本文使用同一个数据集进行数据预处理练习,其中包含了人脸图片文件夹,CSV文件,txt文件。
数据集主要是针对于人脸照片进行年龄以及性别的预测,在导入模型签的一些简单的数据处理。
1.对人脸图片文件夹,txt文件的操作
1.1.数据集格式
├── faces
├── 00000A02.jpg
├── 00002A02.jpg
├── 00004A02.jpg
├── 00006A02.jpg
├── ......
├── face_gender_label.txt
- 在txt文件中,对每个jpg文件,都标注了文件类别:0 ,1。
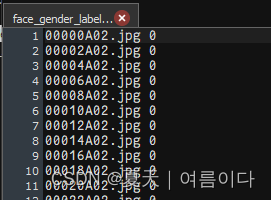
其中第一列就是对应文件的名字,第二列就是该文件所属的类别
然后,还给出了不同类别对应的分类的具体名称:0 为女性 ,1为男性。
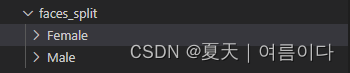
目的就是实现将女性男性分别建立文件夹,根据标签进行分类至不同文件夹,并保存照片。
想实现的效果如下:
├── Female
├── 00000A02.jpg
├── 00002A02.jpg
├── 00004A02.jpg
├── 00006A02.jpg
├── ......
├── Male
├── 07974A11.jpg
├── 07976A12.jpg
├── 07978A12.jpg
├── 07980A12.jpg
├── ......
1.2.提取txt文件中的标签,按照标签类型保存人脸图片的代码实现。
(如果是修改为自己的数据集的话,只需要修改读取的路径,以及txt文件路径及名称)
import os
import shutil
label_file = open("D:\\Pro\stfa1227\\STFA\\face_gender_label.txt", 'r')
input_path = "D:\\Pro\stfa1227\\STFA\data_set\\face_data\\faces_JinChungChen"
output_path = "D:\\Pro\stfa1227\\STFA\data_set\\faces_split"
lables=["Male","Female"]
data = label_file.readlines()
i = 1
for line in data:
str1 = line.split(" ")
file_name = str1[0]
file_label = str1[1].strip()
old_file_path = os.path.join(input_path, file_name)
new_file_path = ""
if "0" in file_label:
new_file_path = os.path.join(output_path, lables[int(file_label) - 1])
elif "1" in file_label:
new_file_path = os.path.join(output_path, lables[int(file_label) - 1])
if not os.path.exists(new_file_path):
print("Path " + new_file_path + " not existed,creat new one......")
os.makedirs(new_file_path)
new_file_path = os.path.join(new_file_path, file_name)
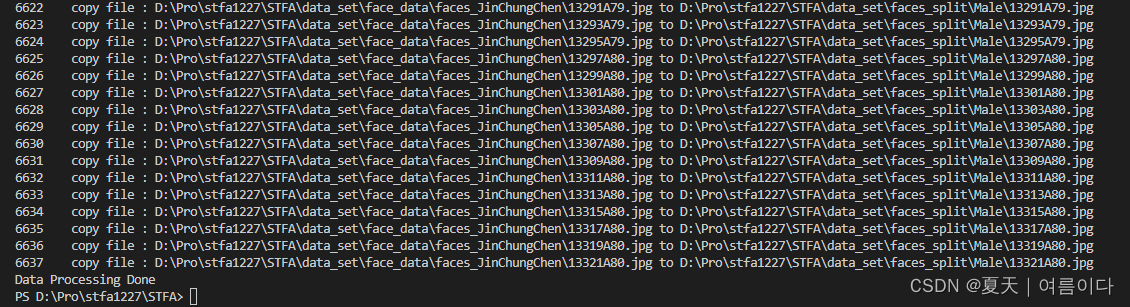
print("" + str(i) + "\tcopy file : " + old_file_path + " to " + new_file_path)
shutil.copyfile(old_file_path, new_file_path)
i = i + 1
print("Data Processing Done")
str1[1]和str1[1].strip()的区别
strip: 用来去除头尾字符、空白符(包括\n、\r、\t、' ',即:换行、回车、制表符、空格)
结果
1.2.根据上面提取的文件,按照比例划分为训练集和测试集
(如果是修改为自己的数据集的话,只需要修改读取的路径)
代码
import os
from shutil import copy, rmtree
import random
def mk_file(file_path: str):
if os.path.exists(file_path):
rmtree(file_path)
os.makedirs(file_path)
def main():
random.seed(0)
split_rate = 0.1
cwd = os.getcwd()
data_root = os.path.join(cwd, "data_set/face_data")
origin_photos_path = os.path.join(data_root, "faces_split")
assert os.path.exists(origin_photos_path), "path '{}' does not exist.".format(origin_photos_path)
photo_class = [cla for cla in os.listdir(origin_photos_path)
if os.path.isdir(os.path.join(origin_photos_path, cla))]
train_root = os.path.join(data_root, "train")
mk_file(train_root)
for cla in photo_class:
mk_file(os.path.join(train_root, cla))
val_root = os.path.join(data_root, "val")
mk_file(val_root)
for cla in photo_class:
mk_file(os.path.join(val_root, cla))
for cla in photo_class:
cla_path = os.path.join(origin_photos_path, cla)
images = os.listdir(cla_path)
num = len(images)
eval_index = random.sample(images, k=int(num*split_rate))
for index, image in enumerate(images):
if image in eval_index:
image_path = os.path.join(cla_path, image)
new_path = os.path.join(val_root, cla)
copy(image_path, new_path)
else:
image_path = os.path.join(cla_path, image)
new_path = os.path.join(train_root, cla)
copy(image_path, new_path)
print("\r[{}] processing [{}/{}]".format(cla, index+1, num), end="") # processing bar
print()
print("processing done!")
if __name__ == '__main__':
main()
结果

(为了看的方便,我把刚才的faces_split文件夹名修改为faces_gender_photos)
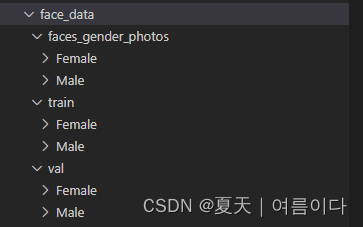
原本的照片不变,只是重新划分了训练集和验证集,以此方便深度网络模型去训练!
2.对人脸图片文件夹,CSV文件的操作
(python深度学习图像处理CSV文件分类标签图片到各个文件夹)
2.1.数据集格式
├── faces
├── 00000A02.jpg
├── 00002A02.jpg
├── 00004A02.jpg
├── 00006A02.jpg
├── ......
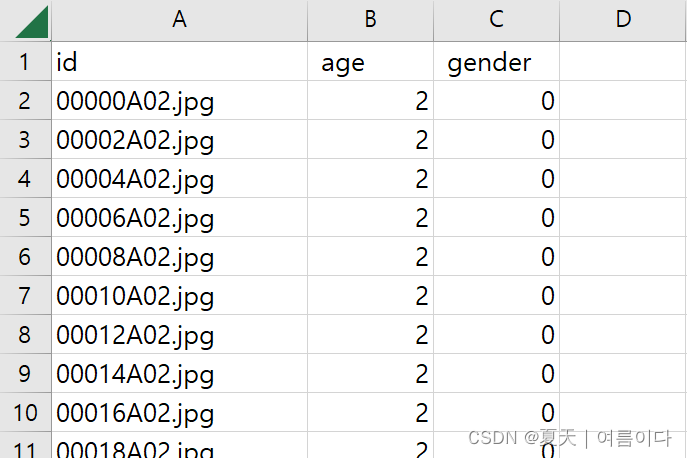
├── faces.csv
faces.csv文件详情
import pandas as pd
import os
import shutil
# 读取表格文件+填写你的csv文件的位置
f = open(r"D:\\Pro\\stfa1227\\STFA\\data_set\\face_data\\train_age_JCC.csv", "rb")
list = pd.read_csv(f)
# 进行分类----填写你要分类文件夹的标签,有多少就写多少
for i in ['age','gender']:
if not os.path.exists(i):
os.mkdir(i)
listnew = list[list["age"] == i]#type是你csv文件里面的你要处理的那一列的列名称
l = listnew["id"].tolist()#image这里是你的处理文件的名字的列名称
j = str(i)
for each in l:
#这里是你数据文件放置的位置
shutil.copy('D:\\Pro\\stfa1227\\STFA\\data_set\\csv_datapro\\' + each, j)