问题背景:
一套Oracle11.2.0.4的RAC集群,通过Dataguard switchover方式迁移到新机器之后,运行第一天应用报障说应用性能慢,需要进行性能问题排查
问题分析:
首先,登陆到服务器,用TOP看一眼两个节点数据库的服务器整体负载情况,节点二的负载别节点一高,但整体cpu,io等待负载还是在正常的范围内,查看数据库的等待事件,也没有大量IO,锁争用的等待事件,初步判断数据库的整体负载正常,可能是某些模块语句有问题,再次跟应用确认应用是全部慢,还是某个功能、语句慢,得到应用回复说是部分涉及与其他系统交互的存储过程执行起来慢,这与我们之前的初步判断基本一致,那接下来我们的分析方向就锁定为这一类涉及与其他系统交互的存储过程
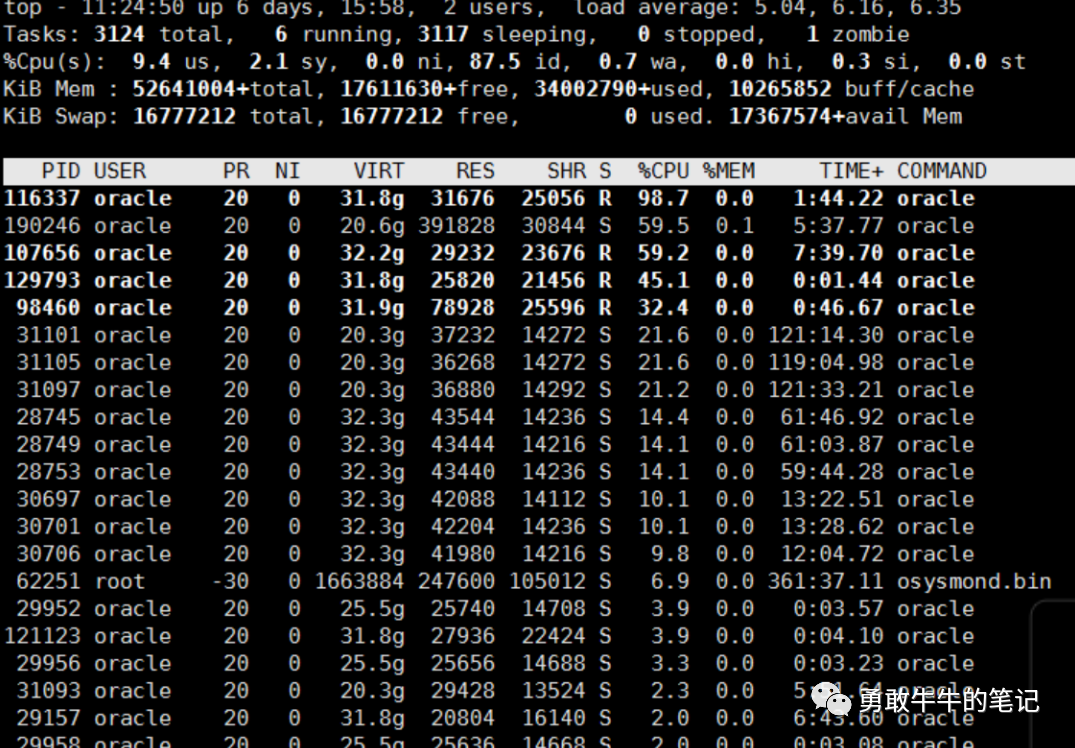
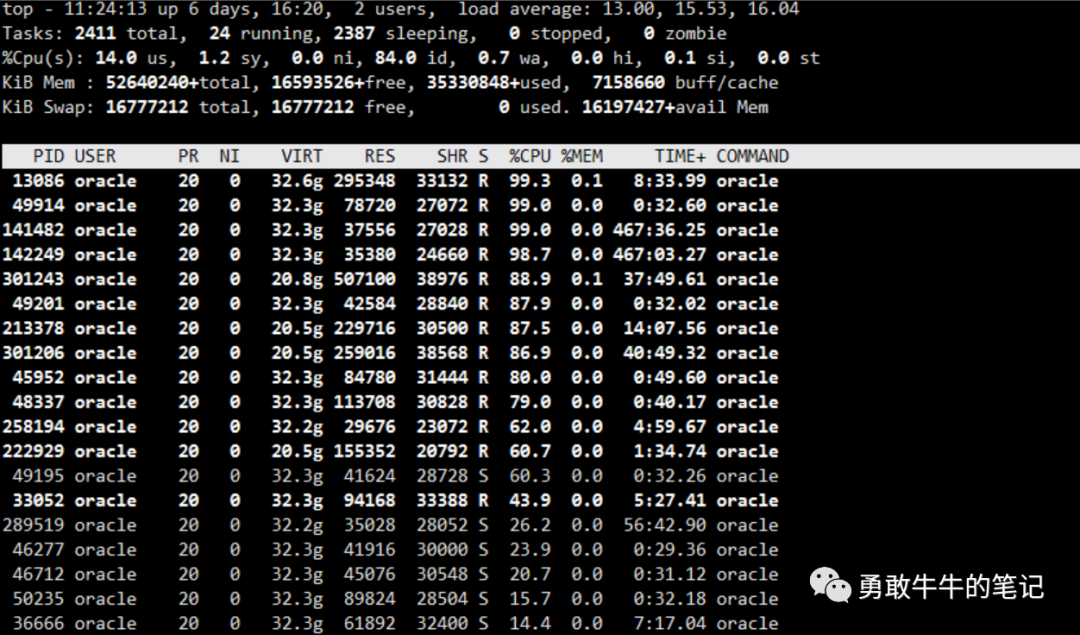
让应用提供了其中一个正在执行的存储过程XXX_APP_INTERFACE_PKG.GET_PRE_XXX_RESULT,sql_id:6321wf6xz0at4,应用描述这个存储过程迁移之前的执行时间是在5分钟之内可以执行完,现在的执行时间要超过10分钟以上,最近一次30分钟还没执行完,查看当前执行存储过程的会话,等待事件为TCP Socket (KGAS)
注:KGAS是数据库服务层中处理TCP/IP套接字的组件,KGAS接口不参与客户端/服务器通信,而是当数据库服务上的会话使用PLSQL包如UTL_HTTP,UTL_TCP进行TCP/IP调用时使用到,在调用过程出现的等待为TCP Socket (KGAS)

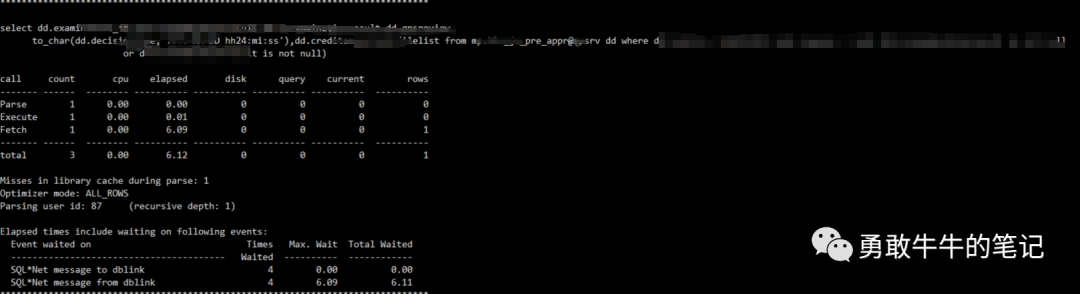
用10046跟踪了该会话执行的sql情况,并用tkprof格式化跟踪产生的trc文件
--跟踪会话
oradebug setmypid
oradebug unlimit 106903
oradebug event 10046 trace name context forever,level 12
oradebug tracefile_name
--关闭跟踪会话
oradebug event 10046 trace name context off
--格式化trc文件
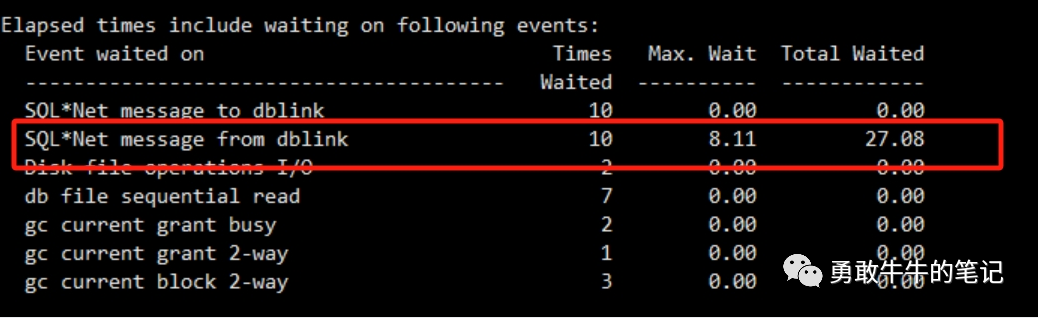
tkprof trc文件 生成文件从trc文件看,执行的存储过程语句主要的等待为SQL*Net message from dblink等待从dblink的目标端返回数据,没有发现涉及调用UTL_HTTP,UTL_TCP的语句
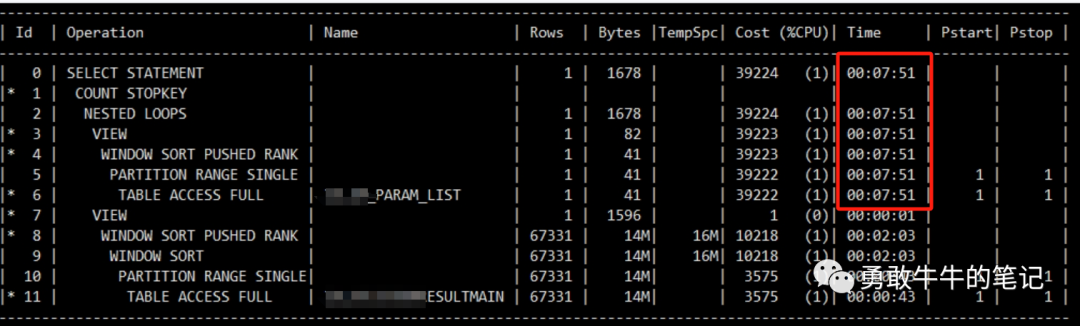
先查看了调用的dblink语句,语句只调用了dblink目标端的表,没有与源端的表进行关联,去掉dblink直接在目标端跑了一下,发现语句的执行效率的确一般,执行时间需要6-7秒,主要消耗在于语句里面一张超过1G大小的表XXX_PARAM_LIST的全表扫描
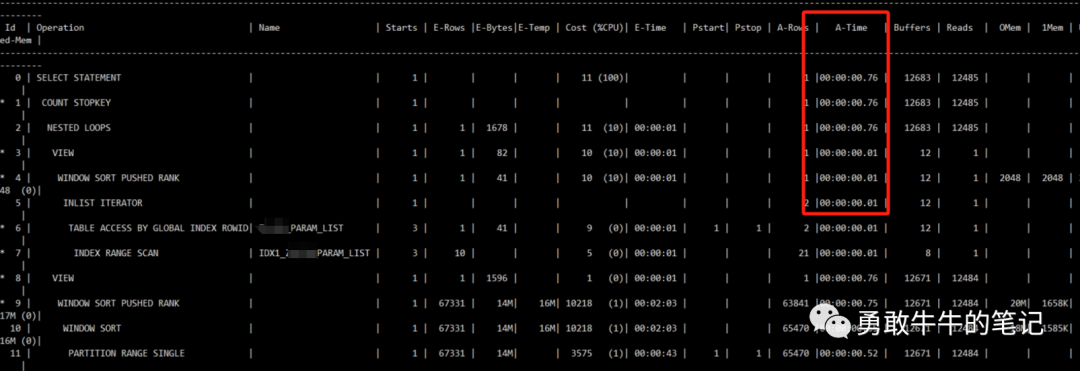
查询语句结构不复杂,where条件列组合的唯一值也较多过滤行不错,可以直接通过创建一个组合索引快速优化这个语句,创建索引优化了语句,执行时间降为1秒以内
优化了高消耗的语句之后,存储过程的执行速度还是没有任何改善,还是要找到真正引发TCP Socket (KGAS)等待的代码,直接去分析10046生成的trc文件,之前是检查生成的tkprof文件,格式完之后的文件可能会遗漏了一些存储过程执行的信息,直接是trc里面搜等待事件TCP Socket (KGAS)的关键字,发现了一些引发等待事件TCP Socket (KGAS)的输入值,里面有个http开头的url地址
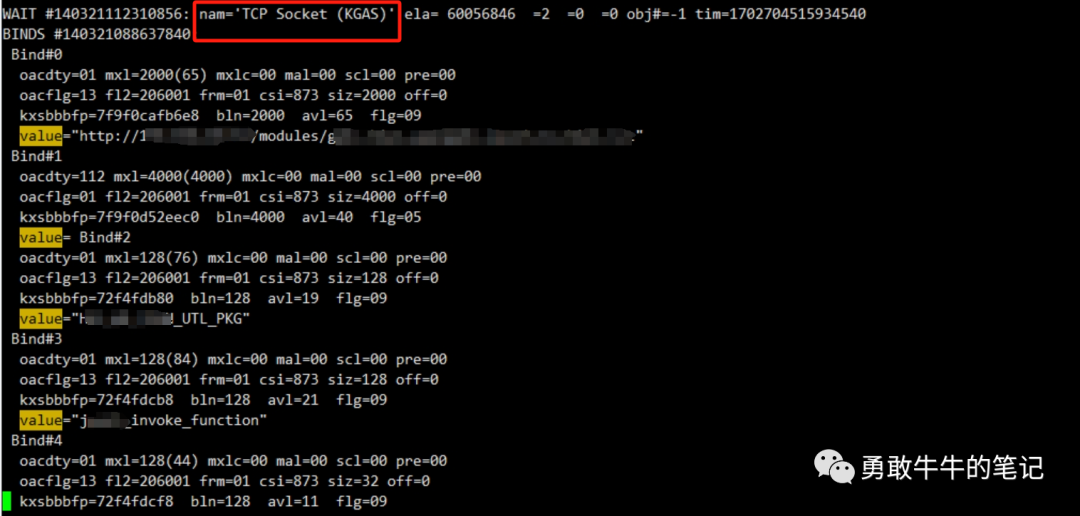
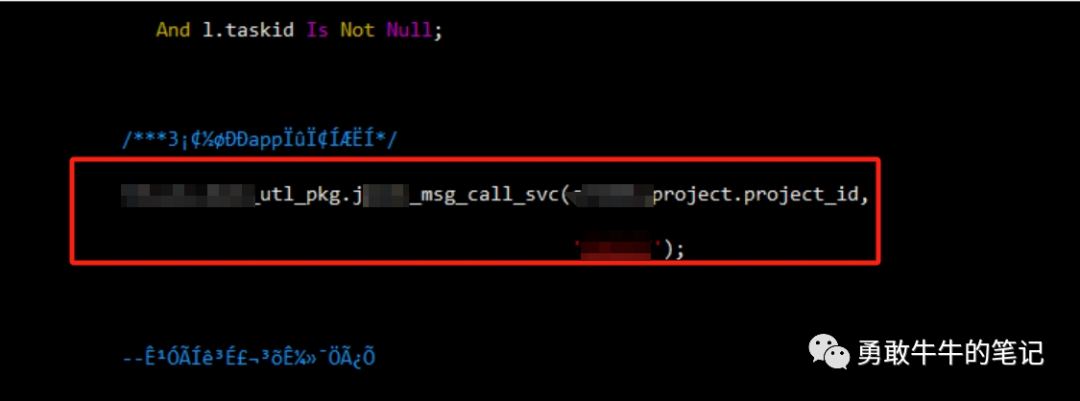
进一步查看了存储过程里面的代码,发现里面调用了一个消息推送的存储过程,该存储过程使用了UTL_HTTP包进行了外部url的请求
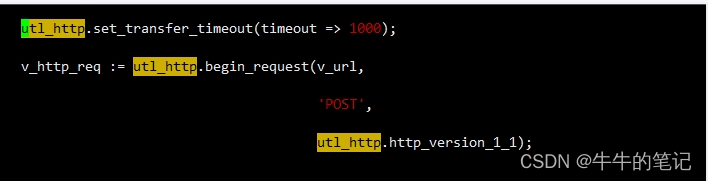
尝试使用curl工具从数据库的服务器去测试之前发现的url能否访问成功,出现访问超时的报错Failed connect to xxxxx;connection timed out,到这里终于抓到了问题的真凶,存储过程里面通过UTL_HTTP包进行了外部url的消息推送,而数据库服务器与请求的url存在网络通信不通问题,导致存储过程一直出现TCP Socket (KGAS)的等待,存储过程执行缓慢
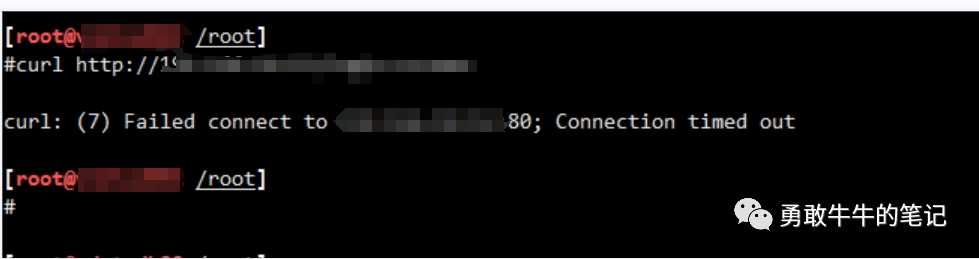
进一步跟网络管理员确认,迁移之后并没有完全开通新服务器到应用系统的网络策略,而数据库迁移只是替换了scan ip,主机的IP是发生了变化的,所以数据库服务器跟一些外部的应用系统存在网络不通的问题,最终导致数据库迁移到新环境之后,那些存在系统交互的存储过程执行起来变慢
问题解决:
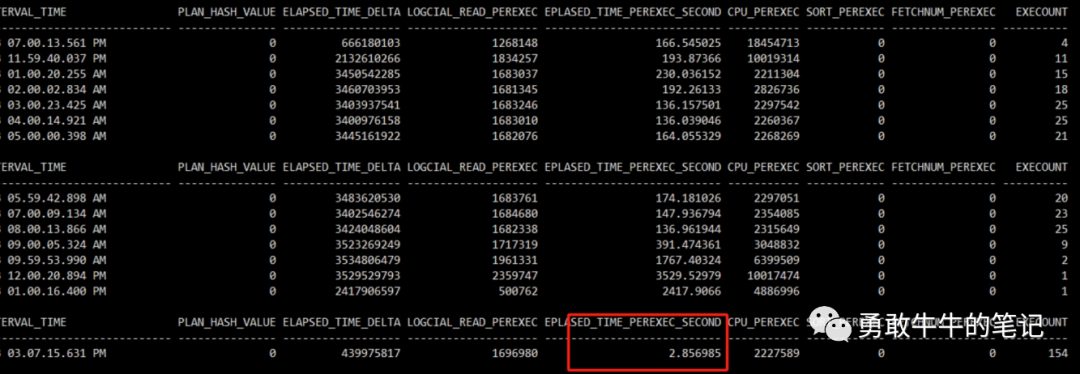
网络重新开通了网络策略,将新数据库服务器的主机IP加入到了旧的数据库组里面,确保新数据库服务器与应用系统的网络相通,存储过程的执行效率也恢复了正常,平均执行时间从原来的2417秒降到了2.85秒



![[雷池WAF]长亭雷池WAF配置基于健康监测的负载均衡,实现故障自动切换上游服务器](https://img-blog.csdnimg.cn/img_convert/ace5c6389fb022a80ab2398ab241a89c.png)