最后一个算术运算结果是否为0,运算结果是否为负数等。
语法如下:
je <label> (jump when equal)
jne <label> (jump when not equal)
jz <label> (jump when last result was zero)
jp <label> (jump when greater than)
jge <label> (jump when greater than or equal to)
jl <label> (jump when less than)
jle <label> (jump when less than or equal to)
举例:
cmp eax,ebx
jle done # 如果eax的值小于等于ebx的值,跳转到done指示的指令执行,否则执行下一跳指令
3)cmp/test指令。cmp指令用于比较两个操作数的值,test指令对两个操作数进行逐位与运算,这两类指令都不保存操作结果,仅根据运算结果设置CPU状态字中的条件码。
语法如下:
cmp <reg>,<reg> / test <reg>,<reg>
cmp <reg>,<mem> / test <reg>,<mem>
cmp <mem>,<reg> / test <mem>,<reg>
cmp <reg>,<con> / test <reg>,<con>
cmp和test指令通常和jcondition指令搭配使用,举例:
cmp dword ptr [var],10 # 将var指示的主存地址的4字节内容,与10比较
jne loop # 如果相等则继续顺序执行,否则跳转到loop处执行
test eax,eax # 测试eax是否为零
jz xxxx # 为零则置标志ZF为1,跳转到xxxx处执行
4)call/ret指令。分别用于实现程序(过程,函数等)的调用及返回。
语法如下:
call <label>
ret
call指令首先将当前执行指令地址入栈,然后无条件转移到由标签指示的指令。与其他简单的跳转指令不同,call指令保存调用之前的地址信息(当call指令结束后,返回调用之前的地址)。
ret指令实现了程序的返回机制,ret指令弹出栈中保存的指令地址,然后无条件转一件到保存的指令地址执行,call和ret是程序(函数)调用中最关键的两条指令。
3. 条件码
编译器通过条件码(标志位)设置指令和各类转移指令来实现程序中的选择结构语句。
1.条件码(标志位)
除了整数寄存器,CPU还维护者一组条件码(标志位)寄存器,他们描述了最近的算术或逻辑运算操作的属性。可以检测这些寄存器来执行条件分支指令,最常用的条件码有:
CF:进(借)为标志。最近无符号整数加(减)运算后的进(借)位情况。有进(借)位,CF=1,否则CF=0。如(unsigned)t<(unsigned)a,因为判断大小是相减。
ZF:零标志。最近的操作的运算结算是否为0,若结果为0,ZF=1;否则ZF=0。如(t==0)。
SF:符号标志。最近的带符号数运算结果的符号。负数时,SF=1;否则SF=0。
OF:溢出标志。最近带符号数运算的结果是否溢出,若溢出,OF=1;否则OF=0。
可见,OF和SF对无符号数运算来说没有意义,而CF对带符号数来说没有意义。
如何判断溢出,简单的就是正数相加变负数为溢出,负数相加变正数溢出。考研中通常考十六进制的两个数的溢出,可如下方法判断:
- 数据位高位进位,符号位进位未进位,溢出。
- 数据位高位未进位,符号位进位,溢出。
- 数据位高位进位,符号位进位,不溢出。
- 数据位高位未进位,符号位未进位,不溢出。
简单来说就是数据位高位和符号位高位进位不一样的时候就会溢出。
常见的算术逻辑运算指令(add,sub,imul,or,and,shl,inc,dec,not,sal等)会设置条件码。但有两类指令只设置条件码而不改变任何其他寄存器,即cmp和test指令,cmp指令和sub指令的行为一样,test指令与and指令的行为一样,但它们只设置条件码,而不更新目的寄存器。
控制流指令中的jcondition条件转移指令,就是根据条件码ZF和SF来实现跳转。
注意:乘法溢出后,可以跳转到“溢出自陷指令”,例如int 0x2e就是一条自陷指令,但是考研只需要掌握溢出,可以跳转到“溢出自陷指令”即可,不需要记自陷指令有哪些。
第三节:各种变量赋值汇编实战
1. 各种变量赋值汇编实战解析
针对整型,整型数组,整型指针变量的赋值(浮点与字符等价的),对应的汇编进行解析。首先编写C代码。
#include <stdio.h>
int main() {
int arr[3]={1,2,3};
int *p;
int i=5;
int j=10;
i=arr[2];
p=arr;
printf("i=%d\n",i);
return 0;
}
# 生产汇编代码指令
gcc -m32 -masm=intel -S -fverbose-asm main.c
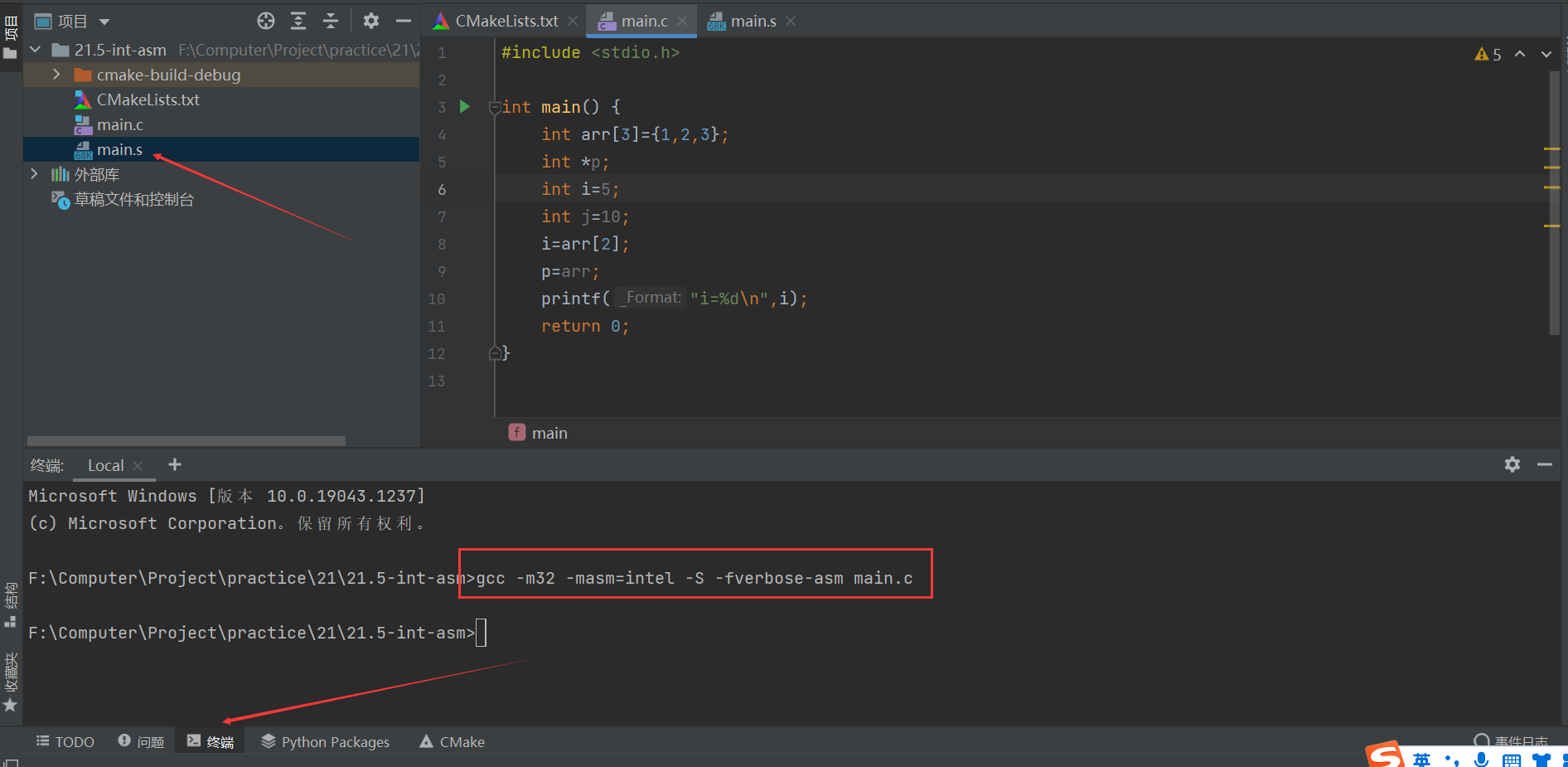
C代码在让CPU去运行时,其实所有的变量名都已经消失了,实际是数据从一个空间,拿到另一个空间的过程。
我们访问所有变量的空间都是通过栈指针(esp时刻都存着栈指针,也可以称为栈顶指针)的偏移,来获取对应变量内存空间的数据的。
.text
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "i=%d\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
push ebp #
mov ebp, esp #,
and esp, -16 #,
sub esp, 48 #,
# main.c:3: int main() {
call ___main #
# main.c:4: int arr[3]={1,2,3};
mov DWORD PTR [esp+24], 1 # arr, # 把常量1放入栈指针(esp寄存器存的栈指针)偏移24个字节的位置
mov DWORD PTR [esp+28], 2 # arr, # 同上解释
mov DWORD PTR [esp+32], 3 # arr, # 同上解释
# main.c:6: int i=5;
mov DWORD PTR [esp+44], 5 # i, # 把常量5放入栈指针偏移44个字节的位置,这个位置时变量i的空间
# main.c:7: int j=10;
mov DWORD PTR [esp+40], 10 # j, # 把常量10放入栈指针偏移40个字节的位置,这个位置时变量j的空间
# main.c:8: i=arr[2];
mov eax, DWORD PTR [esp+32] # tmp89, arr # 把栈指针偏移32个字节的位置拿到的数据,存放到寄存器eax中
mov DWORD PTR [esp+44], eax # i, tmp89 # 把eax寄存器的内容放入栈指针偏移44个字节的位置,偏移44个字节的位置刚好是i的空间
# main.c:9: p=arr;
lea eax, [esp+24] # tmp90, # lea和mov不一样,是拿栈指针偏移24个字节的位置的地址,把地址放到eax寄存器中
mov DWORD PTR [esp+36], eax # p, tmp90 # 把eax寄存器的内容放入栈指针偏移36个字节的位置。栈指针偏移36个字节的位置,刚好是p的空间
# main.c:10: printf("i=%d\n",i);
mov eax, DWORD PTR [esp+44] # tmp91, i # 把栈指针,偏移44个字节的位置拿到的数据,放到寄存器eax中
mov DWORD PTR [esp+4], eax #, tmp91 # 把eax数据放到栈指针偏移4个字节位置的内存中
mov DWORD PTR [esp], OFFSET FLAT:LC0 #, # 把LC0(也就是上面那个字符串)的地址,放到寄存器栈指针执行的内位置
call _printf # # 调用printf函数
# main.c:11: return 0;
mov eax, 0 # _10,
# main.c:12: }
leave
ret
.ident "GCC: (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project) 8.1.0"
.def _printf; .scl 2; .type 32; .endef
说明:ptr是pointer(指针)的缩写。
汇编里面ptr是规定的字(既保留字),是用来临时指定类型的。可以理解为:ptr是临时的类型转换,相当于C语言中的强制类型转换。
例如:mov ax,bx。是把bx寄存器里的值赋予ax,由于二者都是寄存器,长度已定(word型),所以没有必要加WORD.
mov ax,word ptr [bx]。是把内存地址等于“bx寄存器的值”的地方所存放的数据,赋予ax。由于只是给出一个内存地址,不知道希望赋予的ax的,是byte还是word,所以可以用word明确指出;如果不用,既(mov ax,[bx]),则在8086中是默认传递一个字,即链各个字节给ax。
intel中的:
- dword ptr 长字(4字节)
- word ptr 双字
- byte ptr 一字节
第四节:选择循环汇编实战
1. 选择循环汇编实战解析
#include <stdio.h>
int main() {
int i=5;
int j=10;
if(i<j){
printf("i is small\n");
}
for(i=0;i<5;i++){
printf("this is loop\n");
}
return 0;
}
生成汇编代码的方法和上一节一致。
.text # 这里是文字常量区,放了我们的字符串常量,LC0和LC1分别是我们要用到的两个字符串常量的起始地址
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "i is small\0"
LC1:
.ascii "this is loop\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
push ebp #
mov ebp, esp #,
and esp, -16 #,
sub esp, 32 #,
# main.c:3: int main() {
call ___main #
# main.c:4: int i=5;
mov DWORD PTR [esp+28], 5 # i, # 把常量5放入栈指针偏移28个字节的位置,这个位置是变量i的空间
# main.c:5: int j=10;
mov DWORD PTR [esp+24], 10 # j, # 把常量10放入栈指针偏移24个字节的位置,这个位置是变量j的空间
# main.c:6: if(i<j){
mov eax, DWORD PTR [esp+28] # tmp89, i # 把栈指针偏移28个字节的位置内的值,放入eax寄存器
cmp eax, DWORD PTR [esp+24] # tmp89, j # 比较eax寄存器内的值和栈指针偏移24个字节位置的值的大小,拿eax寄存器的值减去DWORD PTR [esp+24],然后设置条件码
jge L2 #, # 如果eax寄存器大于等于DWORD PTR [esp+24],那么跳转到L2,否则直接往下执行,jge是根据条件码ZF和SF来判断的。
# main.c:7: printf("i is small\n");
mov DWORD PTR [esp], OFFSET FLAT:LC0 #, # 把LC0的地址,放到寄存器栈指针指向的内存位置
call _puts #
L2:
# main.c:9: for(i=0;i<5;i++){
mov DWORD PTR [esp+28], 0 # i, # 把常量0放入栈指针偏移28个字节的位置,这个位置是变量i的空间
# main.c:9: for(i=0;i<5;i++){
jmp L3 # # 无条件跳转到L3
L4:
# main.c:10: printf("this is loop\n");
mov DWORD PTR [esp], OFFSET FLAT:LC1 #, # 把LC1的地址,放到寄存器栈指针指向的内存位置
call _puts #
# main.c:9: for(i=0;i<5;i++){
add DWORD PTR [esp+28], 1 # i,
L3:
# main.c:9: for(i=0;i<5;i++){
cmp DWORD PTR [esp+28], 4 # i, # 比较栈指针偏移24个字节位置的值域4的大小,拿DWORD PTR [esp+24]减去4,然后形成条件码
jle L4 #, # 小于等于就跳转到L4
# main.c:12: return 0;
mov eax, 0 # _11,
# main.c:13: }
leave
ret
.ident "GCC: (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project) 8.1.0"
.def _puts; .scl 2; .type 32; .endef
这里主要掌握指令:cmp,jge,jmp,jle等,以及了解以下字符串常量是存放在文字常量区。
第五节:函数调用汇编
1. 函数调用汇编实战
#include <stdio.h>
int add(int a,int b){
int ret;
ret=a+b;
return ret;
}
int main() {
int a,b,ret;
int *p;
a=5;
p=&a;
b=*p+2;
ret=add(a,b);
printf("add result=%d\n",ret);
return 0;
}
生成汇编代码的方法和上一节一致。
函数调用的汇编原理解析:
首先明确一点,函数栈是向下生长的,所谓向下生长,是指从内存高地址向内存低地址的路径延伸。于是,栈就有了栈底和栈顶,栈顶的地址要不栈底的低。
对x86体系的CPU而言,寄存器ebp可称为帧指针或基址指针(base poin
ter),寄存器esp可以称为栈指针(stack pointer)。
说明:
-
ebp在为改变之前始终指向栈帧的开始(也就是栈底),所以ebp的用途是在堆栈中寻址。
-
esp会随着数据的入栈和出栈而移动,即esp始终指向栈顶。
假设函数A调用函数B,称函数A为调用者,函数B为被调用者,则函数调用过程描述如下:
(1)首先将调用者A的堆栈的基址(ebp)入栈,以保存之前任务的信息。
(2)然后将调用者A的栈顶指针(esp)的值赋给ebp,作为新的基址(即被调用者B的栈底),原有函数的栈顶,是新函数的栈底。
(3)再后在这个基址(被调用者B的栈底)上开辟(一般是sub指令)相应的空间用作被调用者B的栈空间。
(4)函数B返回后,当前栈帧的ebp恢复为调用者A的栈顶(esp),使栈顶恢复函数B被调用前的位置,然后调用者A从恢复后的栈顶弹出之前的ebp值(因为这个值在函数调用前一步被压入堆栈)。

这样,ebp和esp就都回复了调用函数B前的位置,即栈恢复函数B调用前的状态,相当于(ret指令做了什么)
mov esp,ebp // 把ebp内的内容赋值到esp寄存器中,也就是B函数的栈基作为原有调用者A函数的栈顶
pop ebp // 弹出栈顶元素,放到ebp寄存器中,因为原有A函数的栈基指针被压到了内存里,所以弹出后,放入ebp,这样原函数A的现场恢复完毕

.text
.globl _add
.def _add; .scl 2; .type 32; .endef
_add: # add函数的入口,这里阅读需要结合函数调用图
push ebp # # 把原有函数,也就是main函数的栈基指针压栈,压栈是把ebp的值保存到内存上,位置就是esp指向的位置
mov ebp, esp #, # 把main的栈顶指针esp,作为add函数的栈基指针ebp
sub esp, 16 #, # 由于add函数自身要使用栈空间,把esp减去16,是指add函数的栈空间大小是16个字节
# main.c:5: ret=a+b;
mov edx, DWORD PTR [ebp+8] # tmp93, a # 拿到实参,也就是a的值,放入edx
mov eax, DWORD PTR [ebp+12] # tmp94, b # 拿到实参,也就是b的值,放入eax
add eax, edx # tmp92, tmp93 # jiang eax和edx相加
mov DWORD PTR [ebp-4], eax # ret, tmp92 # 把eax,也就是ret的值,放入ebp减4个字节位置
# main.c:6: return ret;
mov eax, DWORD PTR [ebp-4] # _4, ret
# main.c:7: }
leave
ret # 函数返回,弹出压栈的指令返回地址,回到main函数执行
.def ___main; .scl 2; .type 32; .endef
.section .rdata,"dr"
LC0:
.ascii "add result=%d\12\0"
.text
.globl _main
.def _main; .scl 2; .type 32; .endef
_main:
push ebp #
mov ebp, esp #,
and esp, -16 #,
sub esp, 32 #,
# main.c:8: int main() {
call ___main #
# main.c:11: a=5;
mov DWORD PTR [esp+16], 5 # a, # 把常量5放入栈指针偏移16个字节的位置,这个位置是变量a的空间
# main.c:12: p=&a;
lea eax, [esp+16] # tmp91, # 这里用lea,和mov不一样,是将esp+16位置的地址,放到eax寄存器中
mov DWORD PTR [esp+28], eax # p, tmp91 # 把eax中的值放到栈指针偏移28字节位置,也就是指针变量p中
# main.c:13: b=*p+2; # 下面两个mov是间接访问的经典解析
mov eax, DWORD PTR [esp+28] # tmp92, p # 栈指针偏移28字节位置,也就是指针变量p的值,放到eax寄存器
mov eax, DWORD PTR [eax] # _1, *p_5 # 把eax寄存器中的值作为地址,去内存访问到相应的数据,放入eax中
# main.c:13: b=*p+2;
add eax, 2 # tmp93, # 对eax中的值加2结果,结果还是在eax中
mov DWORD PTR [esp+24], eax # b, tmp93 # 把eax中的值放到栈指针偏移24字节位置,也就是变量b中
# main.c:14: ret=add(a,b); # 下面是函数调用,实参传递的经典动作,从而理解值传递是怎么实现的
mov eax, DWORD PTR [esp+16] # a.0_2, a # 栈指针偏移16字节位置,也就是变量a的值,放到eax寄存器
mov edx, DWORD PTR [esp+24] # tmp94, b # 栈指针偏移24字节位置,也就是变量b的值,放到eax寄存器
mov DWORD PTR [esp+4], edx #, tmp94 # 把edx中的值(变量b),放到寄存器指针偏移4,自己的内存位置
mov DWORD PTR [esp], eax #, a.0_2 # 把eax中的值(变量a),放到寄存器栈指针指向的内存位置
call _add # # 调用add函数
mov DWORD PTR [esp+20], eax # ret, tmp95
# main.c:15: printf("add result=%d\n",ret);
mov eax, DWORD PTR [esp+20] # tmp96, ret
mov DWORD PTR [esp+4], eax #, tmp96
mov DWORD PTR [esp], OFFSET FLAT:LC0 #,
call _printf #
# main.c:16: return 0;
mov eax, 0 # _10,
# main.c:17: }
leave
ret
.ident "GCC: (x86_64-posix-sjlj-rev0, Built by MinGW-W64 project) 8.1.0"
.def _printf; .scl 2; .type 32; .endef
这里主要掌握add,sub,call,ret等指令。
2. 机器码
如何得到机器码,需要执行下面两条指令。
# 第一条
gcc -m32 -g -o main main.c (Mac一致)
# 第二条
objdump --source main.exe ->main.dump (Mac去掉.exe后缀,写为main即可)
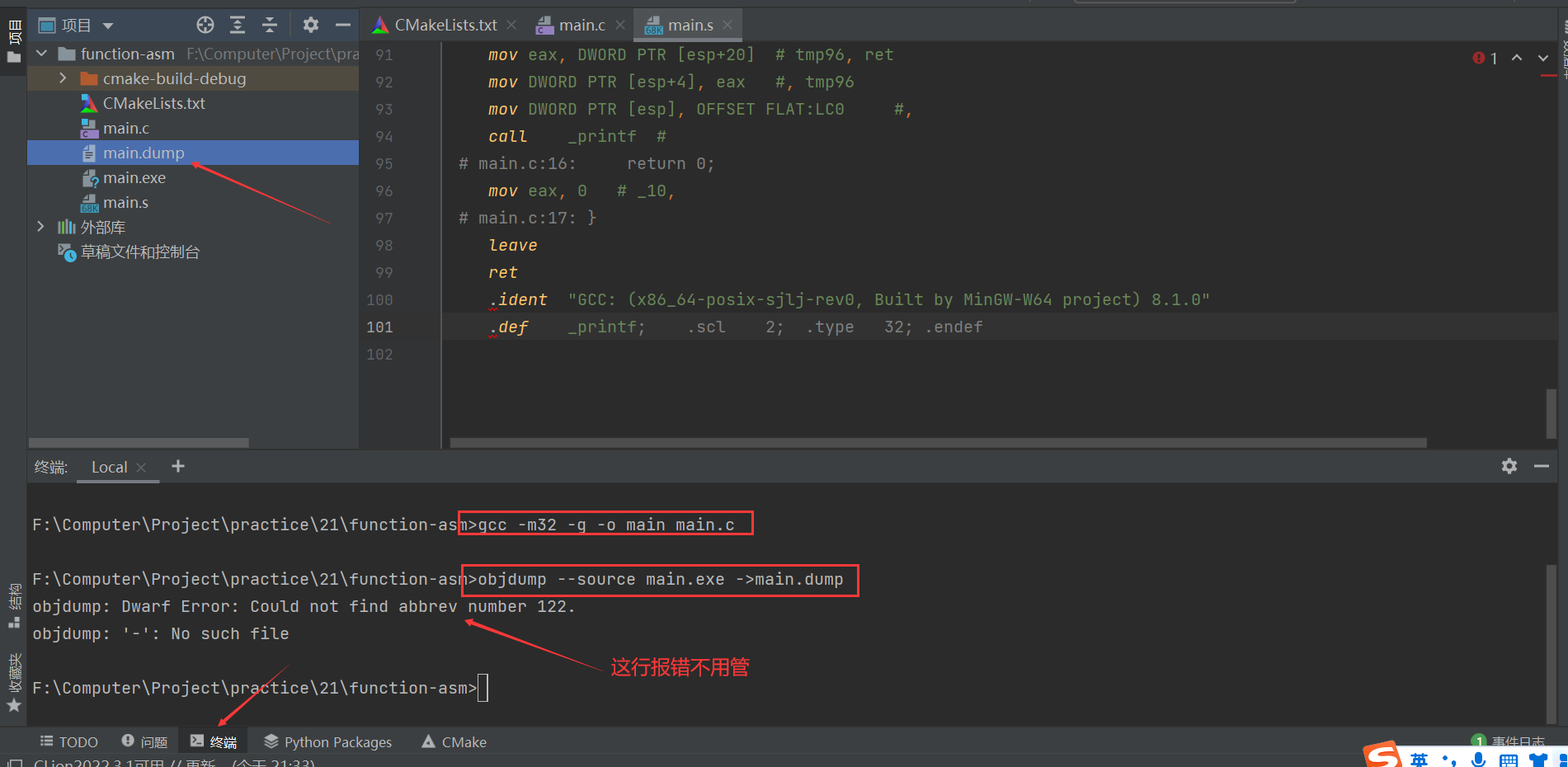
// 原文很长,我们找到add函数和main函数部分即可
#include <stdio.h>
int add(int a,int b){
40150f: 90 nop
00401510 <_add>:
401510: 55 push %ebp
401511: 89 e5 mov %esp,%ebp
401513: 83 ec 10 sub $0x10,%esp
int ret;
ret=a+b;
401516: 8b 55 08 mov 0x8(%ebp),%edx
401519: 8b 45 0c mov 0xc(%ebp),%eax
40151c: 01 d0 add %edx,%eax
40151e: 89 45 fc mov %eax,-0x4(%ebp)
return ret;
401521: 8b 45 fc mov -0x4(%ebp),%eax
}
401524: c9 leave
401525: c3 ret
00401526 <_main>:
int main() {
401526: 55 push %ebp
401527: 89 e5 mov %esp,%ebp
401529: 83 e4 f0 and $0xfffffff0,%esp
40152c: 83 ec 20 sub $0x20,%esp
40152f: e8 ec 00 00 00 call 401620 <___main>
int a,b,ret;
int *p;
a=5;
401534: c7 44 24 10 05 00 00 movl $0x5,0x10(%esp)
40153b: 00
p=&a;
40153c: 8d 44 24 10 lea 0x10(%esp),%eax
401540: 89 44 24 1c mov %eax,0x1c(%esp)
b=*p+2;
401544: 8b 44 24 1c mov 0x1c(%esp),%eax
401548: 8b 00 mov (%eax),%eax
40154a: 83 c0 02 add $0x2,%eax
40154d: 89 44 24 18 mov %eax,0x18(%esp)
ret=add(a,b);
401551: 8b 44 24 10 mov 0x10(%esp),%eax
401555: 8b 54 24 18 mov 0x18(%esp),%edx
401559: 89 54 24 04 mov %edx,0x4(%esp)
40155d: 89 04 24 mov %eax,(%esp)
401560: e8 ab ff ff ff call 401510 <_add> // 掌握这里即可
401565: 89 44 24 14 mov %eax,0x14(%esp)
printf("add result=%d\n",ret);
401569: 8b 44 24 14 mov 0x14(%esp),%eax
40156d: 89 44 24 04 mov %eax,0x4(%esp)
401571: c7 04 24 00 40 40 00 movl $0x404000,(%esp)
401578: e8 bf 0f 00 00 call 40253c <_printf>
return 0;
40157d: b8 00 00 00 00 mov $0x0,%eax
}
说明:对于机器码,我们只需要掌握e8 ab ff ff ff call 401510 <_add>中的e8 ab ff ff ff是什么含义即可,e8代表call,而ab ff ff ff是通过00401510-401565所得。