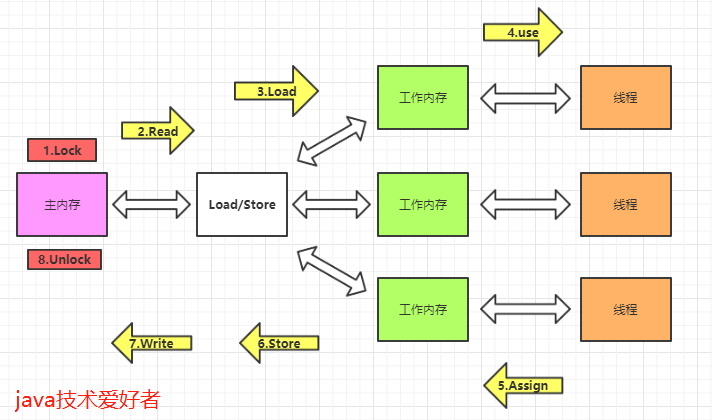
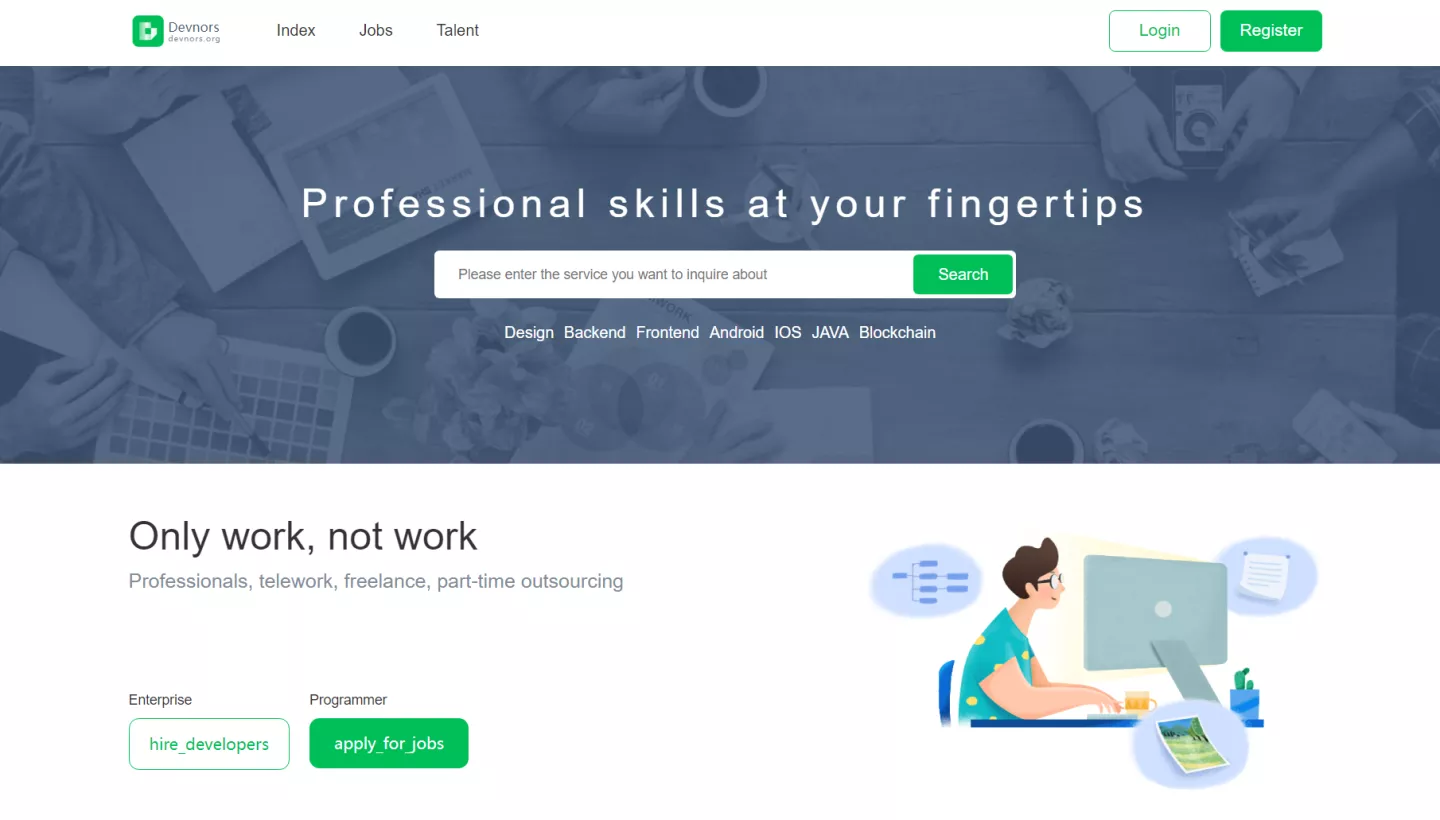
TiDB 集群问题导图
1. 服务不可用
1.1 客户端报 "Region is Unavailable" 错误
-
1.1.1
"Region is Unavailable"一般是由于 region 在一段时间不可用导致(可能会遇到"TiKV server is busy"或者发送给 TiKV 的请求由于not leader或者epoch not match被打回,或者请求 TiKV 超时等),TiDB 内部会进行backoff重试机制,backoff的时间超过了一定阈值(默认 20s),就会报错给客户端,如果backoff在阈值内该错误对于客户端是无感知的。 -
1.1.2 多台 TiKV 同时 OOM 导致 region 在一定时期内没有 leader ,见案例 case-991。
-
1.1.3 TiKV 报
TiKV server is busy,超过backoff时间,参考 4.3TiKV server is busy属于内部流控机制,后续可能不计入backoff时间,正在改善。 -
1.1.4 多台 TiKV 启动不了导致 region 没有 leader。单台物理主机部署多个 TiKV 实例,一个物理机挂掉,由于 label 配置错了导致 region 没有 leader ,见案例 case-228。
-
1.1.5 follower apply 落后,成为 leader 之后把收到的请求以
epoch not match理由打回,见案例 case-958(TiKV 内部需要优化改机制)。
1.2 PD 异常导致服务不可用,请查看 5 PD 问题
2. Latency 明显升高
2.1 短暂性的
- 2.1.1 TiDB 执行计划不对导致延迟增高,请参考 3.3
- 2.1.2 PD 出现选举问题或者 OOM 问题,请参考 5.2 和 5.3
- 2.1.3 某些 TiKV 大量掉 leader,请参考 4.4
2.2 Latency 明显升高(持续的)
-
2.2.1 TiKV 单线程瓶颈
-
单个 TiKV region 过多导致单个 gRPC 线程成为瓶颈(查看 grafana -> TiKV-details ->
Thread CPU/gRPC CPU Per Thread监控),v3.x 以上版本可以开启hibernate region特性来解决,见案例 case-612。 -
v3.0 之前版本 raftstore 单线程或者 apply 单线程到达瓶颈(grafana -> TiKV-details ->
Thread CPU/raft store CPU 和 Async apply CPU超过80%),可以选择扩容 TiKV(v2.x 版本)实例或者升级到多线程模型的 v3.x 版本,见案例 case-517。
-
-
2.2.2 CPU load 升高
-
2.2.3 TiKV 写入慢,请参考 4.5
-
2.2.4 TiDB 执行计划不对,请参考 3.3
3. TiDB 问题
3.1 DDL
-
3.1.1 修改
decimal字段长度报错"ERROR 1105 (HY000): unsupported modify decimal column precision", 见案例 case-1004,TiDB 暂时不支持修改decimal字段长度。 -
3.1.2 TiDB DDL job 卡住不动 / 执行很慢(通过
admin show ddl jobs可以查看 DDL 进度)-
原因1:与外部组件(PD / TiKV)的网络问题
-
原因2:早期版本(v3.0.8 之前)TiDB 内部自身负载很重(高并发下可能起了很多协程)
-
原因3:早期版本(v2.1.15 & v3.0.0-rc1 之前) PD 实例删除 TiDB key 无效的问题,会导致每次 DDL 变更都需要等 2 个 lease(很慢)
-
其他未知原因(请上报 bug 到 github.com/pingcap/tidb)
-
解决方法:第 1 种原因需要检查与外部组件的网络问题;第 2,3 种原因已经修复,需要升级到高版本;其他原因可选择以下兜底方案进行 DDL owner 迁移
-
DDL owner 迁移方案
-
1:如果与该台 TiDB 可以网络互通,执行重新进行 owner 选举命令:
curl -X POST http://{TiDBIP}:10080/ddl/owner/resign -
2:如果与该台 TiDB 不可以网络互通,需旁路下线,通过
tidb-ctl工具,从 PD 集群的 etcd 中直接删除 DDL owner,之后也会重新选举:tidb-ctl etcd delowner [LeaseID] [flags] + ownerKey
-
-
-
3.1.3 TiDB 日志中报
"information schema is changed"的错误-
原因1:正在执行的 DML 所涉及的表和正在做 DDL 的表相同,可以通过命令
admin show ddl job查看正在运行的 DDL 操作。 -
原因2:当前执行的 DML 时间太久,且这段时间内执行了很多 DDL(新版本
lock table也会导致 shema 版本变化),导致中间schema version变更超过 1024 个版本数 -
原因3:当前执行 DML 请求的 TiDB 实例长时间不能加载到新的
schema information(与 PD 或者 TiKV 网络问题等都会导致此问题),而这段时间内执行了很多 DDL 语句(也包括lock table语句),导致中间schema version变更超过 1024 个版本数 -
解决方法:前 2 种原因都不会导致业务问题,相应的 DML 会在失败后重试;第 3 种原因需要检查 TiDB 实例和 PD 及 TiKV 的网络情况。
-
背景知识:
schema version的增长数量与每个 DDL 变更操作的schema state个数一致, 例如:create table操作会有 1 个版本变更,add column操作会有 4 个版本变更(详情可以参考 online schema change)。所以太多的 column 变更操作会导致schema version增长的很快。
-
-
3.1.4 TiDB 日志中报
"information schema is out of date"的错误-
原因1:执行 DML 的 TiDB 被
graceful kill后准备退出,且此 DML 对应的事务执行时间超过一个 DDL lease,在事务提交时候会报此错. -
原因2:TiDB 在执行 DML 时,有一段时间连不上 PD 和 TiKV,导致以下问题:
- TiDB 在超过一个 DDL Lease(默认
45s) 的时间内没有加载到新的 schema; - 或者导致 TiDB 断开与 PD 之间带
keep alive设置的连接。
- TiDB 在超过一个 DDL Lease(默认
-
原因3:TiKV 压力大或者是网络超时,通过监控 grafana -> TiDB 和 TiKV 节点的负载情况。
-
解决方法:第 1 种原因在 TiDB 起来时,手动重试该 DML 即可;第 2 种原因需要检查 TiDB 实例和 PD 及 TiKV 的网络波动情况;第 3 种情况需要检查 TiKV 为什么繁忙,参考 4 TiKV 问题。
-
3.2 OOM 问题
-
3.2.1 现象
-
客户端:客户端收到 tidb-server 报错
"ERROR 2013 (HY000): Lost connection to MySQL server during query" -
日志
-
dmesg -T | grep tidb-server结果中有事故发生附近时间点的 OOM-killer 的日志 -
tidb.log 中可以
grep到事故发生后附近时间的"Welcome to TiDB"的日志(即 tidb-server 发生重启) -
tidb_stderr.log 中能 grep 到
"fatal error: runtime: out of memory" 或 "cannot allocate memory" -
v2.1.8 及其之前的版本,tidb_stderr.log 中能 grep 到
“fatal error: stack overflow”
-
-
监控:tidb-server 实例所在机器可用内存迅速回升
-
-
3.2.2 定位造成 OOM 的 SQL(目前所有版本都无法完成精准定位,需要在发现 SQL 后再做进一步分析确认 OOM 是否的确由该 SQL 造成)
> = v3.0.0的版本, 可以在 tidb.log 中grep “expensive_query”,该 log 会记录运行超时、或使用内存超过阈值的 SQL。< v3.0.0的版本, 通过grep “memory exceeds quota”定位运行时内存超限的 SQL。
注意
单条 SQL 内存阈值默认值为
32GB,可通过tidb_mem_quota_query系统变量进行设置,作用域SESSION, 单位Byte。也可以通过配置项热加载的方式,对配置文件中的mem-quota-query项进行修改,单位Byte。 -
3.2.3 缓解 OOM 问题
- 通过开启
SWAP的方式,可以缓解由于大查询使用内存过多而造成的 OOM 问题。但该方法会在内存空间不足时,由于存在 IO 开销,因此大查询性能造成一定影响。性能回退程度受剩余内存量、读写盘速度影响。
- 通过开启
-
3.2.4 OOM 常见原因
-
SQL 中包含 join,通过 explain 查看发现该 join 选用
HashJoin算法且inner端的表很大。如 TiDB-4116 -
单条
UPDATE/ DELETE涉及的查询数据量太大。见案例 case-882 -
SQL 中包含
Union连接的多条子查询。见案例 case-1828
-
3.3 执行计划不对
-
3.3.1 现象
-
SQL 相比于之前的执行时间有较大程度变慢,执行计划突然发生改变;如果慢日志中输出了执行计划,可以直接对比执行计划
-
SQL 执行时间相比于其他数据库(例如 MySQL)有较大差距;可以对比其他数据库执行计划,例如
Join Order是否不同 -
慢日志中 SQL 执行时间
Scan Keys数目较大
-
-
3.3.2 排查执行计划问题
-
explain analyze {SQL}。在执行时间可以接受的情况下,对比 explain analyze 结果中count和 execution info 中rows的数目差距;如果在TableScan/IndexScan行上发现比较大的差距,很大可能是统计信息出问题;如果在其他行上发现较大差距,则也有可能是非统计信息问题。 -
select count(*)。在执行计划中包含join等情况下,explain analyze 可能耗时过长;此时可以通过对TableScan/IndexScan上的条件进行select count(*),并对比 explain 结果中的row count信息,确定是不是统计信息的问题
-
-
3.3.3 缓解问题
-
v3.0 版本以及以上版本可以使用
SQL Bind功能固定执行计划 -
更新统计信息。在大致确定问题是由统计信息导致的情况下,先 dump 统计信息保留现场。如果统计信息是由于过期导致,例如
show stats_meta中 modify
count / row count 大于某个值(例如 0.3)或者表中存在时间列的索引情况下,可以先尝试 analyze table 恢复;如果配置了 auto analyze,可以查看系统变量tidb_auto_analyze_ratio是否过大(例如大于 0.3),以及当前时间是否在tidb_auto_analyze_start_time和tidb_auto_analyze_end_time范围内。 -
其他情况需报 bug
-
3.4 SQL 执行报错
-
3.4.1 客户端报
"ERROR 1265(01000) Data Truncated"错误。原因是 TiDB 内在计算Decimal类型处理精度时候,和 MySQL 不兼容(内部正在修复中,预计 v3.0.10 版本修复),具体原因如下:- MySQL 内如果两个大精度
Decimal做除法运算,超出最大小数精度时(30),会只保留30位且不报错; - TiDB 在计算结果上,也是这样实现的,但是在内部表示
Decimal的结构体内,有一个表示小数精度的字段,还是保留的真实精度; - 比如
(0.1^30) / 10,TiDB 和 MySQL 的结果都是正确的为 0,因为精度最多30,但是 TiDB 内表示精度的那字段,还是 31; - 多次
Decimal除法计算后,虽然结果正确,但是这个精度可能越来越大,最终超过 TiDB 内的另一个阈值 72,就会报"Data Truncated"的错误;Decimal 的乘法计算就不会有这个问题,因为绕过越界,会直接把精度设置为最大精度限制。
- 解决方法:可以通过手动加 Cast(xx as decimal(a, b)) 来绕过这个问题,a 和 b 就是目标的精度。
- MySQL 内如果两个大精度
4. TiKV 问题
4.1 TiKV panic 启动不了
- 4.1.1
sync-log = false,机器断电之后出现"unexpected raft log index: last_index X < applied_index Y"错误。符合预期,需通过tikv-ctl工具恢复 region; - 4.1.2 虚拟机部署 TiKV,kill 虚拟机/物理机断电,出现
“entries[X, Y] is unavailable from storage"错误。符合预期,虚拟机的 fsync 不可靠,需通过tikv-ctl工具恢复 region - 4.1.3 其他原因(非预期,需报 bug)
4.2 TiKV OOM
-
4.2.1
block-cache配置太大导致 OOM,在监控 grafana -> TiKV-details 选中对应的 instance 之后查看 RocksDB 的block cache size监控来确认是否是该问题。同时请检查[storage.block-cache] capacity = # "1GB"参数是否设置合理,默认情况下 TiKV 的block-cache设置为机器总内存的45%;在 container 部署的时候需要显式指定该参数,因为 TiKV 获取的是物理机的内存,可能会超出 container 的内存限制。 -
4.2.2. coprocessor 收到大量大查询,返回的数据量太大,gRPC 发送速度跟不上 coprocessor 往外吐数据的速度导致 OOM。可以通过检查监控: grafana -> TiKV-details -> coprocessor overview 的
response size是否超过network outbound流量来确认是否属于这种情况。 -
4.2.3 其他部分占用太多内存(非预期,需报 bug)
4.3 客户端报 server is busy 错误。通过查看监控: grafana -> TiKV -> errors 监控确认具体 busy 原因。server is busy 是 TiKV 自身的流控机制,TiKV 通过这种方式告知 tidb/ti-client 当前 TiKV 的压力过大,等会再尝试
-
4.3.1 TiKV RocksDB 出现
write stall。一个 TiKV 包含两个 RocksDB 实例,一个用于存储 raft 日志,位于 data/raft,一个用于存储真正的数据,位于data/db。通过grep "Stalling" RocksDB日志查看 stall 的具体原因,RocksDB 日志是 LOG 开头的文件,LOG 为当前日志level0 sst太多导致 stall,添加参数[rocksdb] max-sub-compactions = 2(或者 3)加快 level0 sst 往下 compact 的速度,该参数的意思是将 从 level0 到 level1 的 compaction 任务最多切成max-sub-compactions个子任务交给多线程并发执行。见案例 case-815pending compaction bytes太多导致 stall,磁盘 IO 能力在业务高峰跟不上写入,可以通过调大对应 cf 的soft-pending-compaction-bytes-limit和hard-pending-compaction-bytes-limit参数来缓解。- 如果 pending compaction bytes 达到该阈值,RocksDB 会放慢写入速度。默认值 64GB,
[rocksdb.defaultcf] soft-pending-compaction-bytes-limit = "128GB" - 如果 pending compaction bytes 达到该阈值,RocksDB 会 stop 写入,通常不太可能触发该情况,因为在达到 soft-pending-compaction-bytes-limit 的阈值之后会放慢写入速度。默认值 256GB,
hard-pending-compaction-bytes-limit = "512GB"见案例 case-275; - 如果磁盘 IO 能力持续跟不上写入,建议扩容。如果磁盘的吞吐达到了上限(例如 SATA SSD 的吞吐相对 NVME SSD 会低很多)导致 write stall,但是 CPU 资源又比较充足,可以尝试采用压缩率更高的压缩算法来缓解磁盘的压力,用 CPU 资源换磁盘资源。
- 比如 default cf compaction 压力比较大,调整参数
[rocksdb.defaultcf] compression-per-level = ["no", "no", "lz4", "lz4", "lz4", "zstd", "zstd"]改成compression-per-level = ["no", "no", "zstd", "zstd", "zstd", "zstd", "zstd"]
- 比如 default cf compaction 压力比较大,调整参数
- 如果 pending compaction bytes 达到该阈值,RocksDB 会放慢写入速度。默认值 64GB,
- memtable 太多导致 stall。该情况一般发生在瞬间写入量比较大,并且 memtable flush 到磁盘的速度比较慢的情况下。如果磁盘写入速度不能改善,并且只有业务峰值会出现这种情况,可以通过调大对应 cf 的 max-write-buffer-number 来缓解。
- 例如
[rocksdb.defaultcf] max-write-buffer-number = 8(默认值5),同时请求注意在高峰期可能会占用更多的内存,因为可能存在于内存中的 memtable 会更多
- 例如
-
4.3.2
scheduler too busy- 写入冲突严重,
latch wait duration比较高,查看监控: grafana -> TiKV-details -> scheduler prewrite 或者 scheduler commit 的latch wait duration。scheduler 写入任务堆积,导致超过了[storage] scheduler-pending-write-threshold = "100MB"设置的阈值。 - 写入慢导致写入堆积,该 TiKV 正在写入的数据超过了
[storage] scheduler-pending-write-threshold = "100MB"设置的阈值。请参考 4.5
- 写入冲突严重,
-
4.3.3
"raftstore is busy",主要是消息的处理速度没有跟上接收消息的速度。短时间的channel full不会影响服务,长时间持续出现该错误可能会导致 leader 切换走append log遇到了 stall,参考 4.3.1append log duration比较高,导致处理消息不及时,可以参考 4.5 分析为什么append log duration比较高。- 瞬间收到大量消息(查看 TiKV Raft messages 面板),raftstore 没处理过来,通常情况下短时间的 channel full 不会影响服务
-
4.3.4 TiKV coprocessor 排队,任务堆积超过了
coprocessor 线程数 * readpool.coprocessor.max-tasks-per-worker-[normal|low|high]。大量大查询导致 coprocessor 出现了堆积情况,需要确认是否有由于执行计划变化导致出现大量扫表操作,请参考 3.3
4.4 某些 TiKV 大量掉 leader
-
4.4.1 TiKV 重启了导致重新选举
- TiKV
panic之后又被 systemd 重新拉起正常运行,可以通过查看 TiKV 的日志来确认是否有panic,这种情况属于非预期,需要报 bug - 被第三者
stop/kill,被 systemd 重新拉起。查看dmesg和TiKV log确认原因 - TiKV 发生 OOM 导致重启了,参考 4.2
- 动态调整
THP导致 hung 住,见案例 case-500
- TiKV
-
4.4.2 查看监控:grafana -> TiKV-details -> errors 面板
server is busy看到 TiKV RocksDB 出现 write stall 导致发生重新选举,请参考 4.3.1 -
网络隔离导致重新选举
4.5 TiKV 写入慢
- 4.5.1 通过查看 TiKV gRPC 的 prewrite/commit/raw-put(仅限 raw kv 集群) duration 确认确实是 TiKV 写入慢了。通常情况下可以按照 performance-map 来定位到底哪个阶段慢了,下面列出集中常见的情况
- 4.5.2 scheduler CPU 繁忙(仅限 transaction kv)。prewrite/commit 的 scheduler command duration 比 scheduler latch wait duration + storage async write duartion 更长,并且 scheduler worker CPU 比较高,例如超过 scheduler-worker-pool-size * 100% 的 80%,并且或者整个机器的 CPU 资源比较紧张。如果写入量很大,确认下是否 [storage] scheduler-worker-pool-size 配置得太小。其他情况请报 bug
- 4.5.3 append log 慢。TiKV grafana 的 Raft IO/append log duration 比较高,通常情况下是由于写盘慢了,可以检查 RocksDB - raft 的 WAL Sync Duration max 值来确认,否则可能需要报 bug
- 4.5.4 raftstore 线程繁忙。TiKV grafana 的 Raft Propose/propose wait duration 明显高于 append log duration。请查看
- 1)[raftstore] store-pool-size 配置是否过小(该值建议在[1,5] 之间,不建议太大)。
- 2)机器的 CPU 是不是不够了
- 4.5.5 apply 慢了。TiKV grafana 的 Raft IO/apply log duration 比较高,通常会伴随着 Raft Propose/apply wait duration 比较高。可能是
- 1) [raftstore] apply-pool-size 配置过小(建议在 [1, 5] 之间,不建议太大),Thread CPU/apply cpu 比较高;
- 2)机器的 CPU 资源不够了;
- 3)region 写入热点问题,单个 apply 线程 CPU 使用率比较高(通过修改 grafana 表达式,加上 by (instance, name) 来看各个线程的 cpu 使用情况),暂时对于单个 region 的热点写入没有很好的方式,最近在优化该场景;
- 4)写 RocksDB 比较慢,RocksDB kv/max write duration 比较高(单个 raft log 可能包含很多个 kv,写 rocksdb 的时候会把 128 个 kv 放在一个 write batch 写入到 rocksdb,所以一次 apply log 可能涉及到多次 RocksDB 的 write);
- 5)其他情况,需要报 bug
- 4.5.6 raft commit log 慢了。TiKV grafana 的 Raft IO/commit log duration 比较高(4.x 版本的 grafana 才有该 metric)。每个 region 对应一个独立的 raft group,raft 本身是有流控机制的,类似 TCP 的滑动窗口机制,通过参数 [raftstore] raft-max-inflight-msgs = 256 来控制滑动窗口的大小,如果有热点写入并且 commit log duration 比较高可以适度调大改参数,比如 1024
- 4.5.7 其他情况,请参考 performance-map 上的写入路径来分析
5. PD 问题
5.1 PD 调度问题
-
5.1.1 merge 问题
-
跨表空 region 无法 merge,需要修改 TiKV 的
[coprocessor] split-region-on-table = false参数来解决,4.x 版本该参数默认为 false,见案例 case-896。 -
region merge 慢,可检查监控 grafana -> PD -> operator 面板是否有 merge 的 operator 产生,可以适当调大
merge-schedule-limit参数来加速 merge。
-
-
5.1.2 补副本/上下线问题
-
TIKV 磁盘使用
80%容量,PD 不会进行补副本操作,miss peer 数量上升,需要扩容 TiKV,见案例 case-801。 -
下线 TiKV,有 region 长时间迁移不走,v3.0.4 版本已经修复改问题,见 PR https://github.com/tikv/tikv/pull/5526 和见案例 case-870。
-
-
5.1.3 balance 问题
- leader/region count 分布不均,见案例 case-394, case-759。主要原因是 balance 是依赖 region/leader 的 size 去调度的,所以可能会造成 count 数量的不均衡,4.0 新增了一个参数
[leader-schedule-policy],可以调整 leader 的调度策略,根据 “count” 或者是 “size” 进行调度。
- leader/region count 分布不均,见案例 case-394, case-759。主要原因是 balance 是依赖 region/leader 的 size 去调度的,所以可能会造成 count 数量的不均衡,4.0 新增了一个参数
5.2 PD 选举问题
-
5.2.1 PD 发生 leader 切换
-
磁盘问题,PD 所在的节点 I/O 被打满,排查是否有其他 I/O 高的组件与 PD 混部以及盘的健康情况,可通过监控 grafana -> disk performance -> latency 和 load 等指标进行验证,必要时可以使用 fio 工具对盘进行检测,见案例 case-292
-
网络问题,PD 日志中有
"lost the TCP streaming connection",排查 PD 之间网络是否有问题,可通过监控 grafana -> PD -> etcd 的 round trip 来验证,见案例 case-177 -
系统 load 高,日志中能看到
"server is likely overloaded",见案例 case-214
-
-
5.2.2 PD 选不出 leader 或者选举慢
-
选不出 leader,PD 日志中有
"lease is not expired",见 issues https://github.com/etcd-io/etcd/issues/10355 v3.0.x 版本和 v2.1.19 版本已 fix 该问题,见案例 case-875 -
选举慢,region 加载时间长,从 PD 日志中
grep "regions cost"(例如日志中可能是 load 460927 regions cost 11.77099s), 如果出现秒级,则说明较慢,v3.0 版本可开启 region storage(设置use-region-storage为 true),该特性能极大缩短加载 region 的时间,见案例 case-429
-
-
5.2.3 TiDB 执行 SQL 时报 PD timeout
-
PD 没 leader 或者有切换,参考 5.2.1 和 5.2.2
-
网络问题,排查网络相关情况。通过监控 grafana -> blackbox_exporter -> ping latency 确定 TiDB 到 PD leader 的网络是否正常
-
PD panic,报 bug
-
PD OOM 参考 5.3
-
其他原因,通过
curl http://127.0.0.1:2379/debug/pprof/goroutine?debug=2抓 goroutine,报 bug
-
-
5.2.4 其他问题
-
PD 报
FATAL错误,日志中有"range failed to find revision pair",3.0.8 已经 fix 改问题,见 PR https://github.com/pingcap/pd/pull/2040 详情请参考案例 case-947 -
其他原因,需报 bug
-
5.3 PD OOM
-
5.3.1 使用 /api/v1/regions 接口时 region 数量过多可能会导致 PD OOM,v3.0.8 版本修复,见 https://github.com/pingcap/pd/pull/1986
-
5.3.2 滚动升级的时候 PD OOM,gRPC 消息大小没限制,监控可看到 TCP InSegs 较大,v3.0.6 版本修复,见 https://github.com/pingcap/pd/pull/1952 详情请参考案例 case-852
5.4 grafana 显示问题
- 5.4.1 监控 grafana -> PD -> cluster -> role 显示 follower,grafana 表达式问题,3.0.8 版本修复,见 issue https://github.com/pingcap/tidb-ansible/pull/1065 详情请参考案例 case-1022
6. 生态 tools 问题
6.1 binlog 问题
-
6.1.1 TiDB binlog 是能将 TiDB 的修改同步给下游 TiDB 或者 MySQL 的工具,见官方文档 https://github.com/pingcap/tidb-binlog
-
6.1.2 Pump/Drainer Status 中 Update Time 正常更新,日志中也没有异常,但下游没有数据写入
- TiDB 配置中没有开启 binlog,需要修改 TiDB 配置
[binlog]
- TiDB 配置中没有开启 binlog,需要修改 TiDB 配置
-
6.1.3 Drainer 中的 sarama 报
EOF错误- Drainer 使用的 Kafka 客户端版本和 Kafka 版本不匹配,需要修改配置
[syncer.to] kafka-version来解决,见 TOOL-199
- Drainer 使用的 Kafka 客户端版本和 Kafka 版本不匹配,需要修改配置
-
6.1.4 Drainer 写 kafka 失败然后 panic,kafka 报
"Message was too large"错误-
binlog 数据太大,造成写 Kafka 的单条消息太大,需要修改 kafka 的下列配置来解决:
message.max.bytes=1073741824 replica.fetch.max.bytes=1073741824 fetch.message.max.bytes=1073741824
见案例 case-789
-
-
6.1.5 上下游数据不一致
-
部分 TiDB 节点没有开启 binlog。v3.0.6 及之后的版本可以通过访问
http://127.0.0.1:10080/info/all接口可以检查所有节点的 Binlog 状态。之前的版本可以通过查看配置文件来确认是否开启了 binlog。 -
部分 TiDB 节点进入 ignore binlog 状态。v3.0.6 及之后的版本可以通过访问
http://127.0.0.1:10080/info/all接口可以检查所有节点的 Binlog 状态。之前的版本需要看 tidb 的日志中是否有 ignore binlog 关键字来确认是该问题。 -
上下游 timestamp 列的值不一致
-
时区问题,需要确保 drainer 和上下游数据库时区一致,drainer 通过
/etc/localtime获取时区,不支持TZ环境变量,见案例 case-826。 -
TiDB 中 timestamp 的默认值为 null,mysql 5.7 中 timestamp 默认值为当前时间(mysql 8 无此问题),因此在上游写入 null 的 timestamp 且下游是 mysql 5.7 时,timestamp 列数据不一致。在开启 binlog 前,在上游执行
set @@global.explicit_defaults_for_timestamp=on;可解决问题,见 TOOL-1539。
-
-
其他情况报 bug。
-
-
6.1.6 同步慢
-
下游是 TiDB/MySQL,上游频繁做 DDL,参见案例 case-1023。
-
下游是 TiDB/MySQL,需要同步的表中存在没有主键且没有唯一索引的表,这种情况会导致 binlog 性能下降,建议加主键或唯一索引。
-
下游输出到文件,检查目标磁盘/网络盘是否慢。
-
其他情况报 bug。
-
-
6.1.7 Pump 无法写 binlog,报
"no space left on device"错误- 本地磁盘空间不足,Pump 无法正常写 binlog 数据。需要清理磁盘空间,然后重启 Pump。
-
6.1.8 Pump 启动时报错
"fail to notify all living drainer"- Pump 启动时需要通知所有 Online 状态的 Drainer,如果通知失败则会打印该错误日志。可以使用 binlogctl 工具查看所有 Drainer 的状态是否有异常,保证 Online 状态的 Drainer 都在正常工作。如果某个 Drainer 的状态和实际运行情况不一致,则使用 binlogctl 修改状态,然后再重启 Pump。见案例 fail-to-notify-all-living-drainer。
-
6.1.9 Drainer 报错
"gen update sqls failed: table xxx: row data is corruption []"- 触发条件:上游做 Drop Column DDL 的时候同时在做这张表的 DML。已经在 v3.0.6 修复,见 case-820。
-
6.1.10 Drainer 同步卡住,进程活跃但 checkpoint 不更新
- 已知 bug 在 v3.0.4 fix,见案例 case-741。
-
6.1.11 任何组件
panic- 报 bug
6.2 DM 问题
-
6.2.1 DM 是能将 MySQL/MariaDB 的数据迁移到 TiDB 的迁移工具,见 GitHub
https://github.com/pingcap/dm/ -
6.2.2 执行
query-status或查看日志时出现"Access denied for user 'root'@'172.31.43.27' (using password: YES)"-
在所有 DM 配置文件中,数据库相关的密码都必须使用经 dmctl 加密后的密文(若数据库密码为空,则无需加密)
-
在 DM 运行过程中,上下游数据库的用户必须具备相应的读写权限。在启动同步任务过程中,DM 会自动进行相应权限的检查 官方文档:前置检查
-
同一套 DM 集群,混合部署不同版本的 DM-worker/DM-master/dmctl,见案例 asktug-1049
-
-
6.2.3 DM 同步任务中断并包含
"driver: bad connection"错误-
发生
"driver: bad connection"错误时,通常表示 DM 到下游 TiDB 的数据库连接出现了异常(如网络故障、TiDB 重启等)且当前请求的数据暂时未能发送到 TiDB-
1.0.0 GA 之前的版本,DM 发生该类型错误时,需要先使用 stop-task 命令停止任务后再使用 start-task 命令重启任务。
-
1.0.0 GA 版本,增加对此类错误的自动重试机制,见 PR
https://github.com/pingcap/dm/pull/265
-
-
-
6.2.4 同步任务中断并包含 invalid connection 错误
-
发生
"invalid connection"错误时,通常表示 DM 到下游 TiDB 的数据库连接出现了异常(如网络故障、TiDB 重启、TiKV busy 等)且当前请求已有部分数据发送到了 TiDB。由于 DM 中存在同步任务并发向下游复制数据的特性,因此在任务中断时可能同时包含多个错误(可通过 query-status 或 query-error 查询当前错误)。-
如果错误中仅包含
"invalid connection"类型的错误且当前处于增量复制阶段,则 DM 会自动进行重试。 -
如果 DM 由于版本问题(v1.0.0-rc.1 后引入自动重试)等未自动进行重试或自动重试未能成功,则可尝试先使用 stop-task 停止任务,然后再使用 start-task 重启任务。
-
-
-
6.2.5 relay 处理单元报错 event from * in * diff from passed-in event * 或同步任务中断并包含
"get binlog error ERROR 1236 (HY000)、binlog checksum mismatch, data may be corrupted"等 binlog 获取或解析失败错误-
在 DM 进行 relay log 拉取与增量同步过程中,如果遇到了上游超过 4GB 的 binlog 文件,就可能出现这两个错误。原因是 DM 在写 relay log 时需要依据 binlog position 及文件大小对 event 进行验证,且需要保存同步的 binlog position 信息作为 checkpoint。但是 MySQL binlog position 官方定义使用 uint32 存储,所以超过 4G 部分的 binlog position 的 offset 值会溢出,进而出现上面的错误。
-
对于 relay 处理单元, 可通过官网步骤进行手动处理。
-
对于 binlog replication 处理单元,可通过官网步骤进行手动处理。
-
-
-
6.2.6 DM 同步中断,日志报错
"ERROR 1236 (HY000) The slave is connecting using CHANGE MASTER TO MASTER_AUTO_POSITION = 1, but the master has purged binary logs containing GTIDs that the slave requires."-
检查 master 的 binlog 是否被 purge
-
检查 relay.meta 中记录的位点信息
-
relay.meta 中记录空的 GTID 信息,DM-worker 进程在退出时、以及定时(30s)会把内存中的 gtid 信息保存到 relay.meta 中,在没有获取到上游 GTID 信息的情况下,把空的 GTID 信息保存到了 relay.meta 中。见案例 case-772。
-
relay.meta 中记录的 binlog event 不完整触发 recover 流程后记录错误的 GTID 信息,该问题可能会在 1.0.2 之前的版本遇到,已在 1.0.2 版本修复。见案例 case-764。
-
-
-
6.2.7 DM 同步报错
"Error 1366: incorrect utf8 value eda0bdedb29d(\ufffd\ufffd\ufffd\ufffd\ufffd\ufffd)"- 该值 mysql 8.0 和 tidb 都不能写入成功,但是 mysql 5.7 可以写入成功。可以开启 TiDB 动态参数
tidb_skip_utf8_check参数跳过数据格式检查。
- 该值 mysql 8.0 和 tidb 都不能写入成功,但是 mysql 5.7 可以写入成功。可以开启 TiDB 动态参数
6.3 lightning 问题
-
6.3.1 TiDB lightning 是快速的全量数据导入工具,见 Github
https://github.com/pingcap/tidb-lightning -
6.3.2 导入速度太慢
-
region-concurrency设定太高,线程间争用资源反而减低了效率。排查方法- 从日志的开头搜寻
region-concurrency能知道 Lightning 读到的参数是多少; - 如果 Lightning 与其他服务(如 Importer)共用一台服务器,必需手动将
region-concurrency设为该服务器 CPU 数量的75%; - 如果 CPU 设有限额(例如从 K8s 指定的上限),Lightning 可能无法自动判断出>来,此时亦需要手动调整
region-concurrency。
- 从日志的开头搜寻
-
表结构太复杂。每条索引都会额外增加 KV 对。如果有 N 条索引,实际导入的大小就差不多是 Mydumper 文件的 N+1 倍。如果索引不太重要,可以考虑先从 schema 去掉,待导入完成后再使用 CREATE INDEX 加回去。
-
Lightning 版本太旧。尝试使用最新的版本,可能会有改善。
-
-
6.3.3
"checksum failed: checksum mismatched remote vs local"-
原因1:这张表可能本身已有数据,影响最终结果。
-
原因2:如果目标数据库的校验和全是 0,表示没有发生任何导入,有可能是集群太忙无法接收任何数据。
-
原因3:如果数据源是由机器生成而不是从 Mydumper 备份的,需确保数据符合表的限制,例如:1)自增 (AUTO_INCREMENT) 的列需要为正数,不能为 0。2)单一键和主键 (UNIQUE and PRIMARY KEYs) 不能有重复的值。
-
解决办法:参考官网步骤处理
-
-
6.3.4
"Checkpoint for … has invalid status:(错误码)"-
原因:断点续传已启用。Lightning 或 Importer 之前发生了异常退出。为了防止数据意外损坏,Lightning 在错误解决以前不会启动。错误码是小于 25 的整数,可能的取值是 0、3、6、9>、12、14、15、17、18、20、21。整数越大,表示异常退出所发生的步骤在导入流程中越晚。
-
解决办法:参考官网步骤处理
-
-
6.3.5
"ResourceTemporarilyUnavailable("Too many open engines …: 8")"- 原因:并行打开的引擎文件 (engine files) 超出 tikv-importer 里的限制。这可能由配置错误引起。即使配置没问题,如果 tidb-lightning 曾经异常退出,也有可能令引擎文件残留在打开的状态,占据可用的数量。
- 解决办法:参考官网步骤处理
-
6.3.6
"cannot guess encoding for input file, please convert to UTF-8 manually"-
原因:Lightning 只支持 UTF-8 和 GB-18030 编码的表架构。此错误代表数据源不是这里任一个编码。也有可能是文件中混合了不同的编码,例如,因为在不同的环境运行过 ALTER TABLE,使表架构同时出现 UTF-8 和 GB-18030 的字符。
-
解决办法:参考官网步骤处理
-
-
6.3.7
"[sql2kv] sql encode error = [types:1292]invalid time format: '{1970 1 1 0 45 0 0}'"-
原因:一个 timestamp 类型的时间戳记录了不存在的时间值。时间值不存在是由于夏令时切换或超出支持的范围(1970 年 1 月 1 日至 2038 年 1 月 19 日)。
-
解决办法:参考官网步骤处理
-
7. 常见日志分析
7.1 TiDB
-
7.1.1
"GC life time is shorter than transaction duration"。事务执行时间太长,超过了 GC lifetime(默认 10min),可以通过修改 mysql.tidb 表来调整life time,通常情况下不建议修改,会导致大量老版本堆积起来(如果有大量 update 和 delete 语句)。 -
7.1.2
"txn takes too much time"。事务太长时间(超过 590s)没有提交,准备提交的时候报该错误。可以通过调大[tikv-client] max-txn-time-use = 590参数,以及调大GC life time来绕过该问题(如果确实有这个需求)。通常情况下建议看看业务是否真的需要执行这么长时间的事务。 -
7.1.3 coprocessor.go 报
"request outdated"。发往 TiKV 的 coprocessor 请求在 TiKV 端排队时间超过了 60s,直接返回该错误。需要排查 TiKV coprocessor 为什么排队这么严重。 -
7.1.4 region_cache.go 大量报
"switch region peer to next due to send request fail"且 error 信息是"context deadline exceeded"。请求 TiKV 超时触发 region cache 切换请求到其他节点,可以对日志中的 addr 字段继续"grep "<addr> cancelled"根据 grep 结果:-
"send request is cancelled"。请求发送阶段超时,可以排查监控 grafana -> TiDB -> Batch Client/Pending Request Count by TiKV 是否大于 128 来确定是否因发送远超 KV 处理能力导致发送堆积,如果 Pending Request 不多需要排查日志确认是否因为对应 KV 有运维变更导致短暂报出, 否则非预期,需报 bug -
"wait response is cancelled"。请求发送到 TiKV 后超时未收到 TiKV 相应需要排查对应地址 TiKV 响应时间和对应 region 在当时的 PD 和 KV 日志来确定为什么 KV 未及时响应。
-
-
7.1.5 distsql.go 报
"inconsistent index"。数据索引疑似发生不一致,首先对报错的信息中 index 所在表执行admin check table <TableName>命令,如果检查失败则先通过命令关闭 GC ,并报 bug。begin; update mysql.tidb set variable_value='72h' where variable_name='tikv_gc_life_time'; commit;
7.2 TiKV
-
7.2.1
"key is locked"。读写冲突,读请求碰到还未提交的数据,需要等待其提交之后才能读。少量这个错误对业务无影响,大量出现这个错误说明业务读写冲突比较严重。 -
7.2.2
"write conflict"。乐观事务中的写写冲突,同时多个事务对相同的 key 进行修改,只有一个事务会成功,其他事务会自动重取 timestamp 然后进行重试,不影响业务。如果业务冲突很严重可能会导致重试多次之后事务失败,这种情况下建议使用悲观锁。 -
7.2.3
"TxnLockNotFound"。事务提交太慢,过了 ttl(小事务默认 3s) 时间之后被其他事务回滚了,该事务会自动重试,通常情况下对业务无感知。 -
7.2.4
"PessimisticLockNotFound"。类似TxnLockNotFound,悲观事务提交太慢被其他事务回滚了。 -
7.2.5
"stale_epoch"。请求的 epoch 太旧了,TiDB 会更新路由之后再重新发送请求,业务无感知。epoch 在 region 发生 split/merge 以及迁移副本的时候会变化。 -
7.2.6
"peer is not leader"。请求发到了非 leader 的副本上,TiDB 会根据该错误更新本地路由(如果错误 response 里面携带了最新的 leader 是哪个副本这一信息)并且重新发送请求到最新 leader,一般情况下业务无感知。在 v3.0 后 TiDB 在原 leader 请求失败时会尝试其他 peer 也会导致 TiKV 频繁出现 not leader 日志, 可以通过排查 TiDB 对应 region 的"switch region peer to next due to send request fail"日志排查发送失败根本原因,参考 7.1.4。另外也可能是由于其他原因导致一些 region 一直没有 leader 导致,请参考 4.4。