KV数据分片和分布
KV存储数据组织方式
- Hash:对于Hash方式,键值对数据的存储位置由预定义的Hash函数确定,因此所有键值对数据不是有序排列。Hash方式的优点是通过Hash函数计算存储位置的效率高,因此处理插入、删除、更新、单点查询操作的速度都比较快,但主要确定是由于无序存储,无法处理范围查询。
- 有序排列:可以支持所有的键值对数据访问接口,包括范围查询,一般采用树形结构组织数据(如B树),因此在进行插入、删除、更新、单点查询操作时的速度比Hash方式略低。
KV分片
对于一个 KV 系统,将数据分散在多台机器上有两种比较典型的方案:
- Hash:按照 Key 做 Hash,根据 Hash 值选择对应的存储节点。
- Range:按照 Key 分 Range,某一段连续的 Key 都保存在一个存储节点上
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-azeZqlMB-1672623809846)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/16a9487e-94ec-4b68-a12c-4a06b3d03ede/Untitled.png)]](https://img-blog.csdnimg.cn/250cc11e7b4b4df7a21d44d9ab27695f.png)
当分布式系统采用分片方式进行负载均衡时,相关的问题是,分片会放置在分布式系统中的哪个节点上,即数据分布问题;以及用户访问数据时,如何知道目标分片在哪个节点中。
多数系统首先根据各节点的存储容量进行负载均衡,在相近存储容量时,一般采用随机放置的策略。一旦系统中出现了负载不均衡比较严重的情况,可以在系统负载比较低时进行一定程度的数据迁移,提升负载均衡程度。
元数据:分片在节点上的分布信息,以及范围分片模式下每个分片负责的Key范围。
元数据的维护方式:
一是由专门的元数据服务器来维护,用户访问时需要先联系元数据服务器,然后定位到具体的数据服务器进行访问;并且为了减少元数据访问带来的网络通信,用户端一般都会有元数据的缓存。典型的系统是TiDB,系统中包含一个重要的子系统Placement Driver (PD)专门用来维护元数据,而且PD本身也是一个分布式系统,来保障系统的可靠性。
二是每个节点都存储着元数据,方便访问时定位,各个节点之间不断同步更新的元数据。例如CockroachDB中每个数据节点都维护所有分片的元数据,并且各个节点之间通过Gossip协议来同步元数据。
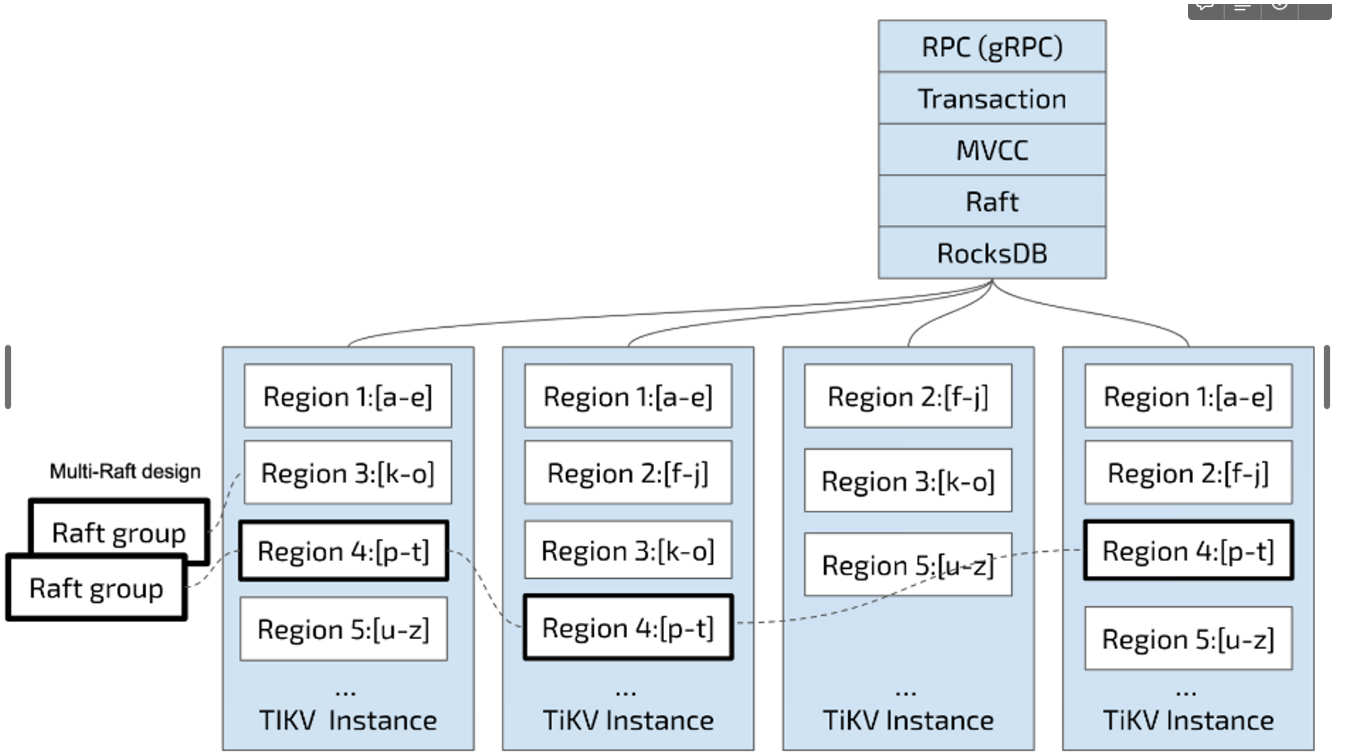
TiKV
参考自 https://book.tidb.io/session1/chapter2/tidb-storage.html
TiKV 选择了第二种方式,将整个 Key-Value 空间分成很多段,每一段是一系列连续的 Key,将每一段叫做一个 Region,并且会尽量保持每个 Region 中保存的数据不超过一定的大小,目前在 TiKV 中默认是 96MB。每一个 Region 都可以用 [StartKey,EndKey) 这样一个左闭右开区间来描述。
将数据划分成 Region 后,TiKV 将会做两件重要的事情:
- 以 Region 为单位做 Raft 的复制和成员管理
- 以 Region 为单位,将数据分散在集群中所有的节点上,并且尽量保证每个节点上服务的 Region 数量差不多
第一点,数据按照 Key 切分成很多 Region,每个 Region 的数据只会保存在一个节点上面(暂不考虑多副本)。TiDB 系统会有一个组件(PD)来负责将 Region 尽可能均匀的散布在集群中所有的节点上,这样实现了存储容量的水平扩展、负载均衡。为了保证上层客户端能够访问所需要的数据,系统中也会有一个组件(PD)记录 Region 在节点上面的分布情况,也就是通过任意一个 Key 就能查询到这个 Key 在哪个 Region 中,以及这个 Region 目前在哪个节点上(即 Key 的位置路由信息)。
第二点,TiKV 是以 Region 为单位做数据的复制,也就是一个 Region 的数据会保存多个副本,TiKV 将每一个副本叫做一个 Replica。Replica 之间是通过 Raft 来保持数据的一致,一个 Region 的多个 Replica 会保存在不同的节点上,构成一个 Raft Group。其中一个 Replica 会作为这个 Group 的 Leader,其他的 Replica 作为 Follower。所有的读和写都是通过 Leader 进行,读操作在 Leader 上即可完成,而写操作再由 Leader 复制给 Follower。