系列文章目录
文章目录
- 系列文章目录
- 前言
- 零、环境搭建
- 一、下载CIFAR10数据集
- 二、测试图片
- 三、模型搭建
- 四、开始train
- 五、测试
- 六、tensorboard可视化
- 总结
前言
通过一个官方列子,清楚深度学习中图像的训练的整个流程
零、环境搭建
- pycharm下载:pycharm官网
- pycharm安装及使用教程【400MB左右】:PyCharm使用教程(详细版 - 图文结合)
- anaconda安装及使用教程【可以跳过】:最新Anaconda3的安装配置及使用教程(详细过程)
- 安装pytorch包:pytorch官网
如果电脑没有GPU,可以只用安装CPU版本的pytorch
conda install pytorch torchvision torchaudio cpuonly -c pytorch

6. 下载大佬的源代码【3MB左右】:deep-learning-for-image-processing
7. 大佬b站视频:pytorch官方demo(Lenet)
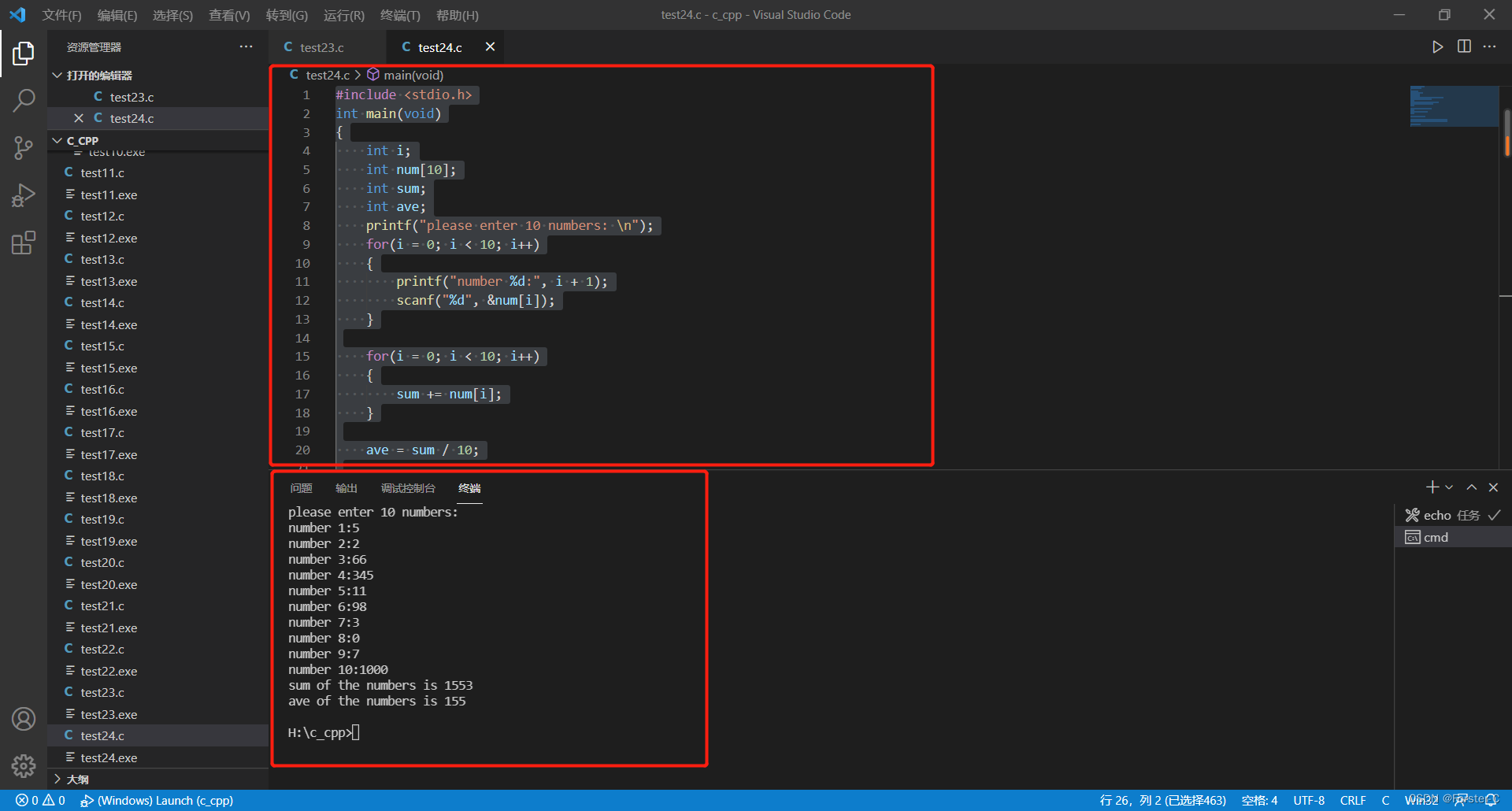
一、下载CIFAR10数据集
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-MTGvqaD8-1672647885101)(计算机视觉-图像处理结合深度学习.assets/image-20230101223814211.png)]](https://img-blog.csdnimg.cn/05cfc083c56a40efb22b7d6720453fb5.png)
在代码download处改为:True,其余代码先注释掉。
#下载数据集
#下载数据集
import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
def main():
transform = transforms.Compose(
[transforms.ToTensor(), #将图片转换为tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#标准化
#torchvision.datasets. 下载数据集
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
# root表示将数据集下载到什么地方 train = True表示导入训练数据集
# transform = transform 对数据进行预处理
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=True, transform=transform)#transform是对函数预处理的函数
#torchvision.datasets.可以查看数据集
if __name__ == '__main__':
main()
下载成功

二、测试图片

import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
#
#
def main():
transform = transforms.Compose(
[transforms.ToTensor(), #将图片转换为tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#标准化
#torchvision.datasets. 下载数据集
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
# root表示将数据集下载到什么地方 train = True表示导入训练数据集
# transform = transform 对数据进行预处理
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)#transform是对函数预处理的函数
#torchvision.datasets.可以查看数据集
# #导入训练集
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36, #导入训练集 shuffle = True 表示打乱数据集
shuffle=True, num_workers=0) #num_workers表示线程数 windows下只能设置为0,否则会报错
#导入测试集 10000张图片
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=4, #batch_size改成4,10000张图片看不了
shuffle=False, num_workers=0)#num_workers=0线程个数,windows下只能为0
test_data_iter = iter(testloader) #转换迭代器
test_image, test_label = test_data_iter.next() #通过.next()获得图片和标签值
#类别,元组类型 plane->0
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
#测试 需要numpy和plot包
def imshow(img):
img = img / 2 + 0.5 # unnormalize 对图像进行反标准化处理
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # h= w= channel=0
plt.show()
# print labels 打印标签
print(' '.join(f'{classes[test_label[j]]:5s}' for j in range(4)))
# show images 查看图片
imshow(torchvision.utils.make_grid(test_image))
if __name__ == '__main__':
main()
三、模型搭建

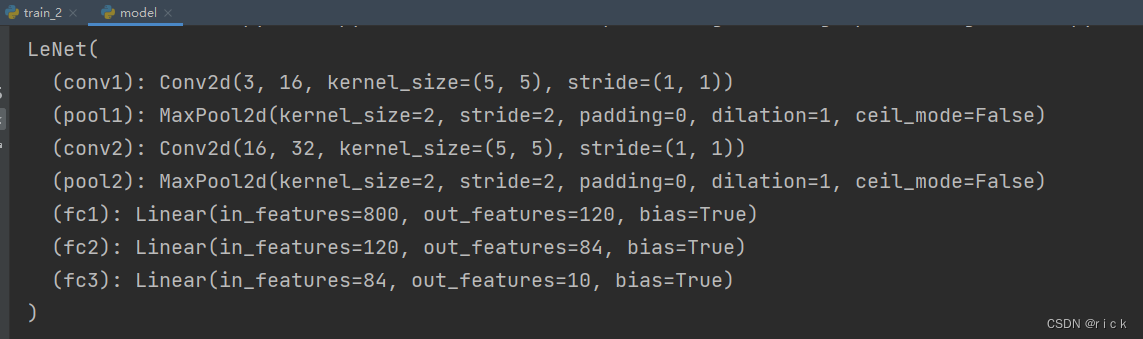
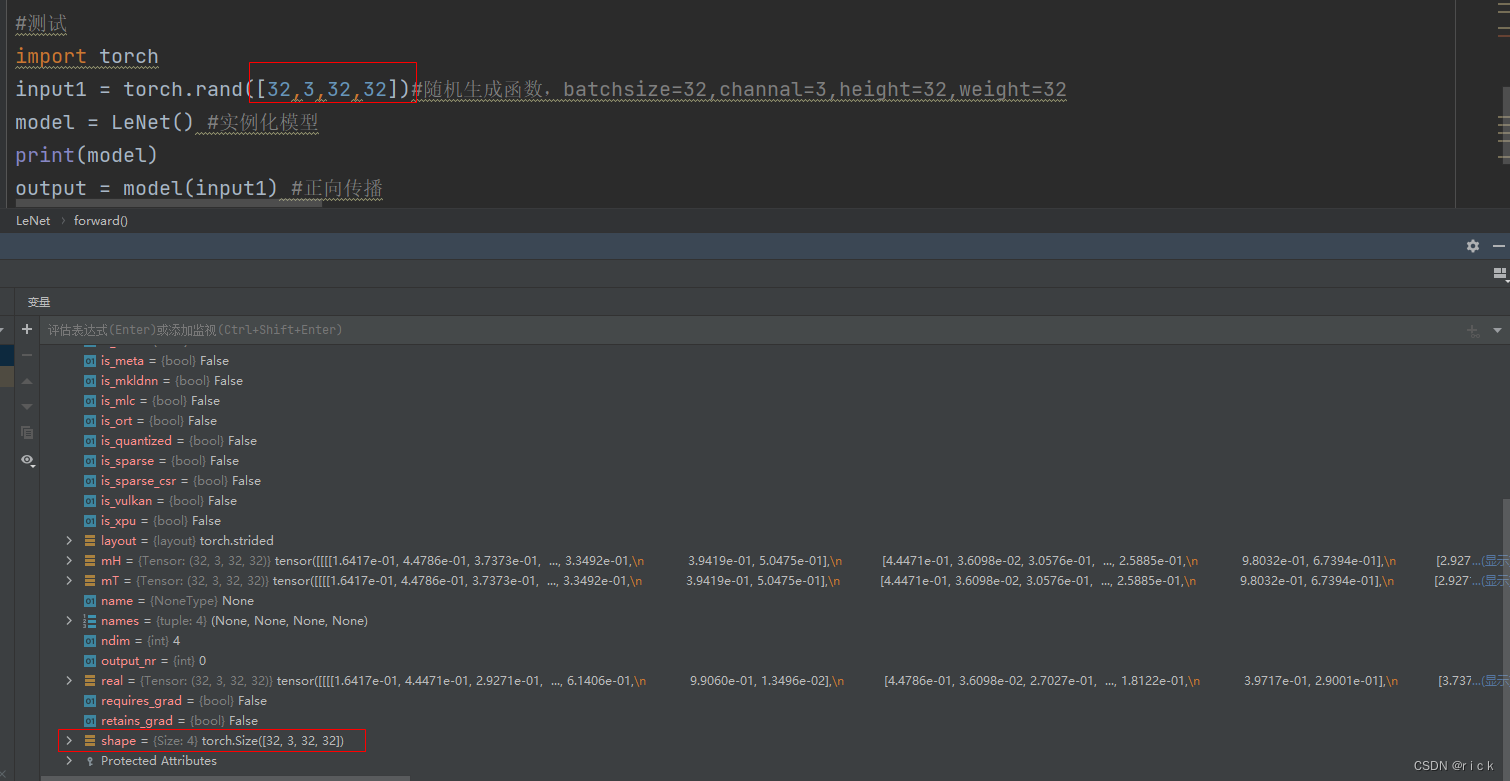
单步测试查看尺寸变化
import torch.nn as nn
import torch.nn.functional as F
class LeNet(nn.Module): #类Lenet继承nn.Module父类
def __init__(self):
super(LeNet, self).__init__() #super函数解决多继承可能遇到的问题
self.conv1 = nn.Conv2d(3, 16, 5) #定义第一个卷积层 3个通道(RGB),16个卷积核,5代表尺度,5x5的卷积核
self.pool1 = nn.MaxPool2d(2, 2) #定义池化层(下采样层),只改变图片的高和宽。池化核2x2,步距为2的最大池化操作
self.conv2 = nn.Conv2d(16, 32, 5) #定义第二个卷积层,深度为16,卷积核32,5x5的卷积核
self.pool2 = nn.MaxPool2d(2, 2) #定义第二个池化层
self.fc1 = nn.Linear(32*5*5, 120) #定义第一个全连接层,全连接层输入是一维向量,需要将特征矩阵展平
self.fc2 = nn.Linear(120, 84) #定义第二个全连接层,120为上一层的输出
self.fc3 = nn.Linear(84, 10) #定义第三个全连接层,84为上一层的输出 10根据super修改,这里是10个类别
def forward(self, x): #正向传播 x代表输入的数据
x = F.relu(self.conv1(x)) # input(3, 32, 32) 第一层输出 output(16, 28, 28)
x = self.pool1(x) # output(16, 14, 14) 通过最大池化后,高度和宽度降为原来的一半,深度不变16
x = F.relu(self.conv2(x)) # output(32, 10, 10) N = (W-F+2P)/S +1 => N=(14-5+2x0)/1 +1 = 10
x = self.pool2(x) # output(32, 5, 5) 通过第二个池化层,高度和宽度降为原来的一半
x = x.view(-1, 32*5*5) # output(32*5*5) 将全连接层拼接,变成一维向量,-1表示第一个维度,展平后的个数:32*5*5
x = F.relu(self.fc1(x)) # output(120)
x = F.relu(self.fc2(x)) # output(84)
x = self.fc3(x) # output(10)
return x
#测试
# import torch
# input1 = torch.rand([32,3,32,32])
# model = LeNet()
# print(model)
# output = model(input1)
四、开始train

第一个500步,训练损失率时1.747,测试准确率时0.436
迭代5个epoch后,测试准确率达到:0.652
最后生成模型权重文件:Lenet.pth文件

import torch
import torchvision
import torch.nn as nn
from model import LeNet
import torch.optim as optim
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
def main():
transform = transforms.Compose(
[transforms.ToTensor(), #将图片转换为tensor
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#标准化
#torchvision.datasets. 下载数据集
# 50000张训练图片
# 第一次使用时要将download设置为True才会自动去下载数据集
# root表示将数据集下载到什么地方 train = True表示导入训练数据集
# transform = transform 对数据进行预处理
train_set = torchvision.datasets.CIFAR10(root='./data', train=True,
download=False, transform=transform)
#导入训练集
train_loader = torch.utils.data.DataLoader(train_set, batch_size=36, #导入训练集 shuffle = True 表示打乱数据集
shuffle=True, num_workers=0)
#导入测试集
# 10000张验证图片
# 第一次使用时要将download设置为True才会自动去下载数据集
# val_set = torchvision.datasets.CIFAR10(root='./data', train=True,
# download=False, transform=transform)
# val_loader = torch.utils.data.DataLoader(val_set, batch_size=10000,
# shuffle=False, num_workers=0)
# val_data_iter = iter(val_loader)
# val_image, val_label = val_data_iter.next()
testset = torchvision.datasets.CIFAR10(root='./data', train=False,
download=False, transform=transform)
testloader = torch.utils.data.DataLoader(testset, batch_size=10000,
shuffle=False, num_workers=0)#num_workers=0线程个数,windows下只能为0
test_data_iter = iter(testloader)
test_image, test_label = test_data_iter.next() #通过.next()获得图片和标签值
#类别,元组类型 plane->0
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet() #实例化模型
loss_function = nn.CrossEntropyLoss() #定义损失函数
optimizer = optim.Adam(net.parameters(), lr=0.001)#使用Adam优化器 导入参数量,lr是学习率
#训练过程
for epoch in range(5): # loop over the dataset multiple times 训练迭代多少轮 迭代5次
running_loss = 0.0 #记录累积的训练损失
for step, data in enumerate(train_loader, start=0): #遍历训练集样本
# get the inputs; data is a list of [inputs, labels]
inputs, labels = data #输入图像和标签
# zero the parameter gradients 清除历史损失梯度 如果不清除历史梯度,就会对计算的历史梯度进行累加
#一般batchsize越大,训练效果越好,但由于设备硬件原因,batchsize可能不会太大,通过下面这个函数解决
optimizer.zero_grad()
# forward + backward + optimize
outputs = net(inputs) #将输入图片传入到网络中
loss = loss_function(outputs, labels) #计算损失 outputs是网络预测的值,labels是输入图片对应的标签
loss.backward() #将loss进行反向传播
optimizer.step() #参数更新
# print statistics 打印输出
running_loss += loss.item() #累加损失
if step % 500 == 499: # print every 500 mini-batches 每隔500步打印信息
with torch.no_grad(): #with是一个上下文管理器,这个函数在验证和测试阶段有用
outputs = net(test_image) # [batch, 10] 进行正向传播
predict_y = torch.max(outputs, dim=1)[1] #得到预测最大值的标签类别 需要在第一个维度去寻找,只需要找到index
accuracy = (predict_y==test_label).sum().item() /test_label.size(0) #将预测标签与真实标签比较 ,前面得到的是tensor数据,需要使用.item()进行数据转换
#除以测试样本的数量,除以测试样本的数量,就得到准确率
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))#迭代到多少轮,多少轮的哪一步,每500步统计平均误差
running_loss = 0.0
print('Finished Training')
#保存模型
save_path = './Lenet.pth'
torch.save(net.state_dict(), save_path)#保存网络中的所有参数
if __name__ == '__main__':
main()
五、测试
测试得到的结果准确
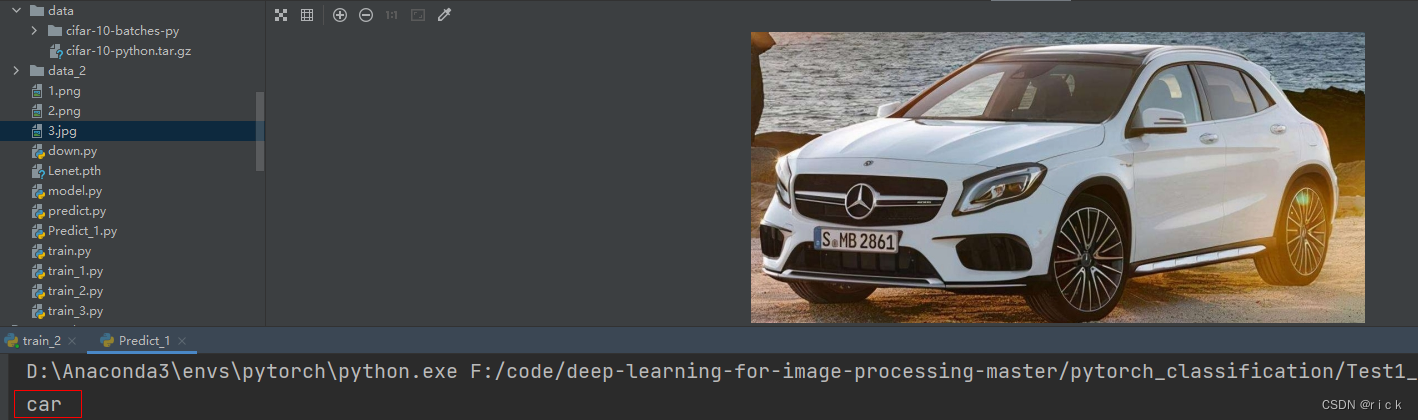
#train.py
import torch
import torchvision.transforms as transforms
from PIL import Image
from model import LeNet
def main():
transform = transforms.Compose(
[transforms.Resize((32, 32)),#缩放:将任意大小图片转换为规定的格式:32x32
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])#标准化处理
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
net = LeNet() #实例化
net.load_state_dict(torch.load('Lenet.pth')) #载入权重文件
im = Image.open('3.jpg') #载入图像 高度,宽度,channal
im = transform(im) # [C, H, W] 预处理 深度 高度 宽度
im = torch.unsqueeze(im, dim=0) # [N, C, H, W] 增加一个维度
with torch.no_grad():
outputs = net(im)#将图像传入到网络中
predict = torch.max(outputs, dim=1)[1].data.numpy()#找到预测最大值的index(索引)第0个维度是batchsize,第1个维度才是channal
print(classes[int(predict)])
if __name__ == '__main__':
main()
六、tensorboard可视化
参考:(傻瓜教程)TensorBoard可视化工具简单教程及讲解(TensorFlow与Pytorch)
- TensorBoard是一个可视化工具,它可以用来展示网络图、张量的指标变化、张量的分布情况等。特别是在训练网络的时候,我们可以设置不同的参数(比如:权重W、偏置B、卷积层数、全连接层数等),使用TensorBoader可以很直观的帮我们进行参数的选择。它通过运行一个本地服务器,来监听6006端口。在浏览器发出请求时,分析训练时记录的数据,绘制训练过程中的图像。
- 安装tensorboard
pin install tensorboard
或者
conda install tensorboard

- 测试例子1
#tensorboard.py
import numpy as np
from tensorboardX import SummaryWriter
writer = SummaryWriter(log_dir='scalar')
for epoch in range(100):
writer.add_scalar('scalar/test', np.random.rand(), epoch)
writer.add_scalars('scalar/scalars_test', {'xsinx': epoch * np.sin(epoch), 'xcosx': epoch * np.cos(epoch)}, epoch)
writer.close()
运行tensorboard.py文件后,相关文件会保存到scalar文件中
- 然后在终端输入命令
tensorboard --logdir scalar
- 打开浏览器输入地址:http://localhost:6006/ 便得到可视化图

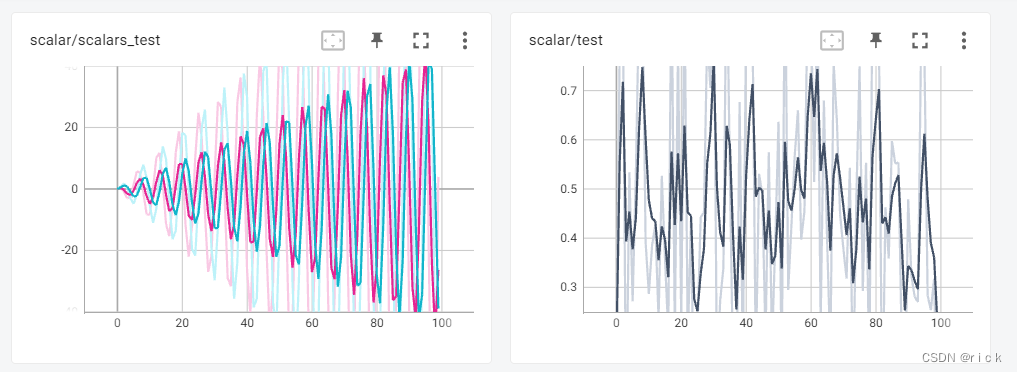
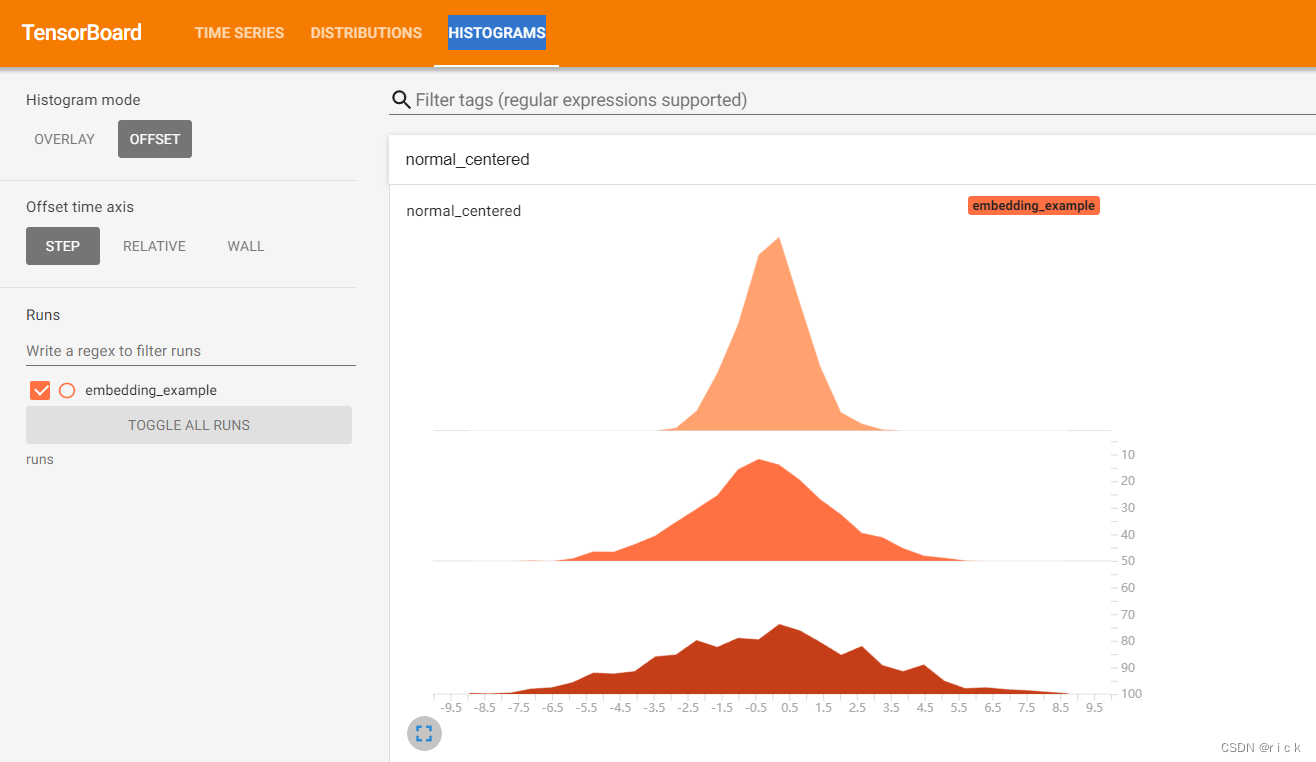
- 测试例子2【直方图 (histogram)】
参考:详解PyTorch项目使用TensorboardX进行训练可视化
使用 add_histogram 方法来记录一组数据的直方图。
add_histogram(tag, values, global_step=None, bins='tensorflow', walltime=None, max_bins=None)
参数
tag (string): 数据名称
values (torch.Tensor, numpy.array, or string/blobname): 用来构建直方图的数据
global_step (int, optional): 训练的 step
bins (string, optional): 取值有 ‘tensorflow’、‘auto’、‘fd’ 等, 该参数决定了分桶的方式,详见这里。
walltime (float, optional): 记录发生的时间,默认为 time.time()
max_bins (int, optional): 最大分桶数
from tensorboardX import SummaryWriter
import numpy as np
writer = SummaryWriter('runs/embedding_example')
writer.add_histogram('normal_centered', np.random.normal(0, 1, 1000), global_step=1)
writer.add_histogram('normal_centered', np.random.normal(0, 2, 1000), global_step=50)
writer.add_histogram('normal_centered', np.random.normal(0, 3, 1000), global_step=100)
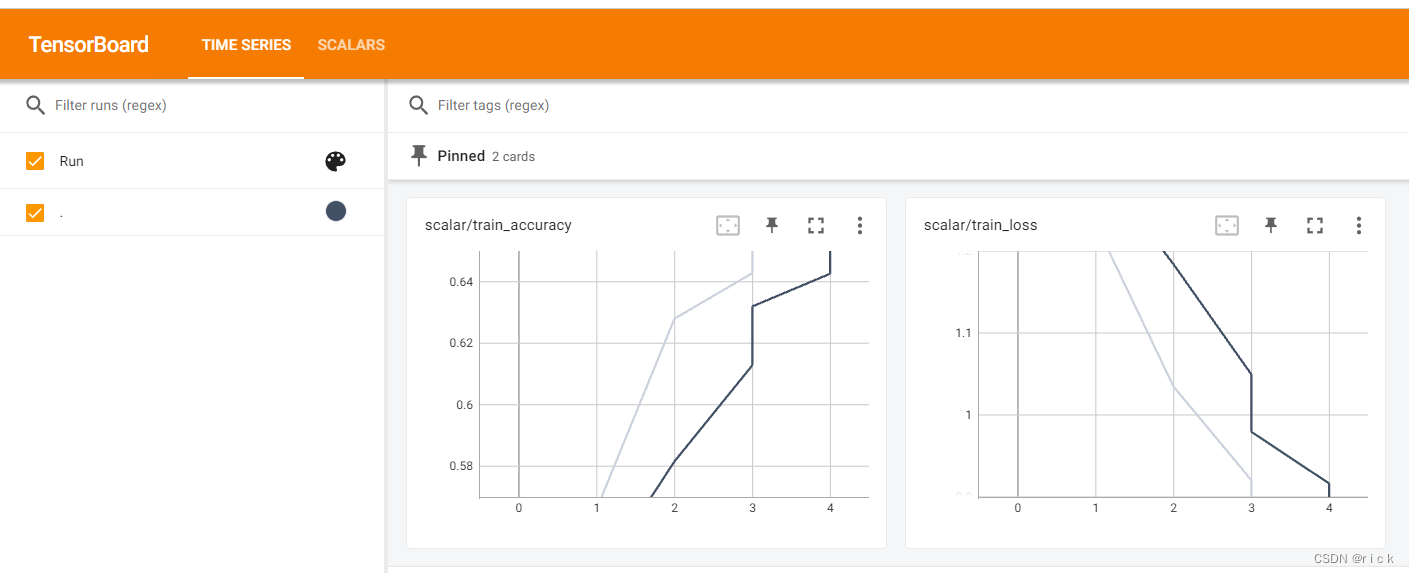
- 在train.py代码中加入代码用tensorboard可视化训练结果
# print statistics 打印输出
running_loss += loss.item() #累加损失
writer = SummaryWriter(log_dir='scalar')
if step % 500 == 499: # print every 500 mini-batches 每隔500步打印信息
with torch.no_grad(): #with是一个上下文管理器,这个函数在验证和测试阶段有用
outputs = net(test_image) # [batch, 10] 进行正向传播
predict_y = torch.max(outputs, dim=1)[1] #得到预测最大值的标签类别 需要在第一个维度去寻找,只需要找到index
accuracy = (predict_y==test_label).sum().item() /test_label.size(0) #将预测标签与真实标签比较 ,前面得到的是tensor数据,需要使用.item()进行数据转换
#除以测试样本的数量,除以测试样本的数量,就得到准确率
print('[%d, %5d] train_loss: %.3f test_accuracy: %.3f' %
(epoch + 1, step + 1, running_loss / 500, accuracy))#迭代到多少轮,多少轮的哪一步,每500步统计平均误差
writer.add_scalar('scalar/train_accuracy', accuracy, epoch)
writer.add_scalar('scalar/train_loss',running_loss / 500, epoch)
running_loss = 0.0
writer.close()
总结
- 通过对图像处理基础讲解,学习了卷积层、池化层、全连接层的概念。
- 学习了训练数据集的整个流程。
- 了解使用tensorboard可视化结果。