文章目录
- 一、mycat一主一从读写分离原理
- 二、搭建MySQL主从复制
- 三、配置mycat2一主一从读写分离
- 四、配置Mycat2双主双从读写分离
- 4.1 Mysql 双主双从搭建步骤
- 1、创建MySQL数据库与MySQL 机器信息
- 2、双柱双从配置
- 2.1 master1配置
- 2.2 master2配置
- 2.3 Slave1、Slave2 配置
- 3、在两台主机上建立账号,并授权Slave。
- 4、开始搭建主从复制(S1复制M1,S2复制M2,M1-M2相互复制)
- 4.2 双主双从读写分离扩展
- 4.3 读写分离扩展
- 1、读写分离(一主m一从s,无备)
- 2、读写分离(一主m一从s,从机s也可以当作备用机)
- 3、读写分离(一主m一从s,一备b)
- 4、MHA、MGR(一主m一从s一备b,READ_ONLY判断主)
- 5、GARELA_CLUSTER(一主m一从s一备b,b是多主)
一、mycat一主一从读写分离原理
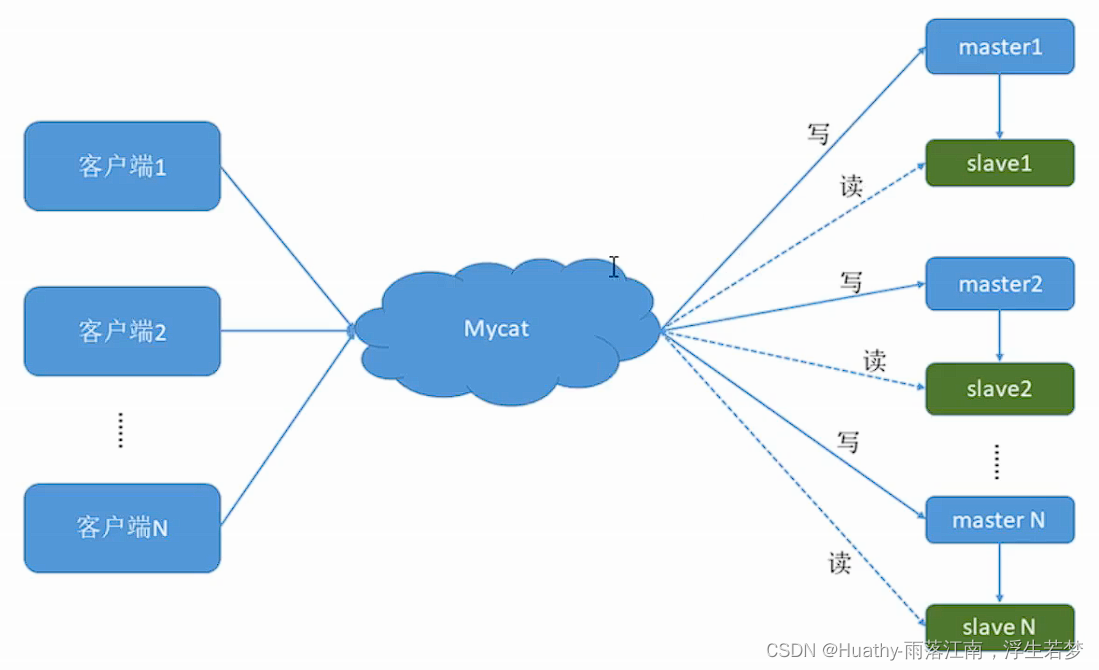
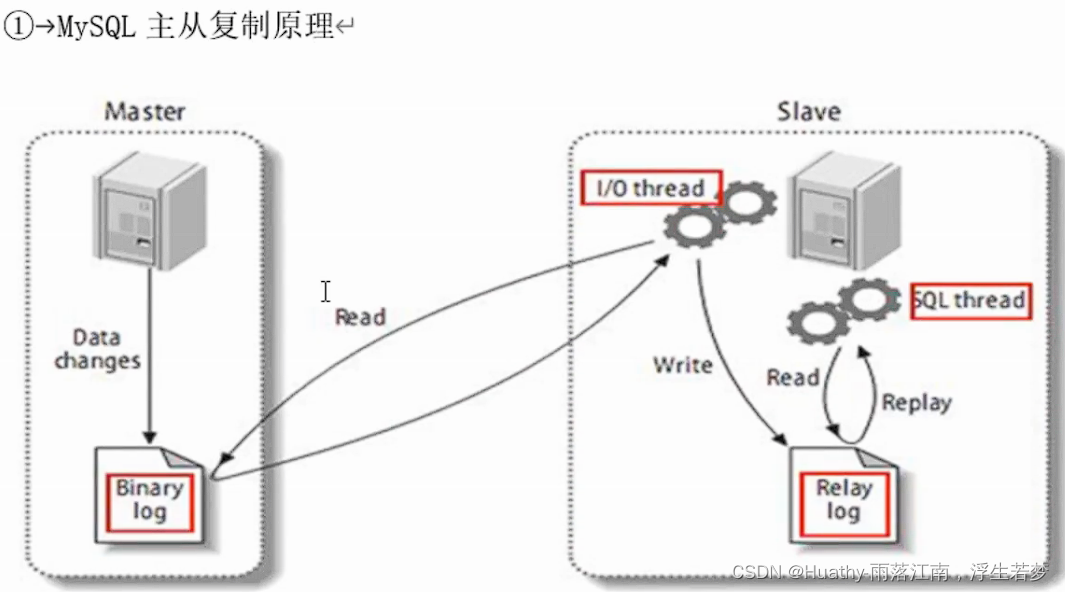
二、搭建MySQL主从复制
这里的主从复制可以参考文章:Docker搭建Mysql主主架构
重新搭建主从复制的两个命令:
stop slave;
reset master;
mysql的主从复制是从接入点开始,主机之前的数据,从机不会复制;但是redis是从头开始备份,主机之前的数据,从机也会获得。
三、配置mycat2一主一从读写分离
- 登录mycat2,创建逻辑库,配置数据源。
create database mydb1
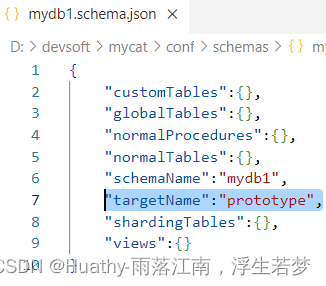
- 修改
mydb1.schema.json,指定数据源targetName、prototype,配置主机数据源。
- 添加数据源
-- 添加主库
/*+ mycat:createDataSource{
"name":"rwSepw",
"url":"jdbc:mysql://127.0.0.1:23306/?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"admin"
} */;
-- 添加从库
/*+ mycat:createDataSource{
"name":"rwSepr",
"url":"jdbc:mysql://127.0.0.1:33306/?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"admin"
} */;
-- 查看数据源配置
/*+ mycat:showDataSources{} */;
- 添加集群
-- 添加集群
/*+ mycat:createCluster{
"name":"prototype",
"masters": ["rwSepw"],
"replicas": ["rwSepr"]
} */;
-- 查看集群信息
/*+ mycat:showClusters{} */;
- 重启mycat2,并测试读写分离
mycat restart
测试原理,利用了mysql的logbin中statement可能导致数据不一致的特性。
扩展:MySQL的logbin三种类型
statement:
ROW:
MIXED:解决了一部分数据不一致的问题。
测试:
-- 利用两台MySQL主机名不一致来判断
insert into tb1 values(1,@@hostname);
select * from tb1;
注意:如果是用的docker,默认的hostname是容器ID的前几位。可以在创建的时候使用--hostname=$(hostName)传入hostname变量。
docker run -p port:prot --name mysql --hostname=$(hostName) mysql3306
四、配置Mycat2双主双从读写分离
一个主机m1用于处理所有写请求,它的从机 s1 和另一台主机m2 还有它的从机 s2 负责所有读请求。当m1主机岩机后,m2 主机负责写请求,m1、m2 互为备机。架构图如下“
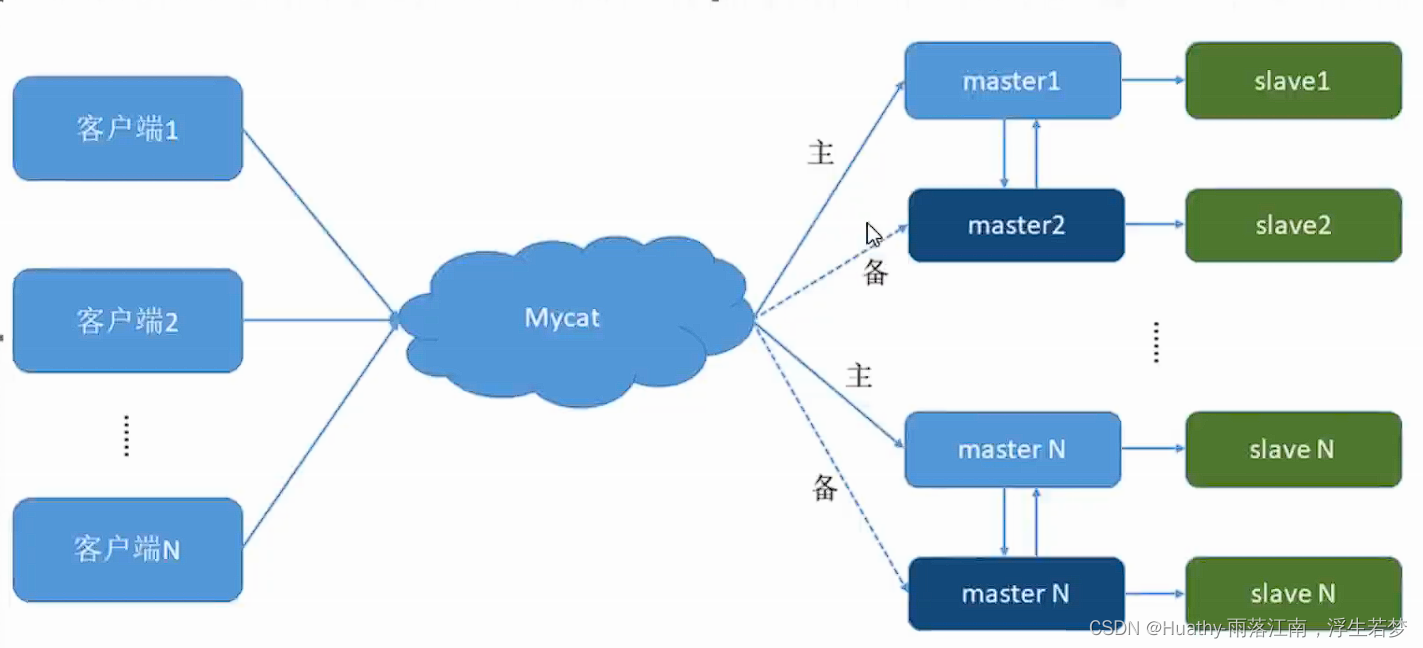
4.1 Mysql 双主双从搭建步骤
1、创建MySQL数据库与MySQL 机器信息
| 角色 | IP | 端口映射 | 机器名 | server-id |
|---|---|---|---|---|
| master1 | 172.17.0.3 | 13306 -> 3306 | mysql-13306 | 1 |
| master2(备用机) | 172.17.0.5 | 23306 -> 3306 | mysql-23306 | 2 |
| slave1 | 172.17.0.6 | 33306 -> 3306 | mysql-33306 | 3 |
| slave2 | 172.17.0.7 | 43306 -> 3306 | mysql-43306 | 4 |
注意:这里是使用docker创建的MySQL数据库,我们要使用容器内的IP地址。所以我们要使用以下命令来查看容器的IP:docker inspect mysql-13306 --format='{{.NetworkSettings.IPAddress}}
docker 创建四台MySQL:
docker run -p 13306:3306 --add-host=mysql-13306:172.17.0.2 --privileged=true --name mysql-13306 --hostname=mysql-13306 -v /D/Docker/mysql-13306/mysql:/etc/mysql -v /D/Docker/mysql-13306/logs:/logs -v /D/Docker/mysql-13306/data:/var/lib/mysql -v /D/Docker/mysql-13306/mysql-files:/var/lib/mysql-files -e MYSQL_ROOT_PASSWORD=admin -d mysql:5.7
docker run -p 23306:3306 --add-host=mysql-23306:172.17.0.3 --privileged=true --name mysql-23306 --hostname=mysql-23306 -v /D/Docker/mysql-23306/mysql:/etc/mysql -v /D/Docker/mysql-23306/logs:/logs -v /D/Docker/mysql-23306/data:/var/lib/mysql -v /D/Docker/mysql-23306/mysql-files:/var/lib/mysql-files -e MYSQL_ROOT_PASSWORD=admin -d mysql:5.7
docker run -p 33306:3306 --add-host=mysql-33306:172.17.0.4 --privileged=true --name mysql-33306 --hostname=mysql-33306 -v /D/Docker/mysql-33306/mysql:/etc/mysql -v /D/Docker/mysql-33306/logs:/logs -v /D/Docker/mysql-33306/data:/var/lib/mysql -v /D/Docker/mysql-33306/mysql-files:/var/lib/mysql-files -e MYSQL_ROOT_PASSWORD=admin -d mysql:5.7
docker run -p 43306:3306 --add-host=mysql-43306:172.17.0.5 --privileged=true --name mysql-43306 --hostname=mysql-43306 -v /D/Docker/mysql-43306/mysql:/etc/mysql -v /D/Docker/mysql-43306/logs:/logs -v /D/Docker/mysql-43306/data:/var/lib/mysql -v /D/Docker/mysql-43306/mysql-files:/var/lib/mysql-files -e MYSQL_ROOT_PASSWORD=admin -d mysql:5.7
2、双柱双从配置
2.1 master1配置
修改D:\Docker\mysql-13306\mysql\my.cnf,并将其拷贝到容器中etc/mysql/目录下:
docker cp D:/Docker/mysql-13306/mysql/my.cnf mysql-13306:/etc/mysql/
配置内容:
[mysqld]
# 主服务器唯一ID
server-id=1
# 启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
# 设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
# 表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1,65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1,65535
auto-increment-offset=1
2.2 master2配置
修改D:\Docker\mysql-23306\mysql\my.cnf,并将其拷贝到容器中etc/mysql/目录下:
docker cp D:/Docker/mysql-23306/mysql/my.cnf mysql-23306:/etc/mysql/
配置内容
[mysqld]
# 主服务器唯一ID
server-id=3
# 启用二进制日志
log-bin=mysql-bin
# 设置不要复制的数据库(可设置多个)
binlog-ignore-db=mysql
binlog-ignore-db=information_schema
# 设置需要复制的数据库
binlog-do-db=需要复制的主数据库名字
binlog_format=STATEMENT
# 在作为从数据库的时候,有写入操作也要更新二进制日志文件
log-slave-updates
# 表示自增长字段每次递增的量,指自增字段的起始值,其默认值是1,取值范围是1,65535
auto-increment-increment=2
# 表示自增长字段从哪个数开始,指字段一次递增多少,他的取值范围是1,65535
auto-increment-offset=3
2.3 Slave1、Slave2 配置
修改D:\Docker\mysql-33306\mysql\my.cnf和D:\Docker\mysql-43306\mysql\my.cnf,并将其拷贝到容器中etc/mysql/目录下:
docker cp D:/Docker/mysql-33306/mysql/my.cnf mysql-33306:/etc/mysql/
docker cp D:/Docker/mysql-43306/mysql/my.cnf mysql-43306:/etc/mysql/
Slave1 配置内容:
# 从机唯一ID
server-id=2
# 启用中继日志
relay-log=mysql-relay
Slave2 配置内容:
# 从机唯一ID
server-id=4
# 启用中继日志
relay-log=mysql-relay
注意:由于修改配置要重启所有MySQL服务。docker restart mysql-13306
3、在两台主机上建立账号,并授权Slave。
grant replication slave on *.* to 'rep'@'%' identified by '123456';flush privileges;
flush privileges;
4、开始搭建主从复制(S1复制M1,S2复制M2,M1-M2相互复制)
-- 创建M1-S1的主从复制。这里给出案例,其他的雷同。
-- 查看M1主机状态,并记录下File和Position位置
SHOW MASTER STATUS;
-- 在S1上执行change命令,创建主从复制并开启
change master to master_host='172.17.0.3',master_port=3306,master_user='rep'
,master_password='123456',master_log_file='mysql-bin.000001',master_log_pos=154;
start slave; -- 开启slave
show slave status; -- 查看状态
stop slave; --停止slave
注意:如果配置出错可以使用reset master来重置主从复制。
4.2 双主双从读写分离扩展
- 修改mycat2的集群配置来实现多种主从
mycat2的特点是凸显了集群的概念。和MySQL主从复制、集群配合来实现多节点的读写分离。
-- 查看数据源信息
/*+ mycat:showDataSources{} */
-- 创建写数据源,端口13306。并修改name、url创建写数据源2rwSepw2,端口23306。
/*+ mycat:createDataSource{
"name":"rwSepw1",
"url":"jdbc:mysql://127.0.0.1:13306/db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"admin"
}*/;
-- 创建读数据源rwSepr1,端口33306。并修改name、url创建读数据源2rwSepr2,端口43306。
/*+ mycat:createDataSource{
"name":"rwSepr1",
"url":"jdbc:mysql://127.0.0.1:33306/db1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"admin"
}*/;
- 修改集群配置Cluster
- 查看集群配置:
/*! mycat:showClusters{} */ - 执行以下命令:
/*! mycat:createCluster{ "name":"prototype", "masters":["rwSepw1","rwSepw2"], "replicas":["rwSepw2","rwSepr1","rwSepr1"] } */ - 也可以直接修改
mycat\conf\clusters\prototype.cluster.json文件,并重启mycat2{ "clusterType":"MASTER_SLAVE", "heartbeat":{ "heartbeatTimeout":1000, "maxRetryCount":3, "minSwitchTimeInterval":300, "showLog":false, "slaveThreshold":0.0 }, "masters":[ "rwSepw1", "rwSepw2" ], "maxCon":2000, "name":"prototype", "readBalanceType":"BALANCE_ALL", "replicas":[ "rwSepw2", "rwSepr1", "rwSepr2" ], "switchType":"SWITCH" }
- 查看集群配置:
- mycat2新建db1库新建tb1表。也可以修改以下的配置文件
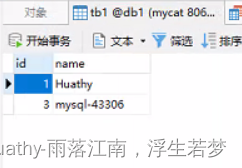
mycat\conf\schemas\db1.schema.json{ "customTables":{}, "globalTables":{}, "normalProcedures":{}, "normalTables":{ "tb1":{ "createTableSQL":"CREATE TABLE `db1`.`tb1` (\n\t`id` int(0) NOT NULL AUTO_INCREMENT,\n\t`name` varchar(255) NULL,\n\tPRIMARY KEY (`id`)\n)", "locality":{ "schemaName":"db1", "tableName":"tb1", "targetName":"prototype" } } }, "schemaName":"db1", "shardingTables":{}, "views":{} } - 测试,插入数据,然后在mycat8066中查询
insert into tb1 values(3, @@hostname)
4.3 读写分离扩展
通过对集群配置的修改,可以根据需求实现更多种情况的读写分离配置。
1、读写分离(一主m一从s,无备)
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"m"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"s"
],
"switchType":"SWITCH",
"timer:": {
"initialDelay": 30,
"period": 5,
"timeUnit": "SECONDS"
}
}
2、读写分离(一主m一从s,从机s也可以当作备用机)
需要实现mysql双主架构
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"m","s"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"s"
],
"switchType":"SWITCH",
"timer:": {
"initialDelay": 30,
"period": 5,
"timeUnit": "SECONDS"
}
}
3、读写分离(一主m一从s,一备b)
需要实现mysql双主架构
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"m","b"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"s"
],
"switchType":"SWITCH",
"timer:": {
"initialDelay": 30,
"period": 5,
"timeUnit": "SECONDS"
}
}
4、MHA、MGR(一主m一从s一备b,READ_ONLY判断主)
{
"clusterType":"MHA", // 或者MGR
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"m","b"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"s"
],
"switchType":"SWITCH",
"timer:": {
"initialDelay": 30,
"period": 5,
"timeUnit": "SECONDS"
}
}
5、GARELA_CLUSTER(一主m一从s一备b,b是多主)
{
"clusterType":"GARELA_CLUSTER",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"m","b"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"s"
],
"switchType":"SWITCH",
"timer:": {
"initialDelay": 30,
"period": 5,
"timeUnit": "SECONDS"
}
}