原文作者:我辈李想
版权声明:文章原创,转载时请务必加上原文超链接、作者信息和本声明。
文章目录
- 前言
- 常见用法
- 1.消息可靠性
- 2.持久化机制
- 3.消息积压
- 批量消费:增加 prefetch 的数量,提高单次连接的消息数
- 并发消费:多部署几台消费者实例
- 4.重复消费
- 二、其他
- 1.队列存在大量unacked数据
前言
常见用法
1.消息可靠性
RabbitMQ 提供了多种机制来确保消息的可靠性,以防止消息丢失或被意外删除。以下是几种提高消息可靠性的方法:
-
持久化消息(Durable Message):在发布消息时,将消息的
deliveryMode设置为2,即可将消息设置为持久化消息。持久化消息会将消息写入磁盘,即使 RabbitMQ 服务器重启,消息也不会丢失。 -
持久化队列(Durable Queue):创建队列时,将队列的
durable参数设置为true,即可创建一个持久化队列。持久化队列会将队列的元数据和消息都存储在磁盘上,即使消息队列服务器重启,队列的元数据和消息仍然可以恢复。 -
确认模式(Publisher Confirms):使用确认模式可以确保消息被成功发送到 RabbitMQ 服务器,并得到确认。通过在信道上使用
channel.confirmSelect()启用确认模式,然后通过channel.waitForConfirms()方法来等待服务器的确认。 -
事务模式(Transactions):使用事务模式可以保证消息的原子性,要么全部发送成功,要么全部失败。通过在信道上使用
channel.txSelect()开启事务模式,在发送消息后使用channel.txCommit()提交事务,或使用channel.txRollback()进行回滚。 -
消费者应答(Consumer Acknowledgement):在消费者接收和处理消息后,必须发送确认应答给 RabbitMQ 服务器。通过使用
channel.basicAck()方法发送确认应答,以告知服务器消息已经成功处理。
通过使用上述机制,可以在 RabbitMQ 中实现消息的可靠性传输和处理,以防止消息的丢失和重复传递。
2.持久化机制
在RabbitMQ中,消息持久化是一种机制,可以确保消息在服务器宕机或重启之后不丢失。默认情况下,RabbitMQ的消息是存储在内存中的,如果服务器宕机,则会导致消息的丢失。要实现消息的持久化,可以采取以下步骤:
-
创建一个持久化的交换机(Exchange):
在定义交换机时,将其durable参数设置为true,例如:channel.exchangeDeclare("exchange_name", "direct", true); -
创建一个持久化的队列(Queue):
在定义队列时,将其durable参数设置为true,例如:channel.queueDeclare("queue_name", true, false, false, null); -
将持久化的队列与交换机进行绑定:
使用队列和交换机的bind方法进行绑定,例如:channel.queueBind("queue_name", "exchange_name", "routing_key"); -
发布持久化的消息:
在发布消息时,将消息的deliveryMode属性设置为2,表示消息是持久化的,例如:String message = "Hello RabbitMQ!"; channel.basicPublish("exchange_name", "routing_key", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
通过以上步骤,就可以实现消息的持久化。当RabbitMQ服务器宕机或重启后,消息会被保存在磁盘中,并在服务器恢复后重新投递给消费者。需要注意的是,虽然消息被持久化了,但是在发送到队列之前,仍然有可能发生丢失,所以在实际的应用中,还需要考虑一些因素,比如网络故障、消费者的可靠性等。
3.消息积压
批量消费:增加 prefetch 的数量,提高单次连接的消息数
为了提高消费性能,可以将多个消息批量进行消费,减少消费者和消息队列的交互次数。通过设置合适的批量消费大小,可以在一次网络往返中消费多个消息,从而提高消费性能。
要实现RabbitMQ的批量消费,可以使用RabbitMQ的channel.basicQos方法来设置每次消费的消息数量。以下是一个示例代码,演示如何实现批量消费:
import pika
def callback(ch, method, properties, body):
print("Received message: %s" % body)
# 处理消息的逻辑
# 发送确认给RabbitMQ
ch.basic_ack(delivery_tag=method.delivery_tag)
def consume_messages():
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
# 设置每个消费者一次性获取的消息数量
channel.basic_qos(prefetch_count=10)
# 注册消费者并开始消费消息
channel.basic_consume(queue='my_queue', on_message_callback=callback)
# 进入一个循环,一直等待消息的到来
channel.start_consuming()
consume_messages()
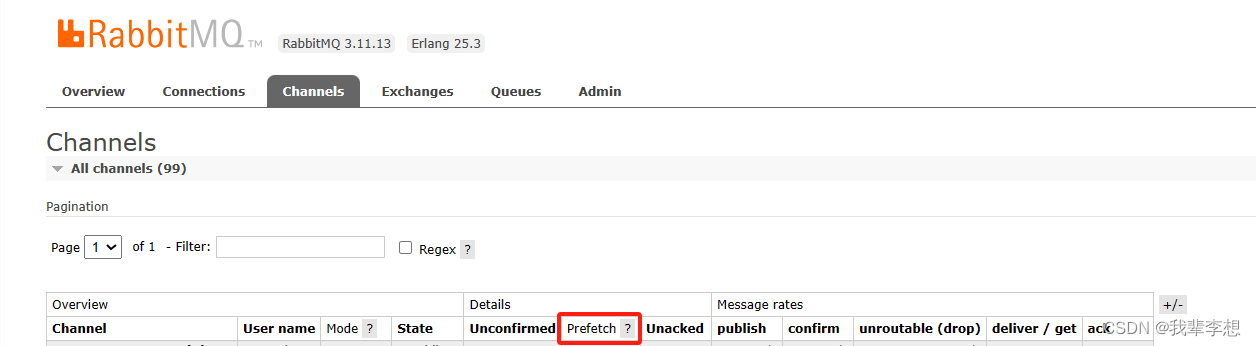
在上面的代码中,我们通过channel.basic_qos(prefetch_count=10)设置每次处理的消息数量为10。这样,在消费者处理完10条消息之前,RabbitMQ将不会再向其发送更多消息。
这样,就实现了RabbitMQ的批量消费。你可以根据需求,在basic_qos方法中设置适合你的消息数量。
并发消费:多部署几台消费者实例
可以采用多线程或多进程的方式进行消息的并发消费,将多个消费者并行处理消息。通过增加并发消费者的数量,可以提高消息的处理速度,提高消费的性能。
使用进程池来消费RabbitMQ的消息可以更好地管理并发性能。通过使用进程池,可以在一个固定的池子中创建多个进程,并且复用它们来消费消息,从而减少进程创建和销毁的开销。
以下是一个使用进程池消费RabbitMQ消息的示例:
import multiprocessing
import os
import time
import pika
def consumer(queue_name):
connection = pika.BlockingConnection(pika.ConnectionParameters(host='localhost'))
channel = connection.channel()
channel.queue_declare(queue=queue_name)
def callback(ch, method, properties, body):
print(f'Process {os.getpid()} received message: {body}')
time.sleep(1)
channel.basic_consume(queue=queue_name, on_message_callback=callback, auto_ack=True)
channel.start_consuming()
def main():
# 创建进程池
pool = multiprocessing.Pool(processes=5)
# 在进程池中提交任务
for _ in range(5):
pool.apply_async(consumer, ('my_queue',))
pool.close()
pool.join()
if __name__ == '__main__':
main()
在上述示例中,我们使用multiprocessing.Pool来创建一个包含5个进程的进程池。然后,我们使用apply_async方法向进程池中提交任务,每个任务都是调用consumer函数来消费"my_queue"队列中的消息。进程池会自动分配任务给闲置的进程来处理。通过close和join方法,我们可以确保所有任务都被完成。
4.重复消费
-
消息确认:在消费者处理完一条消息后,通过调用
basic_ack方法手动确认消息已经成功消费。这样,RabbitMQ就会将该消息标记为已经处理,不会再次发送给其他消费者。同时,还可以设置auto_ack参数为False,禁用自动消息确认机制,以确保消息被正确确认。 -
消息持久化:可以通过设置消息的
delivery_mode属性为2来将消息标记为持久化消息。这样,即使消费者在处理消息时发生故障,消息也会被保存在磁盘上,待消费者恢复正常后会重新投递。 -
唯一消费者:可以通过设置队列的
exclusive参数为True,创建一个排他队列。这样,只有一个消费者可以连接到该队列,并独占地消费其中的消息,避免重复消费。 -
消息去重:在消费者端可以维护一个已消费消息的记录,例如在数据库或缓存中记录已消费的消息的ID或唯一标识。每次消费消息时,先检查记录中是否已经存在该消息,如果存在则跳过,避免重复处理。
-
幂等操作:在消费者的处理逻辑中,要确保操作是幂等的,即多次执行同一个操作的效果和执行一次的效果是一样的。这样,即使消息被重复消费,也不会产生副作用。
二、其他
1.队列存在大量unacked数据
通过rabbitmq的后台管理,进入相应的队列,滑到最下边,找到purge。purge将清空这个队列的消息。