文章目录
- Hadoop高手之路6-Zookeeper分布式协调服务
- 一、Zookeeper简介
- 二、Zookeeper的特性
- 1. 一致性C
- 2. 可靠性
- 3. 顺序性
- 4. 原子性A
- 5. 实时性
- 三、Zookeeper分布式集群的部署
- 1. 下载安装包
- 2. 上传
- 3. 解压
- 4. 配置环境变量
- 5. 配置Zookeeper
- 1) 复制一个配置模板文件
- 2) 修改配置文件
- 3) 创建myid文件
- 6. 分发zookeeper文件
- 7. 在各服务器上创建myid文件
- 8. 分发环境变量配置文件
- 9. 使环境变量起作用
- 四、Zookeeper集群服务的启动和关闭
- 1. 启动Zookeeper服务
- 2. 查看zookeeper集群各服务器的角色
- 3. 关闭Zookeeper服务
- 五、测试Zookeeper服务
- 1. 启动各节点的Zookeeper服务
- 2. 杀死leader,模拟服务器宕机
- 3. 查看各节点角色
- 4. 通过zookeeper客户端连接zookeeper服务
- 六、Zookeeper的Shell操作
- 1. 启动Zookeeper集群
- 2. 启动shell
- 3. help显示所有的操作命令
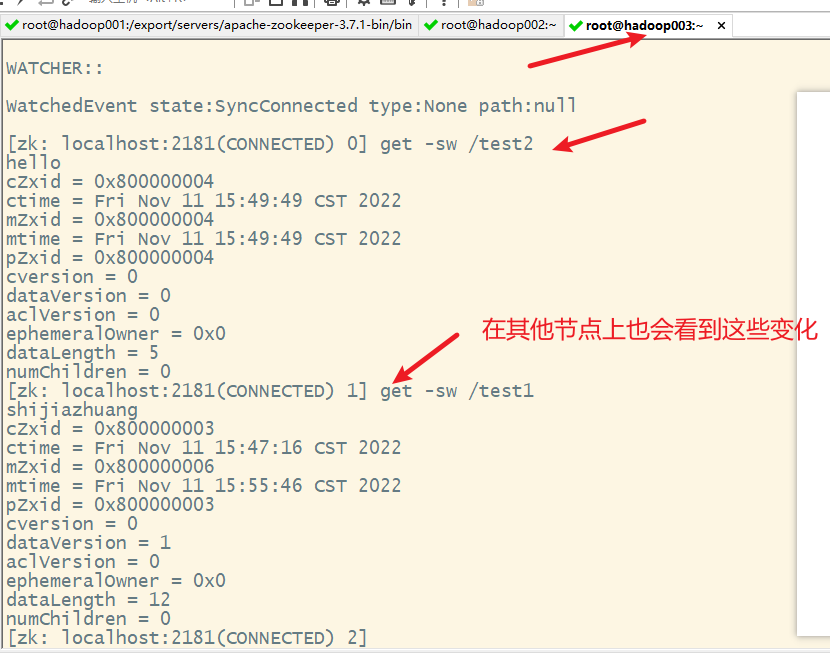
- 4. ls查看目录信息
- 5. ls -sw查看目录的数据信息
- 6. create创建节点
- 7. get获取节点数据
- 8. 修改节点
- 9. delete删除节点
- 七、Zookeeper的Java API操作
- 1. 启动idea,创建一个新的maven项目
- 2. 添加pom依赖
- 3. 新建一个包,并在包下新建类
- 1) 测试客户端代码
- 2) 创建目录节点
- 3) 创建子目录节点
- 4) 获取节点数据
- 5) 获取子目录节点数据
- 6) 修改子目录节点数据
- 7) 判读节点是否存在
- 8) 删除节点
- 9) 完整代码
- 八、Zookeeper的数据模型
- 1. 数据的存储结构
- 2. Znode类型
- 3. 节点的属性
- 九、Zookeeper的Watch机制
- 1. Watch机制简介
- 2. Watch机制的特点
- 1) 一次性触发
- 2) 事件封装
- 3) 异步发送
- 4) 先注册再发送
- 十、Zookeeper的选举机制
- 1. 选举机制简介
- 1) 服务器ID
- 2) 选举状态
- 3) 数据ID
- 4) 逻辑时钟
- 2. 选举机制的类型
- 1) 全新选举
- 2) 非全新选举
- 十一、Zookeeper的应用场景
- 1. 数据发布与订阅
- 2. 统一命名服务
- 3. 分布式锁

Hadoop高手之路6-Zookeeper分布式协调服务
一、Zookeeper简介
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在$zookeeper_home\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
zookeeper主要是用来解决分布式集群中的一致性和单点故障问题
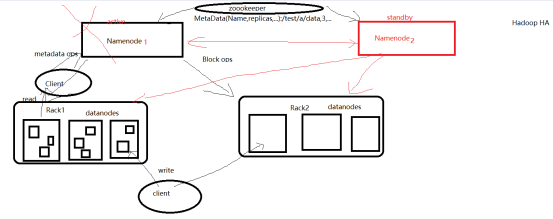
二、Zookeeper的特性
保证了数据的AC特性
1. 一致性C
每个服务器都保存一份相同的数据副本,客户端连接到zookeeper集群的任意节点上,看到的的目录树都是一致的。
2. 可靠性
如果对目录结构进行任意的增删改查,那么所有的节点都会随着进行相应的改变。
3. 顺序性
Zookeeper顺序性分为全局有序和偏序两种。
-
全局有序:如果在一台服务器上某一种操作(消息)a先于b进行,那么所有的服务器上都是a先于b进行的。
-
偏序:如果一个操作(消息)b在a后被同一个发送者发布,a必将排在b前面。
4. 原子性A
一次数据的更新操作要么成功要么失败,不存在中间的状态。
5. 实时性
Zookeeper保证客户端在一个时间间隔范围内获得服务器的更新信息。
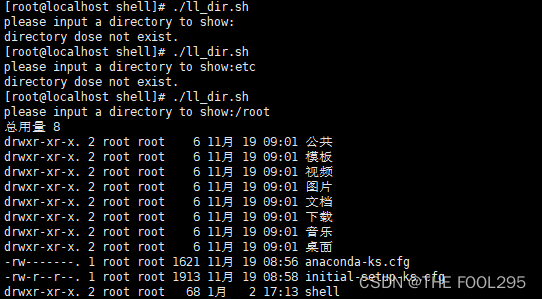
三、Zookeeper分布式集群的部署
1. 下载安装包
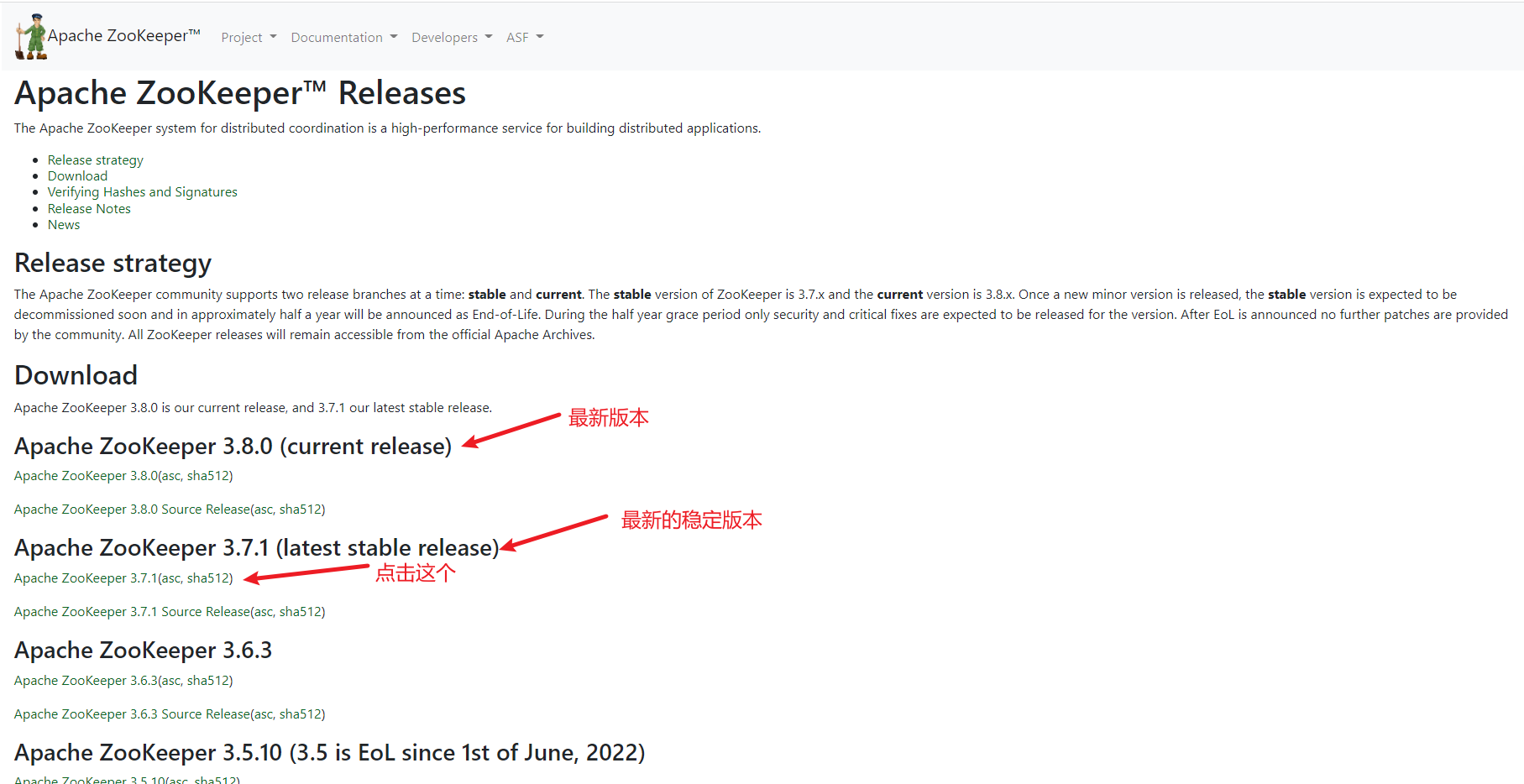
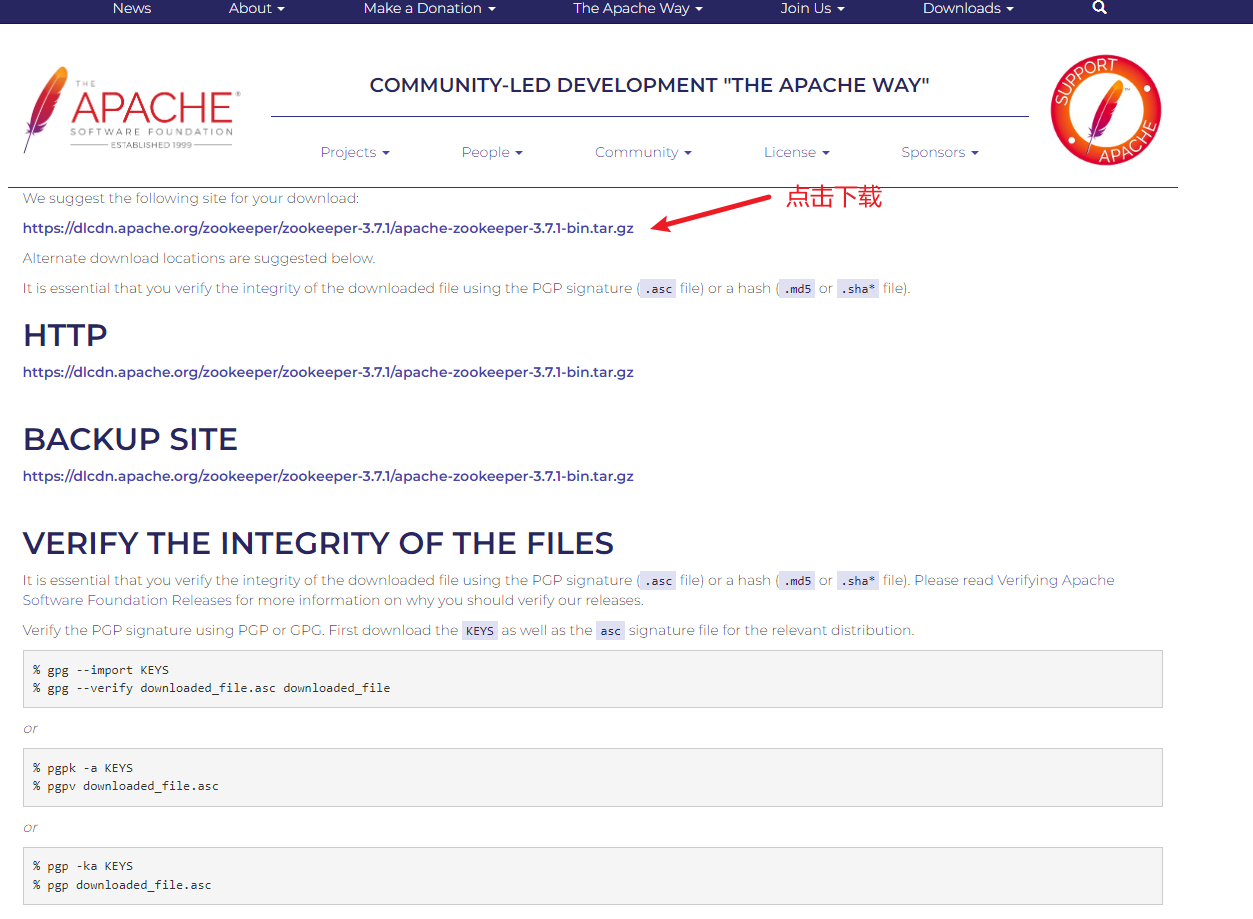
2. 上传
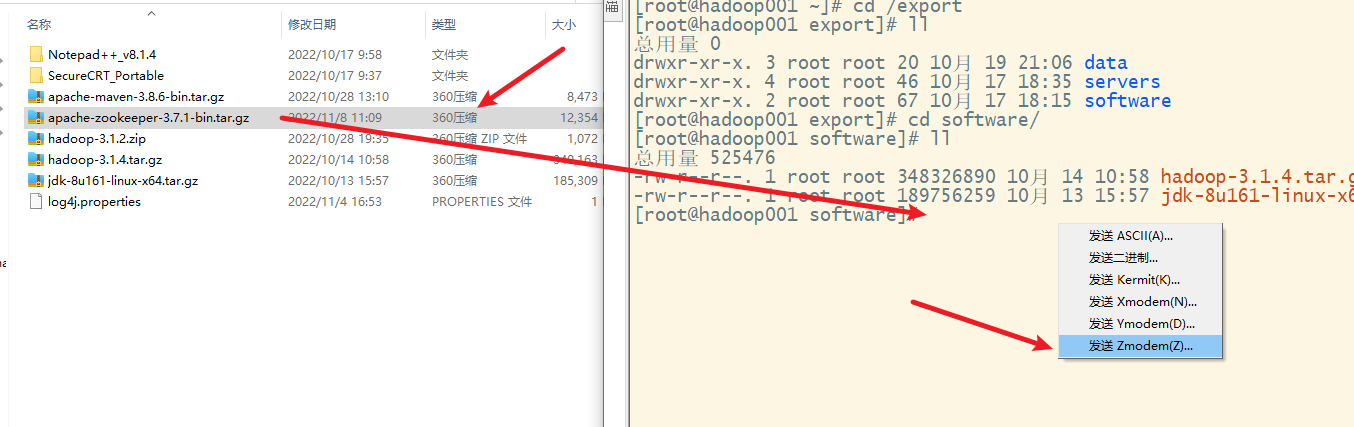
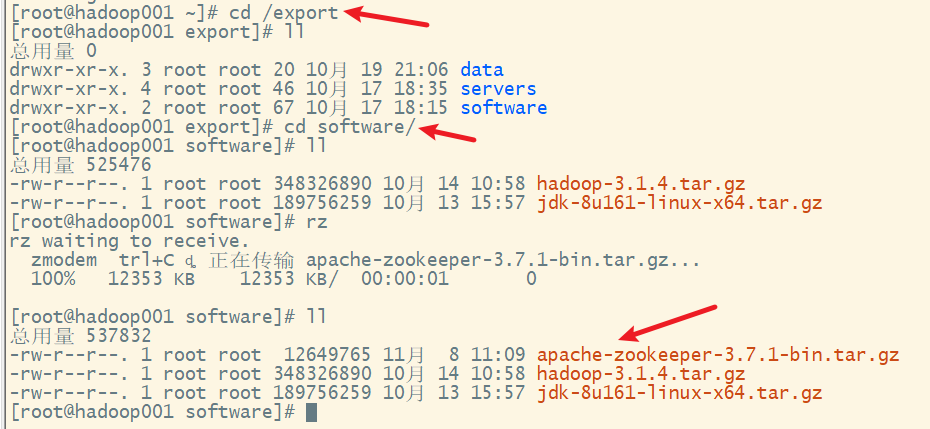
3. 解压


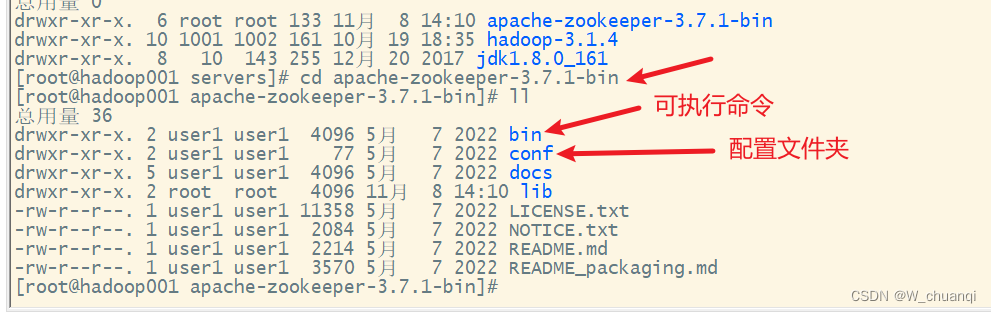
4. 配置环境变量

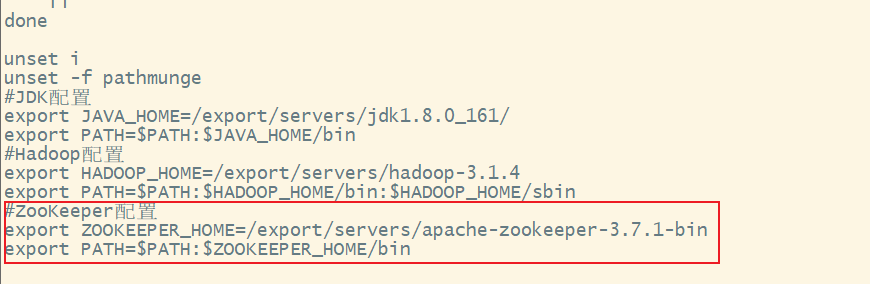
5. 配置Zookeeper
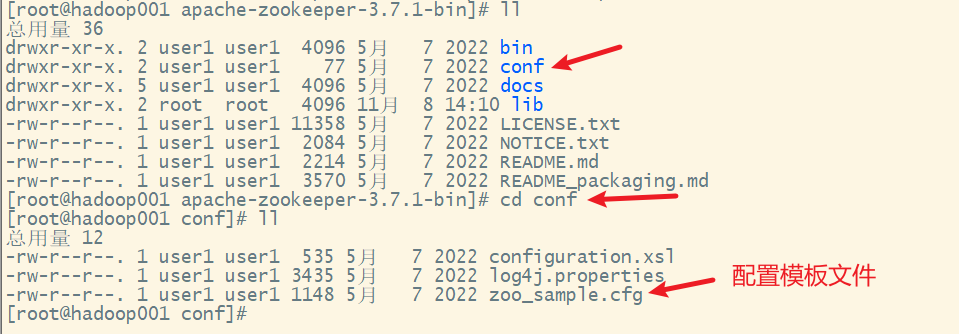
1) 复制一个配置模板文件
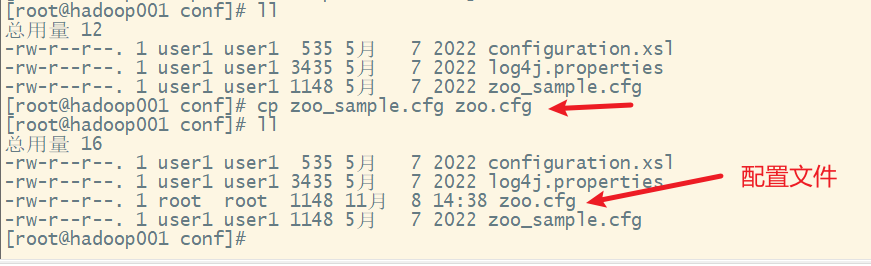
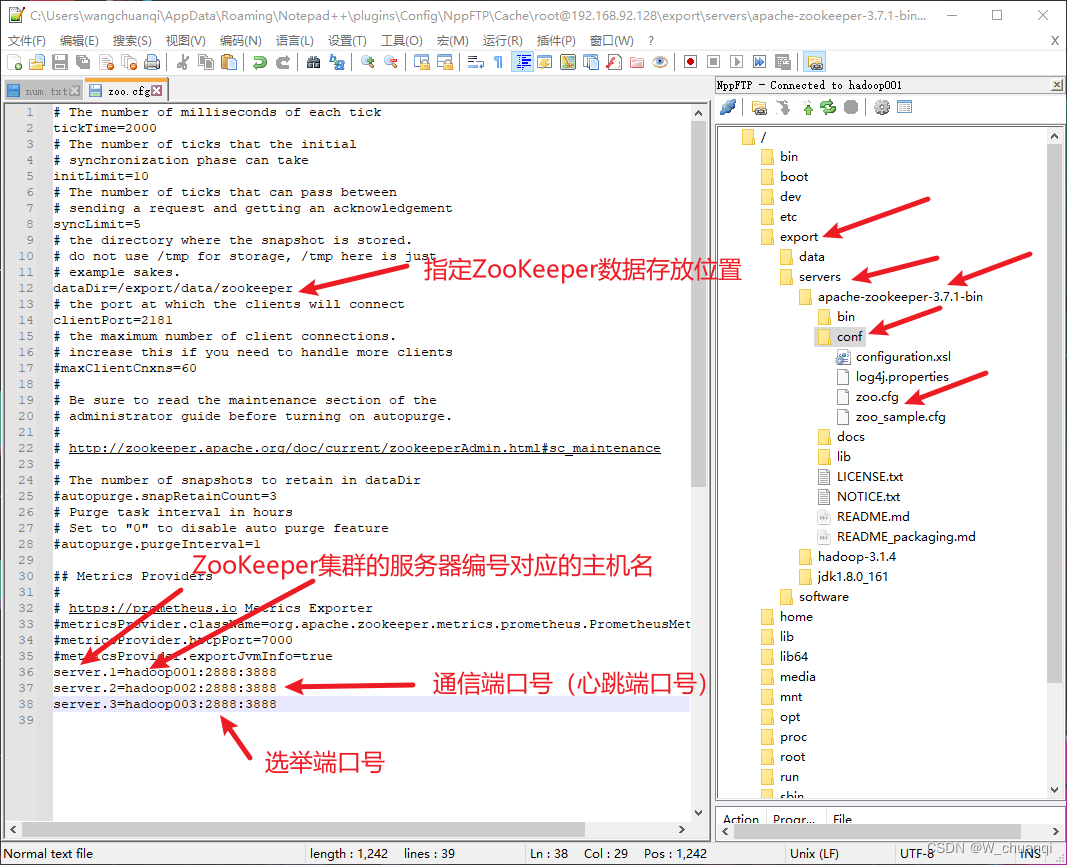
2) 修改配置文件
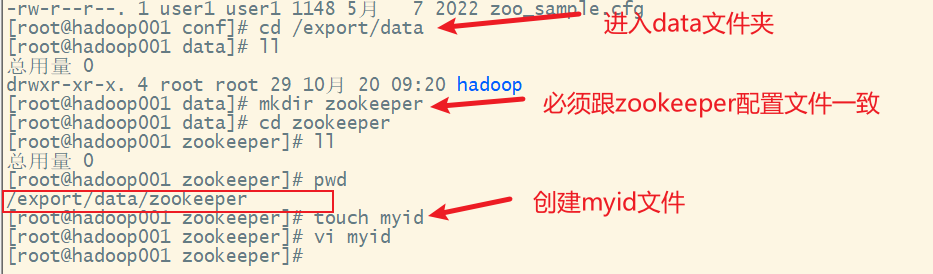
3) 创建myid文件
myid文件的数据越大,越容易被选举成为leader,这个文件的内容一般就是服务器的编号,在每个服务器上都要创建相应的目录以及该文件。
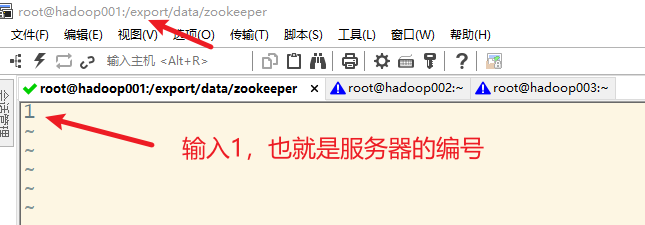
6. 分发zookeeper文件


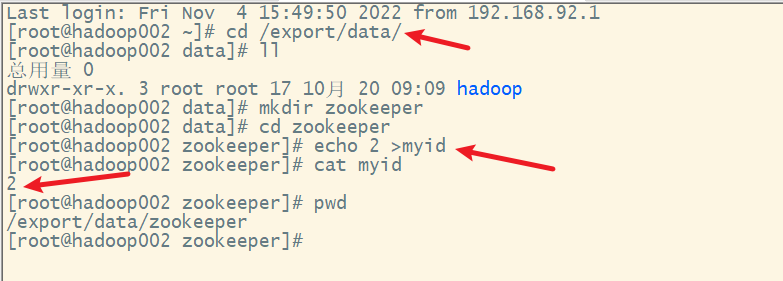
7. 在各服务器上创建myid文件
在hadoop002上
在hadoop003上
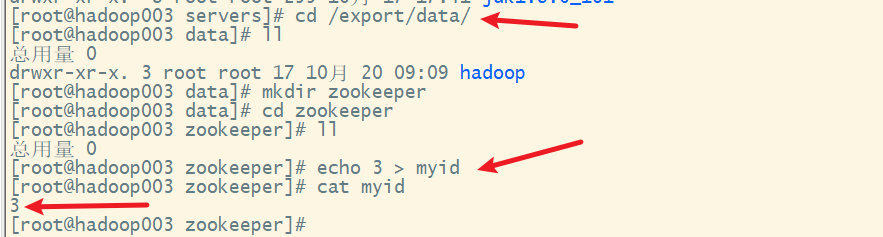
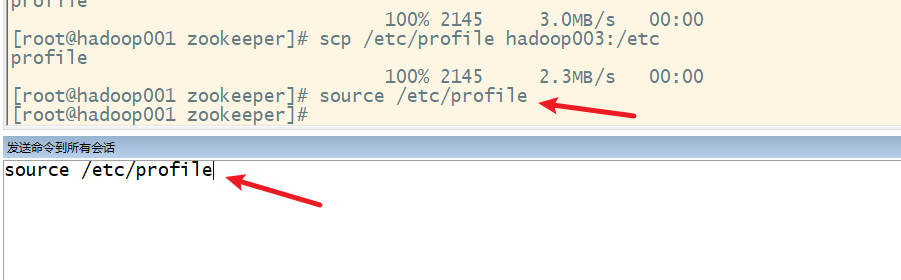
8. 分发环境变量配置文件

9. 使环境变量起作用
四、Zookeeper集群服务的启动和关闭
1. 启动Zookeeper服务
依次在hadoop001、hadoop002和hadoop003上启动Zookeeper服务
在hadoop001上

在hadoop002上
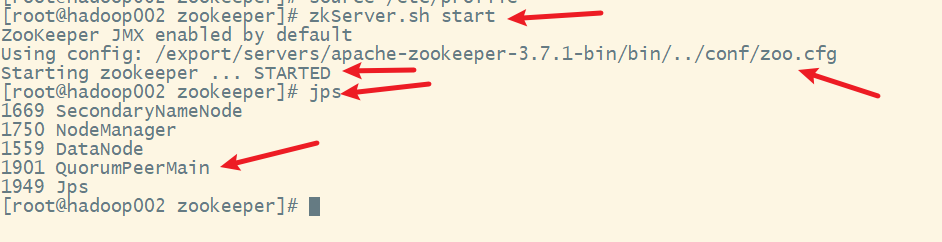
在hadoop003上
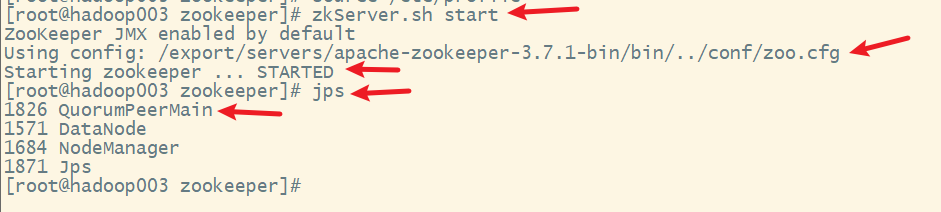
2. 查看zookeeper集群各服务器的角色
角色有三种:leader(领导者)、follower(跟随者)、observer(观察者)
在hadoop001上

在hadoop002上

在hadoop003上

说明:因为先启动node1,然后启动node2,node2的myid为2,而且超过节点个数的半数,所以node2被选举为leader
3. 关闭Zookeeper服务
在hadoop001上
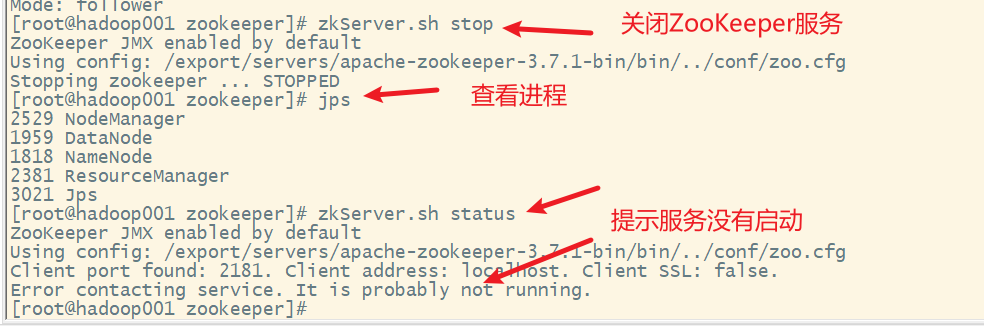
在hadoop002上
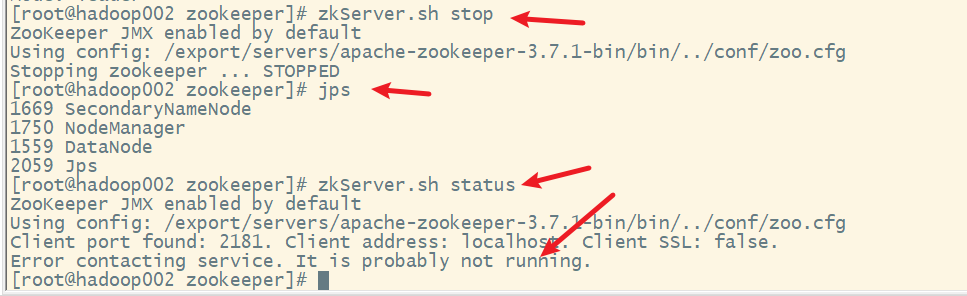
在hadoop003上
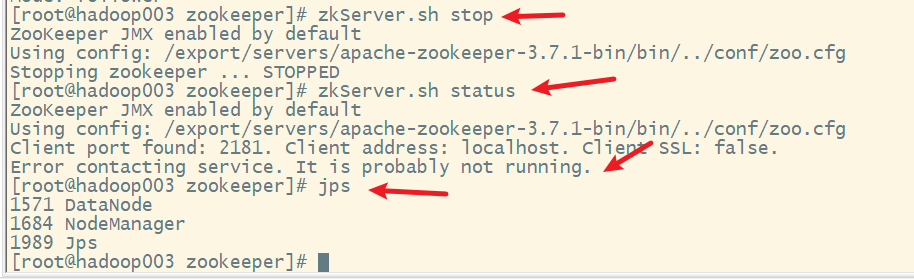
五、测试Zookeeper服务
先启动Zookeeper后,杀掉leader的进程,然后查看选举产生新的leader
1. 启动各节点的Zookeeper服务
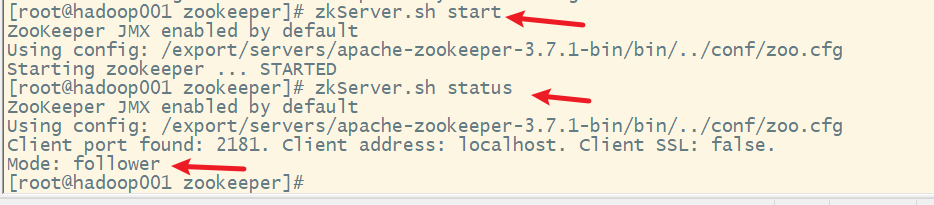
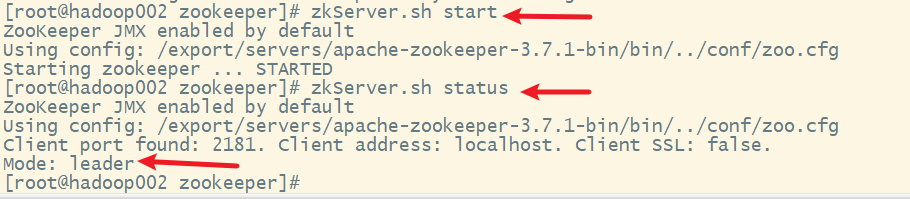

2. 杀死leader,模拟服务器宕机
在hadoop002上
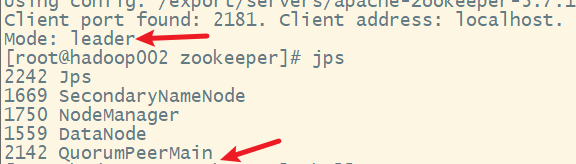
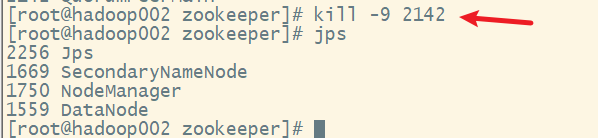
3. 查看各节点角色
发现hadoop003已经被选举为leader



4. 通过zookeeper客户端连接zookeeper服务

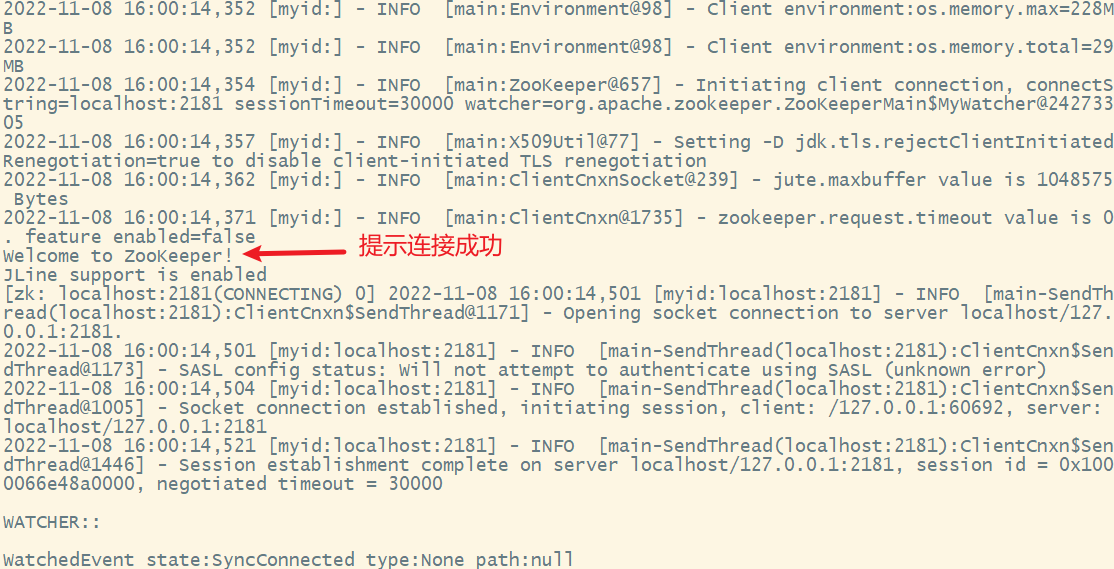
没有出现[zk: localhost:2181(CONNECTED) 0],输入回车就可以了
可以输入命令

六、Zookeeper的Shell操作
1. 启动Zookeeper集群
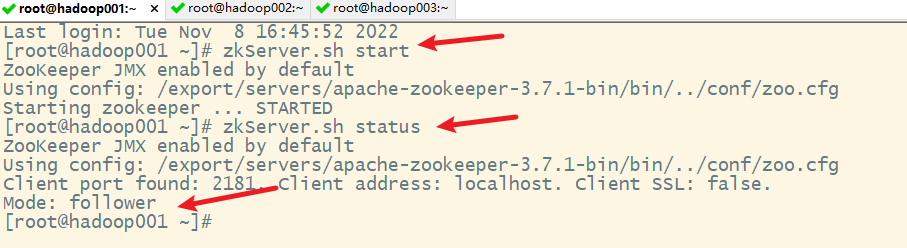
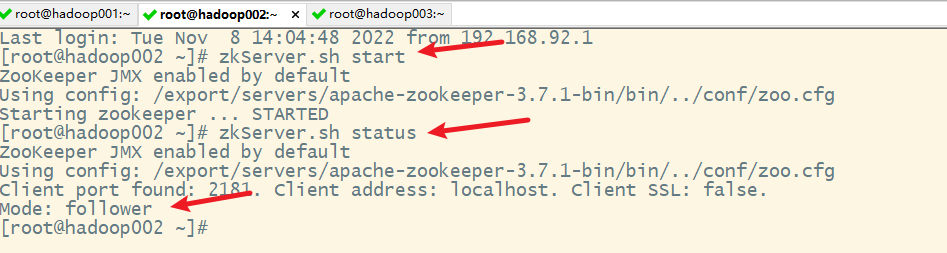
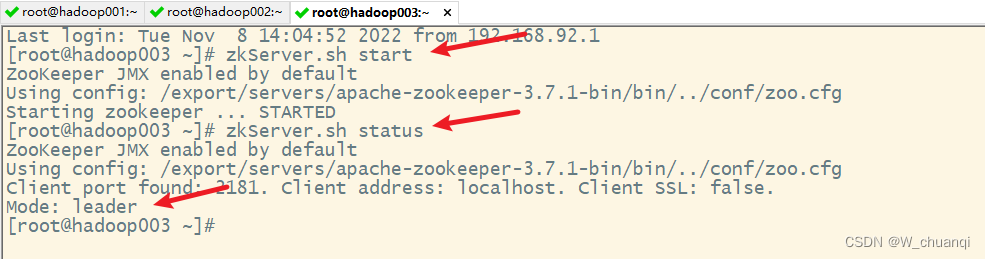
2. 启动shell

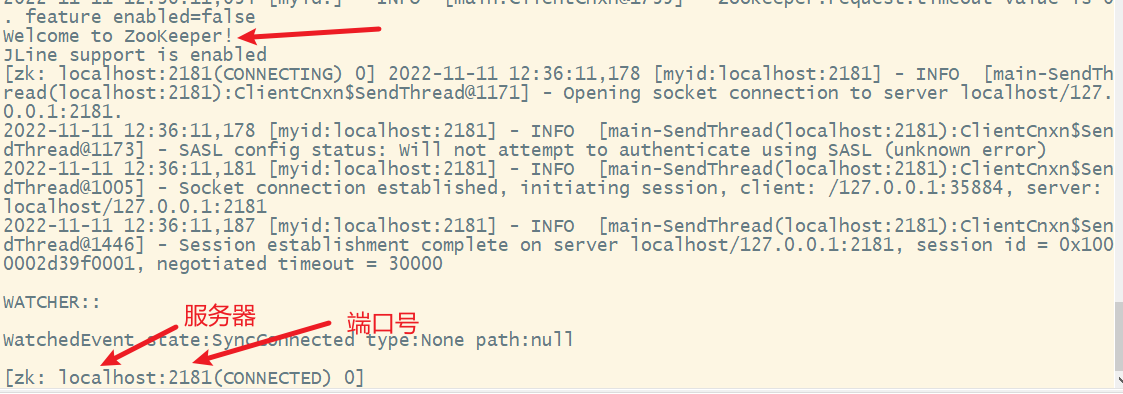
3. help显示所有的操作命令
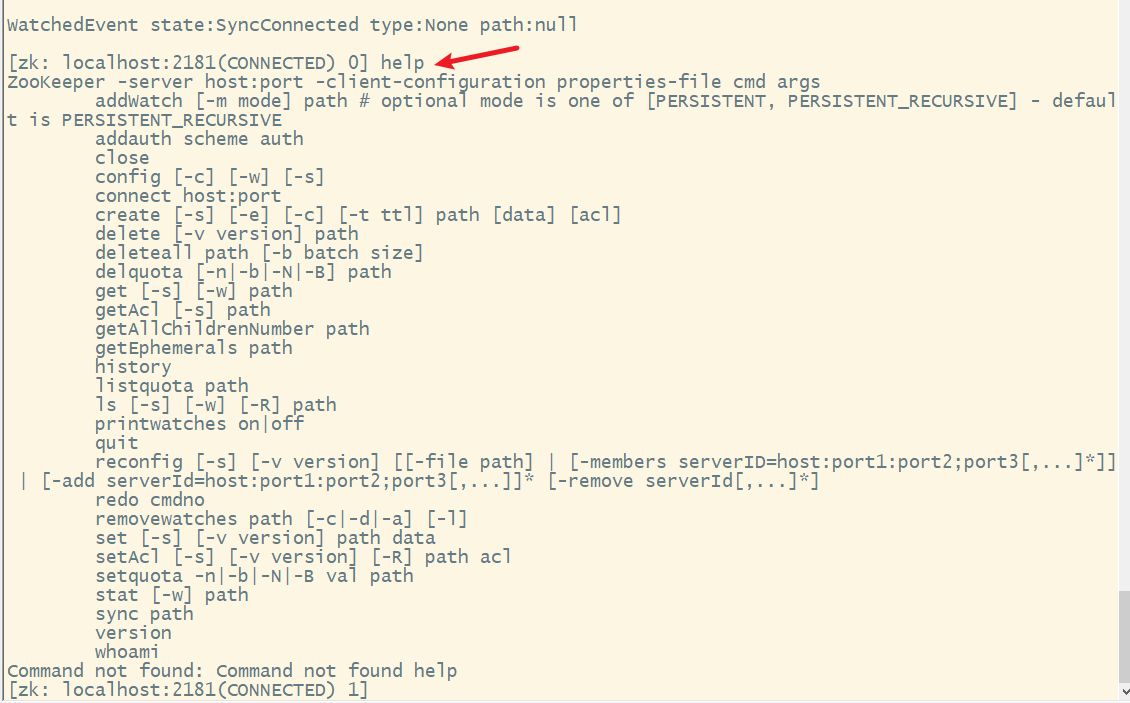
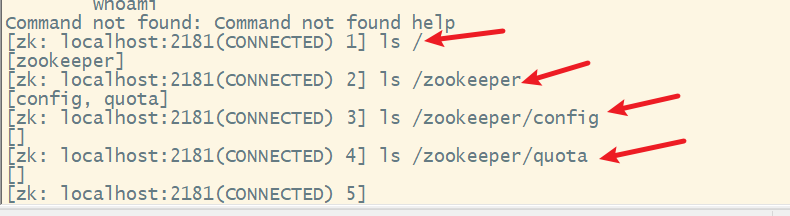
4. ls查看目录信息

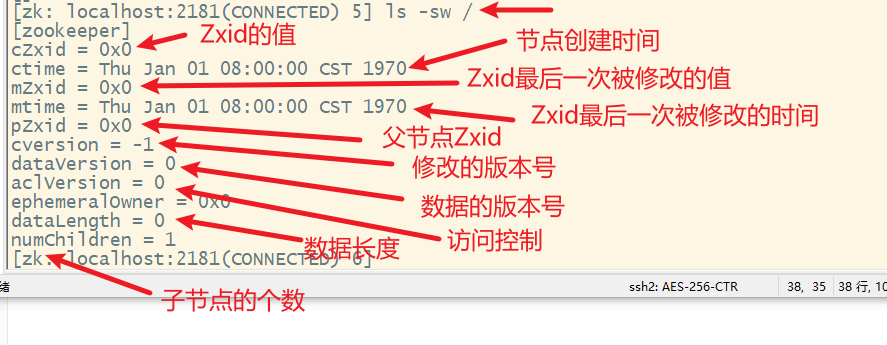
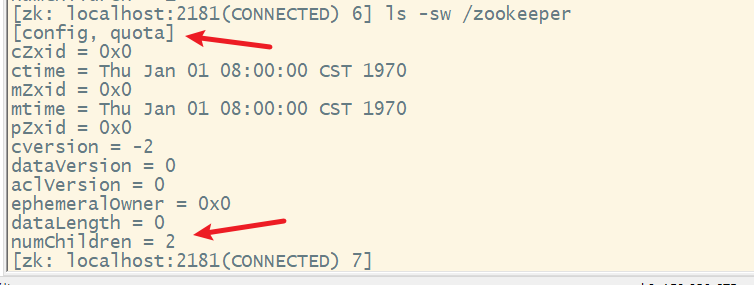
5. ls -sw查看目录的数据信息
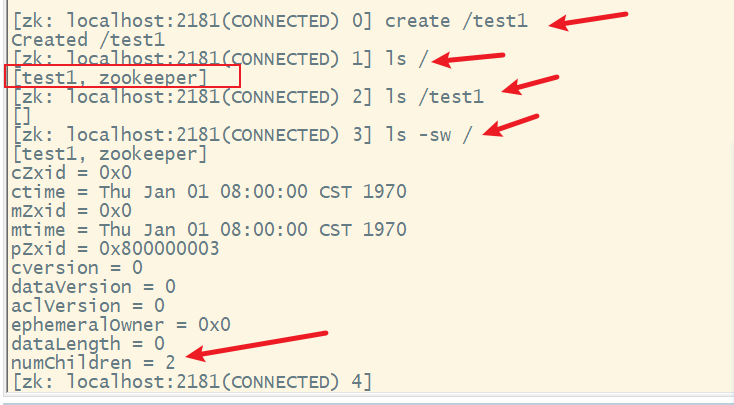
6. create创建节点
格式:
create [-s] [-e] path [data] [acl]
说明:
- s:开启节点的序列化特性
- e:创建的是临时节点,如果不加默认创建永久节点
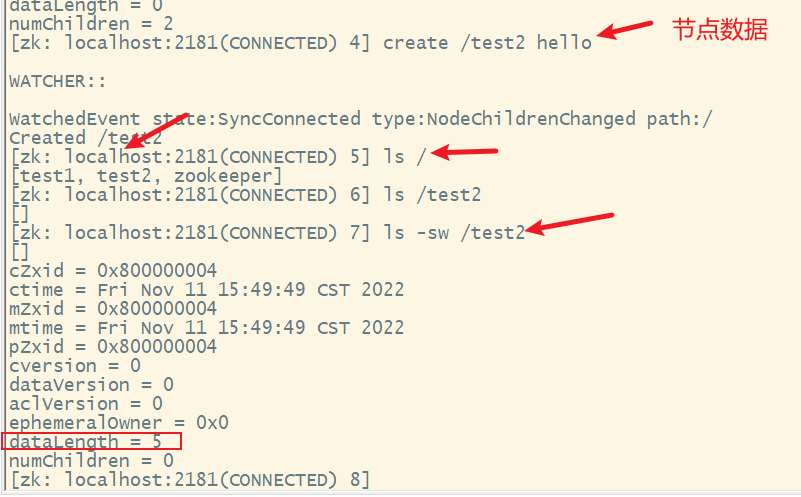

7. get获取节点数据
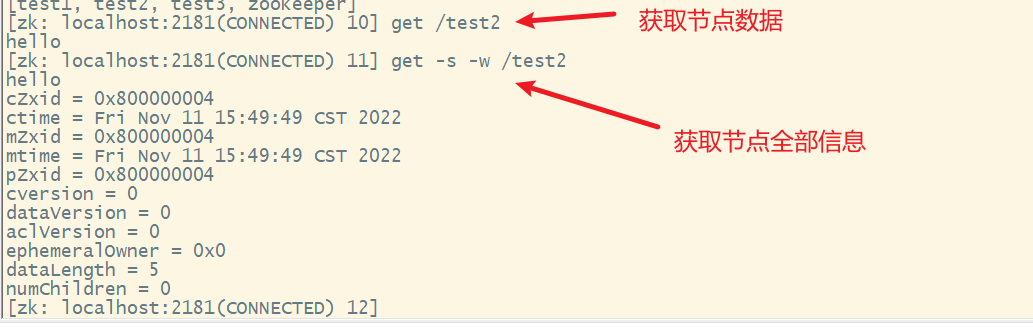
8. 修改节点
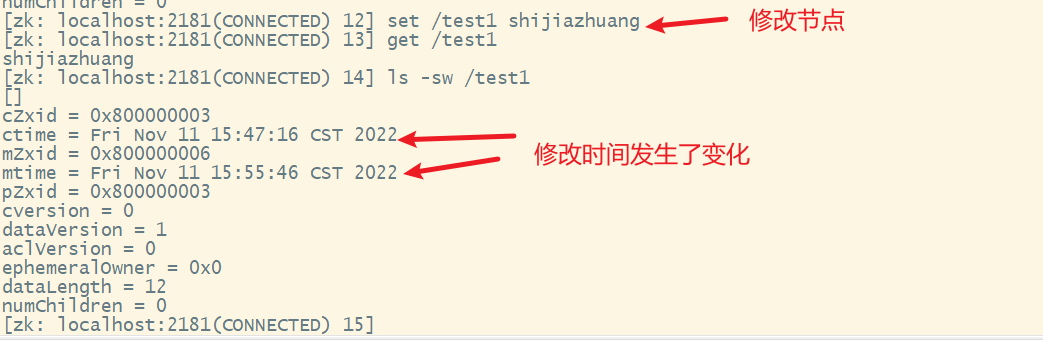
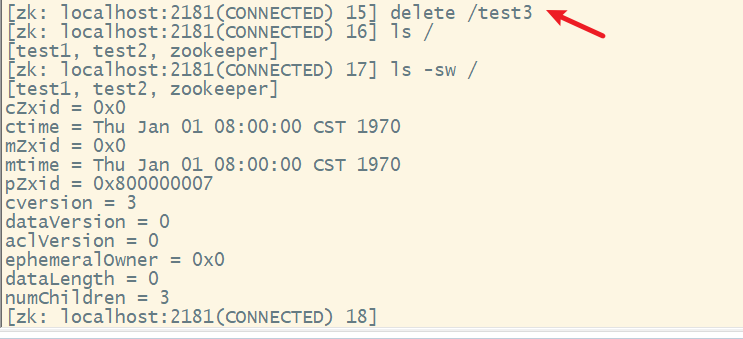
9. delete删除节点
七、Zookeeper的Java API操作
1. 启动idea,创建一个新的maven项目
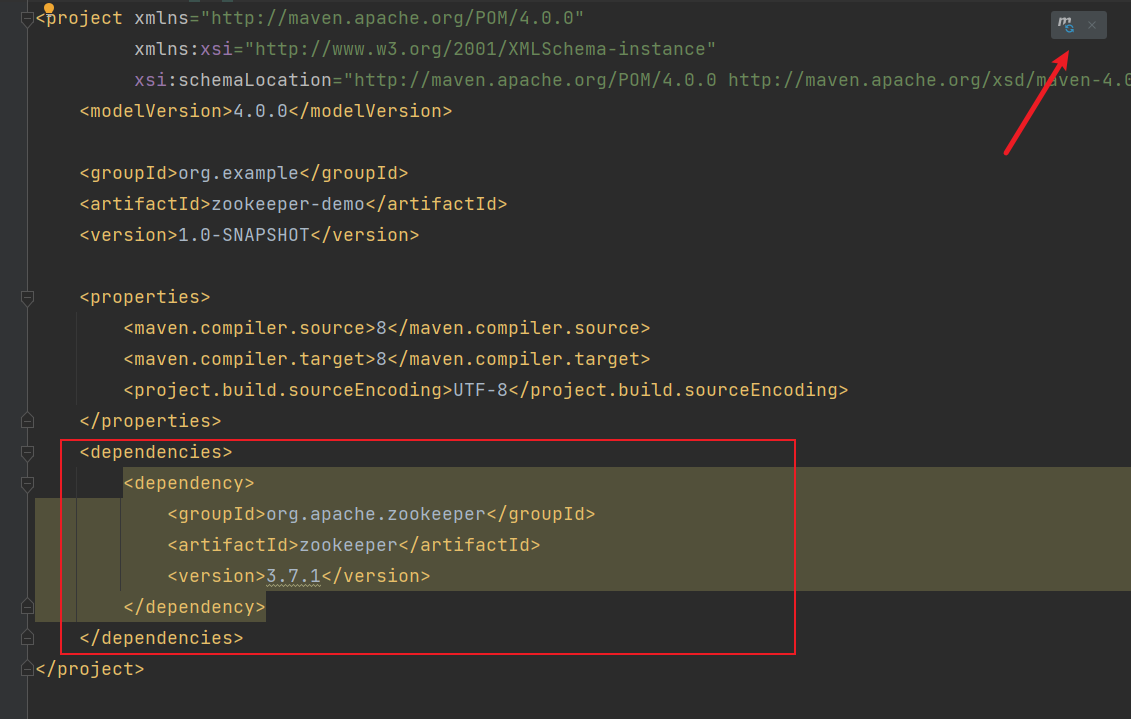
2. 添加pom依赖
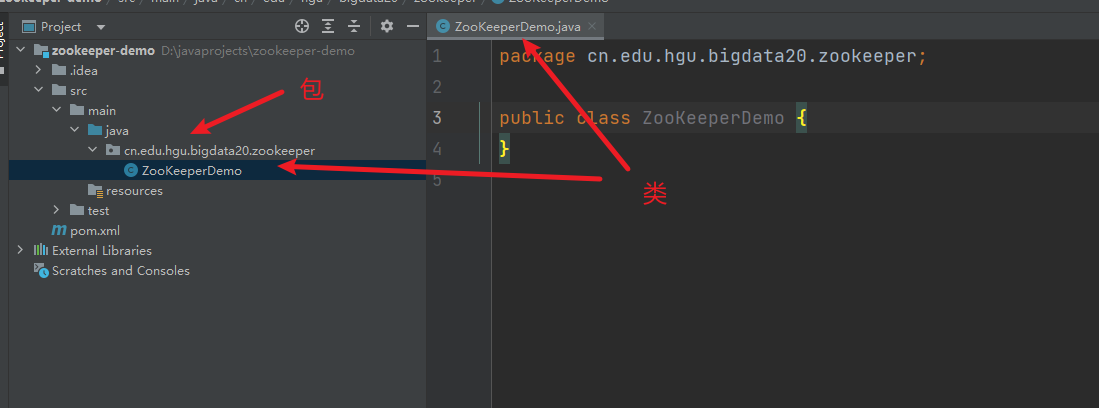
3. 新建一个包,并在包下新建类
1) 测试客户端代码
新建包和类
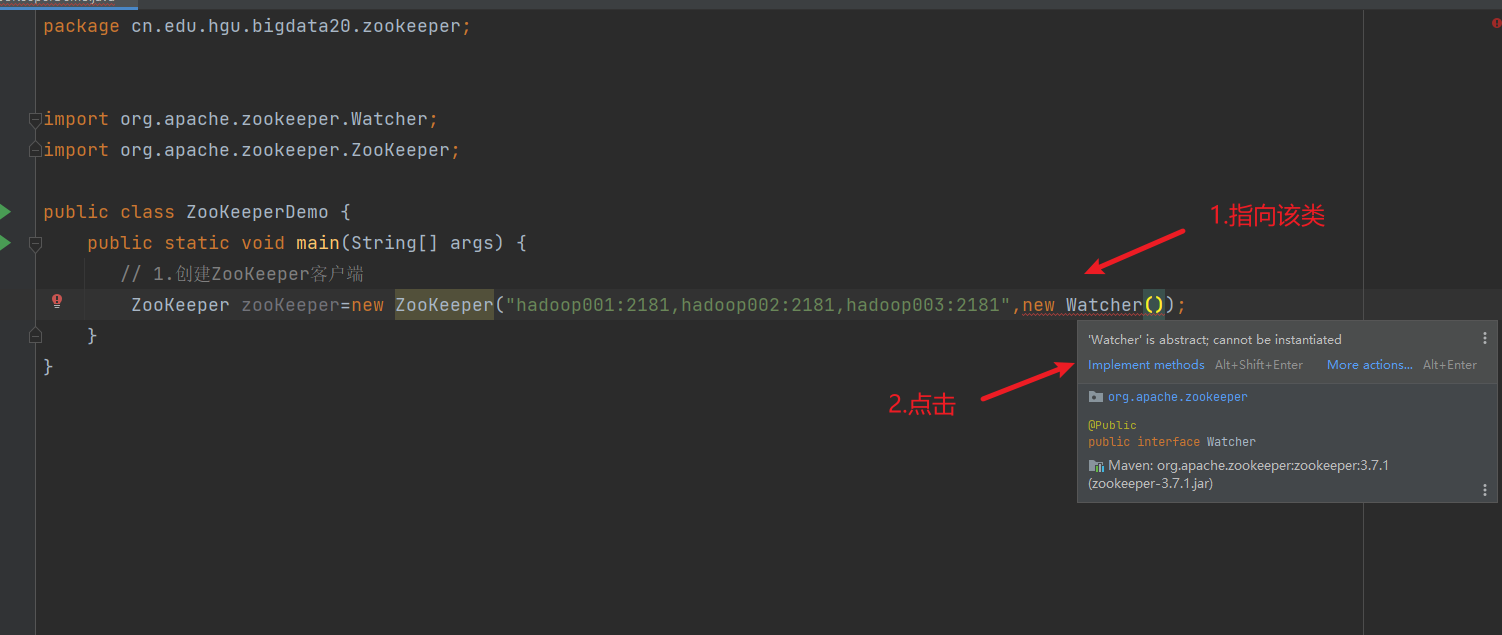
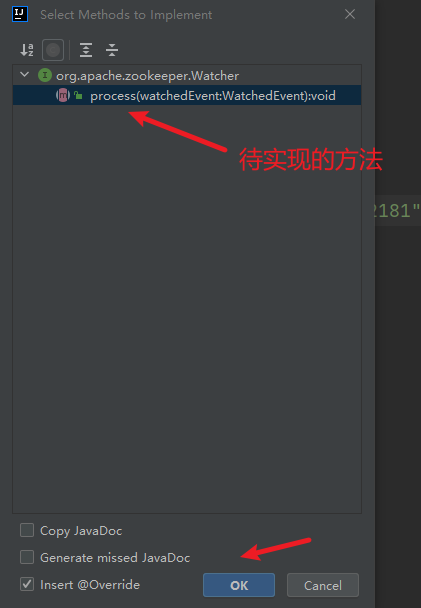
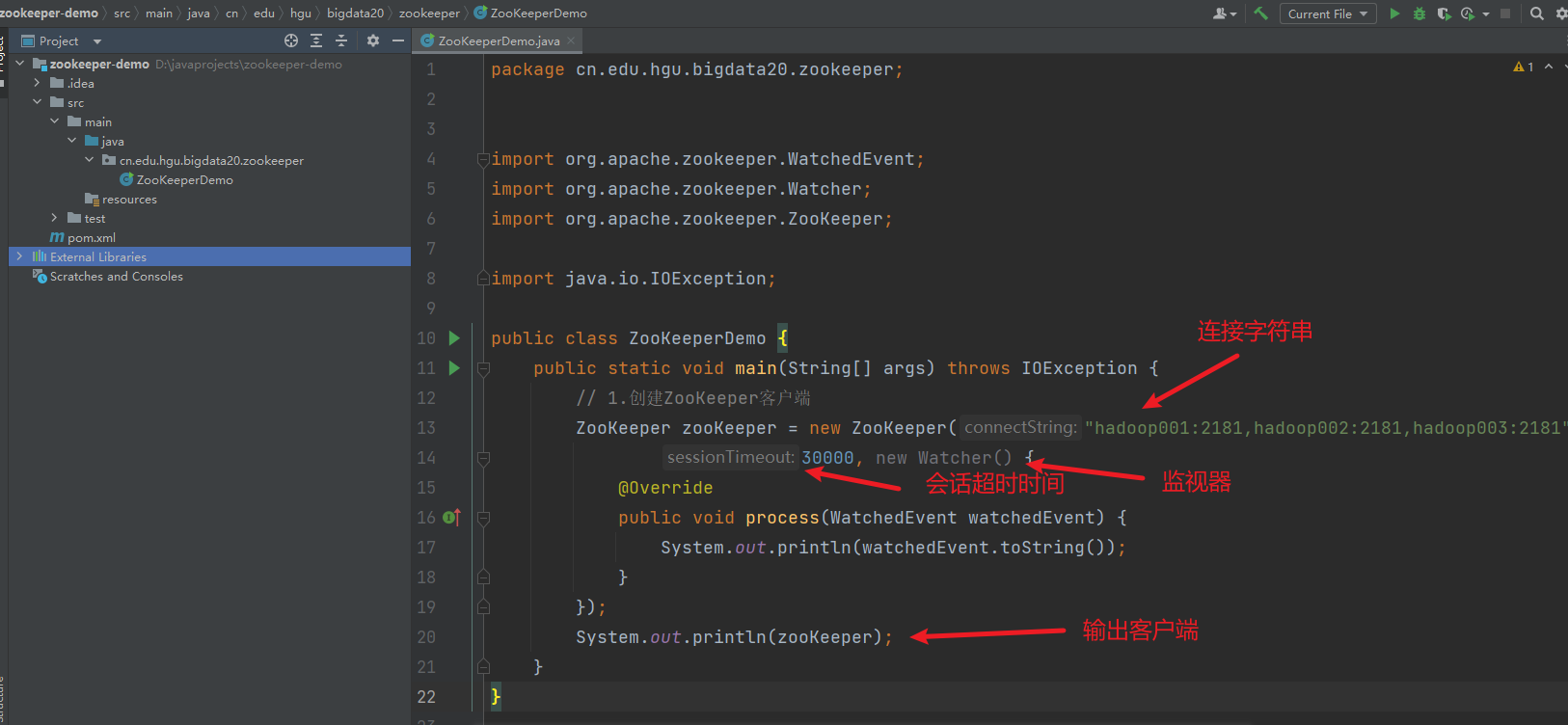
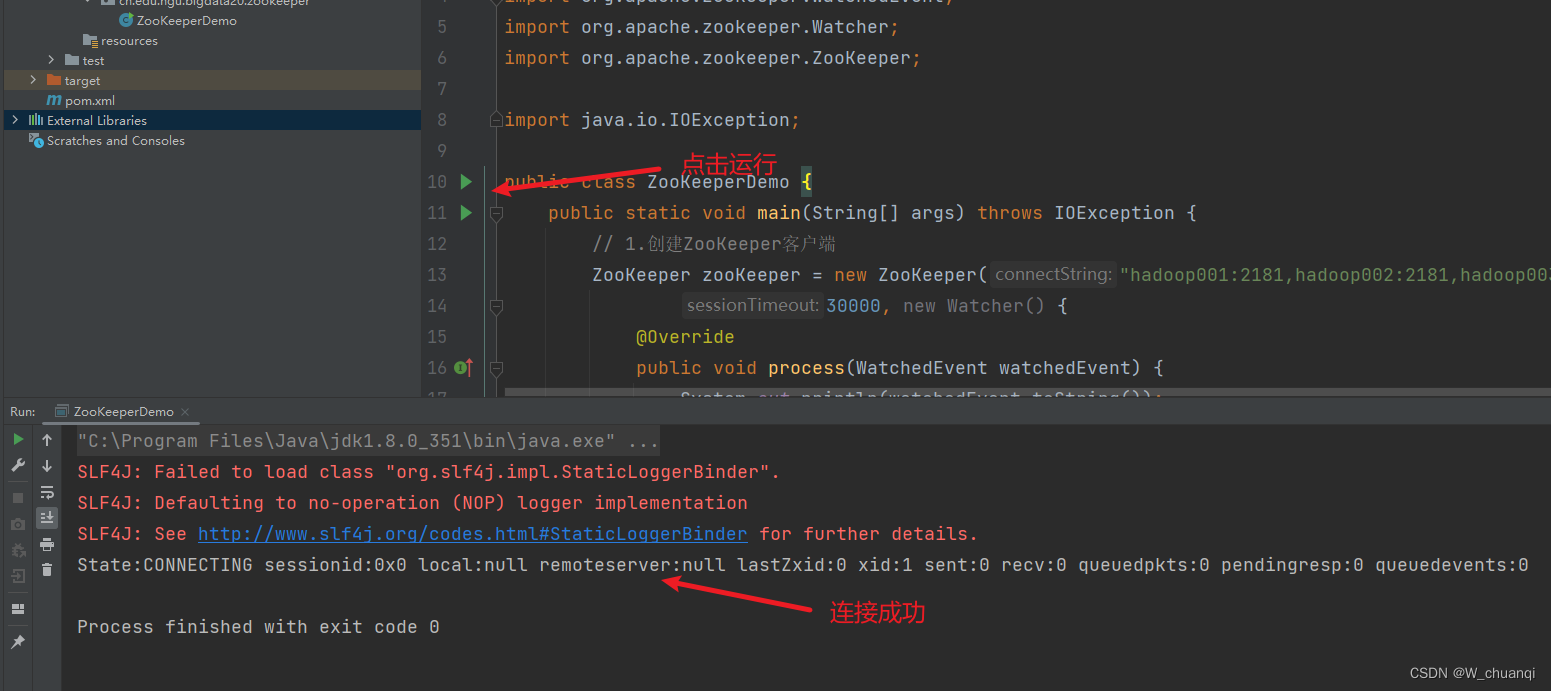
2) 创建目录节点
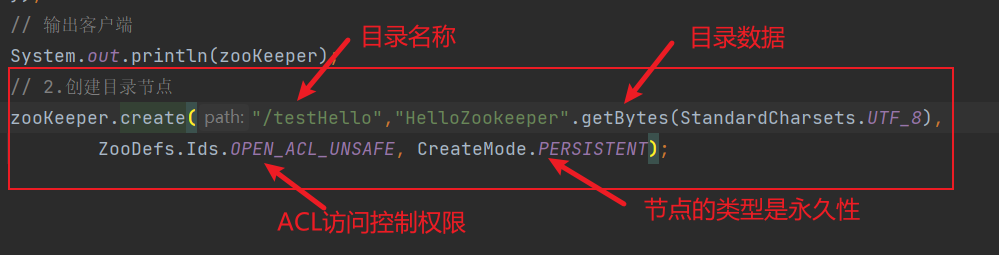
运行

通过客户端的shell进行查看

3) 创建子目录节点
先将目录代码注释掉,否则会报错
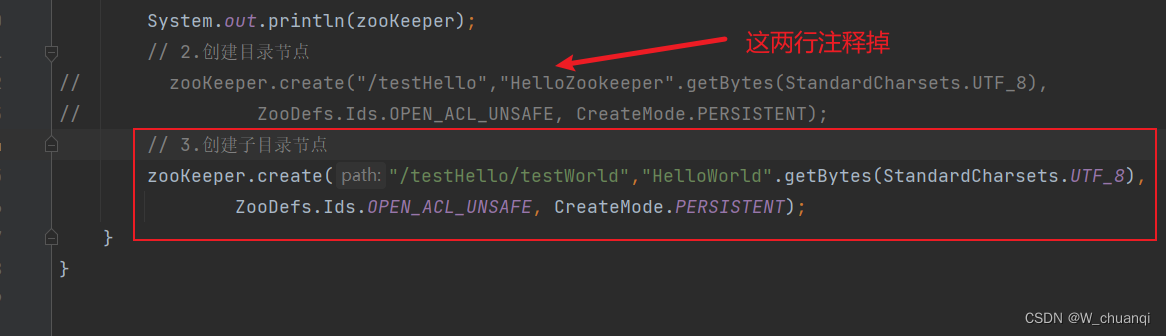
运行,查看结果
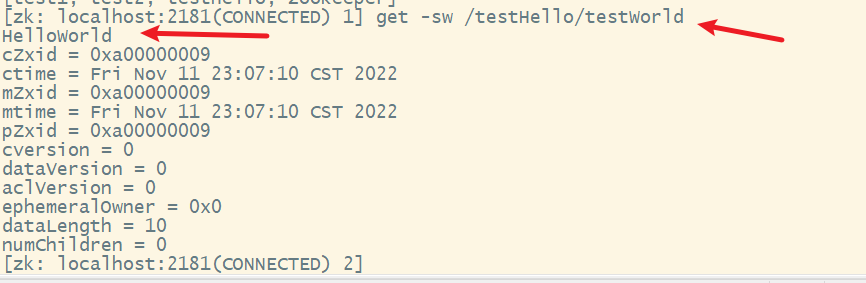
4) 获取节点数据
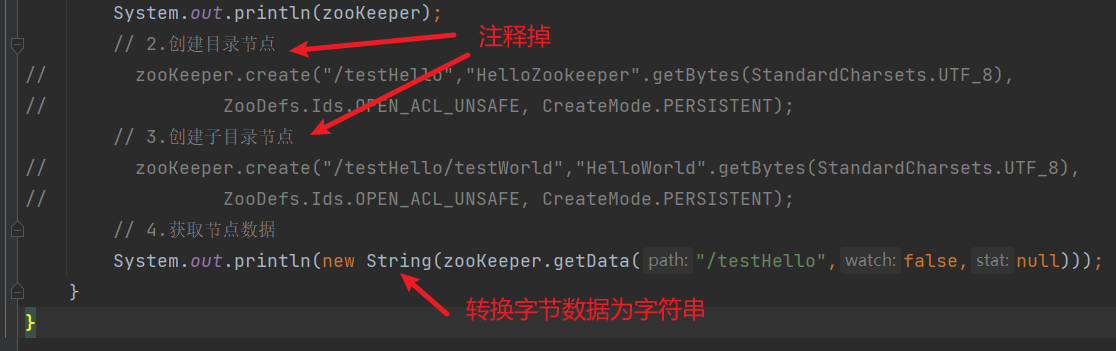
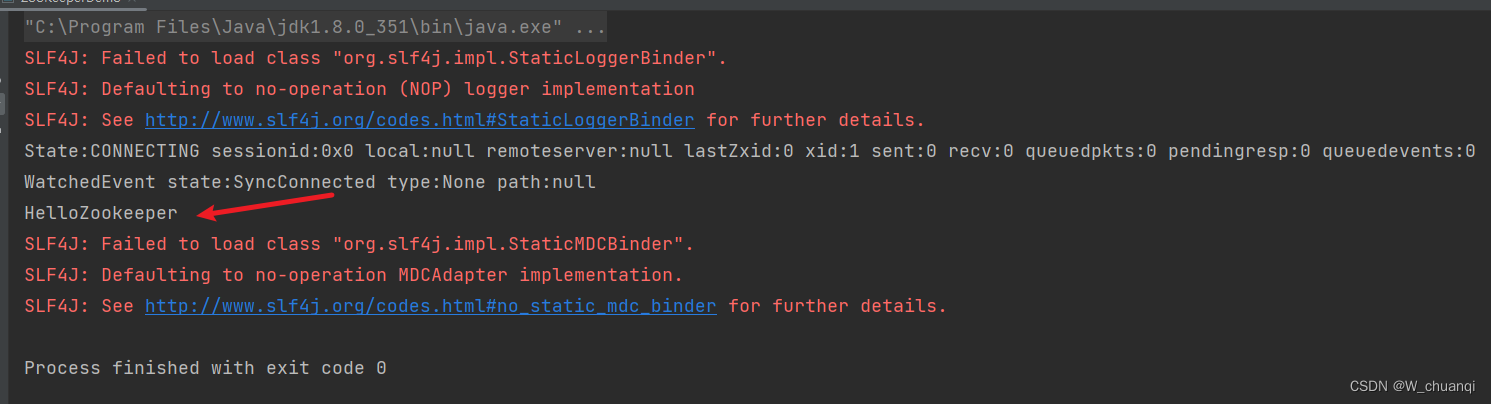
5) 获取子目录节点数据

6) 修改子目录节点数据

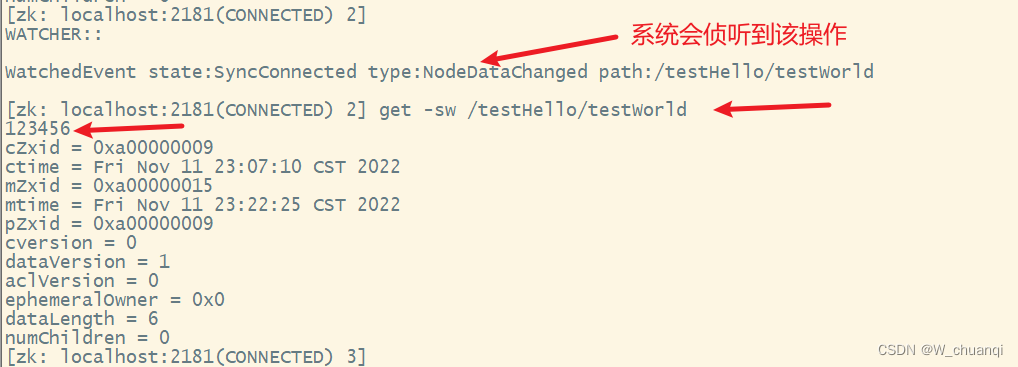
7) 判读节点是否存在

8) 删除节点


9) 完整代码
package cn.edu.hgu.bigdata20.zookeeper;
import org.apache.zookeeper.*;
import java.io.IOException;
import java.nio.charset.StandardCharsets;
public class ZooKeeperDemo {
public static void main(String[] args) throws IOException, InterruptedException, KeeperException {
// 1.创建ZooKeeper客户端
ZooKeeper zooKeeper = new ZooKeeper("hadoop001:2181,hadoop002:2181,hadoop003:2181",
30000, new Watcher() {
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println(watchedEvent.toString());
}
});
// 输出客户端
System.out.println(zooKeeper);
// 2.创建目录节点
// zooKeeper.create("/testHello","HelloZookeeper".getBytes(StandardCharsets.UTF_8),
// ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 3.创建子目录节点
// zooKeeper.create("/testHello/testWorld","HelloWorld".getBytes(StandardCharsets.UTF_8),
// ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
// 4.获取节点数据
// System.out.println(new String(zooKeeper.getData("/testHello",false,null)));
// 5.获取子目录的节点数据
// zooKeeper.getChildren("/testHello",true);
// 6.修改子目录节点数据
// zooKeeper.setData("/testHello/testWorld","123456".getBytes(StandardCharsets.UTF_8)
// ,-1);
// 7.判断节点是否存在
// System.out.println(zooKeeper.exists("/testHello",true));
// 8.删除节点
zooKeeper.delete("/testHello/testWorld", -1);
}
}
八、Zookeeper的数据模型
1. 数据的存储结构
树型结构,树中的每个节点被称为Znode,每一个Znode默认能够存储1MB的数据,由三部分组成:stat(状态信息)、data(数据信息)和children(子节点)
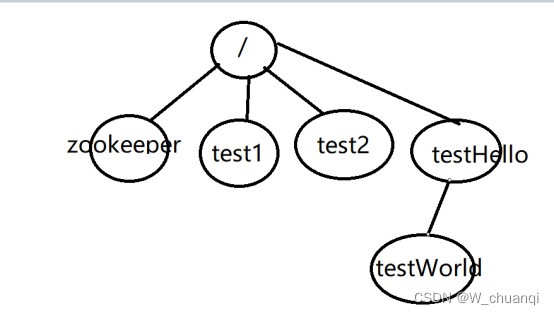
2. Znode类型
加上-s选项,可以创建四种类型的节点
- 永久节点:该节点的生命周期不依赖于会话,只有执行删除操作的时候才还被删除。
- 临时节点:该节点的生命周期依赖于创建它们的会话,一旦会话结束,临时节点会被自动删除,也可以手动删除,临时节点不允许拥有子节点
- 序列化永久节点
- 序列化临时节点
创建一个临时节点:
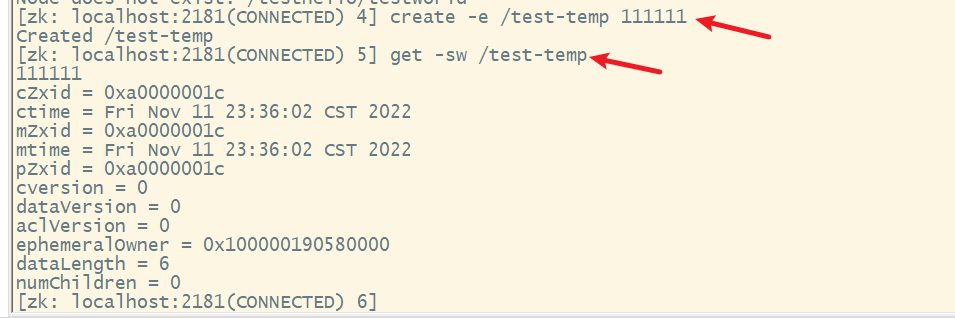
退出会话后再次进入,发现临时节点被自动删除
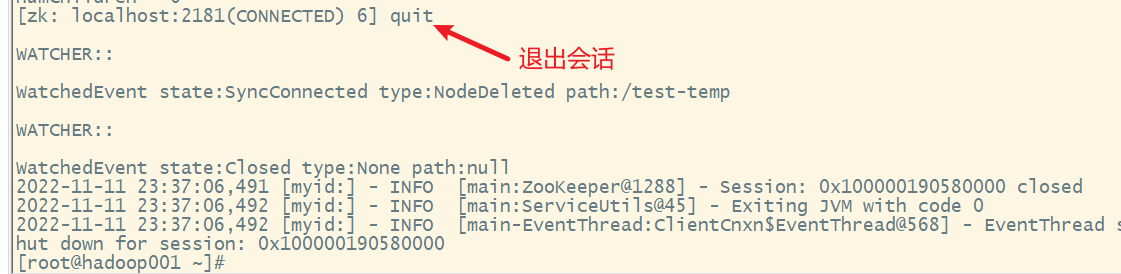
创建会话
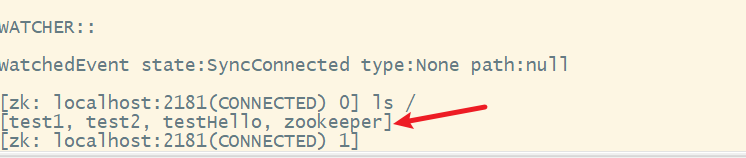
3. 节点的属性
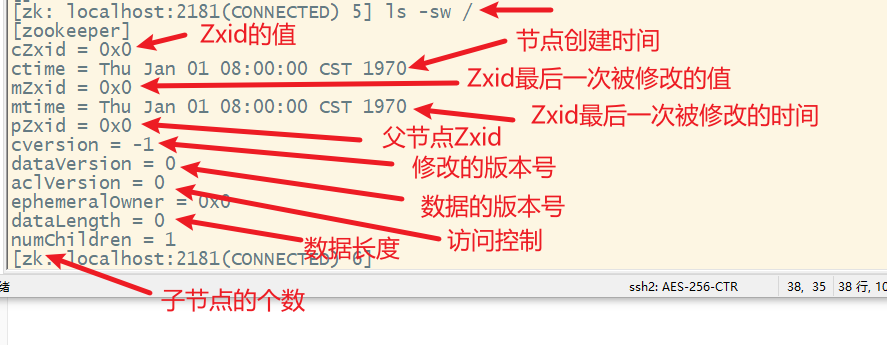
九、Zookeeper的Watch机制
1. Watch机制简介
在Zookeeper中,引入watch机制来实现分布式的通知功能,zookeeper运行客户端向服务器端注册一个watch监听,当服务器端的一些事件触发了这个watch,那就会指定客户端发送一个事件通知,来实现分布式的通知功能。
2. Watch机制的特点
1) 一次性触发
2) 事件封装
包括了状态、类型和路径

3) 异步发送
4) 先注册再发送
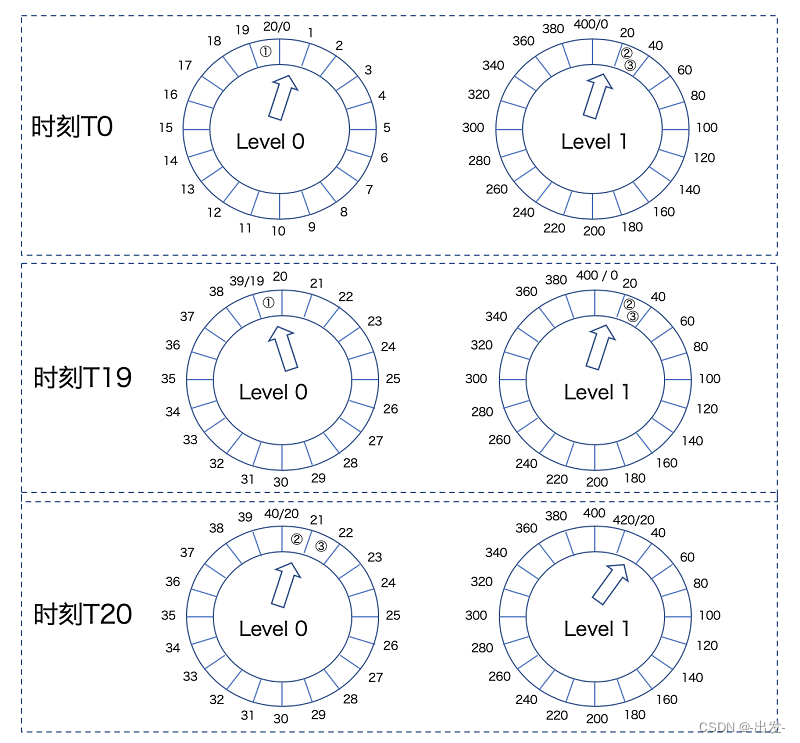
十、Zookeeper的选举机制
1. 选举机制简介
Zookeeper为了保证各节点协同工作,需要一个Leader角色,而Zookeeper采用FirstLeaderElection算法,且投票数大于节点的半数则胜出成为Leader。
1) 服务器ID
配置集群时,给每个服务器一个myid,该编号越大,则权重越大,越容易被选举为Leader
2) 选举状态
- LOOKING:竞选状态
- FOLLOWING:随从状态,同步leader状态,参与投票
- OBSERVING:观察状态:同步leader状态,不参与投票
- LEADING:领导者状态
3) 数据ID
最新的数据版本号,该值越大,说明数据越新,权重越大,越容易被选为leader
4) 逻辑时钟
也叫做投票次数,起始值为0,每投完一次票,这个值就会增加。该值越低,说明投票次数越少,该服务器就有可能宕机。
2. 选举机制的类型
1) 全新选举
是指新搭建起来,没有数据id和逻辑时钟的选举。选举步骤:
步骤1:服务器1启动,先给自己投票后发送投票信息,处于LOOKING状态
步骤2:服务器2启动,先给自己投票,跟服务器1进行对比,服务器2编号大而胜出,服务器1会把票投给服务器2,如果超过半数,则服务器2为Leader状态,服务器1为追随者状态,否则两个服务器都是LOOKING状态。
步骤3:依次进行其他服务器的启动投票,选出Leader状态,其他服务器成为FOLLOWING状态
2) 非全新选举
对于正常运行的Zookeeper集群,一旦中途有服务器宕机,则需要重新选举。
步骤1:首先统计逻辑时钟是否相同,如果不同,有小的逻辑时钟,说明存在宕机,需要重新投票选举。
步骤2:统一逻辑时钟,对比数据ID值,ID值大的胜出。
步骤3:如果逻辑时钟和数据ID都相同,这比较服务器的ID(编号),值大者胜出。
说明:非全新选举是一种优中选优,保证Leader是集群中数据最完整、最可靠的。
十一、Zookeeper的应用场景
1. 数据发布与订阅
也叫全局配置中心
2. 统一命名服务
阿里开源的分布式服务框架Dubbo采用Zookeeper作为命名服务