文章目录
- 前言
- 1. 环境准备
- 2. 生成密钥
- 3. 配置参数
- 4. 创建 ReplicaSet
- 5. 副本集维护
- 5.1 新增成员
- 5.2 移除节点
- 5.4 主节点降级
- 5.5 阻止选举
- 5.6 允许副本节点读
- 5.7 延迟观测
- 6. 连接副本集
- 后记
前言
本篇文章介绍 MongoDB ReplicaSet 如何搭建,及常用的维护方法。
1. 环境准备
单机 MongoDB 安装部署,可参考 MongoDB 单机部署 文档。
| IP | Hostname | Role |
|---|---|---|
| 172.16.104.55 | 172-16-104-55 | PRIMARY |
| 172.16.104.56 | 172-16-104-56 | SECONDARY |
| 172.16.104.57 | 172-16-104-57 | SECONDARY |
- CentOS Linux release 7.9.2009 (Core)
- MongoDB version v4.2.25
配置 /etc/hosts 映射:
172.16.104.57 172-16-104-57
172.16.104.56 172-16-104-56
172.16.104.55 172-16-104-55
2. 生成密钥
通过密钥文件身份验证, mongod 副本集中的每个实例都使用密钥文件的内容作为共享密码来对部署中的其他成员进行身份验证。只有 mongod 具有正确密钥文件的实例才能加入副本集。
在主节点生成密钥,可通过下方命令完成:
openssl rand -base64 756 > /data/mongodb/data/keyFile
chmod 400 /data/mongodb/data/keyFile
然后将密钥文件,scp 到其他节点的相同目录下:
scp /data/mongodb/data/keyFile root@172.16.104.56:/data/mongodb/data/keyFile
记得调整文件属组:
chown mongod:mongod /data/mongodb/data/keyFile
3. 配置参数
在原来的配置文件基础上,需要添加如下内容:
security:
keyFile: <path-to-keyfile>
replication:
replSetName: <replicaSetName>
keyFile 就是刚才生产密钥的文件路径,replSetName 是集群的名称,3 台实例都需要配置。
# where to write logging data.
systemLog:
destination: file
logAppend: true
path: /data/mongodb/logs/mongod.log
# Where and how to store data.
storage:
dbPath: /data/mongodb/data
journal:
enabled: true
# how the process runs
processManagement:
fork: true # fork and run in background
pidFilePath: /data/mongodb/run/mongod.pid # location of pidfile
replication:
replSetName: myReplSet
# network interfaces
net:
port: 27017
bindIp: 0.0.0.0 # Enter 0.0.0.0,:: to bind to all IPv4 and IPv6 addresses or, alternatively, use the net.bindIpAll setting.
security:
authorization: enabled
keyFile: /data/mongodb/data/keyFile
配置修改完成后,重启 3 台实例。
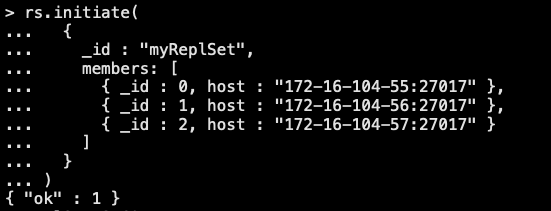
4. 创建 ReplicaSet
rs.initiate(
{
_id : "myReplSet",
members: [
{ _id : 0, host : "172-16-104-55:27017" },
{ _id : 1, host : "172-16-104-56:27017" },
{ _id : 2, host : "172-16-104-57:27017" }
]
}
)
查看 ReplicaSet 状态:
rs.status()
如果集群成员都正常,那 infoMessage 为空。
5. 副本集维护
5.1 新增成员
rs.add("172-16-104-57:27017")
新增节点的数据会自动同步,分为两个阶段 Initial Sync 和 Replication,先通过 init sync 同步全量数据,再通过 replication 不断重放 Primary 上的 oplog 同步增量数据。
另外,当创建副本集节点数比较多的时候,主节点需要每次需要心跳检测来判断自己是否符合 “大多数”。这种情况下,心跳的网络流量和选举所花费的时间都会比较大。为避免这种情况我们可以指定某几个节点具体选举的权利。
rs.add({"_id":4,"host":"xx:xx","votes":0})
5.2 移除节点
rs.remove("172-16-104-57:27017")
5.4 主节点降级
将主节点降级为副本节点,触发选举且原主节点不会被选为主。
rs.stepDown(stepDownSecs, secondaryCatchUpPeriodSecs)
- stepDownSecs:降级主节点的秒数,在此期间该节点不会被选为主节点,默认 60 秒。
- secondaryCatchUpPeriodSecs:避免主节点降级时,有增量数据未被副本节点接收,等待的时间。
5.5 阻止选举
当一个节点维护的时候,使用下方命令阻止其在一定时间内,不会被选为主节点。
rs.freeze()
5.6 允许副本节点读
副本节点默认不允许执行操作,执行命令会报错 not master and slaveOk=false 可使用下方命令,允许副本节点只读。
rs.secondaryOk()
5.7 延迟观测
可使用下方命令查看备节点延迟:
db.printSecondaryReplicationInfo()
6. 连接副本集
MongoDB 连接串参数,支持指定多个副本集节点,可通过 readPreference 分配读写。

后记
推荐阅读:https://www.mongodb.com/docs/manual/reference/method/js-replication/