遗留问题:
6-1 1
在C语言中,如果要保留小数的话,一定要除以2.0,而不是2。
设整型变量m,n,a,b的值均为1,执行表达式(m = a>b)||(n = a<b)后,表达式的值以及变量m和n的值是?请写出过程。在C语言中
首先,计算表达式"a>b",由于整型变量a和b的值均为1,所以"a>b"的结果为0。
接着,由于"||"是逻辑或运算符,它会在第一个操作数为真(非零)时停止计算并返回真,否则继续计算第二个操作数。因此,由于"a>b"的结果为0(假),所以需要继续计算表达式"a<b"。
同样,由于a和b的值均为1,所以"a<b"的结果也为0(假)。
然后,将这个结果赋值给变量n,即n=0。
最后,由于"||"运算符的左右两边都是假(0),所以整个"||"运算的结果为假(0)。但是,由于"C语言"中逻辑运算符的优先级低于赋值运算符,所以"(m = a>b)"实际上是在将"a>b"(即0)赋值给m,因此m的值变为0。
所以,执行表达式"(m = a>b) || (n = a<b)"后,表达式的值为0,变量m和n的值均为0。
对于||来说,一个为假,就都是假,何况两个都为假呢!
判断运算结果的数据类型方式:小跟大
char<short<int<long<float<double
在C语言中,数据类型的大小排序(从最小到最大)大致如下:
1. `char`:通常占用1字节(8位),用于存储字符。
2. `short`:短整型,通常占用2字节(16位),用于存储较小的整数。
3. `int`:整型,通常占用4字节(32位),用于存储整数。
4. `long`:长整型,通常占用4字节(32位)或更大,具体取决于编译器和平台。在某些系统中,它可能占用8字节(64位)。
5. `long long`:长长整型,至少占用8字节(64位),用于存储非常大的整数。
6. `float`:单精度浮点数,通常占用4字节(32位),用于存储带有小数的数值。
7. `double`:双精度浮点数,通常占用8字节(64位),用于存储更精确的带有小数的数值。
8. `long double`:长长精度浮点数,至少占用10字节(80位),提供更高的精度。
需要注意的是,这些大小并不是在所有系统和编译器中都固定不变的。具体的大小可能会受到编译器、平台架构(如x86、ARM等)以及编译选项的影响。为了确保代码的可移植性,可以使用 `<limits.h>` 和 `<float.h>` 头文件中的宏来获取确切的类型大小。
在C语言中,运算符的优先级排序
在C语言中,运算符的优先级排序如下(从高到低):
1. **括号** (`()`、`[]`、`.`、`->`):括号运算符、数组下标、结构体成员访问和指针成员访问具有最高的优先级。
2. **一元运算符** (`++`、`--`、`+`、`-`、`&`、`*`、`!`、`~`、`sizeof`、`type *`、`type &`、`type (expression)`):包括递增/递减、正负号、取地址、解引用、逻辑非、按位取反、大小计算、类型转换等。
3. **乘法** (`*`)、**除法** (`/`)、**模运算** (`%`):这些算术运算符具有相同的优先级。
4. **加法** (`+`)、**减法** (`-`):这些算术运算符具有相同的优先级。
5. **左移** (`<<`)、**右移** (`>>`):位移运算符。
6. **小于** (`<`)、**大于** (`>`、**小于等于** (`<=`)、**大于等于** (`>=`):关系运算符。
7. **等于** (`==`)、**不等于** (`!=`):相等性比较运算符。
8. **按位与** (`&`):位操作运算符。
9. **按位异或** (`^`):位操作运算符。
10. **按位或** (`|`):位操作运算符。
11. **逻辑与** (`&&`):逻辑运算符。
12. **逻辑或** (`||`):逻辑运算符。
13. **条件运算符** (`? :`):三目运算符。
14. **赋值运算符** (`=`、`+=`、`-=`、`*=`、`/=`、`%=`、`<<=`、`>>=`、`&=`、`^=`、`|=`):赋值运算符的优先级较低,但结合性是从右到左的。
15. **逗号运算符** (`,`):逗号运算符具有最低的优先级。
注意:当优先级相同的操作符出现在一个表达式中时,它们的计算顺序遵循从左到右的结合性规则,除非特别说明。使用括号可以改变运算的优先级和顺序。
若变量a=3,b=2,c=1,表达式a>b>c的运算结果以及运算过程
表达式"a>b>c"是一个逻辑表达式,它会按照优先级和结合性规则进行计算。
在这个表达式中,首先计算"a>b",即3>2,结果为真(1)。
然后,将这个结果与"c"进行比较,即1>c。由于"c"的值为1,所以1>c的结果为假(0)。
因此,整个表达式"a>b>c"的运算结果为假(0)。运算过程如下:
- 计算3 > 2,结果为真(1)
- 计算1 > 1,结果为假(0)
所以,最终结果为假(0)。
若变量x为int类型,则表达式x=1,x+5,x++的值是?
因为x+5和x++都没有=号,因此最后的结果还是x=1
若有变量定义”double x = 5.6 ;“则表达式(int)x != 6的值是?请写出解题过程
首先,我们需要理解这个表达式:
`(int) x != 6`
这里,`(int) x`是对变量x进行类型转换,将double类型的5.6转换为int类型。在C语言中,这种转换会去掉小数部分,只保留整数部分,所以 `(int) x` 的值为5。
然后,我们计算 `(int) x != 6`,也就是5 != 6。
不等运算符 `!=` 用于比较两个操作数是否不相等。在这个情况下,5和6确实不相等,所以 `(int) x != 6` 的结果为真(1)。
因此,表达式 `(int) x != 6` 的值为1。解题过程如下:
1. 将 double 类型的变量 x (值为 5.6)转换为 int 类型,得到整数 5。
2. 比较转换后的整数 5 和常量 6 是否不相等,结果为真(1)。
设int型变量x的值是5,则sizeof(x)、sizeof(x++)以及变量x的值是?
sizeof 是一个编译时运算符,它返回变量或类型的字节大小。在C语言中,int型变量通常占用4个字节。
对于这个问题:
-
sizeof(x):这个表达式会返回变量x的大小,即sizeof(int),在大多数系统上为4字节。 -
sizeof(x++):这个表达式也会返回变量x的大小,即sizeof(int),因为在sizeof运算符内部,x++的操作不会立即执行,而是先计算sizeof的值。也就是说,sizeof只会计算变量的类型大小,而不会影响变量的值。 -
变量x的值:由于
sizeof(x++)并不会改变x的值,所以变量x的值仍然是5。
总结:
sizeof(x)的值是 4(字节)。sizeof(x++)的值也是 4(字节)。- 变量x的值是 5。
为什么sizeof(x++)并不会改变x的值
sizeof 是一个编译时运算符,它的主要作用是计算变量或类型的字节大小。当使用 sizeof(x++) 时,实际上发生了以下两个步骤:
-
计算
x++:这是一个后置递增运算符,它会先返回变量x的当前值,然后将x的值增加1。但是,这个操作的结果并没有被存储或者用于任何表达式,因此这个递增的结果会被丢弃。 -
计算
sizeof:编译器在此阶段并不执行实际的运行时操作,而是仅仅分析x的类型并计算其占用的内存大小。由于sizeof是在编译时确定的,所以它不会受到x++操作的影响。
因此,虽然 x++ 会执行递增操作,但由于其结果没有被使用,并且 sizeof 是在编译时计算的,所以 x 的值并不会因为 sizeof(x++) 这个表达式的存在而改变。如果想要改变 x 的值并获取新的大小,你需要分开进行这两个操作,如:x++; sizeof(x);。这样,x 的值就会先递增,然后再计算新值的大小。
x++; sizeof(x);那sizeof(x)的值是什么
在执行了 x++; 之后,变量 x 的值会增加1。假设初始时 int x = 5;,那么执行 x++; 后,x 的值变为6。
接下来执行 sizeof(x);,这个表达式会计算变量 x 的大小,也就是 sizeof(int)。在大多数系统上,int类型通常占用4个字节。
所以,执行 x++; sizeof(x); 之后,sizeof(x) 的值是4(字节)。请注意,这里 sizeof(x) 的值与 x 的实际数值(6)无关,它只取决于变量 x 的类型(在这个例子中是int类型)。
if(x > y);是对的语句
while(1);是对的语句
if(x == y)&& (x != 0) x++;是错的语句,if()要有一个大括号。
switch语句中一定要有default分支吗。 在C语言中
在C语言中,switch语句中不一定要有default分支。默认情况下,如果case子句中的条件都不满足,程序会跳过switch语句块继续执行后续的代码。
然而,包含一个default分支通常是良好的编程实践,因为它可以处理未预期的或者没有在case子句中明确列出的情况。这样做可以增强代码的健壮性和可维护性,防止因未来修改或输入数据变化而导致的未定义行为。
以下是一个包含default分支的switch语句示例:
```c
int input;
printf("Enter a number between 1 and 5: ");
scanf("%d", &input);
switch (input) {
case 1:
printf("You entered 1.\n");
break;
case 2:
printf("You entered 2.\n");
break;
case 3:
printf("You entered 3.\n");
break;
case 4:
printf("You entered 4.\n");
break;
case 5:
printf("You entered 5.\n");
break;
default:
printf("Invalid input. Please enter a number between 1 and 5.\n");
break;
}
```在这个例子中,如果输入的值不在1到5的范围内,default分支将被执行,提示用户输入无效。如果没有default分支,当输入超出预期范围时,程序可能会意外地执行switch语句块后的代码,或者如果没有后续代码,则可能不会有任何反应,这可能会使问题更难被发现和调试。
case后只能根常量吗?在C语言中。
在C语言中,case语句后的表达式通常是一个常量表达式或者枚举常量。这是因为case标签需要在编译时就能够确定其值,而变量的值通常在运行时才能确定。
以下是在C语言中合法的case后的表达式类型:
1. 整型常量:例如 `case 1:`、`case 20:` 等。
2. 字符常量:例如 `case 'a':`、`case 'B':` 等。
3. 枚举常量:如果你定义了一个枚举类型,那么其枚举成员可以作为case后的表达式,例如:
```c
enum Color {RED, GREEN, BLUE};
...
switch(color) {
case RED: ...
case GREEN: ...
case BLUE: ...
}
```4. 常量表达式:一些可以在编译时计算出结果的表达式也可以用作case后的表达式,例如:
```c
#define MAX 10
...
switch(i) {
case MAX - 1: ...
}
```需要注意的是,尽管case后面通常跟随常量,但在同一个switch语句中,不同的case标签不能有相同的值。此外,每个case后面的语句块应该以break、return或者goto等能够跳出switch语句的语句结束,否则会进入下一个case的执行,这种现象被称为“穿透”(fallthrough)。当然,如果有意让多个case共享相同的处理代码,也可以省略break语句。
case后的多条语句无须用大括号括起来
在C语言中,多少条语句需要if的大括号
在C语言中,如果if语句后面只有一条语句需要执行,从语法上讲,可以省略大括号{}。但是,这是一个常见的编程习惯和风格问题,且为了提高代码的可读性和避免潜在的错误,强烈建议始终使用大括号来包围if语句的执行块,即使它只包含一条语句。
以下是一个不使用大括号的例子:
```c
if (condition)
single_statement;
```然而,这样的写法可能会在后续的代码维护中引入错误,比如当你想要添加更多语句到if条件下的时候,很容易忘记添加大括号,导致逻辑错误。以下是一个使用大括号的例子:
```c
if (condition) {
single_statement;
}
```尽管在语法上只有一条语句时大括号是可以省略的,但为了代码的清晰性和防止错误,推荐始终使用大括号来包围if语句的执行块。这是一条普遍接受的编程最佳实践。
在for(表达式1;表达式2;表达式3)中,如果表达式2为空,则该循环为什么不一定是死循环?举个例子
在for循环中,表达式2是循环的条件判断部分。如果表达式2为空(通常表示为";"),那么每次循环都会执行循环体,而不会进行任何条件检查。
然而,这并不一定意味着循环会成为死循环,因为循环的结束可能由其他因素控制,比如在循环体内改变了能够影响循环继续与否的状态。
以下是一个例子,说明在表达式2为空的情况下,循环不一定是死循环:
```c
int i = 0;
int limit = 5;
for (; ; ) {
printf("%d\n", i);
if (i == limit) {
break; // 当i达到limit时,使用break语句退出循环
}
i++;
}
```在这个例子中,表达式2为空,但是我们在循环体内添加了一个if语句来检查变量i的值是否等于预设的limit。当i达到limit时,我们使用break语句手动退出循环。因此,虽然表达式2没有提供循环条件,但通过在循环体内进行条件检查和控制,我们可以确保循环不会成为死循环。
用do while 语句构成循环时,当while的表达式为0时结束循环?什么意思
在使用do-while语句构成循环时,循环的执行流程如下:
1. 首先执行一次do后面的语句块(循环体)。
2. 然后检查while后面的表达式(循环条件)的值。
3.
如果循环条件的值为非零(真),那么继续执行循环体;
如果循环条件的值为零(假),那么退出循环。
也就是说,当while后面的表达式的值为0时,表示满足了结束循环的条件,因此循环会在此时终止。这是因为while语句的逻辑是只有当循环条件为真(非零)时才会继续执行循环,而当条件为假(零)时则退出循环。
例如,以下是一个简单的do-while循环示例:
```c
int counter = 0;
do {
printf("%d\n", counter);
counter++;
} while (counter < 5);
```在这个例子中,while的表达式是 `counter < 5`。当 `counter` 的值达到5时,表达式的值变为0(因为5不大于5),此时满足结束循环的条件,循环就会停止执行。
因此,之前有一道题
#include<stdio.h>
int main (){
int x =-1;
do{
x = x*x;
}while(!x);
return 0;
}第一次的时候,x=(-1)*(-1),结果为1,那进入while那里后,取反,为0,是假,则退出循环,因此,循环体执行一次。
整型表达式和整型常量表达式的区别?
整型表达式和整型常量表达式的主要区别在于它们的值是否在编译时就能确定:
1. 整型表达式:
- 整型表达式是由整型常量、整型变量、运算符和其他表达式组合而成的,其值可以在运行时计算得出。
- 例如:`int result = a + b;` 中的 `a + b` 就是一个整型表达式,它的值取决于变量 `a` 和 `b` 的当前值。
2. 整型常量表达式:
- 整型常量表达式是一种特殊的整型表达式,它的值在编译时就必须是可知的和确定的。
- 整型常量表达式由整型常量、枚举常量、`sizeof`运算符以及这些元素通过算术运算符和位运算符组合而成,但不包含任何变量或者函数调用,因为它们的值在运行时才能确定。
- 例如:`enum Color {RED, GREEN, BLUE}; int value = RED + sizeof(int);` 中的 `RED + sizeof(int)` 是一个整型常量表达式,因为它的值在编译时就可以确定。
总结起来,整型表达式的值可能在运行时根据变量的当前状态变化,而整型常量表达式的值在编译时就必须是确定的,不依赖于运行时的变量状态。整型常量表达式通常用于需要在编译时就知道确切值的场合,如数组大小定义、case语句中的标签值等。
整型常量或整型表达式有什么区别
整型常量和整型表达式在C语言中主要有以下区别:
1. 整型常量:
- 整型常量是一个固定的、不可改变的整数值。它在编译时就已经确定了具体的数值。
- 例如:`int a = 10;` 中的 `10` 就是一个整型常量。
2. 整型表达式:
- 整型表达式是由整型常量、整型变量、运算符和其他表达式组合而成的,其值可以在运行时计算得出。
- 整型表达式的结果必须是整数类型。
- 例如:`int b = a + 5;` 中的 `a + 5` 就是一个整型表达式,它的值取决于变量 `a` 的当前值。
简而言之,整型常量是一个已知且不变的整数值,而整型表达式是一个可以计算出整数值的公式或组合。在引用数组元素时,两者都可以用作下标,只要它们最终计算出来的值是合法的整数索引即可。
1+3 算是整型常量表达式吗
是的,`1+3` 算是一个整型常量表达式。这个表达式由两个整型常量(1和3)通过加法运算符(+)组合而成,其值在编译时就可以确定为4。因此,它符合整型常量表达式的定义。尽管在编写代码时通常不会单独写出这样的表达式,但在某些上下文中,如宏定义或静态初始化等场景,可能会用到这种形式的整型常量表达式。
什么是初始化?就是一开始就要给好元素。
比如:int a[ ] ={6,7,8};
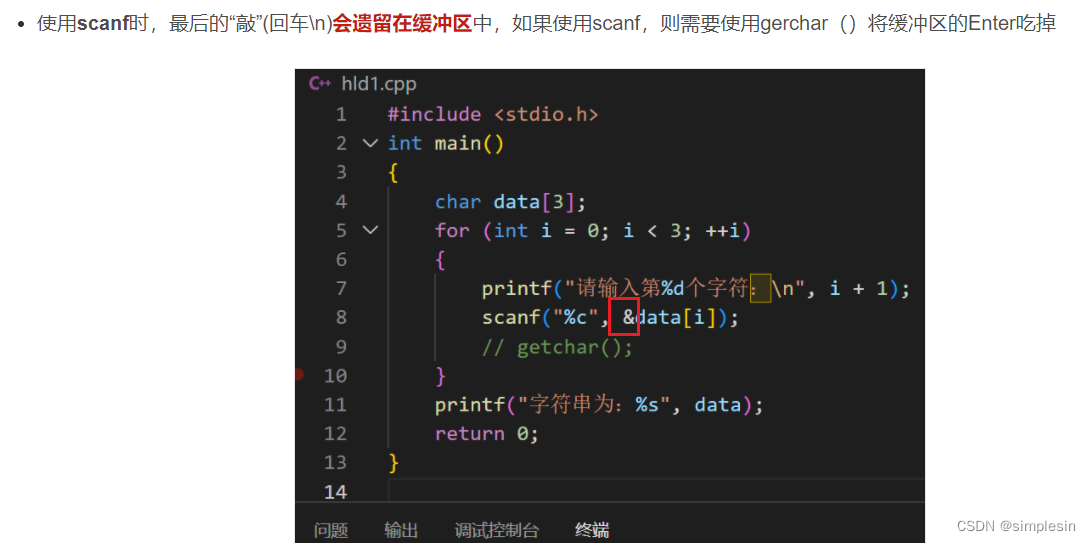
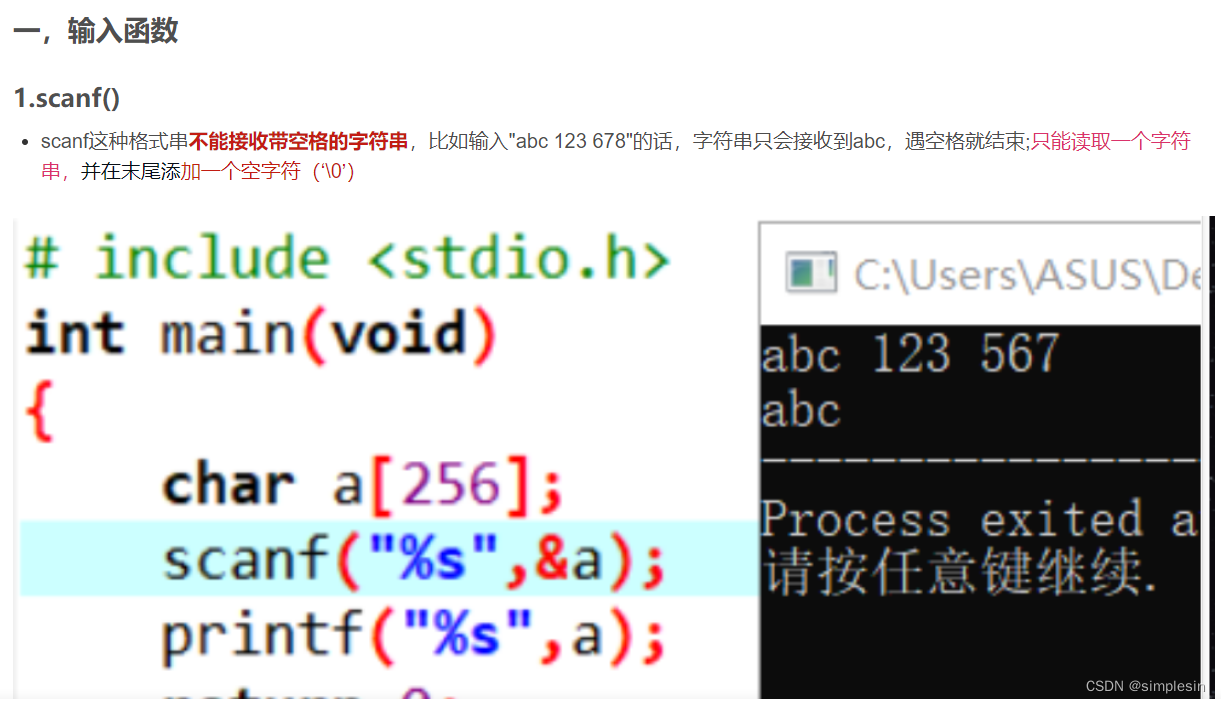
C语言字符数组的输入与输出的详细说明_c语言数组输入-CSDN博客
昨日的一些细节补充
字符占一个字节,因此转义字符'\n'占1个字节
定义符号常量不可以有分号,因此这样才是对的
#define base 1/3
这样是错的
#define base 1/3 ;
'A'+'C'没什么意义,但'A'-'C'有一定意义,知道他们中间有几个字母。
><都可以用来比较字符的大小,strcmp的实现其实就是用了这两个运算。