做了部分注释,比较乱
本示例结构:

1,源代码
#include <stdlib.h>
#include <stdio.h>
#include "cuda_runtime.h"
#include "nccl.h"
#include "mpi.h"
#include <unistd.h>
#include <stdint.h>
#include <sys/time.h>
#define MPI_CHECK(cmd) do { \
int e = cmd; \
if( e != MPI_SUCCESS ) { \
printf("Failed: MPI error %s:%d '%d'\n", \
__FILE__,__LINE__, e); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define CUDA_CHECK(cmd) do { \
cudaError_t e = cmd; \
if( e != cudaSuccess ) { \
printf("Failed: Cuda error %s:%d '%s'\n", \
__FILE__,__LINE__,cudaGetErrorString(e)); \
exit(EXIT_FAILURE); \
} \
} while(0)
#define NCCL_CHECK(cmd) do { \
ncclResult_t r = cmd; \
if (r!= ncclSuccess) { \
printf("Failed, NCCL error %s:%d '%s'\n", \
__FILE__,__LINE__,ncclGetErrorString(r)); \
exit(EXIT_FAILURE); \
} \
} while(0)
static uint64_t getHostHash(const char* string) {
// Based on DJB2a, result = result * 33 ^ char
uint64_t result = 5381;
for (int c = 0; string[c] != '\0'; c++){
result = ((result << 5) + result) ^ string[c];
}
return result;
}
static void getHostName(char* hostname, int maxlen) {
gethostname(hostname, maxlen);
for (int i=0; i< maxlen; i++) {
if (hostname[i] == '.') {
hostname[i] = '\0';
return;
}
}
}
void print_vector(float* A, int n)
{
for(int i=0; i<n; i++)
printf("%.2f ", A[i]);
}
void init_dev_vectors(float* A_d, float* B_d, int n, int rank, long long seed, int dev_idx)
{
float * A = (float*)malloc(n*sizeof(float));
float * B = (float*)malloc(n*sizeof(float));
//float * M = (float*)malloc(n*sizeof(float));//max[i] = max(A[i], B[i]);
//float * S = (float*)malloc(n*sizeof(float));//sum[i] = sum(A[i], B[i]);
srand(seed);
for(int i=0; i<n; i++)
{
A[i] = (rand()%100)/100.0f;
B[i] = (rand()%100)/100.0f;
}
printf("\nrank = %d, gpuid = %d, sendbuff =\n", rank, dev_idx);
print_vector(A, n);
printf("\n\n");
// printf("\nrank = %d, Sum =\n", rank); print_vector(S, n);
cudaMemcpy(A_d, A, n*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(B_d, B, n*sizeof(float), cudaMemcpyHostToDevice);
free(A);
free(B);
}
void get_seed(long long &seed)
{
struct timeval tv;
gettimeofday(&tv, NULL);
seed = (long long)tv.tv_sec * 1000*1000 + tv.tv_usec;//only second and usecond;
//printf("useconds:%lld\n", seed);
}
void fetch_dev_vector(float* A_d, int n, int rank, int dev_id)
{
float* A = (float*)malloc(n*sizeof(float));
cudaMemcpy(A, A_d, n*sizeof(float), cudaMemcpyDeviceToHost);
printf("rank = %d,gpuid =%d recvbuff =\n", dev_id, rank);
print_vector(A, n);
printf("\n\n");
free(A);
}
int main(int argc, char* argv[])
{
int size = 16;//32*1024*1024;
int myRank, nRanks, localRank = 0;
//initializing MPI
MPI_CHECK(MPI_Init(&argc, &argv));
MPI_CHECK(MPI_Comm_rank(MPI_COMM_WORLD, &myRank));
MPI_CHECK(MPI_Comm_size(MPI_COMM_WORLD, &nRanks));
//calculating localRank which is used in selecting a GPU
uint64_t hostHashs[nRanks];
char hostname[1024];
getHostName(hostname, 1024);
hostHashs[myRank] = getHostHash(hostname);
MPI_CHECK(MPI_Allgather(MPI_IN_PLACE, 0, MPI_DATATYPE_NULL, hostHashs, sizeof(uint64_t), MPI_BYTE, MPI_COMM_WORLD));
for (int p=0; p<nRanks; p++) {
if (p == myRank) break;
if (hostHashs[p] == hostHashs[myRank]) localRank++;
}
//each process is using two GPUs
int nDev = 2;
float** sendbuff = (float**)malloc(nDev * sizeof(float*));
float** recvbuff = (float**)malloc(nDev * sizeof(float*));
cudaStream_t* s = (cudaStream_t*)malloc(sizeof(cudaStream_t)*nDev);
//picking GPUs based on localRank
for (int i = 0; i < nDev; ++i) {
CUDA_CHECK(cudaSetDevice(localRank*nDev + i));
CUDA_CHECK(cudaMalloc(sendbuff + i, size * sizeof(float)));
CUDA_CHECK(cudaMalloc(recvbuff + i, size * sizeof(float)));
CUDA_CHECK(cudaMemset(sendbuff[i], 1, size * sizeof(float)));
CUDA_CHECK(cudaMemset(recvbuff[i], 0, size * sizeof(float)));
CUDA_CHECK(cudaStreamCreate(s+i));
long long seed = 0;
get_seed(seed);
//void init_dev_vectors(float* A_d, float* B_d, int n, int rank, long long seed, int dev_idx)
init_dev_vectors(sendbuff[i], recvbuff[i], size, myRank, seed, i);
}
ncclUniqueId id;
ncclComm_t comms[nDev];
//generating NCCL unique ID at one process and broadcasting it to all
if (myRank == 0) ncclGetUniqueId(&id);
MPI_CHECK(MPI_Bcast((void *)&id, sizeof(id), MPI_BYTE, 0, MPI_COMM_WORLD));
//initializing NCCL, group API is required around ncclCommInitRank as it is
//called across multiple GPUs in each thread/process
NCCL_CHECK(ncclGroupStart());
for (int i=0; i<nDev; i++) {
CUDA_CHECK(cudaSetDevice(localRank*nDev + i));
NCCL_CHECK(ncclCommInitRank(comms+i, nRanks*nDev, id, myRank*nDev + i));
}
NCCL_CHECK(ncclGroupEnd());
//calling NCCL communication API. Group API is required when using
//multiple devices per thread/process
NCCL_CHECK(ncclGroupStart());
for (int i=0; i<nDev; i++)
NCCL_CHECK(ncclAllReduce((const void*)sendbuff[i], (void*)recvbuff[i], size, ncclFloat, ncclSum,
comms[i], s[i]));
NCCL_CHECK(ncclGroupEnd());
//synchronizing on CUDA stream to complete NCCL communication
for (int i=0; i<nDev; i++)
CUDA_CHECK(cudaStreamSynchronize(s[i]));
for(int i=0; i<nDev; i++)
fetch_dev_vector(recvbuff[i], size, myRank, i);
//freeing device memory
for (int i=0; i<nDev; i++) {
CUDA_CHECK(cudaFree(sendbuff[i]));
CUDA_CHECK(cudaFree(recvbuff[i]));
}
//finalizing NCCL
for (int i=0; i<nDev; i++) {
ncclCommDestroy(comms[i]);
}
//finalizing MPI
MPI_CHECK(MPI_Finalize());
printf("[MPI Rank %d] Success \n", myRank);
return 0;
}
2,构建
2.1 Makefile
LD_FLAGS := -lnccl -L/usr/local/cuda/lib64 -lcudart -I/usr/local/cuda/include
MPI_FLAGS := -I /home/hipper/ex_openmpi/local/include -L /home/hipper/ex_openmpi/local/lib -lmpi
#-lmpi_cxx
EXE := ngpuPerProcess_mxnGPU_mProcess_oneServer
# multiProcess_multiDevice_oneServer_allreduce
# singleProcess_multiDevice_oneServer_allreduce
all: $(EXE)
ngpuPerProcess_mxnGPU_mProcess_oneServer: ngpuPerProcess_mxnGPU_mProcess_oneServer.cpp
g++ -g $< -o $@ $(LD_FLAGS) $(MPI_FLAGS)
hello_comm: hello_comm.cpp
g++ -g $< -o $@ $(LD_FLAGS)
.PHONY: clean
clean:
-rm $(EXE)
2.2 构建
$ make
3,运行
$ ../../ex_openmpi/local/bin/mpirun -np 2 ./ngpuPerProcess_mxnGPU_mProcess_oneServer4,效果
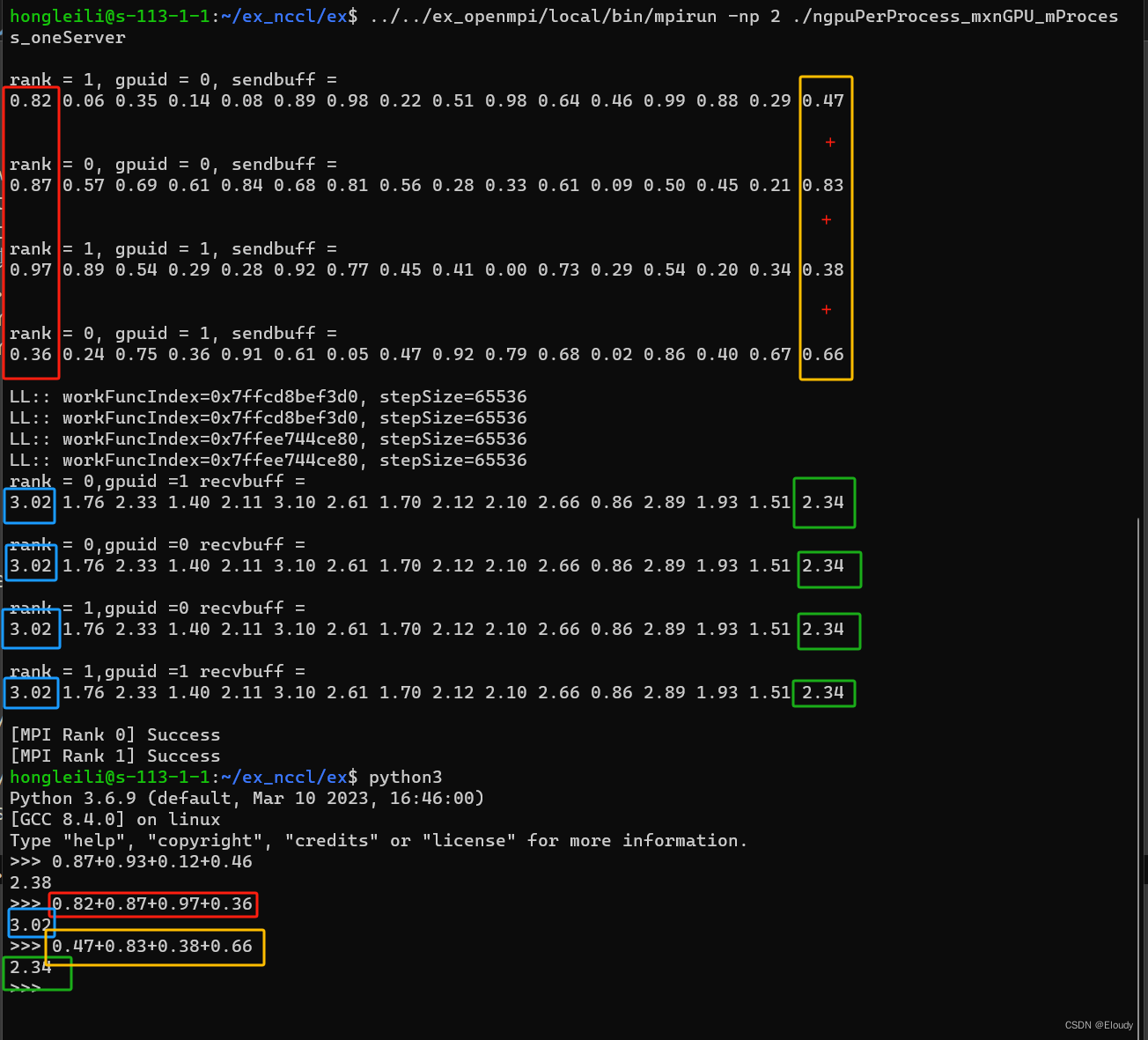
数学效果跟前文相同