一、原理介绍
-
hdfs
指令测试:hdfs dfs -mkdir /ranger
原理:根据路径进行文件夹操作赋权。一旦指定文件夹权限,则该用户可以操作该文件夹及该文件夹底下的子文件夹。
-
yarn
指令测试:hadoop jar /home/hadoop/module/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar pi -Dmapred.job.queue.name=default 2 2
原理:根据队列进行赋权,被赋权的用户可以提交任务给队列执行。
-
hive
原理:根据数据库、表、字段进行过滤用户的权限。
-
hbase
原理:根据数据库、字段族、字段进行过滤用户的权限。
二、配置用户
ps:注意,配置了kerberos后,验证用户不再是验证linux用户,而是验证kerberos用户。
-
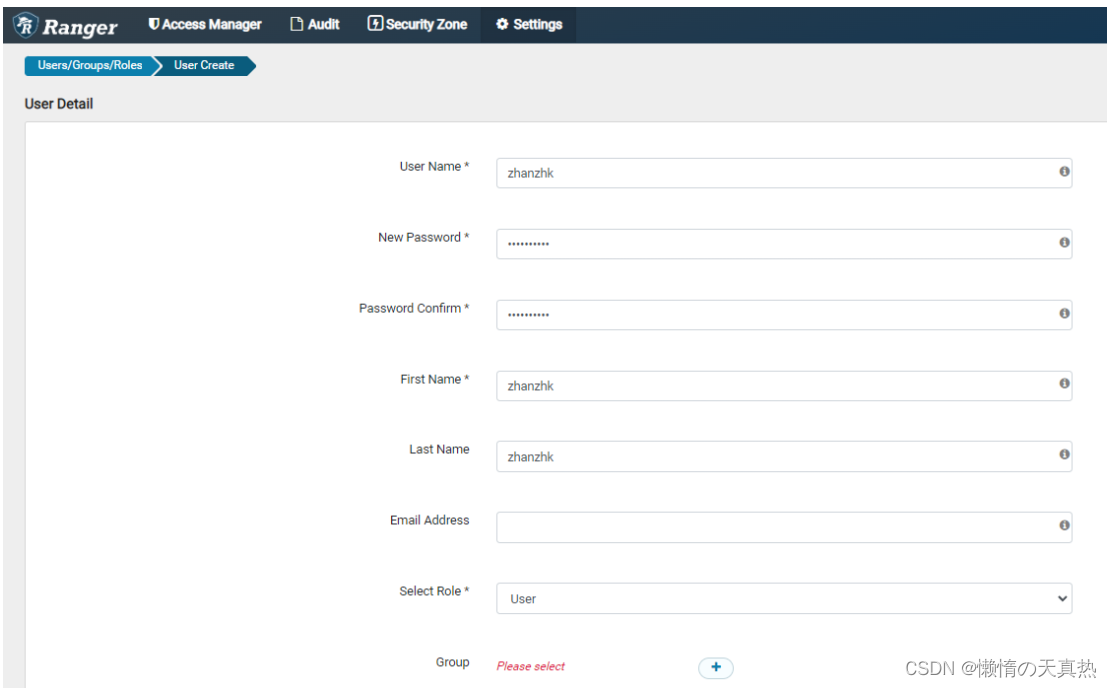
添加用户:有两种方式,但是无论哪种方式添加的用户,效果都一样,因为都只是用来给用户赋权,不用于其他功能。
1)使用同步方式,如ranger-usersync插件
2)手动创建。
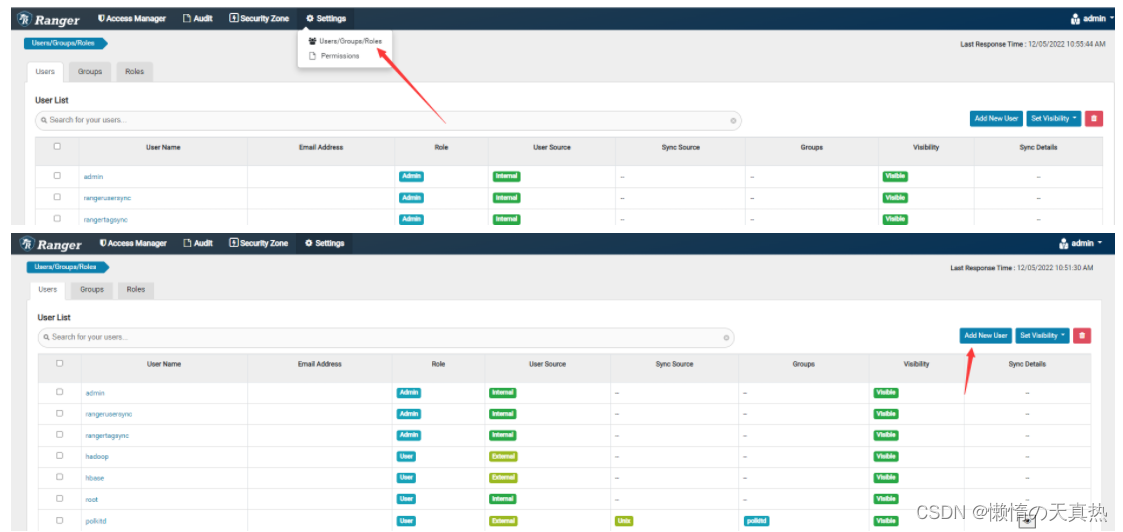
ps1:User Name、First Name、Last Name用户名称,取一样的即可
ps2:Select Role,用户权限,一般选择User
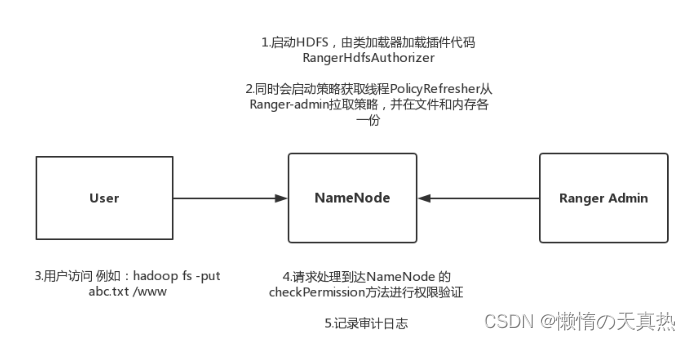
三、配置hdfs
-
原理
-
新增
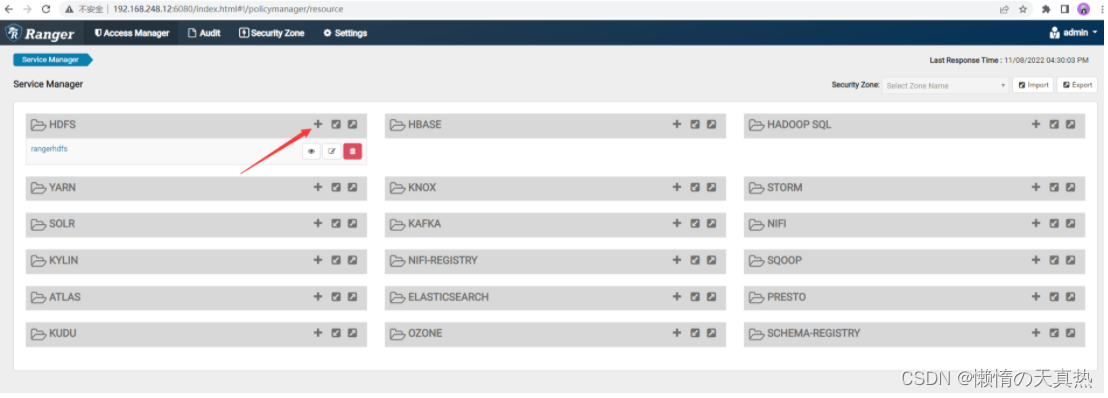
-
设置
ps1:Service Name,名称为/home/hadoop/RangerHive/ranger-2.2.0-hive-plugin/inistall.propreties的REPOSITORY_NAME属性
ps2:Username&Password,ranger-hdfs的最高权限用户
ps3:Namenode URL,/home/hadoop/module/hadoop-3.2.2/etc/hadoop/hdfs-site.xml的dfs.namenode.rpc-address.mycluster.nn1和nn2属性,用“,”隔开
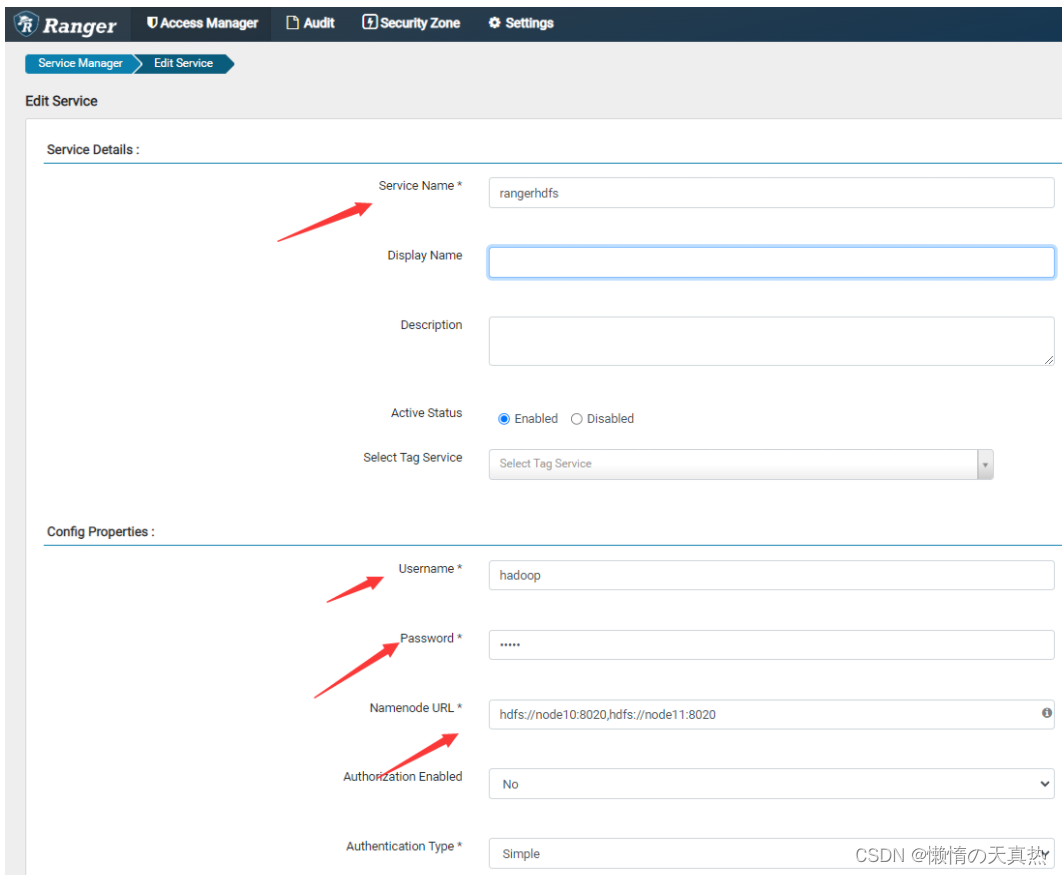
-
测试连接
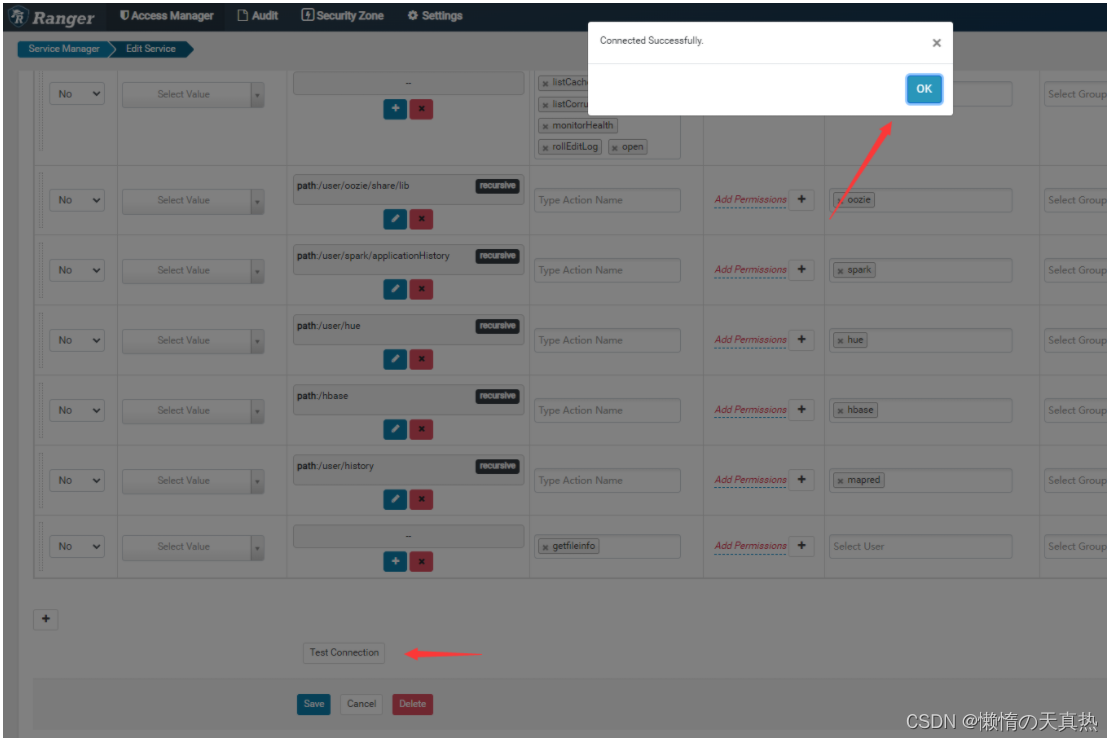
-
测试上传功能
-
使用hadoop用户创建文件夹:hdfs dfs -mkdir /ranger
-
使用hadoop用户上传:hdfs dfs -put test.txt /ranger
结果:上传成功
-
新建用户zhanzhk并且上传:hdfs dfs -put test.txt /ranger
结果:报错put: Permission denied: user=root, access=WRITE, inode=“/ranger”:hadoop:supergroup:drwxr-xr-x
-
重启ranger-usersync同步用户: ranger-usersync restart
只能同步ranger服务器的用户
-
配置zhanzhk这个用户的权限,然后add即可
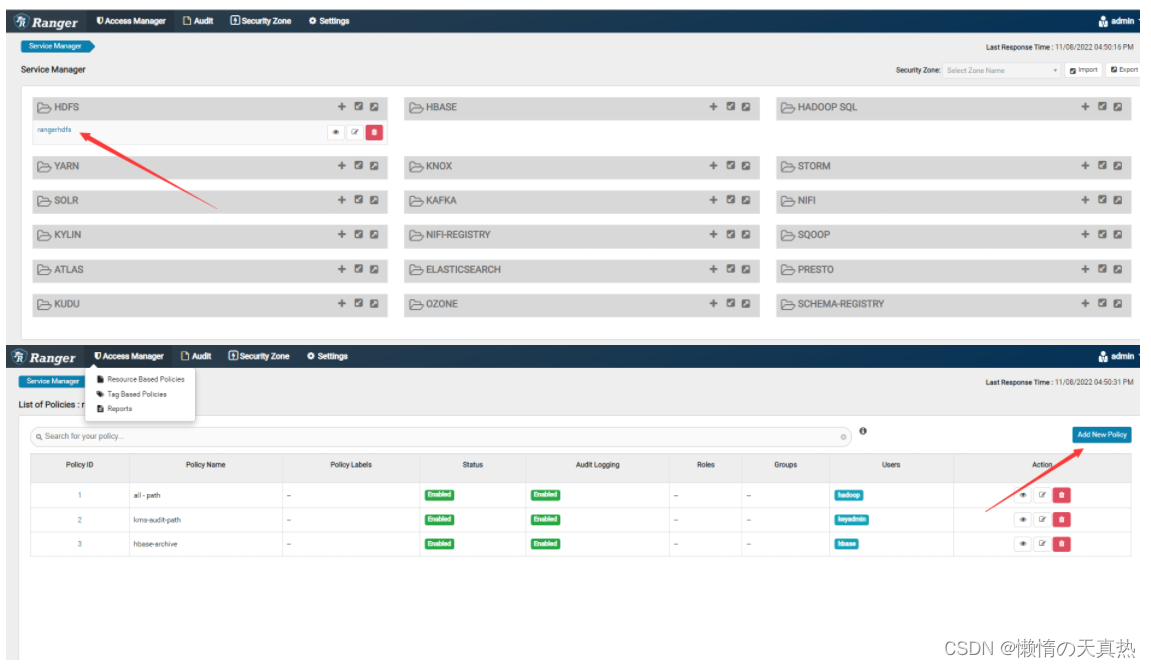
-
重新执行上传指令,成功!
-
策略是可以重复使用的,只要在权限里面配置不同用户即可,一般都会生产一些默认权限,如下
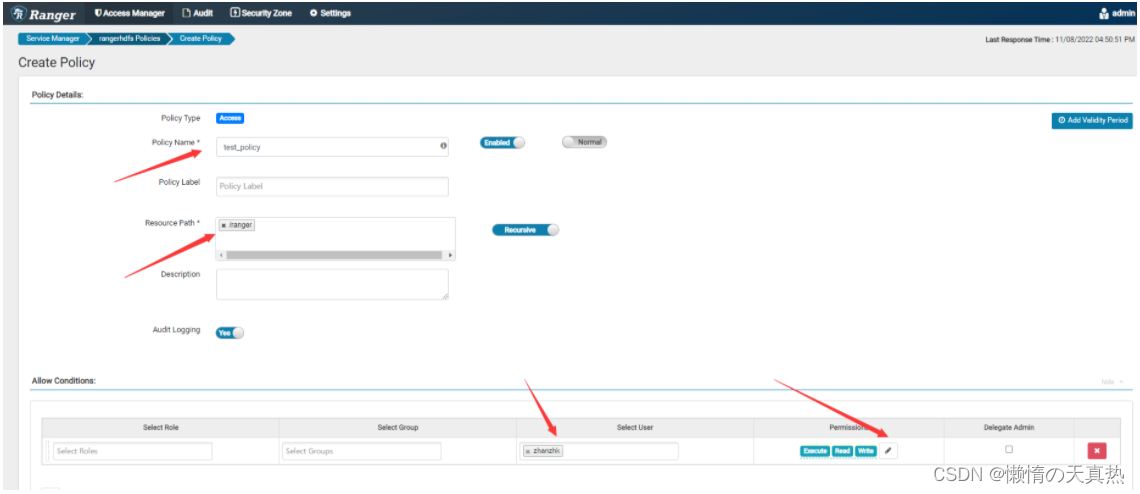
四、配置hive
-
原理
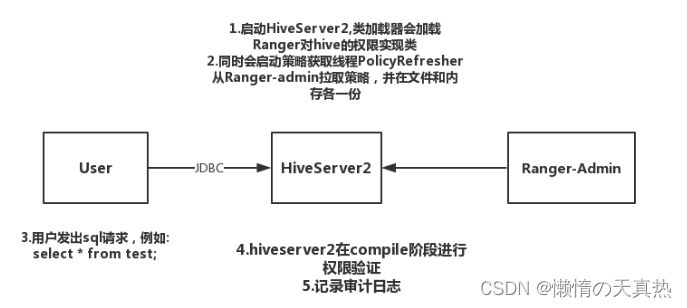
-
查看mysql相关权限
mysql -uroot -p use mysql; SELECT host,user,Grant_priv,Super_priv FROM mysql.user;
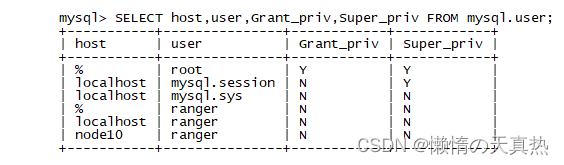
-
修改mysql相关权限
UPDATE mysql.user SET Grant_priv='Y', Super_priv='Y'; flush privileges; -
连接hive查看数据
cd /home/hadoop/module/hive bin/beeline -u jdbc:hive2://node10:10000/default -n root -p ffcsict123 select * from student;错误:Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [root] does not have [SELECT] privilege on [default/student/*] (state=42000,code=40000)
-
添加用户
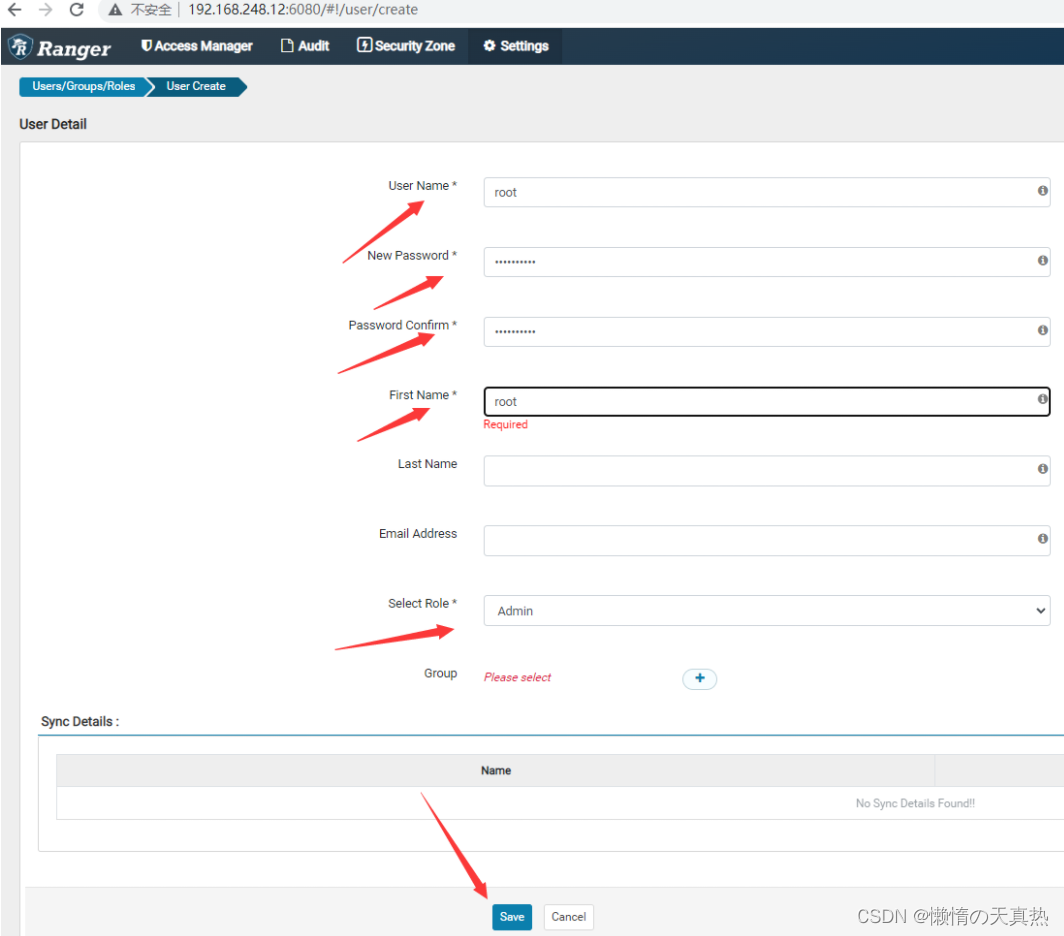
-
配置hive

配置基础信息

选中add,稍等一会,再点击编辑

点击测试
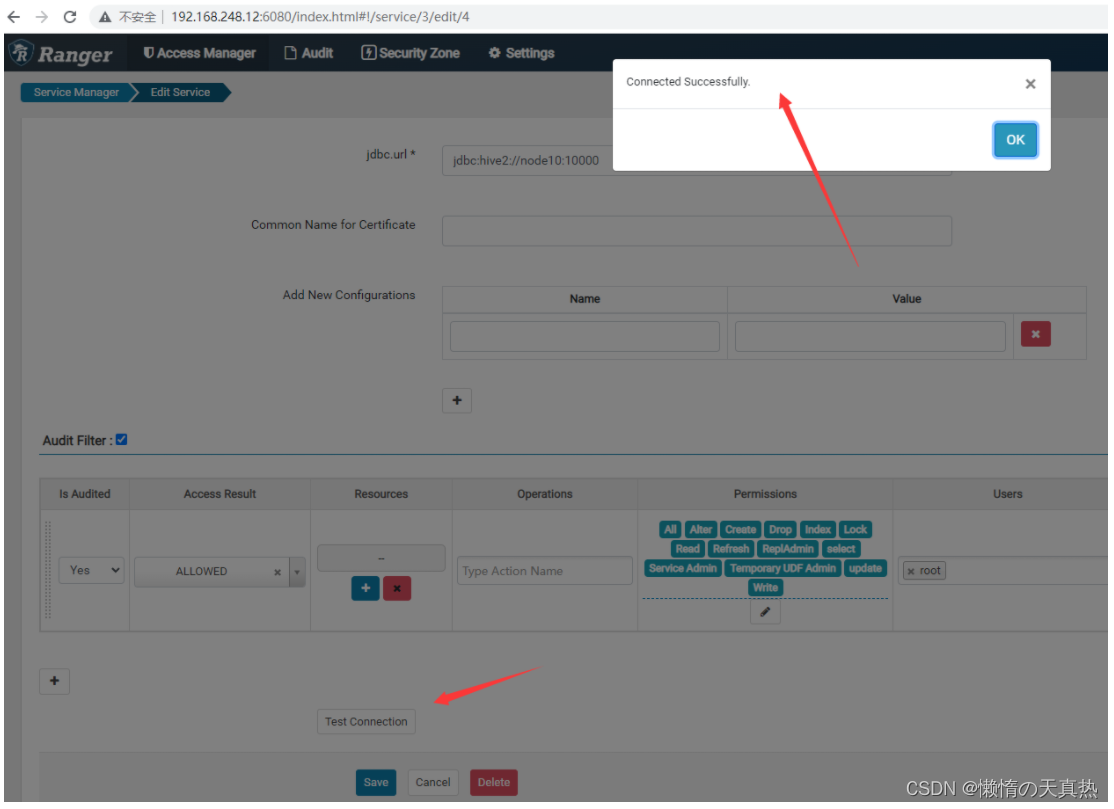
-
连接hive查看数据
cd /home/hadoop/module/hive bin/beeline -u jdbc:hive2://node10:10000/default -n root -p ffcsict123 select * from student;显示查询成功
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-K1psOpqh-1672657950955)(C:\Users\86188\AppData\Roaming\Typora\typora-user-images\image-20221109092827812.png)]](https://img-blog.csdnimg.cn/29fda101b2d042628bbedc76e39f6c52.png)
-
配置成功!
-
测试hadoop用户
cd /home/hadoop/module/hive bin/beeline -u jdbc:hive2://node10:10000/default -n hadoop -p ffcsict123 select * from student;结果:Error: Error while compiling statement: FAILED: HiveAccessControlException Permission denied: user [hadoop] does not have [SELECT] privilege on [default/student/*] (state=42000,code=40000)
-
配置hadoop用户的权限
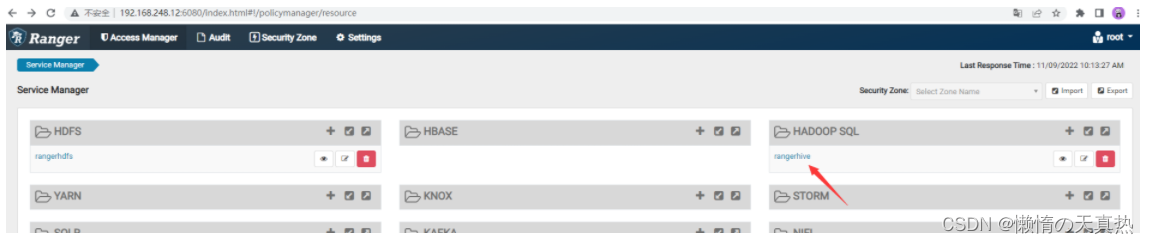
可以看到已经存在一些相关的权限配置策略,我们直接用即可

设置hadoop,添加读权限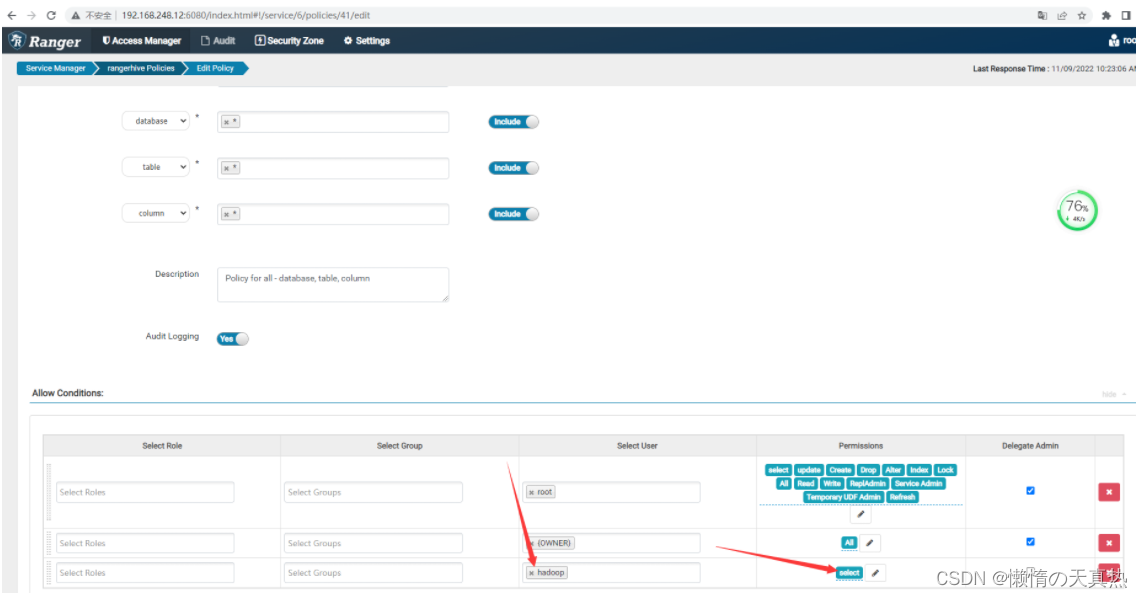
-
测试hadoop用户
cd /home/hadoop/module/hive bin/beeline -u jdbc:hive2://node10:10000/default -n hadoop -p ffcsict123 select * from student;
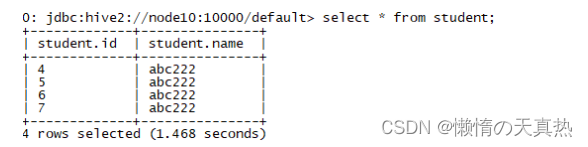
- 成功!!!
五、配置hbase
-
原理
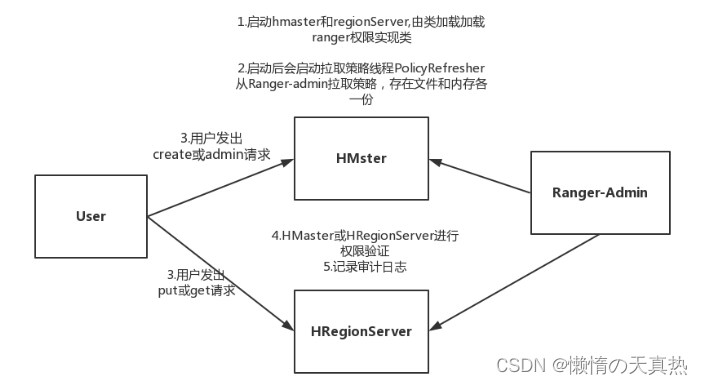
-
相关指令
cd /home/hadoop/hbase/hbase-2.1.0/bin 1. 启动客户端:./hbase shell 2. 建表:create 'B_STU','cf' 3. 插入数据:put 'B_STU','001','cf:age','20' 4. 覆盖数据:put 'B_STU','001','cf:age','18' 5. 查看表数据: scan 'B_STU' 6. 根据键查询数据:get 'B_STU','001' -
连接测试
cd /home/hadoop/hbase-2.3.5/bin 1. 启动客户端:./hbase shell 2. 建表:create 'B_STU','cf'报错:ERROR: org.apache.hadoop.hbase.security.AccessDeniedException: Insufficient permissions for user ‘hadoop’ (action=create)
-
在ranger界面新建hbase任务
新建一个
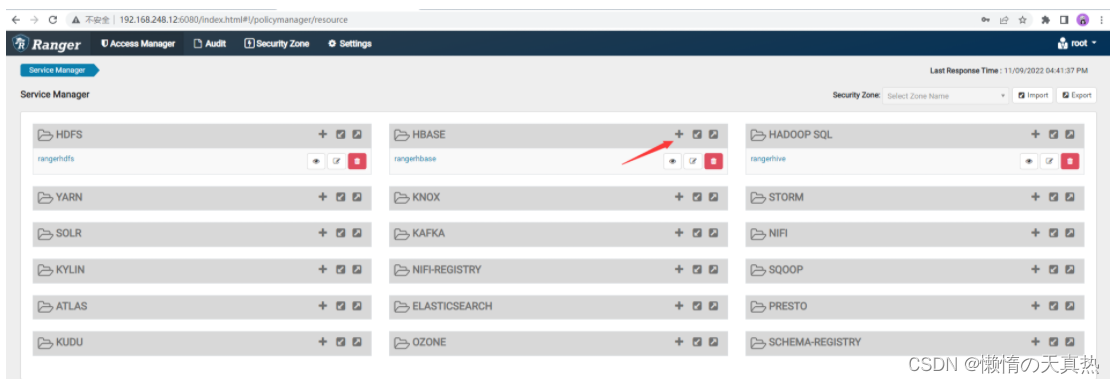
名称跟配置文件对应
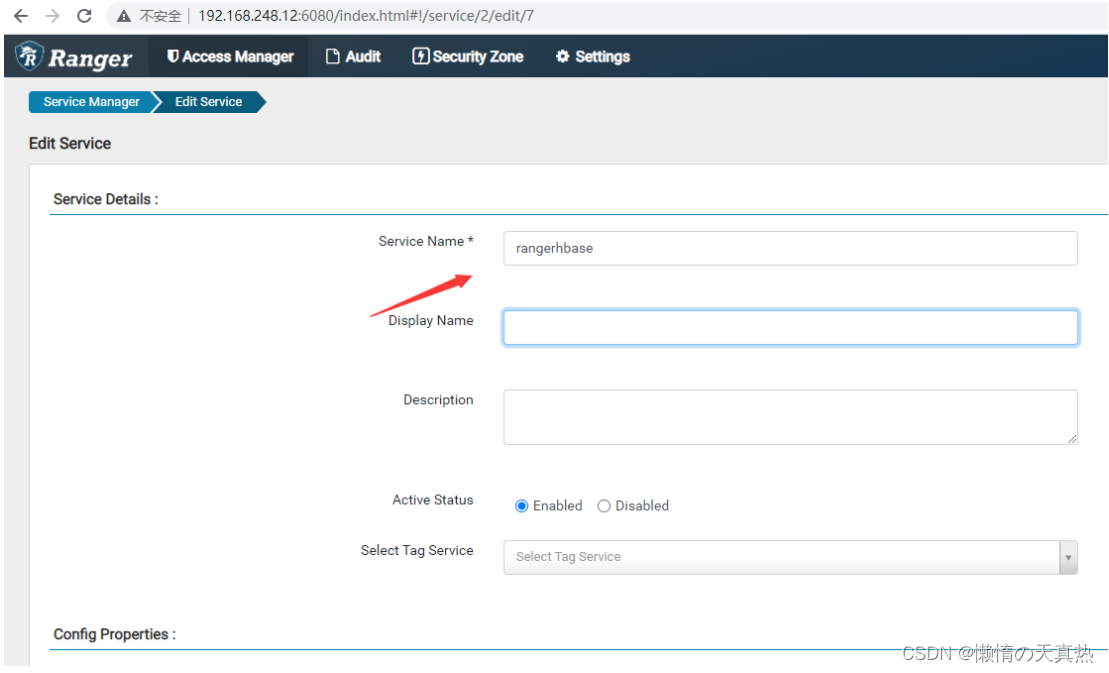
配置zk和用户
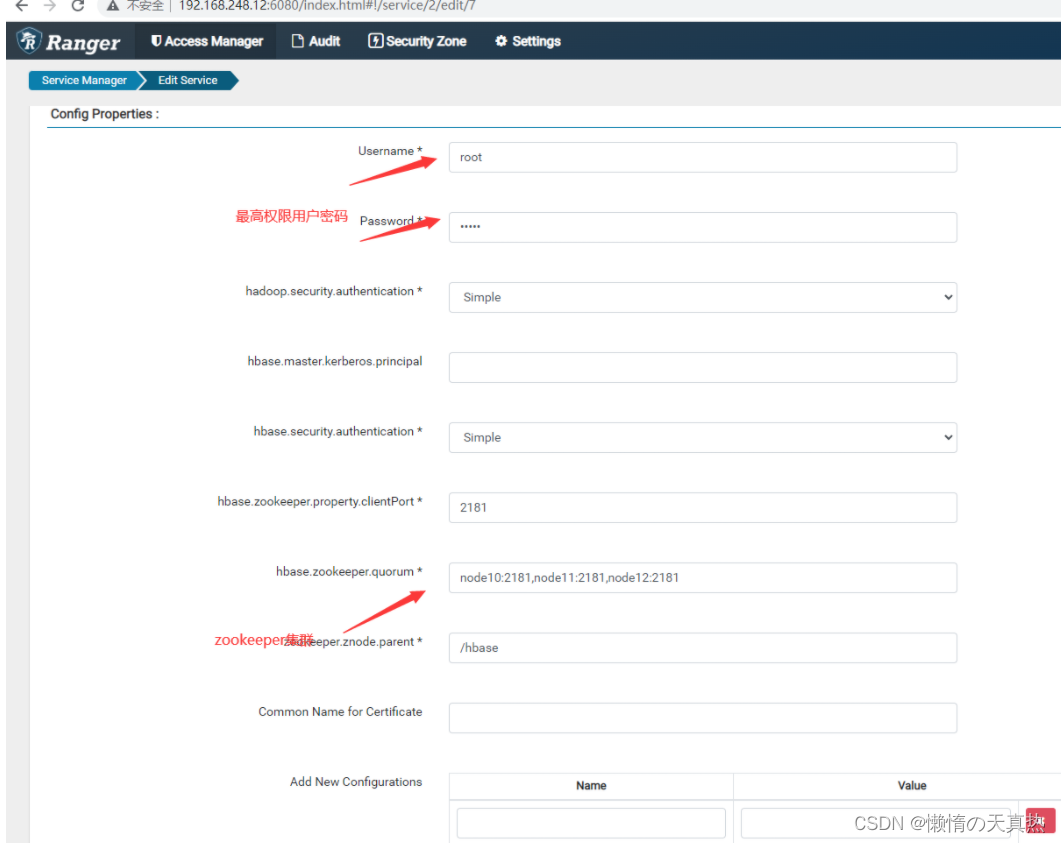
测试
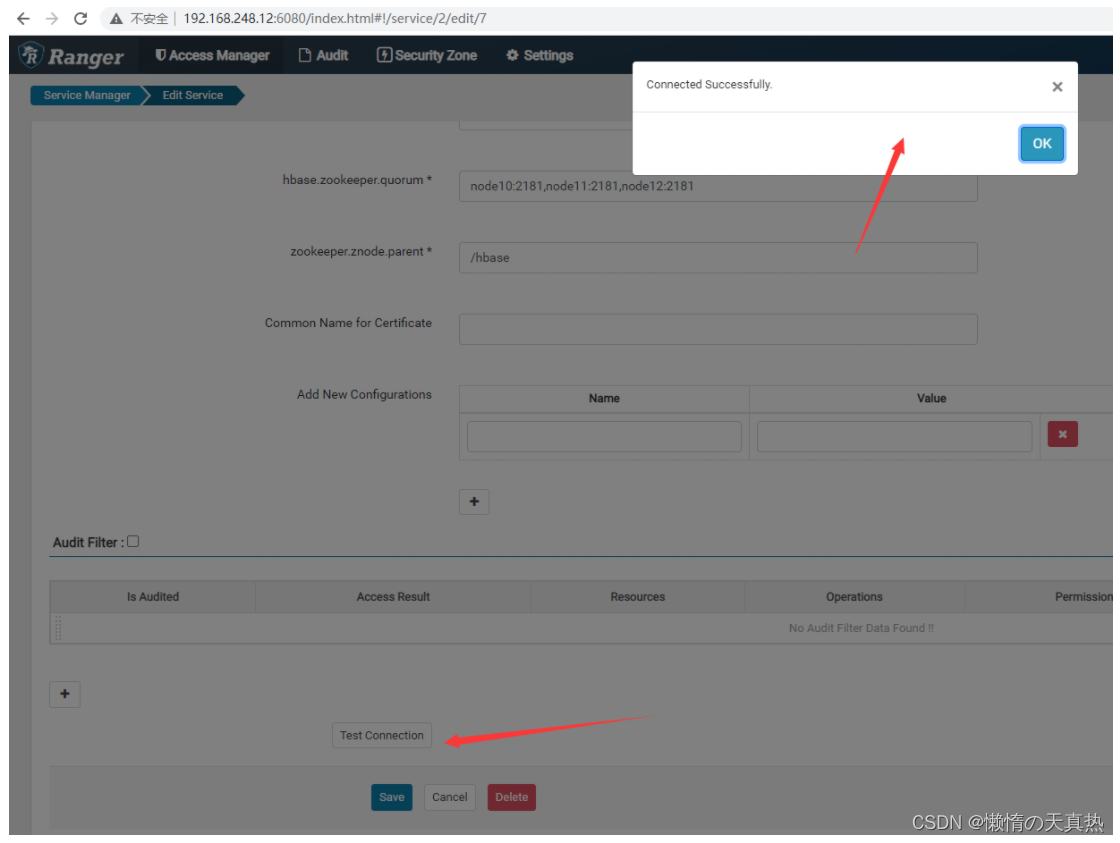
-
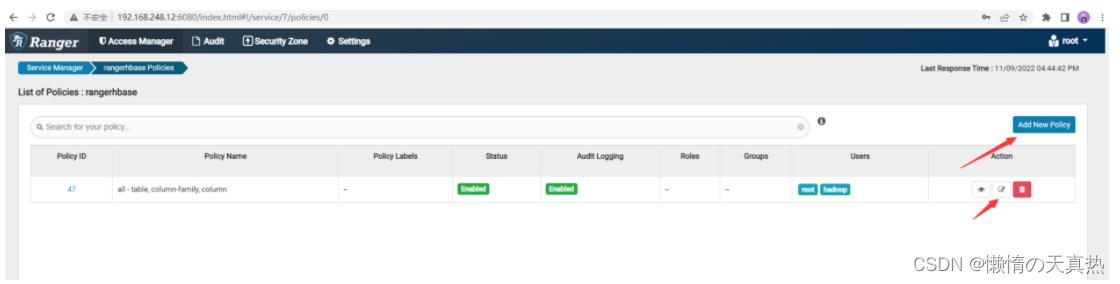
在ranger界面分配ranger权限

可以新建策略,也可以使用默认创建的最高权限策略,这里选择直接使用默认建好的
添加hadoop用户,保存即可
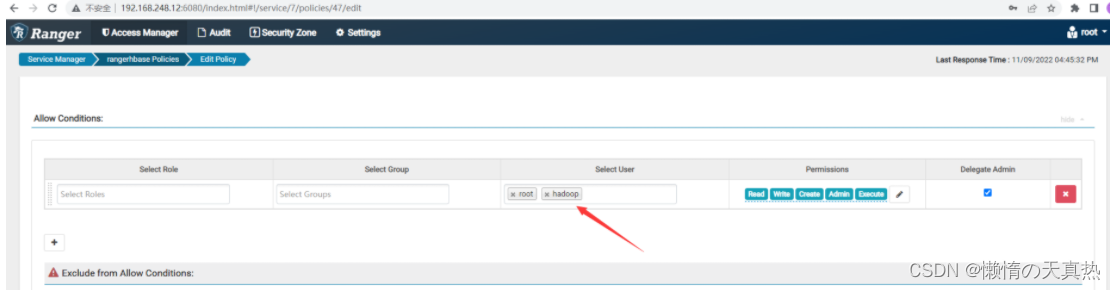
-
连接测试
cd /home/hadoop/hbase/hbase-2.3.5/bin 1. 启动客户端:./hbase shell 2. 建表:create 'B_STU','cf'成功!!!!!
六、配置yarn
-
原理
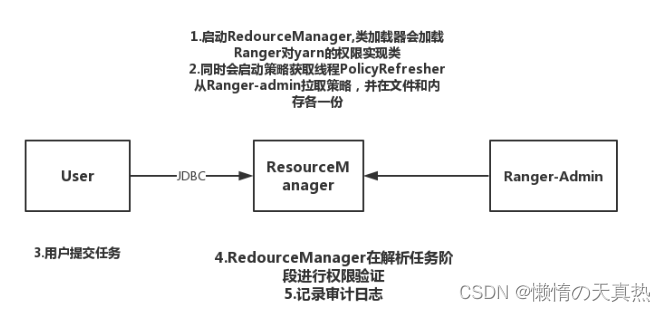
-
配置文件:vi /home/hadoop/module/hadoop-3.2.2/etc/hadoop/capacity-scheduler.xml,添加yarntest队列
<!-- 新增队列yarntest --> <property> <name>yarn.scheduler.capacity.root.queues</name> <value>default,yarntest</value> <description> The queues at the this level (root is the root queue). </description> </property> <!-- default队列资源占50 --> <property> <name>yarn.scheduler.capacity.root.default.capacity</name> <value>50</value> <description>Default queue target capacity.</description> </property> <!-- default队列资源不足时,最大抢占资源60% --> <property> <name>yarn.scheduler.capacity.root.default.maximum-capacity</name> <value>60</value> <description> The maximum capacity of the default queue. </description> </property><!-- yarntest队列资源占50 --> <property> <name>yarn.scheduler.capacity.root.yarntest.capacity</name> <value>50</value> </property> <!-- yarntest,最大抢占资源60% --> <property> <name>yarn.scheduler.capacity.root.yarntest.maximum-capacity</name> <value>60</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.user-limit-factor</name> <value>1</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.state</name> <value>RUNNING</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.acl_submit_applications</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.acl_administer_queue</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.acl_application_max_priority</name> <value>*</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.maximum-application-lifetime </name> <value>-1</value> </property> <property> <name>yarn.scheduler.capacity.root.yarntest.default-application-lifetime </name> <value>-1</value> </property> -
切换新建用户测试
hadoop jar /home/hadoop/module/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar pi -Dmapred.job.queue.name=default 2 2报错:org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.security.AccessControlException): Permission denied: user=zhanzhk, access=WRITE, inode=“/user”:root:supergroup:drwxr-xr-x
-
给zhanzhk用户添加“/user”文件夹的hdfs写权限,重新执行
hadoop jar /home/hadoop/module/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar pi -Dmapred.job.queue.name=yarntest 2 2报错:Caused by: org.apache.hadoop.security.AccessControlException: User zhanzhk does not have permission to submit application_1668046054877_0003 to queue yarntest
-
新建任务
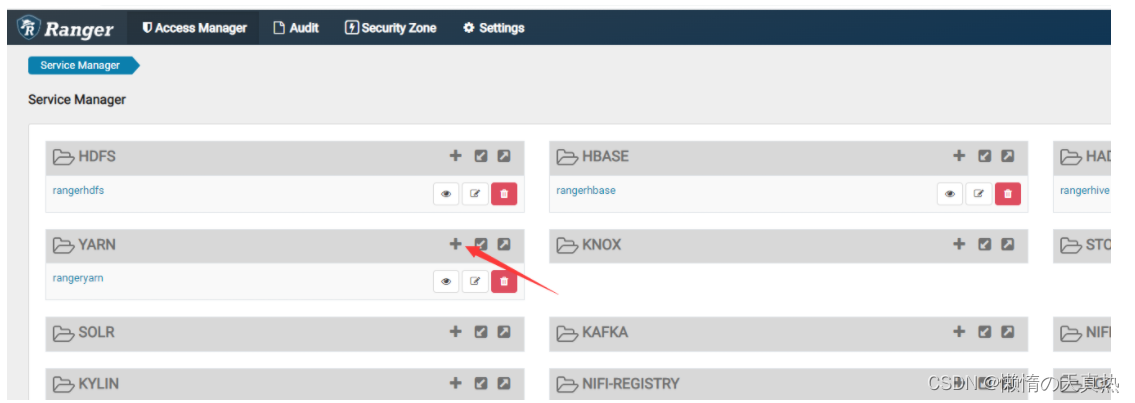
配置相关信息
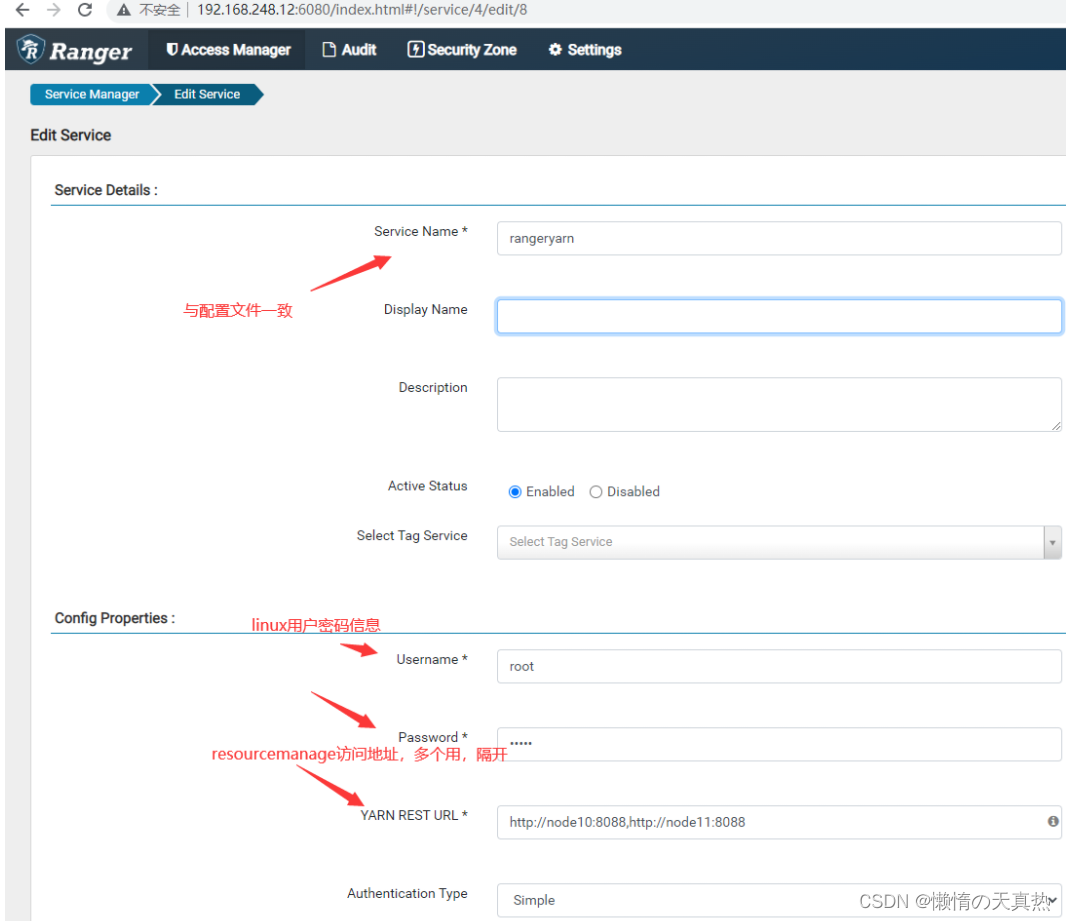
测试
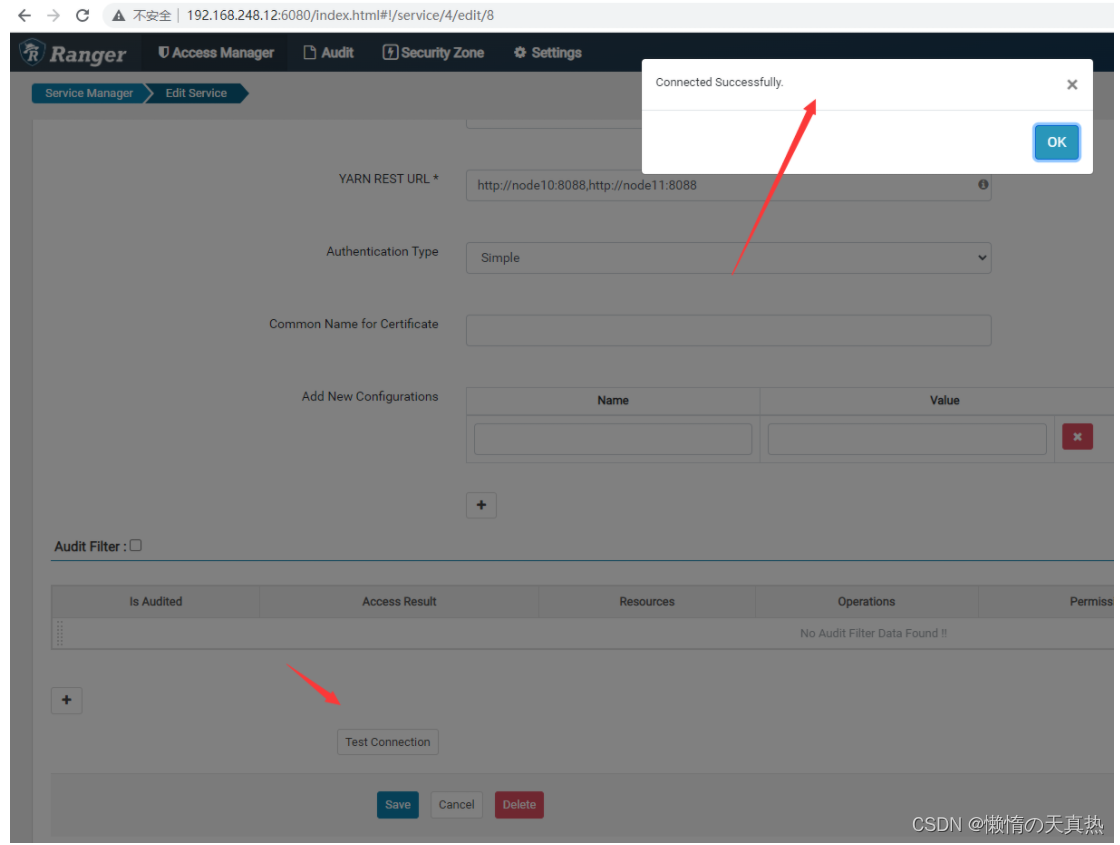
-
配置用户权限
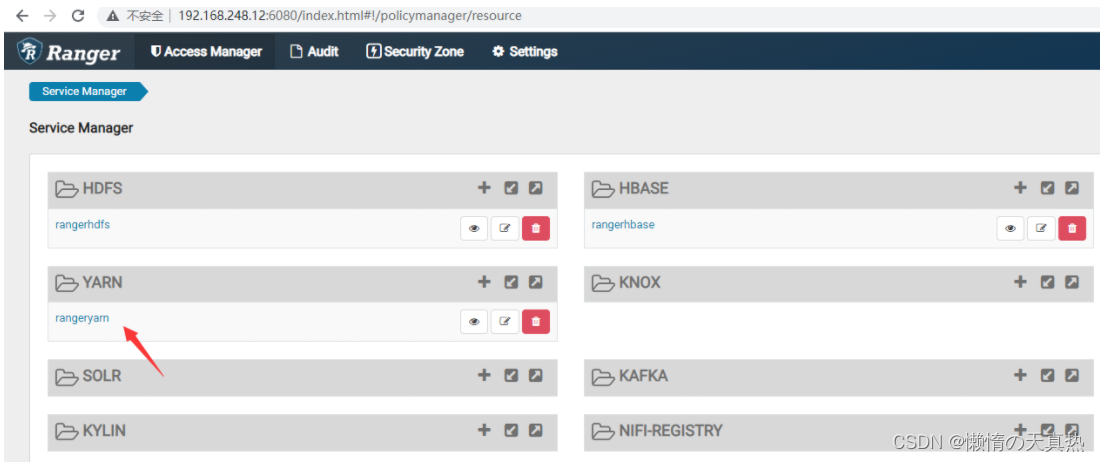
可新建策略,也可以使用默认生成的策略,这里直接使用默认的
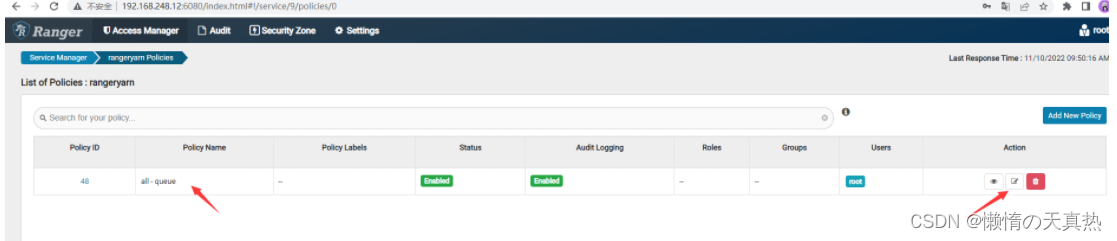
配置新增用户并且保存
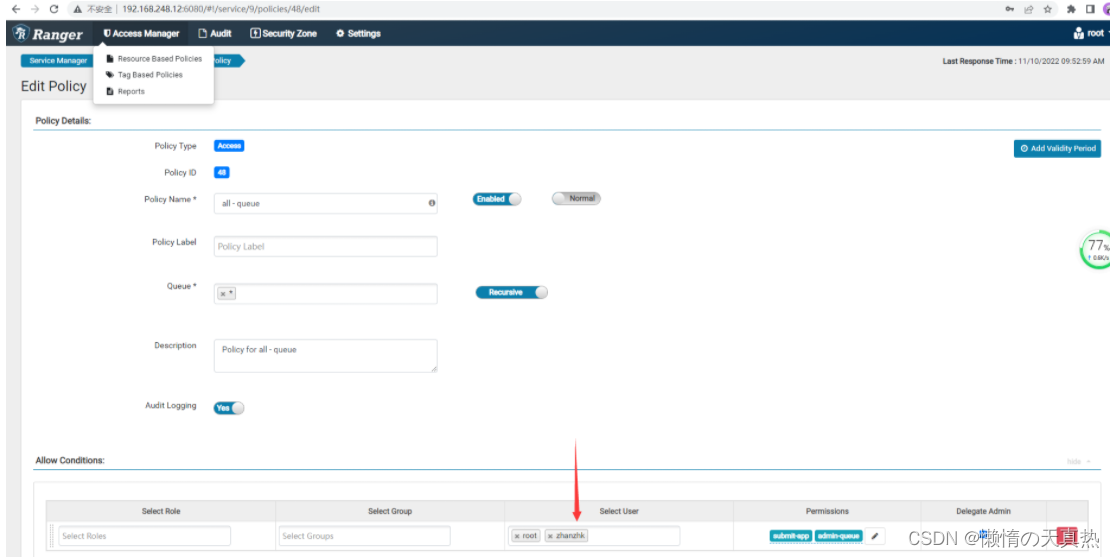
-
重新执行
hadoop jar /home/hadoop/module/hadoop-3.2.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.2.jar pi -Dmapred.job.queue.name=yarntest 2 2成功!!!
七、相关注意点
-
hdfs的权限是可以逐级赋权,即赋与二级目录权限,则一级目录无权限
-
hdfs根目录默认对所有的用户都开放操作权限,需要限制只对hadoop超级管理员开放:hdf dfs -chmod 700 /
-
用户如果想要放开权限,需要做以下操作及开启相关文件夹权限
---------------------------------------------hdfs操作----------------------------------------------------
1)开启需要访问的文件夹权限即可
---------------------------------------------yarn操作----------------------------------------------------
1)yarn队列赋权
2)hdfs-yarn临时文件创建与赋权:/tmp/hadoop-yarn/staging/用户名
3)日志临时文件创建与赋权:/tmp/logs/用户名
4)用户文件创建与赋权:/user/用户名
5)日志:/home/hadoop/module/hadoop-3.2.2/logs/用户名
6)历史:/tmp/hadoop-yarn/staging/history/done_intermediate/用户名
--------------------------------------------hive操作----------------------------------------------------
1)hive数据库权限配置
2)yarn队列权限配置
3)hdfs-hive数据库文件夹权限:/user/hive/warehouse/数据库名.db
4)hdfs-hive临时工作文件权限:/tmp/hive/用户名
--------------------------------------------hbase----------------------------------------------------
1)hbase数据库表权限配置
-
队列的名称,一定要加上“root.”
八、整合kerberos后的配置差别
-
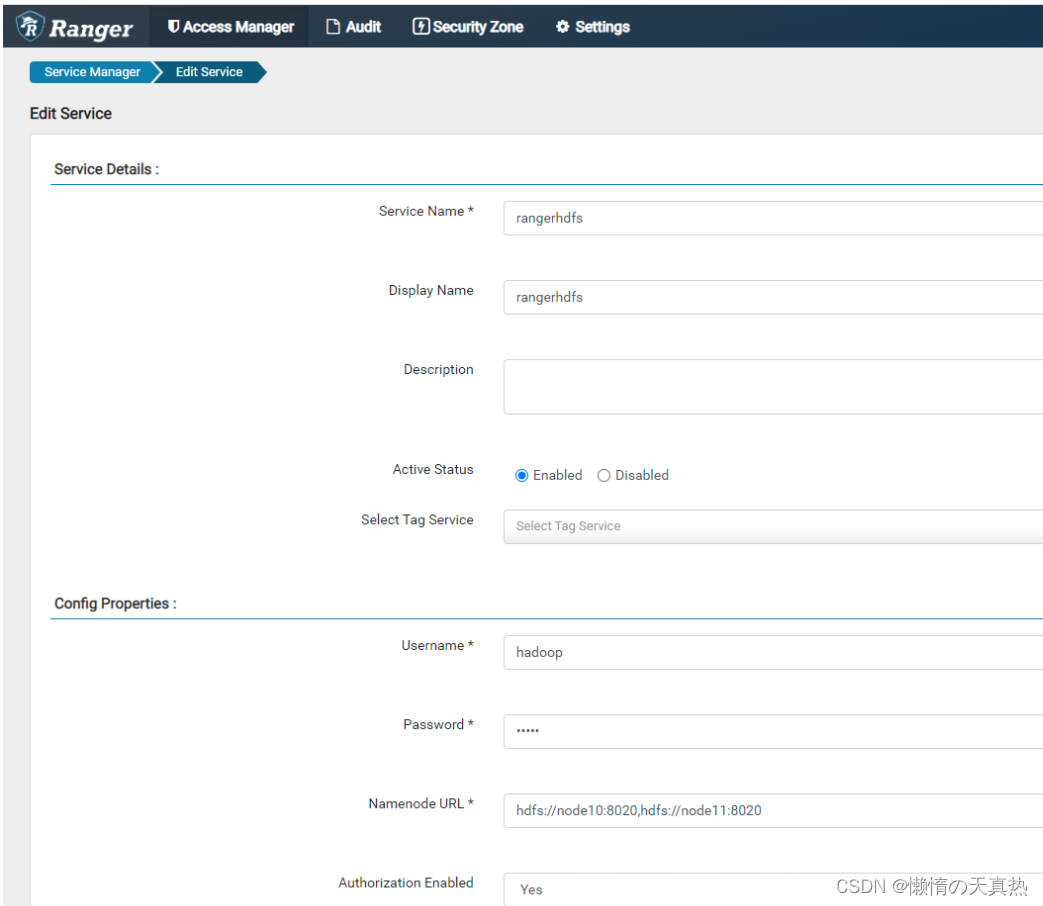
配置hdfs
ps1:Service Name,服务名称,取配置文件
ps2:Username&Password,ranger-hdfs的最高权限用户
ps3:Namenode URL,namenode节点访问地址,取配置文件
ps4:Authorization Enabled,开启权限控制
ps5:Authentication Type,权限控制类型,选择kerberos
ps6:hadoop.security.auth_to_local,默认DEFAULT
ps7:dfs.datanode.kerberos.principal,datanode的kerberos认证用户
ps8:dfs.namenode.kerberos.principal,namenode的kerberos认证用户
ps9:policy.download.auth.users,刷新策略的kerberos用户
ps10:dfs.journalnode.kerberos.principal,journalnode的kerberos认证用户

-
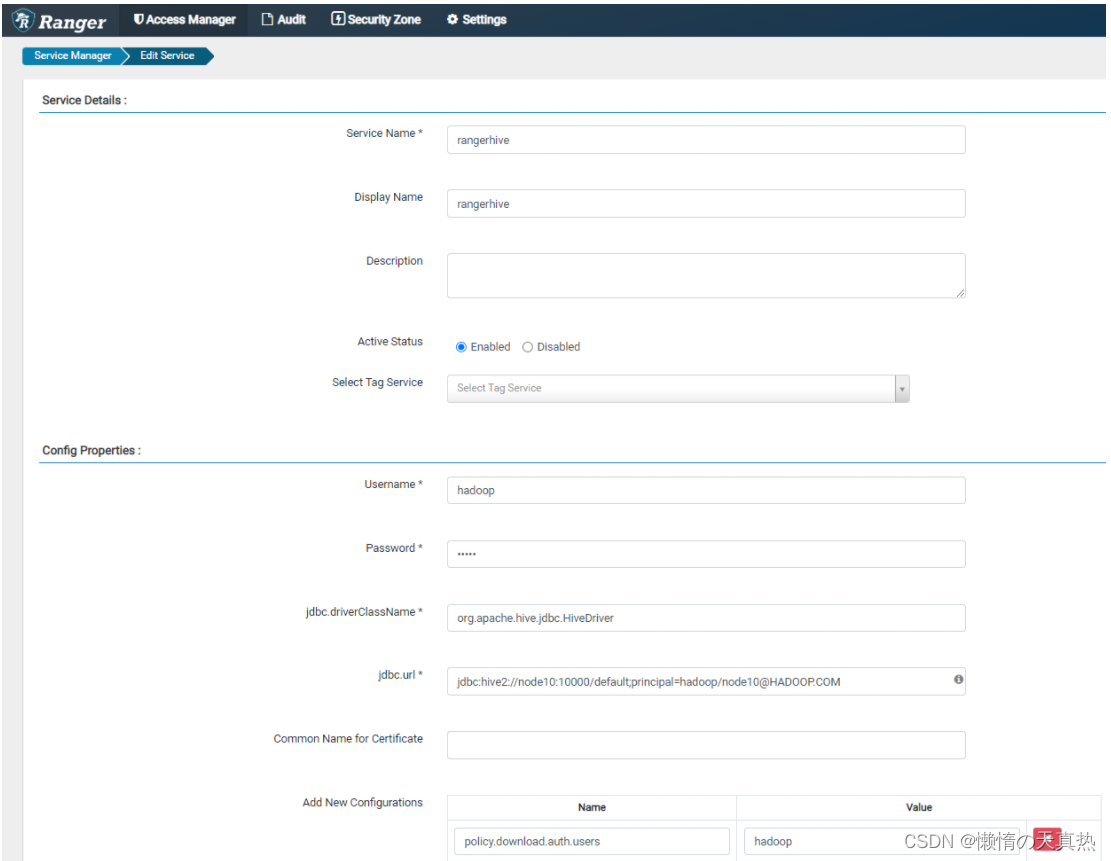
配置hive
ps1:Service Name,服务名称,取配置文件
ps2:Username&Password,ranger-hive的最高权限用户
ps3:jdbc.url,访问hive路径
ps4:policy.download.auth.users,刷新策略的kerberos用户
-
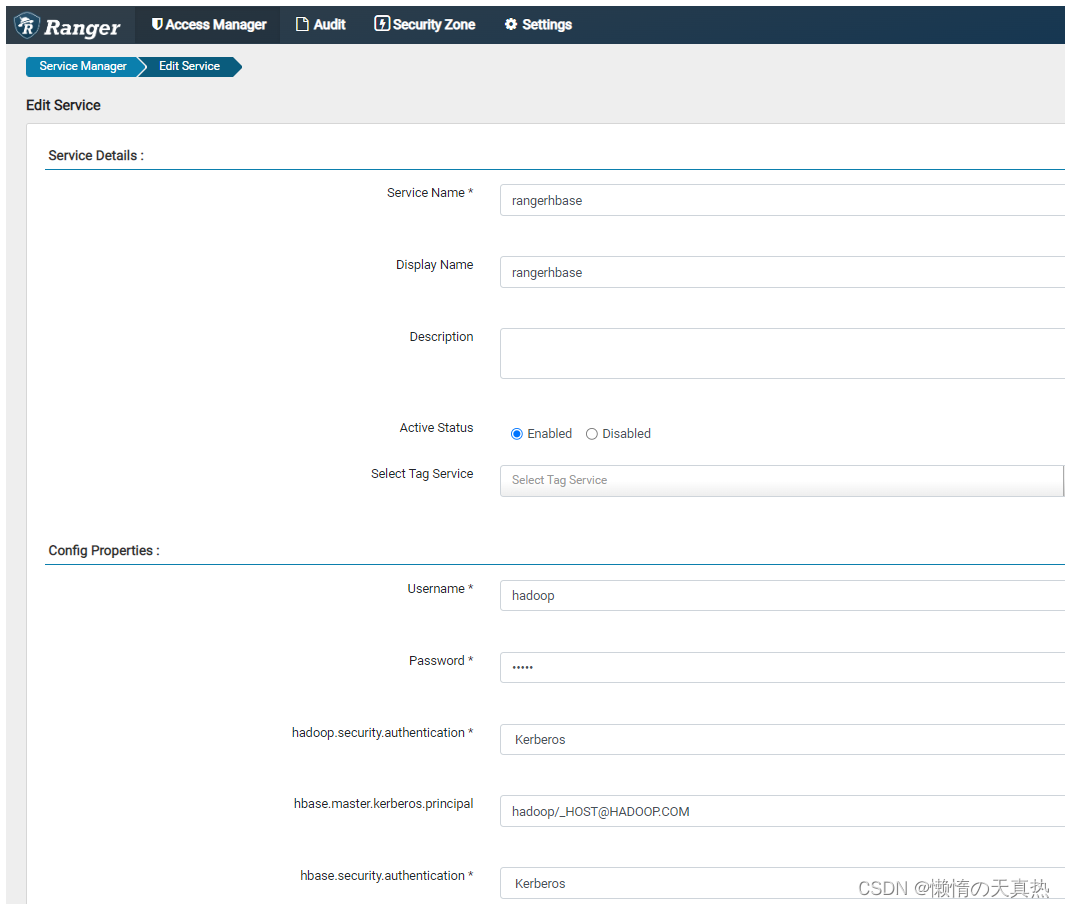
配置hbase
ps1:Service Name,服务名称,取配置文件
ps2:Username&Password,ranger-hbase的最高权限用户
ps3:hadoop.security.authentication,权限控制类型,选择kerberos
ps4:hbase.master.kerberos.principal,hbase的kerberos认证用户
ps5:hbase.security.authentication,权限控制类型,选择kerberos
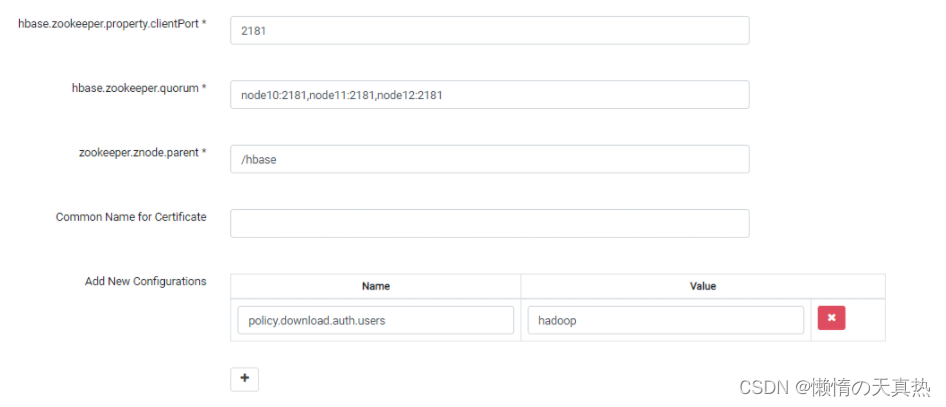
ps6:hbase.zookeeper.quorum ,zookeeper集群地址
ps7:policy.download.auth.users,刷新策略的kerberos用户
-
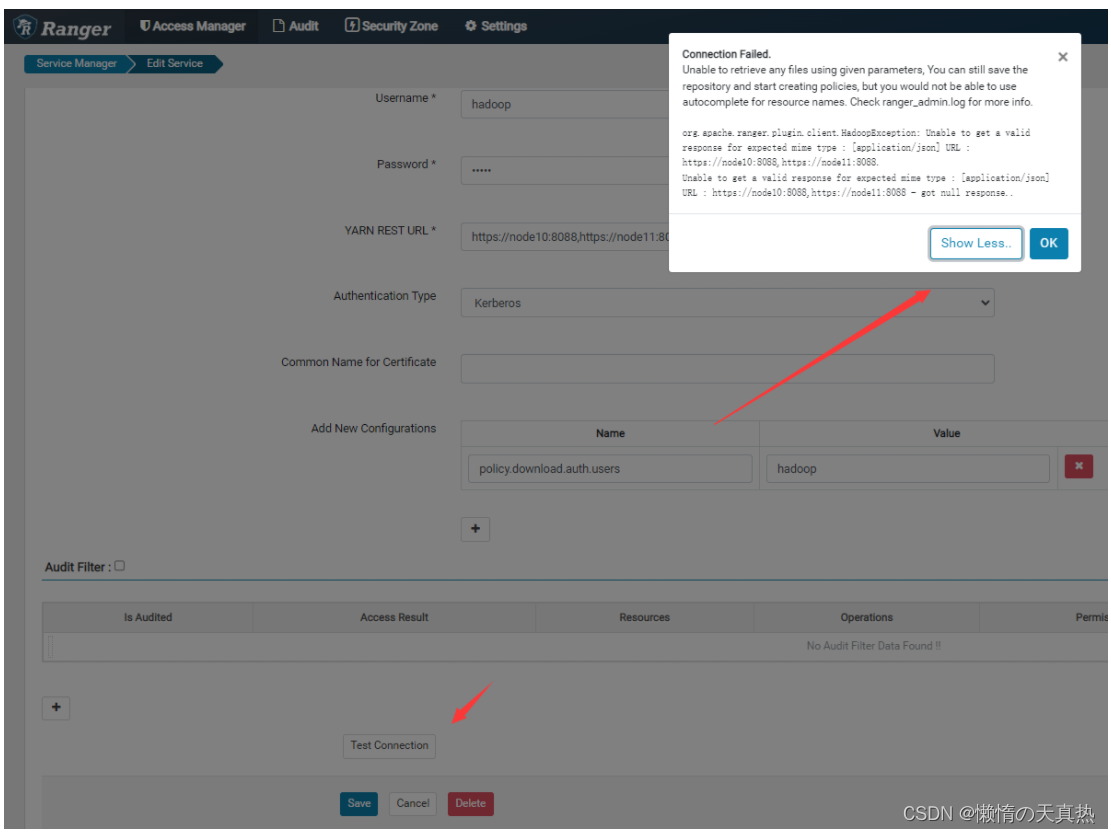
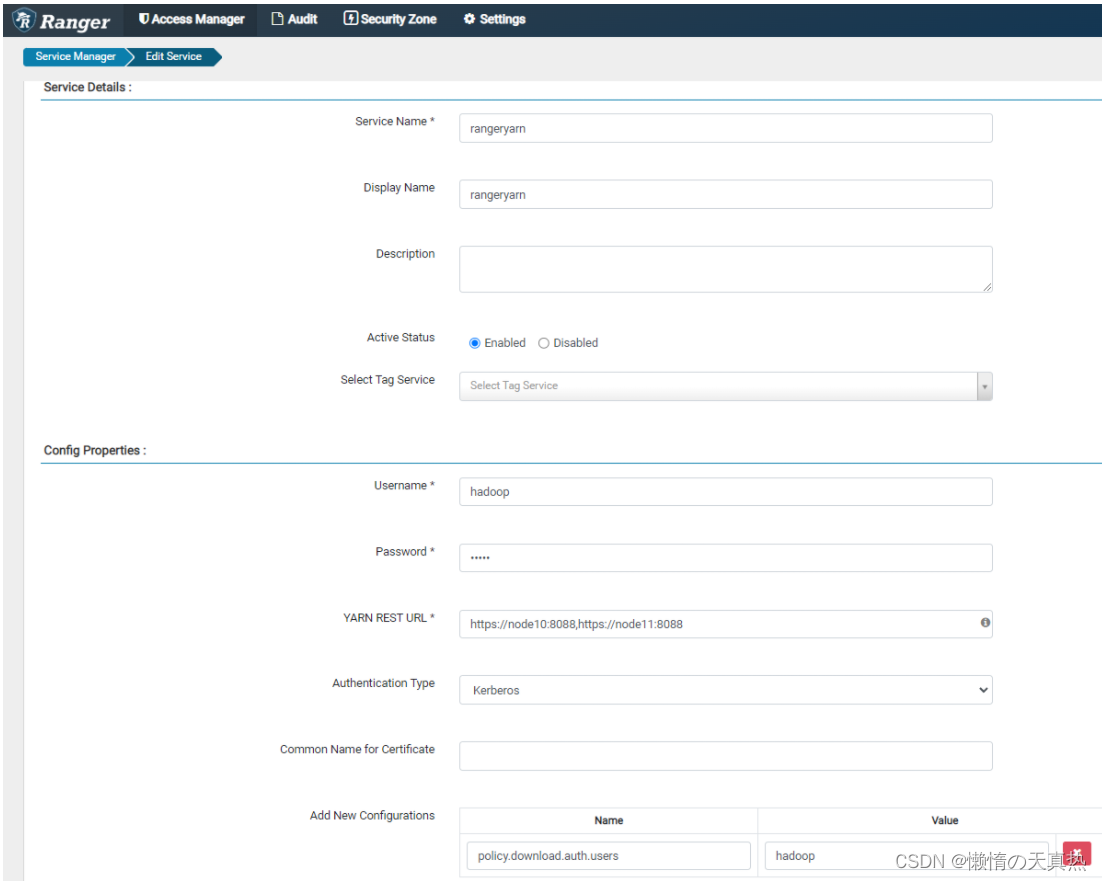
配置yarn
ps1:Service Name,服务名称,取配置文件
ps2:Username&Password,ranger-yarn的最高权限用户
ps3:YARN REST URL,yarn的访问地址
ps4:Authentication Type,权限控制类型,选择kerberos
ps5:policy.download.auth.users,刷新策略的kerberos用户
ps:可能版本原因导致连接测试失败,但是经过测试,kerberos+ranger监控yarn权限无异常,可以使用,仅测试连接失败,暂不解决这种情况。